Video-as-Answer: Predict and Generate Next Video Event with Joint-GRPO
Abstract: While LLMs have become impactful in many real-world applications, video generation remains largely confined to entertainment. Motivated by video's inherent capacity to demonstrate physical-world information that is difficult to convey through language alone (e.g., imagine teaching someone to tie a tie using only text), we identify an underutilized opportunity to extend video as a new answer modality for Next-Event Prediction (NEP), formalized as Video-Next-Event Prediction (VNEP). While the established NEP task takes a video with a procedural or predictive question as input to predict the next event in text, VNEP requires dynamic video responses. This shift from telling to showing unlocks more intuitive and customized answers for procedural learning and creative exploration. However, this task remains challenging for existing models, as it demands an understanding of multimodal input, instruction-conditioned reasoning, and the generation of video with visual and semantic consistency. To address this, we introduce VANS, a model that leverages reinforcement learning to align a Vision-LLM (VLM) with a Video Diffusion Model (VDM) for VNEP. The core of VANS is our proposed Joint-GRPO that orchestrates the VLM and VDM to function as a unit. Driven by a shared reward on their respective output, it optimizes the VLM to produce captions that are both accurate and friendly to visualize, while guiding the VDM to generate videos that are faithful to these captions and the input visual context. To enable this learning, we craft VANS-Data-100K, a dedicated dataset for the VNEP task. Experiments on procedural and predictive benchmarks demonstrate that VANS achieves state-of-the-art performance in both video event prediction and visualization. Codes are released in https://github.com/KlingTeam/VANS.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but powerful question: instead of answering video questions with text, what if we answered with a new video? The authors introduce a task called Video-Next-Event Prediction (VNEP). Given a short input video and a question like “What happens next?” the system should make a short video that shows the next step. They build a system called VANS that can understand the current video, decide what should happen next, and then generate a new video that matches that plan.
Key Objectives and Questions
To make this idea work, the paper focuses on three goals:
- Can we move from “telling” (text answers) to “showing” (video answers) for next-event prediction?
- Can we align two different AI skills—understanding and planning (language + vision) and video generation—so they work smoothly together?
- Can we train this system so the generated video is both correct (matches the plan) and consistent (looks like a believable continuation of the input)?
Methods and Approach (Explained Simply)
The big idea: Use video as the answer
Text can be unclear for step-by-step tasks (like tying a tie or cooking). A video can show motion, timing, and spatial details much better. So the authors define VNEP: take an input video and a question, and generate a new video that demonstrates the next event.
Two specialists working together
Think of the system as a two-person team:
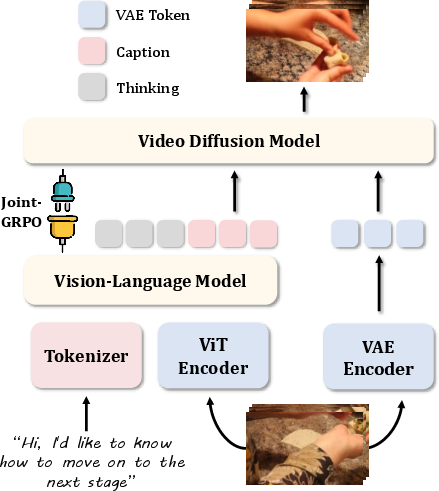
- The “Writer” (a Vision-LLM, or VLM) watches the input video and reads the question, then writes a clear caption describing what should happen next.
- The “Filmmaker” (a Video Diffusion Model, or VDM) takes that caption and actually creates the new video.
Analogy: The Writer drafts the scene description; the Filmmaker shoots the scene to match it.
The problem: Miscommunication
If the Writer describes something that’s hard to film (too vague, not visually realistic), the Filmmaker can’t make a good video. And if the Filmmaker ignores the Writer’s description, the video won’t match the plan. This “semantic-to-visual gap” is the main challenge.
The solution: Train them with joint scores (Joint-GRPO)
They use a training method similar to coaching with scorecards:
- Reinforcement learning (RL) = practice rounds where the model gets points for good behavior and learns from them.
- Joint-GRPO = a way to give both the Writer and Filmmaker shared feedback so they become a good team.
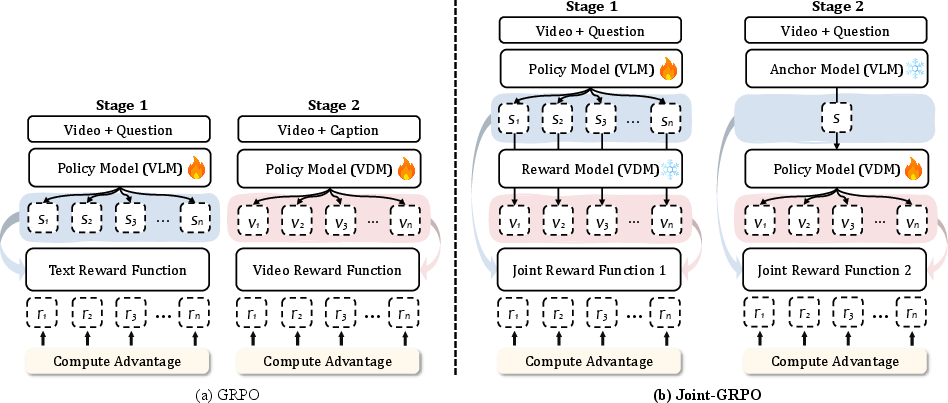
It happens in two stages:
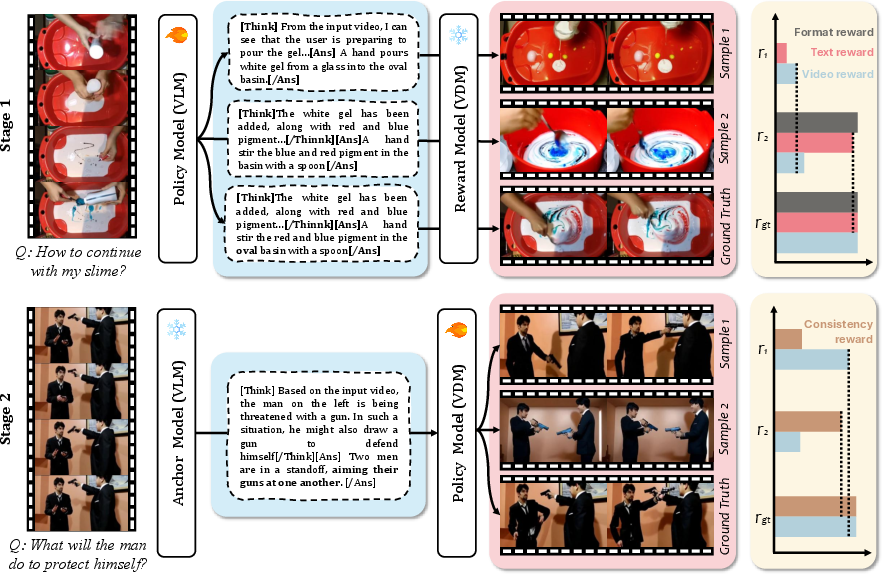
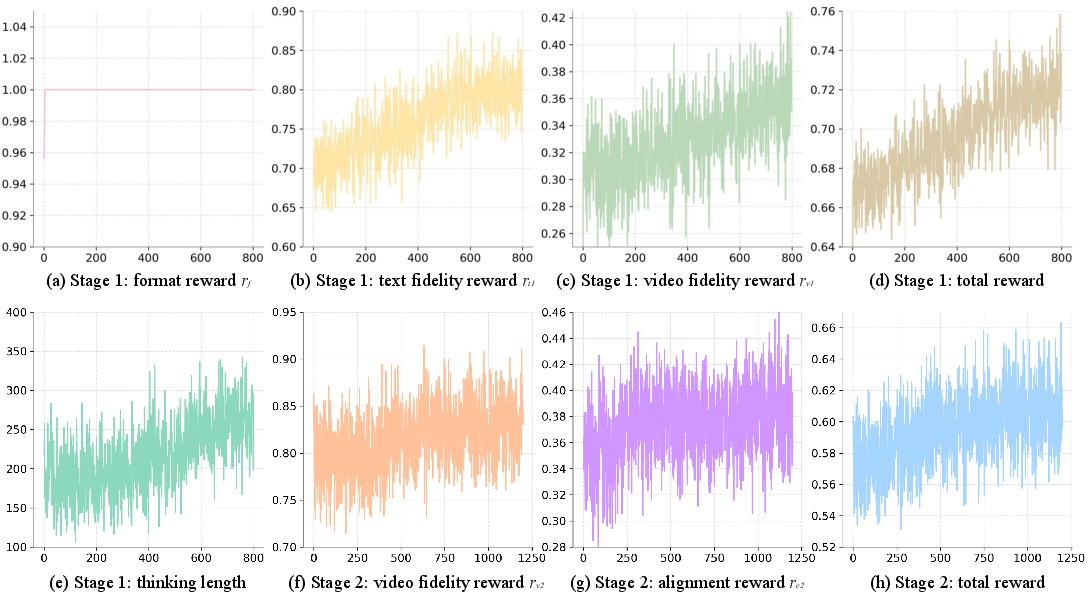
- Stage 1: Coach the Writer
- The Writer gets points for:
- Following the answer format (think first, then answer).
- Having text that’s close to the ground-truth description (text fidelity).
- Being easy to visualize—does the resulting video (from training data) match the caption well (video fidelity)?
- This teaches the Writer to produce captions that are both correct and “shootable.”
- The Writer gets points for:
- Stage 2: Coach the Filmmaker
- The Writer is now “fixed” and provides solid captions.
- The Filmmaker gets points for:
- Video quality and consistency with the input (video fidelity).
- Matching the Writer’s caption (semantic alignment).
- This teaches the Filmmaker to make videos that follow the plan and look like a believable continuation of the original video (same characters, setting, etc.).
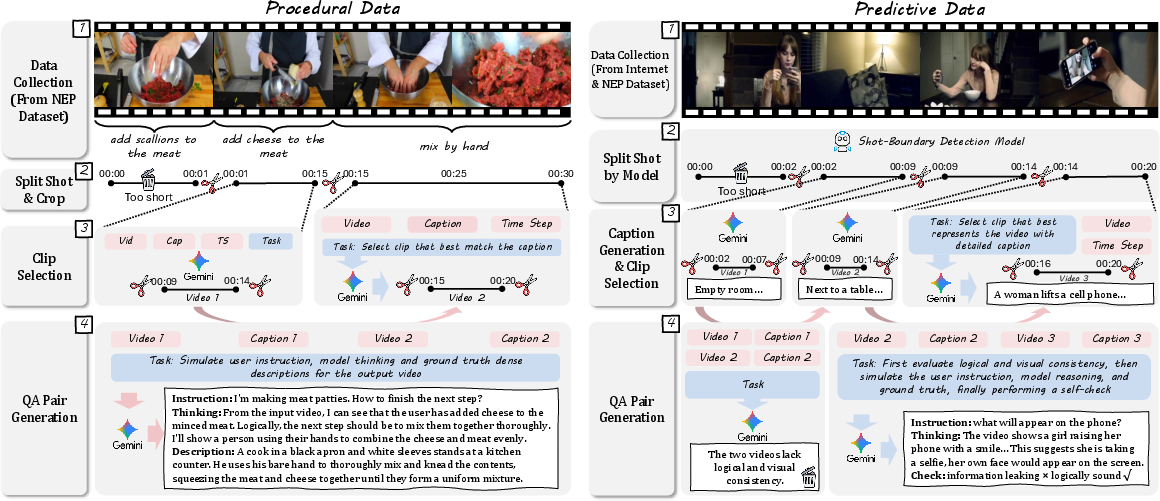
The training data: VANS-Data-100K
They built a new dataset with 100,000 examples. Each example includes:
- An input video
- A question
- An answer that includes both text and an output video This gives the system lots of practice on both procedural tasks (step-by-step actions) and predictive tasks (guessing what likely happens next).
Main Findings and Why They Matter
- VANS beats strong baselines across both types of tasks. In simple terms:
- It predicts the next event more accurately than other methods that only use text or don’t align understanding with generation.
- It generates videos that look better and fit the plan more closely.
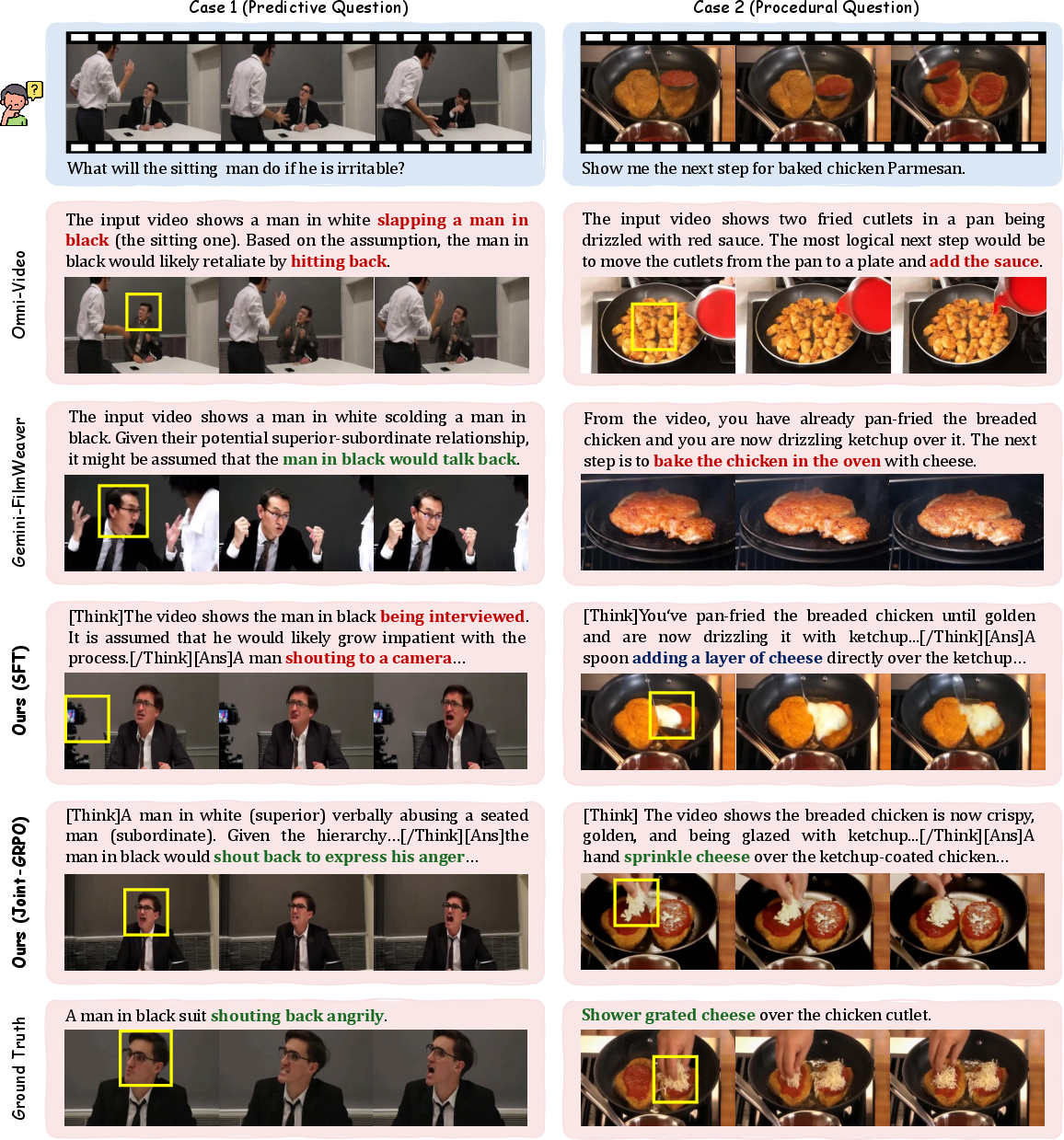
- The system avoids common mistakes:
- It reduces “semantic errors” (like describing the wrong action).
- It reduces “visual errors” (like changing a character’s appearance or ignoring the scene).
- The two-stage training (Joint-GRPO) is crucial:
- Training only the Writer or only the Filmmaker is not enough.
- Training both at once without structure gets unstable.
- The staged approach with joint rewards gives stable, clear improvements.
Implications and Potential Impact
- Better teaching and learning: Imagine getting a custom video showing your exact next step based on your current setup—tying a tie, fixing a bike, or finishing a recipe. It’s clearer than reading instructions.
- More natural help: Video answers could make AI assistants more intuitive by showing you what to do, not just telling you.
- Stronger creativity and planning: The system doesn’t just continue a video; it reasons about what should happen next and visualizes it.
- Beyond entertainment: Video generation can serve education, training, and everyday help—not just make cool clips.
In short, this paper shows how to make AI “show” rather than just “tell,” and how to train two different AI skills to work together so the video answers are both smart and believable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that are either missing, uncertain, or left unexplored in the paper. These points are phrased to be concrete and actionable for future research.
- Task formalization and benchmarks
- Lack of a standardized, public VNEP benchmark with fixed splits and protocols; VANS-Data-100K is introduced but its train/validation/test splits, licensing status, and public availability details are unclear.
- No task-specific metrics that directly assess procedural usefulness (e.g., task completion by humans following the video answer); current metrics are mostly proxy-based (FVD, CLIPScore, BLEU/ROUGE).
- Absence of formal evaluation for multi-future prediction (only qualitative demos); no metrics for plausibility/diversity trade-offs or multi-reference evaluation.
- Dataset construction and bias
- Incomplete documentation of QA generation methodology, annotation quality control, and annotator instructions; unclear how questions/answers avoid leakage or overly templated patterns.
- Potential domain and cultural biases given sources (e.g., YouTube, specific public datasets); no analysis of content diversity (domains, activities, environments), language coverage, or demographic representation.
- VNEP is inherently multi-modal in outcomes, yet the dataset appears to provide single ground-truth futures; no handling of multiple valid next events.
- Legal/ethical status of scraped Internet videos (consent, licensing, privacy) not addressed; unclear if redistribution/derivatives are permissible.
- Reward design and alignment
- Rewards rely heavily on CLIP-based similarities (frame-wise CLIP-V/T) and FVD, which are known to be imperfect proxies for semantics, temporal coherence, and human preference; no human-in-the-loop reward or learned reward model is explored.
- No sensitivity analysis of reward coefficients (all λ set to 1); unclear robustness of Joint-GRPO to different weightings or alternative reward components.
- Stage-2 “anchor caption” filtering (ROUGE-L > 0.6) introduces exposure bias; consequences of anchoring errors or low-quality captions are not quantified.
- Reward hacking is discussed qualitatively, but systematic characterization and detection of failure cases (e.g., static frames, trivial motion) is missing.
- Generalization and robustness
- Generalization to out-of-distribution domains (e.g., scientific procedures, sports, medical contexts), longer videos, and high-resolution outputs is not evaluated.
- Robustness to input noise, occlusions, adversarial prompts, camera motion, and visual domain shifts is not studied.
- No cross-lingual experiments; the system’s performance with non-English questions or multilingual captions remains unknown.
- Temporal and physical consistency
- Metrics and analyses do not directly measure temporal coherence (e.g., motion smoothness, long-range identity tracking) or physical plausibility (e.g., causality, object permanence, physics).
- Identity/background preservation and temporal consistency over longer horizons (beyond 33 frames) are not quantitatively assessed.
- Model scalability and design choices
- Sensitivity to the number of reference frames (n=6) and the specific conditioning scheme (VAE token concatenation) is not explored; alternatives (e.g., flow features, cross-attention design variants) are untested.
- Scalability to larger VLMs/VDMs or different backbones is not analyzed; no cross-model ablations to assess portability of Joint-GRPO.
- Computational costs for training (hardware, time, energy) and scalability of Joint-GRPO to larger datasets/longer videos are not reported.
- Optimization and theory
- No theoretical analysis of stability, convergence, or sample efficiency of Joint-GRPO; comparative studies vs. alternative alignment methods (e.g., DPO, RLHF with human preferences, reward modeling) are absent.
- GRPO equations in text contain typographical/formatting errors, which may impede reproducibility; hyperparameter choices (e.g., KL β, clip ranges) lack justification beyond defaults.
- Baselines and comparisons
- Baseline coverage is limited to specific cascaded and unified models; no comparison with recent RL-aligned multimodal systems or reward-model-based alignment approaches.
- Ablations do not test stronger/larger VLM/VDM backbones to isolate the contribution of Joint-GRPO from model capacity gains.
- Human evaluation and user studies
- Human evaluation is small-scale and limited to subjective ratings; lacks task-based studies quantifying whether video answers improve user success on real procedural tasks versus text-only baselines.
- No user-centric measures such as clarity, learnability, or safety of instructions, and no longitudinal studies on learning outcomes.
- Interactivity and multi-step guidance
- The system predicts a single “next event” clip; mechanisms for iteratively guiding a user through multi-step tasks with closed-loop feedback are not developed or evaluated.
- No exploration of online adaptation to user state changes across steps (interactive correction, personalization beyond initial conditioning).
- Safety and responsible deployment
- Safety policies and guardrails for procedure generation (e.g., risky/illegal activities, medical advice) are not discussed.
- No content moderation or controllability mechanisms to prevent harmful or misleading video guidance are described.
- Practical deployment
- Inference constraints (latency, hardware requirements) limit real-time applicability; strategies for acceleration (distillation, caching, streaming) are not investigated.
- The method relies on paired ground-truth “next-event” videos for RL; pathways to deployable training without such targets (e.g., preference data, weak supervision) are unexplored.
- Failure mode taxonomy
- While qualitative failures are shown (e.g., semantic hallucination, action misalignment), a systematic taxonomy with frequency and conditions of occurrence is missing, along with diagnostics for detecting unexecutable captions or misaligned generations.
Practical Applications
Immediate Applications
Below are actionable use cases that can be piloted with the current VANS system (VLM+VDM cascade aligned via Joint-GRPO) and dataset, assuming offline or near-real-time generation (roughly tens of seconds per answer video), access to GPU inference, and curated prompts.
- Procedural help and how-to assistants for consumers
- Sectors: education, consumer software, creator tools
- What it does: Convert a user’s short phone video (e.g., a half-tied tie, a partially assembled IKEA shelf, a step in a recipe) plus a question into a short personalized “what to do next” video answer rather than text.
- Tools/workflows: Mobile app or web widget that ingests a user clip + instruction; returns a 3–5 s video showing the next step; optional caption overlay.
- Assumptions/dependencies: Good lighting and framing; non–safety-critical tasks; disclaimer for potential inaccuracies; acceptable latency (~35 s per video reported); GPU-backed serving.
- Creator productivity: storyboarding and B-roll generation from rough cuts
- Sectors: media/entertainment, marketing, education
- What it does: Given an edited segment and a prompt (“transition to the next step: pour batter into pan”), generate a short, visually coherent continuation shot as a video answer.
- Tools/workflows: NLE plug-in (Premiere/Resolve) or REST API; “video-as-answer” panel to request next shot clips for tutorials, DIY, recipes.
- Assumptions/dependencies: Style matching may require finetuning; content rights management; manual curation loop for quality control.
- Customer support augmentation with visual resolutions
- Sectors: consumer electronics, appliances, automotive aftermarket
- What it does: From a customer-uploaded clip showing a device state (e.g., printer jam exposed, router lights), produce a short video showing the next corrective action (clear jam, hold reset).
- Tools/workflows: Ticketing-system integration; agent co-pilot that requests customer video; returns a generated step demo; links to parts/SOPs.
- Assumptions/dependencies: Limited to low-risk procedures; internal knowledge base for grounding; human-in-the-loop review.
- Training content authoring for SOPs
- Sectors: manufacturing, field service, retail operations
- What it does: Convert existing procedural footage into “next-event” micro-lessons; for each step, VANS generates the next-step demo tailored to a given partial state.
- Tools/workflows: LMS plug-in that indexes SOP videos; step-wise question templates; batch generation of micro-clips; quiz auto-generation from captions.
- Assumptions/dependencies: Domain adaptation with a small finetuning set; internal review for compliance; not for hazardous tasks without validation.
- Academic benchmarks and methods research
- Sectors: academia, AI labs
- What it does: Use VANS-Data-100K and the VNEP task to evaluate multimodal reasoning + generation and RL alignment across modalities (Joint-GRPO).
- Tools/workflows: Open-source code and dataset; evaluation harness with FVD/CLIP metrics; ablations on reward design and staged RL.
- Assumptions/dependencies: Reproducible compute (VDM inference), adherence to data licenses.
- Interactive tutoring in visual domains
- Sectors: K-12 and vocational education
- What it does: In domains like art, cooking, woodwork, and lab demos, students submit short clips and receive a personalized next-step video that respects the current configuration of materials.
- Tools/workflows: Classroom LMS integration; teacher dashboard to approve/curate outputs; rubric-based assessment using ROUGE/CLIP proxies.
- Assumptions/dependencies: Age-appropriate safety filters; school device constraints; offline batch modes for classroom scale.
- Product manuals that “watch and show”
- Sectors: consumer goods, smart home
- What it does: A manual assistant “observes” a user’s setup (video) and generates the next-step demonstration (e.g., “mount bracket, align level, insert screw”).
- Tools/workflows: QR-code on packaging links to assistant; model conditioned on SKU-specific visuals; multilingual captions.
- Assumptions/dependencies: SKU-specific fine-tuning or retrieval; legal disclaimers; latency tolerance by users.
- Research tool for multimodal alignment strategies
- Sectors: AI/ML tooling
- What it does: Repurpose Joint-GRPO as a template to align any reasoning module (text) with a generator (video/audio/3D) via staged joint rewards.
- Tools/workflows: RL training scripts; plug-in reward adapters (ROUGE/CLIP/Task metrics); synthetic datasets for pretraining.
- Assumptions/dependencies: Reward signal quality; reference models for stability; compute budget.
- Accessibility: visualizing instructions for non-native speakers
- Sectors: public services, community education
- What it does: Generate video demonstrations of instructions (e.g., “how to fill this form next”) when textual instructions are a barrier.
- Tools/workflows: Kiosk/web portal that accepts a short clip of the user’s current state; outputs a concise demo; overlays minimal text.
- Assumptions/dependencies: Sensitive data redaction; simple, non-legal tasks; cultural appropriateness.
- Sports coaching micro-feedback
- Sectors: sports, fitness, physio prehab
- What it does: From a short athlete clip, produce a next-step video showing the correction (e.g., “shift weight, rotate hip next”).
- Tools/workflows: Mobile coaching apps; side-by-side playback of user and generated step; capture templates for angles.
- Assumptions/dependencies: Limited biomechanics fidelity; needs coach review; environment and camera angle constraints.
- Insurance claims triage aid
- Sectors: insurance
- What it does: Given a scene of minor damage, generate “next safe steps” demos (e.g., “document panels, move vehicle to safe spot”).
- Tools/workflows: Claims app integration; post-event guidance clips; policy-specific rules conditioning.
- Assumptions/dependencies: Liability and safety disclaimers; rule-based gating; not for emergencies.
- Content moderation training and policy exemplars
- Sectors: platform policy, trust & safety
- What it does: Create short illustrative videos of “what happens next” for policy edge cases (procedural, not depicting harm) to train reviewers.
- Tools/workflows: Internal policy portal; synthetic exemplars for reviewer calibration.
- Assumptions/dependencies: Strict safety filters; no realistic generation of harmful activities.
Long-Term Applications
The following require further research, scaling, domain-specific finetuning, or real-time/edge deployment advances (e.g., lower latency, higher reliability, safety certification).
- Real-time AR guidance and overlays
- Sectors: field service, manufacturing, healthcare, construction
- What it could do: Wearable or mobile AR recognizes current state and renders the next event as a live overlaid demo (e.g., torque sequence, catheter insertion angle).
- Dependencies: Drastic latency reduction; robust on-device VDMs; strong safety/regulatory validation (especially in medical).
- Assumptions: High-precision state estimation and identity preservation; reliable environment tracking.
- Robotics planning from “video answers”
- Sectors: robotics, warehousing, household assistance
- What it could do: Use generated next-step videos as intermediate plans (visual affordance hints) converted into low-level actions via imitation/RL.
- Dependencies: Cross-modal grounding from video to control; closed-loop safety; reward design for physical feasibility.
- Assumptions: Domain simulators or teleoperation data to align visual plans with actuation constraints.
- Driver assistance and hazard forecasting with visual demos
- Sectors: mobility, ADAS, micromobility
- What it could do: From dashcam clips, synthesize “likely next event” videos (e.g., pedestrian emerges) to prime drivers or upstream planners.
- Dependencies: Real-time inference; calibrated uncertainty and abstention; rigorous validation; on-vehicle compute.
- Assumptions: Geofenced deployment; strong privacy guarantees; bias and failure-mode audits.
- Compliance checking and SOP conformance analytics
- Sectors: pharmaceuticals, food safety, cleanrooms, energy
- What it could do: Compare recorded operator sequences with VNEP-predicted next steps to detect deviations and generate corrective demo steps.
- Dependencies: Domain-specific datasets; formal acceptance tests; audit trails.
- Assumptions: Camera coverage and identity consistency; integration with QMS/LIMS.
- Telemedicine and remote care instruction
- Sectors: healthcare
- What it could do: Patients submit clips; system generates stepwise personalized demos (e.g., inhaler technique, wound dressing) conditioned on observed state.
- Dependencies: Medical oversight; HIPAA/GDPR compliance; clinically validated evaluation metrics beyond CLIP/FVD.
- Assumptions: Narrow, approved task scopes; multilingual support; accessibility adaptation.
- Incident response and public safety training
- Sectors: emergency management, public policy
- What it could do: From scenario clips, generate branching “what happens next” videos to rehearse evacuation and de-escalation procedures.
- Dependencies: Scenario libraries; multi-future control; safety constraints to avoid harmful depiction misuse.
- Assumptions: Governance and watermarking; human-in-the-loop scenario vetting.
- Interactive storytelling and game prototyping via multi-future prediction
- Sectors: gaming, film, advertising
- What it could do: Let writers branch a scene into multiple plausible futures and immediately visualize short next-event clips for each path.
- Dependencies: Style- and character-consistent long-horizon generation; IP/style conditioning; latency and toolchain integration.
- Assumptions: Creator workflows tolerate iterative generation; licensing of likeness and assets.
- Construction progress planning and clash avoidance
- Sectors: AEC (architecture, engineering, construction)
- What it could do: Given a site walkthrough clip, generate the next safe installation step demo, revealing potential clashes before they occur.
- Dependencies: BIM grounding; spatial consistency across shots; jobsite variability handling.
- Assumptions: High-quality site capture; domain finetuning; integration with scheduling tools.
- Financial education and UI-to-Video guidance
- Sectors: finance, fintech
- What it could do: Turn a static UI screenshot (I2V generalization) into a demo of the next safe step (e.g., “how to set a recurring transfer”).
- Dependencies: Secure redaction; guardrails against generating deceptive content; brand/UI-specific conditioning.
- Assumptions: Readily available UI states; regulatory constraints on advice versus instruction.
- Sports analytics: play prediction visualization
- Sectors: sports tech, broadcast
- What it could do: From multi-angle clips, render plausible next-play visualizations personalized to the current formation.
- Dependencies: Multi-camera fusion; team-specific priors; uncertainty quantification.
- Assumptions: Broadcast latency tolerance; rights to training and distribution.
- Energy and utilities fieldwork guidance
- Sectors: energy, utilities
- What it could do: For routine maintenance clips, produce the next-step visual SOP demo (valve operations, panel checks) conditioned on observed indicators.
- Dependencies: Hazard-aware guardrails; asset-specific grounding; offline approval workflows.
- Assumptions: Robustness to outdoor conditions; protective equipment recognition.
Cross-Cutting Assumptions and Dependencies (affect both timelines)
- Latency and compute: Current inference (~4 s caption + ~35 s video) suits offline/asynchronous scenarios; real-time use requires compression, distilled VDMs, or edge acceleration.
- Safety and reliability: Not suitable for high-risk procedures without domain validation and human oversight; requires abstention/uncertainty measures.
- Data and IP: Ensure training/evaluation data licensing, consent for user uploads, and watermarking/fingerprinting for generated media.
- Domain adaptation: Many verticals will benefit from small finetuning sets and retrieval-augmented conditioning on SOPs or manuals.
- Evaluation: General metrics (FVD, CLIP) are insufficient in regulated domains—need task-specific, human-rated, or outcome-based metrics.
- UX and expectations: Clearly communicate that outputs are illustrative; include replay, step-by-step controls, and text backup instructions.
- Governance: Content moderation, bias audits, and policy-compliant templates (e.g., avoiding harmful or deceptive next-events).
These applications leverage the paper’s key innovations: (1) a new answer modality (video) for next-event prediction, (2) Joint-GRPO for aligning a reasoning model with a generative model under a joint reward, and (3) a dedicated VNEP dataset enabling training and benchmarking. Together, they open a path from “telling” to “showing” across consumer help, training, and planning—first offline, and eventually in real-time, safety-critical workflows.
Glossary
- Ablation study: Systematically removing or modifying components to assess their impact on overall performance. "We conduct ablation studies to validate the design of Joint-GRPO"
- Anchor caption: A high-quality reference caption produced by the VLM to condition the VDM during training. "the `now-improved' VLM from Stage 1 generates a candidate anchor caption"
- BELU (BLEU): An n-gram overlap metric for evaluating the quality of generated text against references (spelled “BELU” in the paper). "BELU@1"
- Cascaded pipeline: A sequential architecture where one model’s output conditions another, often leading to mismatch across modalities. "this cascaded pipeline suffers from a semantic-to-visual misalignment;"
- CLIP Similarity: A similarity measure computed using CLIP to evaluate alignment between visual content and text or between videos. "evaluates visual coherence of generated videos with ground-truth using CLIP Similarity"
- CLIPScore: A metric based on CLIP embeddings that measures semantic consistency between generated visual content and text. "measures semantic consistency between the output video and the anchor caption using CLIPScore"
- CLIP-T: CLIP-based score assessing semantic consistency between generated video frames and text. "The CLIP-Score for video consistency (CLIP-V) and semantic consistency (CLIP-T) is computed using a ViT-B/32 model."
- CLIP-V: CLIP-based score assessing visual consistency between generated video frames and the ground-truth frames. "The CLIP-Score for video consistency (CLIP-V) and semantic consistency (CLIP-T) is computed using a ViT-B/32 model."
- Commonsense reasoning: Leveraging implicit human knowledge to infer plausible events or actions. "leverages techniques ranging from event understanding~\cite{chao2015hico} to multiscale temporal modeling and commonsense reasoning~\cite{chen2021joint}."
- Conditioning latent space: The latent representation into which conditioning tokens (e.g., from a VAE) are concatenated to steer generation. "these tokens are then concatenated into the VDM's conditioning latent space."
- DiT (Diffusion Transformer): A transformer-based architecture used within diffusion models for generative tasks. "across all DiT blocks"
- Event-conditioned reasoning: Inferring the next event based on causal or procedural logic given current context. "VNEP focus on event-conditioned reasoning."
- FVD (Fréchet Video Distance): A distributional distance metric assessing the quality and realism of generated videos. "FVD"
- GRPO: A reinforcement learning algorithm that optimizes model policies using grouped trajectory rewards and normalized advantages. "GRPO is an RL algorithm designed to align model outputs with human preferences or complex objectives."
- Instruction-grounded reasoning: Reasoning guided explicitly by user instructions or prompts to produce context-appropriate outputs. "We task the VLM with performing instruction-grounded reasoning"
- I2V (Image-to-Video): Generating a video from a single image while reasoning about plausible temporal evolution. "VANS generalizes effectively to the reasoning image-to-video (I2V) task"
- Joint-GRPO: A two-stage RL strategy coordinating VLM and VDM under a joint reward to align semantics and visuals. "we introduce Joint-GRPO to orchestrate the two models into a cohesive unit for VNEP."
- KL divergence: A measure of divergence between probability distributions used to regularize policy updates in RL. "The clipping mechanism and KL divergence term ensure training stability"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning technique for large models. "using LoRA~\cite{hu2022lora} (rank=8, alpha=32)"
- Multiscale temporal modeling: Methods that capture temporal patterns at multiple scales to understand or predict events. "leverages techniques ranging from event understanding~\cite{chao2015hico} to multiscale temporal modeling and commonsense reasoning~\cite{chen2021joint}."
- Multi-future prediction: Generating multiple plausible future outcomes conditioned on different hypotheses for the same context. "a key generalization capability: multi-future prediction."
- NEP (Next-Event Prediction): Predicting the next event given a video and a procedural or predictive question, typically in text. "uses video as the answer modality for Next-Event Prediction (NEP)."
- Normalized advantage: The advantage value scaled relative to group statistics to stabilize and compare trajectory rewards. "GRPO computes a normalized advantage that measures how much better or worse each trajectory is compared to the group average:"
- ODE (Ordinary Differential Equation): A deterministic continuous-time formulation; here converted to SDE to enable RL training for diffusion. "convert a deterministic Ordinary Differential Equation (ODE) into an equivalent Stochastic Differential Equation (SDE) to enable GRPO training."
- Reward hacking: Exploiting reward signals in ways that increase scores without improving true task performance. "This approach is prone to reward hacking and training instability"
- ROUGE-L: A text evaluation metric based on longest common subsequence to measure semantic similarity. "measures semantic similarity between generated and ground-truth captions using ROUGE-L~\cite{lin2004rouge}."
- SDE (Stochastic Differential Equation): A stochastic continuous-time formulation used to model diffusion processes during training. "convert a deterministic Ordinary Differential Equation (ODE) into an equivalent Stochastic Differential Equation (SDE) to enable GRPO training."
- Semantic hallucination: Generating content that is semantically incorrect or references nonexistent elements. "retains errors like semantic hallucination (predicting non-existent inreview in Case 1)"
- Semantic-to-visual gap: The mismatch between textual semantics and the visual realizability or coherence of generated videos. "This disconnect creates a semantic-to-visual gap"
- SFT (Supervised Fine-Tuning): Training a model on labeled examples to adapt it to a specific task. "a dedicated dataset with 100K video-question-answer triplets for supervised fine-tuning (SFT) on VNEP task."
- Unified models: Architectures that jointly handle understanding and generation within a single model. "unified models~\cite{luo2025univid,wei2025univideo,tan2025omni} attempt to align understanding and generation within a single model"
- VAE (Variational Autoencoder): A generative model that encodes inputs into a latent space; here used to tokenize frames for conditioning. "using a VAE~\cite{wan2025wan}; these tokens are then concatenated into the VDM's conditioning latent space."
- VAE tokens: Discrete latent tokens produced by a VAE from input frames used to condition video generation. "from the input video's VAE tokens"
- VDM (Video Diffusion Model): A diffusion-based generative model specialized for synthesizing videos. "align a Vision-LLM (VLM) with a Video Diffusion Model (VDM) for VNEP."
- ViT (Vision Transformer): A transformer architecture for image/video feature extraction based on patches. "high-level ViT visual features from the input video."
- VLM (Vision-LLM): A model that jointly processes visual inputs and language to perform multimodal reasoning. "align a Vision-LLM (VLM) with a Video Diffusion Model (VDM)"
- VNEP (Video-Next-Event Prediction): Extending NEP by generating a video as the answer to predict the next event. "We pioneer Video-Next-Event Prediction (VNEP)"
- Video continuation: Extending a given video by predicting likely subsequent frames or content. "utilize its native capability for video continuation."
- Visual fidelity: The degree to which generated videos are visually coherent and consistent with the context. "achieving consistent performance on both semantic accuracy and visual fidelity"
Collections
Sign up for free to add this paper to one or more collections.

