Over-Searching in Search-Augmented Large Language Models
Abstract: Search-augmented LLMs excel at knowledge-intensive tasks by integrating external retrieval. However, they often over-search -- unnecessarily invoking search tool even when it does not improve response quality, which leads to computational inefficiency and hallucinations by incorporating irrelevant context. In this work, we conduct a systematic evaluation of over-searching across multiple dimensions, including query types, model categories, retrieval conditions, and multi-turn conversations. Our finding shows: (i) search generally improves answer accuracy on answerable queries but harms abstention on unanswerable ones; (ii) over-searching is more pronounced in complex reasoning models and deep research systems, is exacerbated by noisy retrieval, and compounds across turns in multi-turn conversations; and (iii) the composition of retrieved evidence is crucial, as the presence of negative evidence improves abstention. To quantify over-searching, we introduce Tokens Per Correctness (TPC), an evaluation metric that captures the performance-cost trade-off for search-augmented LLMs. Lastly, we investigate mitigation approaches at both the query and retrieval levels and release the OverSearchQA to foster continued research into efficient search-augmented LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a problem with AI chatbots that use search tools (like web search or databases) to find information. These chatbots are called “search‑augmented LLMs” (LLMs). The problem is over‑searching: the model keeps searching even when searching won’t help. This wastes computer resources (money and time) and can lead to wrong answers if the model pulls in misleading information. The authors study when and why over‑searching happens, how to measure it, and what we can do to reduce it. They also release a new test set called OverSearchQA to help other researchers study this issue.
Key objectives and questions
The paper asks simple but important questions:
- When does using search help a chatbot give better answers, and when does it make things worse?
- Do some kinds of chatbots over‑search more than others?
- Does the quality of search results change how often a model over‑searches?
- What happens in multi‑turn chats (long conversations): does over‑searching snowball over time?
- Can we measure the “cost vs. benefit” of searching?
- What practical steps can reduce over‑searching?
How the researchers studied it
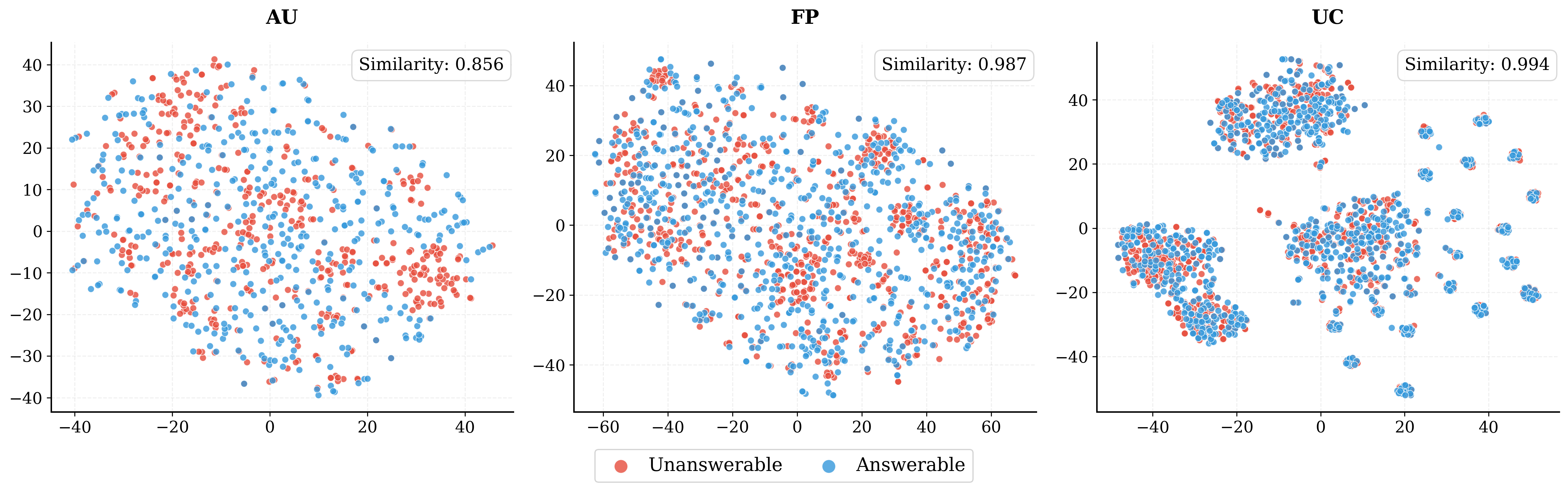
The team built a new dataset called OverSearchQA with 1,188 questions. Half are answerable, and half are unanswerable on purpose. Unanswerable questions fall into three everyday types:
- Answer Unknown: things nobody knows yet, like future events.
- False Premise: questions based on a wrong assumption (e.g., “How many eggs do tigers lay?”—tigers are mammals and don’t lay eggs).
- Underspecified Context: questions that are too vague (e.g., “What is the capital of Georgia?” without saying the country or the U.S. state).
They tested many different AI models, both with search turned off and with search turned on. They measured two kinds of “being correct”:
- Answer accuracy: correct answers for answerable questions.
- Abstention accuracy: correctly refusing to answer unanswerable questions (for example, saying “I don’t know,” pointing out a false assumption, or asking for clarification).
They also introduced a new metric called Tokens Per Correctness (TPC). Think of TPC like “cost per correct outcome”: how many generated words (tokens), input tokens, and search calls did the model use for each correct result? Lower TPC is better. It’s a way to check if the model is being efficient, not just accurate.
To judge whether the model’s responses were correct or proper abstentions, they used strong AI “judges” and confirmed that the judges agreed with each other and with human annotations most of the time.
They also varied the source of information:
- Wikipedia (new and old versions),
- A noisy web‑text dataset without Wikipedia,
- Live web search.
They studied how the balance of “positive evidence” (documents that look like they support an answer) versus “negative evidence” (documents that indicate the question is unanswerable, unclear, or based on a mistake) affects behavior. They also tested multi‑turn conversations (more than one back‑and‑forth) and tried simple fixes, like better prompting and adding synthetic “negative evidence” documents to the search database.
Main findings and why they matter
Here are the main takeaways explained simply:
- Search helps on answerable questions but hurts on unanswerable ones.
- When a question has a real answer, search tends to make accuracy go up.
- When a question should be refused, search makes abstention accuracy go down. The model often tries to answer anyway, pulling in misleading info.
- More complex “reasoning” models over‑search more.
- Models designed to think longer or do deep research keep searching and reasoning, which raises costs and can reduce the ability to say “I don’t know.”
- TPC (cost per correct outcome) increases as models do more searching and longer reasoning, showing inefficiency.
- Failing to abstain is the most expensive mistake.
- When a model answers an unanswerable question, it often searches over and over, spending lots of compute, but still ends up wrong.
- Noisy or low‑quality retrieval makes over‑searching worse.
- Using messier sources pushes models to search more and spend more tokens, greatly increasing TPC.
- Live web search can boost answer accuracy (because it sees more up‑to‑date info) but tends to make abstention worse (more mixed signals).
- The type of evidence matters.
- If retrieved documents clearly say the question is unanswerable (negative evidence), models almost always abstain correctly.
- But negative evidence is rare in the real world, because most documents talk about what we do know, not what we don’t know. This rarity makes abstention harder.
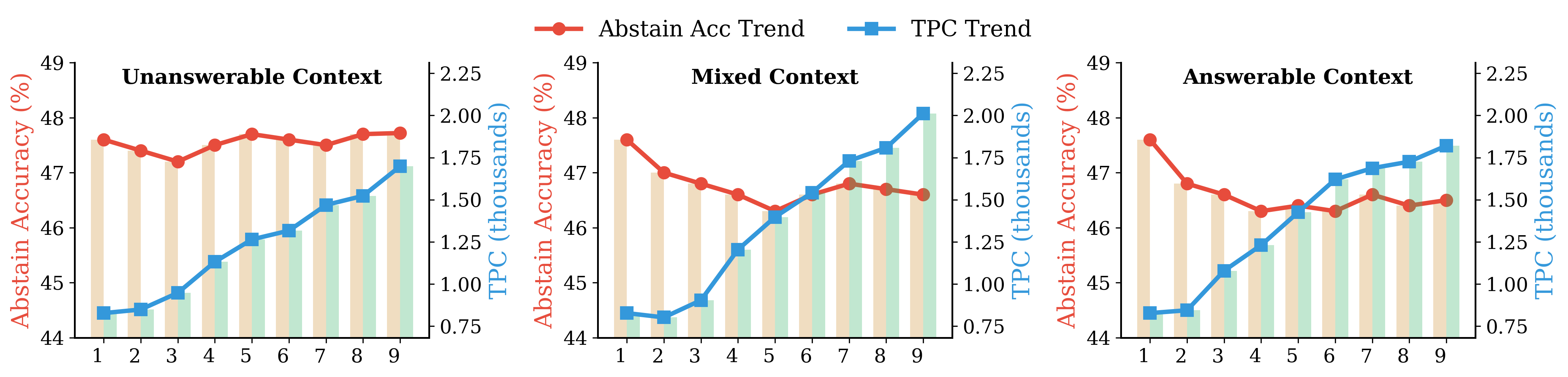
- Multi‑turn chats can snowball over‑searching.
- If earlier turns are answerable, the model gets “in the habit” of answering, and it’s more likely to try to answer the final unanswerable question.
- TPC rises as the conversation gets longer, meaning costs pile up.
- Simple fixes help, but don’t solve it fully.
- Better prompts (instructing the model to consider abstention, showing examples, or adding a self‑evaluation step) can increase abstention accuracy, but may also lower answer accuracy or raise costs.
- Adding synthetic negative evidence to the database helps a little, but not enough, because those documents are hard to retrieve and get drowned out by positive evidence.
Overall, the paper shows a clear trade‑off: search improves correct answers when answers exist, but it makes it harder for models to refuse unanswerable questions. And extra searching often adds cost without improving correctness.
Implications and potential impact
This research highlights that smart AI systems shouldn’t just be good at finding answers—they also need to know when to stop searching and say “I don’t know.” That’s important for:
- Safety: fewer confident but wrong answers.
- Cost: less wasted time and money on unnecessary searches.
- Trust: more honest behavior when information is missing or unknowable.
The TPC metric gives teams a simple way to track efficiency, not just accuracy. The OverSearchQA dataset makes it easier for others to test and improve abstention and search efficiency.
Future systems might:
- Use better rules or training to decide when to search and when to abstain.
- Improve retrieval to surface “negative evidence” that explains why a question is unanswerable.
- Adjust conversational memory to avoid snowballing into over‑searching across turns.
- Reward models not only for correct answers but also for correct refusals, balancing accuracy with responsible behavior.
In short, this paper points out a common flaw in search‑augmented AI and offers tools and ideas to build systems that are both smart and sensible about when to look things up—and when not to.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, organized to guide actionable future research.
- Instance-level characterization of over-searching: Develop per-query criteria and causal attribution methods to identify when additional searches are unnecessary or harmful, beyond aggregate curves and TPC plateaus.
- Learning a search-gating policy: Design and evaluate models that predict answerability before invoking search, with calibrated uncertainty thresholds, dynamic stopping rules, and budget-aware policies.
- Training-time interventions: Explore reinforcement learning or preference optimization that explicitly penalizes unnecessary tool use, integrates abstention-aware rewards, and optimizes TPC directly during training.
- Retrieval systems that surface negative evidence: Create indexing and ranking methods to prioritize uncertainty cues (e.g., contradictions, “unknown” statements), measure their impact on abstention, and compare synthetic vs. mined negative evidence.
- Noise-aware retrieval and filtering: Develop algorithms to detect and downweight misleading “positive” documents and low-quality sources; quantify how source trustworthiness affects abstention and search depth.
- Dynamic search budgeting: Learn per-query early-exit policies, multi-armed bandit or ROI-based stopping criteria that consider retrieval confidence and marginal correctness gains.
- Real-world data coverage: Collect and analyze unanswerable queries from production search logs (including temporal drift and novelty), assess distribution shifts vs. OverSearchQA, and extend to domain-specific (medical, legal) and multilingual settings.
- Multilingual and cross-cultural abstention cues: Evaluate over-searching across languages, differing corpora, and cultural norms about uncertainty and refusal; adapt retrieval and prompting accordingly.
- Generalization beyond search tools: Extend analysis and metrics to other tools (e.g., code execution, calculators, browsing pipelines) to study “over-tooling” and cross-tool compounding costs.
- Causal mechanism of abstention degradation: Conduct controlled experiments that inject distractors or contradictory snippets to isolate whether retrieval context overrides base-model caution and why.
- Clarification-first interaction design: Compare strategies that ask clarifying questions before searching vs. immediate retrieval; quantify effects on abstention accuracy, user satisfaction, and TPC.
- Multi-turn memory and snowball prevention: Investigate state management (e.g., memory pruning, decay of search propensity, turn-level resets) that prevent search behavior from compounding across conversation turns.
- Robustness across retrievers and parameters: Systematically vary top-k, retriever types (dense vs. sparse, hybrid), query reformulation, and web search providers to map how retrieval knobs affect over-searching and abstention.
- High-quality negative evidence generation: Develop scalable methods to generate and rank realistic “unknown”/“cannot be answered” documents (not just synthetic placeholders), with training signals that improve their retrieval placement.
- Metric validity and alternatives: Test TPC sensitivity to cost coefficients (λ, μ), include wall-clock latency, energy, memory, and concurrency costs; compare TPC against cost-quality Pareto frontiers and user-centric metrics.
- LLM judge reliability and standards: Expand human validation, inter-judge calibration, and public benchmarks with standardized abstention taxonomies to reduce judge bias and improve reproducibility.
- Partial-helpfulness vs. abstention: Define graded scoring for responses that appropriately refuse a direct answer but provide safe context or clarifications; assess how search affects partial-helpfulness trade-offs.
- Safety and trust implications: Measure hallucination rates induced by over-search, user trust impacts, and design transparency norms (e.g., signaling when a system abstains or stops searching and why).
- Integration of uncertainty modeling: Combine Bayesian or calibrated confidence estimates with retrieval signals to govern search initiation and termination; evaluate thresholds that optimize both correctness and TPC.
- Proprietary model replicability: Provide open-source proxies and controlled ablations for “deep research” systems to enable reproducible studies of reasoning depth, search frequency, and over-searching dynamics.
- Domain and time sensitivity: Evaluate over-searching for time-sensitive facts (e.g., future events, rapidly changing topics), and assess how stale knowledge snapshots interact with abstention decisions.
- Scaling and refinement of OverSearchQA: Expand dataset size, include real retrieval contexts, annotate presence of negative/positive evidence, update corpora snapshots, and audit for leakage or outdated content.
- Mitigation trade-off calibration: Systematically quantify over-abstention risks from prompt-based mitigations, develop techniques that preserve answer accuracy while restoring abstention (e.g., adaptive few-shot examples).
- Tool-use alignment objectives: Explore post-training alignment that encodes rational search norms (e.g., abstain when evidence is insufficient), study side effects on general reasoning and willingness to answer.
- Real-time search constraints: Investigate asynchronous or time-bounded search, timeouts, and progressive retrieval to reduce over-searching under latency constraints while maintaining correctness.
Glossary
- Abstention: A model’s deliberate choice to withhold a direct answer when a question is unanswerable or uncertain. "Abstention has become an active research topic as it is crucial to prevent LLMs from producing incorrect or misleading responses."
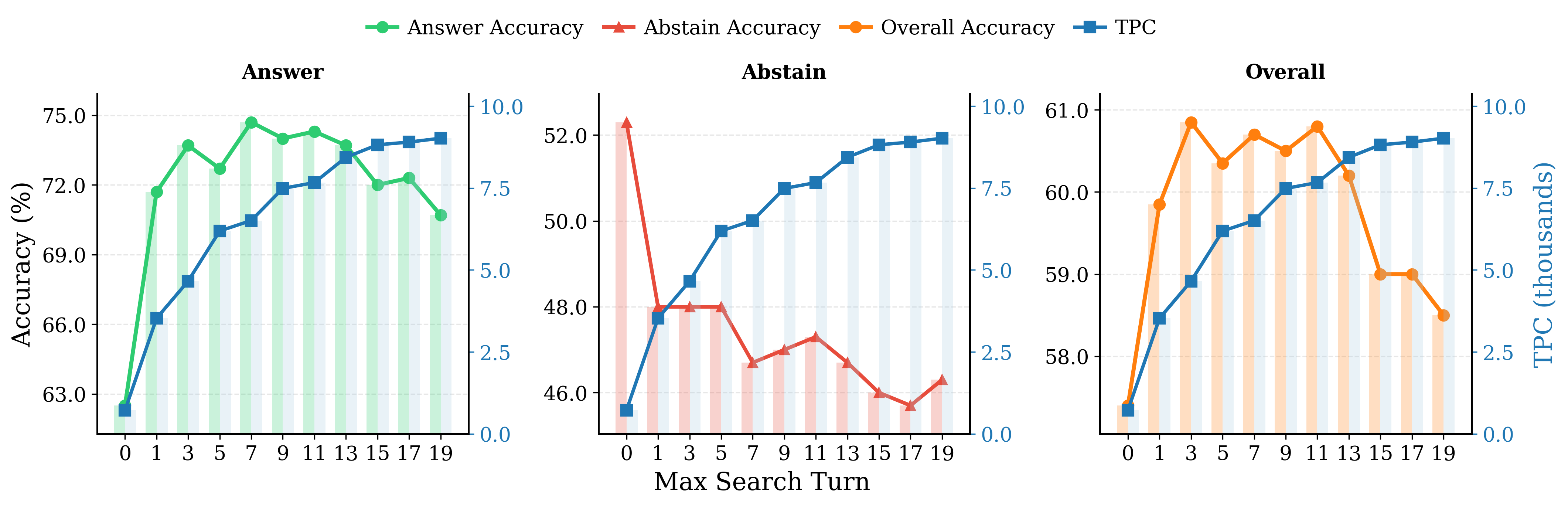
- Abstention accuracy: The fraction of unanswerable queries for which the model correctly abstains. "Abstention accuracy (on unanswerable queries) consistently degrades with more searches."
- Abstention-aware: A prompt-based strategy that explicitly instructs the model to consider abstaining when appropriate. "Abstention-aware explicitly instruct models to consider abstention as a valid response when queries are unanswerable;"
- Abstention cues: Signals in retrieved content (often “negative evidence”) that indicate a query is unanswerable. "Abstention Cues Are Rare."
- Abstention failure: The costly behavior where a model answers a query that should be abstained from. "abstention failure (i.e., answering unanswerable queries) remains the highest TPC for most models,"
- Answer accuracy: The fraction of answerable queries for which the model provides a correct answer. "Answer accuracy (on answerable queries) significantly improves from no search to one search, then peaks around 7 searches and plateaus."
- Answer Unknown (AU): A category of questions about future events or unsolved problems that cannot be answered. "Answer Unknown (AU) -- future events and unsolved problems;"
- C5: A noisy text corpus with Wikipedia removed, used to study retrieval quality effects. "C5, a noisy corpus from \citet{c5} with Wikipedia content removed;"
- Corpus augmentation: Adding documents (e.g., synthetic negative evidence) to a retrieval corpus to influence model behavior. "we evaluate corpus augmentation for over-searching mitigation by inserting 10 synthetic negative evidence for all queries into the corpus"
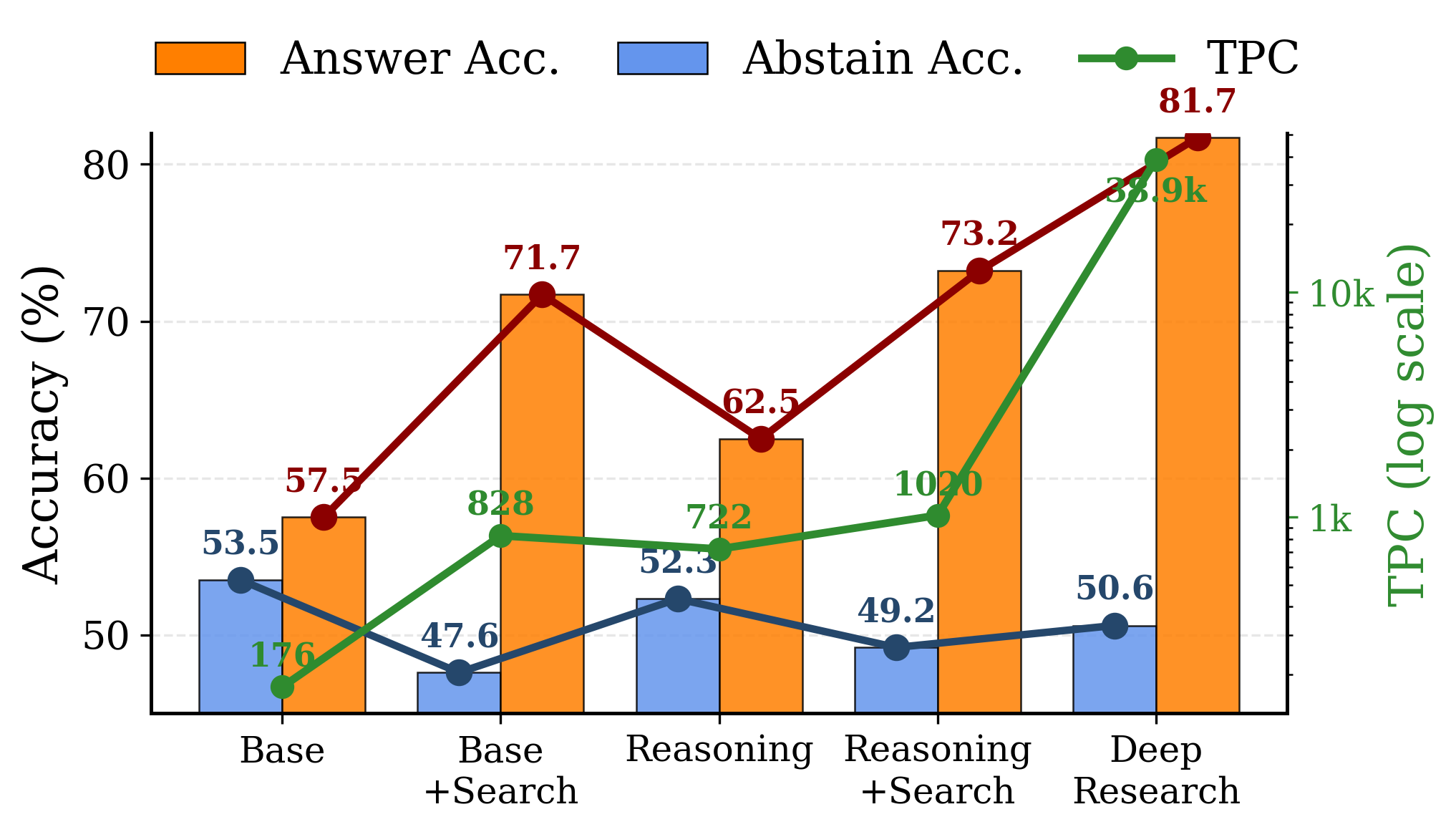
- Deep Research: A tool-augmented configuration that performs extensive, multi-round external research during reasoning. "The Deep Research configuration, for example, reaches the highest answer accuracy but requires significant computational resources, suggesting that increased complexity amplifies over-searching."
- Dual Accuracy: Reporting both answer accuracy (on answerable queries) and abstention accuracy (on unanswerable queries). "Dual Accuracy."
- E5-base: A sentence-embedding model used as the default retriever for dense retrieval over Wikipedia. "Unless otherwise noted, we use Wikipedia (enwiki-20250801) with E5-base \citep{e5} as the default retriever."
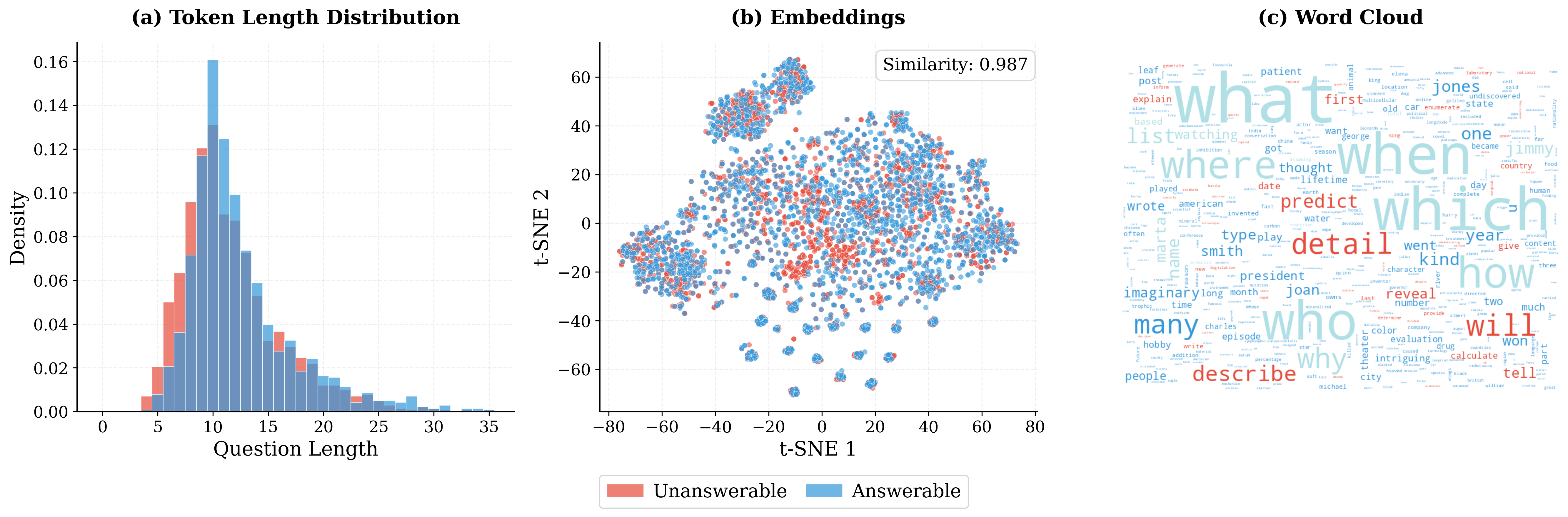
- Embedding neighborhoods: Groups of questions with similar vector embeddings used to match answerable and unanswerable items. "we draw answerable and unanswerable items from similar embedding neighborhoods"
- False Premise (FP): A category of questions containing incorrect assumptions or contradictions. "False Premise (FP) -- incorrect assumptions or contradictory claims;"
- Few-shot learning: Supplying exemplar cases in the prompt to guide behavior (e.g., correct abstention). "Few-shot learning provides examples of appropriate abstention behavior in the system prompt;"
- Grounding (responses): Anchoring model outputs in retrieved or external evidence to improve factuality. "By grounding responses in retrieved information, these models achieve state-of-the-art performance on several knowledge-intensive benchmarks"
- Instruction-tuned: Models fine-tuned to follow human-written instructions and behave accordingly. "instruction-tuned base models recognize the problematic queries and abstain,"
- Large reasoning models (LRMs): LLMs trained or optimized for extended, multi-step reasoning processes. "Large reasoning models (LRMs) such as OpenAI-o1~\citep{o1} and DeepSeek-R1~\citep{r1} improve problem-solving through extended reasoning traces via reinforcement learning."
- LLM judge: Using a LLM as an evaluator to assess correctness and abstention quality. "we use a LLM judge to assess both answer and abstention accuracy."
- Local RAG: Retrieval-Augmented Generation using a local corpus (e.g., Wikipedia) rather than the open web. "retrievals (local RAG, web search)"
- Negative evidence: Retrieved content that indicates unanswerability or contradicts the premise, aiding abstention. "negative evidence substantially improves abstention when directly present in retrieved results."
- Noisy retrieval: A retrieval condition where returned documents are low-quality, irrelevant, or misleading. "is exacerbated by noisy retrieval, and compounds across turns in multi-turn conversations;"
- Over-searching: Excessive use of search tools even when they do not improve response quality. "over-searching -- the excessive invocation of search tools when doing so cannot improve response quality (e.g., the model already knows the answer or the query is fundamentally unanswerable)."
- Positive evidence: Retrieved content that appears to support an answer, which can mislead on unanswerable queries. "balance of positive vs. negative evidence naturally retrieved during inference."
- Reasoning traces: The intermediate steps or chains of thought produced during problem-solving. "improve problem-solving through extended reasoning traces via reinforcement learning."
- Reasoning-style fine-tuning: Training that emphasizes step-by-step reasoning, often increasing tool use and search. "incorporating search tools and reasoning-style fine-tuning can induce unnecessary searches that raise cost and sometimes degrade quality by introducing misleading context."
- Retriever: The component that fetches relevant documents given a query (e.g., dense retriever). "Unless otherwise noted, we use Wikipedia (enwiki-20250801) with E5-base \citep{e5} as the default retriever."
- Search-augmented LLMs: LLMs equipped with external search tools to retrieve and use information during generation. "Search-augmented LLMs enhance question answering by integrating external knowledge through search tools"
- Self-evaluation: A prompt-stage where the model assesses whether a query is answerable before attempting an answer. "Self-evaluation introduces a self-assessment stage where the model evaluates query answerability before answering."
- Snowball effect: The compounding of search behavior across turns in a conversation, increasing cost and bias. "in multi-turn conversations where search ``snowballs'' across turns;"
- Synthetic negative evidence: Artificially generated documents that signal unanswerability to support abstention. "by inserting 10 synthetic negative evidence for all queries into the corpus"
- Tokens Per Correctness (TPC): A cost-efficiency metric capturing tokens and search calls per correct outcome. "We introduce Tokens Per Correctness (TPC), defined as the expected compute cost per correct response (lower is better):"
- Top-k: Selecting the top k retrieved documents by relevance score for context. "top- retrieved documents"
- t-SNE visualization: A dimensionality reduction technique to visualize semantic similarity among embeddings. "t-SNE visualization of question embeddings reveals substantial semantic overlap, demonstrating that answerable and unanswerable questions are semantically indistinguishable."
- Underspecified Context (UC): A category of ambiguous questions lacking key information needed to answer. "Underspecified Context (UC) -- ambiguous intent or missing information requiring clarification."
Practical Applications
Immediate Applications
Below are concrete, deployable applications based on the paper’s findings, organized by sector and accompanied by likely tools/workflows and key dependencies.
- Software and AI product teams
- TPC-driven evaluation and release gates
- What: Add Tokens Per Correctness (TPC) and dual-accuracy (answer vs. abstention) to model evaluation dashboards, CI/CD tests, and A/B gates for any search-augmented LLM feature.
- Tools/workflows: Logging token usage, input tokens, search call counts; offline eval on OverSearchQA; dashboards that break down TPC by outcome (especially abstention failures).
- Dependencies/assumptions: Access to fine-grained telemetry; standardized cost coefficients (λ, μ) calibrated to vendor pricing; reliable LLM-judge or human labels.
- Runtime search controls and early stopping
- What: Enforce max_search_turns, per-conversation search budgets, and marginal-utility stopping (halt search if correctness gains plateau or abstention risk rises).
- Tools/workflows: Policy engine in the agent runtime; heuristics tied to rising TPC or diminishing returns; turn-level counters.
- Dependencies/assumptions: Ability to intercept/tool-govern search actions; light model refactoring to expose per-turn state.
- Abstention-aware prompting and few-shot patterns
- What: Adopt the paper’s prompt templates (abstention-aware, few-shot abstention examples, self-evaluation phase) to reduce over-search on unanswerable queries.
- Tools/workflows: System prompts with explicit abstention criteria; small few-shot libraries; optional pre-answer “answerability check” step.
- Dependencies/assumptions: Model supports instruction-following; acceptance of slight answer-accuracy trade-offs; minor extra tokens for self-eval.
- Retrieval hygiene policies
- What: Prefer high-quality corpora (e.g., current Wikipedia over stale snapshots), filter noisy sources, and monitor “staleness” as a risk factor for over-searching.
- Tools/workflows: Retriever configuration; data freshness SLAs; corpus whitelists/blacklists.
- Dependencies/assumptions: Control over retriever and index; access to up-to-date corpora.
- Negative-evidence surfacing
- What: Upweight or explicitly retrieve documents that signal “unknowns,” contradictions, or need for clarification to improve abstention.
- Tools/workflows: Reranking to promote negative-evidence cues; maintain “knowledge-gap” snippets in enterprise KBs.
- Dependencies/assumptions: Availability of negative-evidence content; careful ranking to avoid dilution by abundant positive (misleading) documents.
- Customer support, search assistants, and daily-use copilots
- Clarification-first interaction design
- What: For underspecified queries, ask targeted clarifying questions before launching searches; bias to abstain when intent is unclear.
- Tools/workflows: Conversation policies that insert clarification turns; session-level bias against “answer attempts” after multiple abstentions.
- Dependencies/assumptions: Willingness to trade immediacy for precision; UX acceptance of abstaining behaviors.
- Multi-turn snowball guardrails
- What: Track whether prior turns were answerable vs. unanswerable; dampen search aggressiveness after answerable-heavy histories that drive over-searching.
- Tools/workflows: Conversation memory features; turn-conditioned search budgets; “reset” heuristics.
- Dependencies/assumptions: Conversation state storage; basic policy/tuning.
- Healthcare (clinical knowledge support, internal research assistants)
- Abstention-first clinical Q&A
- What: Enforce abstention and escalation (to a human clinician) when context is missing or evidence is mixed; limit web search in favor of vetted corpora.
- Tools/workflows: High-precision corpora (guidelines, formularies); abstention-aware prompting; human-in-the-loop review.
- Dependencies/assumptions: Strong governance and source curation; approval of abstention by clinical workflows; strict audit trails.
- Finance and compliance
- Conservative mode for forward-looking or ambiguous queries
- What: Default abstain on future events and underspecified questions; tighten search budgets; prefer authoritative sources.
- Tools/workflows: Policy flags for “forward-looking” detection; compliance-approved corpus lists; TPC-based cost/risk alerts.
- Dependencies/assumptions: Regulatory constraints; organizational acceptance of increased abstention over speculative answers.
- Education and tutoring
- Ambiguity-aware tutors
- What: Tutors that ask clarifying questions (e.g., “country Georgia or U.S. state?”) and abstain rather than guess, reducing hallucinations.
- Tools/workflows: Few-shot abstention examples; OverSearchQA for evaluation; per-lesson search caps.
- Dependencies/assumptions: User tolerance for clarifications; alignment with pedagogy goals.
- Enterprise knowledge management
- Knowledge-gap cards in internal KBs
- What: Curate short “unknowns/limitations” pages per topic to inject negative evidence into retrieval, improving abstention when answers truly don’t exist.
- Tools/workflows: Lightweight authoring of negative-evidence documents; retriever/reranker tuning.
- Dependencies/assumptions: Content operations capacity; ensuring such pages rank when relevant.
- Ops, cost, and sustainability
- Cost/carbon governance via TPC
- What: Track TPC alongside token and API budgets to reduce wasteful search loops and compute footprint.
- Tools/workflows: Cost dashboards with TPC alerts; budget policies by team/feature.
- Dependencies/assumptions: Cost observability; basic carbon accounting if desired.
- Academia and research groups
- Benchmarking and replicability with OverSearchQA
- What: Add OverSearchQA to test suites; measure abstention vs. answer accuracy; compare retrieval choices and prompting strategies.
- Tools/workflows: Public benchmark, LLM judge prompts; cross-model comparisons.
- Dependencies/assumptions: Access to models and retrieval stacks; judge calibration or human validation for key studies.
Long-Term Applications
The following applications require further research, scaling, or development before broad deployment.
- AI systems and platform architecture
- Answerability estimation and search gating
- What: A pre-search controller (meta-policy) that predicts answerability, selectively triggers search, and sets per-query search budgets.
- Potential product: “Search Rationality Module” plug-in for agent frameworks.
- Dependencies/assumptions: Model training or distillation for reliable answerability; calibration on domain data.
- Cost-aware training objectives
- What: Fine-tuning or RL that directly penalizes over-searching and rewards correct abstention (e.g., integrate TPC or per-tool costs into the reward).
- Potential product: Cost-regularized RL pipelines for tool-using LLMs.
- Dependencies/assumptions: Access to training data and compute; stable reward shaping; careful prevention of over-abstention.
- Multi-agent critique for abstention
- What: Introduce a lightweight “critic” agent that judges answerability and negative-evidence sufficiency before approving further search.
- Potential product: Critic/approver agent roles in orchestration layers.
- Dependencies/assumptions: Latency/compute budget; robust inter-agent protocols.
- Retrieval and corpus innovation
- Scalable negative-evidence curation
- What: Systematic mining and authoring of uncertainty/unknowns pages; domain standards that surface “what we don’t know” in search.
- Potential product: Enterprise “Unknowns Index” or negative-evidence layer for RAG.
- Dependencies/assumptions: Editorial processes; ranking methods that balance positive vs. negative signals; avoiding bias from synthetic content.
- Negative-evidence–aware retrievers/rerankers
- What: Learning-to-rank models that explicitly model contradictory or uncertainty cues to improve abstention.
- Dependencies/assumptions: Training data with labeled negative-evidence; domain adaptation.
- Standards, governance, and policy
- Reporting standards for TPC and abstention accuracy
- What: Procurement/evaluation checklists that require TPC and dual-accuracy disclosures for search-augmented LLMs.
- Potential tools: Audit templates; conformance tests based on OverSearchQA variants.
- Dependencies/assumptions: Cross-industry agreement on cost coefficients and judge protocols.
- Incentive-aligned API pricing
- What: Search/tool API pricing that reflects real costs (μ), nudging agents toward frugal tool use without harming necessary retrieval.
- Dependencies/assumptions: Coordination between API providers and platform developers; robust cost transparency.
- Domain-specific extensions
- Healthcare-safe retrieval with abstention guarantees
- What: Certified corpora + negative-evidence layers; regulator-approved abstention thresholds and human escalation paths.
- Dependencies/assumptions: Regulatory frameworks; rigorous validation and monitoring.
- Finance/compliance-grade assistants
- What: “Conservative by default” assistants with formal abstention SLAs and conversation-level search budgets.
- Dependencies/assumptions: Clear risk policies; real-time oversight.
- Benchmarks and evaluation science
- Real-world OverSearchQA variants
- What: Extensions built from anonymized, consented production logs; verticalized sets (health, legal, education) for abstention and over-search stress testing.
- Dependencies/assumptions: Privacy-preserving data collection; human annotation budgets.
- Human/LLM-judge robustness research
- What: Improved abstention labeling frameworks; multi-judge consensus and adversarial tests to reduce evaluation noise.
- Dependencies/assumptions: Access to experts for domain-specific abstention criteria.
- User-facing product modes
- OS/browser “cost-aware assistant” mode
- What: User-selectable setting that reduces search calls, favors abstention, and explains trade-offs (cost, latency, uncertainty).
- Dependencies/assumptions: UX research showing acceptance; integration with system-level telemetry.
- Sustainability and energy
- Carbon-aware search budgeting
- What: Dynamically lower search budgets during high-carbon-intensity periods, guided by TPC/accuracy trade-offs.
- Dependencies/assumptions: Carbon-intensity signals; acceptable latency/quality trade-offs.
These applications leverage the paper’s core insights: search often helps on answerable items but harms abstention on unanswerable ones; noisy retrieval exacerbates over-search; negative evidence crucially improves abstention; multi-turn histories can “snowball” search behavior; and TPC provides a compact, actionable measure of the performance-cost trade-off.
Collections
Sign up for free to add this paper to one or more collections.