Causal-JEPA: Learning World Models through Object-Level Latent Interventions
Abstract: World models require robust relational understanding to support prediction, reasoning, and control. While object-centric representations provide a useful abstraction, they are not sufficient to capture interaction-dependent dynamics. We therefore propose C-JEPA, a simple and flexible object-centric world model that extends masked joint embedding prediction from image patches to object-centric representations. By applying object-level masking that requires an object's state to be inferred from other objects, C-JEPA induces latent interventions with counterfactual-like effects and prevents shortcut solutions, making interaction reasoning essential. Empirically, C-JEPA leads to consistent gains in visual question answering, with an absolute improvement of about 20\% in counterfactual reasoning compared to the same architecture without object-level masking. On agent control tasks, C-JEPA enables substantially more efficient planning by using only 1\% of the total latent input features required by patch-based world models, while achieving comparable performance. Finally, we provide a formal analysis demonstrating that object-level masking induces a causal inductive bias via latent interventions. Our code is available at https://github.com/galilai-group/cjepa.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Causal-JEPA (C-JEPA), a way for computers to learn “world models”—basically, mental models that predict what will happen next in a scene. Instead of focusing on every pixel, the model looks at scenes as collections of objects (like balls, blocks, and robots) and learns how these objects affect each other. The key idea is to hide some objects during training so the model must figure out their states by looking at the others—this encourages real cause-and-effect reasoning, not shortcuts.
What questions did the researchers ask?
- Can we train a world model that truly learns interactions between objects, not just simple patterns or “self-motion” of each object?
- If we hide (mask) some objects’ information during training, will the model learn to reason about cause and effect?
- Will this help on tasks that need counterfactual thinking (like “What would have happened if the blue ball hadn’t moved?”)?
- Can this make planning for robots both accurate and much faster, using far fewer features?
How did they do it?
Here’s the approach in everyday terms:
Seeing the world as objects
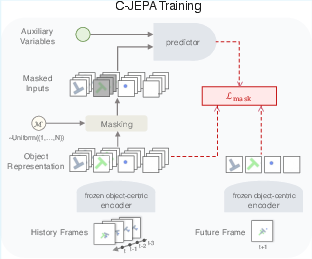
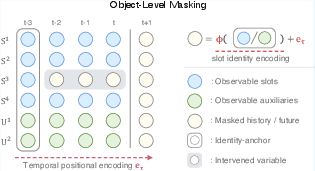
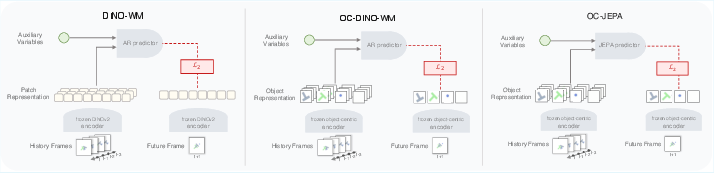
- First, each video frame is turned into a small set of “object slots.” Think of each slot as a compact summary of one object (its identity, position, etc.). This comes from an object encoder (like Slot Attention with VideoSAUR or SAVi).
- This is more efficient than using lots of image patches because there are far fewer object slots than image pieces.
A hide-and-seek training game
- During training, the model plays a game: it hides the history of some objects (like covering parts of a comic strip) and must guess those hidden object states using the visible objects and any extra info (like robot actions).
- To make sure the model knows which object is which, it keeps a tiny “identity tag” for each masked object (an anchor), but hides the rest of its history.
- The model must also predict future object states. So it learns both to “fill in the blanks” for the past and to forecast the future.
The predictor (JEPA) focuses on meaning, not pixels
- The predictor is a transformer (a kind of neural network) trained with a JEPA-style objective: it aligns predicted object summaries with target object summaries, without reconstructing the raw image.
- This makes the model learn the important structure (who affects whom), instead of wasting effort redrawing pixels.
Treating actions as separate helpers
- If actions or robot body signals are available (like “the robot pushed right”), they’re given to the model as separate tokens—like adding extra players to the reasoning group—so the model knows how actions influence objects.
Why this encourages cause-and-effect
- By hiding an object’s history, the model can’t just “cheat” by relying on that object’s own recent motion. It’s forced to look at other objects and actions to infer what happened.
- This acts like a “latent intervention” (a controlled “what-if”) and teaches the model to focus on real interactions that matter.
What did they find?
The authors tested C-JEPA in two areas: visual reasoning and robot planning.
- Visual reasoning (CLEVRER dataset: videos of objects bumping and moving, with questions)
- C-JEPA significantly improved accuracy on counterfactual questions (the “what-if” type), with about a 20% absolute gain compared to the same architecture without object-level masking.
- It also improved overall question-answering performance while staying reconstruction-free (no pixel decoding).
- Too much masking can hurt (because you remove too much useful info), so there’s a sweet spot.
- Robot planning (Push-T: pushing objects to a goal)
- Compared to strong patch-based models, C-JEPA reached similar success rates while using only about 1% of the total input features (tokens).
- This made planning more than 8× faster in their model-predictive control setup, because the model had far fewer tokens to process.
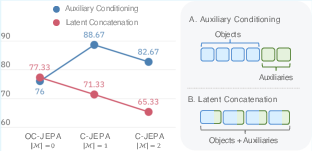
- Modeling actions and robot signals as separate tokens worked better than mixing them into object slots.
Why these results matter:
- Better counterfactual reasoning means the model can answer “what would happen if…” questions more reliably.
- Massive efficiency gains (fewer tokens, faster planning) mean this approach is practical for real-time systems like robots.
What’s the potential impact?
- Smarter simulators and robots: Systems can plan faster and more accurately by understanding how objects interact, not just recognizing them.
- Stronger reasoning: Training with object “hide-and-seek” builds the habit of looking for genuine cause-and-effect, which helps with counterfactual questions and long-term prediction.
- Efficient world models: Using object slots instead of many image patches saves memory and compute, which is important for on-device or real-time applications.
Limitations and future directions (in simple terms):
- The method depends on how good the object encoder is at finding and tracking objects. If that part struggles, the whole system may suffer.
- While the paper explains why masking creates a causal bias, it doesn’t claim the model recovers the exact true causal graph of the world.
- Testing on more complex and diverse environments could further show how well this scales.
Key takeaways
- C-JEPA trains a model to understand object interactions by hiding some objects’ histories and asking it to infer them from others—like a detective using clues.
- This “latent intervention” makes the model learn real cause-and-effect instead of cheap shortcuts.
- It boosts counterfactual reasoning by about 20% and makes robot planning over 8× faster while using about 1% of the features, with accuracy comparable to heavier models.
- Overall, it’s a simple, flexible, and efficient way to build world models that think in terms of objects and their interactions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- External validity and task diversity
- Lack of evaluation on real-world, non-synthetic video datasets and robotics tasks with richer contact dynamics, clutter, deformables, or variable viewpoints.
- Generalization to substantially longer horizons than 160 frames (CLEVRER) or the PushT planning horizon remains untested.
- No assessment under distribution shifts (e.g., novel object shapes/textures, unseen numbers of objects, lighting changes).
- Object cardinality and tracking
- The method assumes a fixed slot count () and relies on a single “identity anchor”; handling variable object counts, object birth/death, and re-identification is not addressed.
- Robustness to slot assignment failures, occlusions, and identity switches in the encoder is not quantified; no mechanism is proposed for online slot rebinding or identity recovery.
- Dependence on frozen encoders
- Encoders (VideoSAUR, SAVi) are frozen; C-JEPA is not trained end-to-end with the encoder, limiting adaptability and potential performance ceilings.
- No strategy is provided for jointly training encoder and predictor without collapse (e.g., teacher–student dynamics, regularization, or target networks), beyond noting this as future work.
- Masking policy design and optimality
- The masking rate, selection policy, and temporal span are tuned empirically; no principled method (e.g., curriculum, uncertainty-aware, or interaction-aware selection) is proposed.
- Potential information leakage via the “identity anchor” is not analyzed (e.g., how much state information is carried forward and whether it enables shortcut interpolation).
- No study of adaptive masking conditioned on scene complexity, interaction density, or model confidence.
- Train–test mismatch and architectural choices
- Training uses bidirectional attention with masked history/future, whereas inference is forward-only; the impact of this mismatch on stability and compounding error is not quantified.
- No comparison to strictly causal (unidirectional) predictors under the same masking objective, nor hybrid architectures that enforce causality at training time.
- Causal claims and validation
- Theoretical “influence neighborhoods” are not empirically validated on datasets with known temporal causal graphs or interventional benchmarks.
- No procedure is given to extract, sparsify, or evaluate learned relational structures (e.g., from attention) against ground-truth interactions.
- The assumptions (object-aligned latents, shared mechanisms, finite-history sufficiency) are strong; failure modes when these assumptions are violated are not probed.
- Uncertainty and robustness
- The predictor is deterministic with MSE in latent space; no uncertainty quantification (e.g., ensembles, latent distributions, or epistemic/aleatoric separation).
- Robustness to sensor noise, partial observability, and adversarial occlusions is not evaluated; no mechanisms for uncertainty-aware planning (risk sensitivity, chance constraints).
- Planning objective and latent metric alignment
- Planning minimizes in latent space to a goal latent; there is no calibration study ensuring latent distances reflect task-relevant geometry.
- No exploration of alternative planning costs (e.g., learned task rewards, value functions) or constraints (e.g., safety, kinematics).
- Sensitivity of success rates to the choice of goal representation (e.g., image vs. latent encoding variability) is not reported.
- Action and auxiliary variable modeling
- While modeling actions/proprioception as separate nodes outperforms concatenation, handling delays, partial observability, or actuation noise is not studied.
- Integration of richer exogenous inputs (e.g., language instructions, force/torque, audio) and their interactions with object tokens is left open.
- Scaling and efficiency limits
- Although token count drops drastically, quadratic attention over entity tokens could become costly as object counts increase; scaling behavior for is untested.
- Comprehensive profiling of training-time efficiency and memory (not just MPC evaluation-time speed) is missing.
- Comparative coverage and fairness
- Empirical comparisons exclude several recent object-centric world models and causal/relational predictors (e.g., sparse attention world models, graph-based dynamics) under identical settings.
- Baselines depend on different encoders (SAVi vs. VideoSAUR); ablations that isolate architectural vs. representation gains remain incomplete.
- Data efficiency and sample complexity
- No analysis of how performance scales with dataset size, pretraining data diversity, or fine-tuning regimes; data efficiency against reconstruction-based methods is unclear.
- Long-horizon rollouts and error compounding
- Error accumulation in latent rollouts is not thoroughly examined (e.g., rollout length vs. degradation curves, stability with and without masking).
- Techniques to mitigate compounding errors (e.g., consistency regularizers, latent self-correction) are not explored.
- Interpretability and controllability of interventions
- The paper frames masking as latent interventions but doesn’t demonstrate controllable “what-if” analyses at inference (e.g., counterfactual planning by clamping specific objects).
- Tools to visualize and edit discovered influence neighborhoods for interpretability or policy debugging are not provided.
- Hybrid objectives and reconstruction
- The method is decoder-free; scenarios where low-level reconstruction stabilizes slot tracking or dynamics (e.g., heavy occlusion) are not investigated.
- Systematic study of hybrid losses (prediction + lightweight reconstruction or contrastive constraints) is absent.
- Failure analyses
- Qualitative/quantitative failure modes (e.g., specific interaction types, high-speed collisions, cluttered scenes) are not dissected, limiting actionable insights.
- Generalization across encoders and hyperparameters
- Sensitivity to the number of slots , slot dimensionality , and masking hyperparameters is only partially covered; no guidance or heuristics for setting these in new domains.
- Online and continual learning
- Adaptation to non-stationary environments, continual object appearance changes, or catastrophic forgetting is not addressed.
- Safety and real-robot deployment
- Planning and control results are in simulation; safety constraints, sim2real transfer, latency under real-time constraints, and hardware robustness are not discussed.
Glossary
- Auxiliary variables: Additional observable inputs (e.g., actions, proprioception) that influence state transitions but are not part of the object state itself. "In addition to object states, we allow for auxiliary observable variables that influence state transitions."
- Autoregressive: A modeling approach that predicts the next step conditioned on previous predicted steps in sequence. "SlotFormer performs autoregressive rollouts over object latents"
- Bidirectional attention: An attention mechanism that allows information to flow in both temporal directions during training for masked prediction. "The predictor f is a ViT-style masked transformer with bidirectional attention"
- Causal discovery: Methods aimed at uncovering causal structure (e.g., graphs) from data. "Masking has also been used in causal discovery to identify latent structure"
- Causal identifiability: The possibility of uniquely determining causal relationships from data under assumptions. "rather than claims of causal identifiability."
- Causal inductive bias: A learning bias that steers models toward causal, intervention-stable dependencies. "object-level masking induces a causal inductive bias via latent interventions."
- Causal sufficiency: An assumption that all common causes are observed. "We emphasize that we do not assume causal sufficiency."
- Counterfactual reasoning: Reasoning about what would happen under alternative (counter-to-fact) scenarios or interventions. "with an absolute improvement of about 20% in counterfactual reasoning compared to the same architecture without object-level masking."
- Cross-Entropy Method (CEM): A stochastic optimization algorithm often used for planning and control. "The optimization problem in Eq.~\eqref{eq:planning} is solved using the Cross-Entropy Method (CEM)."
- Decoder-free design: A modeling setup that avoids pixel-level reconstruction decoders, focusing on latent prediction instead. "highlighting the effectiveness of its decoder-free design and masking-based learning objective."
- DINOv2: A self-supervised vision backbone producing strong image features used as inputs to object-centric encoders. "including DINO and DINOv2, as feature encoders,"
- Entity tokens: Tokenized latent representations of entities (objects and auxiliaries) used by the predictor. "is represented as a set of entity tokens "
- Exogenous variables: External variables that influence the system but are not determined by it. "structured dependencies among object states and exogenous variables"
- Finite-horizon optimal control: Planning that optimizes actions over a fixed future horizon. "planning is performed by solving a finite-horizon optimal control problem"
- Forward prediction: Predicting future states from past observations. "This section analyzes why C-JEPA yields stronger forward prediction than future-only world modeling objectives."
- Identity anchor: A preserved token or state at an initial time step that stabilizes object identity under permutation. "preserving only the earliest time step as an identity anchor."
- Influence neighborhood: The minimal set of contextual variables sufficient for predicting a masked object’s state. "which we formalize as an influence neighborhood."
- Invariant causal prediction: A causal principle seeking predictive relations stable across interventions or environments. "is closely related to prior work on invariant causal prediction"
- Invariant risk minimization: A learning framework promoting predictors invariant across environments. "and invariant risk minimization"
- JEPA (Joint Embedding Predictive Architecture): A self-supervised paradigm that learns to predict in latent space without reconstructing pixels. "JEPA defines a self-supervised learning paradigm that learns to predict in representation space without reconstructing pixels"
- Latent interventions: Interventions applied in latent space (e.g., via masking) to enforce dependency learning. "induces latent interventions with counterfactual-like effects"
- Latent space: A compressed representation space where high-level features are modeled and predicted. "enabling scalable planning and control directly in latent space"
- Mask tokens: Special tokens that replace hidden inputs during masked prediction training. "observations are replaced by mask tokens"
- Masked image modeling: A self-supervised training strategy that masks parts of the input and learns to predict them. "Masked image modeling was originally introduced as a scalable self-supervised learning paradigm"
- Model predictive control (MPC): A control strategy that repeatedly plans over a horizon using a predictive model as new observations arrive. "We further evaluate C-JEPA in a model predictive control (MPC) setting"
- Object-centric representations: Latent representations that organize visual scenes into discrete object slots. "object-centric representations provide a useful abstraction"
- Object self-dynamics: The intrinsic dynamics of an object independent of interactions. "models can easily fall back on object self-dynamics"
- Patch tokens: Tokenized image patches used by patch-based vision transformers as inputs. "In contrast to patch-based predictors, where attention scales quadratically with a large number of patch tokens"
- Permutation-equivariant: A property where the representation or model output is consistent under permutations of input order. "The set representations are permutation-equivariant with respect to the slot ordering."
- Proprioceptive signals: Internal state measurements (e.g., joint positions) of an agent used as auxiliary inputs. "where represents actions and represents proprioceptive signals."
- Reconstruction loss: A loss term that penalizes differences between reconstructed pixels and the original input. "removing reconstruction leads to a severe performance degradation"
- Relational graph: An explicit graph structure representing interactions among entities. "relies on a fixed relational graph"
- Slot Attention: An iterative attention mechanism that groups features into a fixed number of object slots. "Slot Attention was introduced as a mechanism for learning object-centric representations"
- Spurious correlations: Incidental correlations that do not reflect true underlying relationships. "avoiding reliance on spurious pixel-level correlations"
- Tube-based prediction: Prediction over spatiotemporal tubes (space-time regions) in video. "spatiotemporal tube-based prediction in video with V-JEPA"
- Unobserved confounders: Hidden variables that influence both predictors and outcomes, complicating causal inference. "It is important to permit unobserved confounders when using object-centric representations"
- ViT (Vision Transformer): A transformer architecture operating on image tokens (patches) for vision tasks. "ViT-style masked transformer"
- Visual question answering (VQA): Answering natural language questions about visual content. "Empirically, C-JEPA leads to consistent gains in visual question answering"
- World model: A predictive model of environment dynamics enabling reasoning and planning. "World models provide a unifying abstraction for learning, predicting, and reasoning about the dynamics of complex environments"
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s released code and demonstrated gains in counterfactual reasoning and efficient model-predictive control.
- Robotics and industrial manipulation (sector: robotics)
- Use case: Replace patch-based world models in model predictive control for contact-rich tasks (e.g., push, slide, pick-and-place) with C-JEPA to achieve comparable performance at >8× faster planning throughput and ~1% token budget.
- Potential tools/products/workflows:
- Latent-MPC planner module (ROS 2 plugin) that ingests object slots from VideoSAUR/SAVi, optimizes actions via CEM on C-JEPA rollouts, and sends commands to robot controllers.
- Isaac Sim/Unity integration to train C-JEPA with domain visuals and deploy on real robots using sim-to-real pipelines.
- Assumptions/dependencies: Reliable object-centric encoder tuned to the target domain; availability of actions/proprioception as auxiliary inputs; finite-history sufficiency holds; latency benefits depend on transformer token count and hardware; safety validation needed before production.
- Counterfactual video analytics and “what-if” querying (sector: software/media analytics)
- Use case: Enable interactive counterfactual reasoning in multi-object videos (e.g., “If object A hadn’t moved, would collision occur?”) for sports analysis, warehouse safety reviews, and retail store monitoring.
- Potential tools/products/workflows:
- Counterfactual VQA engine combining C-JEPA rollouts with an ALOE-style reasoning layer to answer descriptive/predictive/explanatory/counterfactual questions over imagined trajectories.
- Video QA dashboards for analysts to select objects and time windows, trigger latent interventions (object-level masks), and visualize predicted outcomes.
- Assumptions/dependencies: Domain-adapted object-centric encoders; clear mapping from questions to attention over slot sequences; no claim of causal identifiability—results are intervention-stable predictions, not causal ground truth.
- Edge AI and resource-constrained deployment (sectors: robotics, drones, IoT)
- Use case: Run planning and prediction on embedded devices (AGX Orin-class, drones, mobile manipulators) where compute/memory is limited, using C-JEPA’s small token footprint.
- Potential tools/products/workflows:
- Quantized C-JEPA predictor with frozen encoder; token-budget managers for controlling slot count; on-device CEM planning pipelines.
- Assumptions/dependencies: Efficient object-centric encoder on-device (or offloaded to edge server); careful selection of slot count and masking regime for stability; hardware acceleration for transformers.
- Academic baselines and benchmarks (sector: academia)
- Use case: Adopt C-JEPA as a reconstruction-free baseline to study interaction-aware world models and counterfactual reasoning on CLEVRER, PushT, and new multi-object datasets.
- Potential tools/products/workflows:
- Reproducible training scripts integrating VideoSAUR/SAVi encoders; ablation toolkits for masking strategies (object/tube/token); influence-neighborhood visualization via attention maps.
- Assumptions/dependencies: Data diversity to avoid shortcut solutions; standardized evaluation suites for counterfactual VQA and MPC across domains.
- Game AI and simulation agents (sector: gaming/simulation)
- Use case: Power NPC planning in physics-heavy scenes (projectiles, collisions) using C-JEPA rollouts to evaluate “what-if” strategies at low compute cost.
- Potential tools/products/workflows:
- Game engine plugin that reads object states, masks selected entities, and scores candidate actions via latent goal matching; integration with RL frameworks (e.g., Ray RLlib) for model-based planning.
- Assumptions/dependencies: Consistent object slot extraction from engine state; action spaces aligned with simulation controls; finite-history sufficiency for dynamics.
- Digital twins for process checks (sector: manufacturing/operations)
- Use case: Fast “intervention tests” in assembly lines and robotic cells—simulate the effect of removing/altering a tool/object step to predict downstream impact.
- Potential tools/products/workflows:
- Twin-side “latent intervention tester” that masks object histories in stored sequences and replays rollouts to assess process risk.
- Assumptions/dependencies: Accurate slot mapping from twin telemetry; stable transition mechanisms across cycles; interpret results as predictive influence, not causal proof.
- Pretraining for object-centric encoders (sector: ML tooling)
- Use case: Use the C-JEPA objective to pretrain object-centric encoders without reconstruction losses, improving interaction salience in slots for downstream tasks.
- Potential tools/products/workflows:
- Encoder bootstrapping pipelines with frozen teachers (DINOv2) and JEPA-style predictors; masking schedulers tuned to task complexity.
- Assumptions/dependencies: Strong pretrained backbones; avoidance of representational collapse; tuning of slot count and identity anchors.
Long-Term Applications
These applications are promising but require further scaling, robust encoders, domain adaptation, safety validation, and often multimodal integration.
- Autonomous driving interaction forecasting (sector: transportation)
- Use case: Predict and plan around multi-agent interactions (vehicles, pedestrians, cyclists) with object-level rollouts and counterfactual probes (e.g., “What if the lead vehicle brakes?”).
- Potential tools/products/workflows:
- Multimodal C-JEPA (vision + LiDAR + map priors) for long-horizon planning; risk-aware planners that test interventions and choose robust trajectories.
- Assumptions/dependencies: High-quality object-centric parsing under occlusions and weather; multimodal fusion; regulatory certification; robust training on large-scale driving datasets.
- Household and assistive robots (sector: consumer robotics/healthcare)
- Use case: General-purpose manipulation in cluttered homes (placing, tidying, assisting), reasoning over object interactions and “what-if” outcomes at low latency.
- Potential tools/products/workflows:
- C-JEPA-powered planning stacks with grasp/placement modules; skill libraries using latent goal matching; safety supervisors executing counterfactual checks before action.
- Assumptions/dependencies: Reliable perception on diverse household objects; tactile/proprioception integration; user safety constraints; long-tail generalization.
- Surgical and clinical robotics (sector: healthcare)
- Use case: Low-latency planning for tool-tissue interactions; modeling outcomes of subtle changes (force, trajectory) to avoid complications.
- Potential tools/products/workflows:
- Multimodal C-JEPA integrating endoscopic video and instrument telemetry; “intervention rehearsal” in a digital twin before executing critical steps.
- Assumptions/dependencies: Medical-grade validation; domain-specific encoders; strict regulatory compliance; data scarcity and privacy constraints.
- Urban planning and policy simulations (sector: public policy/urban systems)
- Use case: Explore “what-if” interventions (e.g., removing street furniture, altering signal timing) to predict pedestrian/vehicle interaction outcomes.
- Potential tools/products/workflows:
- City-scale digital twins with object-centric scenes; policy dashboards running latent interventions and displaying influence neighborhoods for stakeholder deliberation.
- Assumptions/dependencies: Robust mapping of urban entities to slots; multi-agent dynamics beyond simple physics; careful communication of non-identifiability and uncertainty.
- Industrial digital twins and supply-chain testing (sectors: manufacturing/logistics)
- Use case: Validate changes in layout, robot programs, or pallet flows via fast rollouts; assess collision risk and throughput impacts under interventions.
- Potential tools/products/workflows:
- “Influence-aware planner” that identifies key entities affecting bottlenecks; optimization tools that propose changes and simulate outcomes.
- Assumptions/dependencies: Accurate slot abstraction of complex processes; integration with ERP/MES; longitudinal stability of transition mechanisms.
- Multimodal embodied agents with language (sectors: software/AI platforms)
- Use case: Agents that plan with C-JEPA rollouts and explain decisions via language grounded in object-level interactions and counterfactuals.
- Potential tools/products/workflows:
- JEPA + LLM stacks where ALOE-style reasoning layers condition on natural-language goals and slot trajectories; “explainable planning” UIs.
- Assumptions/dependencies: Robust alignment between language and slots; grounding data; scalable training; handling latent confounders.
- Education and interactive physics learning (sector: edtech)
- Use case: Student-facing apps that let learners manipulate scenes (mask/move objects) and observe predicted dynamics, building intuition about interactions.
- Potential tools/products/workflows:
- “What-if lab” with C-JEPA under the hood, allowing controlled interventions and explanations via influence neighborhoods.
- Assumptions/dependencies: High-quality visual encoders for varied educational content; carefully designed curricula; transparency about limitations.
- Causal analysis tooling (sector: ML research)
- Use case: Practical exploration of intervention-stable influence neighborhoods as surrogates for causal parent sets in high-dimensional dynamics.
- Potential tools/products/workflows:
- Libraries to extract, visualize, and audit attention-derived neighborhoods across masking regimes; benchmarking against causal discovery datasets.
- Assumptions/dependencies: Clear protocols to avoid overinterpreting attention as causality; datasets with ground-truth structure for validation.
Cross-cutting assumptions and dependencies
- Object-centric encoder quality: Many applications hinge on accurate slot extraction and identity maintenance over time; domain-specific pretraining or fine-tuning is often necessary.
- Masking regime selection: Excessive masking can remove informative dependencies; optimal masking rates are task- and encoder-dependent.
- Finite-history sufficiency: The method presumes that a finite window captures the relevant dynamics; longer memory or external state may be required in complex systems.
- No causal identifiability guarantee: Results reflect intervention-stable predictive influence, not provable causal parent sets; deployments must communicate uncertainty.
- Auxiliary variables: Treat actions/proprioception as explicit conditioning nodes for best performance; integrating them incorrectly (e.g., concatenation into latents) can degrade outcomes.
- Safety and compliance: Robotics and healthcare uses require rigorous validation, fail-safes, and regulatory approvals before production.
Collections
Sign up for free to add this paper to one or more collections.