Multivector Reranking in the Era of Strong First-Stage Retrievers
Abstract: Learned multivector representations power modern search systems with strong retrieval effectiveness, but their real-world use is limited by the high cost of exhaustive token-level retrieval. Therefore, most systems adopt a \emph{gather-and-refine} strategy, where a lightweight gather phase selects candidates for full scoring. However, this approach requires expensive searches over large token-level indexes and often misses the documents that would rank highest under full similarity. In this paper, we reproduce several state-of-the-art multivector retrieval methods on two publicly available datasets, providing a clear picture of the current multivector retrieval field and observing the inefficiency of token-level gathering. Building on top of that, we show that replacing the token-level gather phase with a single-vector document retriever -- specifically, a learned sparse retriever (LSR) -- produces a smaller and more semantically coherent candidate set. This recasts the gather-and-refine pipeline into the well-established two-stage retrieval architecture. As retrieval latency decreases, query encoding with two neural encoders becomes the dominant computational bottleneck. To mitigate this, we integrate recent inference-free LSR methods, demonstrating that they preserve the retrieval effectiveness of the dual-encoder pipeline while substantially reducing query encoding time. Finally, we investigate multiple reranking configurations that balance efficiency, memory, and effectiveness, and we introduce two optimization techniques that prune low-quality candidates early. Empirical results show that these techniques improve retrieval efficiency by up to 1.8$\times$ with no loss in quality. Overall, our two-stage approach achieves over $24\times$ speedup over the state-of-the-art multivector retrieval systems, while maintaining comparable or superior retrieval quality.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Imagine a giant online library where you type a question and the system must find the best passages to answer it. Modern systems use smart math to understand meaning, not just exact words. One very accurate method compares your question to each document word-by-word (very detailed), but that’s slow and expensive.
This paper shows a faster way to keep most of that accuracy while making the system much quicker. The idea: first make a short, smart shortlist of documents using a fast “smart keyword” method, then do the detailed word-by-word check only on that small list. The authors test this idea carefully and show it can be up to 24 times faster while keeping the quality of the results.
What questions the paper tries to answer
- Can we replace slow, word-by-word searching over the entire library with a faster first step that still finds the right documents?
- If we use a strong first step (a learned sparse retriever), will the final results stay as good as the best detailed methods?
- Can we make the second step (the detailed re-check) even faster without losing quality?
- How do different “compression” tricks affect speed, memory, and accuracy?
How they did it (methods in simple terms)
Think of a two-step search:
- Step 1: Make a shortlist quickly
- They use a “learned sparse retriever” (LSR). Think of it as a smart keyword system: it knows which words matter most and can find documents that match the meaning, not just exact words.
- Bonus: They try an “inference-free” version. That means at search time you don’t run a heavy neural network for the query; you look up pre-learned scores for the words. It’s like having a cheat-sheet that makes step 1 even faster.
- Step 2: Rerank (double-check the shortlist carefully)
- They use a “multivector” model (like ColBERT). Imagine your question and each document are split into many small meaning-pieces (one per token/word), and each question word tries to find its best match in the document. This detailed check is accurate but slow—so they only do it for a small shortlist (like 20–50 documents).
Why this helps:
- Old systems did “gather” at the word-piece level across the whole library, which is like comparing every word of your question to every word of every document. That’s too many checks.
- Here, the first step works at the whole-document level and is much cheaper, then the detailed word-by-word method is run only on a small set.
Extra speed-ups and memory tricks:
- Compression (quantization): Like saving photos with smaller file sizes, they compress the vectors (the numbers that represent text meaning) so they take less memory and can be processed faster. They test several kinds:
- OPQ
- MOPQ
- JMPQ (a learned version that often works best)
- Two simple reranking shortcuts:
- Candidate Pruning (CP): If first-step scores drop a lot after a certain point, stop considering the rest (they’re likely not useful).
- Early Exit (EE): If the top results don’t change for a while during checking, stop early.
Fair testing:
- They re-created (reproduced) several state-of-the-art systems built around multivector search (EMVB, WARP, IGP) on two public datasets (MS MARCO passages and LoTTE) to compare speed, memory, and result quality under the same conditions.
- They used modern search engines for the first step (kANNolo and Seismic) and standard encoders (Splade for sparse retrieval; ColBERTv2 for multivector reranking).
What they found and why it matters
Main findings:
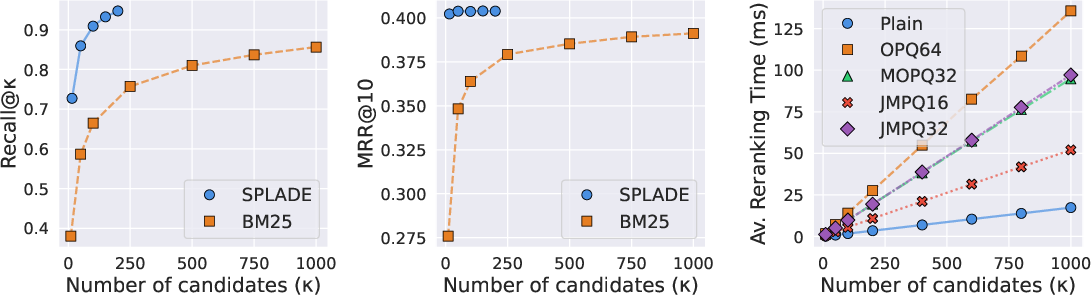
- Strong first step beats token-level gathering: Using a learned sparse retriever to get a shortlist is faster and picks more relevant candidates than older “token-level gather” methods.
- Big speed-ups with similar quality: Their two-stage setup is up to 24× faster than the best existing multivector systems, while keeping similar or better accuracy.
- Inference-free first step saves compute: Removing the query neural network in step 1 still keeps good results but makes searches faster.
- Small shortlists are enough: You only need to rerank around 20–50 candidates to get high-quality answers.
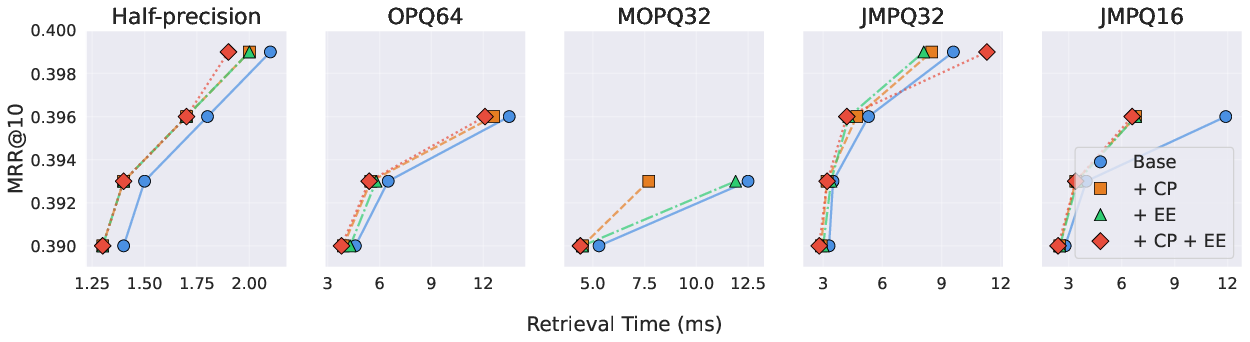
- Compression works: Smart compression (especially JMPQ) cuts memory by up to ~13× with tiny or no quality loss.
- Simple shortcuts help: Candidate Pruning and Early Exit speed up reranking by up to 1.8× with no drop in quality.
Why it matters:
- Real search systems need to be fast, cheap, and accurate. This approach keeps the accuracy of detailed comparisons but at much lower cost and delay, making it practical for large-scale use (like web search, help centers, or Q&A systems).
What this could change (implications)
- Two-stage search is the way to go: First use a smart, fast method to gather a small, meaningful shortlist; then apply detailed reranking. This can become the standard design for modern search engines.
- Lower costs, greener systems: Faster searches mean less computing power and energy, which matters at internet scale.
- Better user experience: Users get accurate results faster.
- Easier deployment: Compression and inference-free tricks make it simpler to run these systems on normal hardware.
- A stronger baseline for future research: The authors share an end-to-end implementation, so others can build on it and push the field forward.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues, missing analyses, and open directions arising from the paper that future researchers could concretely address.
- Dataset scope and generalization: evaluation is limited to MS MARCO v1 passages (dev.small) and LoTTE-pooled (search/dev). No experiments on document-level corpora, multi-lingual collections, or diverse benchmarks (e.g., BEIR, TREC DL), leaving generalization across domains, languages, and document lengths untested.
- End-to-end quality metrics: effectiveness is reported mainly via MRR@10 (MS MARCO) and Success@5 (LoTTE). Missing NDCG@10/100, Recall@k, MAP, and statistical significance tests to assess robustness and ranking fidelity at deeper cut-offs.
- Candidate generation recall vs. MaxSim truth: the paper motivates replacing token-level gather with LSR but does not quantify how often LSR fails to include the documents that would be top-ranked by full MaxSim. A per-query recall analysis of the true top-MaxSim neighbors (vs. LSR candidates) is needed to understand failure modes and tail behavior.
- Component-wise latency breakdown: the claim that query encoding with two neural encoders becomes the dominant bottleneck is not supported by isolated profiling. Provide detailed CPU time breakdown for query encoding, first-stage retrieval, and reranking across different hardware, query lengths, and parameter settings.
- Heuristic pruning and early exit: Candidate Pruning (CP) and Early Exit (EE) are simple heuristics (α, β thresholds) evaluated only on MS MARCO. Assess their impact on LoTTE and other datasets, quantify cases where late-arriving candidates improve the final top-k, and explore learned/adaptive stopping criteria with formal guarantees.
- Sensitivity to candidate size: the reranking stage is limited to κ ≤ 50. Investigate behavior for larger κ (e.g., κ ∈ [100, 1000]) needed by high-recall or exploratory tasks, and design per-query adaptive κ selection strategies based on first-stage signals and uncertainty estimates.
- Memory footprint and scalability: storing both sparse (4–13 GB) and multivector (10–22.5 GB) representations is substantial for ~2–9M-passage corpora. Analyze scalability to 100M–1B documents, including memory-tiering (RAM/disk), compression of sparse indices, and distributed deployment implications.
- Index maintenance and dynamism: the pipeline’s behavior under frequent updates (insertions/deletions), re-quantization needs for OPQ/MOPQ/JMPQ, and incremental retraining or codebook adaptation is unexplored. Quantify update latencies and quality drift over time.
- Supervised quantization generalization: JMPQ is trained on MS MARCO and not evaluated cross-domain (LoTTE uses MOPQ). Study domain-shift effects, cross-collection generalization, and the cost/benefit of supervised quantization vs. unsupervised alternatives.
- Quantization error analysis: effectiveness comparisons do not include reconstruction error diagnostics. Provide token-level and document-level error distributions, their impact on MaxSim score perturbations, and calibration/compensation methods for quantization-induced bias.
- First-stage engine diversity: only kANNolo (sparse HNSW) and Seismic (block-pruned inverted index) are tested. Compare with other state-of-the-art sparse engines (e.g., Block-Max Pruning, Dynamic Superblock Pruning) and graph/inverted hybrids to ensure conclusions are engine-agnostic.
- Comparative coverage of hybrid baselines: several relevant hybrids (Splate, SLIM, BGE-M3, SparseEmbed, MUVERA) are absent from experiments. Add these baselines with end-to-end latency and memory measurements to validate the proposed approach against the broader field.
- Interaction function variants: reranking uses ColBERT-style MaxSim. Explore alternative late-interaction functions (e.g., weighted MaxSim, top-m aggregation, attention-based interactions) and their compatibility with quantization and SIMD acceleration.
- Query type robustness: the pipeline’s performance for short/ambiguous queries, rare-term queries, numeric/code-heavy queries, and OOV/morphologically rich languages is unknown—especially under inference-less LSR. Conduct stratified analyses by query class and term distribution.
- Fairness of “single-encoder” comparisons: inference-less LSR removes the query encoder, aligning with competitor pipelines that use one encoder at query time. However, explicit fairness checks (e.g., matching compute budgets, encoding caches, batching effects) are not reported. Provide matched scenarios across all methods.
- Parameter tuning reproducibility: grid-search ranges for ef_s, κ, α, β and Seismic accuracy targets (Accuracy@50) are dataset-specific. Document seeds, tuning protocols, and selection criteria to ensure reproducibility across runs and collections.
- Throughput and parallelism: searches are executed single-core for fairness, but production systems rely on multi-core/GPU parallelism. Profile throughput under concurrent queries, multi-threading, SIMD/GPU offloading, and energy/compute cost to validate real-world deployability.
- Preprocessing costs: OPQ/MOPQ/JMPQ training and preprocessing overheads are noted qualitatively but not quantified. Report wall-clock training times, memory usage during codebook learning, and amortization over index lifetime.
- Integration and deployment: practical concerns (index build pipelines, cold-start behavior, caching strategies, query batching) are not addressed. Provide guidelines and measurements for operational deployment in large-scale systems.
- Failure case analysis: the paper argues BM25 yields noisy candidates even at large κ. Conduct detailed qualitative/quantitative error analyses comparing BM25-, LSR-, and token-level-gather candidate sets to identify recurring failure patterns and guide hybrid candidate fusion strategies.
- Adaptive multi-signal gather: explore combining multiple first-stage signals (BM25 + LSR + dense single-vector) with learned fusion or cascade selection to further improve recall/coherence without inflating reranking cost.
- Privacy and content leakage: storing token-level embeddings and sparse term weights may expose sensitive content. Assess privacy risks and explore techniques (e.g., differential privacy, secure embeddings) to mitigate leakage in multivector/sparse indexes.
- Licensing and reproducibility details: the anonymous code release lacks explicit training seeds, exact versions for quantizer training, and full competitor index-building scripts. Provide complete artifacts to ensure exact reproduction of reported numbers.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can adopt the paper’s two-stage “LSR first-stage + multivector reranker” pipeline, compression schemes, and reranking optimizations now.
- Search stack upgrade for web and enterprise search (software, e-commerce, media)
- What: Replace BM25 or token-level gather in existing stacks with learned sparse retrieval (e.g., Splade or inference-less Li-LSR via Seismic) and rerank with ColBERTv2 using small candidate sets (≤50), applying CP/EE for SLA control.
- Why: Up to 24× end-to-end speedups and 7–12.8× memory reductions with comparable or better relevance.
- Tools/workflows: Seismic (inverted index) or kANNolo (sparse HNSW) for first-stage; kANNolo RerankIndex for multivector reranking; JMPQ/MOPQ/OPQ for compression; CP/EE knobs (α, β) for latency.
- Assumptions/dependencies: Availability of Splade/Li-LSR/ColBERTv2 checkpoints, index build time, domain mismatch risk (tune κ, α, β to maintain recall), CPU SIMD support for MaxSim, integration into the current search service.
- Cost- and latency-aware RAG retrieval for LLM applications (software, customer support, analytics)
- What: Use inference-less LSR to remove query encoder at runtime and ColBERTv2 reranking for higher-quality contexts with small candidate budgets; integrate CP/EE to bound latency.
- Why: Improves context quality and reduces tail latency and CPU/GPU costs in retrieval-augmented generation.
- Tools/workflows: Seismic + Li-LSR for first-stage; ColBERTv2 + JMPQ32/JMPQ16 for compact reranker; per-query early-exit triggers for tight SLAs.
- Assumptions/dependencies: RAG pipeline must accept small top-k; token budget constraints; domain adaptation may be needed for non-English content.
- E-commerce product search and sponsored listing reranking (e-commerce, advertising)
- What: Two-stage neural retrieval for product catalogs; rerank 20–50 candidates to balance relevance and latency; use CP/EE for peak-load control.
- Why: Fewer reranked candidates reduce serving cost while maintaining relevance metrics similar to full token-level pipelines.
- Tools/workflows: Seismic first-stage, compressed multivector reranker; A/B testing harness; real-time reindexing policy for assortment updates.
- Assumptions/dependencies: Product text quality and coverage; real-time index refresh strategies; catalog segmentation into passages if needed.
- Internal knowledge base and helpdesk search (software, enterprise IT)
- What: Deploy the two-stage pipeline in enterprise search portals and help centers to improve semantic coverage over FAQ/KB documents at CPU-only cost.
- Why: Better query-understanding than BM25 without GPU dependencies; lower ops costs than token-level gather pipelines.
- Tools/workflows: OpenSearch/Elasticsearch + Seismic for sparse retrieval; RerankIndex microservice for late interaction; monitoring of κ, α, β for SLA/quality.
- Assumptions/dependencies: Access control integration; incremental indexing support; English-centric models unless adapted.
- Legal e-discovery and compliance search (legal, finance)
- What: Use LSR + multivector reranking to improve recall@small-κ for large corpora of contracts, policies, and filings; compress embeddings to fit large collections in RAM.
- Why: Faster turnaround for investigations with CPU-only serving; improved semantic recall vs lexical-only stacks.
- Tools/workflows: Seismic with tuned block pruning; JMPQ32 for memory savings; CP/EE to cap worst-case latencies.
- Assumptions/dependencies: Passage segmentation for long documents; auditability/traceability requirements; domain-specific fine-tuning may be needed.
- Clinical guideline and biomedical literature retrieval (healthcare, research)
- What: Two-stage retrieval for guidelines, PubMed abstracts, and internal protocols; small candidate reranking to keep latency low.
- Why: Better semantic matching for clinician queries than BM25; CPU-only feasibility for on-prem or privacy-sensitive settings.
- Tools/workflows: Seismic/Li-LSR first-stage; ColBERTv2 reranker with JMPQ16 for memory-constrained environments.
- Assumptions/dependencies: Regulatory and privacy constraints; domain adaptation of models for biomedical vocabulary.
- Developer documentation and code search (software engineering)
- What: Apply LSR + multivector reranking to API docs, READMEs, internal wikis; optionally segment code/comments as passages.
- Why: Improved relevance on ambiguous natural-language queries; lower infra cost vs token-level gather solutions.
- Tools/workflows: Seismic indices co-located with docsets; CP/EE for interactive latency; compression for fitting large repos.
- Assumptions/dependencies: Tokenization strategies for code; potential need for domain-specific encoders.
- Memory-optimal ColBERT deployments via quantization (software, infra)
- What: Use JMPQ16/JMPQ32 or MOPQ32 to reduce memory footprint by 7–12.8× without quality loss, enabling denser multi-tenant deployments.
- Why: Significant RAM savings with minimal MRR degradation; improved cost efficiency.
- Tools/workflows: Offline compression pipeline (JMPQ supervised, MOPQ/OPQ unsupervised); integrated into index build jobs.
- Assumptions/dependencies: JMPQ requires supervised training and compute; verify effectiveness on in-domain data.
- Latency-SLA orchestration with CP/EE (software, ops)
- What: Integrate candidate pruning and early-exit policies to stabilize tail latency while preserving top-k quality.
- Why: 1.8× reranking speedups reported with no measurable loss in effectiveness.
- Tools/workflows: Online controllers that tune α (CP) and β (EE) per query class or traffic condition; dashboards tracking MRR@10/Success@5 vs P95 latency.
- Assumptions/dependencies: Requires telemetry and safe-guard rails to revert if quality dips; per-domain re-tuning.
- Academic reproducibility and benchmarking (academia)
- What: Use the released kANNolo RerankIndex + Seismic recipes to benchmark new encoders, compression, and reranking strategies under a unified framework.
- Why: Comparable baselines and end-to-end latency metrics accelerate fair evaluation and ablations.
- Tools/workflows: Provided Rust implementation, dataset recipes (MS MARCO, LoTTE), grid search over ef_s, κ, α, β.
- Assumptions/dependencies: Compute availability for index builds; consistent hardware for timing comparisons.
Long-Term Applications
These opportunities are promising but require further research, model adaptation, scaling, or ecosystem integration.
- On-device private semantic search (daily life, healthcare, field ops)
- What: Run inference-less LSR + compressed multivector reranking on edge devices (laptops, mobile) for offline or private search.
- Why: Eliminates network dependency and preserves privacy; compression fits more data into limited RAM.
- Required advances: ARM-optimized SIMD for MaxSim; incremental/streaming indexing; careful energy profiling; multilingual encoders.
- Dependencies: Efficient on-device index updates; robust memory management; secure local storage.
- Real-time or streaming indexing at web scale (software, media)
- What: Support high-frequency updates for news, products, and user-generated content while keeping two-stage SLAs.
- Why: Broader applicability to freshness-sensitive applications.
- Required advances: Low-latency Splade/Li-LSR document updates; fast multivector embedding and compression pipelines; background rebuild strategies.
- Dependencies: Engineering for near-real-time ingestion; consistency guarantees across stages.
- Domain-specific supervised compression (JMPQ) and multilingual generalization (global enterprises, public sector)
- What: Train JMPQ per domain/language to retain peak effectiveness under aggressive compression.
- Why: Extends memory and latency gains to specialized domains and non-English corpora.
- Required advances: Labeled training data and compute for end-to-end supervised compression; evaluation across languages and domains.
- Dependencies: Data availability; regulatory compliance for training on proprietary text.
- Federated and privacy-preserving retrieval across silos (finance, healthcare, government)
- What: Two-stage retrieval over distributed indices with secure aggregation of candidate sets and local reranking.
- Why: Keep data in place while enabling cross-silo search with limited bandwidth and strong privacy constraints.
- Required advances: Protocols for federated sparse retrieval and secure candidate merging; privacy guarantees for token and vector signals.
- Dependencies: Network constraints; policy/legal frameworks; secure enclaves or HE/MPC if required.
- Multimodal two-stage retrieval (media, e-commerce)
- What: Extend LSR-style sparse first-stage and multivector reranking to text–image or text–audio scenarios.
- Why: Unify semantic search across modalities with similar efficiency gains.
- Required advances: Mature multimodal sparse encoders; multivector late-interaction for non-text features; joint compression methods.
- Dependencies: Modality-specific datasets and benchmarks; serving engines for mixed sparse/dense posting lists.
- Auto-tuning controllers for SLA–quality trade-offs (software, ops)
- What: Bandit/learning-based controllers that adjust κ, α, β, and ef_s online by segment, query intent, or load.
- Why: Maintain target relevance while minimizing median and tail latency under variable traffic.
- Required advances: Safe exploration strategies; interpretable control policies; robust telemetry loops.
- Dependencies: Observability stack; rollback mechanisms; data drift monitoring.
- Turnkey plugins for popular search engines and vector databases (software vendors)
- What: Production-grade connectors offering Seismic/LSR first-stage and multivector reranking for Elasticsearch/OpenSearch/Vespa/pg_vector.
- Why: Broad adoption via familiar platforms, simplifying migration from BM25-only stacks.
- Required advances: Stable APIs, sharding/replication support for sparse + multivector stores; operational guides.
- Dependencies: Vendor ecosystem collaboration; performance parity on distributed clusters.
- Energy- and cost-aware procurement guidelines (policy, sustainability)
- What: Evidence-based recommendations for public and large-scale deployments to adopt energy-efficient two-stage neural retrieval.
- Why: 24× speedups and CPU-only serving can reduce energy use and cloud spend.
- Required advances: Independent LCA studies on energy/carbon; standardized reporting (e.g., joules/query).
- Dependencies: Access to infra telemetry; policy frameworks that reward efficiency.
- Retrieval services for LLM agents and tool use (software, AI platforms)
- What: Latency-bounded retrieval microservices that provide high-quality context in multi-tool agent pipelines.
- Why: Agent step-times are sensitive to tail latency; small rerank sets reduce overall toolchain delays.
- Required advances: Orchestration SDKs; per-agent adaptive κ and CP/EE policies; caching strategies across tool calls.
- Dependencies: Interoperability with agent frameworks; monitoring across multi-step tasks.
- Robustness on long documents and structured data (legal, technical standards)
- What: Methods to segment, index, and rerank very long or structured documents with consistent recall and latency.
- Why: Many high-value corpora exceed passage lengths used in current benchmarks.
- Required advances: Segmentation strategies, cross-segment aggregation, structure-aware multivector scoring; efficient update schemes.
- Dependencies: Domain-specific schemas; evaluation datasets and metrics beyond passages.
Glossary
- Accuracy@50: An evaluation metric for ANN configurations measuring the fraction of true nearest neighbors present among the top-50 results. "For Seismic, we first tune its construction and search parameters to reach Accuracy@50 (the fraction of true nearest neighbors contained within the top-50 approximate retrieval results) levels in with $0.01$ steps."
- Approximate Nearest Neighbors (ANN): Algorithms and data structures for efficiently retrieving near neighbors approximately rather than exactly. "Modern retrieval pipelines rely on efficient Approximate Nearest Neighbors (ANN) search or inverted-index engines to support fast retrieval."
- Block-Max Pruning: An inverted-index technique that accelerates query processing by pruning blocks based on their maximum possible contribution. "Complementary to graph-based ANN approaches, another family of systems leverages inverted indexes optimized for LSR, including Block-Max Pruning~\cite{bmp}, Dynamic Superblock Pruning~\cite{dsbp}, and Seismic \cite{seismic,seismic_knn,seismic_journal}."
- BM25: A classical probabilistic bag-of-words ranking function for lexical information retrieval. "In literature, BM25\ and similar lexical bag-of-words models have been widely used for first-stage retrieval."
- Candidate Pruning (CP): A reranking optimization that truncates the candidate list when first-stage scores drop sharply below a threshold. "Candidates Pruning (CP): we truncate the candidate list using a threshold based on the difference between the -th candidate score and subsequent scores."
- ColBERT: A multivector late-interaction model that encodes token-level vectors and scores with MaxSim. "Late-interaction models such as ColBERT \cite{colbert} and Xtr \cite{xtr} represent each document as a set of token-level vectors and compute relevance through the operator, which allows every query token to interact with every document token."
- ColBERTv2: An improved ColBERT variant introducing residual compression and better training. "ColBERTv2 \cite{colbertv2} introduced residual compression and improved training."
- Dynamic Superblock Pruning: An inverted-index optimization that prunes larger superblocks to reduce evaluation. "Complementary to graph-based ANN approaches, another family of systems leverages inverted indexes optimized for LSR, including Block-Max Pruning~\cite{bmp}, Dynamic Superblock Pruning~\cite{dsbp}, and Seismic \cite{seismic,seismic_knn,seismic_journal}."
- Early Exit (EE): A reranking optimization that stops evaluating more candidates once the top results stabilize for several steps. "Early Exit (EE): during reranking, if the top- results remain unchanged for consecutive candidates, we stop reranking early, speculating on the fact that successive candidates are unlikely to improve the final ranking."
- Hierarchical Navigable Small World (HNSW): A graph-based ANN index enabling fast search via hierarchical layers. "When building HNSW with kANNolo, we experimentally verify that number of neighbors and construction precision yield optimal results respectively on LoTTE and MsMarco."
- Inverted Document Frequency (IDF): A term-weighting factor reflecting how rare or informative a term is across documents. "Subsequent work introduced more sophisticated scoring mechanisms like integrating an Inverted Document Frequency (IDF) term into the loss function and use term IDF as query scores~\cite{DBLP:journals/corr/abs-2411-04403}."
- Inverted index: A retrieval structure mapping terms to postings lists, enabling efficient sparse querying. "LSR supports efficient inverted index retrieval~\cite{seismic,bmp}."
- Jointly-optimized Multivector Product Quantization (JMPQ): A supervised multivector PQ method that jointly optimizes codebooks and the query encoder. "JMPQ: Jointly-optimized Multivector Product Quantization~\cite{jmpq}, is a supervised version of Multivector-PQ that jointly optimizes both levels and the query encoder to minimize the reconstruction error."
- kANNolo: A research-oriented ANN library supporting both dense and sparse retrieval. "kANNolo \cite{kannolo} is a research-oriented ANN library that supports both dense and sparse retrieval."
- Learned Sparse Retrieval (LSR): Neural approaches that produce sparse, interpretable term-weight vectors capturing contextual semantics. "Learned Sparse Retrieval (LSR) approaches bridge the gap between lexical and dense models by generating sparse term-weight representations that capture contextual semantics beyond exact token matching~\cite{sparse1,sparse2,sparse3}."
- Li-Lsr: An inference-less sparse retrieval method that learns a fixed lookup from terms to scores. "Learned Inference-less Sparse Retrieval (Li-Lsr)~\cite{li-lsr} learns an optimal lookup table at training time by projecting the static word embeddings into a scalar value by means of a linear layer."
- MaxSim: A late-interaction scoring operator summing per-query-token max similarities to document tokens. "a refine phase that applies full scoring on these candidates to produce the final ranking."
- Multivector: Representations that encode queries/documents as sets of token-level vectors enabling fine-grained interactions. "Learned multivector representations power modern search systems with strong retrieval effectiveness, but their real-world use is limited by the high cost of exhaustive token-level retrieval."
- Optimized Product Quantization (OPQ): A PQ variant applying a rotation to subspaces to reduce quantization error. "Optimized Product Quantization~\cite{opq} is a variant of PQ~\cite{pq} that rotates the subspaces to improve compression."
- Product Quantization (PQ): A vector compression method partitioning dimensions into subspaces and quantizing each independently. "Emvb \cite{emvb} further optimized ColBERT-style retrieval through bit-vector prefiltering, SIMD acceleration, and PQ-based~\cite{pq} refinement, achieving up to faster retrieval than Plaid, with minimal quality loss."
- Proximity-graph indexes: Graph-based structures built over neighbor relationships to drive efficient ANN search. "Igp \cite{igp} introduced an incremental greedy probing strategy over proximity-graph indexes, which incrementally expands search regions and finds high-quality candidates with fewer probes."
- Reranking: A second-stage scoring step that reorders initial candidates using a more expressive model. "We implement the reranking in the kANNolo library by introducing the RerankIndex structure."
- Seismic: A state-of-the-art inverted-index engine for LSR that prunes computation by ranking blocks via summaries. "Seismic\ represents the current state-of-the-art in LSR."
- SIMD: CPU vector instructions enabling parallel computation on arrays for speedups. "an optimized operator for late interaction exploiting SIMD instructions"
- Splade: A learned sparse encoder with sparsity-inducing regularization and log-saturation producing interpretable term weights. "A cornerstone in this family is Splade \cite{splade}, which introduced sparsity-inducing regularization and log-saturation on term weights to produce highly sparse, interpretable representations while preserving semantic coverage."
- Success@5: An effectiveness metric indicating whether the correct answer appears within the top-5 results. "MRR@10 on MsMarco $38.3$, Success@5 on LoTTE $69.0$"
- Two-stage retrieval: A pipeline with a fast first-stage candidate generator followed by a more expensive reranker. "This design naturally aligns with the classical two-stage retrieval architecture."
- UniCOIL-T5: A sparse retrieval approach that enriches documents with contextual terms predicted by T5 models. "Early works such as UniCOIL-T5~\cite{unicoil1,unicoil2} expanded document text with contextual terms predicted by DocT5Query~\cite{doc2query}, enabling lexical-style indexing with neural enrichment."
- XTR: A multivector method that reshapes training to make token-level retrieval predictive of document relevance. "XTR~\cite{xtr} redefines the training objective to make token retrieval itself more predictive of document-level relevance, partially closing the trainingâinference gap."
Collections
Sign up for free to add this paper to one or more collections.