A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Abstract: We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces EB-JEPA, a small, easy-to-use software library that helps computers learn from images and videos without needing labels. Instead of trying to recreate every pixel, it teaches models to understand the “meaning” of what they see and to predict what will happen next. It also shows how these learned understandings can be used to plan actions, like guiding a simple agent through a maze.
What questions were the authors trying to answer?
- How can we teach a model to focus on important ideas in images and videos (like objects and motion), without wasting time on tiny pixel details that don’t matter?
- Can the same learning idea work for single images, videos over time, and even for planning actions in a simple world?
- How can we make these methods easy to try on a single computer with one GPU, so students and researchers can learn and experiment quickly?
- Which parts of the method are truly necessary to make it work well and avoid failure modes like “collapse” (where the model learns nothing useful)?
How did they approach the problem?
Key idea: Predict the meaning, not the pixels
Most video or image generation systems try to predict every pixel. That’s hard and often unnecessary, because many pixels don’t matter for understanding. EB-JEPA takes a different route:
- First, it turns each image (or video frame) into a compact “summary” called a representation. Think of this as the gist of what’s in the scene.
- Then, it learns to predict future representations (the gist of the next frame), not the raw pixels.
- The better the predicted representation matches the real one, the lower the “energy” (a score measuring how well the model did). Training means pushing this energy down for correct predictions.
This saves computation and focuses the model on meaningful information.
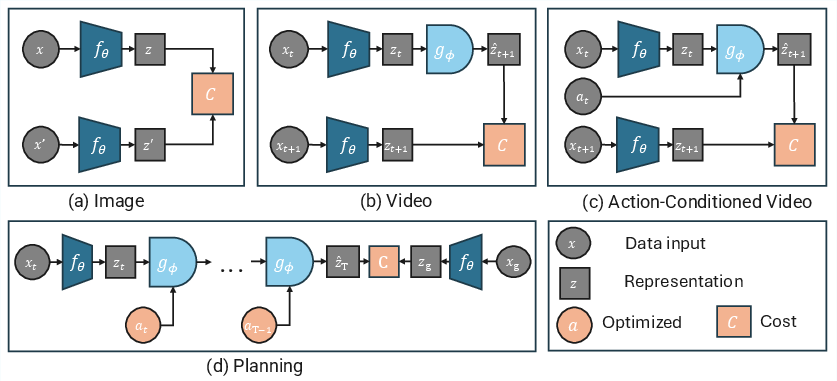
Three example projects in one library
To show the idea works in different situations, the library includes three small, well-documented examples that train in a few hours on a single GPU:
- Images: Learn representations that are stable under small changes (like cropping or color shifts).
- Videos: Predict the next moment’s representation from recent frames (learning basic motion and dynamics).
- Action-conditioned world models: Predict what happens next when actions are taken (used for planning to reach goals).
Keeping the model honest: preventing “collapse”
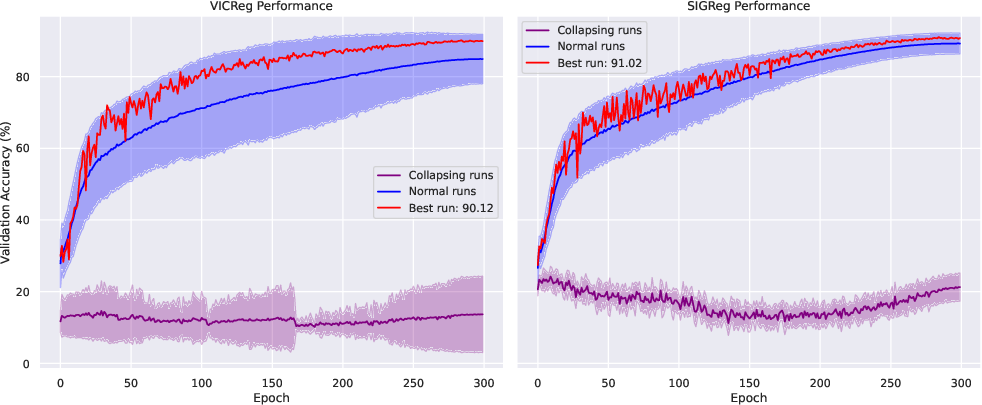
A common failure is “collapse,” where the model outputs the same representation for everything (useless!). The library includes regularizers—extra training rules—to keep representations rich and varied:
- Variance and covariance terms (VICReg): Encourage features to spread out and not be redundant—like making sure your notes cover all important topics, not the same one over and over.
- SIGReg: A simpler alternative with one main knob to tune; it nudges features into a balanced shape that works well for learning.
For world models (where actions influence the future), the library adds:
- Temporal similarity: Keep nearby moments smooth and consistent.
- Inverse dynamics (IDM): Predict the action from before-and-after states, which ties actions to their effects and prevents shortcutting.
Planning with the learned world
Once the model can imagine how the world changes with actions, it can plan. The planner (MPPI) works like this:
- It “imagines” many possible action sequences.
- It simulates what would happen using the learned world model.
- It scores each imagined path by how close it gets to the goal (not just at the end, but along the way).
- It keeps improving the best action sequences until it finds a good plan.
This is like trying many routes on a map in your head and choosing the one that gets you closest to your destination.
What did they find?
Here are the key results the authors report:
- Image understanding: On CIFAR-10 (a common image dataset), the learned representations reached about 91% accuracy when tested with a simple linear classifier. This shows the features are useful for real tasks.
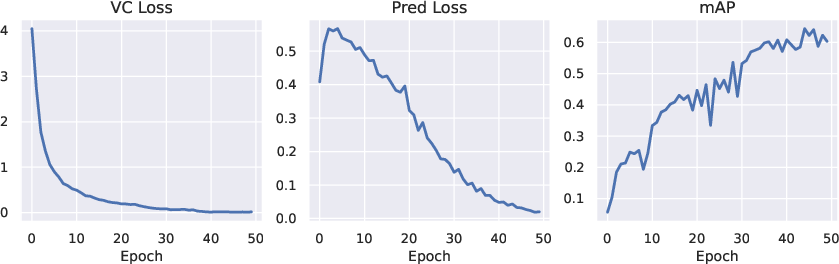
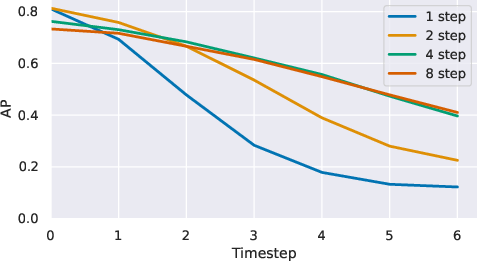
- Video prediction: Training the model to predict multiple steps ahead (not just the very next step) greatly improved performance on a related detection task. It also made long rollouts (predicting many frames into the future) more stable and realistic.
- Action-based planning: In a simple “Two Rooms” navigation world with changing walls, the model planned successful paths 97% of the time. Summing progress toward the goal across all steps (not only the final step) made planning more reliable.
- Why regularization matters: Turning off any of the regularization pieces hurt performance a lot. Removing the inverse dynamics loss caused nearly complete failure (about 1% success), proving it’s essential to avoid misleading shortcuts. Variance and covariance terms each added big gains, and temporal similarity also helped significantly.
- Easy-to-use and efficient: All examples are designed to run on a single GPU in a few hours, making them practical for teaching and quick experiments.
Why does this matter?
- Focused learning: By predicting in “meaning space” instead of pixel space, models learn useful features more efficiently and avoid wasting effort on details that don’t matter.
- One framework, many uses: The same simple idea works for images, videos, and action-driven planning—showing it’s a flexible approach for building smarter systems.
- Education and research: Because the code is clean, small, and fast to train, students and researchers can quickly try out new ideas, understand how things work, and build on them.
- Future potential: These world models could lead to better robots, more reliable planning, and more efficient learning methods. The paper also points to next steps like multi-timescale (hierarchical) planning and learning better goal or value functions.
In short, EB-JEPA makes advanced self-supervised learning and world modeling easier to understand, easier to run, and easier to improve—while showing strong results with simple setups.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what this paper leaves missing, uncertain, or unexplored, aimed at guiding future research.
- External validity at scale: The library is only demonstrated on small, toy benchmarks (CIFAR-10, Moving MNIST, Two Rooms). It remains unknown how EB-JEPA performs on standard large-scale datasets (e.g., ImageNet-1k/22k, Kinetics, Ego4D), high-resolution inputs, or complex, real-world environments and robotics tasks.
- Comparative baselines under equal compute: The paper does not provide controlled, apples-to-apples comparisons against reconstruction-based methods (e.g., MAE/VideoMAE), contrastive methods (e.g., SimCLR/MoCo/InfoNCE), or other JEPA variants on the same tasks and compute budget, leaving the practical trade-offs unquantified.
- Transfer to diverse downstream tasks: Beyond CIFAR-10 linear probing and a toy detection AP on Moving MNIST, the paper does not assess transfer to segmentation, object detection, pose estimation, video understanding (e.g., action recognition), or embodied benchmarks; the downstream utility of JEPA features remains undercharacterized.
- Stability and sensitivity at scale: Hyperparameter stability analyses (SIGReg vs VICReg) are limited to CIFAR-10; there is no study of sensitivity across architectures, datasets, or scales (e.g., batch size, optimizer, learning rate, projector size), nor guidelines for robust tuning when scaling.
- Projector design generality: While projector bottlenecks improve image JEPA performance, the paper does not analyze projector design in temporal or action-conditioned settings, nor its impact on learning dynamics, collapse risk, and planning quality.
- Predictor architecture exploration: Video predictors are restricted to ResUNet/GRU with small receptive fields; the paper does not investigate alternatives (e.g., Transformers, temporal ConvNets, hybrids), their scalability, or trade-offs between complexity, training stability, and long-horizon accuracy.
- Rollout training choices (K, TBPTT): The benefits of multi-step rollouts are shown on Moving MNIST, but the paper does not quantify the compute/gradient stability trade-offs of larger K, truncated backpropagation through time vs full backprop, or optimal rollout schedules across tasks.
- Action encoder design: The action encoder q_ω is under-specified and not ablated; it is unclear how its architecture, receptive field, and capacity influence representation quality, prediction accuracy, and planning success.
- World-model generalization and robustness: The Two Rooms setup is deterministic and highly simplified; the paper does not test robustness to stochastic dynamics, partial observability, sensor noise, occlusions, or distribution shifts (e.g., unseen room layouts or changing dynamics).
- Collapse prevention guarantees: While regularization prevents collapse empirically, there are no formal guarantees for the combined objectives (VICReg/SIGReg + temporal similarity + IDM) or clarity on conditions under which each term is necessary/sufficient.
- SIGReg scalability and overhead: The computational/memory overhead of SIGReg’s Gaussianity tests (number of projections K, embedding dimensionality) is not characterized, nor is its behavior on high-dimensional embeddings or large-batch regimes.
- Representation metric validity: Planning and training rely on L2 distances in latent space, but there is no validation that these distances align with task-relevant semantics (e.g., that “closeness” in embedding space consistently correlates with goal achievement); learned metrics or value functions remain unexplored.
- Learned cost/value functions: The paper mentions this as a future direction but provides no experiments; it is unclear how learned costs or value functions interact with JEPA world models, whether they improve planning reliability, or how to train them efficiently with limited supervision.
- Planner diversity and control loop analysis: Planning is limited to MPPI/CEM with sampled trajectories; there is no evaluation of gradient-based planners, differentiable planning, policy optimization baselines, closed-loop control stability, or real-time latency constraints.
- Planning metrics beyond success rate: The paper does not report path optimality (e.g., path length suboptimality), energy landscape characteristics, sample efficiency (rollouts per success), or sensitivity to horizon H, temperature τ, and noise σ in MPPI/CEM.
- Long-horizon error compounding: Although multi-step rollouts help, the paper does not quantify compounding prediction errors over long horizons in video or world models, nor evaluate strategies like scheduled sampling, consistency losses, or uncertainty modeling.
- Encoder/backbone scaling: Encoders are small (ResNet-18/ViT-S/IMPALA); the paper does not test larger or pre-trained backbones, frozen vs fine-tuned encoders, or the impact on downstream transfer and planning.
- Data augmentations and masking strategy: Image-JEPA uses view invariance but does not detail augmentation policies or explore masked-prediction strategies (as in I-JEPA) that could drive stronger invariances; their effects on collapse and transfer are not analyzed.
- Regularizer breadth: Only VICReg and SIGReg are studied; other non-contrastive regularizers (e.g., whitening, redundancy reduction variants, decorrelation via orthogonality constraints) and contrastive regularizers are not evaluated within the JEPA framework.
- Automatic collapse detection/mitigation: There is no mechanism for detecting collapse during training or adaptively adjusting regularization strengths to prevent it across different regimes and tasks.
- Sample efficiency: The paper does not quantify how many samples or epochs are required to reach a given performance level, nor compare sample efficiency across regularizers, predictors, and planners.
- Uncertainty estimation and risk-aware planning: The approach assumes deterministic predictions; the paper does not address uncertainty quantification in latent dynamics (e.g., ensembles, stochastic predictors) or how to incorporate uncertainty into planning.
- Partial observability and memory: The models do not explicitly handle POMDPs (e.g., via recurrent memory, belief states); it is unclear how JEPA representations support memory-dependent planning under limited observability.
- Multi-task and transfer learning: The library does not demonstrate training a single JEPA across multiple tasks/datasets or transferring a world model from one environment to another, leaving cross-task generalization an open question.
- Multimodal inputs: EB-JEPA is limited to vision and actions; there is no exploration of multimodal extensions (e.g., language, audio) for instruction-following or grounded planning.
- Evaluation breadth and statistical rigor: Many results are averaged over a small number of seeds/checkpoints; variance across seeds, confidence intervals for key metrics, and rigorous statistical comparisons are limited.
- Energy and compute efficiency claims: While the library is “lightweight” and single-GPU-friendly, the paper does not provide detailed compute/energy usage measurements, memory footprint, or profiling to substantiate efficiency claims across tasks and hyperparameters.
- API maturity and scalability guidance: The paper does not provide concrete guidelines for transitioning EB-JEPA prototypes to distributed training, larger models, or external benchmarks, nor document API support for extensibility (e.g., plugins for new predictors/planners).
- Safety and failure modes: There is no analysis of failure cases (e.g., unsafe planned trajectories, brittleness under adversarial inputs), nor guidance on safe planning constraints or guardrails in more realistic settings.
Glossary
Joint-Embedding Predictive Architectures (JEPA): Refers to a family of models that learn to predict in a learned representation space rather than reconstruct observations in pixel space. Example: "Joint-Embedding Predictive Architectures (JEPAs) offer an alternative paradigm."
VICReg: Variance-Invariance-Covariance Regularization, prevents collapse by ensuring feature dimension spread and decorrelating feature dimensions. Example: "VICReg prevents collapse through two complementary terms."
Energy-Based Models (EBMs): A framework for modeling the compatibility between inputs and outputs using a scalar energy function. Example: "We view this through the lens of Energy-Based Models (EBMs)."
Contrastive methods: Methods that explicitly push up the energy of negative samples to prevent collapse in Energy-Based Models. Example: "Classical EBMs address this through contrastive methods."
Projection space: Space in which regularization losses are computed using a learned projector mapping representations to embeddings. Example: "For image-JEPA and video-JEPA, the regularization losses are computed in a projected space."
Epps-Pulley Gaussianity test: A statistical test used within the SIGReg regularizer to enforce isotropic Gaussian distribution in representations. Example: "The SIGReg objective enforces this by testing Gaussianity along random 1D projections..."
Model Predictive Path Integral (MPPI): A sampling-based optimization algorithm that uses importance sampling to refine action sequences for planning. Example: "We use Model Predictive Path Integral (MPPI) control for planning."
Inverse Dynamics Model (IDM): A loss component that predicts actions from consecutive state representations in the action-conditioned video-JEPA models. Example: "The inverse dynamics model (IDM) loss predicts actions from consecutive representations."
Variance term: Part of the VICReg regularizer that ensures that each feature dimension has sufficient spread across the batch. Example: "The variance term ensures each feature dimension has sufficient spread across the batch."
Covariance term: Part of the VICReg regularizer that decorrelates feature dimensions to encourage the model to use all available capacity. Example: "The covariance term decorrelates feature dimensions to encourage the model to use all available capacity."
Multistep rollout training: A method for training models by augmenting single-step predictions with multiple future-step predictions to improve temporal understanding. Example: "Training with -step rollouts aligns the training procedure with autoregressive inference."
Autoregressive inference: Inference method used during prediction where the model recursively predicts in sequence based on previous predictions. Example: "Training with -step prediction significantly improves Average Precision by reducing exposure bias, i.e., the discrepancy between teacher-forced training and autoregressive inference."
Cross-Entropy Method (CEM): A planning algorithm that uses elite selection to optimize action sequences by fitting a Gaussian distribution. Example: "Unlike the Cross-Entropy Method (CEM) which fits a Gaussian to elite samples, MPPI weights all samples by their exponentiated costs."
Exposure bias: The discrepancy between training models with teacher-forced predictions and evaluating them with autoregressive inference. Example: "Training with longer prediction horizons achieves better downstream performance..."
Temporal similarity loss: A regularization term used to encourage smooth representation trajectories along action sequences. Example: "The temporal similarity loss encourages smooth representation trajectories."
Isotropic Gaussian: Optimal embedding distribution identified by SIGReg for minimizing downstream prediction risk, characterized by a normal distribution with equal variance in all dimensions. Example: "SIGReg introduces SIGReg, a theoretically grounded alternative regularizer."
Vision Transformers (ViT): A type of architecture for neural networks that are based on transformer models for processing visual data. Example: "Encoders (ResNet-18, Vision Transformers (ViT), IMPALA)..."
Energy landscape: The structure formed by the energy function over the space of input-output pairs for Energy-Based Models. Example: "Learning consists of shaping the energy landscape so that correct input-output pairs have lower energy than incorrect ones."
Energy function: A scalar function that measures compatibility between inputs in Energy-Based Models. Example: "An EBM defines a scalar energy function measuring compatibility between inputs and outputs ."
MPPI (Model Predictive Path Integral): A sampling-based optimization algorithm used for planning by iteratively refining action sequences based on their costs. Example: "We use Model Predictive Path Integral (MPPI) control for planning."
Practical Applications
Below is an overview of the paper’s practical implications, mapping findings and methods to concrete use cases. Each item notes sectors, suggested tools/workflows, and key assumptions or dependencies.
Immediate Applications
- Energy-efficient self-supervised visual pretraining on a single GPU
- Sectors: software, manufacturing, retail, education
- Tools/workflows: Use EB-JEPA’s Image-JEPA with SIGReg and a projector to pretrain encoders, then add linear probes for downstream tasks (classification, retrieval). The provided ResNet-18 + SIGReg pipeline achieves ≈91% linear probing on CIFAR-10.
- Assumptions/dependencies: Availability of unlabeled domain data; single-GPU compute; careful projector choice (bottleneck works best for SIGReg); basic PyTorch expertise.
- Label-efficient computer vision pipelines for organizations with limited annotation budgets
- Sectors: healthcare (non-diagnostic admin imagery), retail (inventory images), logistics (package imagery), document processing
- Tools/workflows: Pretrain with EB-JEPA, then train small supervised heads on a modest labeled set. Reuse modular encoders, projectors, and regularizers to reduce engineering overhead.
- Assumptions/dependencies: Domain shift considerations; a minimal labeled set for probing/finetuning; privacy/security policies for on-prem training.
- Latent video prediction modules for resource-constrained analytics
- Sectors: security/surveillance, sports analytics, autonomous drones (simulation), traffic cams
- Tools/workflows: Apply Video-JEPA with multi-step rollout training (k-step, Pareto ≈4) to build motion forecasting and event detection in latent space, reducing pixel-space generation costs and exposure bias.
- Assumptions/dependencies: Access to representative video datasets; tuning rollout steps; integration with downstream detection models.
- Lightweight path planning in simple robot navigation tasks
- Sectors: robotics (education, hobbyist robots, indoor mobile platforms), smart home
- Tools/workflows: Use AC-video-JEPA world models with MPPI or CEM planners for goal-conditioned navigation in small 2D/indoor environments. The paper’s setup achieves ≈97% success in Two Rooms.
- Assumptions/dependencies: Low-dimensional action space; stable sensor streams; careful regularization (variance, covariance, temporal similarity, IDM); planning cost design (prefer cumulative cost over final-state-only).
- Regularization-informed training QA and collapse prevention
- Sectors: academia, MLOps for CV teams
- Tools/workflows: Monitor VICReg/SIGReg metrics (variance, covariance, Gaussianity tests) and IDM loss to detect/troubleshoot collapse in JEPA training. Use ablation insights to prioritize IDM in randomized environments.
- Assumptions/dependencies: Batch statistics monitoring; the ability to alter hyperparameters mid-training; reproducible seeds.
- Rapid prototyping platform for world modeling research and teaching
- Sectors: academia, edtech
- Tools/workflows: Adopt EB-JEPA’s modular components (encoders, predictors, regularizers, planners) in teaching labs and research group sprints; single-GPU examples train in hours, lowering the barrier to entry.
- Assumptions/dependencies: GPU availability in labs; curriculum alignment; students’ familiarity with PyTorch.
- Best-practice planning cost design for energy-based trajectory optimization
- Sectors: robotics (warehouse navigation, inspection), autonomy R&D
- Tools/workflows: Implement cumulative latent-space goal distance across the horizon (not only final state), with MPPI temperature and noise scheduling; combine elite selection with importance weighting.
- Assumptions/dependencies: Reliable latent encoding of goal states; properly set horizons; robust rollout (avoid compounding errors).
- Privacy-conscious on-prem representation learning
- Sectors: healthcare administration, finance operations, legal/compliance document processing
- Tools/workflows: Use JEPA’s self-supervised objectives on sensitive visual data without external labels, keeping data on-prem and focusing on representation-space prediction (reducing pixel-level reconstruction artifacts).
- Assumptions/dependencies: Internal data governance; performance auditing for bias; domain-specific evaluation protocols.
- Edge-friendly upgrades for smart cameras and IoT
- Sectors: smart cities, home security, retail loss prevention
- Tools/workflows: Pretrain compact encoders with EB-JEPA, deploy linear probes on-device for lightweight detection/recognition; periodically update latent predictors with incremental, self-supervised training.
- Assumptions/dependencies: Edge hardware constraints; efficient quantization/pruning; streaming-friendly data augmentations.
- Reproducible baselines for JEPA-style world models
- Sectors: academia, open-source research
- Tools/workflows: Use the provided code, seeds, and hyperparameters for CIFAR-10, Moving MNIST, and Two Rooms as standardized baselines when comparing novel regularizers or predictor architectures.
- Assumptions/dependencies: Community adoption; careful reporting of experimental conditions; contribution workflows (PRs, CI).
Long-Term Applications
- Hierarchical world models for multi-timescale planning in complex systems
- Sectors: autonomous driving, industrial robotics, logistics
- Tools/workflows: Extend EB-JEPA’s modularity to multi-resolution encoders and predictors (fine-grained dynamics + coarse abstractions), enabling long-horizon strategy with local control.
- Assumptions/dependencies: New architectures; larger-scale datasets; safety and verification frameworks; sim-to-real transfer.
- Learned cost/value functions integrated with JEPA dynamics
- Sectors: robotics, autonomy, operations research
- Tools/workflows: Combine JEPA world models with learned value functions (e.g., TD-MPC/TDMPC2) or task-dependent costs from demonstrations to enable more nuanced planning objectives than simple latent distances.
- Assumptions/dependencies: Access to demonstrations or reward signals; stable value learning; broader evaluation on complex tasks.
- General-purpose, low-energy world models on real video streams
- Sectors: healthcare monitoring (non-diagnostic), industrial inspection, energy grid monitoring
- Tools/workflows: Scale latent temporal predictors to real-world, noisy data; learn robust dynamics that handle occlusions, camera motion, and non-stationarity.
- Assumptions/dependencies: Larger and more diverse datasets; domain adaptation; careful treatment of privacy/regulatory constraints.
- Digital twins and simulation-backed planning using latent JEPA models
- Sectors: manufacturing, energy, smart infrastructure
- Tools/workflows: Build latent predictive simulators for facility layouts or grid states; perform trajectory optimization for maintenance scheduling, routing, and anomaly response in latent space to cut compute cost.
- Assumptions/dependencies: High-fidelity sensor integration; validation against ground truth; robust uncertainty quantification.
- Continual, on-device self-supervised learning in consumer devices
- Sectors: consumer electronics, wearables
- Tools/workflows: Incrementally update representations and predictors on-device with JEPA objectives (no labels), maintaining performance under drift and personal context changes.
- Assumptions/dependencies: Efficient continual learning strategies; memory/compute budgets; safeguards against catastrophic forgetting.
- Robust sim-to-real transfer with regularization-aware training
- Sectors: robotics (warehouse, agriculture), drones
- Tools/workflows: Exploit SIGReg/VICReg + IDM/temporal similarity to learn transferable latent dynamics under randomized training; deploy in variable real environments.
- Assumptions/dependencies: Domain randomization curricula; sensor alignment; safety testing.
- Edge AI standards and policy for energy-aware machine learning
- Sectors: public policy, sustainability
- Tools/workflows: Use EB-JEPA’s single-GPU, representation-space prediction paradigm to inform guidelines/incentives for low-energy ML practices and reproducible research in publicly funded projects.
- Assumptions/dependencies: Measurable energy metrics; stakeholder adoption; alignment with sustainability targets.
- Cross-domain JEPA for non-visual sequences (e.g., finance, demand forecasting)
- Sectors: finance, supply chain
- Tools/workflows: Adapt encoders/predictors to time-series signals (prices, demand, sensor data) and learn latent dynamics for forecasting/planning in representation space.
- Assumptions/dependencies: Architecture changes for 1D sequences; careful evaluation vs. established baselines; regulatory compliance in finance.
- Curriculum-standard teaching kits and MOOCs on energy-based self-supervision
- Sectors: education, edtech
- Tools/workflows: Package EB-JEPA labs and ablation studies into standardized course modules; integrate with cloud GPU credits and auto-grading.
- Assumptions/dependencies: Maintenance of the library; institutional partnerships; accessibility accommodations.
- MLOps integrations for JEPA training at scale
- Sectors: software, platform engineering
- Tools/workflows: Build pipelines that monitor regularizers, rollout losses, and planning success rates; auto-tune hyperparameters (especially SIGReg’s single λ) and surface collapse warnings to practitioners.
- Assumptions/dependencies: Production-grade logging/monitoring; resource schedulers; governance for model updates.
Collections
Sign up for free to add this paper to one or more collections.

