$Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
Abstract: We introduce $Ψ_0$ (Psi-Zero), an open foundation model to address challenging humanoid loco-manipulation tasks. While existing approaches often attempt to address this fundamental problem by co-training on large and diverse human and humanoid data, we argue that this strategy is suboptimal due to the fundamental kinematic and motion disparities between humans and humanoid robots. Therefore, data efficiency and model performance remain unsatisfactory despite the considerable data volume. To address this challenge, \ours\;decouples the learning process to maximize the utility of heterogeneous data sources. Specifically, we propose a staged training paradigm with different learning objectives: First, we autoregressively pre-train a VLM backbone on large-scale egocentric human videos to acquire generalizable visual-action representations. Then, we post-train a flow-based action expert on high-quality humanoid robot data to learn precise robot joint control. Our research further identifies a critical yet often overlooked data recipe: in contrast to approaches that scale with noisy Internet clips or heterogeneous cross-embodiment robot datasets, we demonstrate that pre-training on high-quality egocentric human manipulation data followed by post-training on domain-specific real-world humanoid trajectories yields superior performance. Extensive real-world experiments demonstrate that \ours\ achieves the best performance using only about 800 hours of human video data and 30 hours of real-world robot data, outperforming baselines pre-trained on more than 10$\times$ as much data by over 40\% in overall success rate across multiple tasks. We will open-source the entire ecosystem to the community, including a data processing and training pipeline, a humanoid foundation model, and a real-time action inference engine.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “0 (Psi‑Zero): An Open Foundation Model for Universal Humanoid Loco‑Manipulation”
1) What is this paper about?
This paper introduces a new robot “brain” called 0 (pronounced “Psi‑Zero”) that helps human‑shaped robots walk around and use their hands to do everyday tasks at the same time. Think of a robot that can walk to a kitchen counter, pick up a cup, open a fridge, or wipe a table—smoothly and safely. The big idea is to teach the robot in two smart steps: first by learning from lots of first‑person human videos, and then by learning the exact movements needed for a robot’s body.
2) What were the main questions?
The researchers focused on a few key questions, explained simply:
- How can we best use cheap, easy‑to‑find data (like human first‑person videos) to help robots learn?
- Can we avoid mixing very different kinds of data (human movement vs. robot movement) in one big, messy training process?
- Is there a way to make robots move smoothly in the real world, even if the “thinking” part of the model takes a bit of time to decide on actions?
3) How did they do it?
They trained the robot’s “brain” in stages and split the work among different parts, like a small team with different jobs.
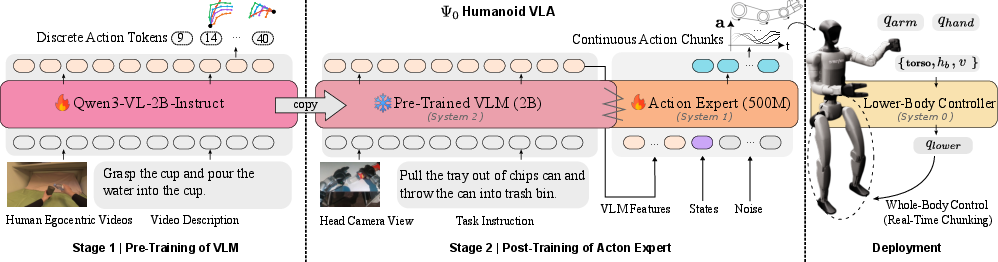
- Three‑part “team” inside the robot:
- System‑2: a vision‑and‑LLM (VLM). This is like a planner that looks at the camera view, reads the instruction (“put the bottle in the sink”), and understands what needs to be done.
- System‑1: an action expert. This is like a skilled driver that turns the plan into exact arm, hand, and body movements.
- System‑0: a leg controller. This is like auto‑pilot for the robot’s legs and balance, keeping it stable while moving.
- Three training stages:
- Stage 1: Learn from people. They pre‑trained the “planner” (the VLM) on about 800 hours of first‑person videos of people using their hands. This helps the model understand what actions look like, from the robot’s eye view.
- Stage 2: Learn exact robot control. They trained the action expert on real humanoid robot data (about 30 hours) so it learns how a robot’s joints should move. Human bodies and robot bodies are different, so this step teaches robot‑specific skills.
- Stage 3: Quick fine‑tuning for new tasks. With a small amount of extra data for a specific task, the robot adapts quickly.
Helpful analogies:
- Action “tokens” are like breaking movements into small Lego pieces so the model can learn the pattern of actions efficiently.
- Action “chunks” are like planning the next few seconds of movement at once, so the robot doesn’t hesitate or jerk around.
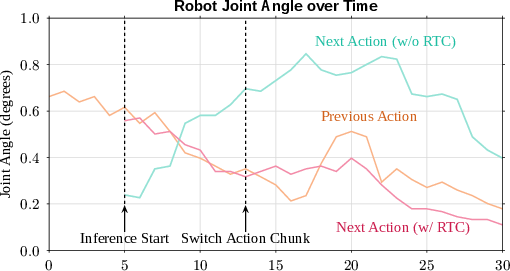
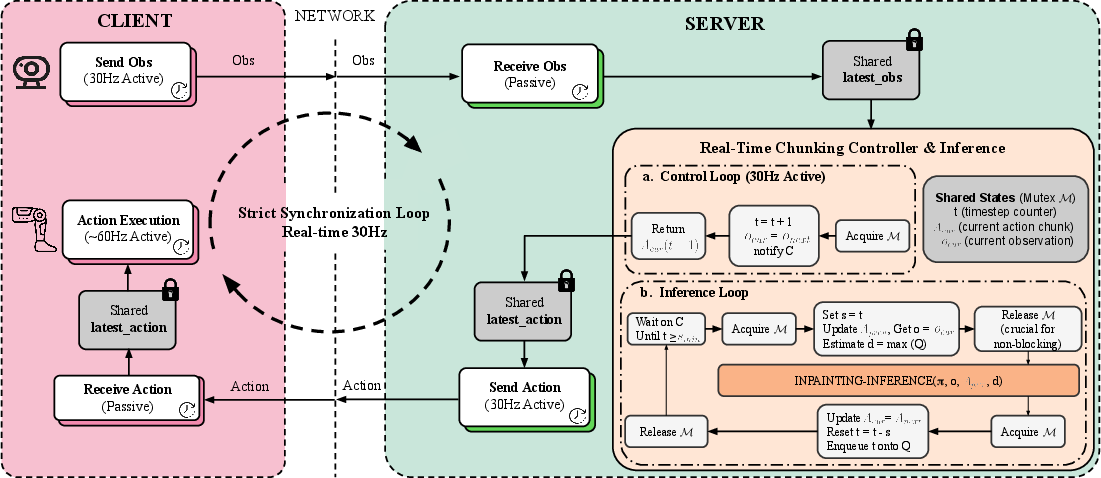
- “Real‑time chunking” is a trick to keep the robot moving smoothly even while the brain is still thinking. It’s like humming a tune while you decide the next verse—no awkward pauses.
Extra tools they built:
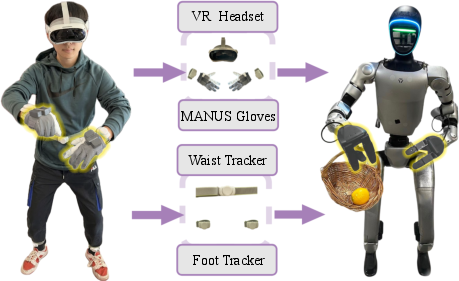
- A teleoperation setup (VR headset, hand gloves, trackers) so a human can safely show the robot what to do, especially for finger and hand skills.
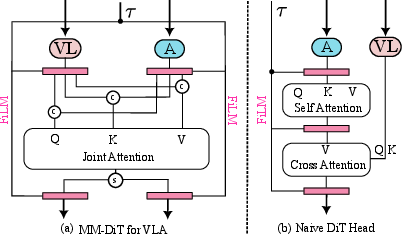
- A special action model (“MM‑DiT”) that better blends what the robot sees and hears (images and instructions) with what it should do next.
4) What did they find, and why is it important?
Main results:
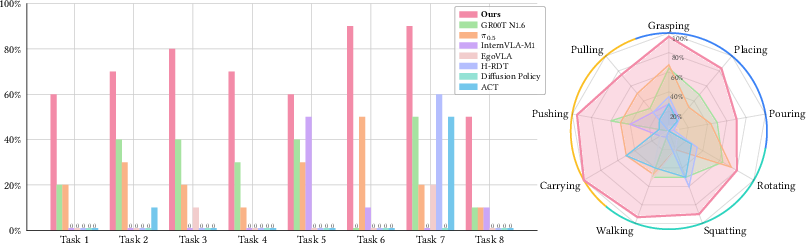
- With only about 800 hours of human videos and 30 hours of robot data, 0 beat other strong methods that used more than 10 times as much data. It did better by over 40% on average across many tasks.
- It handled real, long, multi‑step chores: getting a cup from a coffee machine, pushing a cart, wiping a table, putting a bottle in a sink, and opening a fridge door, among others.
- Training in two steps (human videos first, robot data second) worked better than mixing everything together from the start.
- Their action model (MM‑DiT) predicted smoother, more precise movements than a simpler version.
- Real‑time chunking made the robot’s motions more stable and less shaky.
Why this matters:
- It shows that “better” data (high‑quality, well‑matched videos and robot examples) can beat “more” data.
- It reduces the need for huge, expensive robot demonstrations by humans.
- It brings us closer to helpful home or workplace robots that can handle complex tasks safely.
5) What’s the bigger impact?
If robots can learn this way—first by watching people, then fine‑tuning for their own bodies—we can train capable robots much faster and cheaper. That could make it easier to build robots that help with everyday chores, assist in hospitals or labs, and handle tasks that are dull, dirty, or dangerous for people. The team plans to open‑source the model and tools, which means other researchers and builders can improve, test, and expand the system. Over time, this could speed up progress toward useful humanoid robots in real life.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper and could guide future work:
- Lack of controlled scaling laws: no systematic study relating model capacity, pre-training hours, and robot data volume to performance or data efficiency.
- Data-quality attribution unclear: claims about “high-quality egocentric videos” outperforming large heterogeneous datasets are not validated via controlled ablations across data sources, curation strategies, or noise levels.
- Limited pre-training objective: the VLM is trained on single-step next-action prediction only; effects of temporally richer objectives (e.g., chunked prediction, masked sequence modeling, trajectory contrastive learning) are untested.
- Action tokenization design space unexplored: reliance on FAST tokenization is not compared to alternative discretizers, continuous representation learning, or vector quantization; impact of 0.005 L1 reconstruction error on downstream control is unknown.
- Representation mismatch unexamined: pre-training in 48-DoF task space and post-training in 36-DoF joint space may induce a modeling gap; strategies to align or jointly learn the two spaces are not investigated.
- Frozen VLM backbone during post-training: potential benefits and risks of end-to-end co-tuning (partial or full) for better cross-embodiment alignment are not evaluated.
- Lower-body learning absent: locomotion is delegated to a separate RL controller (AMO), limiting joint learning of whole-body coordination; no exploration of learning lower-body control from data or adapting to varied terrains/obstacles.
- Long-horizon memory limits: beyond action chunking, no explicit memory or recurrent mechanism is used; scalability to episodes far exceeding 2,000 steps and tasks requiring persistent state (e.g., deferred goals) is untested.
- Real-time chunking generality unassessed: training-time RTC is used, but robustness to different latency profiles, hardware, network jitter, and varying action horizons is not quantified; comparisons to test-time RTC are not systematic.
- Sensor modality underutilization: although RGB-D hardware is available, the model appears to use RGB and limited proprioception; benefits of depth, IMU, force/torque, and tactile sensing—and robustness under poor lighting/occlusion—are not assessed.
- State omission in pre-training: the decision to omit state inputs during VLM pre-training may limit embodiment grounding; no ablation on including proprioceptive or kinematic state in pre-training.
- Robustness to visual distribution shift: performance under illumination changes, motion blur, partial occlusions, reflective/transparent objects, or clutter is not evaluated.
- Generalization breadth limited: evaluation covers eight tasks in a few settings; zero-shot transfer to unseen objects, layouts, tools, and long-tail household tasks is not reported.
- Language grounding underexplored: no tests of compositionality, paraphrasing, negation, multi-step instructions, ambiguous goals, or multilingual commands; instruction-following limits are unknown.
- Fairness of baseline comparisons: baselines differ in RTC availability, architecture changes, and hyperparameters; the share of gains due to RTC, teleoperation pipeline, or data preprocessing is not disentangled.
- Minimal compute path unclear: training requires 64×A100 for 10 days; feasibility on modest compute, or performance trade-offs with smaller backbones, is not demonstrated.
- Task diversity and environment variety: tasks focus on pantry-like scenes; breadth across household rooms, outdoor settings, and different affordances (e.g., deformables, articulated mechanisms with high friction) is not explored.
- Hardware generalization: results are only on Unitree G1 with Dex3-1 hands; portability to other humanoids, different hand kinematics/gear ratios, and sensors is untested.
- Payload and dynamic tasks: high-force/fast dynamics (e.g., opening stuck doors, lifting heavy objects, stair climbing, running) are limited by hardware; model capability under higher payload/velocity regimes remains unknown.
- Human-in-the-loop robustness: behavior in the presence of humans (safety, proximity, compliance) and interactive tasks is not addressed; no social-safety evaluation or collision-avoidance policy is reported.
- Safety and constraint handling: the policy lacks explicit physical constraints or safety monitors (e.g., joint torque/velocity limits, self-collision avoidance, force thresholds); recovery strategies for near-failure states are absent.
- Failure-mode taxonomy missing: no detailed analysis of where and why rollouts fail (perception errors vs. planning vs. control), hindering targeted improvements.
- Effects of EgoDex preprocessing: upsampling by 3× and quantile normalization are introduced, but their influence on dynamics fidelity and downstream control is not ablated.
- Coordinate/frame alignment: transforming actions to the head-camera frame during pre-training may create mismatches with robot frames; the consistency and calibration pipeline are not validated quantitatively.
- Operator bias in teleop data: single-operator or homogeneous operator style can bias demonstrations; impact of multiple operators, varied styles, and cross-operator generalization is unstudied.
- Dataset composition transparency: details on how in-domain fine-tuning tasks were split (train/val/test), object identities, and scene diversity are insufficient for assessing overfitting or leakage.
- Continual and online adaptation: the model does not adapt during deployment (no online learning, no self-correction from rollouts); viability of on-robot fine-tuning or RL for refinement is not explored.
- Cross-embodiment transfer limits: while designed for humanoids, extension to non-humanoid morphologies (mobile manipulators, soft hands) and the role of the decoupled recipe there remain open.
- Synthetic data utility: the paper argues for high-quality real videos but does not test if curated simulation or high-fidelity synthetic egocentric data could substitute or complement human videos.
- Instruction grounding with additional context: integrating scene graphs, 3D maps, or language-grounded affordances for planning is not explored; current approach may lack spatial memory/scene understanding at scale.
- Evaluation protocol intervention: allowing evaluator interventions during rollouts complicates success metrics; impact of intervention frequency and type on reported success is not quantified.
- Reliability and longevity: no measurements of hour-scale autonomy, thermal throttling, battery life, and performance degradation over extended runs.
- Privacy/ethics of egocentric video: sourcing, consent, and potential bias in large-scale human videos are not discussed; downstream ethical implications (e.g., replicating unsafe behaviors) are unaddressed.
- Open-source completeness vs. dependency: although code and weights are promised, reliance on large proprietary datasets/hardware and compute-scale may hinder reproducibility; a reproducible “small-scale” recipe is missing.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage the model, pipeline, and methods introduced in the paper, with sector links and key dependencies.
- Humanoid task automation in offices and labs (Robotics, Facilities)
- What: Deploy 0 for pantry/office assistance (e.g., fetching a cup from a coffee machine, pushing a cart, wiping tables, opening/closing doors, placing objects in sinks).
- Tools/workflows: Use the released pre-trained weights, real-time action inference engine, and the provided deployment client; fine-tune the action expert with a few in-domain teleop trajectories.
- Assumptions/dependencies: Humanoid with dexterous hands (e.g., Unitree G1 + Dex3-1), head camera, onboard GPU with ~160 ms per forward pass, RL lower-body controller (e.g., AMO), RTC enabled to avoid jitter; structured indoor environment with basic safety controls.
- Rapid prototyping of humanoid skills with minimal robot data (Robotics R&D, Academia)
- What: Apply the staged training paradigm to quickly adapt to new household/industrial tasks using ~tens of hours of robot data.
- Tools/workflows: Decoupled training pipeline—freeze the VLM backbone pre-trained on human egocentric videos; post-train and fine-tune the MM-DiT action expert in joint space.
- Assumptions/dependencies: Access to the data processing pipeline, GPU compute, and a small number of high-quality teleop demos tailored to the target task.
- Single-operator teleoperation for whole-body loco-manipulation data collection (Robotics tooling, EdTech)
- What: Collect balanced upper-body dexterity and lower-body locomotion data using the paper’s teleoperation setup (VR headset, wrist + waist/foot trackers, MANUS gloves).
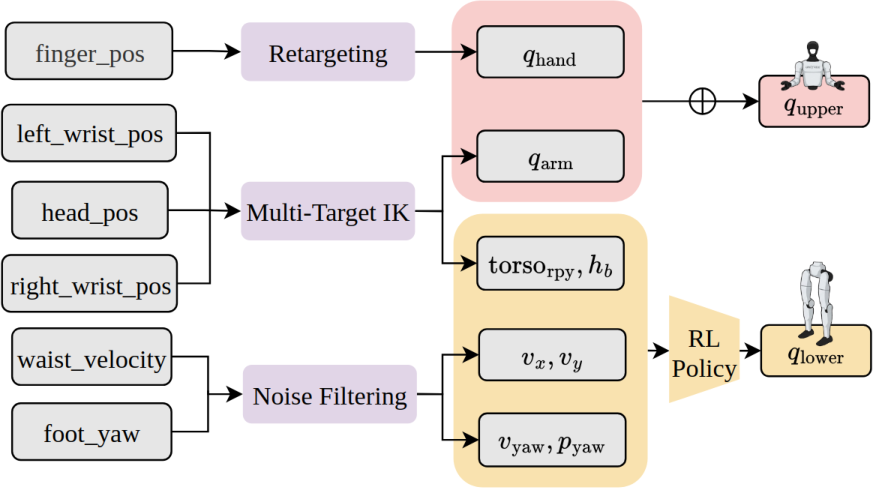
- Tools/workflows: The open-source teleop framework and IK solver; RL controller for stable locomotion; dataset logging for reproducible training.
- Assumptions/dependencies: Wearable hardware availability; calibration for IK and trackers; operator training; clear data consent and privacy workflows.
- Smoother robot control under large-model latency (Software/Robotics middleware)
- What: Integrate training-time Real-Time Chunking (RTC) to suppress motion jitter when using large VLA policies on physical robots.
- Tools/workflows: Incorporate RTC in training and inference pipelines; maintain action chunk consistency across frames.
- Assumptions/dependencies: Access to the training loop; consistent chunk sizes; action history buffering.
- Adoption of a joint-space action expert (MM-DiT) for precision control (Robotics, Software)
- What: Replace end-effector-only heads or naïve DiT with the MM-DiT flow-based action expert for improved precision and VL-conditioning in multi-DoF humanoids.
- Tools/workflows: Plug-in MM-DiT action head into existing VLM backbones; retrain flow-matching objective on robot joint data.
- Assumptions/dependencies: Accurate joint-space telemetry; synchronization with visual inputs; sufficient compute for training and runtime.
- Efficient pretraining using human egocentric videos (Data strategy, Academia)
- What: Adopt the “quality-over-quantity” recipe—pretrain only on high-quality egocentric manipulation videos (e.g., EgoDex) with next-step action token prediction rather than large noisy Internet clips.
- Tools/workflows: FAST action tokenizer to compress continuous actions; next-token training objective for VLM backbones.
- Assumptions/dependencies: Rights to use egocentric video datasets; curated action annotations; alignment of camera viewpoints with downstream robot observations.
- Benchmarking and curriculum design for humanoid loco-manipulation (Academia, Standards)
- What: Use the eight-task evaluation and skill-level metrics to design curricula for long-horizon dexterous loco-manipulation.
- Tools/workflows: Open-source evaluation scripts and tasks; sub-task success tracking; shared action/state representations.
- Assumptions/dependencies: Comparable hardware stack or sim-to-real equivalents; identical observation and action interfaces for fair comparison.
- Facility and retail pilots for light-duty tasks (Industry pilots: Hospitality, Retail)
- What: Conduct small-scope pilots for shelf restocking of lightweight items, pushing carts, door operation, and surface wiping.
- Tools/workflows: Fine-tune on store-specific objects and layouts; integrate with facility safety controls and human-in-the-loop supervision.
- Assumptions/dependencies: Payload/torque limits of current humanoids; restricted, low-risk environments; downtime plans for teleop fallback.
- Hospital logistics assistants for non-patient tasks (Healthcare logistics)
- What: Use robots for item fetching, door operation, cart transportation in back-of-house settings (no direct patient handling).
- Tools/workflows: Task-specific fine-tuning; secure deployment protocols; staff training for co-working.
- Assumptions/dependencies: Infection control and safety policies; limited physical loads; controlled corridors; IT integration for task dispatch.
- Teaching and lab courses on embodied AI with fewer resources (Education)
- What: Run courses that cover VLA pretraining from human video, joint-space policy post-training, and deployment on a humanoid platform.
- Tools/workflows: Released codebase, training pipeline, and example datasets; small-scale GPU clusters; replay-based training labs.
- Assumptions/dependencies: Access to a humanoid or simulated equivalent; institutional data governance; instructor familiarity with VLA stacks.
- Upgrading existing robot stacks with RTC and MM-DiT heads (Robotics integrators)
- What: Retrofitting mobile manipulators or humanoids to reduce jitter and improve precision via the paper’s action head and chunking strategies.
- Tools/workflows: Middleware integration (ROS2 or custom); offline retraining; latency profiling and optimization.
- Assumptions/dependencies: Access to training data; hardware-agnostic interfaces; compute budget to support larger models.
- Data-governed pipelines for human video in robotics (Policy, Compliance)
- What: Establish data governance practices to source and process egocentric human video ethically and legally for robotics pretraining.
- Tools/workflows: Consent and anonymization protocols; usage licenses; dataset curation checklists prioritizing quality over volume.
- Assumptions/dependencies: Institutional review boards (IRB) or equivalent; regional privacy laws (e.g., GDPR, HIPAA where applicable).
Long-Term Applications
These applications require further research, scaling, or productization beyond the current system’s capabilities, or rely on maturing hardware.
- Universal household assistants (Consumer robotics)
- What: General-purpose home help across varied kitchens, laundry rooms, and living spaces with dexterous manipulation and navigation.
- Dependencies: More robust perception under clutter/occlusions; safer hardware; stronger grasp force control; expanded skill libraries; home-specific fine-tuning at scale.
- Flexible manufacturing and assembly (Industry 4.0)
- What: Small-batch assembly, kitting, and reconfigurable line-side operations demanding dexterous manipulation and tool use.
- Dependencies: Tool-change systems, force/torque sensing, compliance control; higher payloads; safety-certifiable behavior models and runtime monitors.
- Elder-care and assistive tasks (Healthcare)
- What: Non-medical assistance—fetching, opening/closing fixtures, light tidying—with human-aware, safety-first behaviors.
- Dependencies: Human-in-the-loop interfaces; safety standards; fall-risk detection; robust failure recovery; legal frameworks for in-home deployment.
- Disaster response and remote intervention (Public safety)
- What: Door opening, switch operation, debris navigation, and equipment manipulation in hazardous zones under teleop-to-autonomy blend.
- Dependencies: Ruggedized hardware, robust locomotion on uneven terrain, multi-modal sensing (thermal/LiDAR), reliable remote comms; domain-adaptation under extreme visuals.
- Cross-embodiment transfer and rapid onboarding to new humanoids (Robotics platforms)
- What: Apply the decoupled training recipe to quickly bring up policies on new humanoid bodies or hand designs.
- Dependencies: Systematic joint-space mapping and calibration; automated retargeting; standardized action/state interfaces across vendors.
- Model-as-a-service for humanoid loco-manipulation (Software)
- What: Cloud or on-prem services that host the VLM backbone + MM-DiT action experts with task libraries and RTC-enabled streaming.
- Dependencies: Low-latency networking; secure APIs; edge-device accelerators; robust fallback if connectivity drops; cost controls.
- Sector-specific skill libraries and “app stores” (Ecosystem)
- What: Curated, validated skill packs (e.g., hospital logistics, hotel housekeeping, retail face-up/restocking) with task-level documentation and safety checks.
- Dependencies: Standardized evaluation and certification; update channels for new skills; cross-site domain adaptation pipelines.
- Generalized embodied learning from large-scale human video (Research)
- What: Expand beyond dexterous manipulation to tool use, deformable object handling, and social-aware interactions using higher-quality, labeled egocentric datasets.
- Dependencies: New data collection standards; richer annotations (tactile proxies, action semantics); larger and more efficient backbone models.
- Unified chunking and safety monitors for large robot policies (Safety engineering)
- What: Combine RTC with runtime constraint monitors, predictive safety filters, and explainability hooks for certifiable behavior.
- Dependencies: Formal verification frameworks; failsafe actuation; standardized safety telemetry; regulatory engagement.
- Energy- and compute-efficient on-robot inference (Energy, Hardware)
- What: Optimize or distill the model for edge deployment (e.g., mixed-precision, sparse attention, model pruning) to cut latency and power.
- Dependencies: Hardware accelerators (Edge GPUs/NPUs), quantization-aware training, co-design with perception stacks.
- Shared autonomy and learning-from-teleop-at-scale (Human–robot interaction)
- What: Seamless blending of operator input with the learned policy for hard cases; automatic skill improvement from day-to-day teleop traces.
- Dependencies: Continual learning pipelines; confidence-aware blending; privacy-preserving data collection; robust versioning and rollback.
- Standards and regulation for egocentric-video–to-robot pipelines (Policy)
- What: Sector-wide norms for dataset quality, consent, bias auditing, and safety evaluation of humanoid foundation models trained on human video.
- Dependencies: Multi-stakeholder consortia; benchmarks and certification suites; compliance tooling integrated into data pipelines.
Notes on feasibility and assumptions common across applications:
- Hardware constraints: Current humanoids have limited payload, finger strength, and robustness; many long-term applications need stronger, safer hardware.
- Compute and latency: Large models impose inference latency; RTC mitigates but edge optimization or distillation is required for broader deployment.
- Data governance: Ethical, legal acquisition of egocentric video data is essential; curation quality strongly impacts outcomes.
- Safety: Real-world deployments require runtime monitors, fail-safes, and regulatory alignment, especially in public and healthcare settings.
- Generalization: While the paper shows strong results in several environments, broad generalization to open-world settings will require more data diversity, better sensing, and continual adaptation.
Glossary
- Action chunk: A short sequence of future actions predicted and executed together to smooth control and reduce latency effects. "the action expert efficiently and concurrently outputs joint-space action chunks."
- Autoregressive pre-training: Training where the model predicts the next element (e.g., action token) conditioned on previous ones. "we autoregressively pre-train a VLM backbone on large-scale egocentric human videos"
- Co-training: Jointly training on multiple heterogeneous data sources or domains at once. "co-training strategies that mix human and robot data"
- Degrees of Freedom (DoF): The number of independent parameters that define a system’s configuration, often used to describe robot joints. "The 8-DoF lower-body actions"
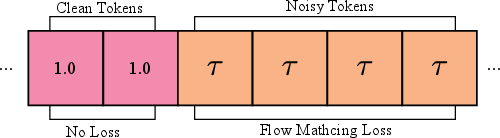
- Diffusion noise: Random noise added during diffusion-based training or generation to be progressively removed by the model. "we randomly remove diffusion noise from the first d!=!uniform(0, d_{\max}) tokens"
- Diffusion Transformer (DiT): A transformer architecture used for diffusion-based generative modeling of sequences or images. "a large diffusion transformer (DiT)"
- Domain adaptation: Techniques for transferring knowledge from one data domain to another with different distributions. "these approaches employ domain adaptation"
- Egocentric (video): First-person perspective video captured from the subject’s viewpoint (e.g., head camera). "Human egocentric videos provide a scalable alternative"
- Embodiment gap: The mismatch in morphology and dynamics between different bodies (e.g., humans vs. robots) that complicates transfer. "due to the substantial embodiment gap between humans and robots."
- End-effector space: A control representation defined by the pose of a robot’s end-effectors (e.g., wrists, grippers) rather than joint angles. "predict arm and hand actions in the end-effector space."
- FAST tokenizer: A learned discretization method that converts continuous action trajectories into token sequences for autoregressive modeling. "Training begins by fitting a FAST tokenizer"
- Flow-based action expert: An action-prediction module trained with flow-based objectives to model action distributions and generate trajectories. "we post-train a flow-based action expert on high-quality humanoid robot data"
- Flow matching: A training objective for flow-based generative models that matches model-predicted velocity fields to the true data-to-noise flow. "the flow-matching training objective"
- Flow timestep: The continuous time parameter in flow-based generative modeling that interpolates between noise and data. "a uniformly sampled flow timestep "
- In-domain (data): Data collected under the same conditions and task distributions as the target deployment setting. "in-domain teleoperated demonstrations."
- Inverse kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. "followed by inverse kinematics (IK) during inference"
- Joint space: A control representation defined by the robot’s joint angles or velocities. "to predict action chunks in the joint space."
- Loco-manipulation: Integrated planning and control of both locomotion and manipulation with a single robot. "loco-manipulation tasks"
- MM-DiT (Multi-Modal Diffusion Transformer): A diffusion transformer variant that fuses multiple modalities (e.g., vision, language, actions) for conditional generation. "a multi-modal diffusion transformer (MM-DiT)"
- Proprioceptive state: Internal sensor readings of a robot that reflect its configuration (e.g., joint positions), independent of external perception. "the whole-body proprioceptive state "
- Real-Time Chunking (RTC): A technique that conditions each new action chunk on previously executed chunks to ensure smoothness under inference delays. "training-time real-time chunking (RTC)"
- Reinforcement learning (RL)-based control policy: A controller trained with reinforcement learning to map high-level commands to stable low-level joint behaviors. "We employ an RL-based control policy~\cite{li2025amo} to control the lower body and torso joints"
- Task space: A control representation defined in Cartesian or operational space (e.g., positions/orientations of effectors) rather than joints. "next-action tokens in the task space."
- Teleoperation: Remote human control of a robot, often using VR or specialized interfaces to collect demonstrations. "VR-based teleoperation"
- Vision-Language-Action (VLA): Models that fuse visual inputs, language instructions, and action generation for embodied control. "a VLA model for humanoid dexterous loco-manipulation."
- Vision-LLM (VLM): Models that jointly process visual and textual inputs to produce aligned representations or outputs. "we pre-train a VLM backbone"
Collections
Sign up for free to add this paper to one or more collections.