SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Corpora
Abstract: We present an ultra-fast and flexible search algorithm that enables search over trillion-scale natural language corpora in under 0.3 seconds while handling semantic variations (substitution, insertion, and deletion). Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning. We theoretically show that the proposed method suppresses exponential growth in the search space with respect to query length by leveraging statistical properties of natural language. In experiments on FineWeb-Edu (Lozhkov et al., 2024) (1.4T tokens), we show that our method achieves significantly lower search latency than existing methods: infini-gram (Liu et al., 2024), infini-gram mini (Xu et al., 2025), and SoftMatcha (Deguchi et al., 2025). As a practical application, we demonstrate that our method identifies benchmark contamination in training corpora, unidentified by existing approaches. We also provide an online demo of fast, soft search across corpora in seven languages.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (Overview)
The paper introduces SoftMatcha 2, a very fast text search tool that can scan through truly massive collections of text (trillions of words) in a fraction of a second. Unlike simple “find” tools, it can handle natural language variations: it finds phrases that mean nearly the same thing, even if a word is changed (substitution), added (insertion), or removed (deletion). The goal is to help researchers quickly look through huge training datasets used for LLMs to answer questions like “Where did this information come from?” or “Did test questions accidentally appear in training data?”
What the researchers wanted to achieve (Key objectives)
Here are the main questions they asked:
- How can we search extremely large text collections (trillions of tokens) in under a second?
- How can we find not only exact matches, but also “soft” matches that allow small changes in wording or length?
- How can we keep the search fast even when the text collection is huge and the query allows many variations?
- Can this approach work across multiple languages and help detect “contamination” (e.g., test questions appearing in training data)?
How it works (Methods explained simply)
Think of trying to find a sentence in a library the size of several Internets. You need two things:
- a brilliant index so you don’t flip through every page, and
- a smart way to avoid checking millions of “almost right” answers.
SoftMatcha 2 combines both.
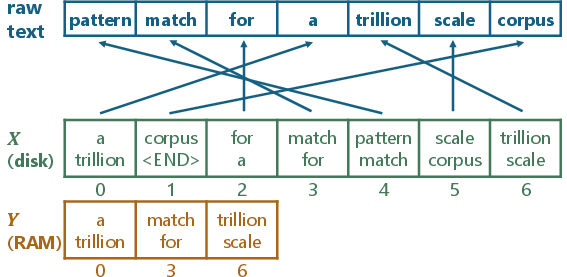
1) A super-fast index on disk (suffix arrays, made “disk‑aware”)
- A suffix array is like a mega-index that lists every possible ending of the text so you can quickly check if a phrase exists.
- Problem: for trillion-token collections, the index is far too big for memory and must live on disk (SSD), which is much slower to access than RAM.
- Their solution: a two-stage, disk-aware design. In stage one, they quickly narrow down where a match could be; in stage two, they confirm the exact spot. This design needs only one disk access per exact lookup, which is a big deal for speed.
Analogy: It’s like using a building directory (stage one) to find the right floor, then a doorplate (stage two) to find the exact apartment—so you don’t wander around every floor.
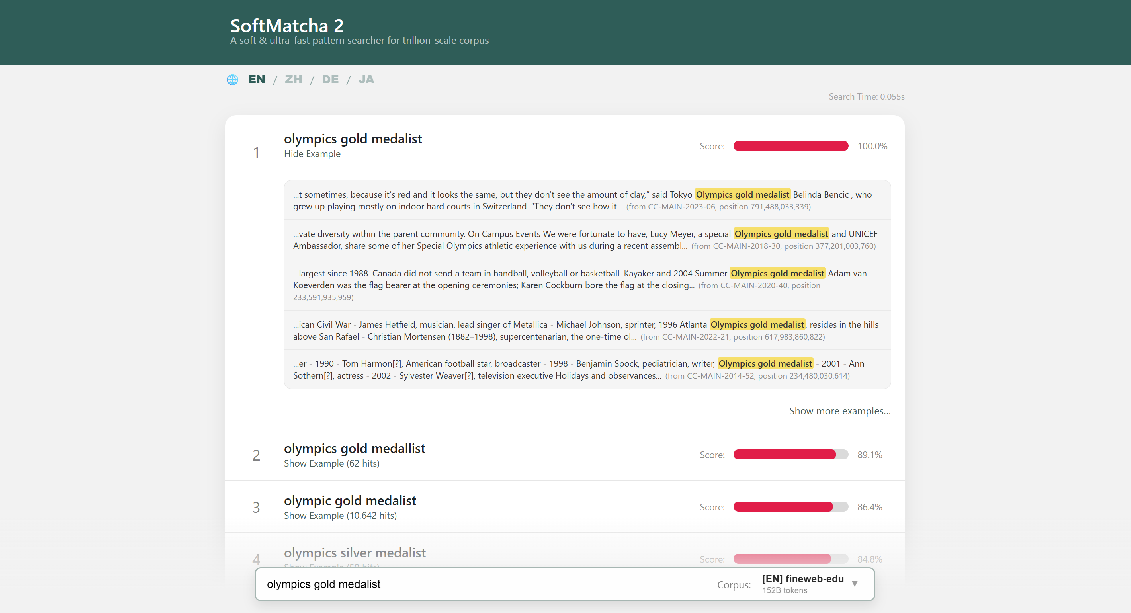
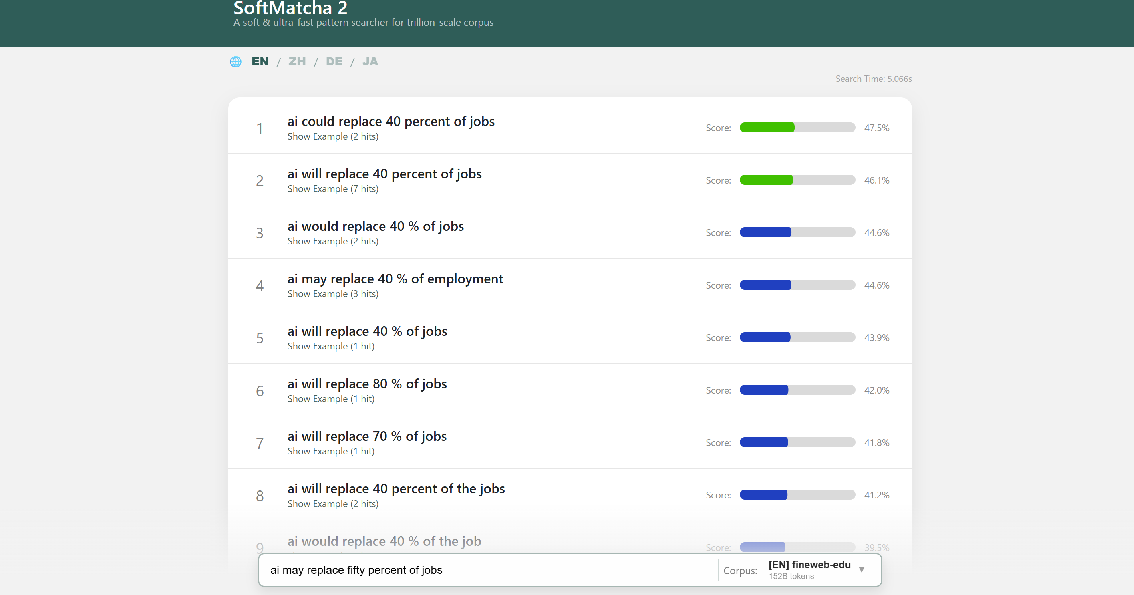
2) “Soft” matching using word meaning
- They represent words as vectors (think of placing words in a big map where similar words are close together).
- They measure how similar two words are (cosine similarity) and smoothly combine these similarities across a phrase.
- They also allow insertions and deletions (like ignoring “the” or adding a small word) but apply a small penalty so results don’t drift too far from the original meaning. Less informative words (like “the” or “of”) get a smaller penalty than important words.
Example:
- Query: “olympics gold medalist”
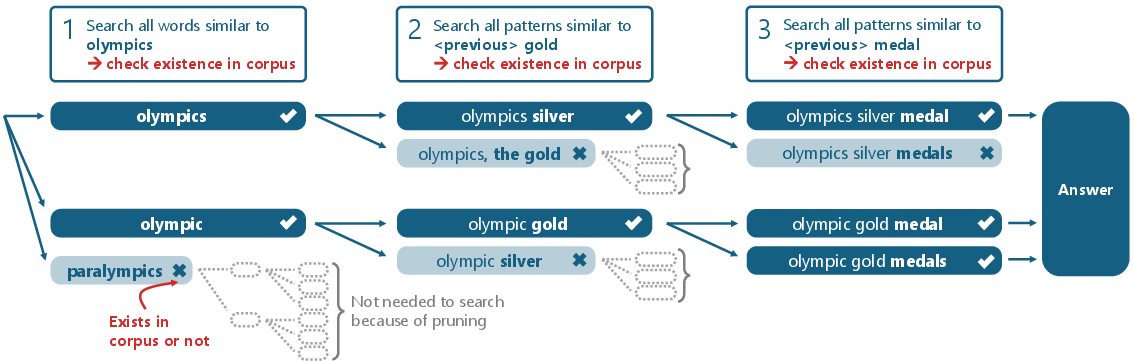
- SoftMatcha 2 can also find: “olympic gold medallist” (spelling change), “olympics silver medalist” (similar meaning), or even “importance of machine learning” vs “importance of the machine learning” (handles a tiny extra word).
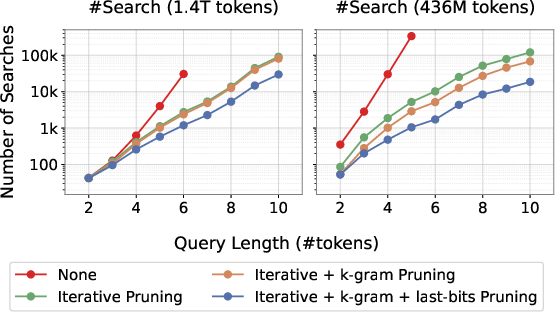
3) Dynamic pruning: cutting down the search space early
- If you allow substitutions, insertions, and deletions, the number of possible variations can explode.
- The tool avoids this by pruning aggressively and early. It builds longer matches step-by-step and keeps only those that actually appear in the corpus at each step.
- This takes advantage of a language fact: most random word combinations don’t occur often (a power-law/Zipf’s law effect), so checking “does this partial phrase exist at all?” quickly eliminates bad candidates.
Analogy: Like a detective narrowing suspects—if a partial clue doesn’t match the records, you drop that branch and move on.
4) Practical extras that speed things up further
- k-gram pruning: Pre-caches whether very common short word pairs/triples even show up, so it can skip unnecessary disk reads.
- “Last-bits” pruning: If a partial phrase is rare, it directly checks its few occurrences rather than trying lots of extensions.
- Adaptive thresholding: If you asked for, say, the top 20 matches but got too few, it slightly relaxes the similarity bar and tries again—until you have enough good results.
What they found (Main results and why they matter)
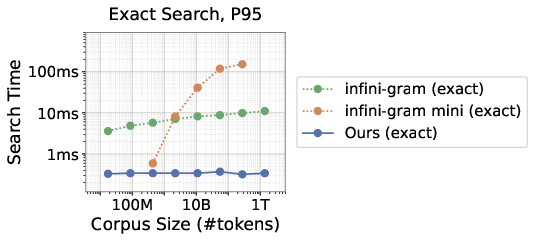
- Very fast exact search: On a 1.4 trillion-token English corpus (FineWeb-Edu), their exact lookup finished 95% of queries in about 0.34 milliseconds—about 33× faster than a popular exact-search system (infini-gram).
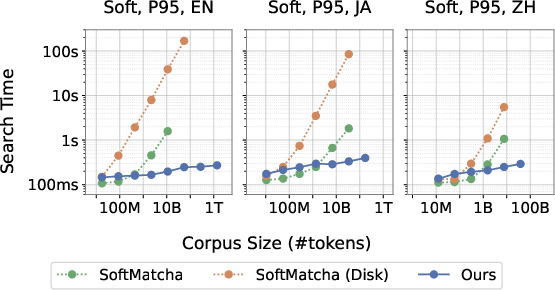
- Very fast soft (semantic) search: For the same huge corpus, 95% of soft searches finished under about 0.28 seconds (278 ms). That’s fast enough for interactive use.
- Works in multiple languages: They showed strong performance in Japanese and Chinese too (95% of searches under ~0.4 seconds), plus tests in other languages.
- Scales better than older methods: Compared to the original SoftMatcha (which used a different index type), SoftMatcha 2 stays fast as the corpus grows very large.
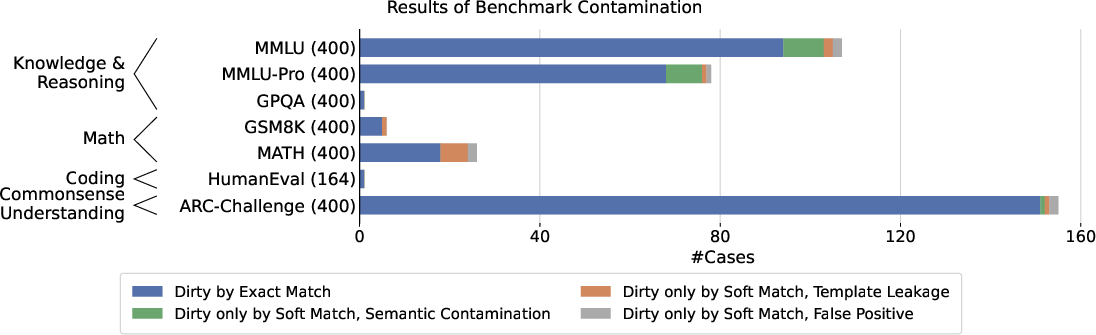
- Practical application: It can detect benchmark contamination—cases where evaluation questions accidentally appear in training texts—something many tools miss. This helps ensure fair testing of LLMs.
- Reasonable index trade-offs: Building the index for the 1.4T-token dataset took about 54 hours and resulted in ~21.6 TB including raw text—large, but manageable on modern servers.
Why it matters: Auditing and searching massive language-model training data is crucial for fairness, safety, and transparency. Doing this in under a second at trillion-token scale opens the door to routine checks that used to be impractical.
What this means going forward (Implications)
- Better auditing of AI training data: Researchers and companies can quickly check whether sensitive or test materials leaked into training sets, improving trust and fairness.
- Faster diagnosis of model behavior: When a model says something strange, you can rapidly look for similar training passages to understand why.
- Works across languages: Makes it more useful for global datasets and multilingual models.
- Strong foundation for future tools: The combination of a disk-efficient suffix array and dynamic pruning shows a path to building other “soft” search tools at massive scale.
In short, SoftMatcha 2 shows that it’s possible to search enormous text collections quickly—even when you allow natural variations in language. That makes it a powerful tool for keeping LLMs honest, safe, and well-understood.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper, phrased to guide follow‑on research.
- Semantic match quality is not systematically evaluated: no precision/recall, MAP, or human relevance judgments against annotated benchmarks; results focus on latency with only qualitative examples.
- Sensitivity of results to key hyperparameters is untested: effects of , the adaptive similarity threshold schedule, smooth-min parameter , and insertion/deletion penalty across languages and domains are not quantified.
- The similarity function relies on static word embeddings (GloVe/fastText/LLaMA token embeddings); robustness to polysemy, domain shift, and out-of-vocabulary (OOV) terms is unclear, and contextualized embeddings are not explored.
- Handling of multi-token synonyms and paraphrases beyond position-wise substitutions plus insertions/deletions is limited; reordering and syntactic alternations (e.g., passive/active voice, clause reordering) are not supported.
- Completeness under OOV tokens is uncertain: if a true soft match contains a token absent from the embedding vocabulary (or poorly represented), candidate enumeration may miss it despite corpus presence.
- Effects of tokenization choices are underexplored: how different tokenizers (word-level, subword/BPE, byte-level) affect both latency and match quality, especially for languages with rich morphology or clitics.
- Cross-tokenization alignment is not addressed: suffix arrays are built over a chosen tokenization, while embeddings may be defined at different granularity, risking mismatches and degraded similarity.
- Language coverage is limited to six languages; generality to highly inflected or agglutinative languages (e.g., Turkish, Finnish), right-to-left scripts (Arabic), and code-mixed text remains untested.
- Domain robustness is not evaluated: performance and pruning behavior on code corpora, logs, biomedical/legal text, or noisy OCR (where Zipfian assumptions or grammar constraints differ) are unknown.
- Theoretical guarantees hinge on an unvalidated hypothesis and Zipf-like -gram assumptions; no empirical verification of these assumptions across languages/domains or analysis of deviations is provided.
- Worst-case behavior is not characterized: adversarial or degenerate queries (e.g., very frequent tokens, very long queries, repeated stopwords) and p99/p999 latency tails are not reported.
- Throughput and concurrency are unmeasured: QPS, multi-user contention, and scheduling strategies under heavy loads are not evaluated, despite dependence on random disk access.
- Memory footprint is high (experiments used 1 TB RAM), and exact RAM requirements for k-gram caching and other in-memory structures are not reported; scaling to commodity hardware is unclear.
- Index size remains large (≈21.6 TB for 1.4T tokens, including raw text); feasibility for ≥10T-token corpora, further compression options, and storage–latency trade-offs are not explored.
- Index construction is single-shot and slow (≈54 hours) with no support for incremental updates, deletions, or online ingestion; strategies for maintaining freshness in dynamic corpora are absent.
- Distributed deployment is not addressed: partitioning, sharding, replication, failover, and consistency in cluster settings remain unexplored, limiting practical scalability and reliability.
- The adaptive thresholding loop may repeat substantial work; no incremental or cached reuse of work across threshold relaxations is described, and its impact on tail latency is unknown.
- The “last-bits pruning” and k-gram pruning heuristics lack formal guarantees; conditions under which these heuristics backfire (e.g., moderately frequent prefixes) and their failure modes are uncharacterized.
- Effects of document boundaries and segmentation are unclear: whether matches crossing document/sentence boundaries are allowed or filtered, and the impact of boundary handling on both quality and speed.
- Retrieval outputs emphasize patterns rather than document-level context; integration with document IDs, passage-level ranking, and downstream use (e.g., contamination auditing pipelines) is only qualitatively demonstrated.
- Privacy and misuse risks are not discussed: large-scale soft search may facilitate PII extraction or reconstruction of sensitive training data; mitigations, access controls, and auditing are absent.
- Comparison breadth is narrow for soft matching: beyond SoftMatcha, alternative fuzzy/approximate substring methods, regex+synonym expansions, or hybrid dense–symbolic approaches are not benchmarked.
- Energy and cost efficiency are unreported: CPU utilization, NVMe wear, and dollar-per-query costs under realistic workloads are unknown.
- Robustness to noisy text (typos, Unicode normalization, punctuation variants, casing) and normalization strategies are not evaluated.
- Open questions about combining context-aware or phrase-level representations (e.g., lightweight contextual embeddings, phrase embeddings) with the suffix-array framework for better semantic matching remain unexplored.
- Impact of K (requested result count) on candidate explosion, pruning efficacy, and latency (including p99) is not quantified; guidance for practitioners is missing.
- Reproducibility of the disk-aware, staged suffix array is limited by reliance on appendices; key engineering choices (parameters, layout, compression settings) need more explicit documentation and ablations.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging SoftMatcha 2’s fast, soft, word-order-aware search (with substitutions, insertions, deletions) and disk-aware suffix-array indexing.
- AI/ML data governance: benchmark contamination detection and dataset auditing
- Sector: software/AI, academia, policy
- Application: scan pretraining corpora to detect evaluation items (and paraphrased variants), check leakage before model training or benchmark release, document provenance
- Tools/workflows: “Benchmark Leak Detector,” pretraining pipeline gatekeeping (pre-check stage), dataset curation dashboards with soft match summaries
- Dependencies/assumptions: index built over training corpora; consistent tokenization; access to high-quality embeddings; storage/compute for multi-TB indexes; threshold calibration to balance recall/precision
- LLM behavior tracing and debugging (memorization and hallucination analysis)
- Sector: software/AI R&D
- Application: trace model outputs back to likely training passages or near-variants to understand memorization; investigate unexpected behaviors or hallucinations
- Tools/workflows: “Memorization Tracer” integrated in eval pipelines; soft-match probes for generated outputs; incident investigation playbooks
- Dependencies/assumptions: access to training corpora; embeddings aligned with training tokenization; legal permissions for data inspection
- Enterprise eDiscovery and compliance text search (clause-level, variant-resilient)
- Sector: legal, finance, enterprise software
- Application: find clauses across contracts and policies despite synonymy, rewordings, insertions/deletions; audit compliance language in filings and disclosures
- Tools/workflows: “Soft Clause Finder” for document management systems; compliance audit jobs; contract lifecycle QA checks
- Dependencies/assumptions: domain-tuned embeddings; secure on-prem indexing; access control and audit logging; threshold tuning for legal sensitivity
- Publishing and education: paraphrase-aware plagiarism detection
- Sector: education, publishing
- Application: catch paraphrased reuse and lightly edited passages; detect variable-length matches and synonym substitutions
- Tools/workflows: “Paraphrase Plagiarism Checker” with soft matching; instructor dashboards; editorial review checks
- Dependencies/assumptions: reference corpora availability; calibrated similarity thresholds to minimize false positives; clear reporting/explainability
- Linguistics and lexicography: large-scale KWIC and collocation analysis
- Sector: academia (linguistics), education
- Application: concordancing at trillion-scale; mining phrase variants, collocations, orthographic/spelling differences (e.g., medalist/medallist); diachronic studies
- Tools/workflows: “Soft Concordancer” with exportable KWIC contexts; research notebooks pipelines
- Dependencies/assumptions: language-specific tokenizers; per-language embeddings; corpus access and licensing
- Healthcare text search: guideline, protocol, and EHR note variant detection
- Sector: healthcare
- Application: search for clinical guideline phrases across paraphrases; deduplicate clinical trial descriptions; find adverse event mentions with insertions/deletions
- Tools/workflows: “Guideline Variants Finder” for clinical knowledge bases; quality review workflows
- Dependencies/assumptions: domain medical embeddings; PHI/PII handling and governance; on-prem hardware; HIPAA-compliant indexing
- Cybersecurity and software: soft secret and code-pattern scanning
- Sector: cybersecurity, software engineering
- Application: detect credential leakage patterns despite obfuscations; approximate code pattern searches across repositories (e.g., unsafe API usage variants)
- Tools/workflows: “Soft Secret Scanner,” “Approx Code Search” integrated with CI; pre-commit hooks
- Dependencies/assumptions: code/token embeddings for source code; repository access; policy for scanning proprietary code
- Knowledge base hygiene: near-duplicate and variant consolidation
- Sector: software docs, customer support
- Application: merge similar FAQ entries; surface redundant/how-to pages; canonicalize knowledge items
- Tools/workflows: “Soft Duplicate Detector” with editorial workflows; KB maintenance sprints
- Dependencies/assumptions: embeddings trained on domain vocabulary; defined dedup thresholds; human-in-the-loop review
- RAG pre-filtering and candidate generation
- Sector: software/AI
- Application: pre-filter retrieval pools with word-order-aware soft searches; harvest candidate passages for reranking; reduce hallucinations by stricter phrase-level matching
- Tools/workflows: retrieval pipeline stage preceding ANN; hybrid sparse-soft re-ranking
- Dependencies/assumptions: index over the RAG corpus; consistent tokenization/embeddings; latency budgets and infrastructure
- Media and OSINT: claim tracking across paraphrases
- Sector: media, civil society
- Application: follow propagation of specific claims/memes across web pages as they mutate; support fact-checking and origin tracing
- Tools/workflows: “Claim Tracker” dashboards; periodic scans with trend reports
- Dependencies/assumptions: web corpus availability; crawl permissions; robust thresholds to avoid overmatching
- IP and patent prior-art search with variant tolerance
- Sector: IP law, R&D
- Application: identify prior art claims phrased differently; search for inventive concepts despite wording changes
- Tools/workflows: “Soft Prior-Art Finder” for patent corpora; with examiner-style filters
- Dependencies/assumptions: domain terminology embeddings; alignment with patent tokenization; legal/licensing compliance for corpora
- Finance: soft search in regulatory filings and risk disclosures
- Sector: finance
- Application: detect paraphrased risk statements across 10-K/CSR reports; audit presence of required regulatory language
- Tools/workflows: “Soft 10-K Scanner”; compliance audit runs
- Dependencies/assumptions: finance-specific embeddings; access to filings; explainable match reporting
Long-Term Applications
Below are use cases that benefit from further research, scaling, or development (e.g., cross-lingual embeddings, streaming indexes, policy integration).
- Cross-lingual soft pattern search and alignment
- Sector: software/AI, academia
- Application: match phrases across languages (e.g., English–Chinese variants), align bilingual corpora, support translation QA
- Tools/workflows: multilingual embeddings and tokenizers; “Cross-Lingual Concordancer”
- Dependencies/assumptions: high-quality multilingual sentence/word embeddings; robust tokenization across languages; evaluation frameworks for cross-lingual precision/recall
- Real-time, streaming indexing and incremental updates
- Sector: enterprise software, search
- Application: continuously ingest new documents while preserving soft-search guarantees and low latency
- Tools/workflows: distributed, sharded staged suffix arrays; write-optimized tiers; background compaction
- Dependencies/assumptions: engineering for concurrent reads/writes; SSD/NVMe performance; consistency guarantees; ops maturity
- LLM provenance and on-the-fly data citation
- Sector: software/AI, policy
- Application: attach source references to generated text by searching training corpora for near-duplicates; improve transparency and trust
- Tools/workflows: “Data Citation Layer” integrated into inference; post-generation soft search with thresholds calibrated to copyright/privacy policies
- Dependencies/assumptions: safe access to training corpora in production; legal review; governance for citation display and user privacy
- Standardized leakage certification and policy frameworks
- Sector: policy, academia, standards bodies
- Application: define and audit “leakage-free” benchmarks and datasets using soft matching; certification programs for model evaluation integrity
- Tools/workflows: audit protocols; benchmark registries; third-party verifiers
- Dependencies/assumptions: community agreement on thresholds/metrics; reproducible pipelines; cooperation from dataset providers
- Platform-scale content moderation and safety scanning
- Sector: social platforms, government
- Application: detect evolving harmful content templates (e.g., instructions, recruitment scripts) across paraphrases and insertions/deletions
- Tools/workflows: “Soft Pattern Moderation” services; risk alerting systems
- Dependencies/assumptions: policy definitions; continuous embedding/domain updates; accuracy controls to avoid over-removal
- Vulnerability and bug-pattern discovery in code at scale
- Sector: software engineering, cybersecurity
- Application: find semantic code patterns across languages and minor variations (e.g., unsafe patterns) with word-order sensitivity adapted to code syntax
- Tools/workflows: cross-language code embeddings; “Soft SAST” augmentation
- Dependencies/assumptions: robust code embeddings/tokenization; language-specific indexers; developer workflows integration
- Misinformation genealogy mapping
- Sector: media, research
- Application: reconstruct propagation chains of claims and their paraphrases over time; quantify influence and mutation patterns
- Tools/workflows: temporal soft-search pipelines; network visualization
- Dependencies/assumptions: time-stamped web corpora; dedup heuristics; ethical use and privacy safeguards
- PII and sensitive content monitoring at web scale
- Sector: policy, cybersecurity
- Application: detect exposure of personal data through approximate patterns (e.g., formats with variations), monitor leaks across paraphrases
- Tools/workflows: “Streaming PII Scanner” with pattern libraries; alerting and takedown workflows
- Dependencies/assumptions: high-precision patterns to minimize false positives; legal authority for scanning; privacy-by-design controls
- Integration into consumer search engines for soft phrase search
- Sector: search/IR
- Application: offer users “phrase-plus-variants” retrieval with word-order-aware semantics; improve query intent satisfaction
- Tools/workflows: hybrid lexical–soft reranking; UI affordances for variant toggles
- Dependencies/assumptions: large-scale deployment economics; latency SLAs; UX research on user expectations
- Domain-adaptive embeddings and tokenization ecosystems
- Sector: broader industry
- Application: tailor soft-search quality to domains (legal, medical, finance, code) by training or selecting domain embeddings/tokenizers
- Tools/workflows: “Embedding Registry” with evaluation suites; automated selection per corpus
- Dependencies/assumptions: ongoing model training; domain data availability; governance on model selection
Notes across applications
- Performance and scale: The staged, disk-aware suffix array enables sub-300 ms p95 soft searches even over trillion-token corpora, but requires significant SSD/NVMe and 10–20+ TB of index storage; smaller corpora can be served on modest hardware.
- Quality: Embedding choice, tokenization consistency, and adaptive thresholding materially affect recall/precision; domain-specific embeddings improve feasibility.
- Governance: Many applications depend on data access rights, privacy and copyright compliance, and transparent reporting to mitigate legal/ethical risks.
Glossary
- Adaptive Similarity Thresholding: A strategy that automatically relaxes or tightens the similarity threshold to retrieve a target number of matches. "Adaptive Similarity Thresholding."
- Aho–Corasick: A classic multi-pattern string matching algorithm that uses a trie with failure links to find occurrences of many keywords efficiently. "KMP / BM / \ AhoâCorasick"
- Approximate nearest neighbor (ANN) search: Algorithms for quickly finding vectors close to a query vector in high-dimensional spaces, typically used for large-scale similarity search. "approximate nearest neighbor (ANN) search"
- Approximate string matching: Matching that allows edits such as substitutions, insertions, and deletions between a pattern and text, often measured via edit distance. "Approximate \ string matching"
- BM25: A probabilistic ranking function that scores documents based on term frequency and inverse document frequency with length normalization. "BM25"
- BigTable: A distributed storage system for structured data that scales to large sizes; here referenced as inspiration for a two-stage indexing scheme. "Google's BigTable"
- Concordancer: A tool in corpus linguistics that displays KWIC lines to analyze how words or phrases are used in context. "with concordancers"
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them, commonly used for word embeddings. "cosine similarity"
- Dense vector search: Retrieval based on continuous embeddings of text, using vector similarity rather than exact token matching. "Dense vector search"
- DFA/NFA (finite automata in regex engines): Deterministic and non-deterministic finite automata models used to implement regular expression matching. "DFA / NFA / \ Virtual Machine"
- Dynamic corpus-aware pruning: A technique that reduces candidate patterns during search by exploiting corpus statistics (e.g., n-gram distributions) to avoid exponential blowup. "dynamic corpus-aware pruning"
- Dynamic programming × bit-parallelism: A method for accelerating DP-based approximate string matching by operating on multiple bits in parallel. "DP \ bit-parallelism"
- Edit distance: A metric that quantifies the minimum number of edits (insertions, deletions, substitutions) needed to transform one string into another. "edit distance"
- Exact lookup: Determining whether a candidate pattern occurs in the corpus using an index without allowing semantic or edit variations. "fast exact lookup"
- FM-index: A compressed full-text index based on the Burrows–Wheeler transform that supports fast substring queries. "FM-indexes"
- Inverted index: A data structure mapping terms to the list of documents (or positions) where they occur, commonly used in information retrieval. "inverted index"
- Iterative pruning: A stepwise strategy that filters candidates at each prefix expansion using corpus checks to prevent combinatorial explosion. "iterative pruning"
- k-gram pruning: A pruning technique that pre-checks frequent 2-grams and 3-grams and caches their corpus presence to avoid disk access at query time. "-gram pruning"
- KWIC (Key Word In Context): A concordance format showing keywords centrally with surrounding context for linguistic analysis. "Key Word In Context"
- Last-bits pruning: A pruning technique that, when a prefix has few corpus occurrences, enumerates its positions directly to check matches instead of expanding suffixes. "Last-bits pruning"
- Lexical search: Retrieval that relies on token overlap and term weighting rather than exact phrase order or semantic similarity. "Lexical similarity \search"
- Power-law distribution of -grams: The empirical observation that -gram frequencies follow a heavy-tailed distribution, often approximated by Zipf-like laws. "power-law distribution of -grams"
- Regular expression matching: Pattern matching using regex syntax interpreted by automata or VM-style engines to find string patterns. "Regular expression \ matching"
- Retrieval-Augmented Generation (RAG): A paradigm that combines external document retrieval with generation models to enhance factuality and coverage. "Retrieval-Augmented Generation~\citep[RAG;]"
- Run-length compression: A simple compression technique that encodes consecutive repeated elements as a single run-length pair to reduce index size. "run-length compression"
- Smooth minimum: A differentiable approximation of the minimum function that aggregates similarities without ignoring non-minimal terms. "This is a smooth minimum"
- Soft (semantic) string matching: Matching that allows semantically similar substitutions and variable-length edits (insertions/deletions) rather than exact token equality. "Soft (semantic) \ string matching"
- Suffix array: A full-text index consisting of sorted starting positions of all suffixes of a text, enabling fast exact substring queries. "suffix array"
- TF-IDF: A term-weighting scheme that scales term frequency by inverse document frequency to score document relevance. "TF-IDF"
- Zipfian whitening: A normalization of word embeddings based on Zipf-derived statistics so that vector norms correlate with information content. "Zipfian whitening"
- Zipf’s law: A statistical law stating that word frequency is inversely proportional to its rank, commonly observed in natural language. "Zipf's law"
Collections
Sign up for free to add this paper to one or more collections.