- The paper introduces Maestro, a self-improving T2I system that iteratively refines prompts using a multi-agent orchestration framework.
- It employs a pairwise comparator and intent grounding to ensure high-quality images and adherence to user intent.
- Experimental results demonstrate superior DSGScores and human preference alignment compared to existing automated prompt optimization methods.
Maestro: Self-Improving Text-to-Image Generation via Agent Orchestration
Overview and Motivation
The paper introduces "Maestro" (referred to as black), a self-improving agentic framework for text-to-image (T2I) generation that autonomously refines prompts and images through orchestrated interactions between multimodal LLM (MLLM) agents and black-box T2I models. The motivation stems from the persistent challenge of prompt sensitivity and under-specification in T2I systems, which often necessitate labor-intensive, iterative prompt engineering by users. Existing automated prompt optimization (APO) methods either rely on large-scale supervised training or test-time optimization with limited feedback mechanisms, both of which struggle to generalize and fully leverage the multimodal reasoning capabilities of modern LLMs.
System Architecture and Workflow
Maestro is designed as a multi-agent system that operates in a test-time optimization regime, requiring only the initial user prompt. The pipeline consists of several key stages:
- Initialization: The user prompt is rewritten using a text-LLM guided by prompt engineering best practices, yielding a more descriptive initial prompt. Simultaneously, the prompt is decomposed into a set of decomposed visual questions (DVQs) via LLM, which probe specific properties implied by the prompt.
- Iterative Generation and Evaluation: At each iteration, the current prompt is used to generate an image via the T2I model. The image is evaluated against the DVQs using an MLLM, producing interpretable feedback.
- Multi-Agent Critique and Proposal: Two complementary prompt generators are invoked:
- Targeted Editing: Identifies DVQs where the image fails, rationalizes the failure, and proposes prompt edits to address specific deficiencies.
- Implicit Improvement: Holistically critiques the image and prompt, proposing general improvements unconstrained by DVQs.
- Pairwise Comparator: A binary tournament is conducted between the newly generated image and the incumbent best image using an MLLM-as-a-judge, optimizing directly for pairwise preference rather than scalar reward.
- Intent Grounding: A self-verification agent ensures that prompt edits remain faithful to the user's original intent by checking for violations against DVQs and correcting as needed.
- Termination: The process repeats until a budget or patience criterion is met, returning the best prompt-image pair.
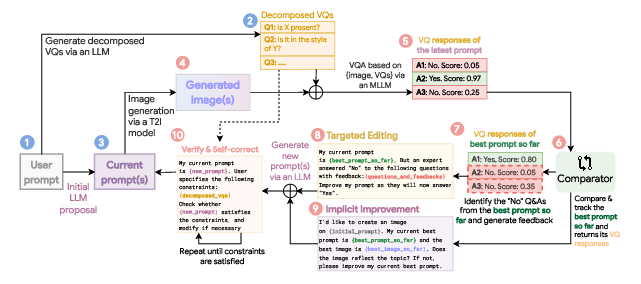
Figure 1: The overall pipeline of Maestro, illustrating initialization, iterative generation, multi-agent critique, pairwise comparison, and intent grounding.
Technical Innovations
Multi-Agent Critique
Unlike prior works that use MLLMs as reward models producing scalar scores, Maestro leverages the full multimodal reasoning capacity of MLLMs to generate interpretable, targeted edit signals. The system distinguishes between explicit, property-driven feedback (via DVQs) and holistic, implicit improvements, enabling nuanced prompt refinement.
Pairwise Objective
Maestro eschews pointwise objectives in favor of direct pairwise comparison, aligning with RLHF/RLAIF paradigms but without intermediate reward model approximation. The binary tournament mechanism robustly tracks the best candidate, mitigating position bias through repeated, randomized judge queries.
Intent Grounding
The self-verification module regularizes the iterative editing process, preventing semantic drift and ensuring that prompt modifications do not violate core user constraints. This is achieved by iteratively checking and correcting prompt proposals against DVQs.
Experimental Results
Quantitative Evaluation
Maestro was evaluated on challenging subsets of the PartiPrompts and DSG-1K datasets using the Imagen 3 T2I model. The evaluation employed both automatic metrics (DSGScore, AutoSxS pairwise comparison) and human preference studies.
- DSGScore: Maestro achieved the highest mean DSGScore (0.921 ± 0.10 on p2-hard, 0.882 ± 0.13 on DSG-1K), outperforming all baselines, including OPT2I which directly optimizes for DSGScore.
- Pairwise Win Rate: Maestro consistently demonstrated superior win rates in AutoSxS evaluations, with distributions strongly favoring its generations over baselines.
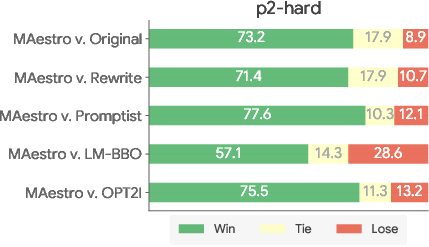
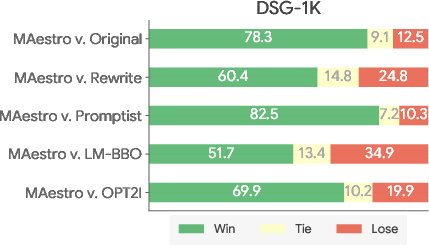
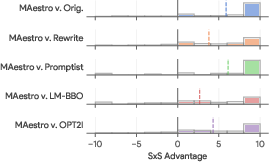
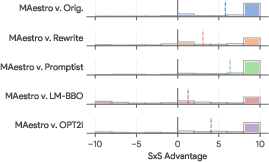
Figure 2: AutoSxS evaluation results showing Maestro's win-tie-lose breakdown and advantage distribution over baselines on p2-hard and DSG-1K.
Ablation Studies
Component-wise ablations revealed that each module—initial rewriting, iterative improvement, pairwise comparator, and self-verification—contributed positively to performance. The full system (V+P+I+R) outperformed variants lacking self-verification or pairwise tracking.
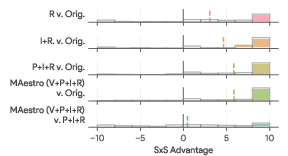
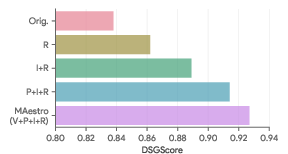
Figure 3: Ablation studies demonstrating the impact of each algorithmic component on pairwise advantage and DSGScore.
Human Preference Alignment
Human evaluators preferred Maestro's generations over the next best method (LM-BBO), with aggregated results closely matching automatic side-by-side comparisons, validating the system's alignment with human perceptual judgments.
Model-Agnostic and Scalable Design
Experiments with different judge and optimizer models (Gemini 1.5, Gemini 2.0) confirmed that Maestro's effectiveness scales with the capabilities of its MLLM components, and its model-agnostic design enables seamless integration with future T2I and LLM advances.

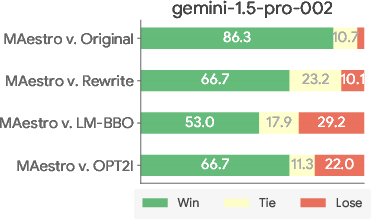

Figure 4: AutoSxS win-tie-lose breakdown using different judge models, illustrating robustness to judge selection.

Figure 5: AutoSxS win-tie-lose breakdown using different optimizer models, showing improved performance with stronger MLLMs.
Qualitative Analysis
Qualitative trajectories demonstrate Maestro's ability to address underspecification, domain-specific concepts, and nuanced aesthetic requirements. The system refines images by enriching prompts with concrete details, correcting failures, and enhancing overall coherence and fidelity to user intent.
Implementation Considerations
- Computational Requirements: Maestro incurs higher test-time compute due to iterative T2I and MLLM calls, but this is offset by improved sample efficiency and elimination of large-scale training data requirements.
- Scalability: The framework is compatible with any black-box T2I and MLLM, facilitating rapid adoption of new models.
- Deployment: Maestro can be deployed as a cloud-based service, leveraging API access to T2I and LLM endpoints. Early stopping and patience criteria allow for resource management.
Implications and Future Directions
Maestro advances the state-of-the-art in automated T2I prompt optimization by integrating interpretable multi-agent critique and robust pairwise evaluation. The framework's model-agnostic, test-time design enables continual improvement as foundation models evolve. The principles underlying Maestro—multi-agent orchestration, pairwise preference optimization, and intent grounding—are broadly applicable to other generative modalities (e.g., audio, video) and tasks lacking objective ground truths.
Potential future developments include:
- Extending Maestro to other generative domains.
- Incorporating improvement trajectories into T2I model training for autonomous self-improvement.
- Exploring more sophisticated agent architectures and feedback mechanisms.
Conclusion
Maestro presents a robust, interpretable, and effective pathway for self-improving T2I generation, leveraging multi-agent orchestration and pairwise MLLM-as-a-judge objectives. The system demonstrates strong empirical gains over existing methods, with performance scaling alongside advances in multimodal foundation models. Its design principles offer a blueprint for future research in agentic, self-improving generative AI systems.