Cold-Start Personalization via Training-Free Priors from Structured World Models
Abstract: Cold-start personalization requires inferring user preferences through interaction when no user-specific historical data is available. The core challenge is a routing problem: each task admits dozens of preference dimensions, yet individual users care about only a few, and which ones matter depends on who is asking. With a limited question budget, asking without structure will miss the dimensions that matter. Reinforcement learning is the natural formulation, but in multi-turn settings its terminal reward fails to exploit the factored, per-criterion structure of preference data, and in practice learned policies collapse to static question sequences that ignore user responses. We propose decomposing cold-start elicitation into offline structure learning and online Bayesian inference. Pep (Preference Elicitation with Priors) learns a structured world model of preference correlations offline from complete profiles, then performs training-free Bayesian inference online to select informative questions and predict complete preference profiles, including dimensions never asked about. The framework is modular across downstream solvers and requires only simple belief models. Across medical, mathematical, social, and commonsense reasoning, Pep achieves 80.8% alignment between generated responses and users' stated preferences versus 68.5% for RL, with 3-5x fewer interactions. When two users give different answers to the same question, Pep changes its follow-up 39-62% of the time versus 0-28% for RL. It does so with ~10K parameters versus 8B for RL, showing that the bottleneck in cold-start elicitation is the capability to exploit the factored structure of preference data.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
Imagine asking an AI, “I have a headache, what should I do?” The “right” answer depends on you. A pregnant person needs to avoid certain medicines; a runner racing tomorrow might want fast relief. The problem is that, at the start, the AI knows none of this. This is called “cold start” personalization: helping someone when you don’t yet know their preferences.
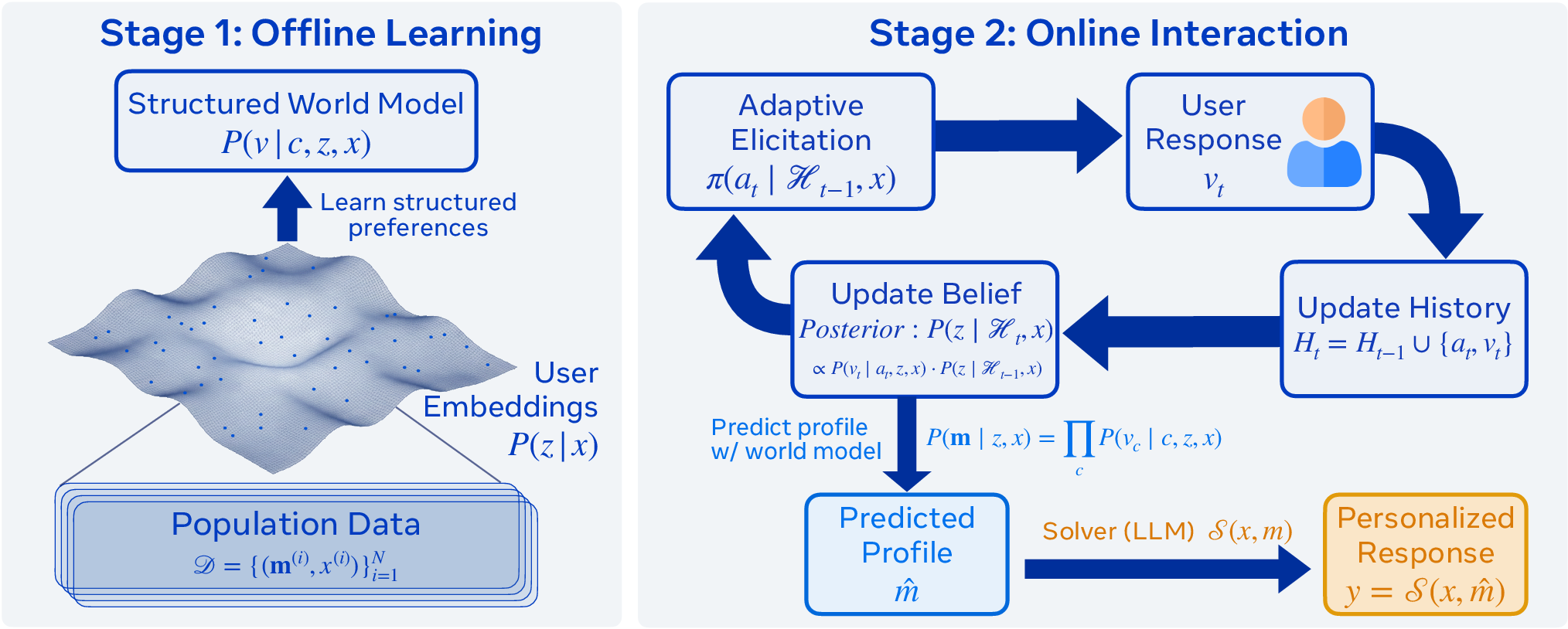
This paper introduces Pep (Preference Elicitation with Priors), a method that asks a few smart questions to quickly figure out what you care about, then gives a response tailored to you. Pep learns general patterns about people’s preferences ahead of time, and then, during a conversation, updates its guesses based on your answers—no extra training needed during the chat.
The main questions the researchers asked
The authors focused on three simple-but-important questions:
- Can an AI learn a “map” of how different preferences usually go together (for example, people who want safer medication advice often also want a gentler tone), and then use that map to ask better questions?
- If the AI separates this “map-learning” from the actual conversation, does it do better than training one big system end-to-end with reinforcement learning (RL)?
- Will this approach reduce how many questions the AI must ask while still giving better, more personalized answers?
How the method works (in everyday terms)
Think of Pep like a detective with two phases:
- Learn the world before the conversation (offline)
- The AI studies many complete “preference profiles” from past users and tasks. These profiles say which aspects people cared about (for example, tone, safety, level of detail) and what choices they made.
- From this, it builds a “structured world model”—basically a map of how preferences are connected. For instance, it learns that users who value safety often prefer clear, reassuring explanations.
- Use the map during the conversation (online, no training needed)
- At the start of a new chat, the AI has a starting guess (a “prior”) about your preferences based on what it learned before.
- As you answer a question, the AI updates its belief using Bayesian reasoning: start with a guess, see evidence (your answer), then adjust the guess. You can think of it like updating a sports prediction after seeing a team’s first few plays.
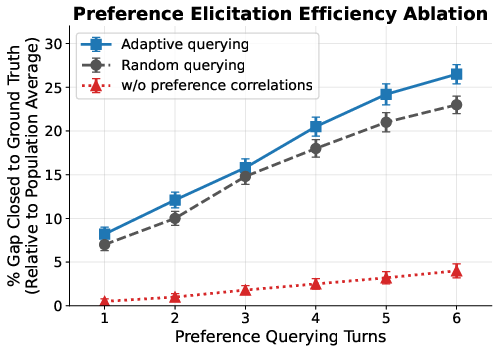
- It picks the next question that will teach it the most about you (this is called “information gain”). For example, asking whether you prefer a formal or casual tone might also tell it how much structure or detail you’ll want.
- After a few questions (the paper uses a budget of 5), the AI predicts your full preference profile, including parts it didn’t ask about, then feeds that profile into a separate LLM to write the final response in the style you like.
A helpful analogy:
- Preferences are like many knobs on a control panel (tone, detail, safety, speed, etc.). Most people only care about 2–4 knobs for any given task. Pep uses its learned map to twist the most revealing knobs first—because turning one knob often hints at where others should be set.
What about reinforcement learning (RL)?
- The authors show that training a model end-to-end with RL for multi-turn questioning often struggles: it only gets a final “score” after all questions and the final answer, so it’s hard for it to know which specific questions helped. In practice, the RL policies they tested often fell back to asking the same sequence of questions to everyone, ignoring what users said.
What they found and why it matters
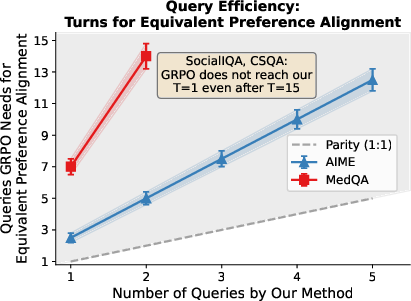
Across four areas—medical questions (MedQA), math problems (AIME), commonsense (CSQA), and social reasoning (SocialIQA)—Pep did better than strong RL baselines and other methods, while asking fewer questions.
Key results:
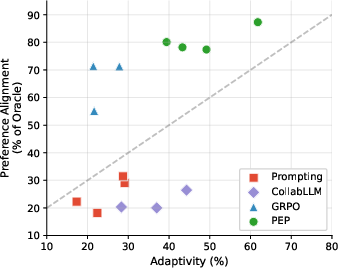
- Better personalization: Pep reached about 80.8% alignment with users’ stated preferences on average, compared to 68.5% for the RL method they tested.
- Fewer questions: Pep achieved similar or better alignment using 3–5 times fewer interactions.
- More adaptive: When two users gave different answers to the same question, Pep changed its next question 39–62% of the time; the RL system did so only 0–28% of the time. In other words, Pep actually listened and pivoted.
- Much smaller model: Pep’s belief model used around 10,000 parameters, compared to about 8 billion for the RL system—showing that a clear structure and good use of prior knowledge can beat sheer size.
Why this matters:
- Asking fewer, smarter questions means a better user experience—faster, more relevant help.
- The method is modular: it can work with any LLM to write the final answer, and it doesn’t need to retrain during a conversation.
- In sensitive areas (like medical advice), discovering the right preference early (e.g., pregnancy constraints) can be safety-critical.
What this could change going forward
Pep shows that personalization isn’t just about big models; it’s about using structure and smart questioning. By learning how preferences relate ahead of time and then updating beliefs on the fly, systems can:
- Personalize quickly, even with new users and new tasks.
- Reduce the risk of one-size-fits-all answers that miss important needs.
- Be more transparent and efficient: ask only what’s needed, then deliver.
The authors also note future directions, like handling open-ended, natural-language questions and answers (not just pre-defined criteria), discovering new preference dimensions automatically, and making sure the learned maps don’t reflect or reinforce social biases.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to support actionable follow-up work:
- Reliance on predefined criteria and values: No mechanism to automatically discover or refine task-specific preference dimensions and value sets from free-form text or interaction; develop unsupervised/weakly supervised methods to induce and update and for new tasks.
- Training data assumptions: The world model requires complete per-criterion profiles during training; investigate learning from partial, noisy, inconsistent, or weak labels, including semi-supervised and self-supervised formulations.
- Robustness to misspecification and shift: The Bayesian posterior and information gain depend on correct priors; evaluate sensitivity to model misspecification, domain/task shift, and subpopulation drift, with calibration diagnostics, posterior auditing, and safe fallback policies.
- Model expressiveness: Only Bayesian linear regression and Gaussian mixtures are explored; assess richer latent structures (hierarchical models, nonlinear embeddings, VAEs, topic or graph models) and their tractable uncertainty/MI computations.
- Cost-aware acquisition: Question selection optimizes entropy/MI but ignores user burden, latency, risk, and safety; design cost-sensitive, multi-objective acquisition that balances alignment gains with user fatigue and risk constraints.
- Solver modularity stress tests: Claims of modularity are evaluated with a single solver (GPT-4.1) and prompt; test robustness across solvers (open-source, tool-using, domain-specific) and prompts to quantify sensitivity and downstream variance.
- Human-in-the-loop validation: Experiments use passive simulated users; run user studies measuring satisfaction, perceived intrusiveness, correction flows, and longitudinal outcomes, including evolving preferences across sessions.
- Evaluation metric reliability: PrefAlign relies on an LLM judge; expand human validation at scale and cross-judge comparison, and complement with outcome-based metrics (task success, safety incidents), especially for MedQA.
- Scalability with large criteria sets: IG/entropy selection enumerates remaining criteria; quantify computational scaling when and develop approximate, batched, or submodular selection methods.
- Criteria construction pipeline: PrefDisco provides ; specify and evaluate automatic criteria generation for unseen tasks (ontology induction, schema learning, distillation from solver behavior).
- Mapping profiles to generation: The solver uses without a formal control policy; study how to translate profiles into generation constraints, resolve conflicts among criteria, and guarantee adherence to safety-critical preferences.
- Adaptivity metrics: Current metric tracks whether the next question changes; design causal/adversarial tests linking adaptivity to alignment gains, and measure meaningful adaptation vs superficial question changes.
- Baseline breadth and fairness: RL baseline is GRPO on Llama-3.1-8B; compare against model-based RL, POMDP planning, hierarchical RL, and RL with dense intermediate rewards or factored critics; ensure matched compute/hyperparameters.
- Sample complexity guarantees: Proposition is abbreviated; provide full proofs with assumptions, tight bounds, and empirical scaling studies across and horizon .
- Privacy-preserving training: Beyond test-time locality, evaluate privacy risks (inference leakage, membership inference) and integrate differential privacy or federated training for the world model.
- Bias detection and mitigation: Quantify demographic/subgroup disparities in priors and elicitation sequences; incorporate fairness-aware training and acquisition (e.g., constraints, reweighting, counterfactual evaluation).
- Natural-language elicitation: Selected criteria are asked via structured prompts; develop generation policies that realize criteria in conversational phrasing, measure user acceptance/comprehension, and handle pragmatic nuance.
- Handling inconsistent/strategic users: Posterior updates assume honest, consistent answers; design robustness to contradictory, adversarial, or low-quality responses, including confirmation questions and uncertainty-aware stopping.
- Cross-task/meta-generalization: Priors are task-conditioned but trained per domain; investigate meta-learning to transfer preference structure across tasks, zero-shot elicitation for unseen tasks, and continual adaptation.
- Adaptive stopping and budgets: Fixed turns in experiments; implement confidence-based stopping rules and evaluate trade-offs between interaction cost and alignment gains.
- Tool-use integration: Examine how inferred preferences guide tool selection (e.g., calculators, medical references) and whether tool-augmented solvers improve alignment and safety.
- Preference granularity and continuity: Current values are categorical/ordinal; support continuous preferences, multi-label criteria, and dynamic granularity refinement (zoom-in questioning on ambiguous dimensions).
- Safety guarantees in sensitive domains: Formalize and verify risk controls for medical and safety-critical contexts (e.g., hard constraints, counterfactual checks, fail-safe responses when uncertainty is high).
- Multilingual and cross-cultural generalization: Assess how priors and elicitation perform across languages and cultural contexts, including multilingual criteria induction and cross-lingual calibration.
- User education and preference formation: The system does not help users articulate unknown needs; explore preference scaffolding, explanations, and value clarification while avoiding reward hacking or manipulation.
Practical Applications
Overview
This paper introduces Pep, a training-free, modular framework for cold-start personalization that learns population-level correlations among preference dimensions offline and performs online Bayesian inference to elicit and predict a user’s full preference profile in just a few turns. It consistently improves alignment vs. RL-based policies while using far fewer interactions and orders-of-magnitude fewer parameters. Below are actionable applications derived from Pep’s findings, methods, and innovations, grouped by deployment horizon.
Immediate Applications
The following applications can be deployed now using Pep’s structured priors, Bayesian updates, and plug-and-play design with existing LLMs or domain-specific solvers. Each bullet lists sector, use case, potential tools/products/workflows, and key assumptions/dependencies.
- Healthcare: safety-aware clinical clarification before guidance
- What: Brief, adaptive elicitation to surface contraindications, urgency, and context (e.g., pregnancy, comorbidities, timelines) prior to recommending OTC drugs or self-care steps.
- How: Embed Pep as a “Clinical Clarifier” in symptom-checkers, telehealth chat, and patient portals; pass the predicted profile to a medical LLM/solver.
- Tools/products: EHR-integrated clarifying widget; SDK for digital health apps; compliance logging dashboard.
- Dependencies/assumptions: Clearly defined criteria (e.g., pregnancy status, medication sensitivities); validated priors from representative populations; medical governance (safety, disclaimers); consent and privacy controls.
- Education: rapid onboarding for AI tutors and course assistants
- What: Cold-start elicitation of learning preferences (rigor vs. intuition, step-by-step depth, pacing, tone) tailored per subject/task.
- How: Add Pep to tutoring chatflows; use information-gain selection to ask ~3–5 questions and pass the inferred profile to the tutor.
- Tools/products: “Adaptive Onboarding” module for edtech LMS; Tutor Persona Profiles; analytics for instructional designers.
- Dependencies/assumptions: Curated per-subject criteria; a capable tutor model; appropriate consent for use of population priors.
- Software/DevTools: developer onboarding assistants
- What: Configure coding assistants (verbosity, language level, test-first vs. code-first, style preferences) in minimal turns.
- How: Pep-integrated IDE extension that elicits preferences and stores a task-conditioned developer profile.
- Tools/products: Plugin for VS Code/JetBrains; profile-to-prompt pipeline for code LLMs; admin console for team policies.
- Dependencies/assumptions: Defined criteria taxonomy per language/toolchain; secure storage of profiles; support for team vs. individual defaults.
- Enterprise/Customer Support: adaptive triage and resolution style
- What: Determine resolution preferences (speed vs. thoroughness), tone, and channel upfront to reduce back-and-forth.
- How: Pep front-end in chatbots and ticket portals; inferred profile conditions response templates or LLM solvers.
- Tools/products: Contact center “Personalization Prior” service; low-turn triage forms; customer success dashboards.
- Dependencies/assumptions: Domain-specific criteria (e.g., compliance needs, technical depth); data minimization and opt-in.
- E-commerce & Media: cold-start conversational personalization
- What: Ask a few high-yield questions to infer style/fit/taste dimensions, then personalize recommendations and copy tone.
- How: Pep drives adaptive questioning; feed predicted profile to ranking/LLM copy generation.
- Tools/products: “Preference Primer” for new users; profile-to-ranking bridge; A/B test harness for query budgets.
- Dependencies/assumptions: Well-defined, task-specific criteria per category; safeguards against biased priors; clear user consent.
- Finance (non-advisory guidance): fast preference elicitation for explainer tools
- What: Infer preferred explanation style (risk framing, glossary depth, visual vs. textual) for educational finance assistants.
- How: Pep layer elicits profile; solver generates tailored educational content or form guidance (not investment advice).
- Tools/products: Banking/fintech FAQ assistants; preference-aware document explainer.
- Dependencies/assumptions: Carefully scoped, non-advisory use; compliance review; criteria vetted for fairness.
- Public sector & policy operations: smarter digital intake and forms
- What: Adaptive, low-burden clarifying questions that infer needs (translation, accessibility, guidance level) for government services.
- How: Pep powers short adaptive interviews before form completion; pass profiles to rules engines or content templates.
- Tools/products: “Adaptive Intake” widget for online portals; accessibility persona inference; audit-ready logs.
- Dependencies/assumptions: Approved criteria (accessibility, literacy level); privacy protections; transparency for personalization.
- Research & Academia: methodology and evaluation tooling
- What: Use Pep to study preference correlations, simulate elicitation policies, and benchmark interactive systems with fewer trials.
- How: Incorporate Pep into IRB-approved user studies to reduce subject burden; evaluate adaptivity vs. alignment tradeoffs.
- Tools/products: Open-source Pep library; experiment harness with rubric-based judges; dataset templates for criteria design.
- Dependencies/assumptions: Availability of complete profiles to learn priors; domain-specific criteria definition; ethical use and data governance.
- Daily-life digital assistants: “just-in-time” personalization
- What: Quickly infer preferred tone, brevity, and next-step style (checklist vs. narrative) for routine tasks (planning, reminders).
- How: Pep runs on first interaction or when task shifts; predicted profile conditions assistant prompts.
- Tools/products: Mobile assistant preference module; on-device inference for privacy; quick reset/override UX.
- Dependencies/assumptions: Lightweight, on-device BLR/GMM feasible; user controls for consent and correction.
Long-Term Applications
These applications require further research, scaling, or productization—especially in free-form elicitation, automated criteria discovery, longitudinal adaptation, or safety-critical integration.
- Natural language elicitation without predefined criteria
- What: Move from fixed criteria catalogs to open-ended, free-form questions and answers while retaining Bayesian tractability.
- How: Learn latent ontologies and extract structured slots from natural language; approximate posteriors with variational methods.
- Potential products: “Free-form Personalizer” for general assistants; ontology learner for new domains.
- Dependencies/assumptions: Robust extraction of preferences from text; stability of latent structures; calibration of uncertainty.
- Automatic discovery of preference dimensions
- What: Unsupervised/semi-supervised discovery of new criteria from user interactions/data, updating the world model over time.
- How: Clustering/representation learning over interaction logs; active proposals for candidate criteria.
- Potential products: Criteria discovery consoles; governance workflows for human vetting.
- Dependencies/assumptions: Sufficient and representative interaction data; safeguards against spurious or biased dimensions.
- Longitudinal personalization across sessions and tasks
- What: Evolve user profiles over time, handle drift, and disambiguate global vs. task-specific preferences.
- How: Hierarchical Bayesian models with per-user priors; session-aware updates; decay mechanisms for stale preferences.
- Potential products: Cross-app preference vaults; federated or on-device personalization stores.
- Dependencies/assumptions: Consent-based profile persistence; privacy-preserving storage (e.g., on-device/federated).
- Safety-critical decision support with formal guardrails
- What: Integrate Pep into clinical decision support, legal drafting assistants, or aviation maintenance workflows to ensure mandatory clarifications before actions.
- How: Couple information-gain elicitation with policy constraints (must-ask criteria sets); formal verification of elicitation coverage.
- Potential products: Safety-gated elicitation engines; conformance checking and audit trails.
- Dependencies/assumptions: Regulator-approved criteria; rigorous validation; human-in-the-loop oversight.
- Human–robot interaction (HRI): preference-aware task execution
- What: Robots infer operator preferences (speed vs. precision, autonomy level, communication style) with a few questions before tasks.
- How: On-device Pep for real-time adaptation; shared autonomy controllers conditioned on inferred profiles.
- Potential products: Robotic onboarding routines; operator preference capsules.
- Dependencies/assumptions: Real-time Bayesian updates on constrained hardware; safe exploration limits; clear operator consent.
- Smart homes and energy management
- What: Cold-start elicitation of comfort/efficiency tradeoffs and schedule sensitivities for thermostats, EV charging, and appliance automation.
- How: Pep-driven quick setup; profile informs control policies; optional continual refinement.
- Potential products: “Energy Persona” setup wizards; adaptive comfort controllers.
- Dependencies/assumptions: Interoperability with control systems; user education and opt-in; fairness across household members.
- Finance (advisory-grade) and insurance personalization
- What: High-stakes elicitation of risk tolerance, restrictions, and horizon prior to advice or coverage personalization.
- How: Pep combined with regulated KYC/risk questionnaires and auditor-approved priors; human review for edge cases.
- Potential products: Advisory “Preference Gate” modules; audit-ready logs and explanations.
- Dependencies/assumptions: Regulatory clearance; rigorous bias assessment; transparent explanations and user confirmation.
- Organizational policy and procurement standards for AI personalization
- What: Codify best practices for minimal-turn, adaptive, privacy-preserving elicitation as a required capability for enterprise AI.
- How: Reference architectures using Pep-style priors; standard metrics (adaptivity, alignment per-user).
- Potential products: Compliance checklists; certification programs; procurement templates.
- Dependencies/assumptions: Sector-wide consensus on criteria and metrics; cross-vendor interoperability.
- Privacy-first, federated preference learning
- What: Learn/upkeep priors and posteriors without centralizing raw interactions via federated or on-device learning/updating.
- How: Federated updates to world models; local posteriors updated on-device; differential privacy for population priors.
- Potential products: Federated Priors Service; on-device Pep runtime.
- Dependencies/assumptions: Communication-efficient updates; privacy budgets; representative federation.
Cross-Cutting Assumptions and Dependencies
- Criteria availability and quality: Immediate deployments presuppose task-specific criteria sets with well-defined value options, validated for clarity and coverage.
- Data for priors: Population-level, complete preference profiles are needed to learn reliable priors; representativeness is essential to avoid bias.
- Solver quality: Pep conditions a downstream solver; end-to-end user experience depends on solver capability and prompt integration.
- User interaction budget: Benefits are largest when interaction turns are limited; UX should support 3–5 high-yield questions.
- Privacy and consent: Users should be informed when preferences are inferred; opt-in, correction, and reset mechanisms should be available.
- Evaluation and monitoring: Adopt alignment and adaptivity metrics; monitor for bias, drift, and failure cases; enable quick rollback of priors.
By integrating a lightweight prior-and-update module like Pep into onboarding or first-contact flows, organizations can achieve higher personalization quality with fewer user interactions, while preserving modularity, privacy, and governance.
Glossary
- Adaptivity: The extent to which the questioning strategy changes based on user responses in multi-turn elicitation. Example: "Adaptivity: percent of cases where different user responses lead to different follow-up questions (higher is better) over 20 trials."
- Bayesian inference: A probabilistic method that updates beliefs (posteriors) from priors using observed data; here used to infer user preferences without additional training. Example: "then performs training-free Bayesian inference online to select informative questions and predict complete preference profiles, including dimensions never asked about."
- Bayesian Linear Regression: A linear regression model with a Bayesian treatment of parameters, enabling uncertainty-aware predictions. Example: "Example 1: Bayesian Linear Regression."
- Belief model: A model that maintains and updates a posterior over a user’s latent preferences as interactions proceed. Example: "The belief model maintains a posterior over user preferences given interaction history."
- Closed-form posteriors: Posterior distributions that can be computed analytically without numerical approximation. Example: "Both models admit closed-form posteriors"
- Cold-start personalization: Personalization when no user-specific history is available, requiring preference inference through interaction. Example: "Cold-start personalization requires inferring user preferences through interaction when no user-specific historical data is available."
- Collaborative filtering: A technique that leverages population-level patterns to infer individual preferences from partial observations. Example: "Collaborative filtering exploits analogous structure in recommender systems"
- Credit assignment: The challenge of determining which earlier actions in a sequence contributed to observed rewards. Example: "the agent must solve credit assignment across all sequential decisions"
- Direct Preference Optimization (DPO): An alignment method that optimizes models directly on preference comparisons, typically offline. Example: "RLHF and DPO align to aggregated preferences without interactive discovery."
- Entropy (marginal entropy): An information-theoretic measure of uncertainty in a distribution; used to select the most uncertain criterion. Example: "The criterion with highest marginal entropy () is queried:"
- Factored supervision: Supervision that provides per-criterion labels rather than a single aggregated signal, enabling structured learning. Example: "We formalize the distinction between factored and entangled supervision for preference elicitation"
- Gaussian Mixture Model: A probabilistic model that represents data as a mixture of Gaussian components; here, user types. Example: "Example 2: Gaussian Mixture Model."
- GRPO: A reinforcement learning algorithm used to train question policies with terminal rewards. Example: "GRPO: Llama-3.1-8B-Instruct given criteria descriptions and preference level descriptions trained with GRPO"
- Information gain: The expected reduction in uncertainty about latent variables from observing an answer to a query. Example: "Example 3: Information Gain. The criterion that maximally reduces uncertainty about the latent variable is queried:"
- Latent factor models: Models that explain observed preferences via low-dimensional hidden factors. Example: "using matrix factorization and latent factor models to infer missing ratings from partial observations"
- Latent variable: An unobserved variable capturing user-specific traits that induce correlations among observed preferences. Example: "We assume a latent variable (user embedding) mediates dependencies between criteria, yielding"
- Matrix factorization: Decomposing a user-criterion matrix into low-rank factors to model preferences. Example: "using matrix factorization and latent factor models to infer missing ratings from partial observations"
- Mutual information: A measure of dependence between random variables; used to score query informativeness. Example: "is the mutual information between the response to criterion and the latent ."
- Partially observable Markov decision process (POMDP): A sequential decision framework where the state is hidden and only observations are available. Example: "We formalize this as a partially observable Markov decision process (POMDP):"
- Posterior: The updated probability distribution over latent variables given observed data. Example: "the posterior over the latent variable updates via Bayes' rule:"
- Preference elicitation: The process of querying users to discover their preferences for personalization. Example: "preference elicitation becomes a natural multi-turn reinforcement learning (RL) problem:"
- Preference profile: A structured set of a user’s criteria and their preferred values for a task. Example: "We represent a user's preferences as a profile"
- PrefAlign: A rubric-based evaluation metric that scores how well a response aligns with a user’s preferences. Example: "We use PrefAlign \citep{li2025personalized}, a weighted alignment score"
- Prior: The initial probability distribution over preferences before observing user-specific responses. Example: "we can construct a prior for each criterion"
- Reinforcement learning (RL): Learning to act by maximizing expected reward through interaction; applied here to learning question policies. Example: "Reinforcement learning is the natural formulation,"
- RLHF (Reinforcement Learning from Human Feedback): Training methods that use human preference signals to shape model behavior. Example: "RLHF and DPO align to aggregated preferences without interactive discovery."
- Sample complexity: The number of samples required to learn a policy or model with desired performance. Example: "It admits sample complexity guarantees polynomial in the number of criteria and independent of the interaction budget "
- Structured world model: A learned model capturing correlations among preference dimensions to guide inference and questioning. Example: "learns a structured world model of preference correlations offline from complete profiles"
- Terminal reward: A reward observed only at the end of a multi-turn interaction, not at intermediate steps. Example: "its terminal reward fails to exploit the factored, per-criterion structure of preference data"
- Uncertainty sampling: A query strategy that selects the criterion with the highest predictive uncertainty. Example: "Example 2: Uncertainty Sampling. The criterion with highest marginal entropy"
- Variational methods: Approximate inference techniques that optimize a surrogate objective to estimate posteriors. Example: "otherwise, it can be estimated via sampling or variational methods."
- World model: An internal model of the environment or user structure that supports planning and inference. Example: "An effective elicitation policy requires a world model: knowledge of how preference dimensions correlate across users."
Collections
Sign up for free to add this paper to one or more collections.