- The paper introduces a novel framework that integrates LLM-based reasoning with volatility-adjusted reinforcement learning for evidence-based trading recommendations.
- It employs a unique three-stage curriculum combining supervised fine-tuning and RL to stabilize structured thesis generation and decision-making.
- Experimental results show superior risk-adjusted returns with improved Sharpe ratios and hit rates compared to baseline models.
Trading-R1: Financial Trading with LLM Reasoning via Reinforcement Learning
Introduction and Motivation
Trading-R1 addresses the challenge of aligning LLMs with the requirements of professional financial trading, emphasizing structured reasoning, interpretability, and risk-aware decision-making. Traditional time-series models lack explainability, and general-purpose LLMs struggle to produce disciplined, actionable trading recommendations. Trading-R1 is designed to bridge this gap by integrating financial domain knowledge, structured thesis generation, and volatility-adjusted reinforcement learning, enabling the model to generate evidence-based investment theses and executable trade decisions.
Data Collection and Labeling
A critical component of Trading-R1 is the Tauric-TR1-DB corpus, comprising 100k samples over 18 months, 14 equities, and five heterogeneous financial data sources (technical, fundamental, news, sentiment, macro). The data pipeline emphasizes breadth (diverse tickers and sectors), depth (multi-modal features per asset-day), and robustness (randomized input composition to simulate real-world data incompleteness). This ensures high signal-to-noise ratio and generalizability across market regimes.
Labels for supervised and RL training are generated via a multi-horizon, volatility-adjusted discretization procedure. Forward returns over 3, 7, and 15 days are normalized by rolling volatility, combined with empirically determined weights, and mapped to a five-class action space (Strong Buy, Buy, Hold, Sell, Strong Sell) using asymmetric quantiles. This approach captures both short-term momentum and medium-term trends, aligns with real-world trading practices, and provides a scalable reward signal for RL.
Training Methodology
Curriculum Design
Trading-R1 employs a three-stage, easy-to-hard curriculum that interleaves supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RFT):
- Stage I (Structure): SFT on professional thesis organization, followed by RFT to reinforce XML-tagged formatting and systematic analysis.
- Stage II (Claims): SFT for evidence-based reasoning, RFT to ground claims with direct citations and sources, mitigating hallucinations.
- Stage III (Decision): SFT for investment recommendation patterns, RFT with volatility-aware outcome rewards to align decisions with market dynamics.
This staged progression stabilizes intermediate reasoning, mitigates error compounding, and builds the discipline required for coherent, actionable trading outputs.
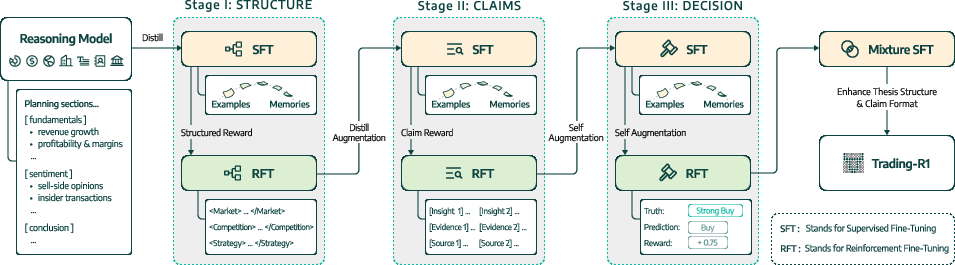
Figure 1: Trading-R1 Training Schema illustrating the multi-stage curriculum integrating SFT and RFT for structured, evidence-based, and market-aligned reasoning.
Reverse Reasoning Distillation
Obtaining high-quality reasoning traces for SFT is challenging due to the opacity of proprietary LLM APIs. Trading-R1 introduces reverse reasoning distillation: final recommendations from black-box models are paired with input data and passed to a planner LLM, which reconstructs plausible reasoning steps. These are further elaborated by a lightweight LLM and programmatically stitched into coherent traces, yielding a synthetic dataset suitable for SFT.

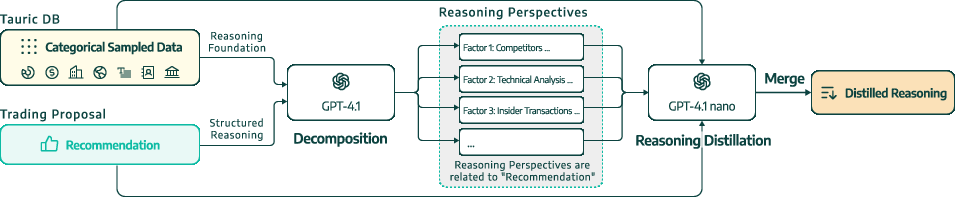
Figure 2: Investment Thesis Distillation from OpenAI Reasoning Models, demonstrating the extraction and reconstruction of reasoning traces for SFT targets.
Reinforcement Learning Optimization
RFT is performed using Group Relative Policy Optimization (GRPO), which stabilizes training by normalizing rewards within groups of sampled trajectories, eliminating the need for a separate value model. The reward integrates structure, evidence, and decision components, with an asymmetric penalty matrix reflecting institutional risk management priorities (e.g., heavier penalties for false bullish signals).

Figure 3: Reinforcement learning on Thesis Structure, Statement, and Decision, showing the integration of multi-component rewards in the RL pipeline.
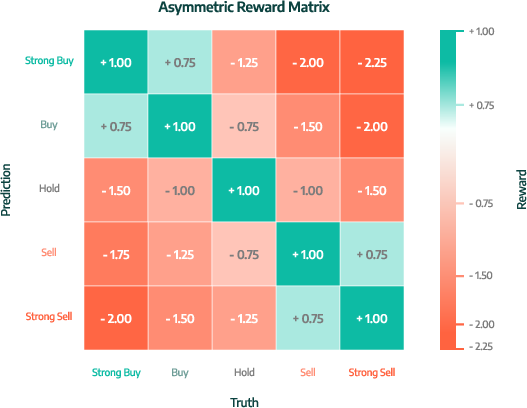
Figure 4: Trading-R1 asymmetric reward heatmap: rewards (-2.25 to 1) based on model prediction vs ground truth, with labels derived from volatility-adjusted discretization.
Experimental Results
Trading-R1 is evaluated via historical backtesting on held-out periods for major equities and ETFs. Metrics include Cumulative Return (CR), Sharpe Ratio (SR), Hit Rate (HR), and Maximum Drawdown (MDD). Baselines span small LLMs (Qwen-4B, GPT-4.1-nano), large LLMs (GPT-4.1, LLaMA-3.3), RL-enhanced models (DeepSeek, O3-mini), and ablations of Trading-R1 (SFT-only, RL-only).
Trading-R1 consistently outperforms baselines, achieving superior risk-adjusted returns and lower drawdowns. For example, on NVDA, Trading-R1 attains a Sharpe ratio of 2.72 and 8.08% return, with a hit rate of 70.0%. On SPY, it achieves a Sharpe of 1.60 and 3.34% return. SLMs and RLMs underperform due to limited parameter capacity and unguided reasoning, while general-purpose LLMs show better consistency but lack domain-specific alignment.
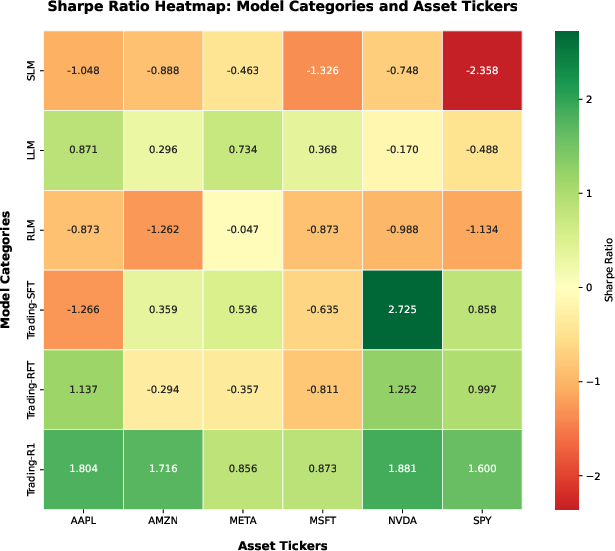
Figure 5: Sharpe Ratio Heatmap comparing Trading-R1 against baselines across multiple assets, highlighting consistent improvements in risk-adjusted performance.
The staged SFT-RFT curriculum is essential: SFT enforces professional output formats and decision patterns, while RFT aligns reasoning with market outcomes. Pure RL or SFT-only variants are less effective, either drifting from financial context or overfitting to superficial heuristics.
Implementation Considerations
- Model Architecture: Trading-R1 uses Qwen3-4B as the backbone, enabling deployment on standard commercial GPUs (8×H100/H200) and supporting long-context inputs (20–30k tokens).
- Data Pipeline: Modular, transparent, and reproducible, facilitating adaptation to proprietary datasets and institutional requirements.
- Reward Design: Three-stage reward system balances structure, evidence, and decision accuracy, with tunable weights for application-specific priorities.
- Deployment: Local and private inference is feasible, supporting sensitive data processing and customizable policies (e.g., sector-specific long/short ratios, trading frequency).
- Limitations: Hallucinations persist in long/noisy contexts; excessive RL may erode structured reasoning; training universe is biased toward large-cap, AI-driven equities; not suitable for high-frequency or fully automated trading without human oversight.
Practical and Theoretical Implications
Trading-R1 demonstrates that LLMs, when properly aligned via staged curriculum and volatility-aware RL, can generate interpretable, evidence-based investment theses and actionable trade recommendations. The framework is particularly suited for research support, structured analysis generation, and institutional applications (data vendors, sell-side/buy-side research). It enables scalable, customizable, and private deployment, augmenting human decision-making in high-throughput scenarios.
Theoretically, Trading-R1 highlights the necessity of disentangling structural and outcome rewards, sequencing reasoning scaffolds before market alignment, and leveraging synthetic reasoning traces for supervision. The staged curriculum mitigates instability and brittleness observed in prior approaches, suggesting a generalizable paradigm for aligning LLMs with complex, risk-sensitive domains.
Future Directions
- Real-time deployment: Enhancing inference speed and sample efficiency for live trading support.
- Offline RL variants: Improving sample efficiency and robustness in low-data regimes.
- Expanded modalities: Integrating alternative data sources (e.g., social media, alternative asset classes) for broader domain adaptability.
- Customization: Enabling fine-grained control over thesis structure, decision policies, and risk preferences for institutional clients.
Conclusion
Trading-R1 establishes a robust framework for financial trading with LLM reasoning, integrating structured thesis generation, volatility-aware RL, and modular data pipelines. It achieves superior risk-adjusted returns and interpretability compared to baseline models, supporting practical applications in research, data processing, and decision support. The staged curriculum and reward design offer a blueprint for aligning LLMs with complex, high-stakes domains, with future work focused on real-time deployment, expanded data integration, and enhanced customization for institutional use.