Test-Time Computing for Referring Multimodal Large Language Models
Abstract: We propose ControlMLLM++, a novel test-time adaptation framework that injects learnable visual prompts into frozen multimodal LLMs (MLLMs) to enable fine-grained region-based visual reasoning without any model retraining or fine-tuning. Leveraging the insight that cross-modal attention maps intrinsically encode semantic correspondences between textual tokens and visual regions, ControlMLLM++ optimizes a latent visual token modifier during inference via a task-specific energy function to steer model attention towards user-specified areas. To enhance optimization stability and mitigate language prompt biases, ControlMLLM++ incorporates an improved optimization strategy (Optim++) and a prompt debiasing mechanism (PromptDebias). Supporting diverse visual prompt types including bounding boxes, masks, scribbles, and points, our method demonstrates strong out-of-domain generalization and interpretability. The code is available at https://github.com/mrwu-mac/ControlMLLM.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
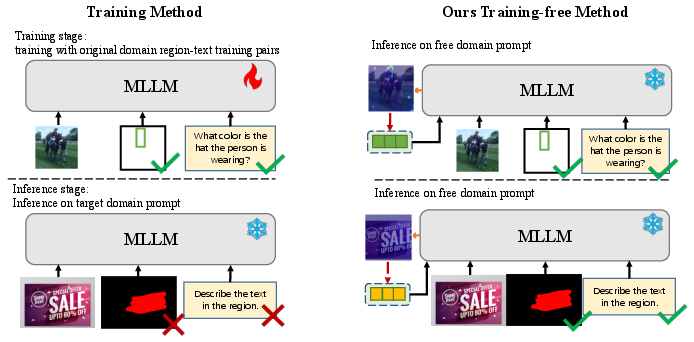
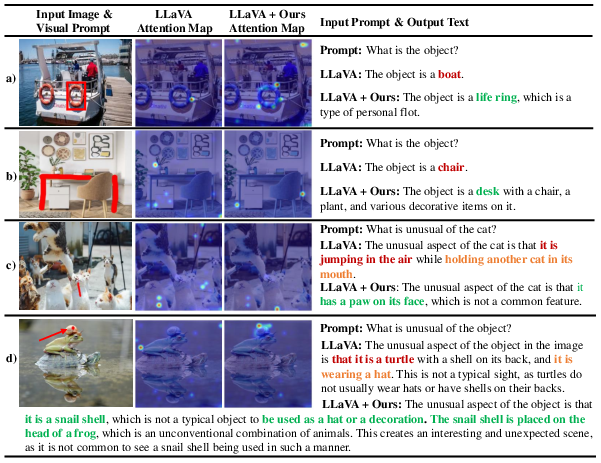
This paper introduces ControlMLLM++, a way to make AI models that understand both images and text (called multimodal LLMs, or MLLMs) pay attention to specific parts of an image—without retraining the model. Think of it as giving the AI a “pointer” so it looks at the exact area you care about, like a box around a hat or a scribble on a road sign, and then answers questions or describes that part more accurately.
What problem are they solving?
Many image+text AIs are good at understanding whole images, but they struggle to focus on small regions. If you ask, “What is written on this sign?” or “Describe the object inside this box,” the model might still talk about the wrong part of the image. Training models to understand regions usually takes lots of data and time. The goal here is to add region-focused understanding at test time (when you’re using the model), with no retraining.
How does ControlMLLM++ work?
To explain the method, let’s break down a few ideas in simple terms:
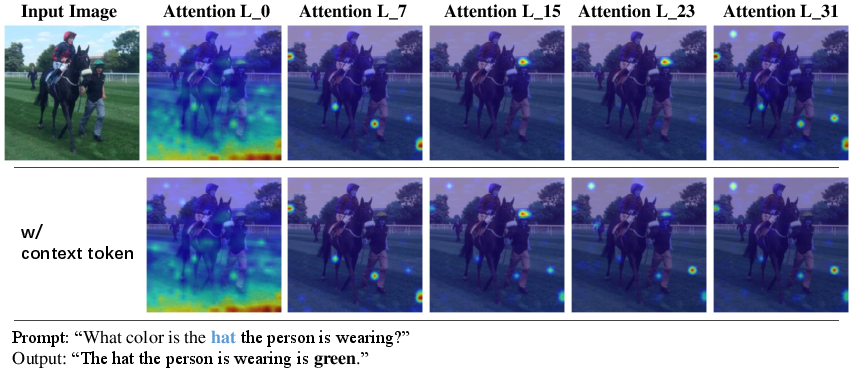
- Attention maps: Inside these AI models, “attention” is like a spotlight showing which parts of the image the model looks at when reading the text. If you ask about a “hat,” the attention map shows the pixels the model thinks are related to “hat.”
- Visual prompts: These are ways for you to point to a region. ControlMLLM++ supports different types:
- Bounding boxes (rectangles you draw)
- Masks (highlighted areas)
- Scribbles (rough lines or shapes)
- Points (single clicks)
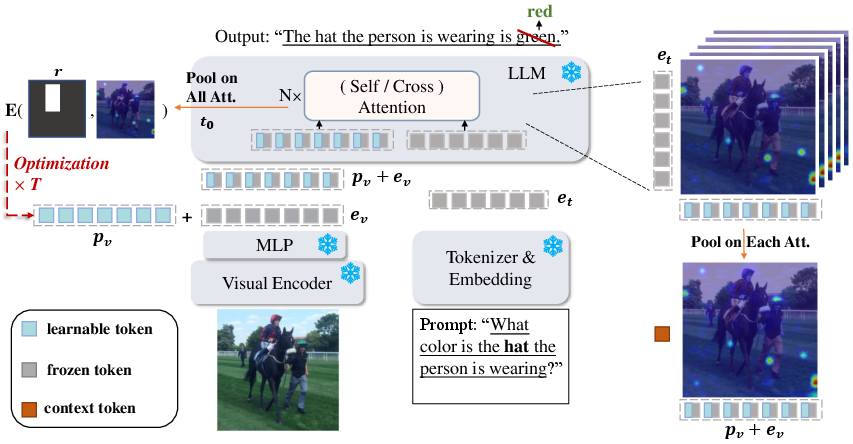
- Latent variable: Imagine adding a tiny “tuner knob” to the image’s internal representation. ControlMLLM++ gently turns this knob during inference (while the model is answering) so the model’s spotlight moves toward the region you specified.
- Energy function: This is a score that checks whether the model’s spotlight (attention) is focused where you want. If the spotlight isn’t on your region, the score pushes the tuner knob to fix it.
Here’s the simple picture: you give the model a prompt (like a box around a sign), and ControlMLLM++ adjusts the model’s internal “focus” so that its attention lights up inside that region. It does this quickly, right as you ask your question, without changing the model’s training.
Two upgrades that make it better
- Optim++: A smarter, faster way to do the tuning. It concentrates on the most important parts of the model (like the first token where the answer starts, and the middle layers where text–image connections are strongest). This makes the focus adjustment quicker and more stable.
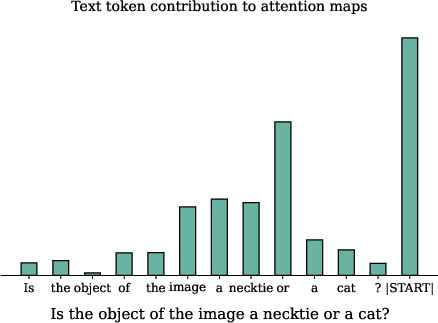
- PromptDebias: Sometimes models trust language too much and ignore the image (this is called “hallucination”). PromptDebias compares outputs with and without the visual prompt and combines them. This reduces language bias, so the model pays more attention to your pointed region rather than guessing from words alone.
What did they find?
ControlMLLM++ delivers accurate, region-specific understanding across many situations:
- It works with boxes, masks, scribbles, and points, giving you flexible ways to point at what matters.
- It improves performance on tasks like:
- Referring object classification: identifying what’s inside the indicated region.
- Reading text in images (OCR): correctly understanding words in a selected area, even when models trained with region data struggle.
- It reduces hallucinations: the model is less likely to “make things up,” because it focuses on the area you provide.
- It generalizes well: it works across different models (like LLaVA and Qwen2.5-VL) and even in new domains it wasn’t trained on (for example, screenshots and signs).
- It doesn’t require retraining: you get region understanding instantly at test time, which saves time and resources.
Why this matters: Many real-world tasks require precise, local understanding—like reading a specific label, describing one person in a crowd, or inspecting a tool in a workshop photo. ControlMLLM++ makes current models better at that without starting from scratch.
What’s the impact?
ControlMLLM++ acts like a plug-in that upgrades existing image+text AIs with fine-grained “point-and-ask” abilities. This can help:
- Developers: Add region-aware reasoning to models quickly, without extra training data.
- Users: Get more accurate answers about exactly what they point to.
- Applications: Improve accessibility (reading signs or labels), education (highlighting parts of diagrams), and safety (inspecting specific areas in technical images).
Overall, the paper shows a practical, training-free way to make multimodal models more controllable, more interpretable (you can see where the model is focusing), and more reliable when answering questions about specific parts of an image.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps and open questions that remain unresolved and could guide future research:
- Attention-as-grounding assumption is unvalidated: the method treats cross-modal attention maps as reliable proxies for semantic grounding, but lacks causal validation (e.g., attention ablation, counterfactual interventions, or gradient-based attribution comparisons) to confirm that attention weights drive outputs rather than correlate with them.
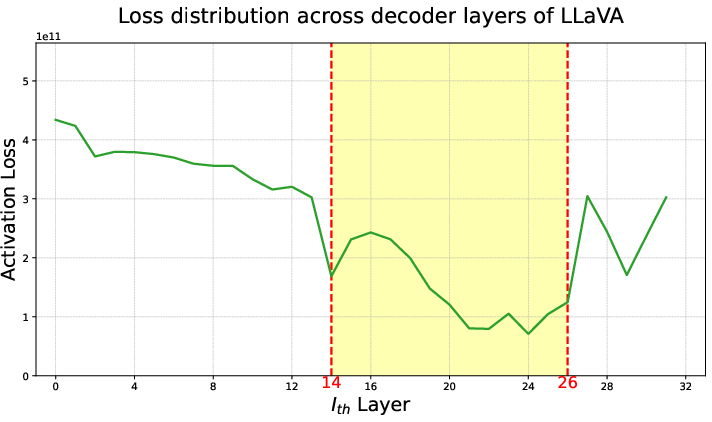
- Layer and token selection is heuristic: Optim++ fixes attention to the “answer-start” token and middle decoder layers (e.g., LLaVA layers 14–26), but provides no principled criterion or adaptive mechanism for selecting tokens/layers across different architectures, prompts, or tasks.
- Highlight token identification deferred: the paper explicitly leaves “optimization based on highlight text tokens” to future work; a concrete method for automatically detecting and weighting semantically pertinent tokens is missing.
- Energy function design is narrow: the mask-based energy maximizes the fraction of attention inside the region but does not penalize attention outside it or incorporate shape/contiguity constraints; alternative objectives (e.g., contrastive inside-vs-outside, sparsity, entropy regularization) are unexplored.
- Sensitivity to hyperparameters is under-characterized: key settings (T, α, β, lr, γ, σ) visibly impact convergence, stability, and accuracy, but comprehensive sensitivity analyses and guidelines for robust defaults across models/domains are lacking.
- Scribble/point soft mask is scale-dependent: the Gaussian distance-transform with fixed σ=0.1 may be resolution- and token-grid dependent; the impact of image size, patch size, and tokenization granularity on soft-mask efficacy is not evaluated.
- Test-time optimization restricted to the 0-th step: optimization only at the first decoding step is justified qualitatively; a systematic study of multi-step or per-token optimization trade-offs (control vs. language fluency) is missing.
- Failure modes when attention misaligns: no analysis of cases where attention maps do not correspond to the intended region (e.g., clutter, occlusion, highly similar distractors), nor mitigation strategies when steering fails or diverges.
- Multi-region and compositional referring is unsupported: the framework assumes a single referred region; handling multiple regions, logical relations (e.g., “left of X, right of Y”), temporal references, or sequential constraints remains open.
- Robustness to imperfect prompts is untested: tolerance to noisy, partial, or adversarial visual prompts (e.g., off-by-one bounding boxes, scribbles overlapping multiple objects) and contradictory text-visual instructions has not been quantified.
- Hallucination mitigation lacks quantitative evaluation: PromptDebias effects are shown qualitatively; standardized benchmarks (e.g., POPE, Object HalBench, MM-hallu) and metrics for hallucination reduction are not reported.
- PromptDebias efficiency and decoding interactions: contrastive decoding requires dual condition evaluations (with/without visual prompt); its compatibility with common decoding strategies (beam search, nucleus sampling) and more efficient variants is unexamined.
- Generalization across architectures is limited: results cover LLaVA-1.5, LLaVA-HR, and Qwen2.5-VL; applicability to other MLLMs with different connectors/attention designs (e.g., Flamingo-like cross-attenders, mixture-of-experts, multi-image encoders) and closed-source APIs is unknown.
- Requirement for gradient access limits deployment: the approach needs backpropagation through the MLLM at inference, which is infeasible for many production settings (quantized inference-only systems, closed-source models); alternatives for gradient-free control are not explored.
- Mapping from pixels to tokens is coarse and under-specified: region-to-token alignment depends on the visual encoder’s patching and connector; how token granularity, stride, and connector transformations affect controllability and precision is not studied.
- High-resolution and dense text scenarios: while LLaVA-HR shows gains on RTC, systematic evaluation of ultra-high-resolution inputs, small objects, dense text (documents, UI screens), and token-grid scalability is missing.
- Out-of-domain coverage remains narrow: evaluation uses LVIS ROC, COCO-Text RTC, RefCOCOg, and Screenshot; broader domain shifts (medical, satellite, charts/plots, diagrams, egocentric views) and multilingual text are not tested.
- Comparative baselines are limited for training-free control: beyond blur and color prompts, stronger training-free baselines (cropping, regional masking, CLIP-guided reweighting, adapter-free connector tricks) are not comprehensively compared.
- Impact on language capabilities is weakly quantified: claims that large η or aggressive control harm language fluency are anecdotal; comprehensive metrics (e.g., perplexity, response coherence, factuality) under controlled conditions are missing.
- Memory and latency overhead trade-offs: measured overhead (especially with PromptDebias) is significant on a 4090 GPU; evaluation on resource-constrained environments (mobile/edge) and batching strategies is absent.
- Safety and alignment implications: test-time steering could be exploited to bypass safety filters or induce targeted content; interactions with alignment mechanisms and defenses (prompt injection, jailbreak resilience) are not addressed.
- Conversational and multi-turn effects: how the optimized latent variable influences subsequent turns, reference carryover, and dialogue context (e.g., dynamic region changes across turns) is not evaluated.
- Video and temporal grounding are out-of-scope: extension to video frames, spatiotemporal regions, and motion-aware attention steering is uninvestigated.
- Multi-modal prompts beyond vision are unsupported: incorporation of audio regions, depth, segmentation hierarchies, or 3D spatial prompts is unexplored.
- Calibration and confidence reporting: the framework provides no confidence scores or failure detection when optimization does not improve grounding; criteria for early termination or fallback behavior are not defined.
- Automatic layer/token weighting: a learned or meta-optimized scheme to weight attention layers/tokens per input/task could improve stability/performance; the current averaging and fixed selection are ad hoc.
- Region-negative guidance: mechanisms to explicitly suppress attention to non-referred regions (e.g., distractors) or handle exclusion prompts (“describe everything except the region”) are not considered.
- Evaluation on more complex tasks: counting, relational reasoning, referential ambiguity resolution, and referring expression comprehension with compositional modifiers are minimally covered and need targeted benchmarks.
- Reproducibility details: exact implementation choices (connector variants, token-grid mapping, scaling of masks to token indices) and standardized settings across models are insufficiently documented for easy replication.
- Theoretical guarantees and convergence: no analysis of optimization convergence, stability conditions, or bounds on attention steering efficacy; theoretical properties of the energy landscape and optimizer dynamics remain open.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be built today using ControlMLLM++ as a test-time, training-free plug-in on open-source MLLMs (e.g., LLaVA, LLaVA-HR, Qwen2.5-VL).
- Region-grounded document AI and OCR
- Sector: software, finance, operations, government
- What: Read or verify only the user-selected field on forms, invoices, receipts, checks, and contracts; disambiguate similar-looking text blocks with box/mask/point prompts; contrastive decoding (PromptDebias) reduces prompt-induced OCR errors.
- Tools/workflow: “Region-Ask” API for images/PDF pages; browser extension to draw a box on a PDF/screenshot and query; back-office invoice validation workflow where an operator highlights the total/PO number to extract/verify.
- Assumptions/dependencies: Requires gradient access to the base MLLM and GPU memory (~13–21 GB for 7B-scale with PromptDebias); better on high-res inputs (LLaVA-HR shows strong gains); latency increases 2–3× when PromptDebias is enabled.
- UI and screen understanding for RPA and QA
- Sector: software, enterprise automation, IT
- What: Robustly query specific UI elements on screenshots (e.g., “What is the status of this job?”) by drawing a box or point; use Optim++ to stabilize referring to small widgets; out-of-domain generalization demonstrated on Screenshot-like tasks.
- Tools/workflow: RPA agent step that captures a screenshot, locates an element via heuristic/locator, then uses ControlMLLM++ to ground and read/describe it; QA teams annotate UI regions to check labels/state.
- Assumptions/dependencies: Access to attention maps and decoding loop; UI changes/layouts still require good visual tokenization; latency may affect real-time RPA loops.
- E-commerce product listing and shelf intelligence
- Sector: retail, supply chain
- What: Extract attributes from specific parts of product photos (logos, size markers, material tags); read shelf price tags or promo labels on retail photos by pointing/scribbling.
- Tools/workflow: Worker highlights the relevant patch; pipeline returns extracted text/attribute with an explanation heatmap to audit.
- Assumptions/dependencies: Illumination/occlusion sensitivity; for very small text, high-resolution encoders help; occasional SAM integration for precise masks adds compute.
- Visual inspection and defect triage
- Sector: manufacturing, logistics
- What: Inspect a referred region of a product/photo for scratches, misalignment, broken seals; ask: “Is the highlighted area a dent or a reflection?”
- Tools/workflow: Operator circles a suspected defect; model describes/labels the ROI and provides grounded rationale via attention maps.
- Assumptions/dependencies: Not a metrology tool; requires calibrated imaging for critical tolerances; domain shift may require human-in-the-loop verification.
- Accessibility: targeted descriptions for low-vision users
- Sector: healthcare, accessibility, consumer apps
- What: Users can tap/draw on an image to receive a focused description (e.g., “What does this label say?”).
- Tools/workflow: Mobile app captures image, uploads to a server-side ControlMLLM++ service; returns grounded answer with reduced hallucinations via PromptDebias.
- Assumptions/dependencies: Cloud inference likely (device GPUs insufficient); careful UI for reliable pointing; privacy controls needed.
- Education and tutoring on diagrams/figures
- Sector: education, publishing
- What: Students/teachers point to a region in a chart, map, or anatomy diagram and ask for explanation or comparison locally (“Explain the highlighted organ’s function”).
- Tools/workflow: LMS plugin enabling region-select queries on images; classroom whiteboard capture with ROIs.
- Assumptions/dependencies: Base model’s subject matter knowledge bounds correctness; verify for exams/assessments.
- Safer, auditable content moderation
- Sector: trust & safety, social media
- What: Human moderators point to questionable content inside an image (e.g., insignia, gesture, text) and ask for targeted classification/description; region grounding reduces off-target hallucinations.
- Tools/workflow: Review dashboard with brush/box tool; returns ROI-focused label and attention overlay for audit.
- Assumptions/dependencies: Policy alignment still required; sensitive content may need ensembles; logs retained for compliance.
- Dataset bootstrapping and annotation acceleration
- Sector: academia, ML ops
- What: Use scribble/point to generate ROI-grounded captions, attributes, or OCR labels; increase label throughput for region-text datasets without model retraining.
- Tools/workflow: Labeling tool integrates ControlMLLM++ to propose region-specific captions/attributes; human validates.
- Assumptions/dependencies: Quality varies with base MLLM; prompt debiasing reduces but doesn’t eliminate biases; still needs human QA.
- Region-aware copywriting and creative workflows
- Sector: marketing, media, design
- What: Generate alt text or creative copy tied to a product area in an image; “Write a caption describing only this logo/texture.”
- Tools/workflow: Design tools extension with box/mask input; export region-grounded descriptions for DAM/SEO.
- Assumptions/dependencies: Creative fidelity bounded by model priors; brand compliance remains a human process.
- Targeted privacy workflows
- Sector: legal, compliance, enterprise IT
- What: Process only selected regions (e.g., redact outside ROI, then analyze ROI) to minimize exposure and focus inference on permitted content.
- Tools/workflow: Preprocessing step to blur/redact background (noted to improve some metrics) before ControlMLLM++.
- Assumptions/dependencies: Full image may still be needed for embedding alignment; confirm policy acceptability of any transient unredacted handling.
Long-Term Applications
These applications are promising but need further research, optimization, or integration work (e.g., lighter inference, closed-model compatibility, regulatory validation).
- Real-time human–robot interaction via pointing and gaze
- Sector: robotics, industrial automation, service robots
- What: Operators point/scribble on a live view; robot grounds commands to the referred object (“Pick this,” “Inspect that bolt”).
- Needed advances: Lower-latency optimization, video-stream extensions, stable token–pixel mapping under motion, safety certification.
- Region-grounded multimodal agents for UI automation
- Sector: enterprise software, productivity
- What: Autonomous agents that robustly operate complex apps by grounding instructions to UI regions across unseen layouts/domains.
- Needed advances: Tighter coupling with detectors/trackers; cross-app memory; fallback heuristics; better hallucination controls and audits.
- Clinical decision support with clinician-drawn ROIs
- Sector: healthcare
- What: Radiologists/pathologists scribble ROIs to request differential descriptions (“Describe calcifications here”).
- Needed advances: Medical-grade validation, bias assessment, domain-specific base models, regulatory clearance; ensure no reliance as a diagnostic device.
- AR assistants for field work and technical support
- Sector: energy, utilities, manufacturing, automotive
- What: AR glasses with ROI pointing/voice to retrieve procedures or interpret gauges/labels in situ.
- Needed advances: On-device or edge inference optimization, robust high-res tokenization, occlusion handling, offline modes.
- Region-guided content editing and controllable generation bridges
- Sector: creative tools, media
- What: Use referring prompts to precisely drive region-aware captioning-to-edit pipelines (e.g., hand off ROI semantics to diffusion models).
- Needed advances: Unified interfaces between MLLMs and T2I models; consistent cross-model attention control; latency reduction.
- Privacy-preserving, ROI-first processing pipelines
- Sector: policy, legal tech, privacy engineering
- What: Architectures that extract and process only ROI features client-side, transmitting minimal data to servers.
- Needed advances: Feature-space ROI slicing with secure enclaves; provable privacy guarantees; standardized ROI metadata.
- Standardized region reasoning benchmarks, audits, and policy guidance
- Sector: policy, standards, academia
- What: Sector-specific tests (finance forms, safety labels, signage) and audit protocols for region-grounded reliability and hallucination rates.
- Needed advances: Broad benchmark curation, agreement on ROI-grounding metrics, sector adoption and governance frameworks.
- Video-level region reasoning
- Sector: media analytics, surveillance, sports, education
- What: Temporal ROI prompts (track and reason over a moving region: “Describe the player I highlighted over the next 5 seconds”).
- Needed advances: Efficient temporal attention steering, token tracking across frames, compute scaling.
- Engineering/CAD copilots with precise ROI grounding
- Sector: AEC, manufacturing design
- What: Point to a subsystem in CAD/renders to query specifications, constraints, or failure modes.
- Needed advances: Domain-specific visual encoders, 3D-to-token mappings, enterprise data integration.
- Automotive in-cabin copilots and V2X explanation
- Sector: mobility
- What: Occupants point and ask about external objects; the system grounds and explains traffic signs/objects.
- Needed advances: Real-time performance, safety-grade reliability, multimodal fusion with sensors, driver-distraction safeguards.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Model access: Requires backprop through attention and logits; not supported by closed APIs (e.g., most hosted MLLMs). Best suited to open weights (LLaVA, Qwen2.5-VL).
- Compute: Additional latency and memory (notably with PromptDebias). Early stopping and Optim++ help, but edge/mobile deployment needs further optimization.
- Architecture: Works with MLLMs that expose cross-attention over visual tokens and token-to-pixel mappings; performance varies with encoder resolution.
- Prompting modality: Boxes/masks generally strongest; scribbles/points may need SAM or distance-transform heuristics; SAM adds extra inference cost.
- Safety/compliance: While PromptDebias mitigates bias/hallucination, human oversight remains essential, especially in regulated domains.
- Domain shift: Robust but not guaranteed; careful validation per domain is required before high-stakes use.
- Integration: Requires hooking into the decoding loop and attention layers; some frameworks sandbox or disable gradient computation in production.
Glossary
- Adam optimizer: An adaptive gradient-based optimization algorithm that estimates first and second moments of gradients to stabilize and speed up convergence. "we replace the previous Gradient Descent, EMA, and Early Stopping strategies with the Adam optimizer"
- answer-start token: A special token marking the beginning of the model’s answer sequence, used to focus attention during initial decoding. "the attention is focused on the answer-start token"
- attention mechanism: The transformer component that computes relevance among tokens via learned query-key interactions. "The core of the transformer-based decoder is the attention mechanism"
- autoregressive: A generation process where each token is produced conditioned on previously generated tokens. "autoregressively as"
- BLEU@4 (B@4): A text-generation metric based on modified n-gram precision up to 4-grams. "BLEU@4~(B@4)"
- CIDEr (C): A captioning metric using TF–IDF-weighted n-grams to measure consensus with human references. "CIDEr (C)"
- contrastive decoding: A decoding method that combines logits from different conditions to reduce bias and improve grounding. "a contrastive decoding strategy"
- cross-attention matrix: The matrix of attention weights from query (text/decoder) tokens to key (visual) tokens across modalities. "the cross-attention matrix is computed as"
- cross-modal attention maps: Attention visualizations linking textual tokens to visual regions that encode semantic correspondences. "cross-modal attention maps intrinsically encode semantic correspondences between textual tokens and visual regions"
- decoder layers: Stacked transformer blocks that perform the generative decoding operations in an LLM. "The loss distribution across decoder layers"
- distance transform: An image operation that computes, for each pixel, its distance to the nearest foreground point or scribble. "distanceTransform function"
- Early Stopping (ES): An optimization control technique that halts updates when performance stops improving to prevent overfitting. "Early Stopping (ES)"
- energy function: An objective crafted to steer optimization (e.g., attention focus) toward desired regions given prompts. "a task-specific energy function"
- Exponential Moving Average (EMA): A smoothing technique applying exponentially decayed weights to stabilize optimization or parameter trajectories. "Exponential Moving Average (EMA)"
- hard mask-based energy function: An energy formulation that uses a binary region mask to guide attention concentration in referred areas. "Hard Mask-based Energy Function"
- LayerSelection: A strategy restricting optimization to selected (often middle) decoder layers where text–visual attention is strongest. "LayerSelection"
- latent variable: A hidden, learnable modifier appended to visual token embeddings and optimized at inference to influence attention. "learnable latent variable"
- learnable visual prompts: Trainable prompt vectors injected into visual tokens to guide region-level reasoning without retraining the model. "learnable visual prompts"
- METEOR (M): A text-generation metric combining precision, recall, and alignment via stemming and synonym matching. "METEOR (M)"
- multimodal hallucination: The phenomenon where a model outputs content unsupported by visual input due to overreliance on linguistic priors. "multimodal hallucination"
- Multimodal LLMs (MLLMs): LLMs that integrate image and text inputs for joint understanding and generation. "Multimodal LLMs (MLLMs) integrate image and text inputs to perform joint understanding and generation"
- Optim++: An enhanced optimization strategy that focuses on answer-start token attention in middle layers and uses Adam for stability. "Optim++"
- out-of-domain generalization: The ability of a model to perform robustly on data distributions different from those seen in development. "strong out-of-domain generalization"
- PromptDebias: A contrastive decoding mechanism that mitigates prompt language bias by combining logits with and without visual prompts. "PromptDebias"
- RefCOCOg: A dataset for referring expressions and grounding used to evaluate region-level description quality. "RefCOCOg"
- Referring Description: The task of generating natural-language descriptions grounded to a user-specified image region. "Referring Description performance on RefCOCOg and Screenshot datasets"
- Referring MLLMs: Multimodal LLMs extended to condition on visual prompts (boxes, masks, points, scribbles) for region-level grounding. "Referring MLLMs aim to extend an MLLM’s output conditioning to incorporate visual referring prompts"
- Referring Object Classification (ROC): A task evaluating whether the model correctly identifies the object category within a referred region. "Referring Object Classification~(ROC) task"
- Referring Text Classification (RTC): A task assessing whether the model can correctly read/classify text content within a referred region. "Referring Text Classification~(RTC) task"
- SAM (Segment Anything Model): A segmentation model that produces masks from prompts like points or scribbles to define regions. "SAM"
- Screenshot dataset: An out-of-domain dataset of GUI screenshots used to evaluate referring description generalization. "RefCOCOg and Screenshot datasets"
- soft mask-based energy function: An energy formulation that applies a distance-weighted (e.g., Gaussian) soft mask around points/scribbles to guide attention. "Soft Mask-based Energy Function"
- SPICE (S): A captioning metric assessing semantic propositional content via scene-graph comparisons. "SPICE (S)"
- test-time adaptation: Adjusting model behavior during inference via optimization without retraining or fine-tuning. "a test-time adaptation framework"
- test-time computing: Performing optimization or control procedures at inference to adapt models to new prompts or domains. "test-time computing method"
- test-time prompt tuning: Optimizing prompt-related parameters during inference on a single sample to adapt model behavior. "a test-time prompt tuning strategy"
- vision-language connector: The module mapping visual encoder outputs into embeddings compatible with the LLM input space. "vision-language connector"
- visual instruction tuning: Fine-tuning on image–text pairs and conversational data to enhance visual dialogue capability. "fine-tuned through visual instruction tuning"
- visual tokens: The embeddings produced by the visual encoder that represent image content in the LLM’s input space. "visual tokens"
Collections
Sign up for free to add this paper to one or more collections.