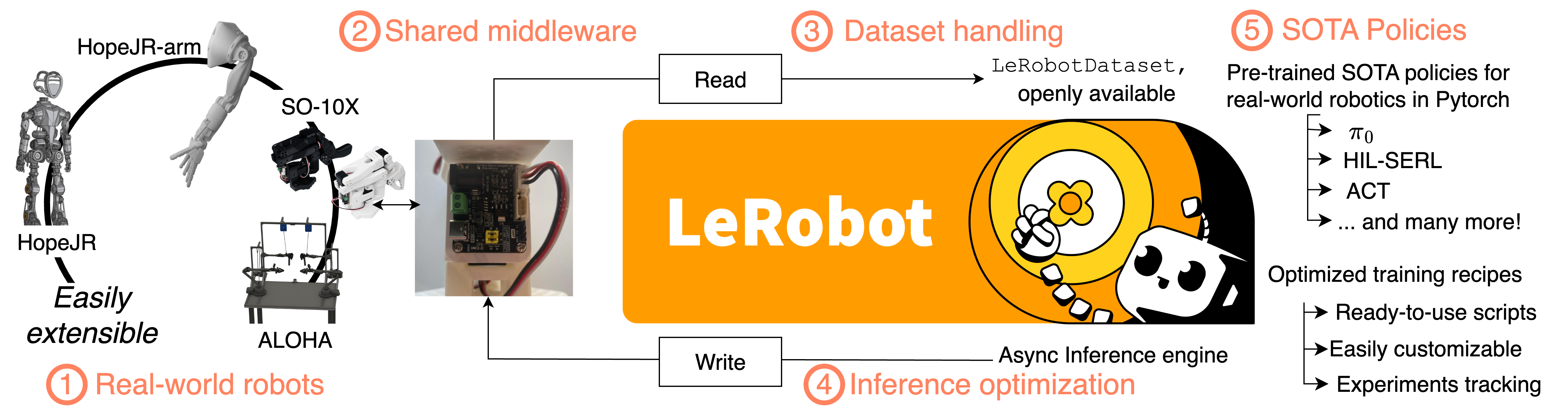
LeRobot: An Open-Source Library for End-to-End Robot Learning
Abstract: Robotics is undergoing a significant transformation powered by advances in high-level control techniques based on machine learning, giving rise to the field of robot learning. Recent progress in robot learning has been accelerated by the increasing availability of affordable teleoperation systems, large-scale openly available datasets, and scalable learning-based methods. However, development in the field of robot learning is often slowed by fragmented, closed-source tools designed to only address specific sub-components within the robotics stack. In this paper, we present \texttt{lerobot}, an open-source library that integrates across the entire robot learning stack, from low-level middleware communication for motor controls to large-scale dataset collection, storage and streaming. The library is designed with a strong focus on real-world robotics, supporting accessible hardware platforms while remaining extensible to new embodiments. It also supports efficient implementations for various state-of-the-art robot learning algorithms from multiple prominent paradigms, as well as a generalized asynchronous inference stack. Unlike traditional pipelines which heavily rely on hand-crafted techniques, \texttt{lerobot} emphasizes scalable learning approaches that improve directly with more data and compute. Designed for accessibility, scalability, and openness, \texttt{lerobot} lowers the barrier to entry for researchers and practitioners to robotics while providing a platform for reproducible, state-of-the-art robot learning.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LeRobot, a free, open-source library that helps robots learn to do tasks by themselves using machine learning. It puts everything you need in one place—from talking to motors, to collecting and sharing data, to training and running smart robot control programs—so researchers and hobbyists can build and test real-world robot skills more easily.
What are the main goals?
The paper focuses on solving a few big problems that slow down robot learning:
- Make different robots easier to control with the same code (like a universal remote).
- Create a standard way to record, store, and share robot data (so everyone can use and combine datasets without headaches).
- Provide ready-to-use, modern learning algorithms that can be trained or reused across tasks.
- Let heavy models run on a separate, powerful computer while the robot keeps moving smoothly.
- Lower the cost and effort needed to do real-world robot experiments.
In simple terms: How can we make robot learning easier, faster, and more reliable for everyone?
How did they build and test it?
Think of LeRobot as a “toolbox” with several matching tools that fit together:
- Middleware (robot control): This is the “universal remote” layer. It gives a consistent Python interface to different kinds of motors and robots, so you don’t need custom code for each device.
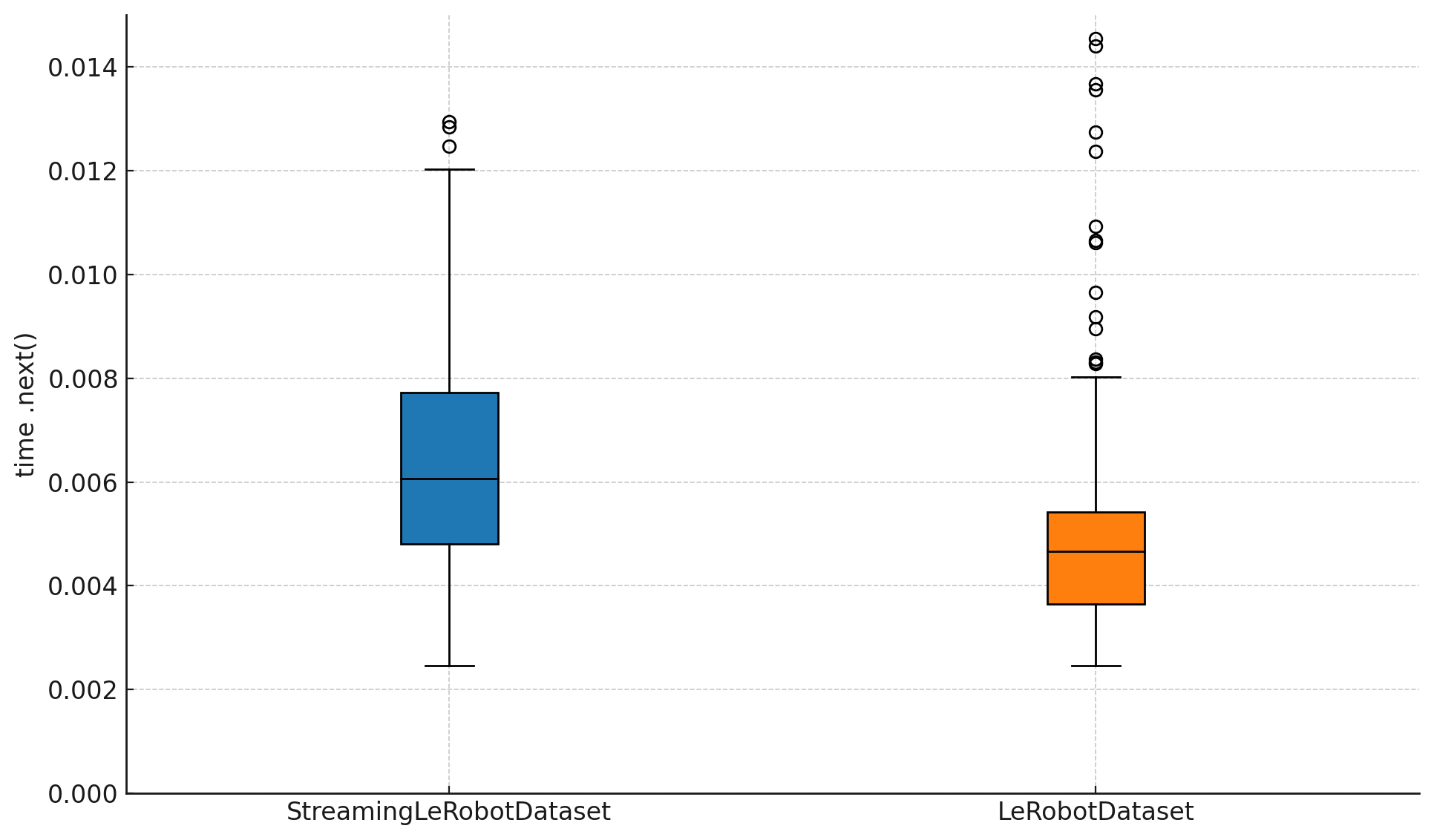
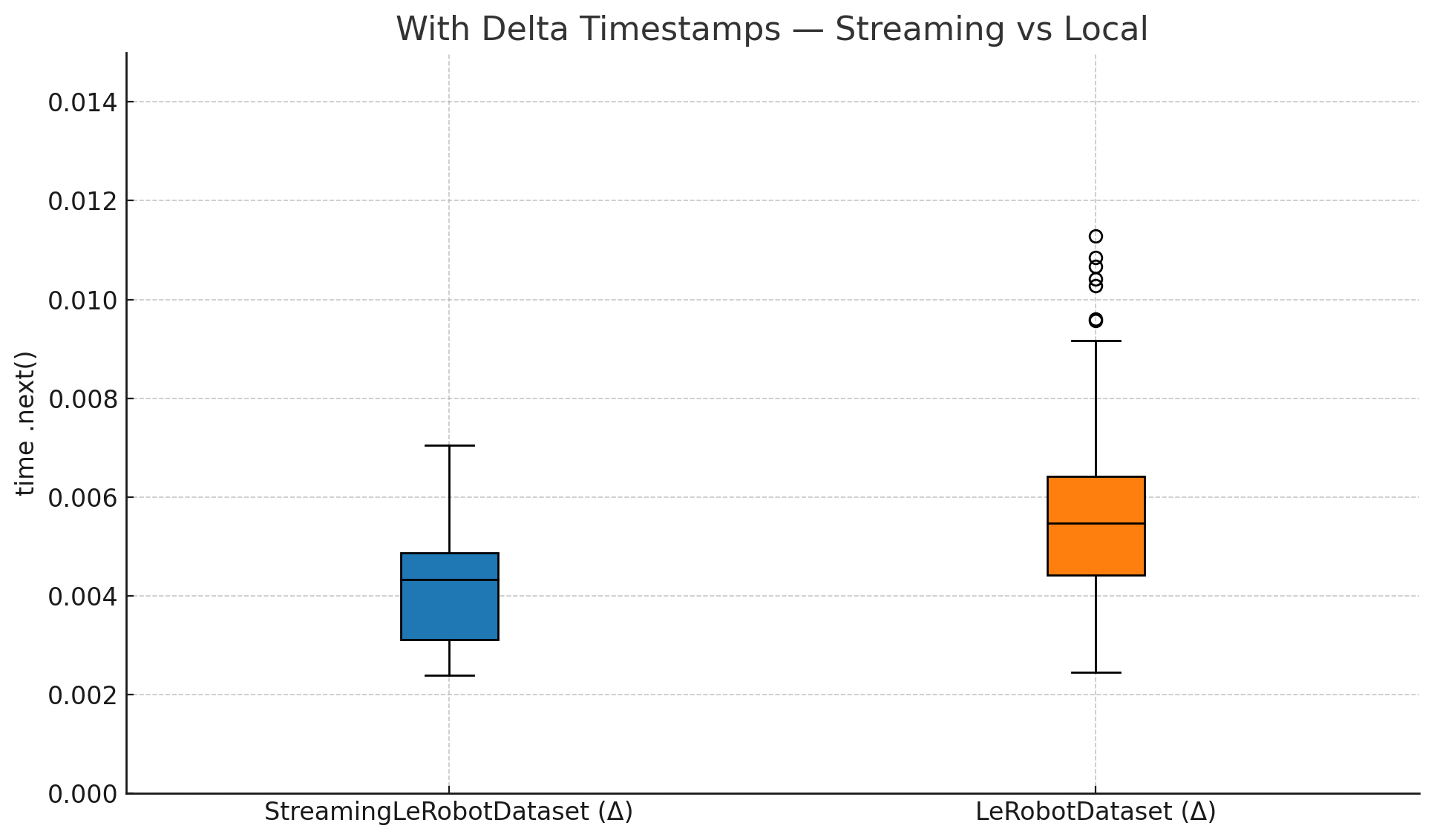
- Datasets (LeRobotDataset): This is a standardized “notebook” for robot memories. It stores multi-camera videos, sensor data, and notes about tasks in a common format. It also supports streaming—like watching a video online instead of downloading the whole file first—so you can train on huge datasets without filling your hard drive.
- Models (learning algorithms): These are the “brains” that turn camera images and sensor readings into actions. LeRobot includes popular methods:
- Imitation learning (Behavioral Cloning): learn from human demonstrations collected via teleoperation (a person controls the robot, the robot records and later copies).
- Reinforcement learning: learn by trying and improving with feedback (rewards), often using prior human data to be safer and faster.
- Small task-specific models (like ACT) and larger multi-task, language-conditioned models (like SmolVLA or π₀) are both supported.
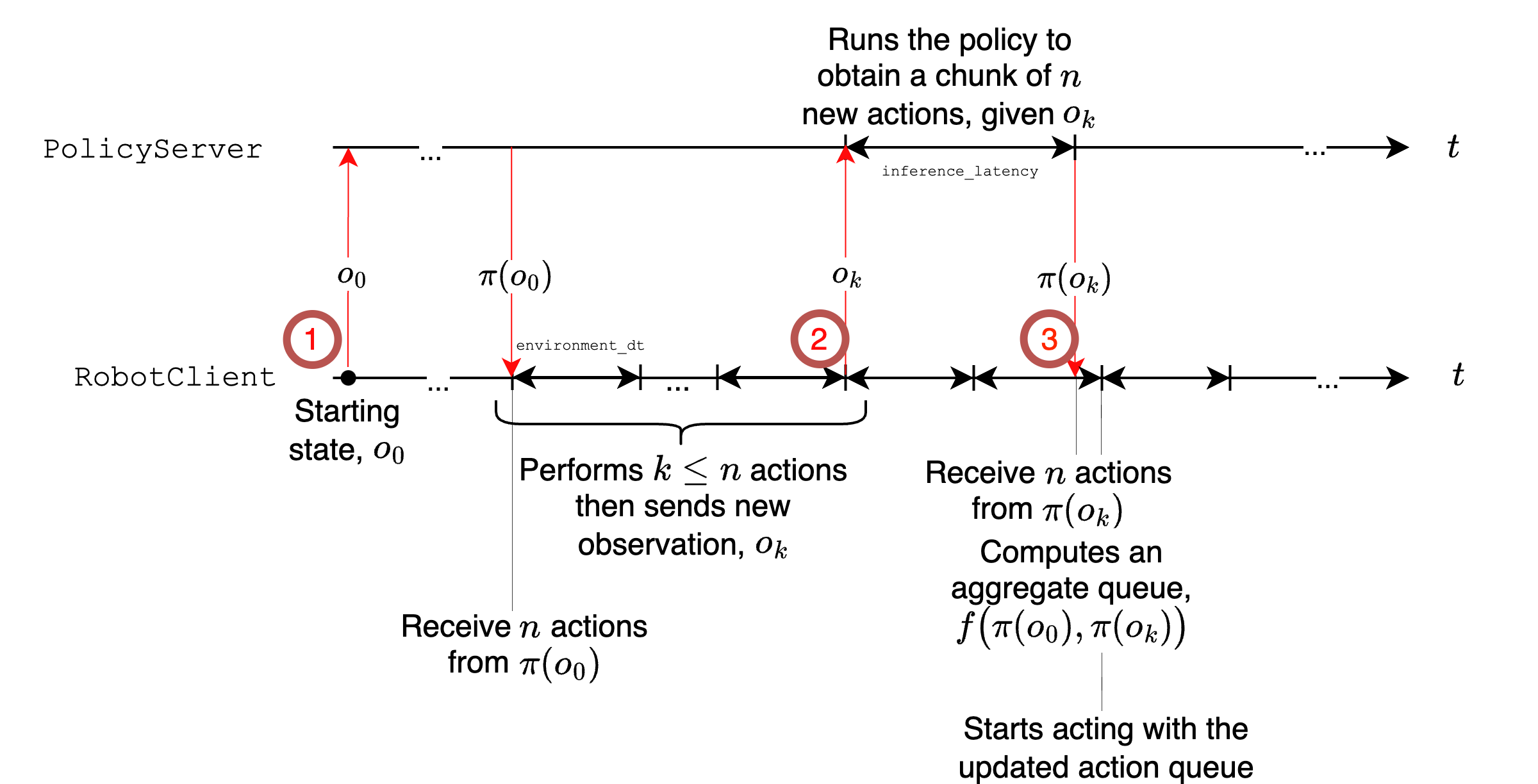
- Optimized inference (running models on robots): This separates “thinking” from “doing.” The robot can keep moving at a steady rhythm while a remote computer calculates the next chunk of actions. It uses an asynchronous system (like a coach sending the next plays while the player is still executing the current ones) so the action queue never runs dry.
They also included support for simulation benchmarks (LIBERO, Meta-World) to test methods systematically, even though the main focus is real-world robots.
What did they find, and why does it matter?
Here are the key outcomes described in the paper and why they’re important:
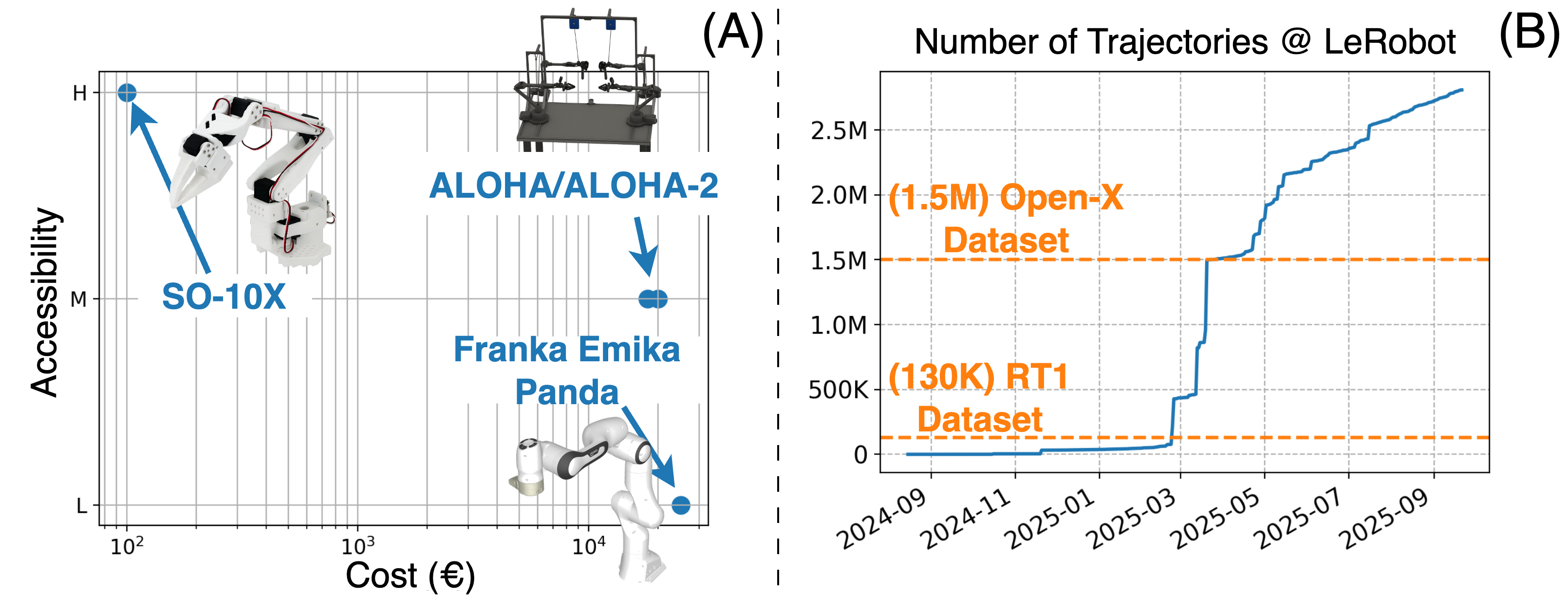
- Unified control across many real robots: LeRobot supports multiple low-cost, open-source arms, grippers, and mobile platforms. This makes it easier for people without expensive lab gear to do serious experiments.
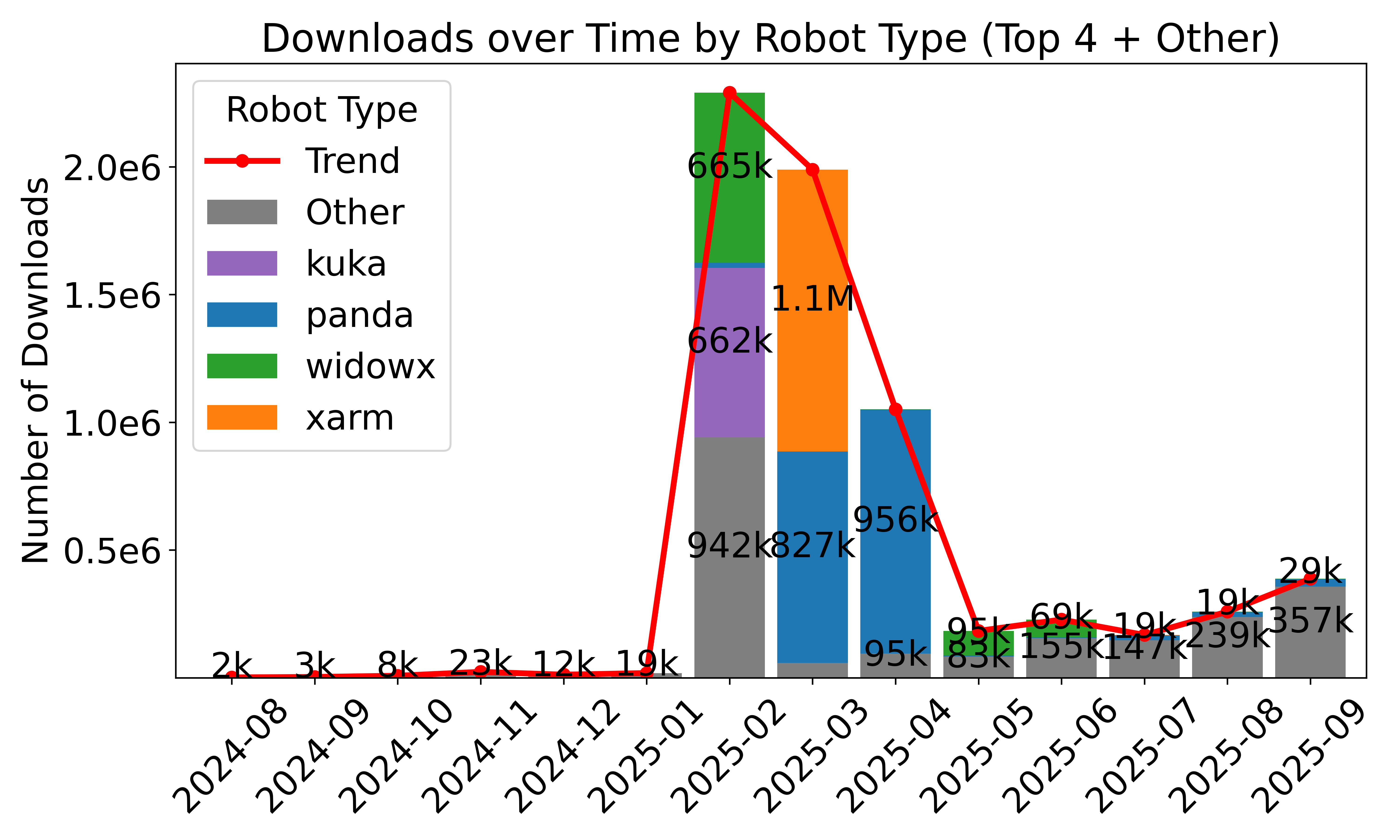
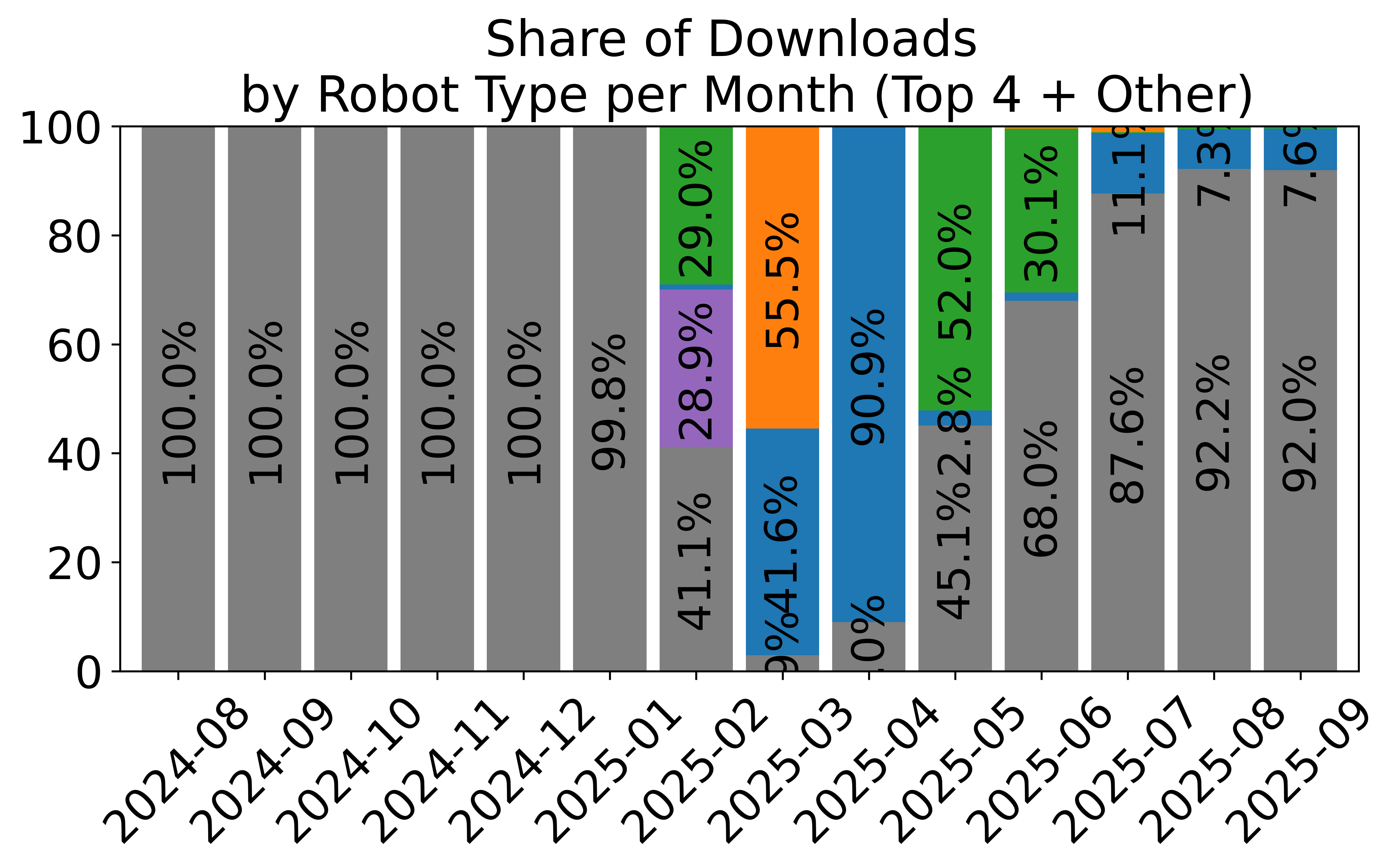
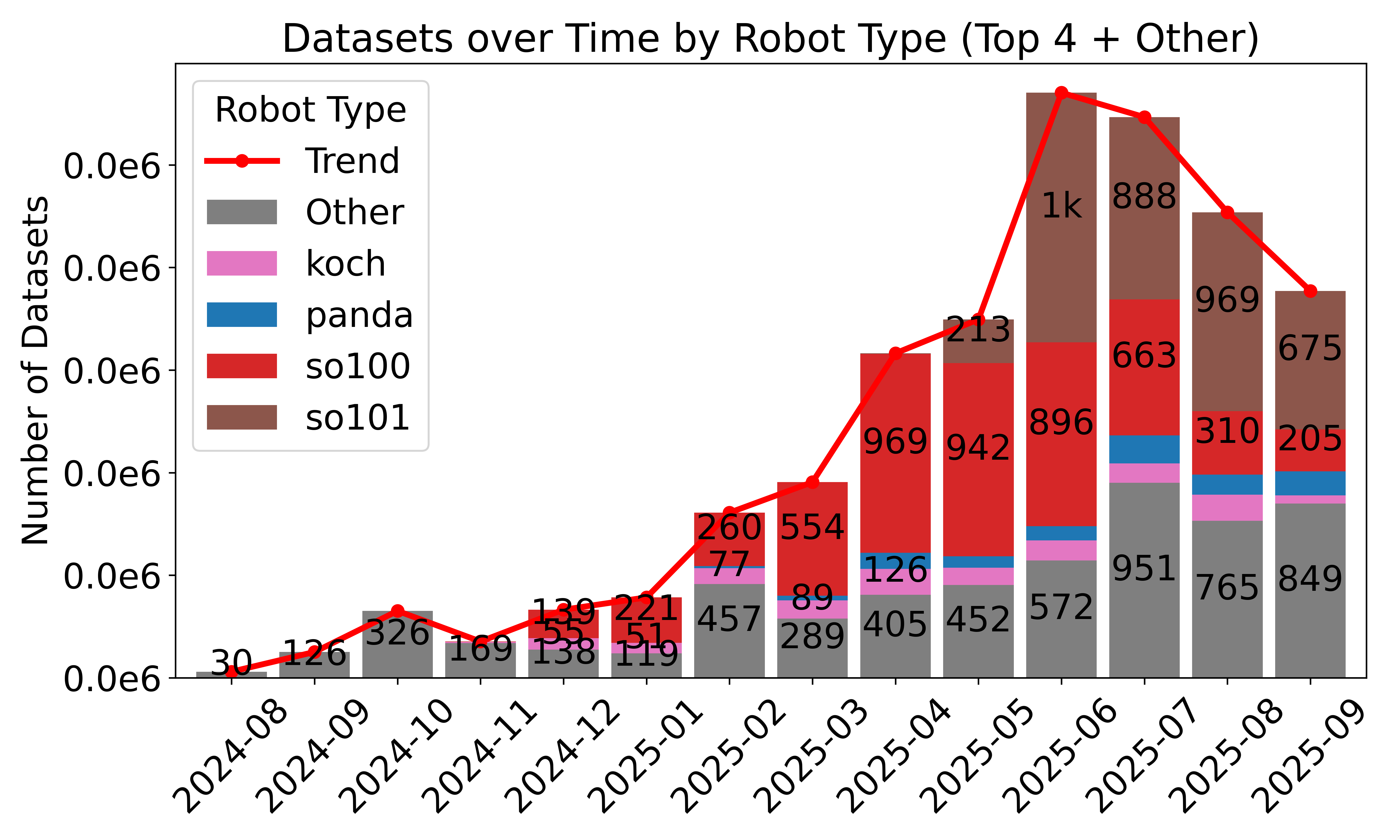
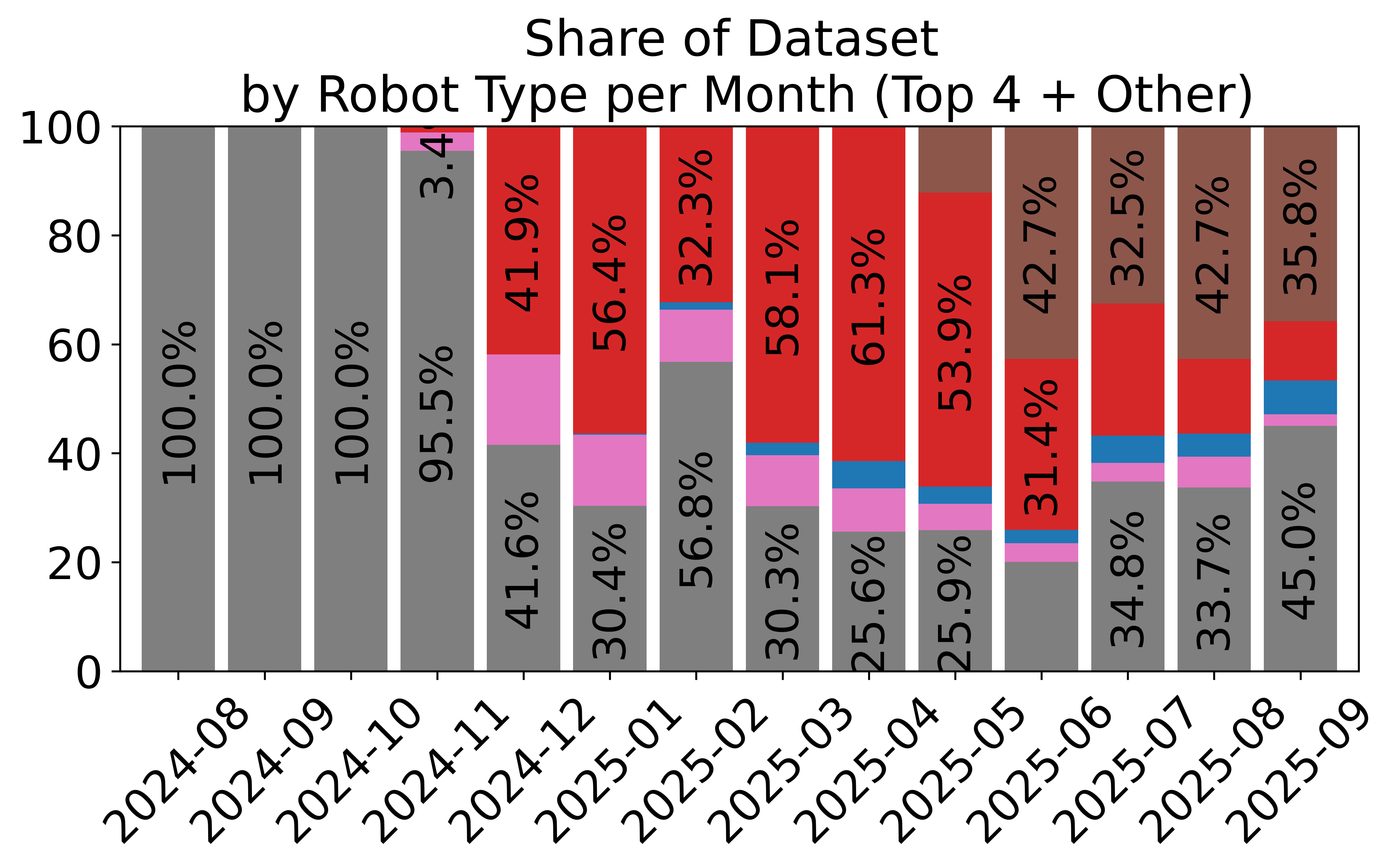
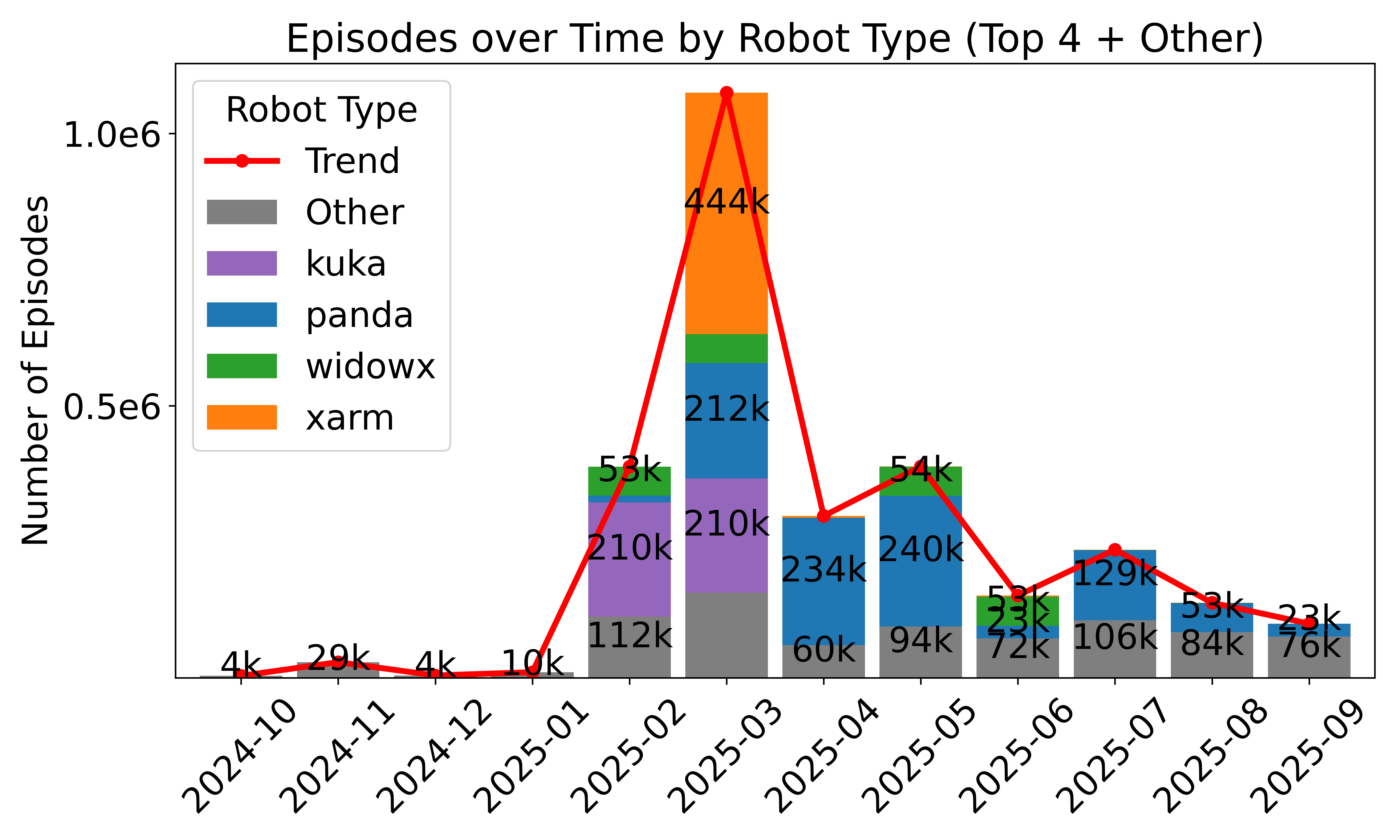
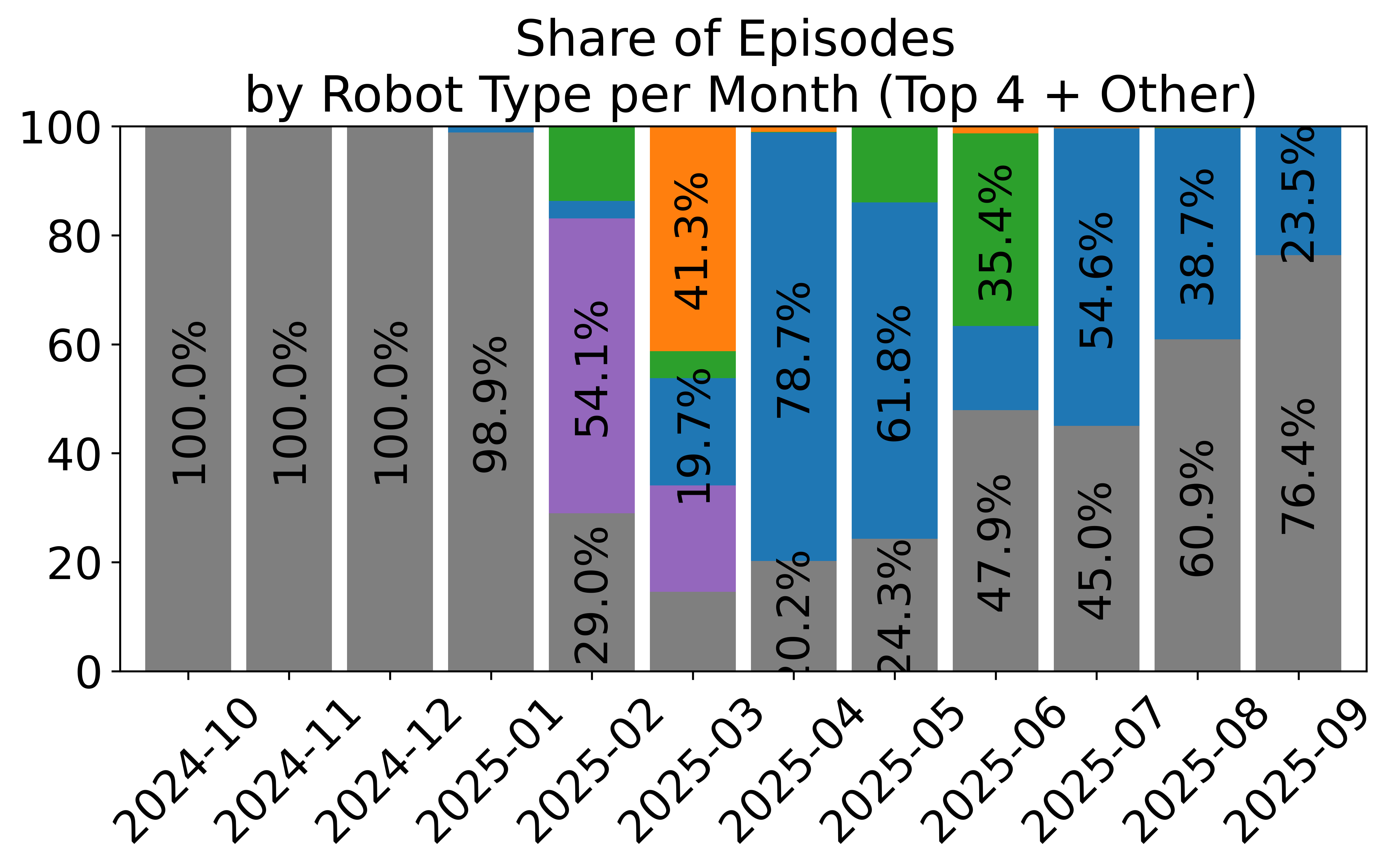
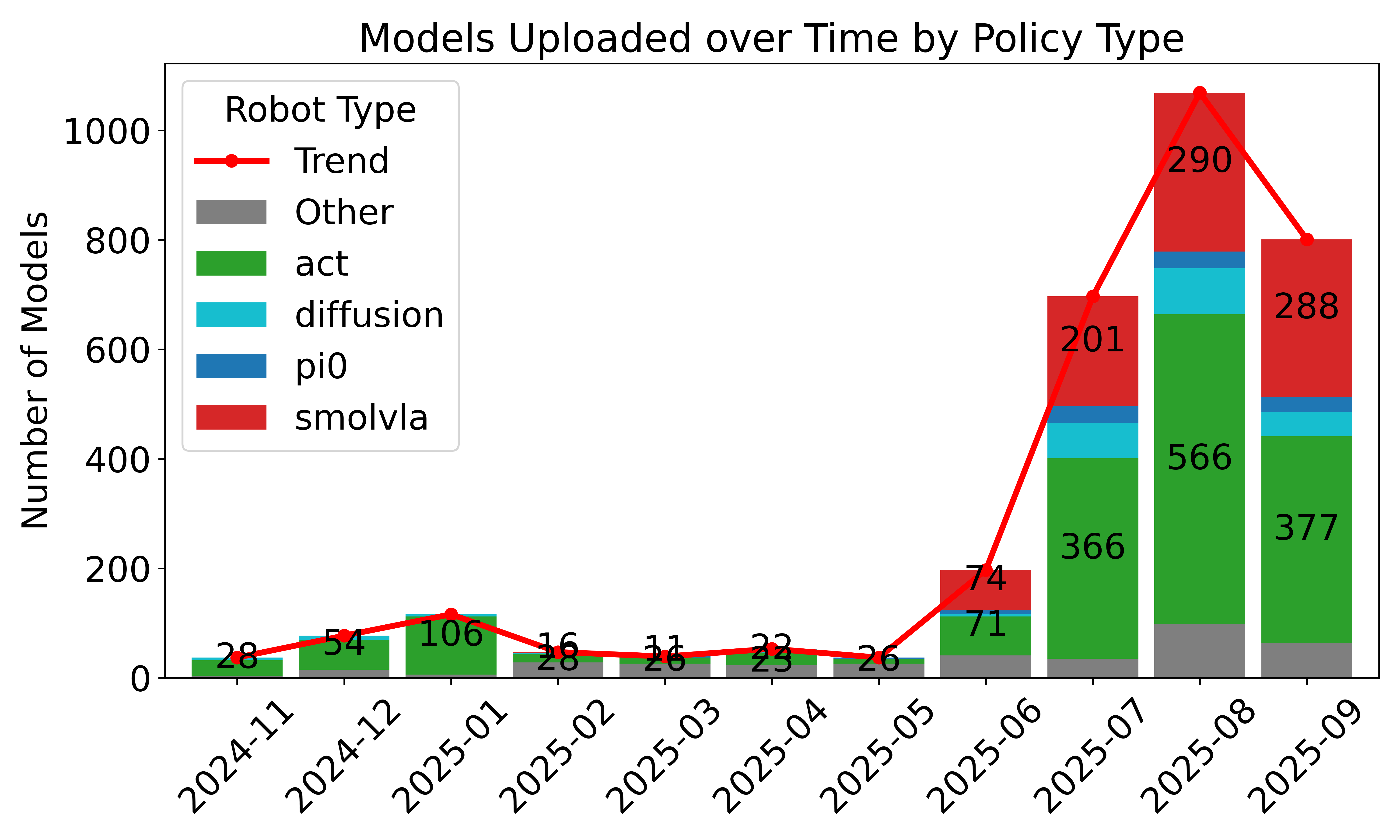
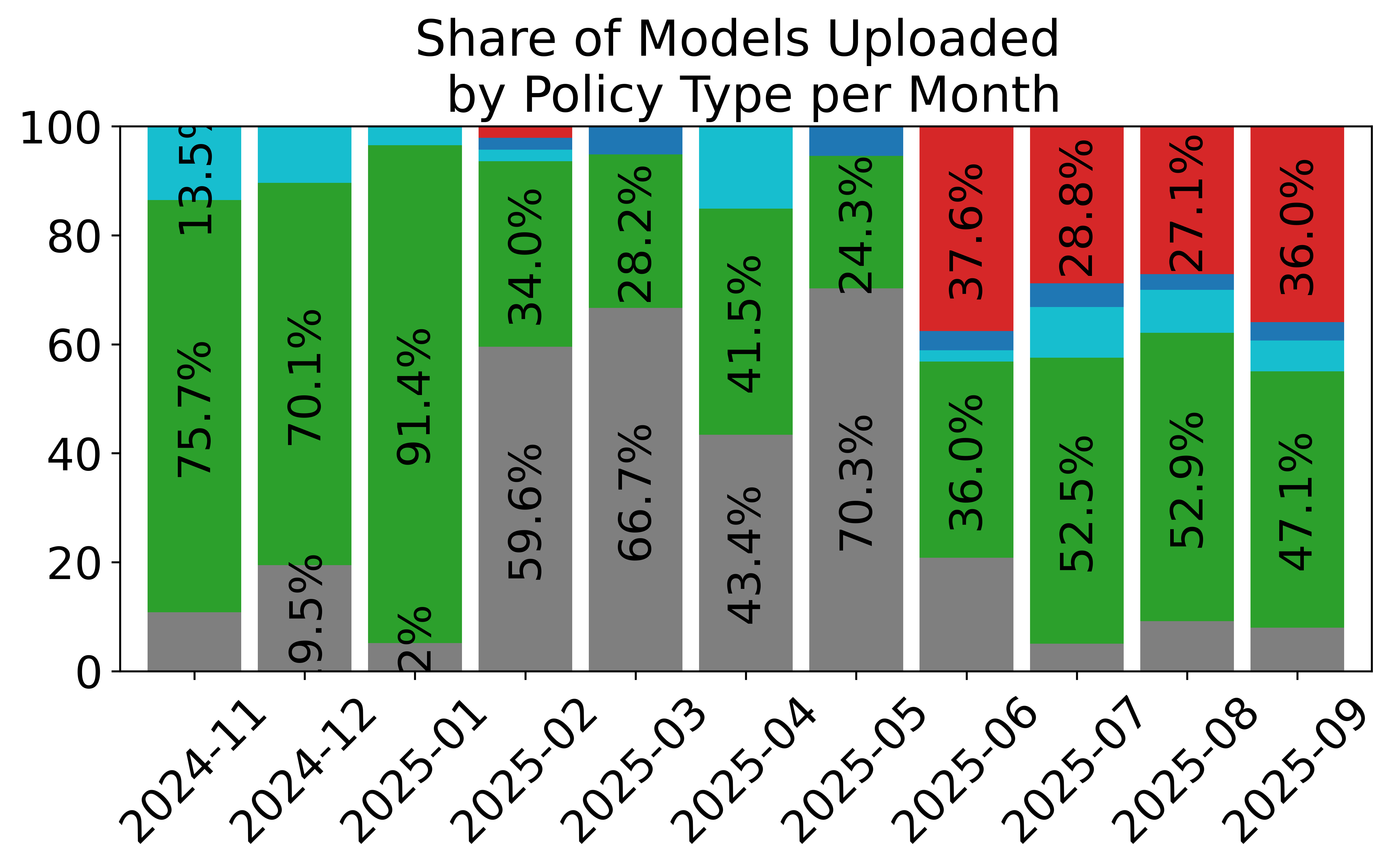
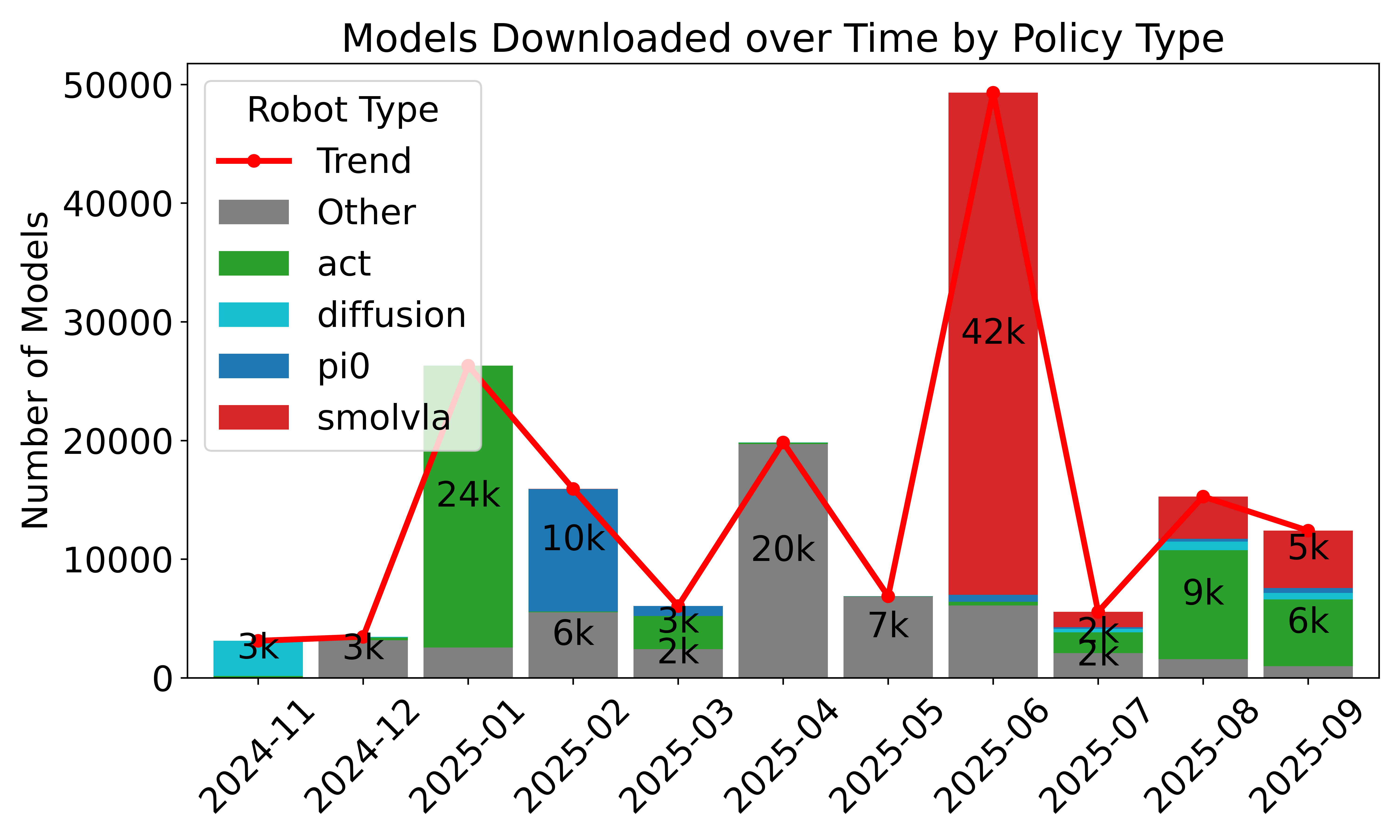
- Standardized, large-scale data sharing: Over 16,000 datasets from thousands of contributors use the LeRobotDataset format. This helps the community reuse data, compare results, and build bigger, better models.
- Efficient streaming: Training directly from remote datasets works smoothly and avoids huge downloads, making large-scale learning accessible on everyday machines with good internet.
- Ready-to-use models: Popular policies (like ACT, Diffusion Policy, SmolVLA, π₀) are integrated with clean PyTorch code. Smaller models run fast even on moderate hardware; larger “foundation” models need stronger GPUs but are supported for research.
- Faster, more reliable control: The “thinking vs. doing” split (asynchronous inference) reduces task time while keeping success rates competitive. This is crucial for real-world deployment where robots must act continuously and safely.
- Community impact: The format and tools are widely used beyond the robots directly supported, showing strong adoption and helping unify a previously fragmented ecosystem.
Why it matters: Robot learning used to be a jumble of incompatible tools, formats, and custom setups. LeRobot brings a clean, open, end-to-end stack, which speeds up research, lowers costs, and helps more people build useful robot skills in the real world.
What does this mean for the future?
- Easier entry into robotics: Students, makers, and new labs can train and deploy robot skills with low-cost hardware and shared datasets.
- Faster progress: Standardized data and reproducible code reduce “plumbing work,” so teams can focus on new ideas, bigger models, and real-world impact.
- Scalable learning: As more demonstrations and compute are added, data-driven policies typically get better—LeRobot is designed to scale with both.
- Practical deployment: The optimized inference setup is a step toward running advanced models on real robots, even if the robot itself doesn’t have a powerful computer.
- Open collaboration: The project invites the community to add more robots, algorithms, and optimizations (like quantization and graph compilation), filling current gaps and pushing the field forward.
In short, LeRobot helps make robot learning more like building with LEGO: shared pieces, clear connections, and the freedom to create complex systems without reinventing the basics each time.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable gaps for future work:
- Middleware coverage and interoperability: No formal adapters for widely used ecosystems (e.g., ROS/ROS 2, MoveIt, CANopen, EtherCAT). Specify and release standardized bridge interfaces and test suites to ensure drop‑in integration with industrial and academic stacks.
- Cross‑embodiment standardization: Absent a unified specification for coordinate frames, units, joint conventions, and orientation parameterizations across robots. Define a canonical schema and validators (including automatic conversions) to prevent silent mismatches.
- Sensor calibration and synchronization: Camera intrinsics/extrinsics, multi‑camera rig calibration, IMU alignment, and end‑to‑end time synchronization (including clock drift) are not captured or enforced. Provide tooling to record calibration artifacts, synchronized timestamps, and drift detection/correction procedures, with reproducibility guarantees.
- Dataset schema validation and required fields: “unknown” robot entries dominate the “Other” category, indicating weak schema enforcement. Introduce mandatory fields (robot_id, embodiment specs, task descriptors, environment metadata), schema versioning, and CI validators to prevent incomplete uploads.
- Data quality and labeling: Success/failure flags, trajectory quality metrics, teleoperator expertise, and environmental complexity are not standardized. Develop a minimal annotation protocol, automatic quality heuristics (e.g., action smoothness, contact events), and confidence scores to support filtering and evaluation.
- Bias, representativeness, and diversity analyses: No audit of object types, task distributions, environments, or operator demographics in decentralized datasets. Establish bias reports and diversity metrics, and publish periodic audits to guide balanced data collection.
- Language conditioning schema: Task descriptions are free‑form, with no ontology, controlled vocabulary, or prompt standardization. Define a shared task taxonomy and language schema (including synonyms, object categories, affordances) to enable reliable language‑conditioned policies.
- Deterministic streaming and reproducibility: StreamingLeRobotDataset lacks formal guarantees for deterministic iteration (ordering, shuffling, seeding), caching policies, and multi‑worker consistency. Specify and test deterministic streaming APIs and document reproducibility contracts.
- Network robustness for remote inference: No characterization of latency bounds, jitter tolerance, packet loss resilience, or bandwidth requirements. Benchmark end‑to‑end delays under realistic network conditions and implement fallback strategies (local safe controllers, degraded modes).
- Security and safety of remote execution: Authentication, encryption, authorization, sandboxing, and audit logging are not addressed. Define a secure communication protocol (e.g., mTLS), role‑based access, and incident logging for remote inference/control.
- Action chunk aggregation policy: The generalized function f for merging overlapping action chunks is unspecified and unanalyzed. Provide default strategies (last‑wins, time‑weighted blending, MPC stitching), safety constraints (rate limits, collision avoidance), and empirical comparisons.
- Real‑time scheduling and deadline compliance: Worst‑case latency, deadline misses, and control loop stability under asynchronous inference are not quantified. Measure deadline adherence across control frequencies and define OS/hardware scheduling recommendations.
- Model optimization and deployment: Quantization, graph compilation (TorchScript/ONNX/TensorRT), kernel fusion, and distillation are noted as future work but unimplemented. Deliver optimized pipelines with performance bounds on edge devices and low‑end GPUs.
- Comprehensive real‑world benchmarks: No standardized, cross‑robot, cross‑task evaluation suite with shared metrics, protocols, and ground truth. Curate a reproducible benchmark (tasks, objects, environments, metrics like SR, cycle time, safety events) and publish baseline results.
- Scaling laws and data–compute tradeoffs: The effects of dataset size, diversity, and compute on policy performance are unstudied. Run controlled scaling experiments (monotonicity, diminishing returns, cross‑embodiment transfer) and report empirical laws.
- Sim‑to‑real transfer: While LIBERO/Meta‑World are integrated, pipelines for domain randomization, representation alignment, and sim‑real gap quantification are absent. Provide sim‑to‑real recipes and report transfer performance and failure modes.
- Safety, HRI, and compliance: Deployment of learned policies lacks documented safety guardrails (e‑stop integration, geofencing, collision constraints), risk assessments, and standards compliance. Publish a safety checklist and reference implementations.
- Failure handling and recovery: Behavior under inference stalls, empty action queues, desynchronization, or model errors is unspecified. Implement safe fallback controllers, queue health monitoring, and recovery policies (e.g., hold‑position, retract).
- Dataset converters and interoperability: Bidirectional converters for ROS bags, TFDS, custom JSON/Protobuf formats are only mentioned informally. Release robust converters with validation and unit tests to unify legacy datasets.
- Embodiment retargeting: Methods to reuse policies across different kinematics (action space mappings, learned retargeters, inverse kinematics back‑ends) are not provided. Develop retargeting tools and evaluate cross‑robot generalization.
- RL pipelines and safety: While RL algorithms are referenced, on‑policy safety constraints, reward learning integrations, and human‑in‑the‑loop interfaces are incomplete. Offer plug‑and‑play reward models, intervention APIs, and safety‑aware training protocols with benchmarks.
- Compute, energy, and cost profiling: Training/inference energy use, throughput, and cost are not measured. Publish standardized profiles to guide hardware selection and sustainable deployment.
- Privacy, licensing, and compliance for shared data: Policies for PII in videos, consent, licensing (e.g., CC‑BY vs. non‑commercial), and takedown mechanisms are not defined. Provide governance documentation, automated PII checks, and compliant hosting practices.
- Community processes and maintainability: Contribution guidelines, long‑term API stability, CI/CD, and deprecation policies are not detailed. Establish governance, testing standards, and roadmap transparency to sustain the ecosystem.
Practical Applications
Immediate Applications
The items below outline concrete, deployable uses of the library’s unified middleware, dataset tooling, optimized inference, and reference robot learning models. Each item lists relevant sectors, likely tools/workflows, and key dependencies.
- Low-cost robotic manipulation cells for SMEs
- Sectors: robotics, manufacturing, logistics
- Tools/workflows: LeRobot Python middleware controlling SO-10X/Koch-v1.1; quick “collect–train–serve” loop with ACT or Diffusion Policy; asynchronous inference to keep real-time control while predicting action chunks; use ACT (≈5 ms per forward pass on RTX 4090; ~100–200 Hz) for pick-place, kitting, sorting
- Assumptions/dependencies: reliable calibration; safe workcell design; adequate GPU if using larger models; optional low-latency network if offloading inference; task variability within training distribution
- Rapid teleoperation-driven data collection in labs and startups
- Sectors: academia, robotics startups, education
- Tools/workflows: VR/leader–follower teleop with shared middleware; record demonstrations to LeRobotDataset; stream data with StreamingLeRobotDataset to avoid large local storage
- Assumptions/dependencies: access to teleop hardware; human operator time; data licensing/privacy for vision streams; time sync and metadata completeness
- Reproducible robot learning courses and assignments
- Sectors: education, academia
- Tools/workflows: standardized datasets and streaming for student projects; train baseline BC/RL policies (ACT, Diffusion Policy, TD-MPC, HIL-SERL) in <100 LOC recipes; evaluate in LIBERO/Meta-World via built-in API
- Assumptions/dependencies: classroom compute and internet connectivity; curated starter datasets; instructor familiarity with PyTorch
- Edge–cloud split inference for compute-constrained robots
- Sectors: robotics, software, cloud
- Tools/workflows: decoupled inference stack with remote policy server and on-robot controller; custom aggregation function f for overlapping action chunks; maintain fixed control rates despite heavy models
- Assumptions/dependencies: stable, low-latency network; secure communication; watchdogs/failsafes for network drops; deterministic control loop timing
- Model selection and hardware sizing for product teams
- Sectors: robotics, product engineering
- Tools/workflows: use reported memory/latency tables to choose policy class (e.g., ACT vs SmolVLA vs π0) and GPU; prototype on MPS/CPU vs RTX/A100 to validate timing budgets
- Assumptions/dependencies: similar observation/action sizes to benchmarks; adherence to fp32 (or adopt quantization/graph compile if needed)
- Open dataset curation and sharing
- Sectors: academia, research consortia
- Tools/workflows: convert existing ROS bag/TFDS/JSON datasets to LeRobotDataset; add task language descriptions and embodiment metadata; stream and mix datasets across labs
- Assumptions/dependencies: community adoption of schema; careful metadata standardization; clear licenses and data governance
- Language-conditioned prototyping for demos and UX tests
- Sectors: robotics, HRI/UX research
- Tools/workflows: SmolVLA for language-conditioned manipulation in constrained demos; rapid iteration on prompt/task phrasing; use asynchronous inference to mask longer forward passes
- Assumptions/dependencies: GPU availability; language grounding limited to trained tasks; safety measures for ambiguous commands
- Multi-robot lab orchestration via a single API
- Sectors: academia, corporate R&D
- Tools/workflows: control HopeJR-Arm, Reachy-2, Stretch-3, LeKiwi, SO-10X through the same middleware; reuse policies and datasets across embodiments when feasible
- Assumptions/dependencies: per-robot adapter completeness; consistent sensor/camera calibration; embodiment-specific tuning
- Early-stage assistive and service robot trials in controlled settings
- Sectors: healthcare research, facilities operations
- Tools/workflows: prototype fetch-and-carry, tidying, and tool handover with ACT/SmolVLA on safe platforms (e.g., Stretch-3, Reachy-2); collect user studies via teleop + BC
- Assumptions/dependencies: institutional safety/IRB approvals; strictly controlled environments; operator override; limited task diversity
- Hackathons and maker projects with open hardware
- Sectors: education, community innovation
- Tools/workflows: 3D-printable arms (SO-10X), BOMs, shared middleware; weekend projects: teleop demos, pick-place, simple sorting
- Assumptions/dependencies: availability of parts/tools; minimal mechanical assembly expertise; local compute or streaming datasets
Long-Term Applications
These applications are plausible extensions contingent on wider adoption, scaling, and further research in modeling, safety, and systems.
- Generalist, cross-embodiment robot foundation models
- Sectors: robotics, logistics, consumer devices
- Tools/workflows: Large multi-task VLA/flow/diffusion policies (e.g., successors to π0/SmolVLA) trained on mixed LeRobotDataset corpora; language-conditioned control across many robots
- Assumptions/dependencies: orders-of-magnitude more diverse data; robust cross-embodiment alignment; inference optimization (quantization, graph compilation) to meet real-time constraints and power budgets
- Global decentralized robotics data commons
- Sectors: academia, policy, software
- Tools/workflows: community teleoperation at scale; standardized metadata and streaming; federated or privacy-preserving training
- Assumptions/dependencies: data governance (privacy, IP), quality control, standardized annotation; sustained funding and infrastructure
- Marketplace for robot skills and datasets
- Sectors: software platforms, robotics
- Tools/workflows: “app store” of LeRobot-compatible policies packaged with embodiment specs; evaluation badges from standardized test suites; dataset bundles for fine-tuning
- Assumptions/dependencies: intellectual property/licensing clarity; certification and liability frameworks; robust versioning and rollback
- Standards and certification based on a common data/middleware schema
- Sectors: policy/regulation, industry consortia
- Tools/workflows: formalization of LeRobotDataset-like schema for public grants, procurement, and benchmarking; certification protocols for safety and reproducibility
- Assumptions/dependencies: multi-stakeholder consensus; regulators recognize open standards; conformance tooling and third-party auditors
- Managed edge–cloud orchestration for fleets
- Sectors: cloud, robotics-as-a-service, telecom
- Tools/workflows: hosted inference servers, policy hot-swapping, fleet-wide telemetry using standardized datasets; 5G/TSN backbones for low-latency control
- Assumptions/dependencies: reliable low-latency networks; cybersecurity hardening; graceful degradation and local fallback policies
- Robust assistive robots in homes and clinics
- Sectors: healthcare, eldercare, daily living
- Tools/workflows: language-guided service tasks (meal prep assistance, medication fetching) with VLA policies fine-tuned on in-the-wild data; teleop-to-autonomy bootstrapping
- Assumptions/dependencies: stringent safety, privacy, and reliability standards; domain generalization to cluttered homes; regulatory approvals and reimbursement models
- National-scale STEM programs with real robot data
- Sectors: education, public policy
- Tools/workflows: curriculum kits with low-cost arms; streaming access to large robot datasets; standardized lab rubrics and leaderboards
- Assumptions/dependencies: teacher training; equitable access to hardware/compute; sustainable hosting of public datasets
- Industrial certification and KPIs for manipulation
- Sectors: manufacturing, logistics
- Tools/workflows: LeRobot-based test harnesses that quantify cycle time, success rate, robustness to perturbations; acceptance tests for new cells
- Assumptions/dependencies: agreed-upon task suites; impartial test facilities; performance tied to operational SLAs
- Stronger sim-to-real bridges anchored by a shared data format
- Sectors: robotics research, simulation software
- Tools/workflows: LIBERO/Meta-World pretraining with structured task taxonomies, followed by real-data fine-tuning; standardized logging for gap analysis
- Assumptions/dependencies: improved contact-rich simulation fidelity; automated domain randomization; consistent sensor models
- Mobile manipulation for environmental monitoring and light field work
- Sectors: environmental services, agriculture
- Tools/workflows: LeKiwi-like platforms with off-board inference; dataset-driven policies for valve turning, sampling, instrument placement
- Assumptions/dependencies: weather-hardening; autonomy in GPS/communications-challenged areas; long-horizon task decomposition
- Open hardware adoption for local automation in developing regions
- Sectors: economic development, small-scale manufacturing
- Tools/workflows: BOMs and printable parts (SO-10X, HopeJR-Arm) plus standardized software stack; local data collection and skill sharing
- Assumptions/dependencies: supply chains for actuators/electronics; training programs; localized documentation and support
- Safety and networking requirements for off-board control codified in regulation
- Sectors: policy/regulation, telecom
- Tools/workflows: standards for network resilience, encryption, fail-safe behaviors, and situational awareness when inference is remote
- Assumptions/dependencies: cross-industry collaboration; incident reporting frameworks; certification labs
Notes on cross-cutting dependencies:
- Data quality and coverage: Policies improve with scale but depend on diverse, well-annotated, and legally shareable data.
- Compute and optimization: Larger models may require quantization/graph compilation and hardware acceleration not yet integrated.
- Networking: Off-board inference hinges on low-latency, secure connectivity and robust fallbacks.
- Safety and governance: Real-world deployment needs safety cases, auditing, and compliance with privacy and labor regulations.
- Embodiment variance: Cross-robot generalization remains an open research challenge; adapters and calibration are essential.
Glossary
- ACT: A single-task visuomotor imitation-learning policy that predicts short sequences of actions (action chunks) from observations. "ACT~\citep{zhaoLearningFineGrainedBimanual2023} is a particularly popular model"
- Action chunks: Short sequences of future control commands predicted at once by a policy, then executed step-by-step by the controller. "action chunks, "
- Aggregation function : A user-specified function to merge overlapping predicted action chunks in asynchronous inference. "aggregation function "
- Asynchronous inference stack: A deployment setup where action prediction and execution are decoupled and run in parallel to reduce latency and meet control-rate constraints. "a generalized asynchronous inference stack."
- Asynchronous producer-consumer scheme: An inference-control pattern where a producer (policy) generates action chunks while a consumer (controller) executes them at a fixed rate. "asynchronous producer-consumer scheme"
- Behavioral Cloning (BC): An imitation-learning approach that learns a policy by directly copying expert demonstrations without explicit reward signals. "Imitation Learning via Behavioral Cloning (BC)"
- Bill of Materials (BOM): A detailed list of parts and components required to build a robot platform. "Bill of Materials (BOM)"
- Denoising steps: Iterative refinement steps used during inference of diffusion/flow models to transform noise into coherent actions. "10 denoising steps at inference"
- Diffusion Models: Generative models that learn to produce samples by reversing a noise-adding diffusion process, used here to model action distributions. "Diffusion Models"
- Diffusion Policy: A diffusion-based imitation-learning policy for visuomotor control that predicts action sequences. "Diffusion Policy~\citep{chiDiffusionPolicyVisuomotor2024}"
- Entropy-regularized: A reinforcement-learning technique that adds an entropy term to the objective to encourage exploration and robust policies. "Off-policy, entropy-regularized methods"
- Explicit models: Hand-crafted analytical models of system dynamics used in classical pipelines for perception, planning, and control. "explicit models, implemented as modular pipelines"
- Flow Matching: A generative modeling approach that learns continuous-time flows to transform simple distributions into complex ones, used for action generation. "Flow Matching~\citep{lipmanFlowMatchingGenerative2023}"
- Foundation models: Large, general-purpose models trained on broad data at scale, intended to transfer across many tasks and embodiments. "robot foundation models"
- Full precision (fp32): Numerical representation using 32-bit floating point, often used as a baseline for model inference and evaluation. "full precision (fp32)"
- Graph compilation: Low-level model optimization that compiles compute graphs for faster inference on specific hardware backends. "graph compilation"
- HIL-SERL: A real-world RL framework that combines human-in-the-loop interventions with learned reward models to accelerate training. "HIL-SERL~\citep{luoPreciseDexterousRobotic2024}"
- Implicit models: Learned, data-driven models that map observations directly to actions without explicit analytic dynamics. "implicit models"
- IterableDataset: A PyTorch data interface for streaming/iterating over data without random indexing, useful for remote or large datasets. "IterableDataset interface"
- LIBERO: A simulation benchmark suite for evaluating agents on compositional and life-long learning tasks in manipulation. "LIBERO"
- Logical decoupling: Separation of inference and control at the software level so predictions are generated concurrently with execution. "logical decoupling implements inference"
- Look-ahead horizon (H): The number of future steps for which a policy predicts actions in each chunk. "look-ahead horizon "
- Meta-learning: A training paradigm where agents learn to adapt quickly to new tasks from few examples. "meta-learning (ML1, ML10, ML45)"
- Meta-World: A multi-task robotics benchmark suite for evaluating meta-learning and transfer in manipulation tasks. "Meta-World"
- Middleware: Software interfaces bridging high-level ML code and low-level robot hardware/control systems. "high-to-low level control interfaces (middleware)"
- MPS backend: Apple’s Metal Performance Shaders backend for accelerating PyTorch models on macOS devices. "the MPS backend"
- Multi-task learning: Training a single model to perform multiple tasks simultaneously, often improving generalization. "multi-task learning (MT10, MT50)"
- Off-policy: An RL setting where the learning policy differs from the behavior policy that generated the data, enabling replay and sample reuse. "Off-policy, entropy-regularized methods"
- Parquet (.parquet): A columnar, compressed tabular storage format used for scalable dataset records. ".parquet files"
- Physical decoupling: Running inference on a separate machine from the robot controller to leverage more compute without breaking real-time control. "Physical decoupling allows inference to run on a remote machine"
- π0 (pi_0): A multi-task vision-language-action policy for general-purpose robotic control. ""
- Quantization: Reducing numerical precision (e.g., to int8/fp16) to shrink model size and speed up inference with minimal accuracy loss. "quantization"
- Reinforcement Learning with Prior Data (RLPD): An RL approach that mixes offline and online data without pretraining to speed up convergence. "Reinforcement Learning with Prior Data (RLPD)"
- Reward classifiers: Learned models that infer reward signals from data, removing the need for hand-crafted reward functions. "learned reward classifiers"
- Return maximization: The RL objective of maximizing the expected sum of discounted rewards over time. "return maximization"
- ROS bags: ROS-specific log files for recording and replaying sensor and actuator data. "ROS bags"
- Simulation-induced discrepancies: Differences between simulated and real-world dynamics that can degrade real-world policy performance. "simulation-induced discrepancies"
- SmolVLA: A small-scale vision-language-action model enabling language-conditioned control for robots. "SmolVLA~\citep{shukorSmolVLAVisionLanguageActionModel2025}"
- Soft Actor Critic: An off-policy, entropy-regularized RL algorithm known for stability and sample efficiency in continuous control. "Soft Actor Critic~\citep{haarnojaSoftActorCriticOffPolicy2018}"
- State-of-the-art (SOTA): The best reported performance or most advanced methods at the time in a given research domain. "state-of-the-art (SOTA) robot learning algorithms"
- StreamingLeRobotDataset: A streaming dataset interface enabling on-demand, frame-wise access to large remote robotics datasets. "StreamingLeRobotDataset"
- Teleoperation: Remote control of a robot by a human operator, often used to collect expert demonstrations. "teleoperation data"
- TD-MPC: A model-based RL/control approach that uses temporal-difference learning and model predictive control for efficient policy learning. "TD-MPC~\citep{hansenTemporalDifferenceLearning2022}"
- torchcodec: A PyTorch-compatible library for on-the-fly video decoding to support efficient dataset streaming. "torchcodec"
- Unified memory: A memory architecture where CPU and GPU share a common pool, affecting performance and latency characteristics. "unified memory"
- Variational Auto-Encoders: Latent-variable generative models that learn a structured representation for conditional action generation. "Variational Auto-Encoders"
- Visuomotor policies: Policies that map visual observations directly to motor commands for robotic control. "visuomotor policies"
Collections
Sign up for free to add this paper to one or more collections.