- The paper demonstrates a streamlined, monolithic LLM agent framework that achieves robust and efficient autonomous planning across diverse robotics tasks.
- It features a modular, prompt-driven design integrating LLM reasoning with tool invocation and maintains stateful human-robot interaction using ROS middleware and web interfaces.
- Experimental results show high sim-to-real success rates and improved planning efficacy over multi-agent approaches, emphasizing the impact of targeted prompt engineering.
LEO-RobotAgent: A General-purpose Robotic Agent for Language-driven Embodied Operator
Framework Design and System Architecture
LEO-RobotAgent introduces a streamlined, modular agent framework, enabling LLMs to serve as autonomous planners and controllers for heterogeneous robotic platforms. Central to its design is the closed-loop integration of LLM reasoning, task planning, tool invocation, and environmental feedback, which together facilitate robust task execution and human-robot interaction. The LLM outputs task reasoning and structured action instructions (constrained to JSON) leveraging a prompt-driven architecture that mediates toolset selection, action parameters, and ongoing task state updates. The toolset is fully decoupled and extensible, enabling domain-specific perception, control, or retrieval modules registration at runtime. Historical dialog, action, observations, and user intervention are retained, ensuring accumulative state awareness and traceable operator feedback.
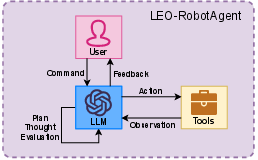
Figure 1: The core schematic of LEO-RobotAgent, showing the LLM-driven loop of plan, act, observe, and human interaction.
The complete system implementation utilizes Robot Operating System (ROS) for middleware communication and web technology for operator interface. The agent, tools, and perception modules are instantiated as ROS nodes, interfacing through a topic/message-passing paradigm. WebSocket integration facilitates seamless configuration, monitoring, and asynchronous interactive dialogs, significantly reducing the operational threshold for users and facilitating both debugging and deployment across platforms.
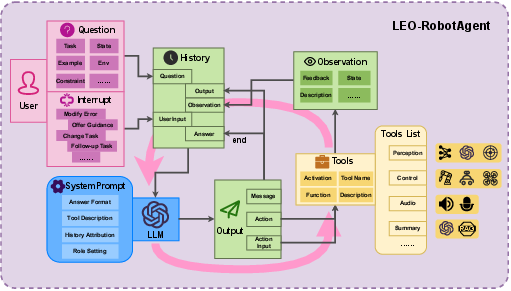
Figure 2: Detailed system implementation diagram showing discrete prompt-driven LLM reasoning, modular tool invocation, observation pipeline, and persistent history.
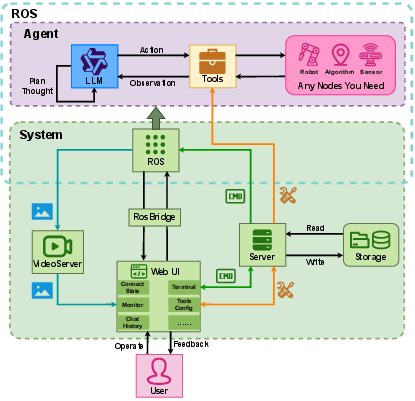
Figure 3: Application-level architecture, integrating web-based configuration, monitoring, and interaction with ROS-based agent nodes and tool modules.
Experimental Validation and Prompt Engineering
The generalization capability and robustness of LEO-RobotAgent are substantiated through both simulation and real-world experiments across UAVs, mobile robots, and manipulators with tasks exhibiting varying complexity and open-endedness. For UAV-based object search and manipulation tasks, the agent demonstrates high success rates with straightforward sim-to-real transfer, limited predominantly by the low-level perception/control tool fidelity rather than the LLM-driven planning.
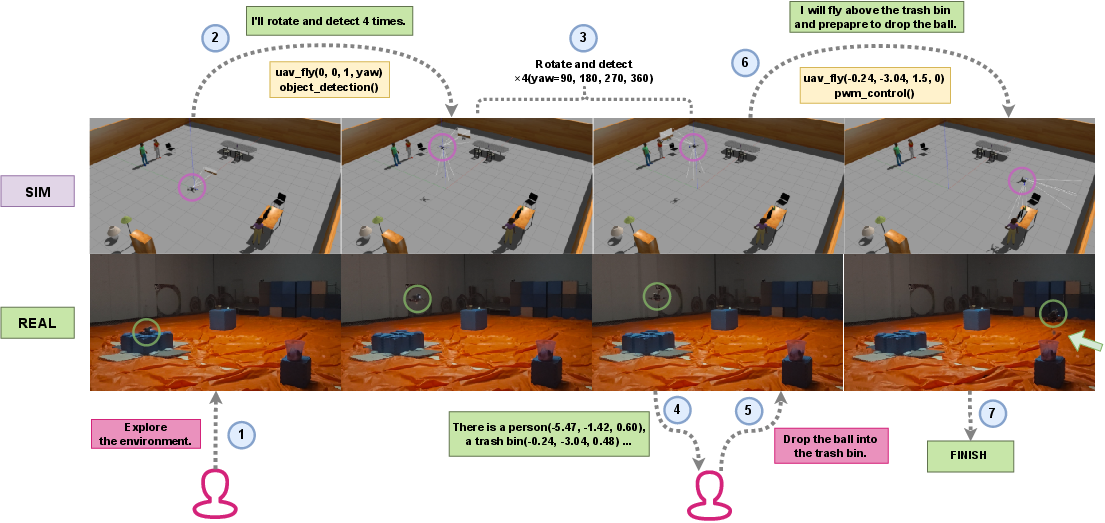
Figure 4: Sim-to-real evaluation using a UAV for complex object search and physical manipulation; the agent achieves effective closed-loop task execution and human-in-the-loop adaptation.
A targeted study investigates the effect of prompt engineering (Chain-of-Thought, one-shot, and hybrid prompting) on planning efficacy and behavior diversity in challenging domains (e.g., indoor and urban UAV search). Quantitative metrics—success rate, average task completion time, and coverage—indicate that role-specific prompt augmentation and demonstration-based conditioned planning yield increased robustness, reduced error, and more efficient execution. Chain-of-Thought induces more novel reasoning chains but incurs increased cost, while example-driven prompting (one-shot) enhances repeatability and minimum performance.


Figure 5: UAV deployment in varied environments, illustrating the impact of structured prompts on task behavior.
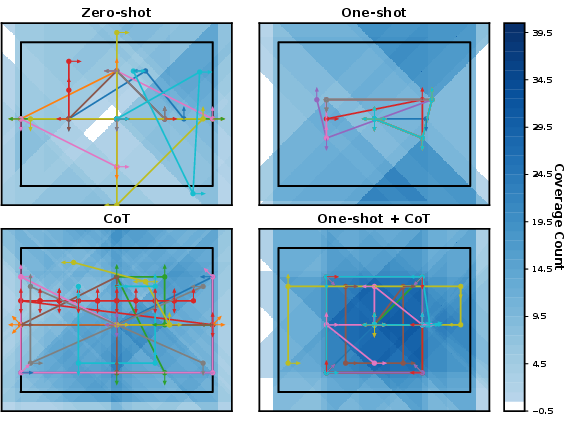
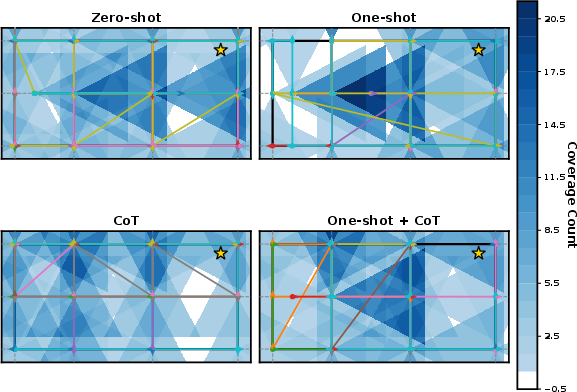
Figure 6: Coverage heatmaps of UAV field-of-view in search, reflecting the effect of different LLM prompting strategies on exploration and efficacy.
Comparative Agent Architectures
The paper presents a direct head-to-head evaluation of LEO-RobotAgent versus alternative LLM-agent architectures, namely: Direct Action Sequencing (DAS), Code-generating Execution (CGE), Dual-LLM Plan-Evaluate (DLLMs), and Tri-LLM Plan-Act-Evaluate (TLLMs). Experiments span tasks emphasizing long-horizon reasoning, subgoal acquisition, and hierarchical planning with embedded natural language subtasks on a wheeled manipulator platform in simulation.
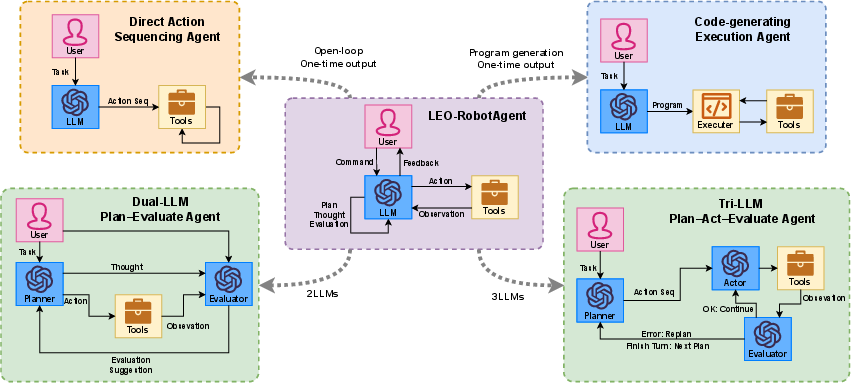
Figure 7: Architectural overview of LEO-RobotAgent and four reference agent schemes compared experimentally.

Figure 8: Mobile manipulator and evaluation environment for agent framework benchmarking.
Results confirm that one-shot architectures such as DAS and CGE perform best on short, unambiguous tasks with low token and computation overhead. However, as task complexity and linguistic ambiguity rise, multi-agent decompositions (DLLMs, TLLMs) suffer from coordination overhead, increased hallucinations, and prompt drift, resulting in lower success rates and efficiency even with exhaustive prompt engineering. LEO-RobotAgent, by consolidating reasoning and action within a single LLM instance and leveraging modular tools and incremental history, consistently achieves superior robustness and efficiency across all tested complexities. This supports the conclusion that streamlined, tool-centric LLM agent frameworks are preferable for embodied robotics, notably reducing debugging surface and system sensitivity to prompt variation.
Theoretical and Practical Implications
The LEO-RobotAgent framework advances the field of language-driven embodied intelligence in several dimensions. Practically, it operationalizes agentic control for diverse robot morphologies and task structures using a minimal but extensible architecture, lowering barriers for deployment and human-robot interaction. Theoretically, it demonstrates that given appropriate modularization and input/output constraints, monolithic LLMs are preferable to multi-LLM ensembles for closed-loop embodied operation—challenging recent trends towards ever more hierarchical/ensemble agent architectures in autonomous robotics. Notably, the clear separation of actuation, perception, and planning as tools—facilitating on-demand augmentation with external LLMs/VLMs/RAG modules—positions this framework as a unifying abstraction layer for future heterogeneous multi-agent robotics systems.
Limitations and Future Directions
Despite strong empirical results, current LLMs exhibit notable deficits in spatial and common-sense reasoning, leading to suboptimal low-level control (e.g., incorrect viewpoint orientation, incomplete spatial coverage) unless explicitly guided via prompt engineering or example-based priming. Integrating 3D spatial reasoning modules or pre-training LLMs with additional real-world grounded data remains an essential path to bridging this gap. There is also an open challenge in scalable prompt tuning and the avoidance of input/output drift over long-horizon tasks without human intervention. These limitations delineate clear directions for LLM architecture refinement and the expansion of embodied AGI capabilities.
Conclusion
LEO-RobotAgent delivers a unified, efficient, and practical agent framework enabling general-purpose LLM-driven autonomous robots. It achieves high versatility, robust cross-domain task planning, and significant reduction in human-robot communication overhead. Empirical analysis shows that minimal, well-engineered architectures outperform more complex, multi-agent or code-generation methods in realistic robot settings. As LLMs’ spatial/scenario reasoning matures, frameworks of this form will be pivotal in closing the loop on open-ended, language-driven embodied intelligence for advanced robotics applications.