Memoria: A Scalable Agentic Memory Framework for Personalized Conversational AI
Abstract: Agentic memory is emerging as a key enabler for LLMs (LLM) to maintain continuity, personalization, and long-term context in extended user interactions, critical capabilities for deploying LLMs as truly interactive and adaptive agents. Agentic memory refers to the memory that provides an LLM with agent-like persistence: the ability to retain and act upon information across conversations, similar to how a human would. We present Memoria, a modular memory framework that augments LLM-based conversational systems with persistent, interpretable, and context-rich memory. Memoria integrates two complementary components: dynamic session-level summarization and a weighted knowledge graph (KG)-based user modelling engine that incrementally captures user traits, preferences, and behavioral patterns as structured entities and relationships. This hybrid architecture enables both short-term dialogue coherence and long-term personalization while operating within the token constraints of modern LLMs. We demonstrate how Memoria enables scalable, personalized conversational AI by bridging the gap between stateless LLM interfaces and agentic memory systems, offering a practical solution for industry applications requiring adaptive and evolving user experiences.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Memoria, a tool that helps chatbots (powered by LLMs) “remember” things about users over time, like a friend who remembers your interests and past conversations. Memoria adds a smart memory layer to chat systems so they can keep conversations coherent in the short term and personalized in the long term, without going over the LLM’s limits on how much text they can handle at once.
What questions did the researchers ask?
The paper tries to answer:
- How can we give LLM-based chatbots a reliable memory so they don’t forget past conversations?
- How can we keep chats both coherent in the moment and personalized across many sessions?
- Can we build a memory that’s easy to understand, update, and scale for real-world apps like customer support or finance?
- Does this memory system improve accuracy, speed, and cost compared to other methods?
How does Memoria work?
Think of Memoria like a two-part memory system plus a simple toolkit that keeps everything organized and efficient.
Two kinds of memory it builds
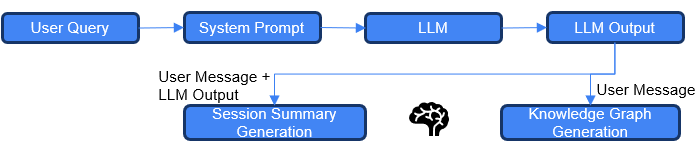
- Session summaries: Short “recaps” of ongoing conversations, like the highlights at the end of a chat. These help the chatbot remember what’s going on right now.
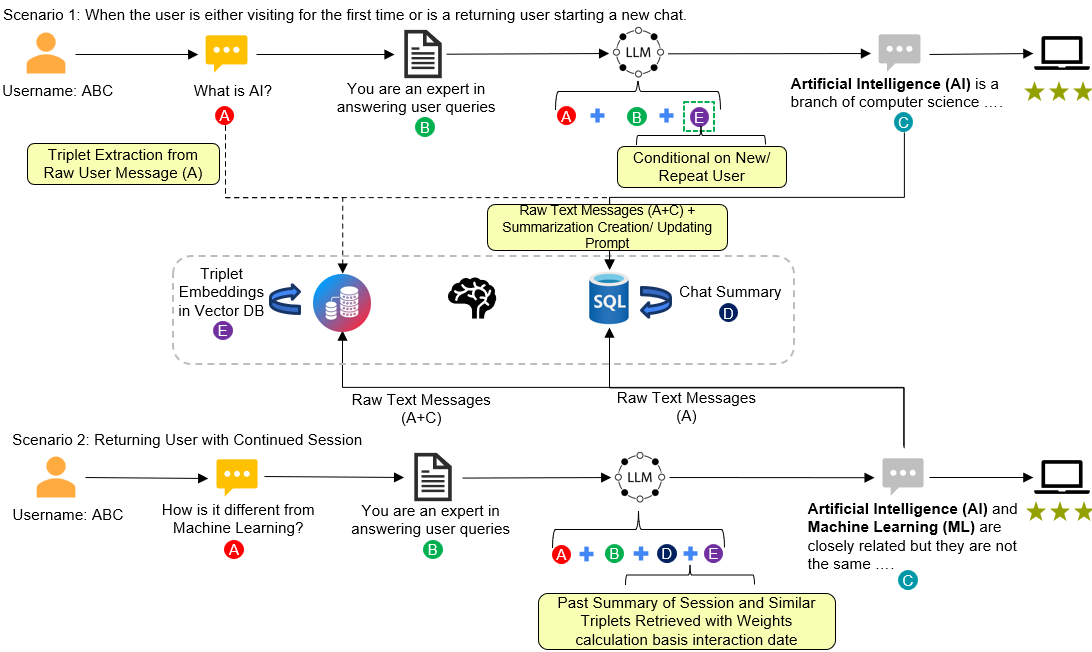
- User knowledge graph (KG): A structured “mind map” of the user’s traits and preferences built over time. It stores facts like “Sam likes ETFs” or “Alex’s shoes are in the closet.” Each fact is saved as a triplet: subject–predicate–object (for example: “Alex–stores–shoes in closet”).
The KG is “weighted,” which means newer facts count more than older ones. This helps the chatbot prefer your latest preferences and avoid confusion when something changes.
Four main parts inside Memoria
To keep memory clear and useful, Memoria includes:
- Structured conversation logging: Every message gets saved with a timestamp and session ID in a small database (SQLite). This is like keeping a neat diary of your chats.
- Dynamic user persona (KG): It builds and updates a user “mind map” from your messages. These facts are also turned into numbers (embeddings) and stored in a vector database (ChromaDB) for quick searching by meaning, not just exact words.
- Real-time session summarization: It creates short summaries of what’s happening during the current conversation so the chatbot can stay on track.
- Context-aware retrieval: When you ask a new question, Memoria fetches the most relevant summary and personal facts, and adds them to the prompt the LLM sees. Recent facts get higher weight, so the most up-to-date information is used.
How it uses memory during chats
- New user, new session: The chatbot has no memory yet, so it answers with just your message and the system’s instructions. Afterward, Memoria extracts facts, saves the messages, and makes a summary.
- Returning user, new session: Memoria instantly pulls your existing “mind map” (KG) to personalize the first reply of the session. It builds a new summary as you chat.
- Returning user, ongoing session: Memoria provides both the session summary and the most relevant, recent KG facts. The chatbot responds with strong continuity and personalization.
What did they find?
The authors tested Memoria on a public benchmark called LongMemEval that measures how well chat assistants handle long-term memory. They compared Memoria to another memory framework called A-Mem and to the approach of feeding the entire chat history to the model (“full context”).
Key results:
- Accuracy: Memoria scored highest or tied for highest on tasks that require recalling single-session user facts and handling updates to knowledge. For example:
- Single-session user facts: Memoria ~87.1%
- Knowledge updates: Memoria ~80.8%
- Speed and cost: Full context prompting was slow and very expensive (over 115,000 tokens per query). Memoria cut the prompt down to roughly 400 tokens on average and reduced latency by up to ~39%, making it much faster and cheaper.
- Precision of memory: A-Mem retrieved a lot of raw messages, which increased prompt size. Memoria’s recency-weighted facts kept prompts small while staying accurate, especially when a user changed their mind or updated a detail.
Why this matters: Memoria shows that using smart, curated memory (summaries + weighted user facts) works better than dumping everything back into the model. It’s both more accurate and more efficient.
Why does this matter?
Memoria helps chatbots act less like forgetful tools and more like helpful assistants that learn over time. This can:
- Improve user experience by remembering preferences and history
- Reduce repetition (you don’t have to re-explain yourself)
- Speed up problem-solving in customer support
- Power better recommendations in e-commerce and finance
- Make long-term conversations feel more natural and trustworthy
Because Memoria doesn’t change the LLM itself (no fine-tuning), it’s easy to plug into existing systems. It uses simple, local tools (SQLite and ChromaDB), making it practical for companies and developers.
Key takeaways
- Memoria is a memory add-on for chatbots that blends short-term summaries with a long-term, easy-to-understand user “mind map.”
- It favors recent facts to keep up with changes, like moving your shoes from under the bed to the closet.
- In tests, it was more accurate than a competing system and much faster and cheaper than feeding the whole conversation back to the model.
- This approach can make conversational AI more personal, consistent, and useful in real-world settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, action-oriented list of what remains missing, uncertain, or unexplored in the paper, to guide future research and engineering work:
- Evaluation scope is narrow: only two LongMemEval categories (single-session-user, knowledge-update) are tested; multi-session, temporal reasoning, single-session-assistant, and preference tracking remain unevaluated.
- No human-centered evaluation: lacks user studies (e.g., satisfaction, trust, perceived personalization), A/B tests, or real-world UX metrics.
- Reliance on “LLM as a judge” without statistical rigor: no inter-rater reliability, confidence intervals, significance testing, or bias analysis in automatic evaluation.
- Limited baselines: comparison only to A-Mem; missing benchmarks against other memory systems (e.g., Zep, LangGraph/LangChain memory, LlamaIndex memory, simple RAG baselines).
- No ablation studies: unclear contribution of each component (session summarization vs KG vs recency weighting); sensitivity to top-K, decay rate, embedding model, and prompt templates is not quantified.
- Triplet extraction quality unmeasured: no precision/recall of LLM-based triplet extraction, noise/hallucination rates, or post-processing filters to ensure correctness.
- Conflict resolution is recency-only: lacks robust mechanisms for contradiction handling, deduplication, entity resolution (synonyms, aliases), predicate schema constraints, or consistency checking.
- Ontology/schema unspecified: no explicit type system, predicate vocabulary, or domain ontology; unclear how KG evolves across domains or how schema is learned/validated.
- Identity and session linking are simplistic: assumes a stable “username”; unresolved issues include device changes, shared accounts, impersonation, and cross-session identity resolution.
- Privacy and compliance are absent: no consent flows, data minimization, retention/deletion (“right to be forgotten”), encryption, access controls, audit logs, or PII redaction strategies.
- Security risks unaddressed: no defenses against prompt injection via memory, poisoning/adversarial triplets, cross-user leakage, or trust scoring and sandboxing of memory entries.
- Governance and transparency missing: no user-facing controls to inspect/edit memory, opt-out, correct errors, or see provenance; no versioning of the persona KG.
- Working memory and parametric memory integration is deferred: open questions on combining Memoria with tool-use, planning/state machines, or model fine-tuning.
- Forgetting/bloat management not specified: beyond retrieval-time decay, there’s no memory compaction, archival, summarization-to-graph compression, or deletion policies.
- Prompt construction is opaque: unclear how weights are encoded in prompts, how token budgets are allocated between summary vs KG, and how templates affect effectiveness.
- Fixed top-K=20 may be suboptimal: no adaptive retrieval based on query complexity, confidence, or uncertainty estimates; no stopping criteria or reranking strategies beyond similarity.
- Time handling has edge cases: min–max normalization over retrieved triplets can distort absolute recency across sessions; time zone, clock skew, and stale data are not addressed.
- Scaling characteristics are unknown: no tests for memory footprint growth, retrieval latency under millions of users/triplets, write/read contention, index rebuild times, or throughput under load.
- Storage choices are non-production: SQLite + Chroma are used, but there’s no discussion of production-grade alternatives (replication, fault tolerance, backups, consistency models) or migration paths.
- Summary algorithm unspecified: no details on incremental summarization methods, compression ratios, drift/hallucination risks, or error accumulation over long sessions.
- Assistant actions excluded from KG: limiting KG to user messages omits verified assistant actions or external updates; provenance and trust levels for facts are not modeled.
- Domain generalization untested: claims of applicability to support/e-commerce/finance lack domain-specific evaluations, schemas, or performance evidence.
- Multilingual and multimodal support absent: no tests for non-English text, code-switching, or other modalities (voice, images); robustness to diverse inputs remains open.
- Personalization metrics missing: beyond accuracy, there are no measures of coherence, personalization quality, contradiction resolution rate, or factuality grounded in trusted sources.
- Latency results lack statistical detail: no variance, per-stage breakdown (retrieval, weighting, prompt build, inference), or environment/network effects; reproducibility is limited.
- Cost analysis omitted: token reductions are reported without pricing impact, budget trade-offs across model/context sizes, or throughput/cost per query.
- Hyperparameter tuning strategy absent: selection of decay rate (α=0.02), K=20, embedding model, and summary length lacks justification, sensitivity analysis, or auto-tuning procedures.
- Handling rare but important long-lived facts is unclear: no “pinned” memory or priority classes to prevent decay of critical information (e.g., immutable identifiers, safety preferences).
- Error detection and correction missing: no mechanisms for anomaly detection in memory, confidence scoring for triplets, human-in-the-loop validation, or rollback/version control.
- Trust and provenance not modeled: triplets lack source credibility scores, data lineage, or integrity checks; mixing user claims with uncertain information may taint memory.
- Query disambiguation with memory is not addressed: no strategies to confirm sensitive memory usage with the user, or to solicit clarifications for ambiguous references.
- Retrieval scoring limited to similarity: no hybrid retrieval combining symbolic constraints, rule-based filters, or knowledge-based validation.
- Reproducibility and openness limited: code/library not yet released; no seeds/configs or full experiment artifacts to ensure reproducibility; dependency on closed models complicates replication.
- Multi-agent/team memory unanswered: how multiple assistants share/scope memory, concurrency control, and access policies across agents/users remains unstudied.
- Legal/regulatory gaps for finance use cases: no audit trails, explanation facilities for regulators, or sector-specific compliance considerations despite financial advisory examples.
Practical Applications
Below are practical, real-world applications derived from the paper’s Memoria framework. They are grouped by deployment horizon and, for each, include sector alignment, indicative tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be implemented today using Memoria’s modular components (session summarization, weighted KG-based user modeling, structured logging, and context-aware retrieval) with the default stack (SQLite3 + ChromaDB, OpenAI embeddings, GPT-4.1-mini) or equivalent open-source alternatives.
- Customer support “memory copilot” for contact centers
- Sector: Software, Customer Support/CRM
- Workflow: Persist ticket history and session summaries; build a user persona KG (issues, preferences, product versions); use recency-weighted retrieval to prime responses; log outcomes for audit.
- Tools: Memoria + Zendesk/Salesforce/ServiceNow, ChromaDB, SQLite3, LangChain/LangGraph/LlamaIndex.
- Assumptions/Dependencies: Reliable user ID mapping; data privacy and consent; robust triplet extraction quality; appropriate decay rate tuning to resolve contradictions.
- Personalized shopping assistant with dynamic preferences
- Sector: E-commerce/Retail
- Workflow: Capture size, brand, budget, style in KG; use session summaries for ongoing cart/returns context; resolve “updated preferences” via recency weighting; pair with product RAG for inventory and specs.
- Tools: Memoria + Shopify/Magento APIs; vector DB for product embeddings; A/B testing for recommendation quality.
- Assumptions/Dependencies: Accurate entity extraction; catalog connectors; clear opt-in for personalization; guardrails against bias/excessive profiling.
- Financial advisory assistant with persistent client context
- Sector: Finance/Wealth Management
- Workflow: Maintain KG of risk tolerance, constraints, holdings, life events; session summaries for reasoning during calls; audit trail in SQL for compliance; prioritize latest suitability updates via decay weights.
- Tools: Memoria + CRM (Salesforce), portfolio/Risk APIs, compliance logging dashboards.
- Assumptions/Dependencies: Regulatory compliance (KYC/AML, suitability, record-keeping, right to be forgotten); encryption at rest and in transit; consent and disclosure flows.
- IT helpdesk and internal support copilots
- Sector: Enterprise IT/Software
- Workflow: Persist device/software preferences, frequent issues, org/team context; use KG to auto-suggest resolution steps; summarize sessions for escalations; prioritize recent changes (e.g., OS upgrade).
- Tools: Memoria + ServiceNow/Jira/Intune; endpoint telemetry as external knowledge.
- Assumptions/Dependencies: Accurate identity resolution; access control and role-based permissions; PII minimization.
- Adaptive tutoring assistant with learner profiles
- Sector: Education
- Workflow: Track learner goals, misconceptions, progress, and preferred modalities in KG; use session summary for continuity; tailor exercises; resolve updated learning goals via recency weights.
- Tools: Memoria + LMS (Canvas/Moodle), content repositories, analytics dashboards.
- Assumptions/Dependencies: Parental consent for minors; fairness and accessibility; robust summarization to avoid compounding errors.
- Patient-facing triage/chat assistants with longitudinal memory
- Sector: Healthcare
- Workflow: KG captures symptoms, medications, allergies, lifestyle notes; session summaries for recent clinical interactions; on-prem deployment; emphasize latest clinical updates via recency weighting.
- Tools: Memoria (on-prem) + EHR connectors (FHIR), encryption and access controls.
- Assumptions/Dependencies: HIPAA/GDPR compliance; clinical safety guardrails; human-in-the-loop review; secure storage; data retention policy.
- Sales and account management copilots
- Sector: Sales/CRM
- Workflow: Track deal context, stakeholder roles, buying signals; summarize calls; retrieve persona KG before next touchpoint; prioritize recent objections or budget changes in prompts.
- Tools: Memoria + HubSpot/Salesforce, call transcript ingestion (ASR), meeting notes.
- Assumptions/Dependencies: ASR accuracy; CRM data hygiene; clear consent for memory across engagements.
- Developer support/chatops assistant with team preferences
- Sector: Software Engineering
- Workflow: Persist code style, stack choices, env quirks, recurrent errors in KG; summarize debugging sessions; prompt with weighted triplets for faster help; link issues to repos.
- Tools: Memoria + GitHub/GitLab/Jira/Slack integrations; code RAG.
- Assumptions/Dependencies: Secure access to code and logs; avoid leaking secrets in memory; configurable retention and redaction.
- Meeting and call summarization plus memory archiving
- Sector: Enterprise Productivity
- Workflow: Ingest transcripts, auto-summarize action points; extract triplets (owner, deadline, decision); recall context in future meetings; recency resolves changed decisions.
- Tools: Memoria + ASR (Whisper), calendar/task apps (Notion/Todoist/Teams).
- Assumptions/Dependencies: Transcript quality; participant consent; cross-app connectors; memory-edit UI.
- Personalized digital assistant for daily life
- Sector: Consumer Productivity
- Workflow: Maintain KG of preferences (diet, commute, habits), upcoming events; session summaries for continuity; prompt augmentation for reminders, recommendations; prioritize latest routines or constraints.
- Tools: Memoria + mobile app, local vector DB; calendar/email/task integrations.
- Assumptions/Dependencies: Local storage options; controllable memory (review/edit/delete); robust data portability.
- Multilingual customer service with cross-language memory continuity
- Sector: Global Support/Localization
- Workflow: Store triplets independent of language; use language-agnostic embeddings; smooth continuity across languages; recency resolves updated preferences regardless of language.
- Tools: Memoria + multilingual embeddings/models; locale-aware prompts.
- Assumptions/Dependencies: Quality of multilingual embeddings; consistency across translation layers; locale-sensitive content policies.
- Policy-compliant memory logging and audit layer
- Sector: Compliance, Risk & Governance
- Workflow: Use SQL logs and KG metadata to provide auditability (who/what/when); enable deletion requests; track memory provenance; report token usage/cost.
- Tools: Memoria + audit dashboards; retention policy enforcement; DSR (data subject request) workflows.
- Assumptions/Dependencies: Clear governance; role-based access; deletion and redaction capabilities; regulator-ready reporting.
Long-Term Applications
These require further research, scaling, multimodal integration, on-device compute, or policy standardization.
- Cross-application “personal memory layer” (interoperable user KG)
- Sector: Software Ecosystems, Consumer Apps
- Workflow/Product: A unified, user-controlled memory vault shared across assistants (email, calendar, chat, shopping), with access controls and portability.
- Dependencies: Identity federation (SSO), standards for memory schemas/APIs, consent and revocation at app level.
- On-device, privacy-preserving memory assistants
- Sector: Mobile/Edge Computing, Consumer
- Workflow/Product: Local Memoria stack (SQLite + lightweight vector DB + small LLM) running offline; memory never leaves device.
- Dependencies: Efficient on-device embeddings/LLMs; encryption; resource-constrained optimization; battery and storage management.
- Federated and differentially private agentic memory
- Sector: Privacy Tech, Policy
- Workflow/Product: Federated learning to improve memory operations (extraction, weighting) without sharing raw data; DP to bound privacy leakage.
- Dependencies: Robust FL/DP implementations; regulator acceptance; performance–privacy trade-offs.
- Multimodal KGs for voice, vision, and spatial context
- Sector: Robotics, Smart Home, AR/VR
- Workflow/Product: Extract triplets from video/audio/sensor data (e.g., “keys in kitchen drawer”); personalize domestic robots; enable spatial memory and temporal updates.
- Dependencies: Reliable multimodal extraction; device integrations; data volume and storage; safety constraints.
- Memory governance toolkit for regulated industries
- Sector: Finance, Healthcare, Public Sector
- Workflow/Product: Policy packs (retention, minimization, consent UI), explainability of memory usage, compliance dashboards, automated DSR handling.
- Dependencies: Industry-specific regulation mapping; certification; integrations with record-keeping systems.
- Long-horizon autonomous agents powered by memory
- Sector: RPA/Automation, Operations
- Workflow/Product: Agents that plan across weeks/months, leveraging recency-aware KG; chain-of-thought guided by evolving state; multi-session task orchestration.
- Dependencies: Reliability guarantees; perturbation-resilience; standardized evaluation; incident response for failures.
- Memory-aware benchmarks and metrics
- Sector: Academia/Research
- Workflow/Product: New datasets and metrics beyond LongMemEval, including forgetting curves, conflict-resolution accuracy, fairness of personalization, temporal reasoning.
- Dependencies: Human-in-the-loop evaluations; open datasets; standardized scoring protocols.
- Adaptive forgetting and fairness-aware weighting
- Sector: Responsible AI
- Workflow/Product: Tuning decay dynamics (alpha) based on task criticality, fairness constraints, and user-specified preferences; “policy-aware forgetting.”
- Dependencies: Formal fairness criteria; user controls; robust monitoring of unintended discrimination.
- Enterprise “memory bus” for multi-agent collaboration
- Sector: Enterprise Software
- Workflow/Product: Shared KG backbone with row-level ACLs; team and project memories; inter-agent subscriptions to relevant memory shards.
- Dependencies: IAM, data mesh architecture, conflict resolution across agents, auditability.
- Longitudinal health and wellness coaches
- Sector: Healthcare/Consumer Health
- Workflow/Product: Integrate wearables, labs, diaries into KG; personalize interventions; detect drift in habits; consented sharing with clinicians.
- Dependencies: Interoperability (FHIR/HL7), medical oversight, device integrations, safety validations.
- Education-wide learner models and portability
- Sector: Education Policy/EdTech
- Workflow/Product: Cross-institution learner KGs (skills, goals, accommodations) with portability and student ownership; personalized curricula over years.
- Dependencies: Data standards; parental/student consent; equitable access; policy frameworks.
- Suitability and conduct monitoring in financial services
- Sector: Finance/Compliance
- Workflow/Product: Real-time checks leveraging persistent client KG; alerts when recommendations conflict with latest constraints; auditable decision logs.
- Dependencies: Regulator alignment; robust provenance; clear explainability.
- Smart energy and home automation assistants with memory
- Sector: Energy/IoT
- Workflow/Product: Capture household routines, device schedules, tariff preferences; optimize energy usage with updated preferences and seasonal changes.
- Dependencies: IoT integrations; grid/tariff APIs; safety and privacy controls.
Notes on general feasibility across applications:
- Data quality and identity resolution: Correctly linking sessions to users is pivotal; errors propagate through KG and summaries.
- Model dependencies: Triplet extraction and summarization quality depend on LLM choice; open-source alternatives may require tuning.
- Cost/latency trade-offs: Benefits hinge on careful prompt curation and top-K selection; monitoring token usage and response times is essential.
- Governance: Consent, transparency, memory edit/delete, and retention policies must be first-class features, especially in regulated contexts.
- Security: Encryption, access controls, and secure logging are non-negotiable when storing persistent memory containing PII.
- Parameter tuning: Decay rate (alpha) and normalization choices materially affect conflict resolution and personalization outcomes.
Glossary
- A‑Mem: An agentic memory framework for LLM agents that organizes and links memory entries, inspired by Zettelkasten. "AâMem automatically generates structured memory entries with contextual descriptions, tags, and embeddings, then dynamically links new memories to related historical entries and evolves its memory graph over time."
- Agentic memory: A capability enabling LLMs to retain and act on information across interactions like an agent. "Agentic memory refers to the memory that provides an LLM with agent-like persistence: the ability to retain and act upon information across conversations, similar to how a human would."
- all‑MiniLM‑L6‑v2: A SentenceTransformers embedding model used to compute text embeddings. "which employs the all-MiniLM-L6-v2 \cite{reimers-2020-allMiniLM-L6-v2} embedding model from SentenceTransformers."
- ChromaDB: An open‑source vector database for storing and retrieving embeddings with metadata. "KG triplets are embedded and stored in a local instance of ChromaDB\footnote{https://docs.trychroma.com/docs/overview/introduction}, enabling vector-based retrieval with metadata support."
- Context window: An LLM’s limited memory buffer of tokens used for conditioning generation. "can be efficiently reintroduced into the LLM context window."
- Episodic memory: Memory of specific events or interactions enabling recall of user‑specific facts. "Episodic memory\cite{tulving1972episodic,zhang2024survey} encapsulates the agentâs ability to recall specific past interactions or events."
- Exponential decay function: A weighting function that reduces influence of older items exponentially. "These triplets are further weighted in real time using an exponential decay function, giving higher priority to more recent triplets, ensuring that updated preferences or contradictions are resolved contextually."
- Exponential Weighted Average (EWA): A scheme assigning exponentially decaying weights to data points to emphasize recency. "To dynamically prioritize KG triplets based on their recency, we apply an Exponential Weighted Average (EWA) scheme."
- GPT‑4.1‑mini: An OpenAI LLM variant used for generation and reasoning. "The underlying LLM used for generation and reasoning tasks is GPT-4.1-mini."
- KG triplets: Structured facts represented as subject–predicate–object used in knowledge graphs. "In SQL for raw representation (subject, predicate, object)."
- Knowledge Graph (KG): A structured graph of entities and relations used to model user traits and preferences. "a weighted knowledge graph (KG)-based user modelling engine that incrementally captures user traits, preferences, and behavioral patterns as structured entities and relationships."
- LangGraph: A LangChain framework for building graph‑structured LLM applications/agents. "Similarly, industrial frameworks such as LangGraph\cite{langgraph2025} and LlamaIndex\cite{llamaindex2024} have begun adopting summarization, vector retrieval, and graph-based profiling."
- LLM as a judge: An evaluation paradigm using an LLM to assess outputs against ground truth. "All experiments were conducted using GPT-4.1-mini as the LLM backend and evaluated with ground truth using LLM as a judge."
- LlamaIndex: A data framework for LLM apps supporting summarization, retrieval, and graph profiling. "Similarly, industrial frameworks such as LangGraph\cite{langgraph2025} and LlamaIndex\cite{llamaindex2024} have begun adopting summarization, vector retrieval, and graph-based profiling."
- LongMemEvals dataset: A benchmark dataset for assessing long‑term memory in chat assistants. "the LongMemEvals dataset\cite{wu2024longmemeval}, which is designed to benchmark memory-augmented LLM systems in realistic business-oriented settings."
- Min‑max normalization: Rescaling values to a fixed range (e.g., [0,1]) to stabilize weighting. "By applying min-max normalization across all triplets:"
- Ontologies: Formal representations of knowledge domains defining concepts and relations. "integrating external knowledge sources such as knowledge bases, ontologies, or APIs."
- Parametric memory: Knowledge captured in an LLM’s parameters during pre‑training; static and not user‑adaptive. "Parametric Memory~\cite{zhang2024survey} refers to the knowledge encoded in the parameters of a LLM during pre-training."
- Prompt augmentation: Adding retrieved or summarized context to prompts to personalize responses. "Prompt Augmentation: The application developer has access to these triplets from the first interaction of the session itself, enabling immediate personalization based on known preferences, interests, or past topics."
- Retrieval Augmented Generation (RAG): A technique that augments LLMs with external retrieved information during generation. "Recent work on external memory such as Retrieval Augmented Generation (RAG), summarization, and memory graphs aims to bridge short- and long-term context."
- Semantic memory: Structured factual knowledge and taxonomy available to the model for grounding responses. "Semantic memory\cite{tulving1972episodic,zhang2024survey} represents the modelâs capacity to access and utilize structured, factual knowledge, including historical data, general world knowledge, domain-specific definitions, and taxonomic relationships."
- Semantic similarity: Embedding‑based similarity used to retrieve relevant items by meaning. "the summary and the top-K triplets (retrieved via semantic similarity from vector DB) filtered for the user basis user name are retrieved."
- SentenceTransformers: A library of transformer‑based models for computing sentence embeddings. "which employs the all-MiniLM-L6-v2 \cite{reimers-2020-allMiniLM-L6-v2} embedding model from SentenceTransformers."
- Temporal KGs: Knowledge graphs that capture the evolution of facts over time. "Batching user interactions into temporal KGs, as done in Ref.~\cite{rasmussen2025zep}, demonstrates a practical pathway for capturing evolving user states."
- Temporal reasoning: Reasoning involving time, sequence, and change across events. "temporal-reasoning."
- Token constraints: Limits on the number of tokens an LLM can process in its context. "while operating within the token constraints of modern LLMs."
- Token overhead: Extra tokens included in prompts that increase cost and latency. "significantly reducing token overhead by avoiding full-history prompting."
- Top‑K matching: Selecting the K most similar items by a ranking metric (e.g., semantic similarity). "During retrieval, we apply semantic top- matching with ."
- Vector database: A database optimized for embedding vectors and similarity search. "in a vector database along with relevant metadata used for filtering relevant set of triplets."
- Vector embeddings: Numeric representations of text or triplets in a vector space for retrieval. "These triplets are embedded as dense vectors and stored in a vector database, along with metadata such as timestamps, user name and source message references etc."
- Vector store: A storage system for embeddings enabling nearest‑neighbor retrieval. "Vector stores lack interpretability and conflict resolution, while graph-based systems struggle with recency and scalability."
- Working memory: Short‑term memory capacity used for ongoing reasoning and multi‑step tasks. "Working memory\cite{baddeley2020working,zhang2024survey} refers to the short-term memory capacity that supports ongoing reasoning, multi-step problem solving, and temporary information retention during active tasks."
- Zettelkasten: A note‑taking method that organizes atomic notes and their links, inspiring memory architectures. "AâMEM\cite{xu2025mem}, inspired by Zettelkasten note-taking~\cite{luhmann1992communicating}, introduces graph-like memory structures that link atomic notes with contextual descriptors, enabling dynamic memory evolution beyond flat storage systems."
Collections
Sign up for free to add this paper to one or more collections.

