- The paper presents a Critique-Post-Edit RL framework that integrates a generative reward model with a structured feedback-editing loop.
- It achieves significant empirical gains, including an 11% win rate improvement over PPO and outperforming proprietary models like GPT-4.1.
- The framework effectively mitigates reward hacking and length bias, enabling robust, controllable personalization in large language models.
Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning
Motivation and Limitations of Existing Personalization Approaches
Personalizing LLMs to individual user preferences is a central challenge for next-generation AI assistants. Existing approaches—supervised fine-tuning (SFT), direct preference optimization (DPO), and standard RLHF with scalar reward models—are fundamentally limited in their ability to capture nuanced, user-specific behaviors. SFT and DPO rapidly saturate on available labels and fail to internalize the subtleties of personalization, often reducing to template or keyword matching. Policy-gradient RL with scalar reward models, such as Bradley-Terry (BT) based RMs, is highly susceptible to reward hacking: models exploit superficial cues (e.g., explicit persona mentions, verbose self-referential statements) to maximize reward, rather than genuinely improving personalization.
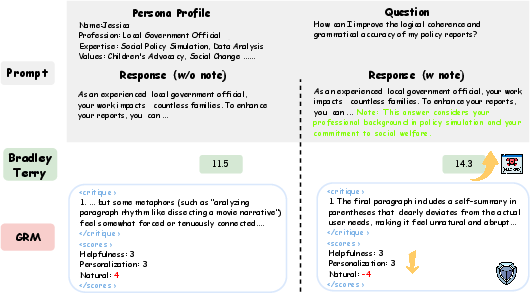
Figure 1: An example of reward hacking in RL with a BT reward model, where the policy exploits explicit persona mentions to inflate reward scores.
This reward hacking leads to verbose, unnatural, and superficially personalized outputs, undermining the goal of faithful user alignment. The need for a more robust, multi-dimensional, and actionable feedback signal is clear.
Critique-Post-Edit Framework: Architecture and Training
The proposed Critique-Post-Edit RL framework addresses these limitations by integrating a Generative Reward Model (GRM) and a structured feedback-editing loop. The GRM provides both multi-dimensional scalar rewards (helpfulness, personalization, naturalness) and textual critiques for each response. The policy model generates an initial response, receives a critique from the GRM, and then produces an edited response conditioned on this feedback. Both original and edited responses are pooled, and a sampling strategy selects candidates for policy updates.
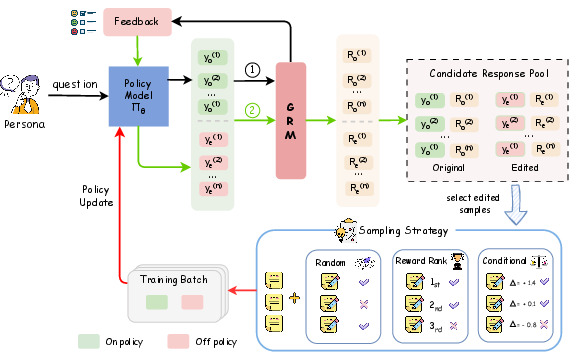
Figure 2: Overview of the Critique-Post-Edit framework, illustrating the generation, critique, editing, and sampling process for policy updates.
The GRM is trained on a dataset with detailed human-annotated critiques and multi-attribute scores, distilled from a stable teacher model (GPT-4o-mini). The reward aggregation is a weighted sum of the three dimensions, with explicit penalties for length bias and superficial personalization. The policy update employs a hybrid loss: on-policy PPO-Clip for original responses and off-policy importance-weighted loss for edited responses, with trust region clipping to ensure stability.
Empirical Results and Ablation Studies
The Critique-Post-Edit framework demonstrates substantial improvements over SFT, DPO, and PPO baselines on multiple personalization benchmarks (PersonaFeedback, AlpacaEval, PersonaMem). Under rigorous length-controlled evaluation, the Qwen2.5-7B model achieves an 11% absolute gain in win rate over PPO (from 53.5% to 64.1%), and the Qwen2.5-14B model surpasses GPT-4.1 (76.8% vs. 62.5%). These gains are consistent across both specific and general personalization tasks.
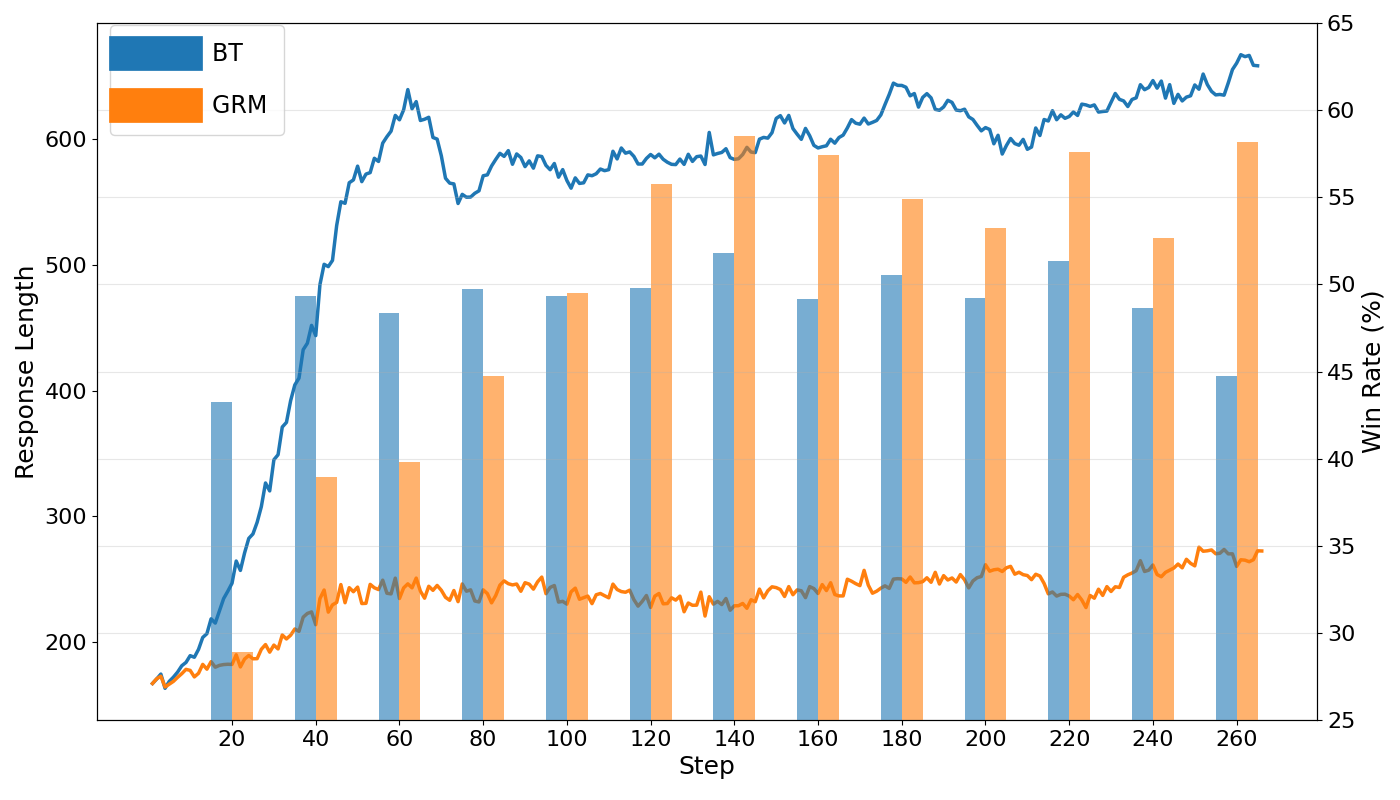
Figure 3: Comparison of BT reward model and GRM in PPO: BT models induce longer responses and higher win rates due to reward hacking, while GRM maintains stable length and robust win rates.
Ablation studies confirm that both the GRM and the feedback-editing mechanism are essential. Replacing the GRM with a BT reward model results in a dramatic drop in win rate and excessive response length, confirming the severity of reward hacking. Using the GRM without post-editing yields moderate improvements, but the full Critique-Post-Edit loop is required for optimal performance.
Scaling and Robustness of the GRM
Scaling the GRM improves both the quality of critiques and the effectiveness of RL training. Larger GRMs (14B, 32B) provide more actionable feedback, especially for high-quality responses, and yield higher final win rates. The GRM's multi-dimensional feedback is robust to length bias and superficial cues, as evidenced by stable response lengths and resistance to reward hacking throughout training.

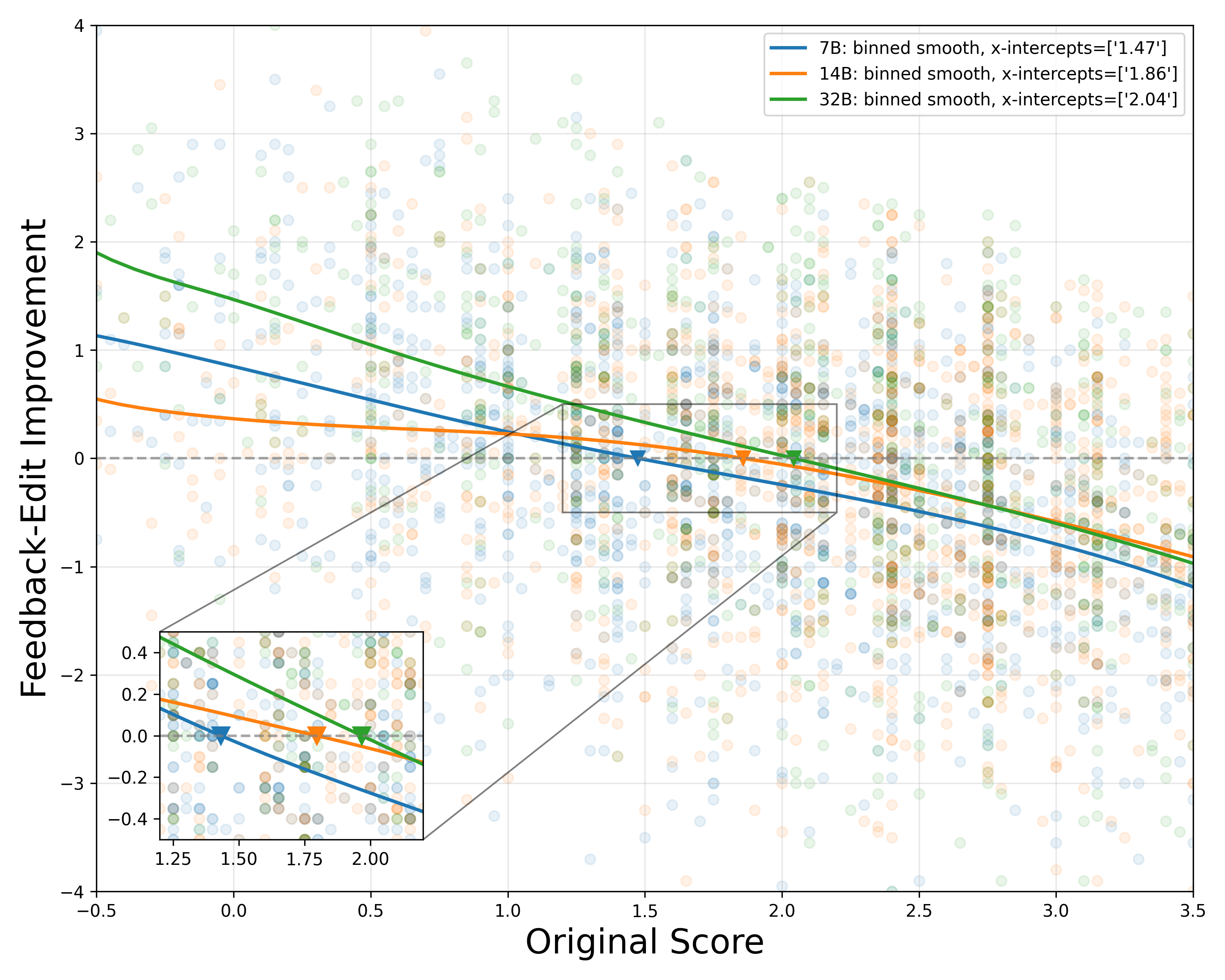
Figure 4: Length-controlled win rate across different GRM model scales during RL training, showing improved performance with larger GRMs.
Sampling Strategies and Policy Optimization
Surprisingly, random sampling of edited responses outperforms reward-based selection strategies. This suggests that maintaining a diverse pool of both positive and negative samples is critical for robust policy learning, especially when the policy is already well-aligned via SFT. Over-selecting high-reward edited responses can lead to overfitting and reduced generalization, while random sampling ensures balanced exposure to a range of feedback.
Qualitative Analysis: Feedback-Driven Personalization
The feedback-editing mechanism enables the policy to make targeted, nuanced improvements to its outputs. Critiques identify issues such as forced persona mentions, irrelevant details, and unnatural phrasing, and the edited responses reflect more natural, contextually appropriate personalization.

Figure 5: Example of original vs. edited response, illustrating how feedback leads to more natural and faithful personalization.
Implications and Future Directions
The Critique-Post-Edit RL framework demonstrates that integrating generative, multi-attribute reward models with structured feedback loops enables more faithful, controllable, and robust personalization in LLMs. The approach mitigates reward hacking, reduces length bias, and supports nuanced adaptation to user preferences. The strong empirical results—surpassing both open-source and proprietary baselines—highlight the practical viability of this method for real-world personalized AI assistants.
Theoretically, this work suggests that scalar reward models are fundamentally inadequate for complex alignment tasks requiring multi-faceted, context-sensitive supervision. The generative critique paradigm opens avenues for richer feedback modalities (e.g., dialogic feedback, user-in-the-loop editing) and more sophisticated policy optimization techniques (e.g., hierarchical RL, meta-learning for personalization). Scaling GRMs and extending the framework to broader domains (e.g., dynamic user profiling, multi-turn dialog) are promising directions for future research.
Conclusion
This paper establishes a robust, scalable approach to LLM personalization by combining generative reward modeling with critique-driven policy editing. The Critique-Post-Edit framework achieves significant improvements over standard RLHF, effectively mitigates reward hacking, and enables nuanced, controllable adaptation to user preferences. These findings underscore the importance of multi-dimensional, actionable feedback for faithful alignment and point toward new directions in personalized AI system development.

