- The paper presents V-JEPA, a self-supervised model that predicts masked video representations to develop an understanding of intuitive physics.
- The study uses the violation-of-expectation paradigm and a surprise metric to quantitatively evaluate concepts like object permanence and gravity.
- Robust performance is demonstrated across benchmarks, including a 98% zero-shot accuracy on IntPhys, outperforming traditional pixel-based models.
Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos
The paper "Intuitive physics understanding emerges from self-supervised pretraining on natural videos" explores the capacity of general-purpose deep neural network models to develop an understanding of intuitive physics through self-supervised video prediction. Utilizing the violation-of-expectation paradigm, the authors evaluated how well these models comprehend concepts such as object permanence and shape consistency, comparing their performance to pixel-based generative models and multimodal LLMs (MLLMs).
Methodology and Approach
The paper introduces Joint Embedding Predictive Architectures (JEPAs), focusing on a particular instantiation named V-JEPA. V-JEPA is trained to predict masked representations in videos, which involves using an encoder to extract representations and a predictor to forecast unobserved portions of the video in this learned representation space. The surprise metric is central to evaluating model performance, measuring prediction error when comparing predicted and observed video representations.
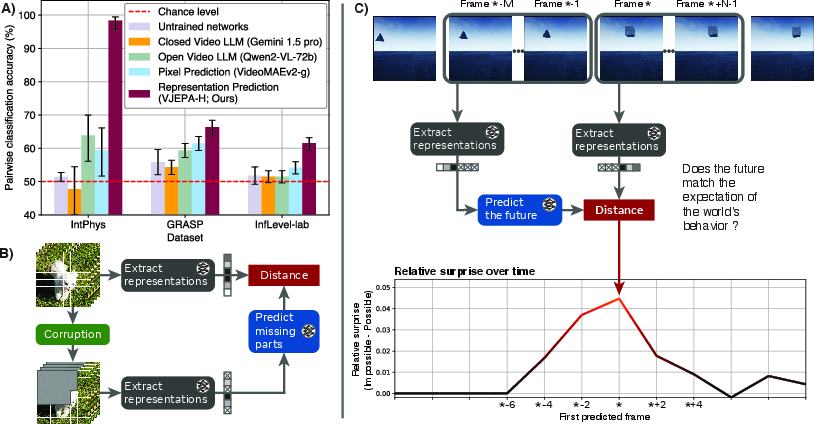
Figure 1: Video prediction in representation space (V-JEPA) achieves an understanding of intuitive physics.
The authors detail how the V-JEPA model utilizes the learned representation space to infer future states in a video and quantify surprise. This approach outperforms simplicity models based on text or pixel prediction.
Evaluation of Intuitive Physics Understanding
The paper evaluates intuitive physics understanding using three datasets: IntPhys, GRASP, and InfLevel. These benchmarks test various physical properties, including object permanence, continuity, and gravity. V-JEPA consistently performs above chance across these datasets, even achieving impressive 98% zero-shot accuracy on the IntPhys benchmark.
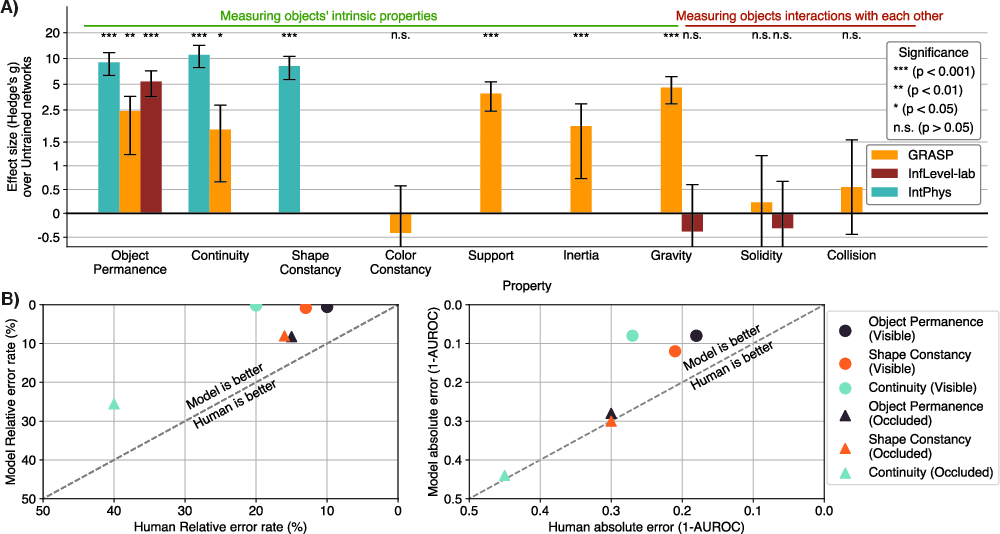
Figure 2: V-JEPA accuracy increase relative to randomly-initialized models and humans across different physical properties and benchmarks.
The superior performance of V-JEPA over other models stems from its ability to encode high-level abstract representations rather than relying on low-level semantic features, illustrating its robustness and reliability in discerning physical violations.
Ablation studies reveal that various design choices influence the emergence of intuitive physics understanding. The training data's diversity, model size, and prediction tasks are significant factors in performance.
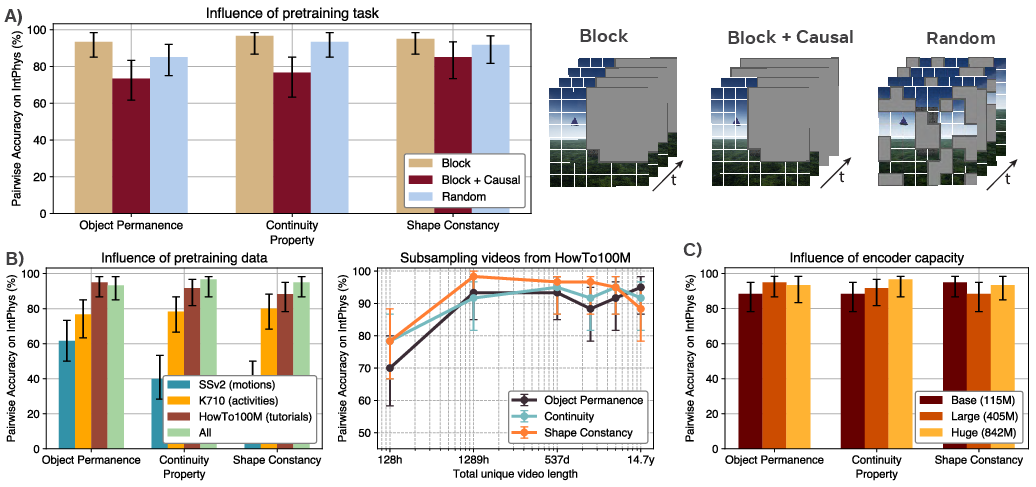
Figure 3: Influence of type of mask, type and amount of training data, and model size on V-JEPA IntPhys scores.
V-JEPA achieves non-trivial performance even with smaller models or reduced training data, underscoring the adequacy of video prediction in a learned representation space for intuitive physics comprehension.
Implications and Future Directions
The results obtained demonstrate significant coverage of intuitive physics by V-JEPA without the need for predefined abstractions. This indicates potential pathways for developing AI systems with enhanced real-world understanding. Notably, current multimodal LLMs and pixel-based generative models fall short in comparison, suggesting areas for improvement in handling intuitive physics tasks.
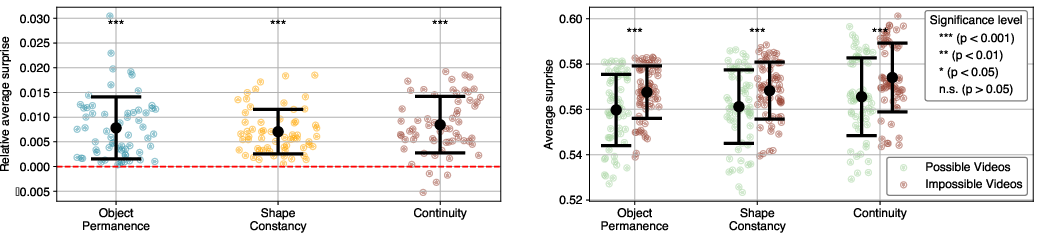
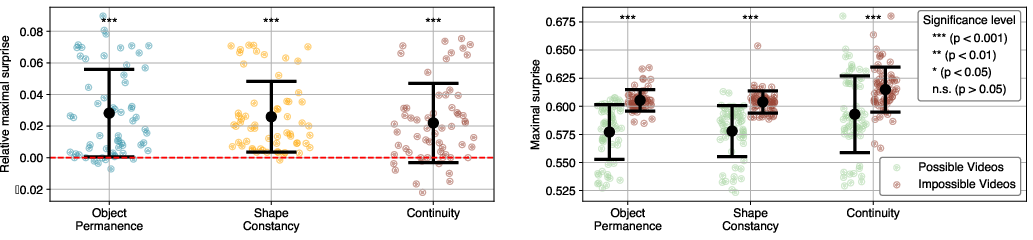
Figure 4: Different surprise measures are better suited for different tasks.
Future studies could focus on enhancing model memory or leveraging hierarchical architectures to capture complex object interactions and contextual dependencies. Additionally, exploring infant-centric video data could yield insights into intuitive physics learning analogous to human development.
Conclusion
The paper successfully demonstrates that intuitive physics understanding can emerge from self-supervised learning models without hardwired knowledge structures. V-JEPA's performance across various benchmarks confirms the effectiveness of predicting in representation space, marking a significant step in bridging the gap between artificial systems and human-level perception. This work lays the groundwork for further research aimed at enriching AI models' physical world comprehension, paving the way for intelligent systems that understand and interact with their environment in more human-like ways.