Learning Personalized Agents from Human Feedback
Abstract: Modern AI agents are powerful but often fail to align with the idiosyncratic, evolving preferences of individual users. Prior approaches typically rely on static datasets, either training implicit preference models on interaction history or encoding user profiles in external memory. However, these approaches struggle with new users and with preferences that change over time. We introduce Personalized Agents from Human Feedback (PAHF), a framework for continual personalization in which agents learn online from live interaction using explicit per-user memory. PAHF operationalizes a three-step loop: (1) seeking pre-action clarification to resolve ambiguity, (2) grounding actions in preferences retrieved from memory, and (3) integrating post-action feedback to update memory when preferences drift. To evaluate this capability, we develop a four-phase protocol and two benchmarks in embodied manipulation and online shopping. These benchmarks quantify an agent's ability to learn initial preferences from scratch and subsequently adapt to persona shifts. Our theoretical analysis and empirical results show that integrating explicit memory with dual feedback channels is critical: PAHF learns substantially faster and consistently outperforms both no-memory and single-channel baselines, reducing initial personalization error and enabling rapid adaptation to preference shifts.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building AI helpers that truly get to know you over time. The authors introduce PAHF (Personalized Agents from Human Feedback), a simple way for an AI to learn your likes and dislikes during real conversations and actions. Instead of relying on a fixed profile or old logs, the AI keeps a small, per-user “memory,” asks you quick questions before doing something risky, and updates its memory when you correct it afterward. The goal is to serve new users well from day one and keep up as people’s preferences change.
Key Questions
The paper focuses on three easy-to-understand questions:
- How can an AI work well for a brand-new user with no history?
- How can it learn directly from you in the moment when it’s unsure what you want?
- How can it quickly adapt when your preferences change (for example, you switch from preferring soda to tea)?
How It Works (Methods and Approach)
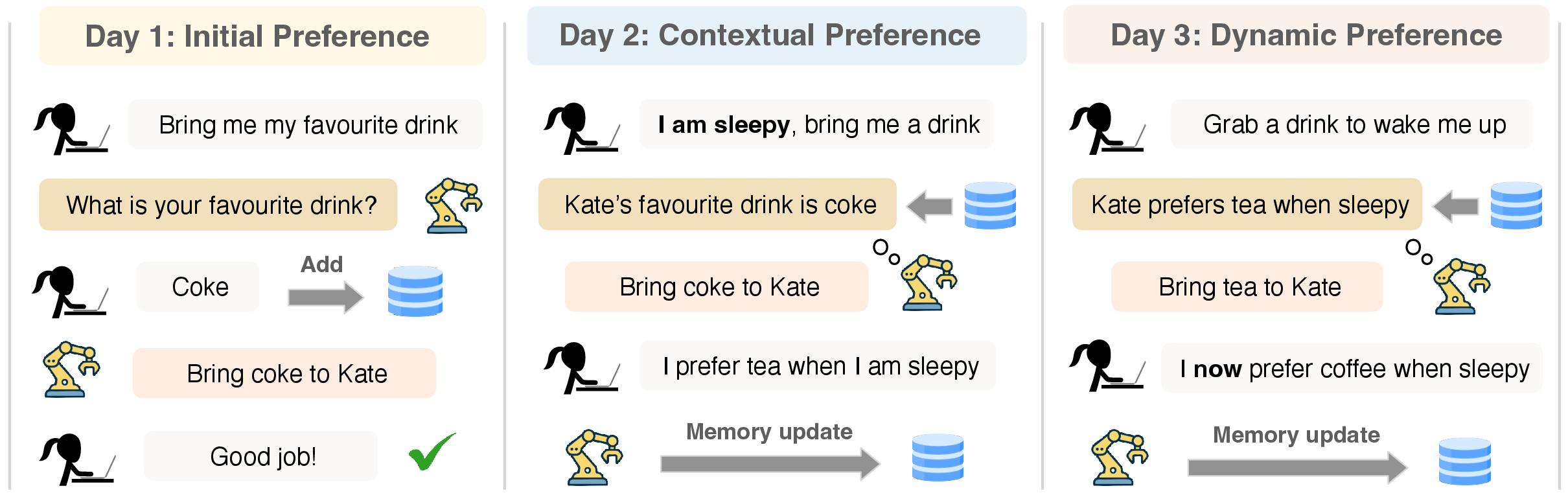
Think of the AI as a helper with a small personal notebook just for you. Every time you interact, it follows a simple three-step loop:
- Pre-action clarification: Before acting, the AI checks its notebook. If it’s missing info or something is unclear, it asks a short question (like “Do you prefer Coke or Sprite?”). This helps avoid obvious mistakes.
- Action: It uses your instruction plus what’s in the notebook to take an action (e.g., bring a drink, choose a product).
- Post-action learning: If it gets something wrong, you correct it (“Actually, I prefer tea when I’m sleepy”). The AI then updates its notebook so it won’t repeat the mistake.
Two key ideas, explained in everyday terms:
- Partial observability: Sometimes the AI just doesn’t know enough yet (like meeting you for the first time). Asking before acting helps here.
- Preference drift: People change. What worked yesterday might be wrong today. Learning from your corrections after the fact helps the AI fix “confidently wrong” beliefs.
How they tested it:
- Two challenge worlds:
- Embodied manipulation: Everyday tasks like bringing the right item or placing something in the right spot.
- Online shopping: Picking one product out of a few options based on your detailed preferences; “near-miss” options are included to make it tricky.
- Four-phase evaluation to see if the AI can learn and then adapt:
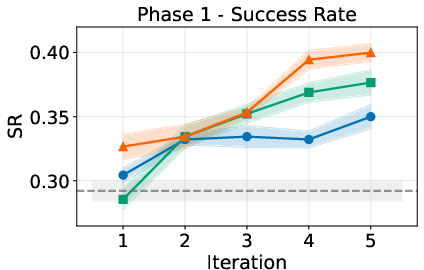
- Phase 1: Learn initial preferences from scratch with live feedback.
- Phase 2: Test what it learned (no feedback allowed).
- Phase 3: Change the user’s preferences and let the AI adapt using feedback.
- Phase 4: Test again to see if it truly adapted (no feedback).
- Comparisons:
- No memory
- Pre-action only (asks questions, no correction updates)
- Post-action only (no questions, learns only from corrections)
- PAHF (both pre- and post-action feedback with explicit memory)
- Simple memory design: Short, per-user notes stored in a mini database. The AI retrieves the most relevant notes before acting and updates or adds notes after feedback. No fancy architecture—just a clean, practical setup.
Theory in plain language:
- If preferences can change, you need post-action learning; otherwise the AI keeps making mistakes when your tastes shift.
- If information is missing at the start, you need pre-action questions; otherwise the AI will guess and be wrong a lot.
- Using both together keeps errors low over time.
Main Findings
What the experiments showed across both worlds:
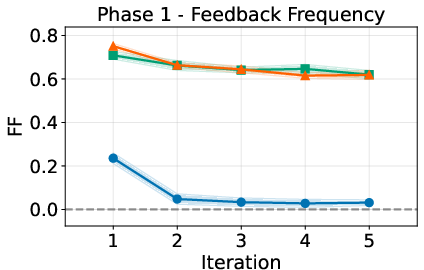
- Pre-action questions reduce early mistakes. When the AI asks quick clarifying questions, it does better right away with new users and unknown preferences.
- Pre-action alone is not enough when preferences change. Once the AI believes it knows you, it may stop asking questions—and can keep being “confidently wrong” if your tastes drift.
- Post-action corrections are essential for fast adaptation. If the AI listens to your corrections after a mistake, it quickly fixes outdated notes and stops repeating the error.
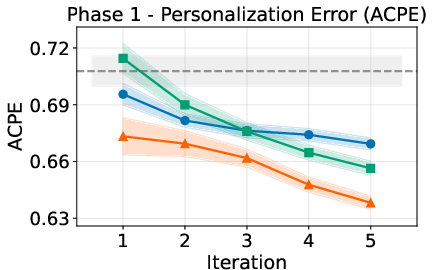
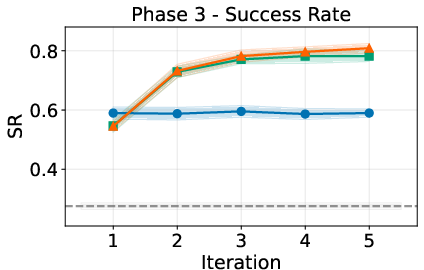
- PAHF (both channels + memory) works best overall. It combines the low early error of pre-action questions with the fast recovery of post-action corrections. In both the embodied tasks and online shopping, PAHF reaches the highest success rates in final tests and keeps cumulative errors lowest.
In short: Asking before acting prevents initial blunders, correcting after acting fixes stale beliefs, and doing both with a simple per-user memory outperforms the alternatives.
Why It Matters (Impact)
This research suggests a straightforward recipe for building more helpful digital assistants and robots:
- Give the AI a clear, per-user memory notebook.
- Let it ask small, targeted questions when uncertain.
- Let it learn from your corrections to keep up with changing preferences.
The payoff is an AI that works well for new users, reduces annoying wrong guesses, adapts quickly as you change, and stays aligned with you over time. This approach can be applied to many real-world settings—from home robots to shopping assistants—without needing huge, pre-collected user datasets or complex new architectures.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following gaps and open questions that future work could address:
- Real-user validation: Results are based on LLM-driven and rule-based simulators; no studies with human participants to assess learning effectiveness, user satisfaction, perceived burden, or robustness to real-world feedback variability.
- Feedback noise and inconsistency: Robustness to noisy, vague, contradictory, or delayed human feedback is not characterized; the framework assumes reliable, timely post-action signals and balanced pre-action responses.
- Adversarial and poisoning resilience: No analysis of attacks via malicious feedback (e.g., prompt injection, memory poisoning) or safeguards against corrupting per-user memory.
- Privacy and data governance: The work does not specify consent, data retention, deletion, right-to-be-forgotten, encryption, or differential privacy for explicit per-user memory.
- Scalability of memory: There is no empirical or theoretical analysis of how retrieval quality, latency, and accuracy degrade as memory grows over long-term use or across many users.
- Memory management and forgetting: Policies for conflict resolution, versioning, decay/expiry of outdated preferences, and preventing catastrophic forgetting are not designed or evaluated.
- Context modeling: Context-dependent preferences are discussed but not operationalized with a formal context representation, context detection, or context-scoped memory updates to prevent overgeneralization.
- Asking-when-to-ask optimization: The clarification policy (how many/which questions, and when to abstain) is heuristic; no cost-sensitive, uncertainty-aware optimization or learning-to-query approach is presented or evaluated.
- Cost-aware evaluation: Metrics do not penalize unnecessary clarifications, user burden, or action costs; a cost-sensitive utility/regret framework is absent.
- Long-horizon tasks: Benchmarks focus on short, low-stakes decisions (single object selection, 3-way shopping choices); scalability to truly long-horizon, interdependent, multi-step tasks with compounding errors is untested.
- Real-world embodiment: No deployment on physical robots or real interactive systems with sensing/actuation noise, latency, and safety constraints.
- Generalization across domains: Cross-domain transfer and out-of-distribution robustness (e.g., new task families, unseen contexts) are not evaluated.
- Multi-user and group settings: The framework assumes per-user isolation; handling shared devices, group preferences, or conflicting preferences among multiple stakeholders is unexplored.
- Preference structure: Online shopping uses strict conjunctive acceptance policies; richer preference forms (rankings, weighted utilities, trade-offs, disjunctions, and context-sensitive exceptions) are not modeled or tested.
- Safety and normative constraints: How to reconcile personalization with safety, legality, or organizational policies (e.g., declining harmful requests) is not specified.
- Theoretical assumptions vs. practice: Guarantees rely on piecewise-stationary preferences, immediate post-error updates, and balanced m-ary queries; the gap to natural-language, imperfect feedback and unknown switch counts K is not bridged.
- Drift detection without errors: Adaptation relies on errors plus post-action feedback; there is no mechanism to detect preference drift proactively (e.g., change-point detection) before making mistakes.
- Salience detector reliability: The LLM-as-judge for feedback salience is assumed correct; there is no measurement of false positives/negatives or impact on downstream performance.
- Sensitivity to hyperparameters: Thresholds for duplicate detection (e.g., similarity τ), retrieval top-k, and note-merging strategies are not systematically ablated for stability and robustness.
- Memory representation: Free-form notes may be insufficient for complex, compositional preferences; the benefits of structured schemas, knowledge graphs, or causal representations are untested.
- Comparison with advanced memory systems: The paper deliberately uses simple memory backends; it does not compare against modern hierarchical/structured memory or learned retrieval controllers.
- Model dependence and reproducibility: Main results rely on closed-source GPT-4o; broader evaluation across open models, smaller models, and resource-constrained settings is limited.
- Efficiency and latency: Interaction costs (compute, latency), number and length of clarifications, and end-to-end responsiveness are not reported, hindering deployment viability assessment.
- Handling sparse or delayed feedback: The framework assumes immediate post-action feedback; performance with sparse, delayed, or batched feedback is not analyzed.
- Abstention and deferral: Policies for abstaining, deferring decisions, or escalating to a human when uncertainty is high are not studied.
- Cross-user interference: Although per-user isolation is intended, risks of embedding/model/context bleed-through or indexing errors across users are not assessed.
- Multilingual and cultural variation: Robustness to multilingual users, code-switching, and culturally diverse preference expressions is untested.
- Benchmark realism: Embodied tasks and shopping scenarios are simplified; real-world constraints (e.g., budgets, prices, availability, shipping, temporal goals) and richer attribute spaces are not incorporated.
- Evaluation granularity for adaptation: While Phase 3/4 report success rates, fine-grained adaptation metrics (e.g., mistakes-to-recovery per switch, adaptation half-life) are not reported.
- Integration with model-level personalization: How explicit memory interacts with or complements RLHF/DPO fine-tuning or meta-learning for personalization is not explored.
- UI/UX design: How to present pre-action questions and memory edits to minimize user friction and enable user-controlled memory curation is not studied.
Practical Applications
Overview
The paper introduces PAHF (Personalized Agents from Human Feedback), a continual personalization framework that couples explicit per-user memory with two complementary feedback channels: (1) pre-action clarification to resolve ambiguity and (2) post-action feedback to correct miscalibration and adapt to preference drift. The authors provide theory and two benchmarks (embodied manipulation and online shopping), showing that PAHF reduces initial errors and adapts quickly when preferences change. Below are actionable applications derived from these findings.
Immediate Applications
The following applications can be deployed with current LLMs, lightweight memory backends (e.g., SQLite/FAISS), and standard RAG pipelines, as described in the paper’s implementation.
- Personalized conversational shopping assistants
- Sectors: Retail, E-commerce
- Product/workflow: Chat-based shopping bots that:
- Ask targeted pre-purchase clarifying questions about essential product features (e.g., size, material, budget).
- Write salient preferences to per-user memory as compact notes.
- Use post-purchase feedback (e.g., “This strap irritates my skin”) to refine future recommendations.
- Dependencies/assumptions: Structured product catalogs and feature metadata; user consent for per-user memory; UI to capture clarifications and post-purchase reactions; guardrails against over-asking; integration with CRM/identity.
- Customer support triage and resolution bots with per-customer memory
- Sectors: Software/SaaS, Telecom, Banking, Insurance
- Product/workflow: Support agents that:
- Query memory for past preferences (e.g., preferred channels, troubleshooting steps tried).
- Ask brief pre-action clarifications to reduce back-and-forth.
- Update memory from post-resolution feedback (“Please always escalate email-related issues”).
- Dependencies/assumptions: CRM integration and identity resolution; consent and data retention policies; escalation to human agents for high-stakes issues; latency/cost management.
- Workplace productivity assistants (email/calendar/task)
- Sectors: Software, Enterprise IT
- Product/workflow: Assistants that:
- Learn user-specific formatting, meeting preferences, and prioritization rules.
- Ask clarifying questions for ambiguous requests (“Do you prefer a 30-min or 60-min slot?”).
- Update memory when corrected (“Stop auto-adding Zoom links for internal 1:1s”).
- Dependencies/assumptions: API access to mail/calendar/tasks; per-user memory isolation; security controls to prevent leakage across users; on-device or encrypted storage options.
- Developer coding copilots with evolving style memory
- Sectors: Software/DevTools
- Product/workflow: IDE plugins that:
- Ask clarifying questions for ambiguous refactorings.
- Store style and lint preferences (“Always use pytest fixtures; prefer f-strings”).
- Update memory on post-action corrections (e.g., when users revert or annotate a fix).
- Dependencies/assumptions: Source code privacy and compliance; fast, local or proxied memory; balancing prompts to avoid interrupting flow.
- Smart-home and IoT assistants that adapt to household preferences
- Sectors: Consumer Tech, Energy
- Product/workflow: Home assistants that:
- Ask brief clarifications (“Comfort or energy savings today?”) before adjusting devices.
- Remember occupant-specific preferences (lighting warmth, thermostat ranges).
- Update memory if corrected (“When I say ‘cooler’ after a workout, target 70°F”).
- Dependencies/assumptions: Multi-user disambiguation; local-first memory for privacy; integration with IoT hubs; fail-safes for comfort/safety.
- Embodied service robots for offices/hospitality (non-critical tasks)
- Sectors: Robotics, Hospitality, Facilities
- Product/workflow: Robots that:
- Retrieve/arrange items grounded in per-user preferences.
- Ask clarifying questions for ambiguous commands.
- Use post-action corrections to revise outdated preferences (e.g., beverage changes).
- Dependencies/assumptions: Reliable user identification; safe manipulation; bandwidth/latency for on-robot inference or edge servers; human-in-the-loop fallback.
- Educational tutoring/chat assistants with preference and misconception tracking
- Sectors: Education, EdTech
- Product/workflow: Tutors that:
- Ask clarifications about goals and difficulty preferences.
- Store per-student notes on methods that work best.
- Update memory from post-task feedback (“Socratic hints help more than direct solutions”).
- Dependencies/assumptions: Guardrails to avoid reinforcing misconceptions; educator oversight; privacy for minors; progress tracking interoperability (LMS/LTI).
- Patient intake and navigation assistants (non-diagnostic)
- Sectors: Healthcare (administrative workflows)
- Product/workflow: Agents that:
- Clarify appointment constraints and communication preferences.
- Remember accessibility or language needs.
- Update memory based on post-visit feedback (“Prefer telehealth for follow-ups”).
- Dependencies/assumptions: HIPAA/GDPR compliance; clinical oversight for any medical content; secure storage and auditability; careful scope delimitation (administrative vs. clinical).
- Evaluation and A/B testing protocols for personalization
- Sectors: Industry and Academia
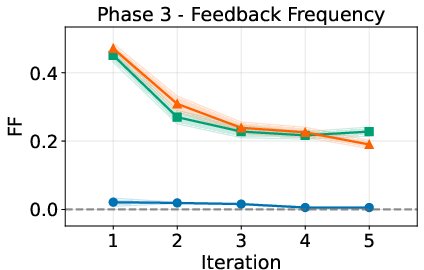
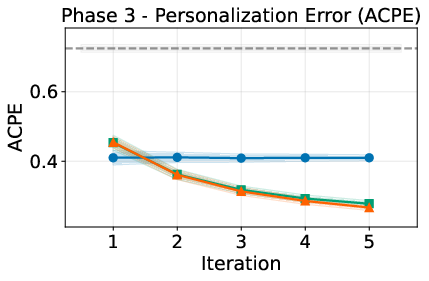
- Product/workflow: Adopt the paper’s four-phase protocol (initial learning/test, drift adaptation/test) with SR, FF, ACPE metrics for:
- Measuring personalization learning curves.
- Stress-testing drift adaptation before production rollout.
- Dependencies/assumptions: Representative task sets; user consent for tracking preference evolution; simulation/human-in-the-loop testbeds.
- Tooling building blocks (now)
- Sectors: Software tooling/platforms
- Product/workflow:
- Memory middleware (SQLite/FAISS) as a service per user.
- Salience detection microservice to filter/store meaningful feedback.
- Clarification UI patterns and APIs for pre-action questions.
- Duplication/merge logic for notes; retrieval with DRAGON+ or equivalent embeddings.
- Dependencies/assumptions: Standardized interfaces across agents; monitoring for query rates and feedback fatigue; cost/latency budgets for LLM calls.
Long-Term Applications
These applications require further research, scaling, safety validation, or regulatory clearance before broad deployment.
- Personalized clinical decision support and care companions
- Sectors: Healthcare
- Potential product/workflow:
- Agents that adapt to changing patient preferences, comorbidities, and adherence patterns.
- Pre-action clarifications for trade-offs (efficacy vs. side effects).
- Post-action feedback from outcomes to update care preference notes.
- Dependencies/assumptions: Clinical trials; integration with EHRs; regulation (FDA/EMA); robust drift detection for safety; human clinician oversight.
- Eldercare and in-home assistive robots
- Sectors: Robotics, Healthcare
- Potential product/workflow:
- Robots that personalize routines (meals, medication reminders) and adapt to evolving needs.
- Safety-first designs with conservative fallback when memory is uncertain.
- Dependencies/assumptions: Reliable identity and intent recognition; safety certifications; robust multi-modal perception; privacy-preserving on-device memory.
- Adaptive robo-advisors that track risk preference drift
- Sectors: Finance/Wealth Management
- Potential product/workflow:
- Advisors that ask clarifying questions during market volatility, then update risk notes from post-action behavior (e.g., panic sells).
- Dependencies/assumptions: Regulatory compliance (suitability, disclosures); model risk management; audit trails for every memory update; strict guardrails to avoid unsuitable advice.
- Cross-app, cross-device “personal memory OS” for user-centric personalization
- Sectors: Platform software, Mobile/OS
- Potential product/workflow:
- Federated per-user memory layer that apps can query/update via standardized APIs.
- Built-in mechanisms for consent, editability, and “right to be forgotten.”
- Dependencies/assumptions: Industry standards for memory schemas and permissions; privacy-preserving sync/federation; conflict resolution and multi-tenant isolation.
- Industrial cobots and operator-adaptive interfaces
- Sectors: Manufacturing, Logistics
- Potential product/workflow:
- Cobots that learn per-operator preferences (tooling layout, speeds) via pre-action checks and post-action corrections.
- Dependencies/assumptions: Safety and compliance standards; integration with MES/PLC systems; rigorous drift monitoring to prevent unsafe overfitting.
- Personalized energy management and demand response
- Sectors: Energy/Utilities, Smart Buildings
- Potential product/workflow:
- Home/building energy managers that clarify comfort vs. savings, then adapt to evolving tariffs/schedules from feedback (“Don’t precool on weekends”).
- Dependencies/assumptions: Smart meter and device integration; occupant identification; coordination with utility DR programs; fairness and privacy considerations.
- Longitudinal tutoring systems that personalize over years
- Sectors: Education
- Potential product/workflow:
- Tutors that evolve with students’ goals and strategies, updating memory based on performance feedback and self-reports.
- Dependencies/assumptions: Curriculum alignment; efficacy studies; equity and bias monitoring; interoperable learner models.
- In-cabin personalization for vehicles
- Sectors: Automotive
- Potential product/workflow:
- Agents that learn occupant preferences (climate, routes, infotainment) and adapt to changing contexts.
- Dependencies/assumptions: Safety-critical integration; driver distraction regulations; multi-user profile management; offline/on-board memory.
- Governance and policy frameworks for adaptive AI memory
- Sectors: Policy/Regulation
- Potential product/workflow:
- Standards for consented per-user memory, transparency on stored notes, user-editable memory, drift audits, and deletion.
- Dependencies/assumptions: Multi-stakeholder alignment; updates to data protection regimes to address live, adaptive memory; compliance tooling and certification programs.
- Platformized PAHF SDKs and observability for enterprise-scale deployment
- Sectors: Software tooling, MLOps
- Potential product/workflow:
- SDKs with pluggable memory backends, salience detection, drift detection dashboards, and four-phase evaluation templates.
- Dependencies/assumptions: Interop with LLM providers; quota/cost controls; SLOs for latency; red-teaming for prompt/feedback injection defenses.
Cross-Cutting Assumptions and Dependencies
To improve feasibility and robustness across the above applications, the following considerations are critical:
- Identity and isolation: Reliable user identification; strict per-user memory isolation to prevent cross-user leakage.
- Consent and control: Transparent collection and editing of memory entries; support for data deletion (“right to be forgotten”) and export; configurable retention.
- Feedback quality and fatigue: Effective salience detection to avoid storing trivial/noisy feedback; rate limits and UX to minimize over-questioning.
- Safety and oversight: Human-in-the-loop for high-stakes domains; conservative defaults when ambiguity remains high; robust safeguards against harmful or adversarial feedback.
- Retrieval and summarization quality: High-quality embeddings; duplicate detection and merge policies; domain adaptation for retrieval.
- Cost and latency: Batching, caching, or on-device inference for responsiveness; efficient memory reads/writes; observability for FF/SR/ACPE tracking.
- Evaluation realism: Transition from simulated feedback (as used in the paper’s benchmarks) to real-user studies; instrumentation to measure drift adaptation in production.
- Multi-user and context dependence: Support for context-scoped preferences (time, location, task) to avoid overgeneralization and miscalibration.
- Regulatory compliance: Domain-specific obligations (HIPAA, GDPR/CCPA, financial suitability); audit logs for memory updates and decisions.
These applications translate the paper’s core insight—complementarity of pre-action clarification and post-action feedback with explicit memory—into concrete tools and workflows that can improve personalization today while charting a path for regulated, safety-critical, and cross-ecosystem deployments over time.
Glossary
- Ablation studies: Systematic experiments that remove or vary components to assess their impact on performance. "we report ablation studies that vary both the agent model"
- Acceptance policy: A rule specifying the conditions under which an option is acceptable; here, a strictly conjunctive set of feature requirements. "acceptance policy, which is strictly conjunctive"
- Average cumulative personalization error (ACPE): A metric tracking the time-averaged cumulative personalization error across learning iterations. "average cumulative personalization error (ACPE)"
- Bayes-optimal: Refers to decisions or error rates that are optimal under a Bayesian posterior over uncertainties. "the Bayes-optimal error is at least some fixed constant "
- Bayesian cognitive models: Probabilistic models of human cognition used to approximate reasoning and preference inference. "leverages Bayesian cognitive models"
- Dense retrieval: Embedding-based retrieval of relevant items via similarity search, typically using vector representations. "top- dense retrieval"
- DRAGON+: An embedding model used for retrieval to compute similarity between notes and queries. "embeddings from DRAGON+"
- Dynamic-preference setting: A scenario where user preferences change over time, requiring continual adaptation. "In the dynamic-preference setting, post-action feedback is crucial"
- Dynamic regret: Performance measure comparing an algorithm’s actions to an oracle in environments with changing optima. "define the dynamic regret"
- Embodied manipulation: Tasks involving physical agents performing object selection and placement in real-world scenes. "Embodied Manipulation Domain."
- FAISS: A library for efficient similarity search over vector embeddings. "a FAISS-based vector index"
- Hindsight simulation: A technique that uses outcomes after actions to simulate and learn corrective behaviors. "proposed hindsight simulation as a mitigation"
- k-nearest-neighbor search: A retrieval method that returns the k most similar items to a query in embedding space. "run -nearest-neighbor search over indexed memory embeddings"
- LLM-as-a-judge: Using a LLM to evaluate or classify feedback or content quality. "implemented as an LLM-as-a-judge"
- Non-Stationarity: Property of preferences or environment that change over time, breaking assumptions of fixed distributions. "Non-Stationarity: The user's preferences are non-stationary"
- Oracle policy: An idealized policy that has full knowledge of the true state and optimal actions. "Let be an oracle policy that knows at every round"
- Partial Observability: Situations where the true state is hidden, leading to uncertainty in decision-making. "Partial Observability: The true state is hidden."
- Persona: A user profile encoding preferences and behaviors that agents must learn and adapt to. "each user's persona is swapped for a new one"
- Piecewise stationary: A process that is stationary within segments but changes a finite number of times. "Preferences are piecewise stationary"
- Post-action feedback: Corrective input provided by the user after an agent acts, used to update memory and policies. "Post-action feedback is essential for fast adaptation."
- Pre-action feedback: Clarifying input solicited by the agent before acting to reduce ambiguity. "Pre-action feedback prevents initial personalization error."
- Preference drift: Evolution of a user’s preferences over time that can invalidate previously learned beliefs. "preference drift"
- ReAct framework: An agent paradigm that interleaves reasoning and acting to solve tasks. "follows the ReAct framework"
- Retrieval-Augmented Generation (RAG): A pipeline that retrieves relevant context and injects it into the model to guide generation. "Retrieval-Augmented Generation (RAG) pipeline"
- Salience detector: A component that filters feedback to identify personalized information worth storing. "passed to a “salience detector”, implemented as an LLM-as-a-judge"
- SQLite: A lightweight, file-based relational database used to persist agent memory. "a portable SQLite note store"
- Vector index: A data structure enabling fast nearest-neighbor search over embeddings. "a FAISS-based vector index"
Collections
Sign up for free to add this paper to one or more collections.