Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Abstract: Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website https://robotics-transformer-x.github.io.
- A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- OpenAI, “GPT-4 technical report,” 2023.
- R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chen et al., “PaLM 2 technical report,” arXiv preprint arXiv:2305.10403, 2023.
- T. Weyand, A. Araujo, B. Cao, and J. Sim, “Google landmarks dataset v2 - a large-scale benchmark for instance-level recognition and retrieval,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- B. Wu, W. Chen, Y. Fan, Y. Zhang, J. Hou, J. Liu, and T. Zhang, “Tencent ML-images: A large-scale multi-label image database for visual representation learning,” IEEE Access, vol. 7, 2019.
- J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer, and C. Bizer, “DBpedia - a large-scale, multilingual knowledge base extracted from wikipedia.” Semantic Web, vol. 6, no. 2, pp. 167–195, 2015. [Online]. Available: http://dblp.uni-trier.de/db/journals/semweb/semweb6.html#LehmannIJJKMHMK15
- H. Mühleisen and C. Bizer, “Web data commons-extracting structured data from two large web corpora.” LDOW, vol. 937, pp. 133–145, 2012.
- A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu et al., “RT-1: Robotics transformer for real-world control at scale,” Robotics: Science and Systems (RSS), 2023.
- A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn et al., “RT-2: Vision-language-action models transfer web knowledge to robotic control,” arXiv preprint arXiv:2307.15818, 2023.
- C. Devin, A. Gupta, T. Darrell, P. Abbeel, and S. Levine, “Learning modular neural network policies for multi-task and multi-robot transfer,” in 2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017, pp. 2169–2176.
- T. Chen, A. Murali, and A. Gupta, “Hardware conditioned policies for multi-robot transfer learning,” in Advances in Neural Information Processing Systems, 2018, pp. 9355–9366.
- A. Sanchez-Gonzalez, N. Heess, J. T. Springenberg, J. Merel, M. Riedmiller, R. Hadsell, and P. Battaglia, “Graph networks as learnable physics engines for inference and control,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 4470–4479. [Online]. Available: https://proceedings.mlr.press/v80/sanchez-gonzalez18a.html
- D. Pathak, C. Lu, T. Darrell, P. Isola, and A. A. Efros, “Learning to control self-assembling morphologies: a study of generalization via modularity,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- R. Martín-Martín, M. Lee, R. Gardner, S. Savarese, J. Bohg, and A. Garg, “Variable impedance control in end-effector space. an action space for reinforcement learning in contact rich tasks,” in Proceedings of the International Conference of Intelligent Robots and Systems (IROS), 2019.
- W. Huang, I. Mordatch, and D. Pathak, “One policy to control them all: Shared modular policies for agent-agnostic control,” in ICML, 2020.
- V. Kurin, M. Igl, T. Rocktäschel, W. Boehmer, and S. Whiteson, “My body is a cage: the role of morphology in graph-based incompatible control,” arXiv preprint arXiv:2010.01856, 2020.
- K. Zakka, A. Zeng, P. Florence, J. Tompson, J. Bohg, and D. Dwibedi, “XIRL: Cross-embodiment inverse reinforcement learning,” Conference on Robot Learning (CoRL), 2021.
- A. Ghadirzadeh, X. Chen, P. Poklukar, C. Finn, M. Björkman, and D. Kragic, “Bayesian meta-learning for few-shot policy adaptation across robotic platforms,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 1274–1280.
- A. Gupta, L. Fan, S. Ganguli, and L. Fei-Fei, “Metamorph: Learning universal controllers with transformers,” in International Conference on Learning Representations, 2021.
- I. Schubert, J. Zhang, J. Bruce, S. Bechtle, E. Parisotto, M. Riedmiller, J. T. Springenberg, A. Byravan, L. Hasenclever, and N. Heess, “A generalist dynamics model for control,” 2023.
- D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine, “GNM: A general navigation model to drive any robot,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 7226–7233.
- Y. Zhou, S. Sonawani, M. Phielipp, S. Stepputtis, and H. Amor, “Modularity through attention: Efficient training and transfer of language-conditioned policies for robot manipulation,” in Proceedings of The 6th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, K. Liu, D. Kulic, and J. Ichnowski, Eds., vol. 205. PMLR, 14–18 Dec 2023, pp. 1684–1695. [Online]. Available: https://proceedings.mlr.press/v205/zhou23b.html
- S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, and C. Finn, “RoboNet: Large-scale multi-robot learning,” in Conference on Robot Learning (CoRL), vol. 100. PMLR, 2019, pp. 885–897.
- E. S. Hu, K. Huang, O. Rybkin, and D. Jayaraman, “Know thyself: Transferable visual control policies through robot-awareness,” in International Conference on Learning Representations, 2022.
- K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauza, T. Davchev, Y. Zhou, A. Gupta, A. Raju et al., “RoboCat: A self-improving foundation agent for robotic manipulation,” arXiv preprint arXiv:2306.11706, 2023.
- J. Yang, D. Sadigh, and C. Finn, “Polybot: Training one policy across robots while embracing variability,” arXiv preprint arXiv:2307.03719, 2023.
- S. Reed, K. Zolna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth-maron, M. Giménez, Y. Sulsky, J. Kay, J. T. Springenberg, T. Eccles, J. Bruce, A. Razavi, A. Edwards, N. Heess, Y. Chen, R. Hadsell, O. Vinyals, M. Bordbar, and N. de Freitas, “A generalist agent,” Transactions on Machine Learning Research, 2022.
- G. Salhotra, I.-C. A. Liu, and G. Sukhatme, “Bridging action space mismatch in learning from demonstrations,” arXiv preprint arXiv:2304.03833, 2023.
- I. Radosavovic, B. Shi, L. Fu, K. Goldberg, T. Darrell, and J. Malik, “Robot learning with sensorimotor pre-training,” in Conference on Robot Learning, 2023.
- L. Shao, F. Ferreira, M. Jorda, V. Nambiar, J. Luo, E. Solowjow, J. A. Ojea, O. Khatib, and J. Bohg, “UniGrasp: Learning a unified model to grasp with multifingered robotic hands,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 2286–2293, 2020.
- Z. Xu, B. Qi, S. Agrawal, and S. Song, “Adagrasp: Learning an adaptive gripper-aware grasping policy,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 4620–4626.
- D. Shah, A. Sridhar, N. Dashora, K. Stachowicz, K. Black, N. Hirose, and S. Levine, “ViNT: A Foundation Model for Visual Navigation,” in 7th Annual Conference on Robot Learning (CoRL), 2023.
- Y. Liu, A. Gupta, P. Abbeel, and S. Levine, “Imitation from observation: Learning to imitate behaviors from raw video via context translation,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 1118–1125.
- T. Yu, C. Finn, S. Dasari, A. Xie, T. Zhang, P. Abbeel, and S. Levine, “One-shot imitation from observing humans via domain-adaptive meta-learning,” Robotics: Science and Systems XIV, 2018.
- P. Sharma, D. Pathak, and A. Gupta, “Third-person visual imitation learning via decoupled hierarchical controller,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- L. Smith, N. Dhawan, M. Zhang, P. Abbeel, and S. Levine, “Avid: Learning multi-stage tasks via pixel-level translation of human videos,” arXiv preprint arXiv:1912.04443, 2019.
- A. Bonardi, S. James, and A. J. Davison, “Learning one-shot imitation from humans without humans,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3533–3539, 2020.
- K. Schmeckpeper, O. Rybkin, K. Daniilidis, S. Levine, and C. Finn, “Reinforcement learning with videos: Combining offline observations with interaction,” in Conference on Robot Learning. PMLR, 2021, pp. 339–354.
- H. Xiong, Q. Li, Y.-C. Chen, H. Bharadhwaj, S. Sinha, and A. Garg, “Learning by watching: Physical imitation of manipulation skills from human videos,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 7827–7834.
- E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn, “BC-Z: Zero-shot task generalization with robotic imitation learning,” in Conference on Robot Learning (CoRL), 2021, pp. 991–1002.
- S. Bahl, A. Gupta, and D. Pathak, “Human-to-robot imitation in the wild,” Robotics: Science and Systems (RSS), 2022.
- M. Ding, Y. Xu, Z. Chen, D. D. Cox, P. Luo, J. B. Tenenbaum, and C. Gan, “Embodied concept learner: Self-supervised learning of concepts and mapping through instruction following,” in Conference on Robot Learning. PMLR, 2023, pp. 1743–1754.
- S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak, “Affordances from human videos as a versatile representation for robotics,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 13 778–13 790.
- P. Sermanet, K. Xu, and S. Levine, “Unsupervised perceptual rewards for imitation learning,” arXiv preprint arXiv:1612.06699, 2016.
- L. Shao, T. Migimatsu, Q. Zhang, K. Yang, and J. Bohg, “Concept2Robot: Learning manipulation concepts from instructions and human demonstrations,” in Proceedings of Robotics: Science and Systems (RSS), 2020.
- A. S. Chen, S. Nair, and C. Finn, “Learning generalizable robotic reward functions from “in-the-wild” human videos,” arXiv preprint arXiv:2103.16817, 2021.
- S. Kumar, J. Zamora, N. Hansen, R. Jangir, and X. Wang, “Graph inverse reinforcement learning from diverse videos,” in Conference on Robot Learning. PMLR, 2023, pp. 55–66.
- M. Alakuijala, G. Dulac-Arnold, J. Mairal, J. Ponce, and C. Schmid, “Learning reward functions for robotic manipulation by observing humans,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 5006–5012.
- Y. Zhou, Y. Aytar, and K. Bousmalis, “Manipulator-independent representations for visual imitation,” 2021.
- C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y. Zhu, and A. Anandkumar, “Mimicplay: Long-horizon imitation learning by watching human play,” in Conference on Robot Learning, 2023.
- K. Schmeckpeper, A. Xie, O. Rybkin, S. Tian, K. Daniilidis, S. Levine, and C. Finn, “Learning predictive models from observation and interaction,” in European Conference on Computer Vision. Springer, 2020, pp. 708–725.
- S. Nair, A. Rajeswaran, V. Kumar, C. Finn, and A. Gupta, “R3m: A universal visual representation for robot manipulation,” in CoRL, 2022.
- T. Xiao, I. Radosavovic, T. Darrell, and J. Malik, “Masked visual pre-training for motor control,” arXiv preprint arXiv:2203.06173, 2022.
- I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell, “Real-world robot learning with masked visual pre-training,” in Conference on Robot Learning, 2022.
- Y. J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V. Kumar, and A. Zhang, “Vip: Towards universal visual reward and representation via value-implicit pre-training,” arXiv preprint arXiv:2210.00030, 2022.
- A. Majumdar, K. Yadav, S. Arnaud, Y. J. Ma, C. Chen, S. Silwal, A. Jain, V.-P. Berges, P. Abbeel, J. Malik et al., “Where are we in the search for an artificial visual cortex for embodied intelligence?” arXiv preprint arXiv:2303.18240, 2023.
- S. Karamcheti, S. Nair, A. S. Chen, T. Kollar, C. Finn, D. Sadigh, and P. Liang, “Language-driven representation learning for robotics,” Robotics: Science and Systems (RSS), 2023.
- Y. Mu, S. Yao, M. Ding, P. Luo, and C. Gan, “EC2: Emergent communication for embodied control,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6704–6714.
- S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak, “Affordances from human videos as a versatile representation for robotics,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 778–13 790.
- Y. Jiang, S. Moseson, and A. Saxena, “Efficient grasping from RGBD images: Learning using a new rectangle representation,” in 2011 IEEE International conference on robotics and automation. IEEE, 2011, pp. 3304–3311.
- L. Pinto and A. K. Gupta, “Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours,” 2016 IEEE International Conference on Robotics and Automation (ICRA), pp. 3406–3413, 2015.
- D. Kappler, J. Bohg, and S. Schaal, “Leveraging big data for grasp planning,” in ICRA, 2015, pp. 4304–4311.
- J. Mahler, J. Liang, S. Niyaz, M. Laskey, R. Doan, X. Liu, J. A. Ojea, and K. Goldberg, “Dex-Net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics,” in Robotics: Science and Systems (RSS), 2017.
- A. Depierre, E. Dellandréa, and L. Chen, “Jacquard: A large scale dataset for robotic grasp detection,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 3511–3516.
- S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen, “Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection,” The International journal of robotics research, vol. 37, no. 4-5, pp. 421–436, 2018.
- D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V. Vanhoucke et al., “QT-Opt: Scalable deep reinforcement learning for vision-based robotic manipulation,” arXiv preprint arXiv:1806.10293, 2018.
- S. Brahmbhatt, C. Ham, C. Kemp, and J. Hays, “Contactdb: Analyzing and predicting grasp contact via thermal imaging,” 04 2019.
- H.-S. Fang, C. Wang, M. Gou, and C. Lu, “Graspnet-1billion: a large-scale benchmark for general object grasping,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 444–11 453.
- C. Eppner, A. Mousavian, and D. Fox, “ACRONYM: A large-scale grasp dataset based on simulation,” in 2021 IEEE Int. Conf. on Robotics and Automation, ICRA, 2020.
- K. Bousmalis, A. Irpan, P. Wohlhart, Y. Bai, M. Kelcey, M. Kalakrishnan, L. Downs, J. Ibarz, P. Pastor, K. Konolige, S. Levine, and V. Vanhoucke, “Using simulation and domain adaptation to improve efficiency of deep robotic grasping,” in ICRA, 2018, pp. 4243–4250.
- X. Zhu, R. Tian, C. Xu, M. Huo, W. Zhan, M. Tomizuka, and M. Ding, “Fanuc manipulation: A dataset for learning-based manipulation with fanuc mate 200iD robot,” https://sites.google.com/berkeley.edu/fanuc-manipulation, 2023.
- K.-T. Yu, M. Bauza, N. Fazeli, and A. Rodriguez, “More than a million ways to be pushed. a high-fidelity experimental dataset of planar pushing,” in 2016 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2016, pp. 30–37.
- C. Finn and S. Levine, “Deep visual foresight for planning robot motion,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 2786–2793.
- F. Ebert, C. Finn, S. Dasari, A. Xie, A. Lee, and S. Levine, “Visual foresight: Model-based deep reinforcement learning for vision-based robotic control,” arXiv preprint arXiv:1812.00568, 2018.
- P. Shilane, P. Min, M. Kazhdan, and T. Funkhouser, “The princeton shape benchmark,” in Shape Modeling Applications, 2004, pp. 167–388.
- W. Wohlkinger, A. Aldoma Buchaca, R. Rusu, and M. Vincze, “3DNet: Large-Scale Object Class Recognition from CAD Models,” in IEEE International Conference on Robotics and Automation (ICRA), 2012.
- A. Kasper, Z. Xue, and R. Dillmann, “The kit object models database: An object model database for object recognition, localization and manipulation in service robotics,” The International Journal of Robotics Research, vol. 31, no. 8, pp. 927–934, 2012.
- A. Singh, J. Sha, K. S. Narayan, T. Achim, and P. Abbeel, “BigBIRD: A large-scale 3D database of object instances,” in IEEE International Conference on Robotics and Automation (ICRA), 2014, pp. 509–516.
- B. Calli, A. Walsman, A. Singh, S. Srinivasa, P. Abbeel, and A. M. Dollar, “Benchmarking in manipulation research: Using the Yale-CMU-Berkeley object and model set,” IEEE Robotics & Automation Magazine, vol. 22, no. 3, pp. 36–52, 2015.
- Zhirong Wu, S. Song, A. Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and J. Xiao, “3D ShapeNets: A deep representation for volumetric shapes,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1912–1920.
- Y. Xiang, W. Kim, W. Chen, J. Ji, C. Choy, H. Su, R. Mottaghi, L. Guibas, and S. Savarese, “ObjectNet3D: A large scale database for 3d object recognition,” in European Conference on Computer Vision (ECCV). Springer, 2016, pp. 160–176.
- D. Morrison, P. Corke, and J. Leitner, “Egad! an evolved grasping analysis dataset for diversity and reproducibility in robotic manipulation,” IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 4368–4375, 2020.
- R. Gao, Y.-Y. Chang, S. Mall, L. Fei-Fei, and J. Wu, “ObjectFolder: A dataset of objects with implicit visual, auditory, and tactile representations,” in Conference on Robot Learning, 2021, pp. 466–476.
- L. Downs, A. Francis, N. Koenig, B. Kinman, R. Hickman, K. Reymann, T. B. McHugh, and V. Vanhoucke, “Google scanned objects: A high-quality dataset of 3D scanned household items,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 2553–2560.
- D. Kalashnikov, J. Varley, Y. Chebotar, B. Swanson, R. Jonschkowski, C. Finn, S. Levine, and K. Hausman, “MT-Opt: Continuous multi-task robotic reinforcement learning at scale,” arXiv preprint arXiv:2104.08212, 2021.
- A. Mandlekar, Y. Zhu, A. Garg, J. Booher, M. Spero, A. Tung, J. Gao, J. Emmons, A. Gupta, E. Orbay, S. Savarese, and L. Fei-Fei, “RoboTurk: A crowdsourcing platform for robotic skill learning through imitation,” CoRR, vol. abs/1811.02790, 2018. [Online]. Available: http://arxiv.org/abs/1811.02790
- P. Sharma, L. Mohan, L. Pinto, and A. Gupta, “Multiple interactions made easy (MIME): Large scale demonstrations data for imitation,” in Conference on robot learning. PMLR, 2018, pp. 906–915.
- A. Mandlekar, J. Booher, M. Spero, A. Tung, A. Gupta, Y. Zhu, A. Garg, S. Savarese, and L. Fei-Fei, “Scaling robot supervision to hundreds of hours with RoboTurk: Robotic manipulation dataset through human reasoning and dexterity,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 1048–1055.
- F. Ebert, Y. Yang, K. Schmeckpeper, B. Bucher, G. Georgakis, K. Daniilidis, C. Finn, and S. Levine, “Bridge data: Boosting generalization of robotic skills with cross-domain datasets,” in Robotics: Science and Systems (RSS) XVIII, 2022.
- A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y. Zhu, and R. Martín-Martín, “What matters in learning from offline human demonstrations for robot manipulation,” in arXiv preprint arXiv:2108.03298, 2021.
- C. Lynch, A. Wahid, J. Tompson, T. Ding, J. Betker, R. Baruch, T. Armstrong, and P. Florence, “Interactive language: Talking to robots in real time,” IEEE Robotics and Automation Letters, 2023.
- H.-S. Fang, H. Fang, Z. Tang, J. Liu, J. Wang, H. Zhu, and C. Lu, “RH20T: A robotic dataset for learning diverse skills in one-shot,” in RSS 2023 Workshop on Learning for Task and Motion Planning, 2023.
- H. Bharadhwaj, J. Vakil, M. Sharma, A. Gupta, S. Tulsiani, and V. Kumar, “RoboAgent: Towards sample efficient robot manipulation with semantic augmentations and action chunking,” arxiv, 2023.
- M. Heo, Y. Lee, D. Lee, and J. J. Lim, “Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation,” in Robotics: Science and Systems, 2023.
- H. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. Vuong, A. He, V. Myers, K. Fang, C. Finn, and S. Levine, “Bridgedata v2: A dataset for robot learning at scale,” 2023.
- T. Winograd, “Understanding natural language,” Cognitive Psychology, vol. 3, no. 1, pp. 1–191, 1972. [Online]. Available: https://www.sciencedirect.com/science/article/pii/0010028572900023
- M. MacMahon, B. Stankiewicz, and B. Kuipers, “Walk the talk: Connecting language, knowledge, and action in route instructions,” in Proceedings of the Twenty-First AAAI Conference on Artificial Intelligence, 2006.
- T. Kollar, S. Tellex, D. Roy, and N. Roy, “Toward understanding natural language directions,” in 2010 5th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2010, pp. 259–266.
- D. L. Chen and R. J. Mooney, “Learning to interpret natural language navigation instructions from observations,” in Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, 2011, p. 859–865.
- F. Duvallet, J. Oh, A. Stentz, M. Walter, T. Howard, S. Hemachandra, S. Teller, and N. Roy, “Inferring maps and behaviors from natural language instructions,” in International Symposium on Experimental Robotics (ISER), 2014.
- J. Luketina, N. Nardelli, G. Farquhar, J. N. Foerster, J. Andreas, E. Grefenstette, S. Whiteson, and T. Rocktäschel, “A survey of reinforcement learning informed by natural language,” in IJCAI, 2019.
- S. Stepputtis, J. Campbell, M. Phielipp, S. Lee, C. Baral, and H. Ben Amor, “Language-conditioned imitation learning for robot manipulation tasks,” Advances in Neural Information Processing Systems, vol. 33, pp. 13 139–13 150, 2020.
- S. Nair, E. Mitchell, K. Chen, S. Savarese, C. Finn et al., “Learning language-conditioned robot behavior from offline data and crowd-sourced annotation,” in Conference on Robot Learning. PMLR, 2022, pp. 1303–1315.
- O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard, “CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,” IEEE Robotics and Automation Letters, 2022.
- O. Mees, L. Hermann, and W. Burgard, “What matters in language conditioned robotic imitation learning over unstructured data,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 11 205–11 212, 2022.
- M. Shridhar, L. Manuelli, and D. Fox, “Perceiver-actor: A multi-task transformer for robotic manipulation,” Conference on Robot Learning (CoRL), 2022.
- F. Hill, S. Mokra, N. Wong, and T. Harley, “Human instruction-following with deep reinforcement learning via transfer-learning from text,” arXiv preprint arXiv:2005.09382, 2020.
- C. Lynch and P. Sermanet, “Grounding language in play,” Robotics: Science and Systems (RSS), 2021.
- M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog et al., “Do as I can, not as I say: Grounding language in robotic affordances,” Conference on Robot Learning (CoRL), 2022.
- Y. Jiang, A. Gupta, Z. Zhang, G. Wang, Y. Dou, Y. Chen, L. Fei-Fei, A. Anandkumar, Y. Zhu, and L. Fan, “VIMA: General robot manipulation with multimodal prompts,” International Conference on Machine Learning (ICML), 2023.
- S. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “ChatGPT for robotics: Design principles and model abilities,” Microsoft Auton. Syst. Robot. Res, vol. 2, p. 20, 2023.
- W. Huang, C. Wang, R. Zhang, Y. Li, J. Wu, and L. Fei-Fei, “VoxPoser: Composable 3d value maps for robotic manipulation with language models,” arXiv preprint arXiv:2307.05973, 2023.
- M. Shridhar, L. Manuelli, and D. Fox, “Cliport: What and where pathways for robotic manipulation,” in Conference on Robot Learning. PMLR, 2022, pp. 894–906.
- A. Stone, T. Xiao, Y. Lu, K. Gopalakrishnan, K.-H. Lee, Q. Vuong, P. Wohlhart, B. Zitkovich, F. Xia, C. Finn et al., “Open-world object manipulation using pre-trained vision-language models,” arXiv preprint arXiv:2303.00905, 2023.
- Y. Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y. Qiao, and P. Luo, “EmbodiedGPT: Vision-language pre-training via embodied chain of thought,” arXiv preprint arXiv:2305.15021, 2023.
- E. Perez, F. Strub, H. de Vries, V. Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” 2017.
- M. Tan and Q. Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” in International conference on machine learning. PMLR, 2019, pp. 6105–6114.
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- S. Ramos, S. Girgin, L. Hussenot, D. Vincent, H. Yakubovich, D. Toyama, A. Gergely, P. Stanczyk, R. Marinier, J. Harmsen, O. Pietquin, and N. Momchev, “RLDS: an ecosystem to generate, share and use datasets in reinforcement learning,” 2021.
- D. Cer, Y. Yang, S. yi Kong, N. Hua, N. Limtiaco, R. S. John, N. Constant, M. Guajardo-Cespedes, S. Yuan, C. Tar, Y.-H. Sung, B. Strope, and R. Kurzweil, “Universal sentence encoder,” 2018.
- X. Chen, J. Djolonga, P. Padlewski, B. Mustafa, S. Changpinyo, J. Wu, C. R. Ruiz, S. Goodman, X. Wang, Y. Tay, S. Shakeri, M. Dehghani, D. Salz, M. Lucic, M. Tschannen, A. Nagrani, H. Hu, M. Joshi, B. Pang, C. Montgomery, P. Pietrzyk, M. Ritter, A. Piergiovanni, M. Minderer, F. Pavetic, A. Waters, G. Li, I. Alabdulmohsin, L. Beyer, J. Amelot, K. Lee, A. P. Steiner, Y. Li, D. Keysers, A. Arnab, Y. Xu, K. Rong, A. Kolesnikov, M. Seyedhosseini, A. Angelova, X. Zhai, N. Houlsby, and R. Soricut, “Pali-x: On scaling up a multilingual vision and language model,” 2023.
- J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Monteiro, J. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Barreira, O. Vinyals, A. Zisserman, and K. Simonyan, “Flamingo: a visual language model for few-shot learning,” 2022.
- D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y. Chebotar, P. Sermanet, D. Duckworth, S. Levine, V. Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence, “PaLM-E: An embodied multimodal language model,” 2023.
- A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021.
- Y. Tay, M. Dehghani, V. Q. Tran, X. Garcia, J. Wei, X. Wang, H. W. Chung, S. Shakeri, D. Bahri, T. Schuster, H. S. Zheng, D. Zhou, N. Houlsby, and D. Metzler, “UL2: Unifying language learning paradigms,” 2023.
- E. Rosete-Beas, O. Mees, G. Kalweit, J. Boedecker, and W. Burgard, “Latent plans for task agnostic offline reinforcement learning,” in Proceedings of the 6th Conference on Robot Learning (CoRL), 2022.
- O. Mees, J. Borja-Diaz, and W. Burgard, “Grounding language with visual affordances over unstructured data,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 2023.
- S. Dass, J. Yapeter, J. Zhang, J. Zhang, K. Pertsch, S. Nikolaidis, and J. J. Lim, “CLVR jaco play dataset,” 2023. [Online]. Available: https://github.com/clvrai/clvr_jaco_play_dataset
- J. Luo, C. Xu, X. Geng, G. Feng, K. Fang, L. Tan, S. Schaal, and S. Levine, “Multi-stage cable routing through hierarchical imitation learning,” arXiv preprint arXiv:2307.08927, 2023.
- J. Pari, N. M. Shafiullah, S. P. Arunachalam, and L. Pinto, “The surprising effectiveness of representation learning for visual imitation,” 2021.
- Y. Zhu, A. Joshi, P. Stone, and Y. Zhu, “Viola: Imitation learning for vision-based manipulation with object proposal priors,” 2023.
- L. Y. Chen, S. Adebola, and K. Goldberg, “Berkeley UR5 demonstration dataset,” https://sites.google.com/view/berkeley-ur5/home.
- G. Zhou, V. Dean, M. K. Srirama, A. Rajeswaran, J. Pari, K. Hatch, A. Jain, T. Yu, P. Abbeel, L. Pinto, C. Finn, and A. Gupta, “Train offline, test online: A real robot learning benchmark,” 2023.
- “Task-agnostic real world robot play,” https://www.kaggle.com/datasets/oiermees/taco-robot.
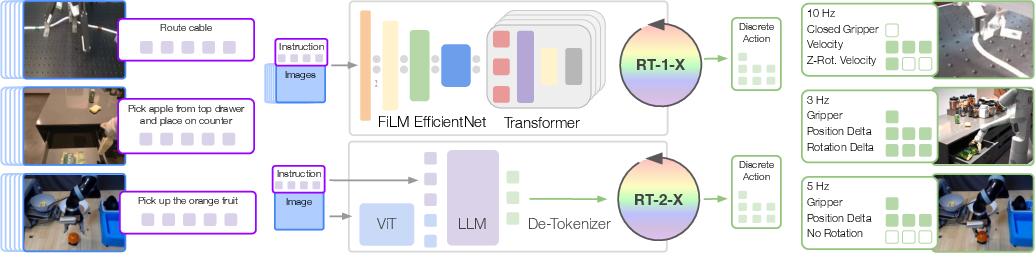
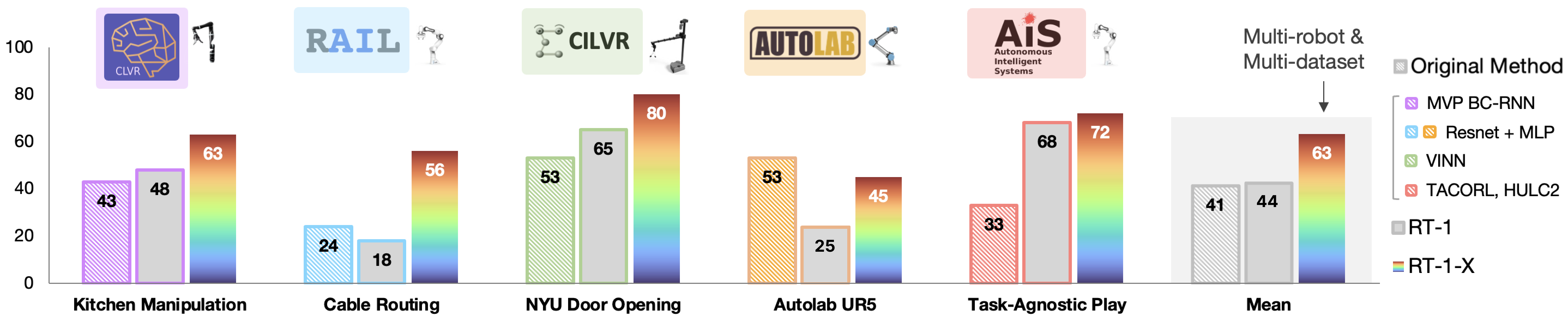

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.