V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Abstract: A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a LLM, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
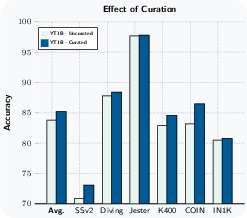
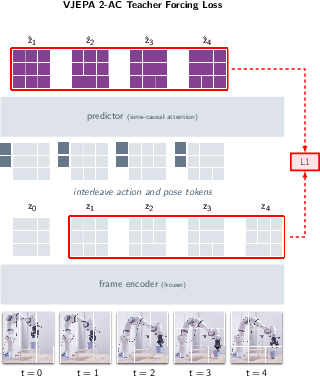
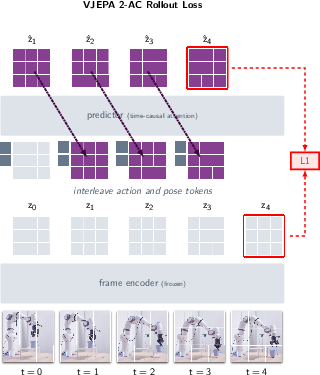
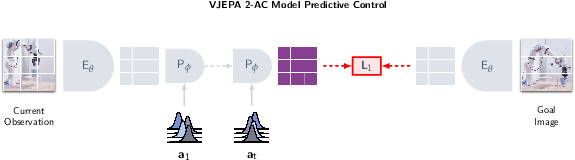





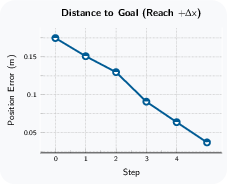


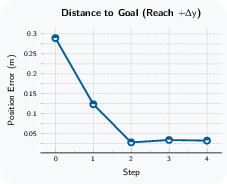


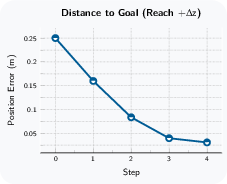

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning”
What is this paper about?
This paper shows how an AI can learn a lot about the world just by watching videos, and then use a small amount of robot data to figure out how to act. The result is a system that:
- understands what’s happening in videos,
- predicts what will happen next,
- and plans actions for a robot to reach a goal (like picking up and moving objects).
In short, the AI first “learns by watching” millions of hours of internet videos, and then learns a little “how to act” from short robot clips. With that, it can solve simple robot tasks in new places without retraining.
1) Big Picture: The main purpose
The goal is to build a “world model” — a kind of mental model that helps the AI understand how things move and change, what actions do, and how to plan steps to reach a goal. The authors do this using a method called self-supervised learning, which means the AI teaches itself from raw videos without needing humans to label everything.
2) The key questions
The paper asks:
- Can an AI learn general knowledge about the physical world by watching internet-scale videos?
- Can that knowledge help it understand actions and motion in new videos?
- Can it predict what will happen next (like guessing a future action in a kitchen video)?
- With just a little robot data, can it plan and control a real robot arm to reach visual goals (like picking and placing objects) in a new lab—without special training for that exact place or task?
3) How it works (in simple terms)
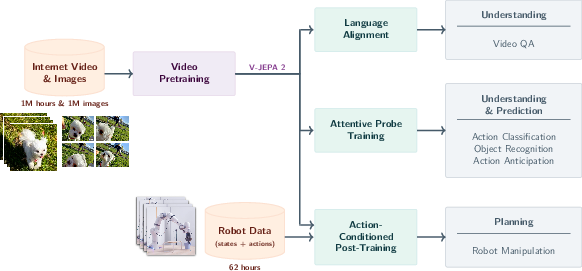
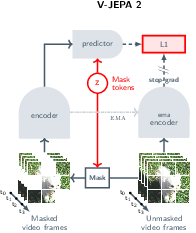
Stage 1: Learning by watching (no actions)
- The model, called V-JEPA 2, watches over 1 million hours of internet videos plus many images.
- It plays a game like “video jigsaw”: parts of the video are hidden, and the model must predict what’s missing—but not at the pixel level. Instead, it works in a “summary space” (think: good notes about the scene) so it focuses on important, predictable things (like where a hand is moving) rather than tiny details (like the exact shape of every leaf).
- This is called a “joint-embedding predictive architecture” (JEPA). “Embedding” means compact summary features; “predictive” means it learns to fill in what’s missing or what comes next in that summary space.
Why not predict pixels? Because pixel-perfect video prediction forces the model to waste effort on unimportant details. Predicting in the “summary space” makes it learn what really matters for understanding and planning.
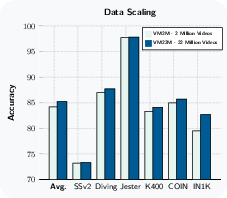
To scale this up, the authors:
- use more and better data (22 million video/image samples, curated to reduce noisy content),
- use a larger model (about 1 billion parameters),
- train longer,
- and gradually use longer/higher-resolution clips (efficiently, to save compute).
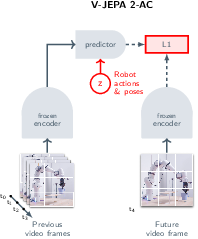
Stage 2: Learning to act (from a little robot data)
- After Stage 1, the visual “brain” is frozen (kept fixed).
- The team adds a small “action head” on top and trains it on about 62 hours of robot videos (from the Droid dataset), which includes the robot’s arm positions and gripper states. No task labels or rewards.
- This action-conditioned model, called V-JEPA 2-AC, predicts how the scene’s features will change if the robot takes certain actions—like “imagine the next moments” given “move the gripper this way.”
Planning to reach a goal (how the robot decides what to do)
- The robot is given a goal as an image (a picture of what the scene should look like).
- The model “imagines” different action sequences and picks the sequence that makes its imagined future look most like the goal picture (in the summary space).
- It uses a sampling method (Cross-Entropy Method) to try many possible action sequences, keep the best ones, and refine them—like smart trial-and-error “in its head.”
- It executes just the first action, then looks again and re-plans (this is called model predictive control).
Analogy: Think of the model as playing chess by mentally simulating future moves and picking the path that gets closest to a desired position.
4) What did they find, and why it matters?
Here are the main results the paper reports:
- Understanding motion and actions
- Strong performance on a motion-heavy benchmark: Something-Something v2 — 77.3% top-1 accuracy. (“Top-1 accuracy” means how often its first guess is right.)
- Predicting what happens next
- State-of-the-art on Epic-Kitchens-100 action anticipation — 39.7 recall@5. (“Recall@5” means the correct answer is in its top-5 guesses.)
- Answering questions about videos
- After aligning V-JEPA 2 with a LLM, it reaches state-of-the-art results at the 8B-parameter scale on several benchmarks that test real-world and time reasoning, for example:
- PerceptionTest: 84.0
- TempCompass: 76.9
- Also strong on MVP, TemporalBench, and TOMATO
- This is notable because the video model was trained without any text labels at first—yet it can be aligned with a LLM and still compete at the top level.
- Planning and acting with a robot
- With only about 62 hours of unlabeled robot videos, V-JEPA 2-AC controls a Franka robot arm in two different labs it never trained in.
- It performs tasks like grasping and pick-and-place from just a single RGB camera view and a goal image—no task-specific training, no rewards, and no extra data collected in those labs.
Why this is important:
- It shows that most of the “world knowledge” needed for robots can be learned by watching huge amounts of everyday videos, not by collecting expensive robot data.
- The model can understand, predict, and plan—three abilities that are key for general-purpose, adaptable AI.
5) What does this mean for the future?
This work suggests a practical path to more general and capable robots:
- Learn common-sense physics and everyday patterns from web-scale videos.
- Add a small amount of real interaction data to link vision to actions.
- Plan by “imagining the future” and choosing actions that bring the scene closer to a goal image.
If developed further, this approach could:
- reduce the cost and time needed to train robots,
- make robots more adaptable to new places and new tasks,
- and help build AI systems that generalize like humans—learning a lot just by observing the world, then using that knowledge to act wisely.
Practical Applications
Below is an analysis of the paper’s practical, real-world applications based on its findings, methods, and innovations. Applications are grouped into immediate (deployable now) and long-term (requiring further research, scaling, or development). Each item indicates sectors, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Video question-answering assistants for enterprise, education, and consumer media
- Sectors: software, education, media/entertainment, enterprise knowledge management
- Tools/Products/Workflows: “Ask-My-Video” API built by aligning the V-JEPA 2 encoder with an LLM; video indexing and temporal retrieval; classroom LMS integrations to enable students to ask questions about lecture recordings; customer support training platforms that generate answers to “what happened when?” queries in procedural videos
- Assumptions/Dependencies: Access to high-quality LLMs and alignment pipelines; robust privacy and compliance for handling proprietary video; domain adaptation for specialized content; inference compute budgets and latency constraints for serving long videos
- Motion understanding and action anticipation for safety and operations monitoring
- Sectors: manufacturing, construction, logistics, smart facilities, retail loss prevention
- Tools/Products/Workflows: Real-time alerting dashboards that anticipate risky actions (e.g., slip/trip hazards, unsafe tool use) or upcoming events (drops, spills) from monocular cameras; proactive interventions (e.g., pause a conveyor) driven by action anticipation signals (Epic-Kitchens-style)
- Assumptions/Dependencies: Sufficient camera coverage and FPS; thresholds to manage false positives; site-specific fine-tuning and bias audits; clear integration with existing safety SOPs and governance
- Sports analytics and broadcast augmentation
- Sectors: sports technology, media/entertainment
- Tools/Products/Workflows: Play anticipation for coaching, automated highlight generation that prioritizes segments preceding pivotal actions, on-air graphics and commentary enhanced by temporal reasoning
- Assumptions/Dependencies: Rights to ingest broadcast feeds; domain-specific fine-tuning for each sport; low-latency inference; evaluation frameworks to prevent biased or misleading analytics
- Video content moderation and compliance
- Sectors: social platforms, regulatory compliance, trust & safety
- Tools/Products/Workflows: Automated detection of risky behaviors or policy violations using motion understanding (e.g., weapon handling cues, dangerous stunts); triage tools for human moderators powered by JEPA embeddings and temporal reasoning
- Assumptions/Dependencies: Multilingual/polylocal context alignment via LLM; robust bias and fairness audits; clear policies that distinguish contextually appropriate actions from violations; privacy and legal safeguards for large-scale video analysis
- Video indexing, retrieval, and search with temporal reasoning
- Sectors: enterprise knowledge bases, media asset management, developer tooling
- Tools/Products/Workflows: JEPA-based embeddings in vector databases for time-aware video search; timeline navigation (“jump to where the tool was inserted”) across procedural and instructional videos; SDKs for dev teams to integrate JEPA encoders into existing search stacks
- Assumptions/Dependencies: Integration with vector DB infrastructure; careful handling of long-form video memory; continued curation for robust coverage of appearance and motion domains
- Zero-shot robot pick-and-place and reaching with goal images (POC deployments)
- Sectors: robotics, lab automation, light manufacturing, warehousing pilot lines
- Tools/Products/Workflows: Model-predictive control (MPC) loops using V-JEPA 2-AC and goal images to perform table-top reaching, grasp, and simple pick-and-place on Franka-like arms; “autonomous reset” behaviors in research labs (move objects back to start states using visual goals)
- Assumptions/Dependencies: Monocular RGB, uncalibrated fixed exocentric camera, compatible end-effector and low-level controllers; environment similarity to Droid-like manipulation (object sizes, surfaces, motions); action constraints (e.g., L1 ball radius) and safety interlocks; current capabilities are limited to short-horizon, prehensile manipulation without task-specific rewards
- Academic reproducibility and benchmarking for world models
- Sectors: academia, applied research labs, open-source communities
- Tools/Products/Workflows: Open-source training recipes (mask denoising in representation space, 3D-RoPE, block-causal transformer), attentive probes for downstream evaluation, progressive-resolution training schedules; reproducible curation pipelines for large video sources
- Assumptions/Dependencies: Access to GPUs and large video datasets; licensing constraints for internet-scale video; rigorous ablation studies and reproducibility checks; community governance for sharing models that could be used for surveillance or sensitive domains
- Energy- and cost-aware training via progressive-resolution schedules
- Sectors: ML Ops, cloud providers, sustainability in AI
- Tools/Products/Workflows: Adoption of warmup-constant-decay schedules with cooldown phases to cut pretraining compute (up to ~8x speedups for high-res long clips); pipeline templates for staged training of video encoders
- Assumptions/Dependencies: Engineering adoption of training curricula and scheduling; monitoring to validate that cooldown benefits transfer across tasks; proper profiling to avoid hidden regressions in accuracy
- Classroom and training video assistants
- Sectors: education, corporate L&D
- Tools/Products/Workflows: Q&A over procedural demonstrations (labs, workshops), timeline navigation to steps and sub-steps, “explain this moment” features for complex tasks
- Assumptions/Dependencies: Domain adaptation to specialized curricula; privacy and FERPA-like compliance; robust semantic grounding and hallucination controls in the LLM component
- Home security and consumer video analytics (privacy-preserving on-device variants)
- Sectors: consumer IoT
- Tools/Products/Workflows: Edge-enabled motion understanding to notify of anticipated events (package handling, door opening, unusual movement), timeline scrubbing and summarization of home footage
- Assumptions/Dependencies: Energy-efficient inference; on-device compute or privacy-preserving streaming; opt-in consent and clear end-user controls; policy-compliant data retention
Long-Term Applications
- Generalist home and service robots with world-model planning
- Sectors: consumer robotics, hospitality, eldercare
- Tools/Products/Workflows: Multi-step task execution from visual sub-goals (tidying, unloading dishwashers, setting tables), compositional planning over longer horizons, skill libraries learned largely from observation plus minimal interaction data
- Assumptions/Dependencies: Scaling from short to long-horizon planning; multi-view and multimodal sensing (depth, tactile); uncertainty-aware control and safety certification; richer goal specification (text + image + constraints)
- Autonomous driving and advanced driver assistance via action anticipation
- Sectors: automotive, mobility
- Tools/Products/Workflows: Predictive models of pedestrian and driver behavior from dashcams; anticipatory interventions; improved situational awareness under complex temporal dynamics
- Assumptions/Dependencies: Extensive domain adaptation; multi-camera/fused sensor inputs; rigorous validation and regulatory approval; liability frameworks for model-based planning
- Surgical and medical video understanding and step anticipation
- Sectors: healthcare
- Tools/Products/Workflows: Real-time assistance during endoscopy or minimally invasive procedures (anticipate next surgical step, detect motion anomalies), post-op video QA and training
- Assumptions/Dependencies: Clinical validation and FDA/EMA approvals; robust datasets with expert annotations; hospital IT integration; strong privacy and security guarantees; handling rare events and edge cases
- AR wearables and predictive assistance
- Sectors: consumer tech, enterprise field service
- Tools/Products/Workflows: Context-aware overlays that anticipate next actions (e.g., “pre-stage the tool you’ll need”), temporal Q&A about what just happened, step-by-step guidance during complex procedures
- Assumptions/Dependencies: Low-latency on-device inference; privacy-preserving pipelines; ergonomic UX; accurate alignment between visual context and language instructions
- Industrial robotics at scale with simulation-light deployment
- Sectors: manufacturing, logistics, energy infrastructure maintenance
- Tools/Products/Workflows: World-model-driven planning across diverse tasks and stations; rapid skill transfer from minimal interaction data; coordinated multi-robot task planning using latent goal energies; “world-model as a service” orchestration for varied robot fleets
- Assumptions/Dependencies: Robustness across surfaces, lighting, object variability; dexterous, contact-rich manipulation beyond current prehensile scope; formal verification for safety-critical operations; integration with MES/SCADA systems
- Video-centric education platforms and dynamic coaching
- Sectors: education, sports, vocational training
- Tools/Products/Workflows: Interactive temporal tutors that anticipate learner actions, give in-the-moment feedback in lab classes or sports drills; adaptive curricula that “pause and explain” predicted difficult steps
- Assumptions/Dependencies: High-quality labeled and unlabeled curricula videos; personalization and fairness safeguards; human-in-the-loop oversight to prevent overdependence
- Broadcast automation and camera robotics
- Sectors: media/entertainment, live events
- Tools/Products/Workflows: Autonomous camera moves that anticipate gameplay or stage events; real-time highlight detection and narrative construction via temporal QA and action anticipation
- Assumptions/Dependencies: Complex multi-camera coordination; artistically acceptable motion planning; audience safety; rights management for content
- Policy and governance frameworks for web-scale self-supervision and embodied AI
- Sectors: public policy, standards bodies, corporate governance
- Tools/Products/Workflows: Standardized curation pipelines and transparency artifacts for large-scale web data; safety standards for model-predictive control in embodied systems; auditing protocols for bias in video understanding; watermarking/traceability for generated and transformed video
- Assumptions/Dependencies: Multi-stakeholder collaboration; evolving legal norms for training on internet-scale data; international harmonization on AI safety and liability; privacy-preserving tools widely adopted
- Toolchains for rapid world-model fine-tuning with small interaction datasets
- Sectors: robotics platforms, ML tooling vendors
- Tools/Products/Workflows: Turnkey “world-model fine-tune kits” that accept small robot videos and action traces to produce deployable planners; latent-energy planning templates compatible with various controllers
- Assumptions/Dependencies: Cross-robot generalization (grippers, kinematics, control stacks); standardized action/state schemas; high-quality logs; calibration-free setup as a stretch goal
- Sustainability gains through optimized training curricula at scale
- Sectors: AI infrastructure, cloud providers, enterprise ML Ops
- Tools/Products/Workflows: Progressive-resolution schedules and cooldown phases that reduce energy usage and cost while preserving performance; standardized profiling and reporting for greener pretraining
- Assumptions/Dependencies: Broad uptake in industry pipelines; monitoring to ensure accuracy-cost tradeoffs are transparent; alignment with corporate ESG goals
Cross-cutting assumptions and dependencies to consider
- Representation-space planning assumptions: success hinges on the latent distance (e.g., L1 in JEPA features) being correlated with true goal achievement; energy functions may need task-specific shaping for complex objectives.
- Data curation and domain coverage: robust performance depends on curated, diverse, and representative pretraining sources; bias and fairness audits are essential for sensitive applications.
- Compute and infrastructure: training and serving long-video models require substantial compute; progressive-resolution training reduces cost but still demands significant resources.
- Safety and governance: embodied deployments require physical safety interlocks, operational constraints, human override, and compliance with local regulations; auditing for surveillance misuse is critical.
- Generalization boundaries: current robot results are table-top, monocular RGB, fixed camera, short-horizon, prehensile tasks; scaling to dexterous, contact-rich, or cluttered environments will require more data, sensing modalities, and control sophistication.
- LLM alignment: video QA quality depends on the LLM’s reliability and grounding; guardrails against hallucination and privacy risks must be in place.
Collections
Sign up for free to add this paper to one or more collections.