- The paper introduces an information-theoretic model that formalizes reasoning in LLMs as strategic information allocation under uncertainty.
- It distinguishes procedural steps from epistemic verbalization, showing how explicit uncertainty expressions enable self-correction.
- Empirical results demonstrate that models with epistemic tokens maintain higher performance and effectively navigate reasoning collapse modes.
Theoretical Framework and Motivation
This paper introduces an information-theoretic model of reasoning in LLMs, formalizing reasoning as strategic information allocation under uncertainty (2603.15500). The central theoretical construct is the separation of procedural information—step-by-step computation, symbolic manipulation, and subtask execution—from epistemic verbalization, defined as the explicit externalization of uncertainty about the reasoning trajectory at the token level. Rather than treating specific tokens (e.g., "Wait") or Aha moments as core mechanisms, the paper emphasizes uncertainty externalization as the key intervention that enables self-correction and continued information acquisition.
The analysis is situated in the closed-world inference setting, where LLMs operate without external evidence, relying exclusively on internal belief transformation. The reasoning process is modeled as self-conditioning, where internally generated representations reshape the predictive distribution Pθ(Y∣st). The objective is to produce a reasoning trace sT minimizing entropy over the target variable, establishing information sufficiency as a necessary condition for task success.
Limits of Procedural Reasoning and Collapse Modes
Procedural reasoning, implemented via step-wise execution and task decomposition (Chain-of-Thought, CoT), is shown to suffer from fundamental limitations. When the execution trajectory diverges from the intended path—either due to unidentifiable subtasks or intermediate misjudgments—further procedural continuation fails to reduce uncertainty about the correct answer, resulting in informational stagnation.
Three collapse modes are identified:
- Recursive step expansion: The model resorts to brute-force substitutions or repetitive steps.
- Problem injection: The model shifts to solving a different problem without explicit recognition.
- Degenerate loops: The model repeats words, tokens, or structures without progress.

Figure 1: Three common modes of reasoning collapse in procedural reasoning, illustrating recursive expansion, problem injection, and degenerate loops.
Once procedural divergence occurs, the conditional entropy of the target variable cannot converge to zero. This is formally shown via information-theoretic arguments, demonstrating that purely procedural continuation is insufficient for recovery or error correction.
Token-level uncertainty (entropy) is often locally low even when reasoning is globally incorrect, failing to capture trajectory-level uncertainty. The notion of epistemic verbalization is introduced: internal assessments (e.g., "Is that step correct?") acquire causal efficacy only when externalized in the reasoning trace. Epistemic verbalization, thus, is not a superficial artifact but an informational signal that enables continued belief refinement and supports downstream control actions such as self-correction.
Analysis reveals that epistemic verbalization is critical for breaking procedural stagnation and achieving information sufficiency. A theoretical proposition demonstrates that sporadic epistemic updates guarantee continued reduction of conditional entropy, formalizing the benefit of uncertainty externalization.
Empirical investigation connects epistemic verbalization to mutual-information peaks ("MI peaks") in reasoning traces. While "thinking tokens" (e.g., "Wait", "Hmm") have been previously correlated with information surges, the paper finds that elevated mutual information is associated not with the tokens themselves, but with evaluative behaviors—explicit epistemic verbalizations.

Figure 2: Token-level analysis of mutual information (MI) shows high MI corresponds to evaluative, epistemic behaviors rather than specific tokens.
For instance, in the AIME24 #7 problem, only models employing epistemic verbalization sustain information gain and self-correct to the correct answer, whereas procedural-only models stagnate.
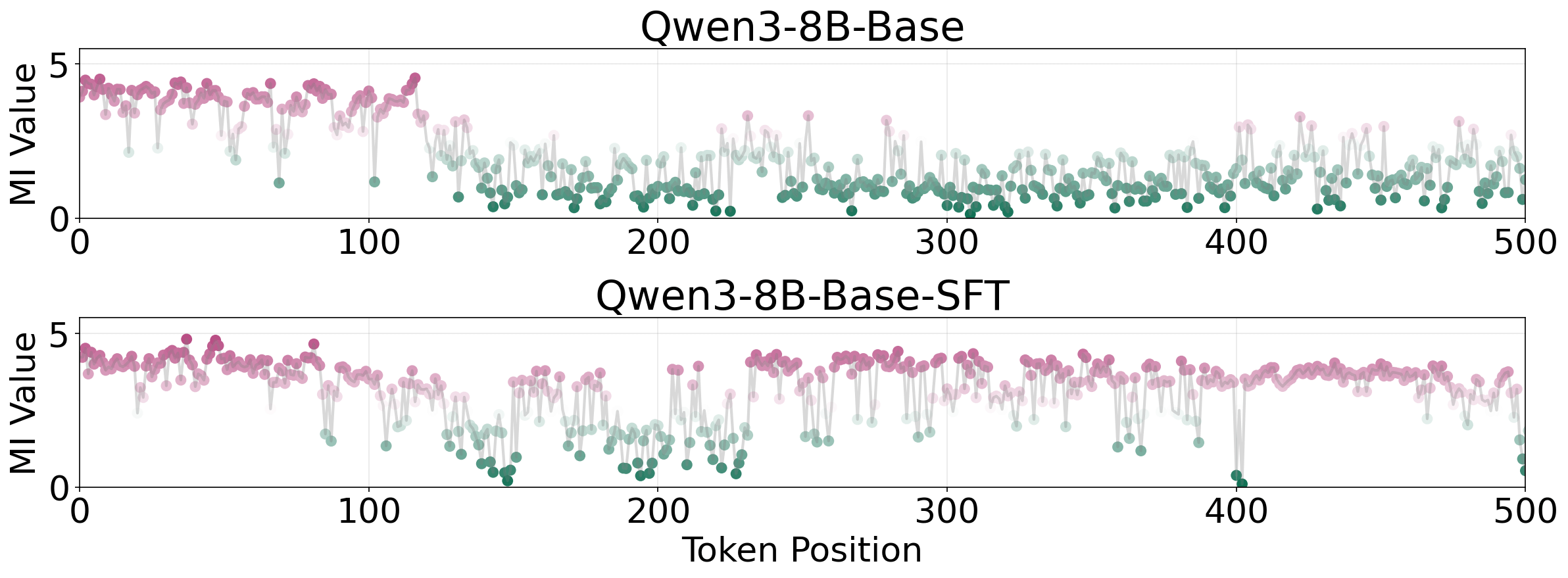
Figure 3: On an AIME24 problem, models using epistemic verbalization maintained information gain and self-corrected, while procedural-only models failed.
This pattern indicates that epistemic verbalization provides actionable structure, facilitating recovery and adaptation during reasoning.
Empirical Analysis: Uncertainty Expression and Model Capacity
The study investigates how uncertainty is verbalized across varying model capacities and task difficulty. Strong numerical results highlight that high-reasoning models facing difficult problems (AIME24/25) generate longer responses and more epistemic verbalizations, particularly in smaller models. As task difficulty increases, smaller models exhibit higher rates of epistemic token occurrence, while larger models achieve higher scores and generate more concise traces.
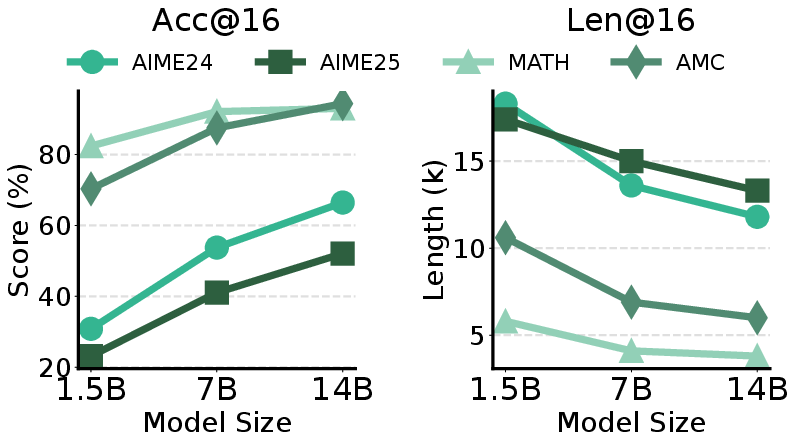
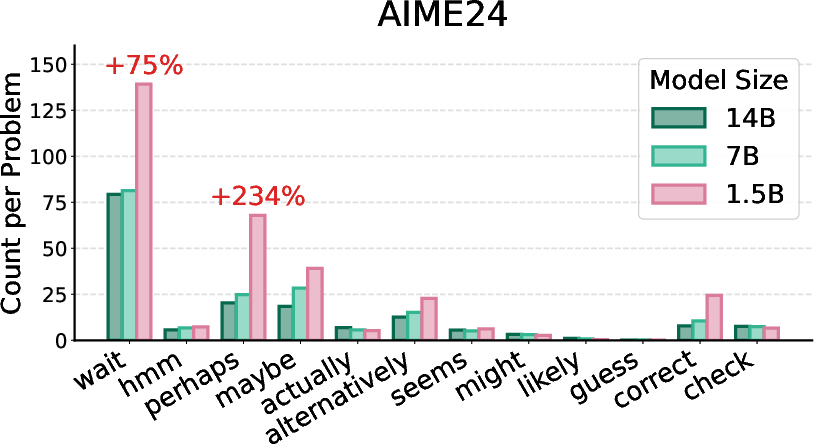
Figure 4: Acc@16 (average score) and Len@16 (average response length) for DeepSeek-Distill 1.5B–14B models on math benchmarks.
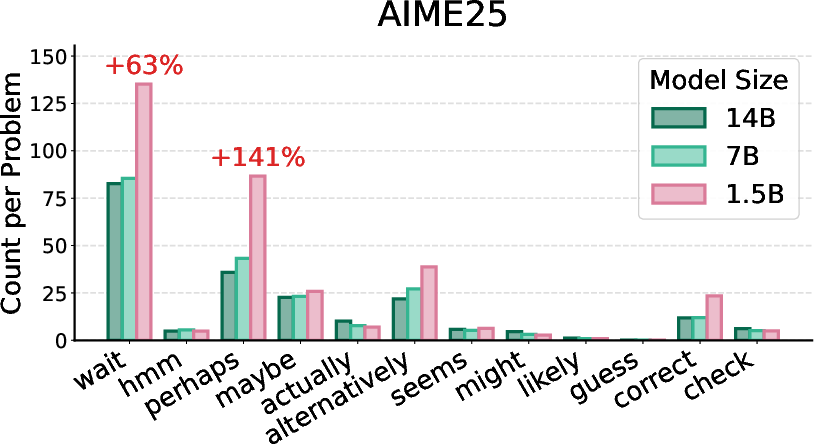
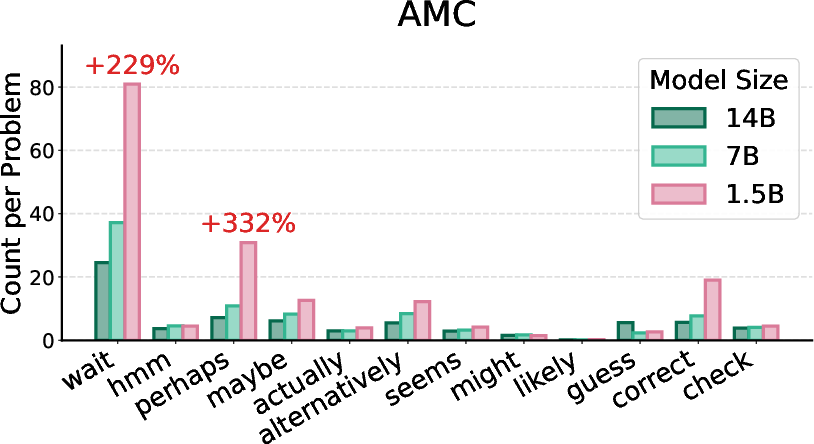
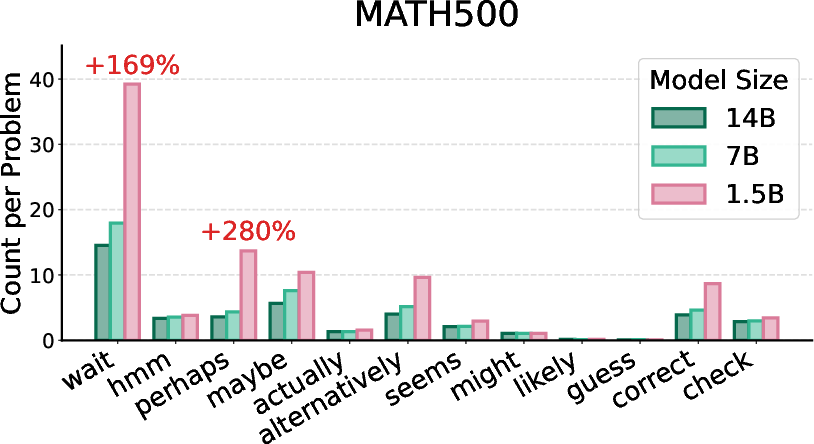
Figure 5: Token occurrence counts for DeepSeek-R1-Distill-Qwen-{1.5B, 7B, 14B} models, illustrating size-dependent epistemic token usage.
Test-Time and Training-Time Controls: Epistemic Tokens and Dataset Structure
Manipulating epistemic token generation at test time reveals substantial effects on performance. Suppressing epistemic tokens in high-reasoning models leads to a 25% drop in accuracy, but models compensate via alternative expressions of uncertainty, demonstrating the underlying diversity of epistemic verbalization. Conversely, inducing epistemic tokens in procedural-only models shows only marginal improvement unless integrated throughout the reasoning trajectory via few-shot prompting.
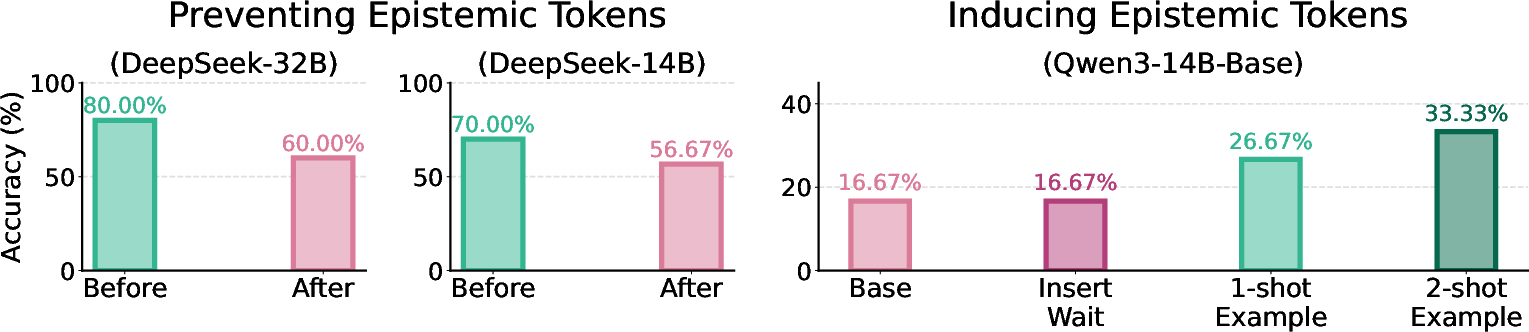
Figure 6: Comparison of epistemic token prevention and induction, demonstrating performance drops and limited gains from token-level interventions.
Controlled distillation experiments using variants of the LIMO dataset, with and without epistemic verbalization, further illuminate the informational role of uncertainty. Models fine-tuned on traces devoid of epistemic verbalization suffer highly degraded reasoning performance, despite procedural correctness of solutions—strongly contradicting the notion that correct procedural traces are sufficient. Performance drop is more severe than token suppression, establishing epistemic verbalization as critical for reasoning and control.
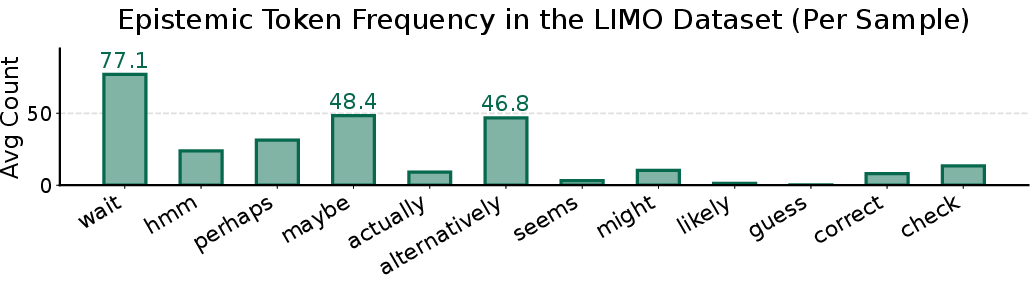
Figure 7: Per-sample counts of epistemic tokens in the LIMO dataset; responses are rich in epistemic verbalizations, especially "Wait".
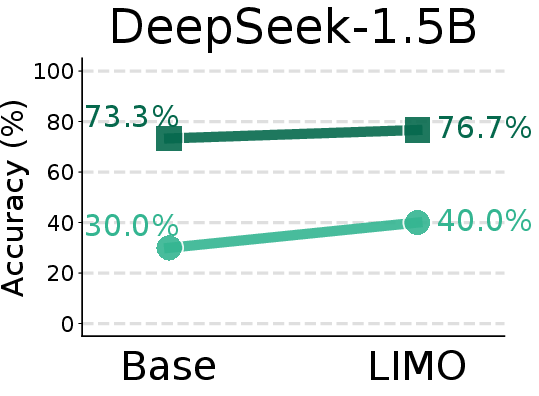
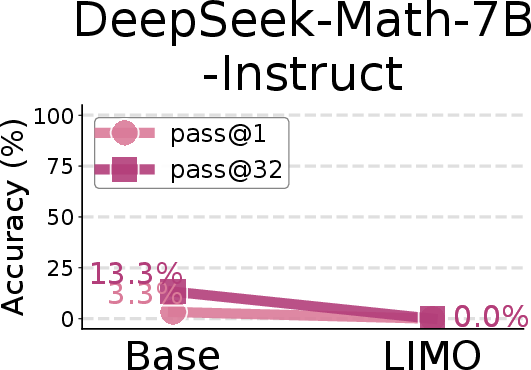
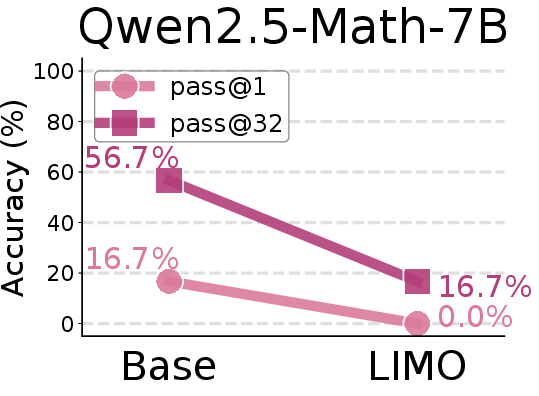
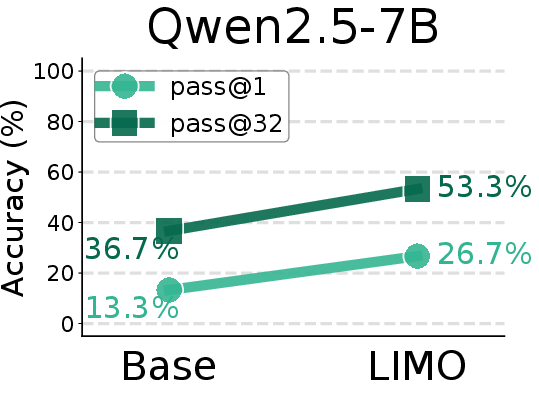
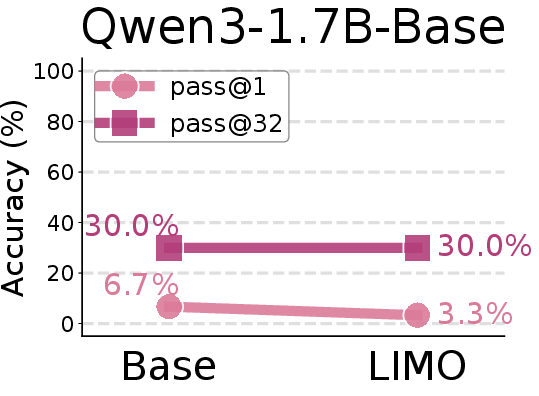
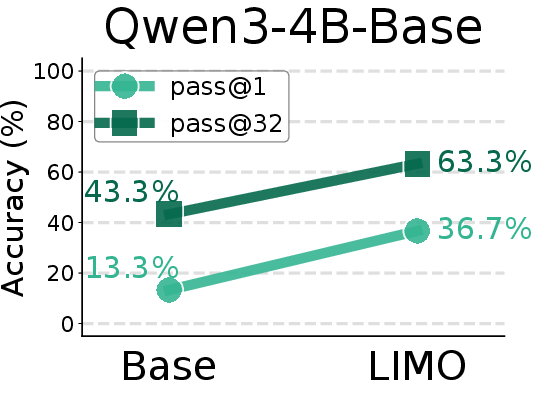
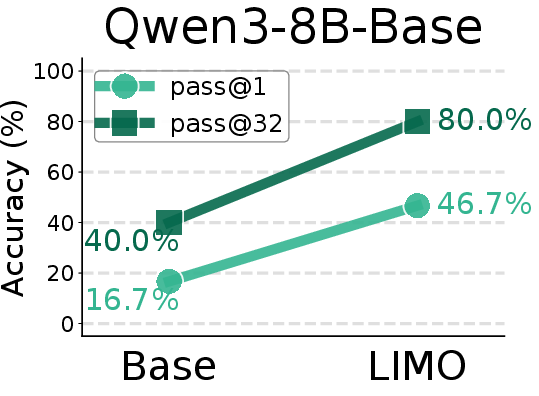
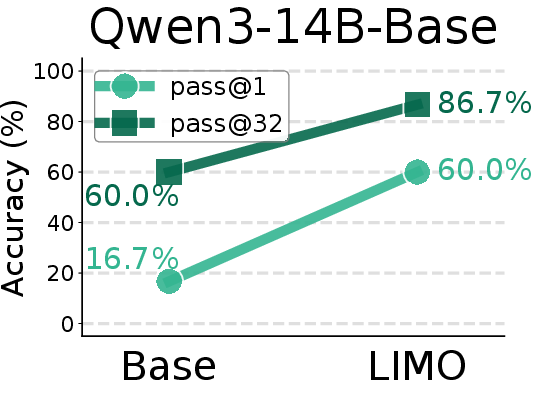
Figure 8: Comparison of AIME24 pass@1 scores between base models and SFT models trained on the LIMO-v2 dataset.
Distributional Alignment and Distillation Outcomes
Evaluating alignment between curated datasets and base model characteristics, the paper demonstrates that effective distillation requires the base model's pre-existing epistemic properties to support the dataset's epistemic signals. Token-level log probability and entropy analyses reveal that successful distillation occurs only when epistemic tokens are within the support of the student model's distribution; otherwise, distillation outcomes are inconsistent or negative.
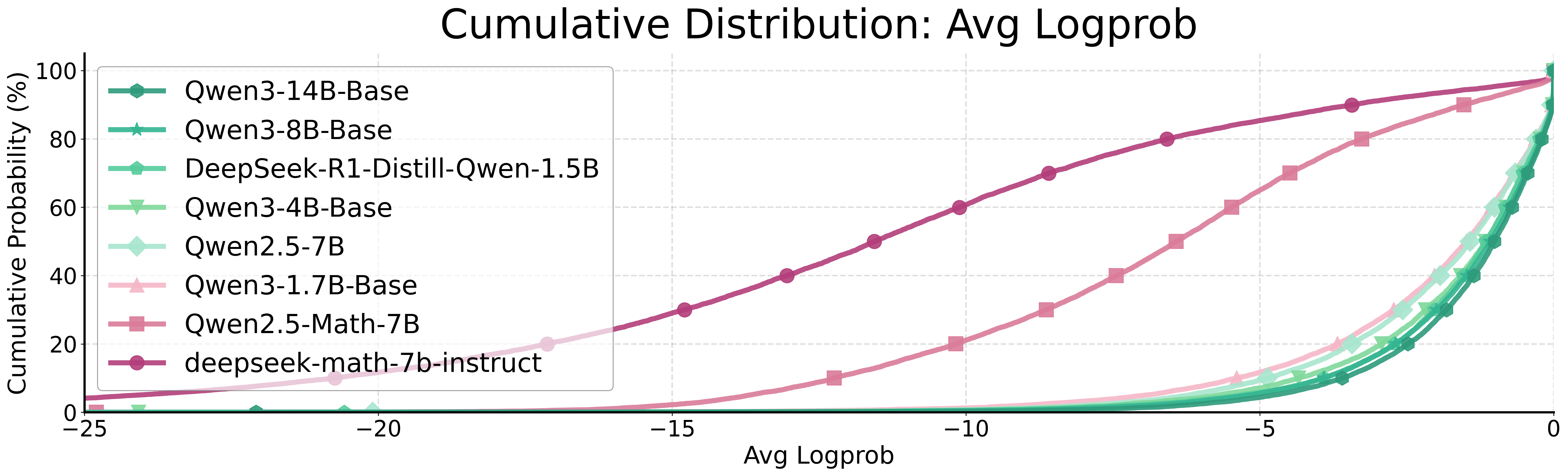
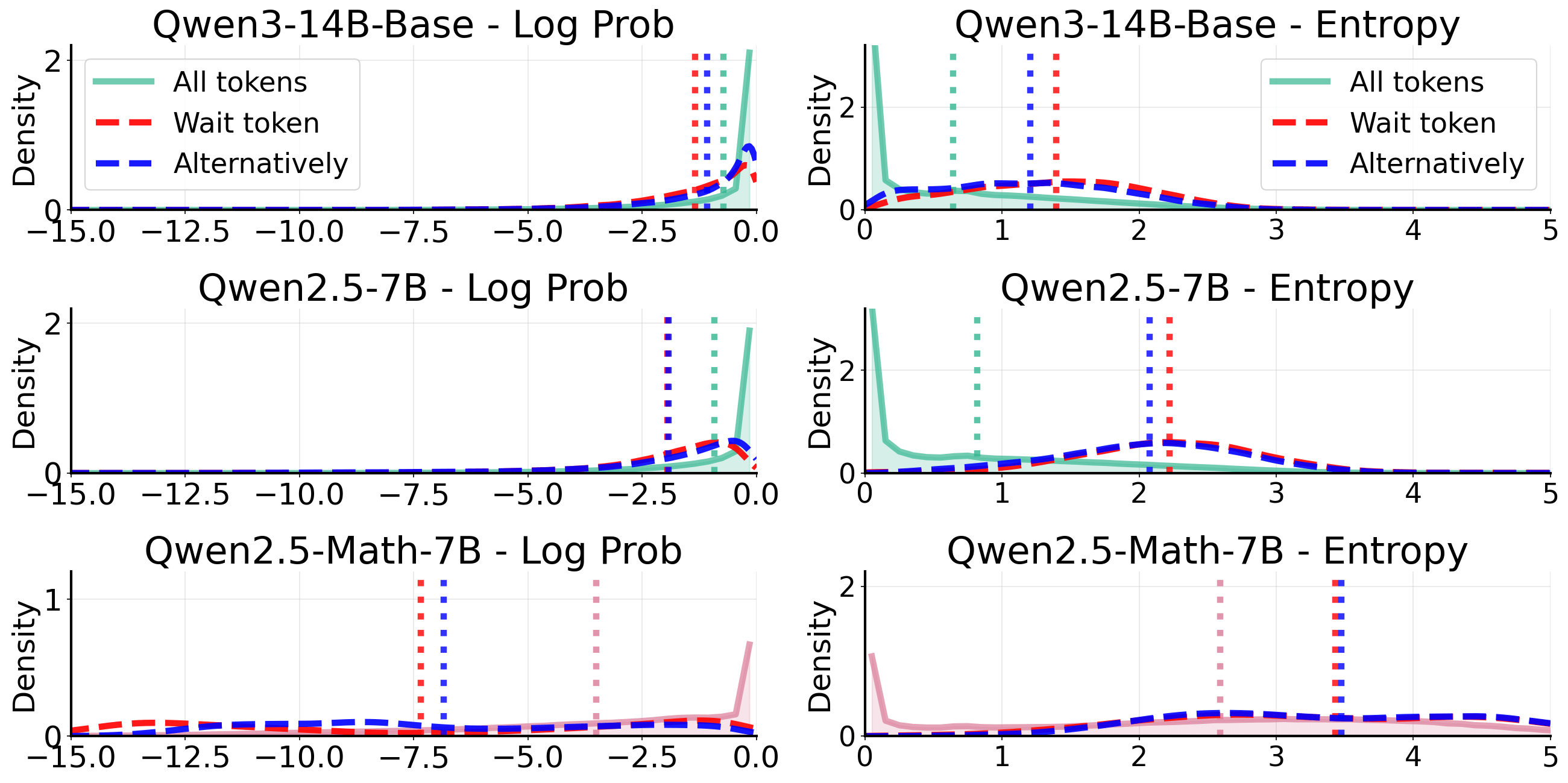
Figure 9: Cumulative distributions of log-probabilities and entropy for all tokens versus epistemic tokens, illustrating alignment and support constraints.
Practical and Theoretical Implications
This information-theoretic framework provides a unified perspective on reasoning dynamics, resolving ambiguities around Aha moments, reflection, and surface-level token manipulations. Distinguishing between procedural and epistemic axes clarifies the conditions under which self-correction can arise, and explains mixed empirical results from prior studies.
From a practical standpoint, post-training, distillation, and RL-based optimization should account for both procedural task span and epistemic verbalization capacity. Effective dataset curation, tag-based annotation, and capability-aware scheduling are recommended to align model development with target reasoning competencies. Compressing chain-of-thought traces must preserve epistemic signals; indiscriminate reduction may eliminate useful uncertainty expressions, particularly in models with limited procedural span.
Theoretically, the framework extends to world-Bayesian settings, generalizing to tool-augmented or agentic LLMs, where epistemic verbalization operates alongside environment-facing actions and external evidence acquisition. The decomposition of information axes supports new evaluation metrics and training strategies for uncertainty-aware reasoning models.
Conclusion
The paper reframes reasoning in LLMs as strategic information allocation under uncertainty, with epistemic verbalization as a central informational axis enabling continued information acquisition and control. Empirical and theoretical analyses demonstrate that explicit uncertainty externalization is essential for robust reasoning, self-correction, and distillation outcomes. The framework integrates prior fragmented observations and provides actionable guidance for model training, evaluation, and future research directions in AI reasoning systems.