- The paper introduces MBT, a fully automated post-training framework that injects human-like metacognitive strategies into LLMs.
- It presents two complementary approaches, MBT-S and MBT-R, which structure reasoning into phases including planning, execution, monitoring, self-correction, and verification.
- Empirical evaluations show significant gains in accuracy, efficiency, and robustness across multi-hop reasoning benchmarks, reducing degeneration failures.
Introduction and Motivation
The research identifies critical structural fragility in Large Reasoning Models (LRMs), particularly in complex multi-hop question answering (MHQA) tasks. Empirical analysis reveals that LRMs often derive correct intermediate answers but fail to preserve these valid conclusions, leading to erroneous final outputs. This deficiency is not attributed to a lack of reasoning capacity but to the absence of metacognitive monitoring—metacognition being the ability to plan, monitor, and verify one’s cognitive processes. LRMs without this self-regulatory mechanism are prone to uncontrolled exploration, misapplied constraints, and logical collapse, as revealed in failure case studies.

Figure 1: A representative reasoning trace generated by Qwen3-4B, showing discarded correct logic due to uncontrolled exploration and lack of metacognitive monitoring.
Process-level analysis across MHQA benchmarks reveals that a substantial fraction of errors are answer-inclusive: the correct answer is derived but subsequently discarded due to failures in logical monitoring rather than knowledge gaps or retrieval limitations.

Figure 2: Breakdown of answer-inclusive errors across MHQA benchmarks, demonstrating the prevalence of failures rooted in metacognitive deficits.
To address these structural failures, the paper introduces Metacognitive Behavioral Tuning (MBT)—a fully automated post-training framework that injects explicit metacognitive behaviors into LM reasoning. MBT comprises two complementary formulations:
- MBT-S (Synthesis): Generates rigorous, normatively structured reasoning traces from scratch using a teacher LM, ensuring strict adherence to metacognitive phases independent of the student model.
- MBT-R (Rewriting): Rewrites the student’s native reasoning traces, selectively correcting instability and enforcing structured monitoring and self-correction, thus aligning intrinsic exploration patterns with robust metacognitive regulation.
Both approaches inject a five-phase reasoning structure including goal filtering, planning, execution with monitoring, self-correction, and verification. MBT uses supervised fine-tuning (SFT) to internalize these behaviors, followed by Group Relative Policy Optimization (GRPO) RL to refine the exploration space and reinforce efficient logical trajectories.
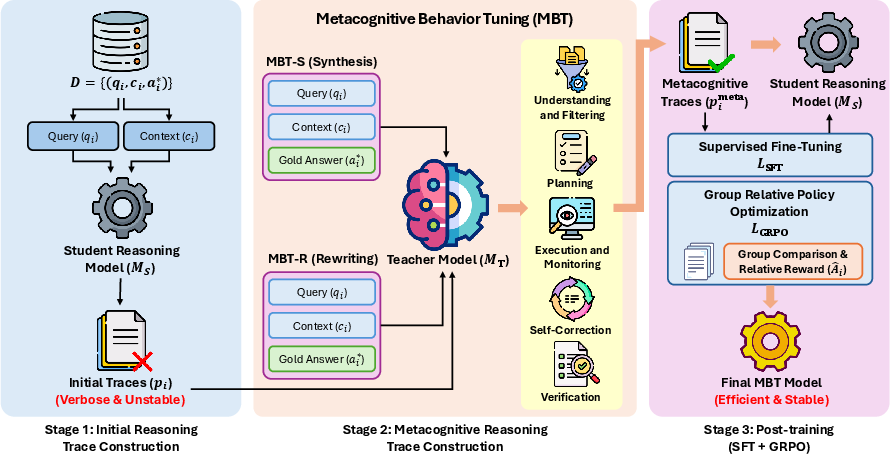
Figure 3: MBT pipeline integrating synthesis (MBT-S) and rewriting (MBT-R) strategies, followed by SFT and GRPO.
Empirical Results and Analysis
Extensive benchmarking on HotpotQA (ID), MuSiQue, and 2WikiMultiHopQA (OOD) demonstrates MBT’s superiority over baselines—including prompt-based metacognitive elicitations, rejection sampling, and efficiency-oriented methods such as TokenSkip and LIMOPro. MBT achieves notable gains in accuracy and robustness, especially on the challenging MuSiQue set, indicating strong generalization and transferability of metacognitive strategies.
Efficiency and Stability
MBT achieves a robust reduction in output length and degeneration failures, effectively eliminating reasoning collapse (e.g., infinite loops and token overflows), while maintaining maximal task accuracy. The improvement is observed across scales (Qwen3 0.6B–4B), with near-zero degeneration and concise traces even under distribution shift. AES (Accuracy-Efficiency Score) is substantially higher for MBT than all baselines.
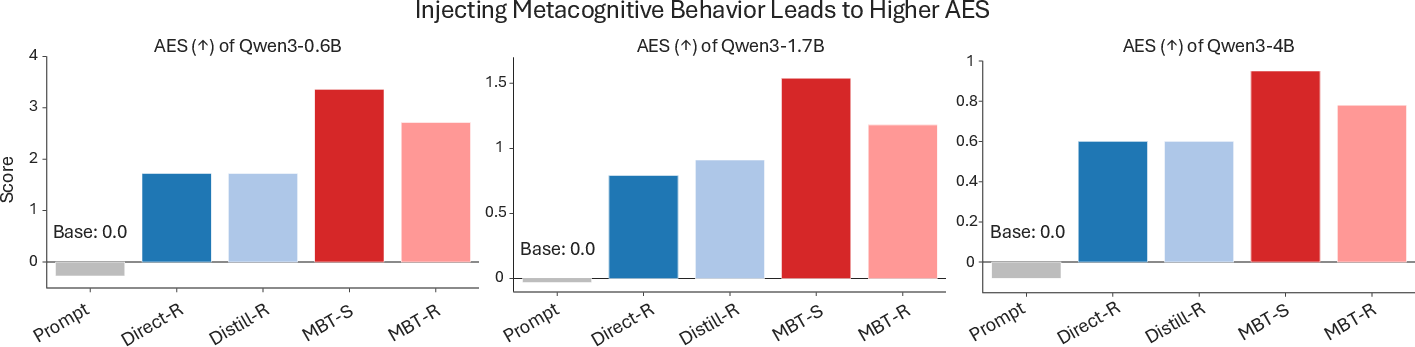
Figure 4: AES comparison on MuSiQue, showing highest scores for MBT-S and MBT-R due to superior accuracy-efficiency trade-off.
Behavioral Regulation: Overthinking and Underthinking
MBT mitigates structural stagnation, balancing exploration and termination. Overthinking (post-solution redundancy) and underthinking (pre-solution stagnation) scores are minimized for MBT, with both MBT-S and MBT-R converging to the optimal stability region.

Figure 5: Structural stability analysis with overthinking versus underthinking scores, confirming MBT-induced stable trajectories.
MBT achieves highest metacognition scores, indicating full integration of planning, monitoring, self-correction, and verification. MBT-R slightly outperforms MBT-S in self-regulatory richness, as rewriting fosters explicit reflection on errors and hypothesis revision.
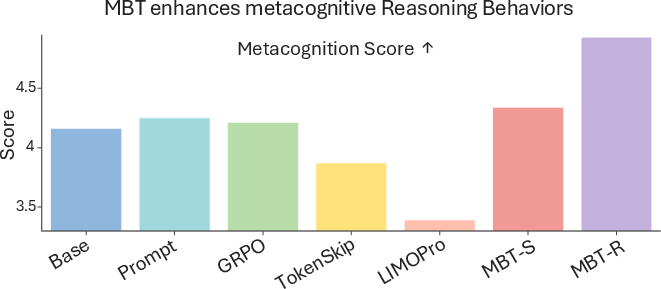
Figure 6: Metacognition Score distribution for Qwen3-4B, with MBT-R demonstrating superior integration of regulatory behaviors.
Mechanistic Analysis and Ablations
The study rigorously tests whether MBT’s improvements are merely a consequence of distilling a stronger teacher’s reasoning trace. Naive distillation matches teacher accuracy but induces severe inefficiency and degeneration, demonstrating that explicit behavioral injection is essential for practical structural stability. Hyperparameter sweeps confirm this fragility as a fundamental consequence of unregulated reasoning distillation. Ablation studies further isolate the synergistic effects of SFT and GRPO: SFT stabilizes structure, while GRPO effectively enhances performance only when applied post-structural alignment.

Figure 7: Example of uncontrolled reasoning trace (base model) demonstrating premature commitment and lack of hypothesis revision.

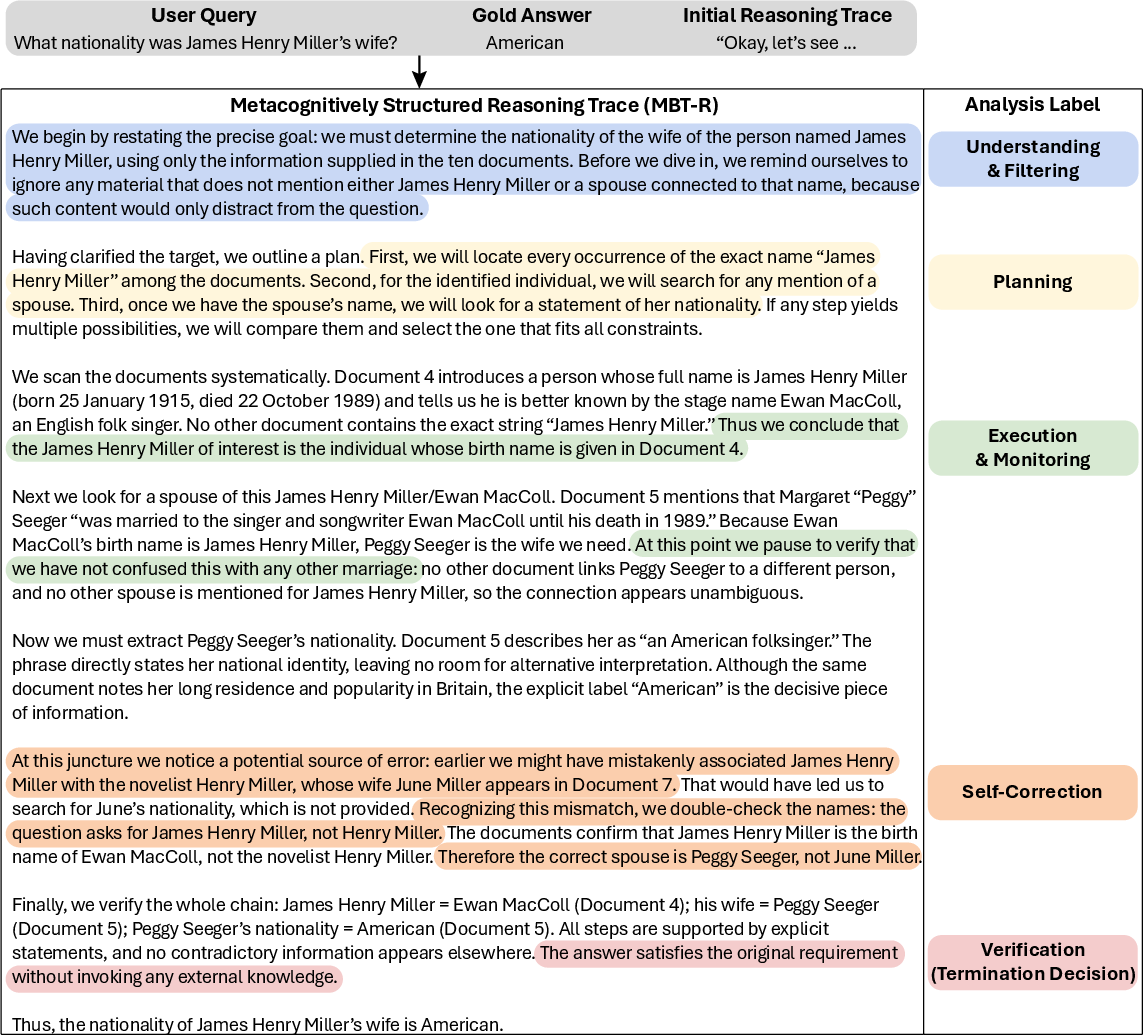
Figure 8: Example of MBT-S synthesized trace exhibiting explicit phases of planning, execution monitoring, self-correction, and rigorous verification.
Implications and Future Directions
MBT moves beyond outcome-centric reward paradigms by internalizing process-level regulation. The explicit injection of metacognitive structure is critical for exploiting latent reasoning capacity, transferring human-like control dynamics to LMs. Practically, MBT enhances interpretability (due to structured traces), reliability, and efficiency—characteristics crucial for high-stakes applications (e.g., clinical and legal domains). The approach is scalable, generalizes across tasks and model sizes, and offers a robust foundation for RL-based optimization.
Theoretically, MBT supports a paradigm shift: from scaling what models can reason (content accumulation) to how models reason (process regulation). This position motivates further investigation of lightweight trace generation, adaptation to novel domains, and integration with moral/intent alignment protocols to address dual-use risks.
Conclusion
Metacognitive Behavioral Tuning is demonstrated as a robust post-training framework for stabilizing and enhancing LLM reasoning. By distilling explicit planning, monitoring, and error-correction behaviors, MBT achieves superior accuracy, efficiency, and structural stability across complex tasks and scales. The results highlight the necessity of behavioral supervision in reasoning optimization, confirming that logical control is as critical as reasoning capacity for the next generation of high-reliability reasoning models.