Toward Expert Investment Teams:A Multi-Agent LLM System with Fine-Grained Trading Tasks
Abstract: The advancement of LLMs has accelerated the development of autonomous financial trading systems. While mainstream approaches deploy multi-agent systems mimicking analyst and manager roles, they often rely on abstract instructions that overlook the intricacies of real-world workflows, which can lead to degraded inference performance and less transparent decision-making. Therefore, we propose a multi-agent LLM trading framework that explicitly decomposes investment analysis into fine-grained tasks, rather than providing coarse-grained instructions. We evaluate the proposed framework using Japanese stock data, including prices, financial statements, news, and macro information, under a leakage-controlled backtesting setting. Experimental results show that fine-grained task decomposition significantly improves risk-adjusted returns compared to conventional coarse-grained designs. Crucially, further analysis of intermediate agent outputs suggests that alignment between analytical outputs and downstream decision preferences is a critical driver of system performance. Moreover, we conduct standard portfolio optimization, exploiting low correlation with the stock index and the variance of each system's output. This approach achieves superior performance. These findings contribute to the design of agent structure and task configuration when applying LLM agents to trading systems in practical settings.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper builds a “team” of AI helpers to pick stocks, like a group of human analysts working together. Instead of giving each AI a vague job (“Analyze this company”), the authors split the work into many small, clear tasks (“Calculate these five ratios,” “Check these news items,” “Score this trend”). They test whether this fine-grained approach makes the AI team invest better, explain its choices more clearly, and fit into real-world portfolios.
What questions did the researchers ask?
The study focuses on simple, practical questions:
- Does breaking big investing jobs into smaller steps help an AI team make better investing decisions than giving broad, fuzzy instructions?
- Which types of AI “specialists” help the most (for example, price-pattern experts vs. financial-statement experts)?
- Does task design make the AI’s reasoning easier to understand and more consistent from one agent to the next?
- Can an AI strategy combine with a market index to make a smoother, more reliable portfolio?
How did they test this?
The authors set up a realistic experiment in the Japanese stock market and compared two styles of AI instructions (fine-grained vs. coarse-grained).
Here’s what they did, in everyday terms:
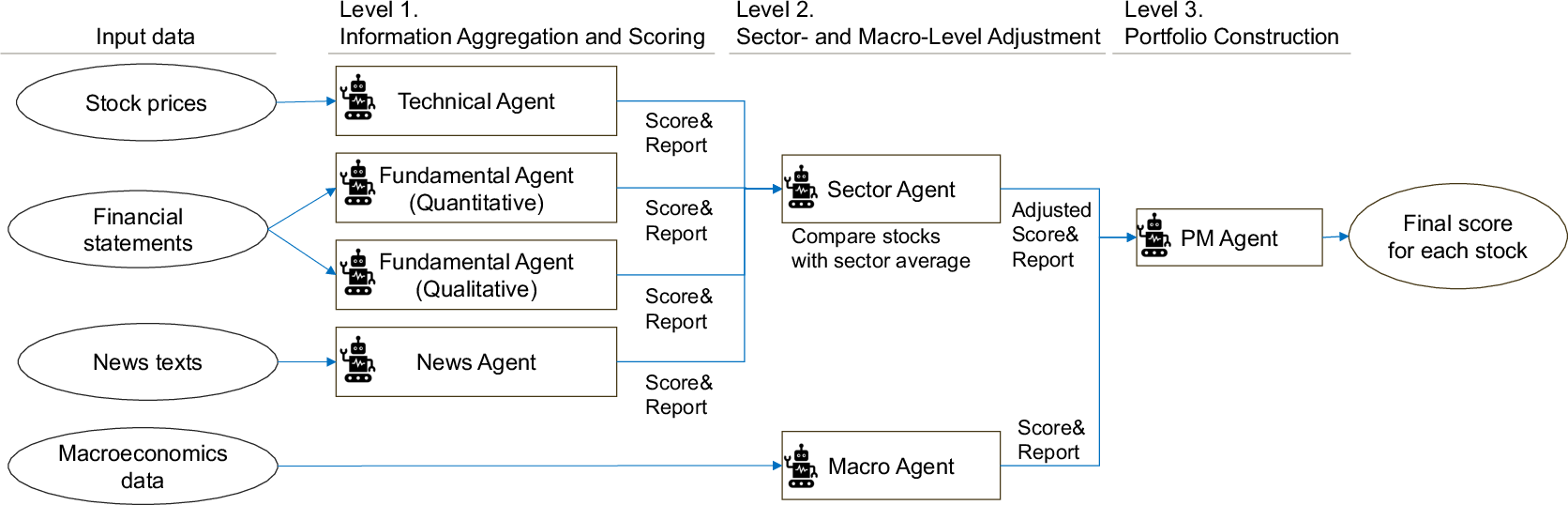
- Built an AI “investment team” with roles:
- Technical Agent: reads price charts and trends.
- Quantitative Agent: checks company numbers (profits, debt, cash flow).
- Qualitative Agent: reads company reports to judge strategy and risks.
- News Agent: scans headlines for good/bad events.
- Sector Agent: compares companies to peers in the same industry.
- Macro Agent: summarizes the big-picture economy (rates, inflation, growth).
- Portfolio Manager (PM): combines all inputs and picks what to buy or sell.
- Compared two ways of telling agents what to do:
- Fine-grained tasks: give pre-computed indicators and specific checklists (e.g., “Use these momentum and volatility measures,” “Score profitability using ROE, margins, and growth”).
- Coarse-grained tasks: hand over raw data (like 1 year of prices or full financial statements) with vague instructions (“Analyze this”) and let the AI figure it out.
- Used real data and realistic rules:
- Universe: Japan’s TOPIX 100 (large, well-known companies).
- Strategy: market-neutral long–short (buying top-scored stocks and shorting low-scored ones in equal amounts). This is like cheering for your favorite team while also betting against a different team so overall you’re less affected by the whole league’s ups and downs.
- Rebalancing monthly: refresh picks once a month.
- No “peeking into the future”: they only fed the AI information that would have been public at the time of each decision, and they used an AI model whose training ended before the test period. This avoids “leakage” (cheating by accidentally using future info).
- Main score: the Sharpe ratio (a simple way to say “how much gain you get for the bumpy ride” — higher is better risk-adjusted performance).
- Checked how well the team communicated:
- Looked at the words the agents used to see if the PM echoed the specialists’ ideas.
- Measured how similar the agents’ write-ups were to each other to see if useful signals traveled up the chain.
- Tried portfolio blending:
- Combined the AI strategy with the overall market index to see if mixing them made a smoother ride (diversification).
What did they find, and why does it matter?
The main results are clear and practical:
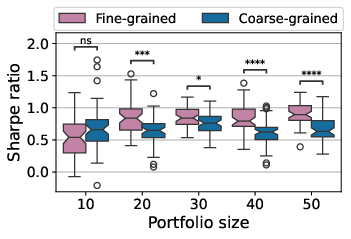
- Breaking tasks into smaller steps worked better.
- The fine-grained setup beat the coarse-grained one in most portfolio sizes when judged by the Sharpe ratio. In plain terms, more detailed instructions led to smarter, more stable performance.
- The “price-pattern” specialist was especially valuable.
- The Technical Agent (which uses tools like momentum and moving averages) drove a lot of the improvement. When this agent was removed, results got worse, especially in the fine-grained setup.
- Not every extra agent helps.
- Removing some agents (like the News or certain fundamentals agents) sometimes improved results. This means more voices aren’t always better; if they add noise, they can hurt performance. Careful task design > simply adding more agents.
- Fine-grained tasks improved communication and clarity.
- With fine-grained prompts, the higher-level agents (Sector, PM) used more precise words (“momentum,” “volatility,” “profitability”) and better reflected the specialists’ insights. This suggests the PM actually “heard” and used the technical and fundamental signals as intended, making decisions more explainable.
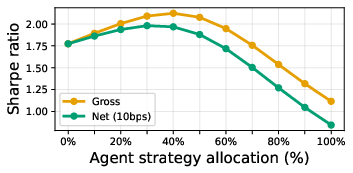
- Combining the AI strategy with the market index made a stronger portfolio.
- The AI strategy didn’t move exactly like the index (low correlation), which is great for diversification. Mixing them (even a simple 50/50 split) raised the Sharpe ratio, meaning a smoother, more efficient performance after accounting for normal trading costs.
Why this matters: In real investing, both performance and trust are critical. This study shows that giving AIs clear, expert-style steps can boost returns and make their reasoning more transparent—important for risk control, oversight, and real-world deployment.
How to think about the methods (in simple terms)
- Fine-grained vs. coarse-grained is like recipes:
- Coarse: “Make dinner from these ingredients.”
- Fine: “Boil pasta 8 minutes, sauté tomatoes, add salt, then mix.”
- The fine version helps even a smart cook (or AI) do better, more consistent work.
- Market-neutral long–short is like balancing:
- You’re not just hoping the whole market goes up. You back your favorites and bet against your least favorites so your results depend more on your choices, not on the whole market’s mood.
- Sharpe ratio is “return per unit of shakiness”:
- It rewards steady, reliable gains over lucky but wild swings.
- No “future peeking” is fairness:
- The AI only gets info that was available at the time, like not reading the answer key before the test.
What could this change in the future?
- Better AI teammates, not just “black boxes”:
- Splitting work into clear steps can make AI investment teams more reliable and easier to audit—key for firms that manage real money and must explain decisions.
- Smarter system design:
- The study suggests you should invest time in task design and information flow, not just add more agents. The right structure helps useful signals (like technical patterns) reach the final decision.
- Practical use right now:
- Even if a company isn’t ready to let AI trade alone, mixing a well-designed AI strategy with a market index can improve a portfolio’s smoothness and efficiency.
In short: Giving AIs clear, step-by-step jobs—much like real analysts do—helps them invest better and explain their choices. This makes AI teams more useful, trustworthy, and easier to plug into real-world portfolios.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to guide actionable next steps for future research.
- Generalizability: Results are confined to TOPIX 100 large-cap Japanese equities with monthly rebalancing over a 27-month window; efficacy across other geographies, mid/small-caps, asset classes (e.g., FX, futures), and higher-frequency horizons (weekly/daily/intraday) remains untested.
- Survivorship and membership dynamics: The handling of historical TOPIX 100 constituent changes (additions/removals, delistings) is not specified, leaving potential survivorship and reconstitution biases unresolved.
- Data-timestamp fidelity and release lags: The backtest assumes “latest available” statements/macros, but does not model actual release times, reporting lags, or revisions (financials, macro series), introducing possible look-ahead bias.
- News timing and scope: Headlines/previews are used without explicit intraday timestamp alignment (time zones, publication delays), and paywalled content is excluded—potentially biasing sentiment coverage and timing; impact of these constraints is not quantified.
- Transaction costs and execution frictions: Core long–short backtest does not explicitly include trading costs, slippage, market impact, borrow availability/fees, dividend treatment, or corporate actions; only the portfolio-blend experiment accounts for a simple 10 bps cost.
- Market-neutrality specifics: The strategy uses equal-weight long/short counts, but does not enforce beta, sector, or factor neutrality; residual factor exposures and their contribution to performance are unmeasured.
- Risk and performance diagnostics: Beyond Sharpe ratio, no drawdown, turnover, capacity, or tail-risk metrics are reported; stability across market regimes and crowding risk are not analyzed.
- Baseline comparisons: There is no comparison with non-LLM benchmarks (e.g., simple rules on the same indicators, linear/ridge models, gradient boosting, or standard quant factor models), limiting attribution of gains to the multi-agent LLM design.
- Confound between feature engineering and task granularity: “Fine-grained” setups supply precomputed indicators/ratios, while “coarse-grained” baselines receive raw data—making it unclear whether improvements stem from decomposition per se or from feature engineering.
- Incomplete granularity test across roles: Fine-vs-coarse granularity is only tested for the Technical and Quantitative agents; task decomposition effects for the Qualitative, News, Sector, Macro, and PM agents remain unexplored.
- Agent-value inconsistency: Ablations show several agents (Quantitative, Qualitative, Macro) often hurt performance; the paper does not propose mechanisms to adaptively gate, weight, or prune agents to mitigate noise.
- Alignment claims unquantified: The paper posits that “alignment between analytical outputs and downstream decision preferences” drives performance, but provides only embedding similarities; no causal tests, calibration analyses, or optimization of alignment are presented.
- Embedding validity for Japanese text: Semantic-propagation analysis uses an English-centric embedding model (text-embedding-3-small) on short Japanese outputs (~100 characters) without validating cross-lingual embedding fidelity or robustness.
- Language/model sensitivity: All results rely on GPT‑4o with a single temperature setting; robustness to model choice (provider, size), multilingual prompting, tokenizer effects, and inference settings (temperature/top‑p) is not assessed.
- Reproducibility under stochasticity: Performance is reported over 50 stochastic trials, but the practical deployment protocol (e.g., number of samples per decision, aggregation policy at inference time) is unspecified; independence of trials sharing the same time series is also not established.
- Missing-data handling: Numerical NaNs are passed directly to the LLM, relying on unspecified model behavior; systematic imputation strategies and their effect on stability/performance are not explored.
- Hallucination and data verification: No safeguards or audits are reported for LLM hallucinations, misparsing of statements, or misattribution of news; the frequency and impact of such errors are unknown.
- Score-to-return calibration: The 0–100 attractiveness scores are not calibrated to expected returns or risk; no analyses link score dispersion to subsequent return distributions (e.g., information coefficient, calibration curves).
- PM aggregation as a black box: The PM consolidates signals via natural language without explicit, testable weighting; comparison against transparent linear/convex aggregation or rule-based ensembles is missing.
- Macro agent design: Macro ablation often improves performance, suggesting the current macro process may inject noise; the paper does not examine why (e.g., indicator selection, lag choice, regime detection) or propose refinement strategies.
- Portfolio-optimization look-ahead risk: The agent-level covariance used for equal risk contribution appears derived from full-period stock covariances; the paper does not specify a rolling, ex-ante estimation window, risking in-sample bias.
- Scalability and cost: Runtime, API costs, and memory constraints for scaling from 100 to thousands of securities, higher rebalancing frequencies, or multi-asset universes are not measured.
- Human-centered interpretability: Although textual analyses are provided, no human evaluation (e.g., analyst ratings of explanations, decision-faithfulness audits) is conducted to establish real-world interpretability and trust.
- Regime robustness: The 2023–2025 period may include idiosyncratic conditions; the strategy’s behavior under different macro/market regimes (e.g., crises, stagflation) is not stress-tested.
- Compliance and operational risks: The paper does not discuss regulatory, data-governance, or model-risk management constraints of deploying external LLMs and multi-agent pipelines in production finance environments.
- Alternative architectures: There is no exploration of simpler non-agent LLM baselines (single-agent with SOPs), classical signal pipelines plus LLM summarization, or hybrid systems that might yield similar performance with lower complexity.
- Fine-grained task design methodology: The process for constructing “realistic” fine-grained tasks (mapping to SOPs, coverage, completeness) is not formalized, hindering reproducibility and adaptation to other domains or teams.
- Sensitivity to universe liquidity and shorting constraints: TOPIX 100 is liquid, but the approach’s capacity and borrow constraints are not quantified; extending to less liquid universes may materially change feasibility and performance.
- Failure-case analysis: Cases where coarse-grained equals or outperforms fine-grained (e.g., N=10) are not investigated to identify when decomposition may be unnecessary or harmful.
- Information content attribution: Beyond Sharpe, the paper does not report signal-level IC/IR, cross-sectional t-stats, or factor-neutralized alphas to isolate genuine predictive content versus incidental exposure.
- Real-time readiness: Latency of the multi-agent pipeline and data ingestion throughput (news/filings) are not benchmarked; operational SLAs for monthly vs higher-frequency deployment are unknown.
Practical Applications
Practical, Real-World Applications Derived from the Paper
The paper proposes and evaluates a hierarchical multi-agent LLM trading framework that decomposes investment analysis into fine-grained tasks (e.g., technical indicators, standardized quantitative metrics, sector adjustment, macro assessment). It demonstrates improved risk-adjusted returns versus coarse-grained designs, better interpretability via agent-level outputs, and portfolio optimization benefits through diversification with market indices. Below are actionable applications grouped by deployment horizon.
Immediate Applications
The following items can be piloted or deployed now, given current toolchains, data sources, and organizational practices.
- Buy-side decision support for monthly long–short portfolios
- Sector: Finance (asset management, hedge funds)
- Application: Use the fine-grained multi-agent LLM to produce monthly, market-neutral long–short recommendations on large-cap equities, with analysts reviewing intermediate rationales before execution.
- Tools/workflows: “Analyst-in-the-loop” agent platform; standardized technical and quantitative prompt libraries; monthly rebalancing scheduler; audit logs of agent reasoning.
- Assumptions/dependencies: Reliable access to time-ordered market, financial statement, and news data; leakage-controlled ingestion; adherence to internal risk limits; transaction cost estimates.
- Portfolio diversification overlay against index holdings
- Sector: Finance
- Application: Blend a low-correlation composite of agent strategies with TOPIX 100 (or other indices) to improve portfolio Sharpe without full autonomy. Start with paper-trading or small allocations.
- Tools/workflows: Equal-risk-contribution aggregation of multiple agent strategies; covariance estimation from stock-level holdings; allocation sweep tooling.
- Assumptions/dependencies: Sufficient out-of-sample validation; transaction cost modeling; operational guardrails; ongoing performance monitoring.
- Explainability and alignment monitoring for AI trading systems
- Sector: Finance, RegTech, Compliance
- Application: Deploy dashboards that track semantic alignment across agents (e.g., cosine similarity between analyst outputs and sector/PM summaries) and vocabulary shifts (log-odds analysis) to evidence traceability and decision provenance.
- Tools/workflows: Embedding-based similarity services; reasoning-text capture pipeline; explainability reports for investment committees.
- Assumptions/dependencies: Stable embedding models; robust text preprocessing; governance processes to review and act on alignment signals.
- Fine-grained prompt library for financial analysis
- Sector: Software/FinTech, Education
- Application: Package and distribute prompts encoding technical indicators (RoC, MACD, RSI, KDJ), standardized quantitative metrics (profitability, safety, valuation, efficiency, growth), sector normalization, and macro scoring to improve LLM output quality and consistency.
- Tools/workflows: Versioned prompt repository; SOP templates; domain-expert curation; unit tests for prompt behavior.
- Assumptions/dependencies: Access to clean, timely inputs; model compatibility; organizational adoption of SOP-based prompt engineering.
- Leakage-controlled data engineering patterns
- Sector: Data/ML Engineering
- Application: Implement strict temporal ordering, knowledge-cutoff-aware ingestion, and monthly decision windows to mitigate look-ahead bias in LLM-driven finance applications.
- Tools/workflows: Time-aware ETL; data access policies; audit trails; dry-run backtesting harnesses.
- Assumptions/dependencies: Reliable historical sources (Yahoo Finance, EDINET/FSA, FRED, reputable news aggregators); legal use of data; CI/CD for data pipelines.
- Sell-side research augmentation and news triage
- Sector: Finance (sell-side research)
- Application: Use the multi-agent system to pre-structure company notes with sector adjustments, quantify sentiment/events from headlines, and surface risks/opportunities for analyst review.
- Tools/workflows: News agent for monthly ingest; qualitative agent extracting governance, risks, and management policies; sector agent synthesizing cross-stock comparisons.
- Assumptions/dependencies: Editor oversight to prevent hallucinations; coverage lists; journalistic standards; timely access to local-language sources.
- Reproducible academic benchmarking and ablation studies
- Sector: Academia
- Application: Adopt the paper’s leakage-controlled backtesting setup, agent ablation methodology, and text-propagation analytics to study multi-agent architectures, task granularity, and decision alignment.
- Tools/workflows: Shared codebase and prompts; standardized metrics (Sharpe); embedding-based similarity protocols; Mann–Whitney U test for significance.
- Assumptions/dependencies: Availability of released code/data; IRB/compliance where necessary; compute budgets for repeated trials.
- Retail investor education and safe analysis aids
- Sector: Education/Daily life
- Application: Provide educational tools that explain how technical and fundamental indicators influence sector-adjusted views, with conservative guardrails and clear disclaimers (not investment advice).
- Tools/workflows: Interactive explainers; monthly market regime summaries; “why” texts from agents for learning.
- Assumptions/dependencies: Risk disclosures; simplified scopes; protection against inappropriate autonomy.
Long-Term Applications
These items require further research, scaling, regulatory evolution, or technological development before widespread deployment.
- Fully autonomous multi-agent trading with adaptive learning
- Sector: Finance
- Application: Integrate reinforcement learning, reflection, and layered memory to adapt policies over time while maintaining explainability and alignment across agents.
- Tools/workflows: Feedback loops from realized P&L; episodic memory management; automated ablation/self-optimization.
- Assumptions/dependencies: Robust RL for non-stationary markets; strong model-risk controls; fail-safes for capital protection.
- Cross-market, multi-asset expansion with multilingual analysis
- Sector: Finance
- Application: Extend the framework to global equities, fixed income, FX, commodities, and sectors using multilingual news and filings; refine sector normalization across diverse taxonomies.
- Tools/workflows: Global data ingestion; cross-lingual embeddings; asset-specific indicator libraries; unified risk models.
- Assumptions/dependencies: Licensing for global data; translation quality; domain adaptation; increased compute and ops maturity.
- Intraday or real-time agent orchestration
- Sector: Finance, Software
- Application: Move from monthly to higher-frequency decision cycles with streaming data, low-latency inference, and micro-rebalancing.
- Tools/workflows: Event-driven pipelines; latency-optimized serving; real-time risk controls; OMS/EMS integrations.
- Assumptions/dependencies: Faster, cheaper inference; robust short-horizon signals; tighter slippage/TC modeling; operational resilience.
- Standardized regulatory frameworks for AI-driven trading
- Sector: Policy/Regulation
- Application: Establish audit standards (explainability logs, alignment metrics), stress testing protocols, leakage controls, and sandbox pathways for AI trading systems.
- Tools/workflows: Supervisory technology (SupTech) portals; standardized reporting schemas; certification programs.
- Assumptions/dependencies: Industry–regulator consensus; evidence from pilots; legal clarity on accountability and model risk.
- Model risk governance and alignment tooling
- Sector: RegTech/ML Ops
- Application: Build commercial tools to monitor semantic alignment, drift, and information propagation across agents, with alerts and remediation workflows.
- Tools/workflows: Alignment scorecards; drift detectors; policy enforcement engines; audit-ready storage of reasoning traces.
- Assumptions/dependencies: Accepted KPIs for alignment; interoperability with existing GRC systems; privacy/security guarantees.
- Domain-tuned financial LLMs and agent components
- Sector: Software/AI
- Application: Train or fine-tune models on curated financial corpora (filings, macro reports, sector primers) to improve quantitative reasoning, reduce hallucinations, and handle NaNs/missing data robustly.
- Tools/workflows: Data curation pipelines; instruction tuning with SOPs; evaluation harnesses specific to finance tasks.
- Assumptions/dependencies: High-quality, licensed data; legal/IP compliance; ongoing calibration against market outcomes.
- Generalized agent information-propagation analytics for other sectors
- Sector: Healthcare, Industrial Ops, Robotics, Education
- Application: Apply alignment and propagation measures (embeddings, similarity matrices, vocabulary shifts) to multi-agent systems in diagnostics, incident response, maintenance planning, and course design.
- Tools/workflows: Cross-domain SOP-driven prompts; semantic telemetry; interpretability dashboards.
- Assumptions/dependencies: Domain-specific data and ontologies; safety-critical validation; stakeholder acceptance.
- Human–agent teaming programs and organizational change
- Sector: Finance (and broader enterprise)
- Application: Formalize workflows where PMs/managers supervise agent teams, set task granularity, and review alignment reports; train staff on SOP-based prompt design.
- Tools/workflows: Training curricula; capability matrices; RACI for agent roles; performance governance.
- Assumptions/dependencies: Cultural adoption; clear incentives; change management resources.
- Sector normalization APIs and services
- Sector: FinTech/Data
- Application: Offer services that benchmark firm metrics against sector averages and adjust scores for PMs and research tools.
- Tools/workflows: Sector taxonomy management; rolling benchmarks; plug-in modules for portfolio tools.
- Assumptions/dependencies: Consistent sector classifications; timely fundamentals; integration with client systems.
- Deeper OMS/EMS integration and automated order routing
- Sector: Finance/Trading Tech
- Application: Connect PM outputs to order management/execution systems with pre-trade risk checks, compliance rules, and staged autonomy.
- Tools/workflows: Rule-based gates; anomaly detection; kill-switches; post-trade analytics.
- Assumptions/dependencies: Vendor cooperation; robust APIs; proven reliability; regulatory approval for increasing autonomy.
Glossary
- Ablation studies: Systematic removal or modification of components to assess their impact on performance. "We conduct ablation studies to quantify the contribution of each specialized agent to overall performance."
- Agent-level covariance: The covariance matrix of returns for multiple strategies/agents derived from underlying asset covariances. "the agent-level covariance is computed as ."
- Basis points (bps): One hundredth of a percent (0.01%), commonly used to quote fees and yields. "10 bps one-way"
- Bollinger Band: A volatility indicator using bands around a moving average to identify extreme price levels. "Volatility: Bollinger Band: Instead of price bands, we identify statistically extreme levels using the Z-score formula"
- CAGR (Compound Annual Growth Rate): The annualized average growth rate of a metric over a period, assuming compounding. "Revenue Growth Rate (CAGR)"
- Chain-of-Thought (CoT) prompting: Prompting that structures reasoning steps explicitly to guide domain-specific analysis. "Financial Chain-of-Thought (CoT) prompting"
- Cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them. "We then compute cosine similarities between agent output vectors"
- Current Ratio: A liquidity metric measuring a firm's ability to pay short-term obligations (current assets/current liabilities). "Current Ratio"
- Dirichlet prior: A Bayesian prior over multinomial distributions, often used in text statistics. "using the log-odds ratio with a Dirichlet prior"
- D/E Ratio: Debt-to-Equity ratio; a leverage metric comparing total debt to shareholders’ equity. "D/E Ratio"
- Dividend Yield: Annual dividends per share divided by price per share; a valuation metric. "Dividend Yield"
- EDINET API: Japan FSA’s API for accessing securities filings and financial reports. "EDINET API"
- Equal risk contribution weighting scheme: A portfolio allocation method that equalizes each component’s contribution to total risk. "constructed using an equal risk contribution weighting scheme."
- Equity Ratio: The proportion of total assets financed by shareholders’ equity. "Equity Ratio"
- EV/EBITDA Multiple: Enterprise value divided by EBITDA; a valuation ratio comparing company value to operating earnings. "EV/EBITDA Multiple"
- Exponential Moving Average (EMA): A moving average that weights recent observations more heavily than older ones. "exponential moving averages (EMA) of price"
- FCF Margin: Free Cash Flow as a percentage of revenue; a profitability measure. "FCF Margin"
- FRED: Federal Reserve Economic Data, a comprehensive U.S. economic time series database. "FRED"
- Inventory Turnover Period: The average number of days inventory is held before being sold. "Inventory Turnover Period"
- JGB (Japanese Government Bond): Government debt securities issued by Japan. "JP 10Y JGB Yield"
- KDJ: A stochastic oscillator variant using %K, %D, and J lines to identify momentum and reversals. "Oscillator: (KDJ):"
- Knowledge cutoff: The most recent date of information included in an LLM’s training data. "knowledge cutoff date"
- Leave-one-out (settings): An evaluation where one component is removed to assess its individual impact. "leave-one-out settings"
- Log-odds ratio: A statistical measure comparing relative word frequencies between groups. "the log-odds ratio with a Dirichlet prior"
- Look-ahead bias: Artificial performance inflation caused by using information not available at the decision time. "look-ahead bias"
- MACD (Moving Average Convergence Divergence): A momentum indicator using differences between EMAs to gauge trend strength. "Moving Average Convergence Divergence (MACD)"
- Mann-Whitney U test: A nonparametric statistical test comparing differences between two independent samples. "Mann-Whitney U test significance"
- Market-neutral strategy: A portfolio designed to have minimal net market exposure, isolating security selection skill. "market-neutral strategy"
- Market regime: The prevailing market environment characterized by factors like trend, volatility, and macro conditions. "evaluates the current market regime"
- MetaGPT: A framework that encodes expert workflows (SOPs) into multi-agent systems for improved reliability. "MetaGPT"
- Operating Profit Margin: Operating profit divided by revenue; a core profitability metric. "Operating Profit Margin"
- Out-of-sample performance: Evaluation on data not used during design or training to assess generalization. "evaluating out-of-sample performance"
- P/E Ratio: Price-to-Earnings ratio; a valuation metric comparing price per share to earnings per share. "P/E Ratio"
- plan-and-execute: An agent paradigm that separates planning from execution to stabilize reasoning. "plan-and-execute"
- Portfolio optimization: The process of allocating weights to assets/strategies to balance return and risk. "standard portfolio optimization"
- Rate of Change (RoC): A momentum metric measuring percentage change over a specified lookback horizon. "Rate of Change (RoC)"
- Rebalancing: Periodic adjustment of portfolio weights back to target allocations. "portfolio rebalancing"
- Reflection mechanisms: Feedback processes that incorporate realized outcomes into subsequent decision policies. "Reflection mechanisms"
- Relative Strength Index (RSI): A momentum oscillator indicating overbought/oversold conditions based on recent gains/losses. "Relative Strength Index (RSI)"
- Risk contribution: The portion of total portfolio variance attributable to an individual asset or strategy. "equalizes each agent's risk contribution to total portfolio variance"
- ROA: Return on Assets; net income divided by total assets, measuring asset efficiency. "ROA"
- ROE: Return on Equity; net income divided by shareholders’ equity, measuring profitability to owners. "ROE"
- Sharpe ratio: Risk-adjusted return metric defined as mean return divided by return standard deviation. "Sharpe ratio"
- Standard Operating Procedures (SOPs): Codified, step-by-step workflows used to ensure consistent execution. "Standard Operating Procedures (SOPs)"
- Stochastic oscillator: A momentum indicator comparing a security’s closing price to its recent high–low range. "We calculate the stochastic oscillator"
- TOPIX 100: An index of the 100 largest stocks by market capitalization in Japan. "TOPIX 100"
- Trailing Twelve-Month (TTM): Aggregating the most recent 12 months of data to capture up-to-date performance. "Trailing Twelve-Month (TTM)"
- US VIX: The U.S. equity market’s implied volatility index derived from S&P 500 options. "US VIX"
- Z-score: A standardized measure indicating how many standard deviations a value is from the mean. "Z-score formula "
- Leakage-controlled backtesting: A backtest design that explicitly prevents future information from influencing past decisions. "under a leakage-controlled backtesting setting."
- Long-short strategy: A strategy that takes both long and short positions to profit from relative performance. "a long-short strategy targeting large-cap stocks in Japanese equity markets."
- EPS (Earnings Per Share): Company earnings allocated to each outstanding share, a core profitability metric. "Market Data: Monthly Close, EPS, Dividends, Issued Shares."
- EPS Growth Rate: The rate at which earnings per share increase over time. "EPS Growth Rate"
- Equity Ratio: The share of a company’s assets financed by equity rather than debt. "Equity Ratio"
- Total Asset Turnover: Revenue divided by total assets, indicating efficiency in using assets to generate sales. "Total Asset Turnover"
Collections
Sign up for free to add this paper to one or more collections.