- The paper introduces the SOFAI-LM architecture that integrates fast LLMs and slower LRMs through a metacognitive feedback loop to enhance complex reasoning tasks.
- It demonstrates that iterative, multi-line feedback significantly boosts success rates in graph coloring and improves performance in code debugging.
- The study highlights domain-specific effects where optimal feedback strategies differ, underscoring the need to balance speed with logical rigor in AI reasoning.
This paper explores the integration of LLMs with metacognitive modules to address complex reasoning tasks, typically handled by large reasoning models (LRMs). By extending the SOFAI cognitive architecture into SOFAI-LM, the study coordinates a fast LLM with a slower but more powerful LRM through a metacognitive feedback loop. This approach allows LLMs to iteratively refine their solutions and, if necessary, invoke the LRM with context-specific feedback. The paper reports superior performance of this integrated model over standalone LRMs in two domains: graph coloring and code debugging.
Problem Context and Challenges
The paper identifies a fundamental trade-off in AI systems between the speed and adaptability of LLMs and the logical rigor and step-by-step reasoning offered by LRMs. While LLMs excel in generalizing across domains quickly, they falter in tasks demanding strict logic and constraint adherence. Conversely, although LRMs provide robust reasoning, they suffer from higher computational costs and slower performance. The paper's contribution lies in reconciling these trade-offs using the SOFAI-LM architecture, inspired by dual-process cognitive theories, which employs metacognition to dynamically balance speed and reliability.
The SOFAI-LM Architecture
The SOFAI-LM architecture integrates fast and slow thinking modalities through a metacognitive governance module. The System 1 (S1) solver is an LLM that rapidly generates initial solutions. The metacognitive module evaluates these solutions, provides iterative feedback, and decides when to employ the System 2 (S2) solver, an LRM, for final deliberation. This structure allows the LLM to self-correct without additional fine-tuning and only leverages the computationally costly LRM when necessary. This is depicted in the SOFAI-LM architecture below.
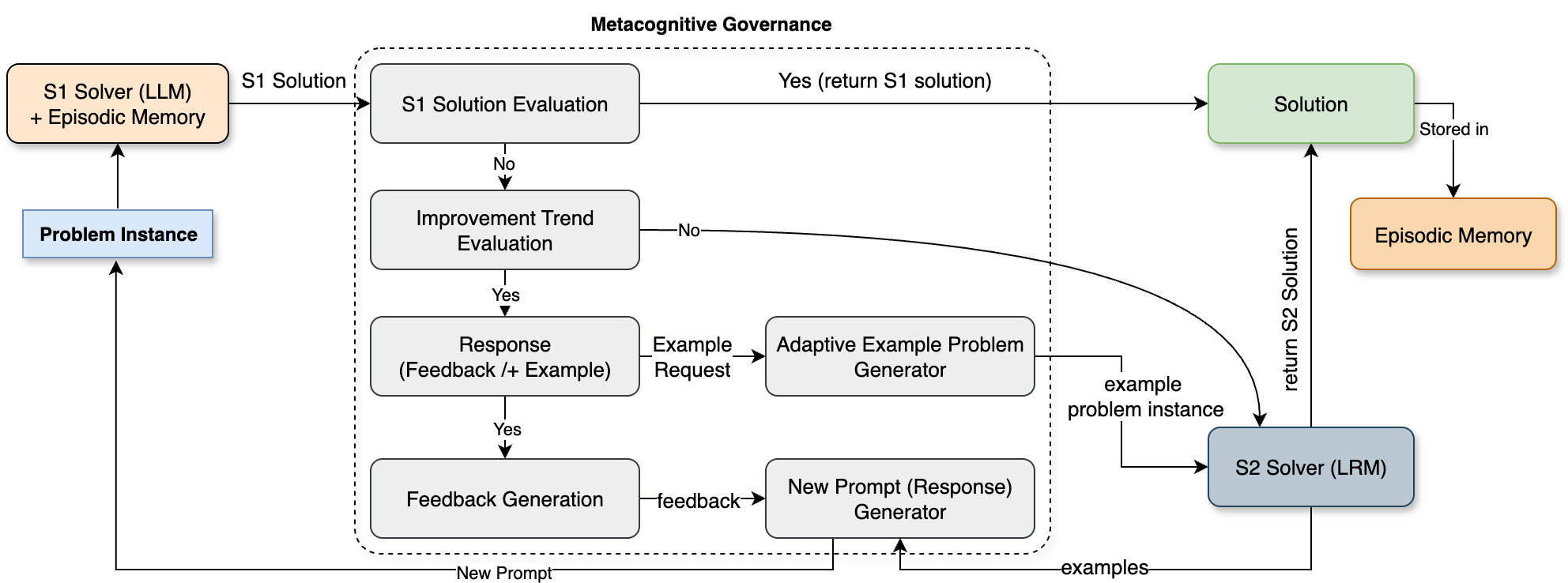
Figure 1: The SOFAI-LM architecture.
Experimental Evaluation
Domains and Methodology
The architectures were tested on graph coloring and code debugging tasks. The former requires consistent solutions for undirected graphs under color constraints, while the latter involves localizing and fixing bugs in Python and C++ programs. Using Granite3.38b as the LLM and Deepseek R18b as the LRM, various configurations and feedback types were evaluated for their impacts on success rate and inference time.
Key Findings
- Iterative Feedback: LLMs significantly improved performance through iterative feedback, especially noticeable in graph coloring tasks where the success rate increased substantially with more iterations (Figure 2).
- Feedback Efficiency: Multi-line feedback (MLF) with minimal episodic memory (MEM) resulted in optimal performance across both domains, as shown in Figure 3.
- LRM Invocation: Data suggests that using an LLM's final attempt or full feedback history boosts LRM performance in code debugging but hinders it in graph coloring, highlighting domain-specific effects (Figure 4).
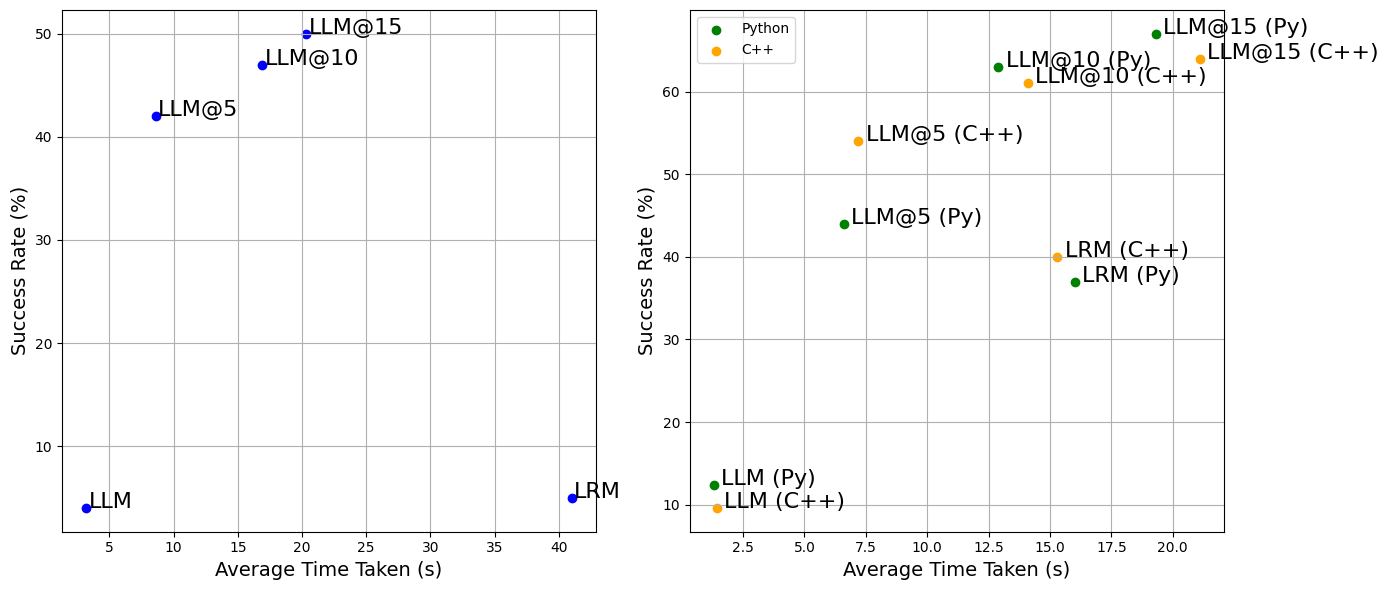
Figure 2: Each point corresponds to a configuration: LLM, LLM@5, LLM@10, LLM@15, and LRM. Left: Graph coloring problems (Solvable, size = 25). Right: Code debugging (Python and C++).
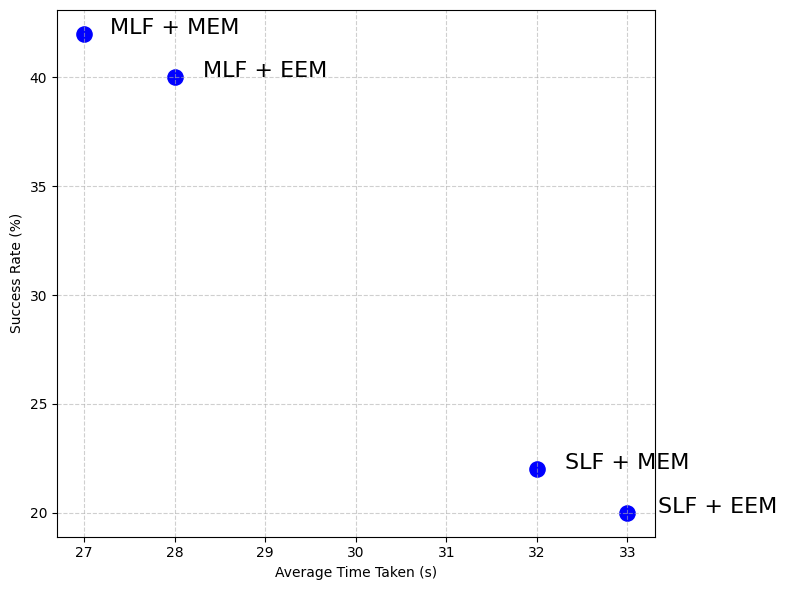
Figure 3: Success rate versus average time for four metacognitive configurations in graph coloring.
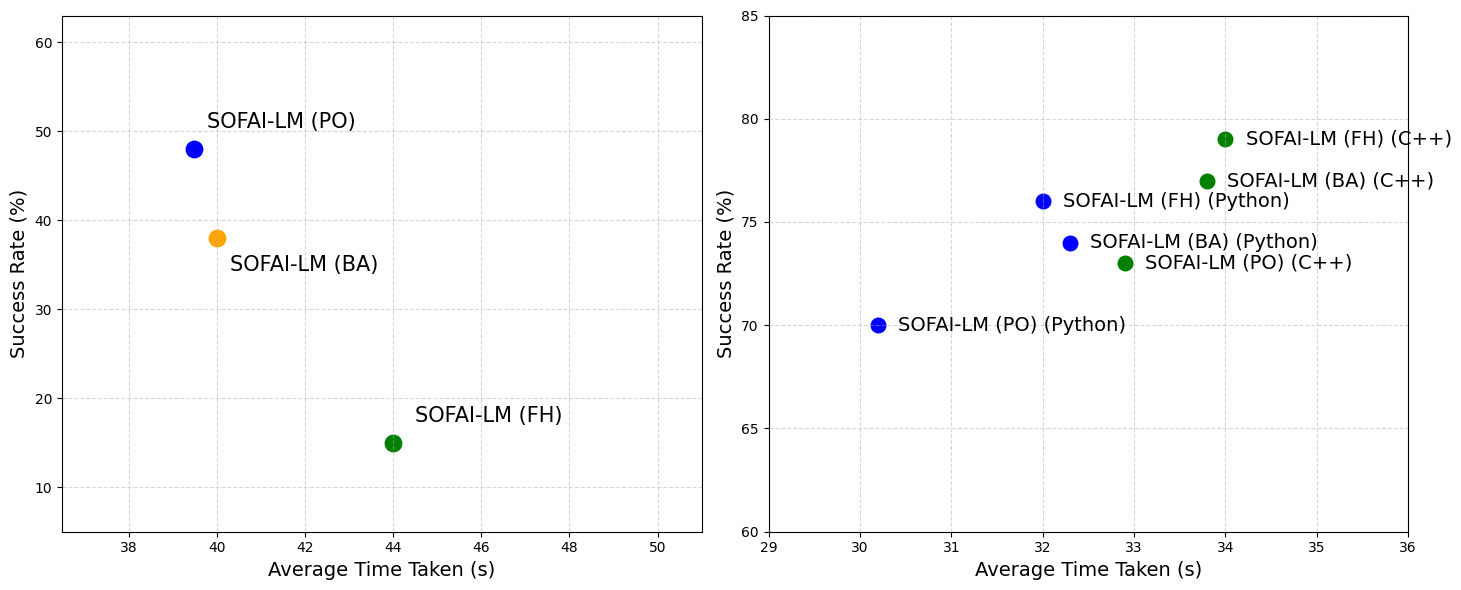
Figure 4: Success rate versus average time for SOFAI-LM using three LRM prompting strategies.
Implications and Future Work
The research demonstrates that integrating LLMs with metacognitive feedback can rival and often surpass traditional LRMs, especially in complex problem-solving scenarios. Such enhancements in the LLMs' capabilities reduce the overhead of reliance on computationally expensive LRMs. Future developments could focus on automating the metacognitive processes further, refining feedback strategies, and extending this architecture to diverse AI reasoning challenges.
In conclusion, the paper successfully illustrates that a metacognition-enabled architecture like SOFAI-LM can significantly enhance the performance of LLMs, offering a promising direction for future research in AI reasoning and problem-solving.