- The paper introduces a hybrid LLM-guided reinforcement learning system that enhances trading performance by improving Sharpe Ratio and reducing Maximum Drawdown.
- It employs a structured prompt engineering approach to generate economically grounded trading strategies, validated through expert reviews and backtesting.
- The integrated LLM+RL model outperforms standard RL baselines across diverse equities, demonstrating faster convergence, stability, and superior risk-adjusted returns.
LLM-Guided Reinforcement Learning in Quantitative Trading
This paper introduces a hybrid architecture that combines the strategic reasoning capabilities of LLMs with the execution strengths of RL agents for algorithmic trading. The system integrates three agents: a Strategist Agent (LLM) generating high-level trading policies, an Analyst Agent (LLM) structuring financial news, and an RL Agent executing short-term trading actions. The authors evaluate the rationale of LLM-generated strategies via expert review and the Sharpe Ratio (SR) and Maximum Drawdown (MDD) of LLM-guided agents versus unguided baselines. The results indicate improved return and risk metrics compared to standard RL.
Aim and Objectives
The research focuses on two primary objectives: LLM Trading Strategy Generation and LLM-Guided RL. The first objective involves developing an approach for LLMs to generate coherent and economically grounded trading strategies, evaluated by expert reviewers. The second objective assesses whether a hybrid LLM+RL architecture improves an agent’s performance across diverse equities and market regimes, specifically by increasing SR and reducing MDD relative to unguided RL baselines, without retraining or fine-tuning.
Materials and Methods
The methodology involves two experiments. Experiment 1 focuses on LLM Trading Strategy Generation, utilizing a multi-modal dataset spanning 2012–2020, including OHLCV data, market data, fundamentals, technical analytics, and alternative data. The data is consumed by the Strategist Agent and the Analyst Agent, which distill news into signals. OpenAI’s GPT-4o Mini is used as the LLM backbone, refined through prompt engineering techniques including a Writer–Judge Loop, In-Context Memory (ICM), Instruction Decomposition, and News Factors.
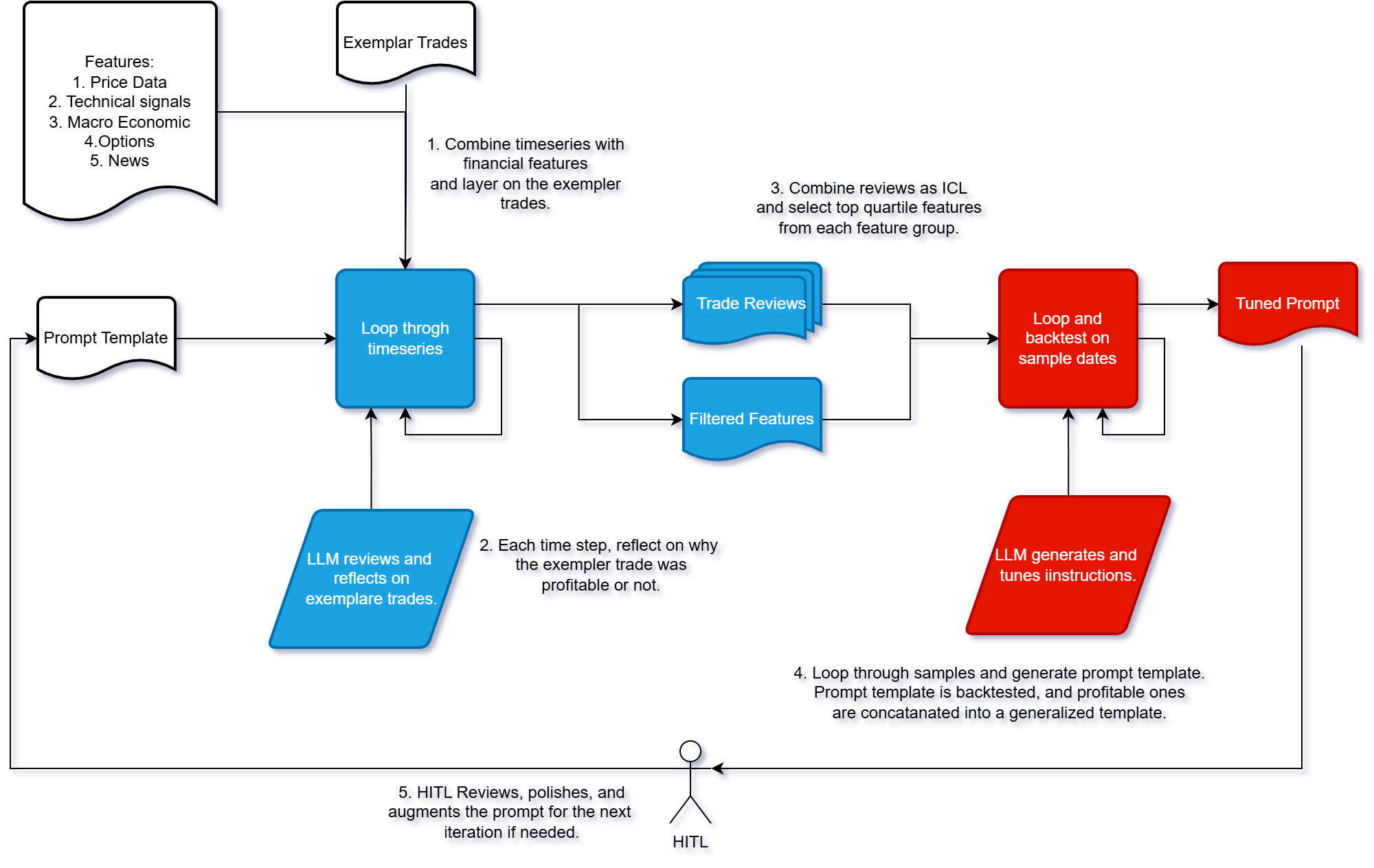
Figure 1: Prompt tuning workflow.
The prompt refinement process follows a structured loop (Figure 1), refining prompts via backtests, and Bayesian regret minimization. This process aims to optimize the LLM's ability to generate expert-aligned trading strategies. The prompts generate the writer-generator prompt πt that are evaluated via backtests (with SR Vπt), judged, and updated using a Bayesian update approach to minimize regret:
R(T)=E[t=1∑T(V∗−Vπt)∣Ht]
Qualitative assessment is conducted via the Expert Review Score (ERS), evaluating LLM-generated rationales along dimensions like economic rationale, domain fidelity, and trade safety.
Experiment 2 focuses on LLM-Guided RL, adopting the DDQN configuration with an LLM-derived interaction term appended to the observation space. This term includes Signal Direction and Signal Strength, derived from the LLM's confidence score and adjusted using entropy-based certainty. The LLM+RL hybrid architecture (Figure 2) integrates the Strategist and Analyst Agents into the DDQN framework. The training uses an NVIDIA RTX 3050, with each equity trained for 3 hours. Evaluation metrics include SR and MDD.
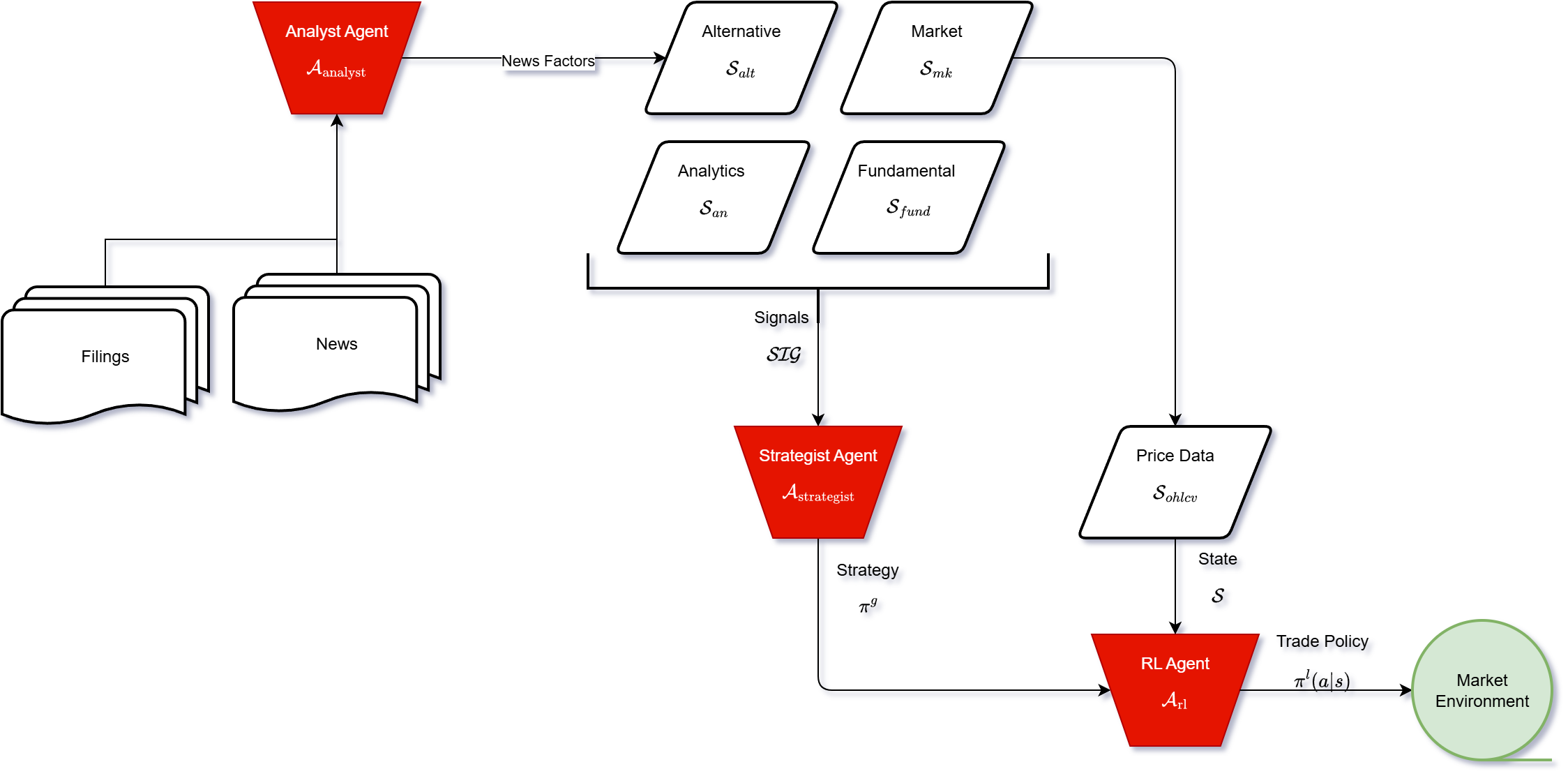
Figure 2: LLM-guided RL architecture.
Results and Discussion
Experiment 1 results indicate that structured prompting significantly influences the quality of generated strategies. Prompt 4, incorporating unstructured news signals, achieves the highest mean SR (1.02) and lowest PPL and entropy. Expert evaluations of Prompt 4 confirm its effectiveness in synthesizing structured and unstructured signals, with high ratings for rationale, fidelity, and safety.
Experiment 2 results demonstrate that the LLM+RL agent outperforms the RL-only baseline in 4 out of 6 assets, with statistically significant differences. The hybrid agent shows improved mean Sharpe and stability, along with faster convergence and lower variance in Q-values. (Figure 3) illustrates AAPL's trading behavior, highlighting the LLM's sparse but confident signals and the RL agent's mistimed entries and exits.
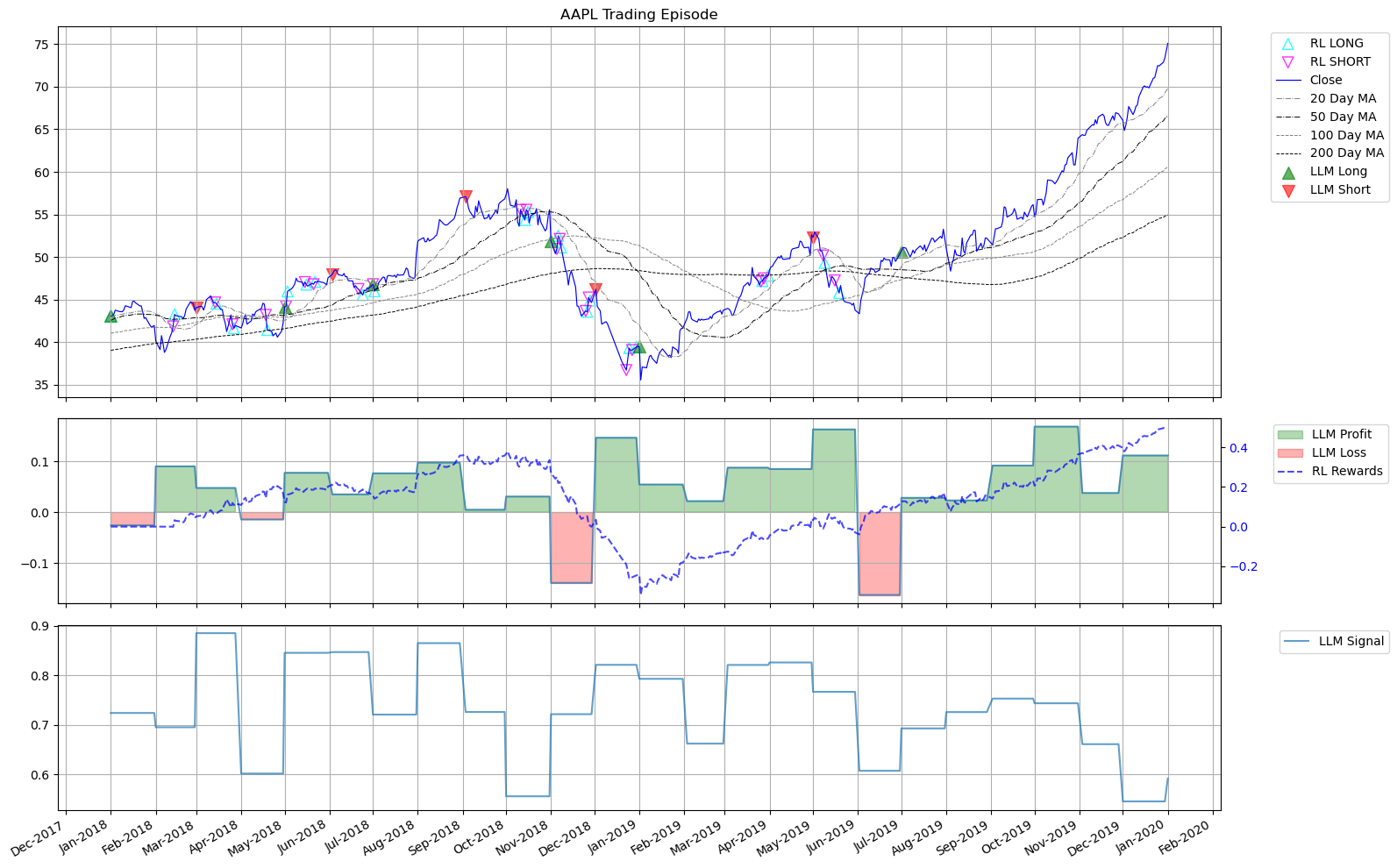
Figure 3: AAPL's performance with LLM+RL model.
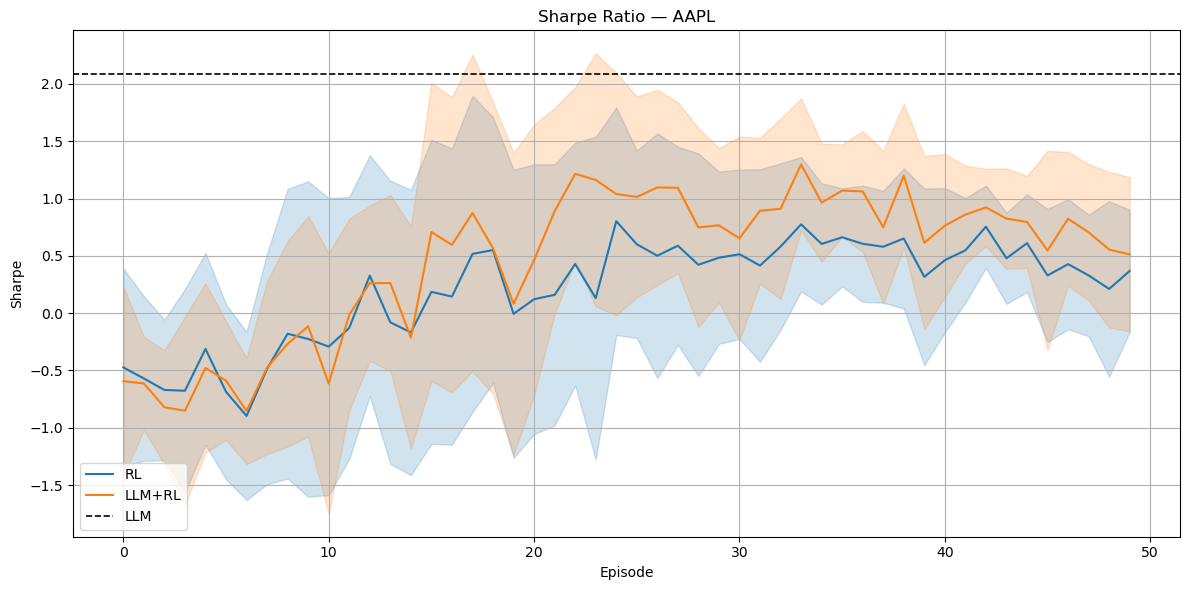
Figure 4: Training behavior for AAPL: Sharpe ratio.
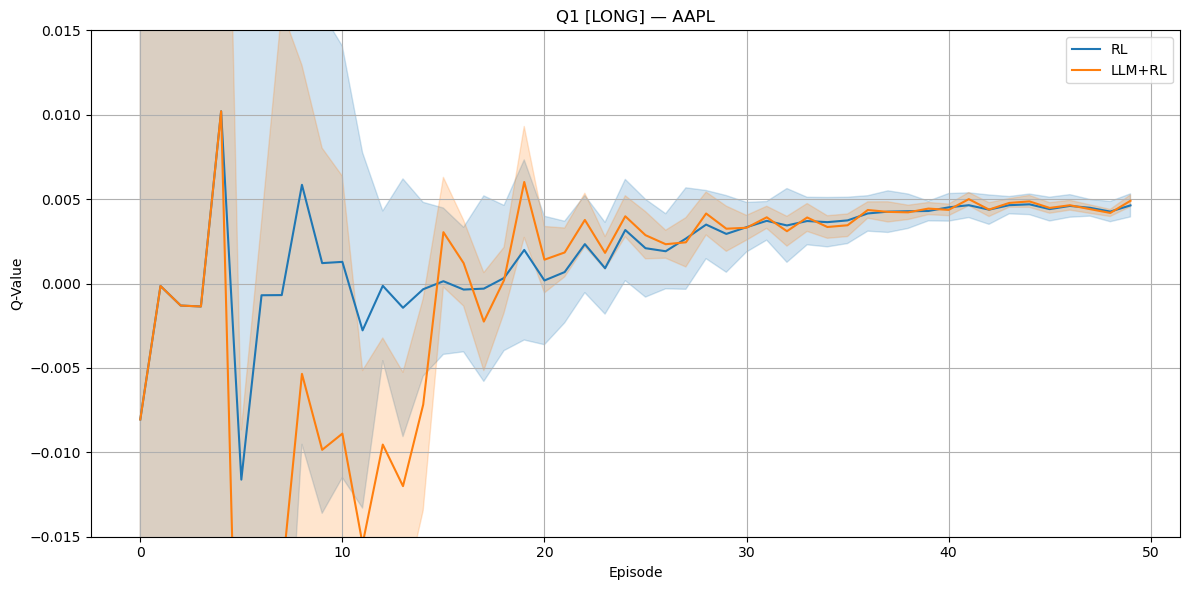
Figure 5: Training behavior for AAPL: Q-values for LONG.
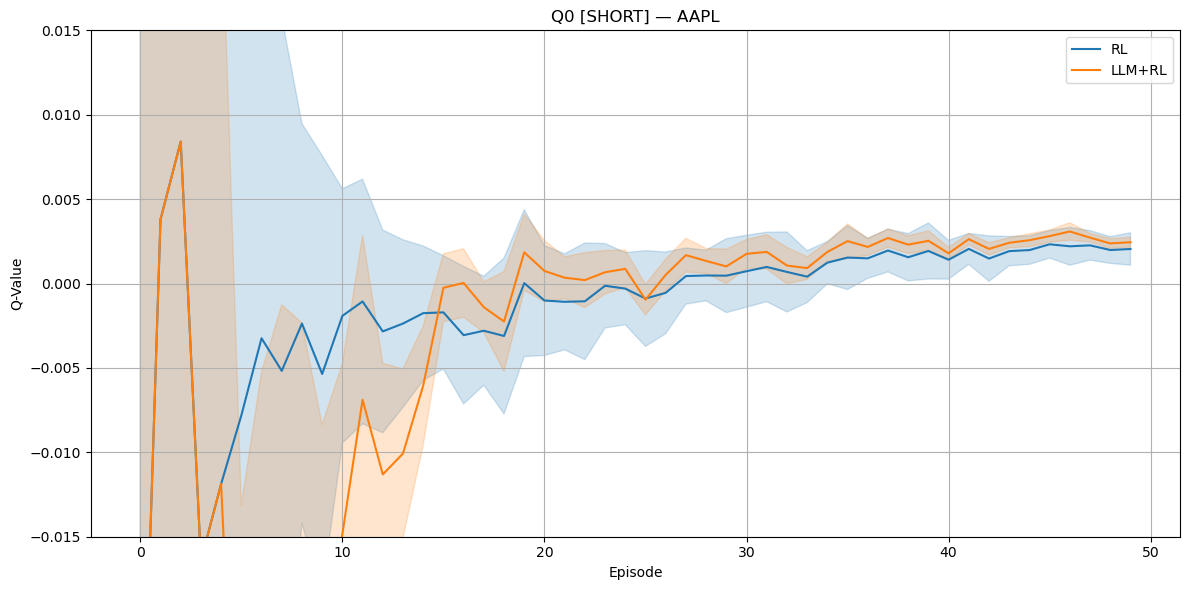
Figure 6: Training behavior for AAPL: Q-values for SHORT.
(Figures 4), (5), and (6) illustrate the evolution of the Sharpe ratio and Q-values for AAPL through training episodes, showing the hybrid LLM+RL agent's superior performance and stability.
Conclusion
The study demonstrates the effectiveness of an RL+LLM hybrid architecture for algorithmic trading, where LLMs generate guidance for RL agents. Structured prompts improve LLM performance, and the LLM-guided RL agent outperforms the RL-only baseline in terms of SR. Future research should focus on reward shaping and modular specialization through multiple LLM agents for specific domains to further reduce risk of confabulation. Overall, the work presents a novel LLM+RL system that improves both return and risk outcomes, supporting modular, agentic setups in financial decision-making.