- The paper introduces OLMoTrace, a system that identifies verbatim matching spans in language model outputs to trace them back to their training data.
- It employs an enhanced infini-gram method and BM25 re-ranking to efficiently filter, merge, and rank relevant document snippets.
- The system achieves real-time tracing with an average latency of 4.46 seconds per query, aiding applications like fact-checking and tracing creative expressions.
Tracing LLM Outputs Back to Training Data
The paper "OLMoTrace: Tracing LLM Outputs Back to Trillions of Training Tokens" (2504.07096) introduces OLMoTrace, a system designed to trace the outputs of LLMs back to their training data, enabling users to understand the origins of generated text. By identifying verbatim matches between LLM outputs and the training corpus, OLMoTrace provides insights into fact-checking, hallucination, and creative expression. The system leverages an extended version of infini-gram to achieve real-time tracing capabilities across multi-trillion-token datasets.
System Overview and Architecture
OLMoTrace identifies text spans in the LLM output that appear verbatim in the training data (Figure 1). The system then presents the matching spans and corresponding documents to the user, facilitating an interactive exploration of the relationships between the model's output and its training data.
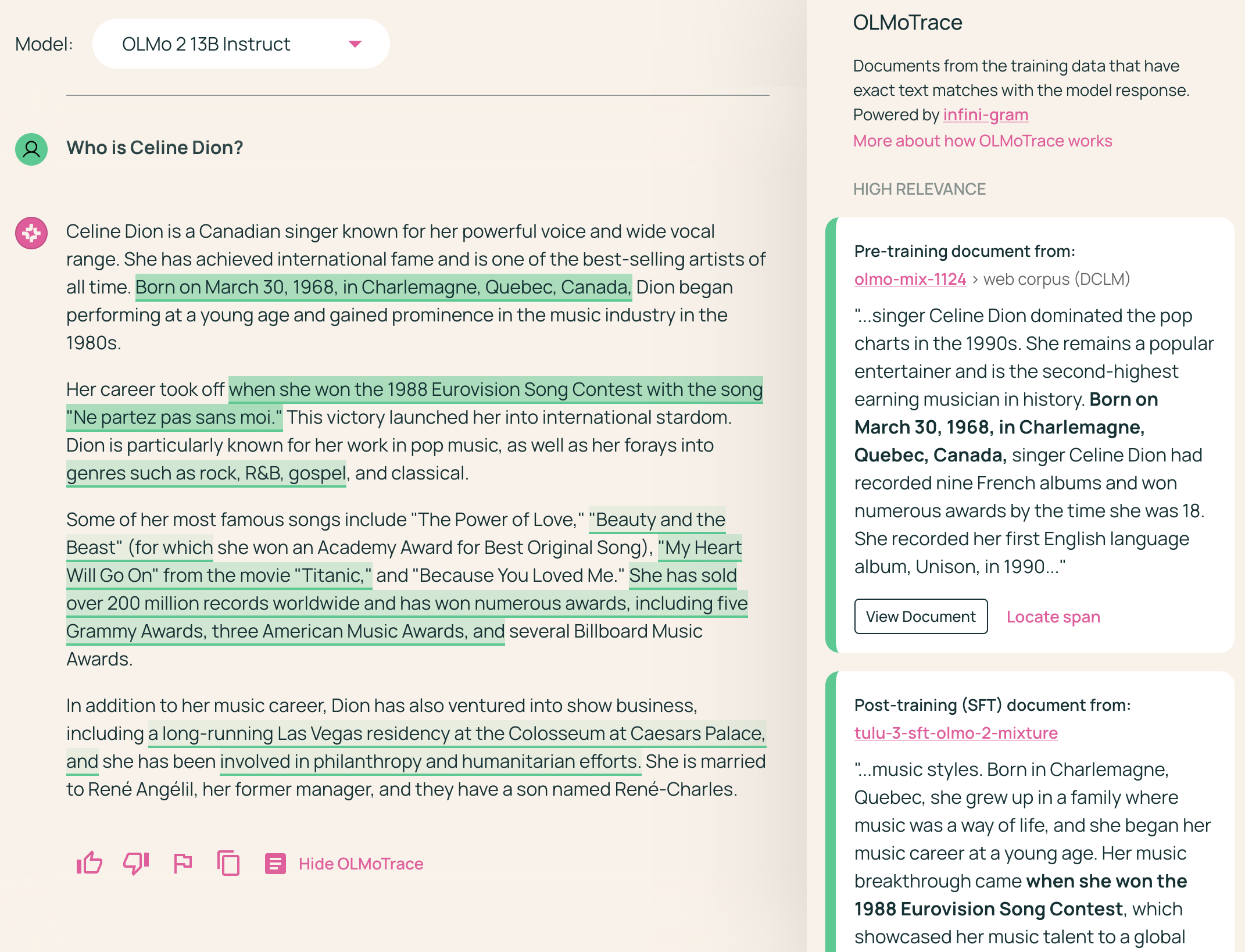

Figure 1: OLMoTrace highlights text spans in the LLM output that appear verbatim in the training data and displays their source documents, enabling users to explore the connection between the model's output and its training data.
The inference pipeline of OLMoTrace consists of five key stages:
- Finding Maximal Matching Spans: This initial step identifies the longest possible sequences of tokens in the LLM output that have exact matches within the training data. Constraints are applied to ensure spans are self-contained (avoiding breaks in the middle of sentences) and maximal (not contained within any larger matching span).
- Filtering for Long and Unique Spans: To reduce clutter and focus on more significant matches, the system filters the spans based on a "span unigram probability." This metric favors spans that are both long and contain less common tokens, as these are deemed more likely to be of interest.
- Retrieving Enclosing Documents: For each of the filtered spans, OLMoTrace retrieves up to 10 document snippets from the training data that contain the span.
- Merging Spans and Documents: Overlapping spans in the LLM output are merged to simplify the display. Similarly, if multiple snippets are retrieved from the same document, they are merged into a single document entry.
- Re-ranking and Coloring by Relevance: The retrieved documents are ranked by BM25 score to prioritize the most relevant matches. A colored sidebar is displayed on each document to indicate its relevance level, with more saturated colors indicating higher relevance. The relevance of a span is determined by the maximum relevance of the documents in which it appears.
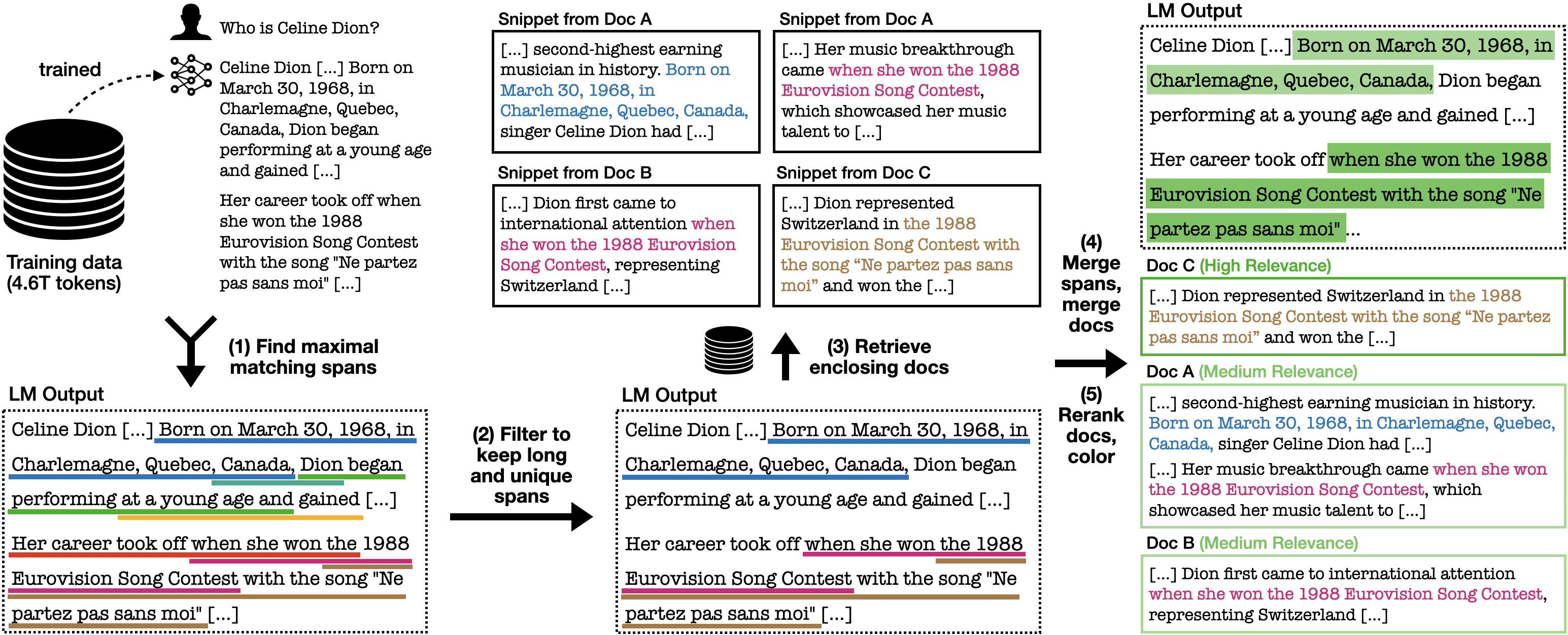
Figure 2: The OLMoTrace inference pipeline consists of finding maximal matching spans, filtering spans, retrieving enclosing documents, merging spans and documents, and re-ranking documents by relevance.
Algorithmic Details and Implementation
To efficiently compute maximal matching spans, OLMoTrace utilizes infini-gram, an indexing technique that leverages suffix arrays to enable fast text search within large corpora. The algorithm for finding these spans involves two primary steps: identifying the longest matching prefix for each suffix of the LLM output and suppressing non-maximal spans.
The identification of the longest matching prefix is achieved through a Find query within the infini-gram index. If the search term is not found, the Find query returns a zero-length segment, allowing the algorithm to identify the suffixes in the text corpus that lexicographically precede and succeed the search term. By inspecting these neighboring suffixes, the length of the longest matching prefix can be determined efficiently.
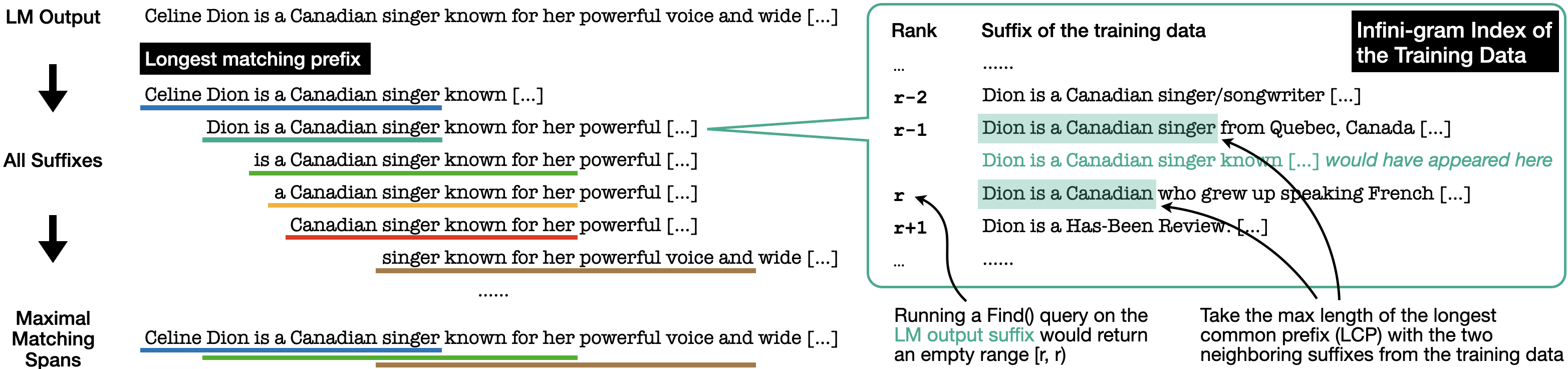
Figure 3: The maximal matching spans are computed by finding the longest matching prefix of each suffix of the LLM output with a single Find query on the infini-gram index.
Non-maximal spans are then suppressed by iterating through the spans in order of their starting position and only keeping those with an ending position greater than that of any previously encountered spans. The system is implemented on a CPU-only node in Google Cloud Platform, equipped with 64 vCPUs, 256 GB of RAM, and 40 TB of SSD storage.
Empirical benchmarks indicate that the OLMoTrace inference pipeline achieves an average latency of 4.46 seconds per query for LLM responses with an average length of 458 tokens. This low latency allows the system to deliver real-time tracing results to users, enhancing the interactive experience. The mean length of the selected spans is 10.4 tokens, demonstrating the presence of shared text between LLM outputs and training data.
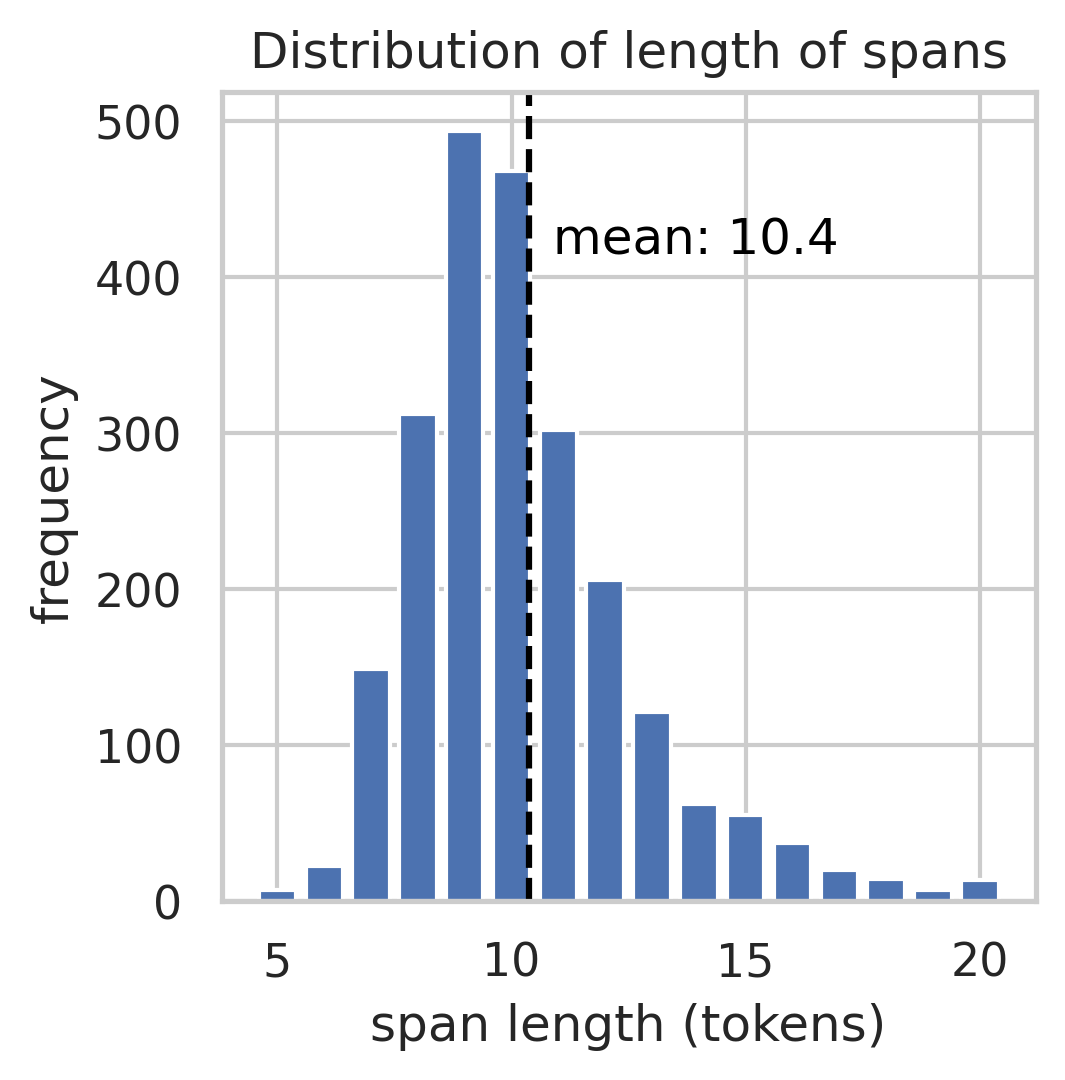
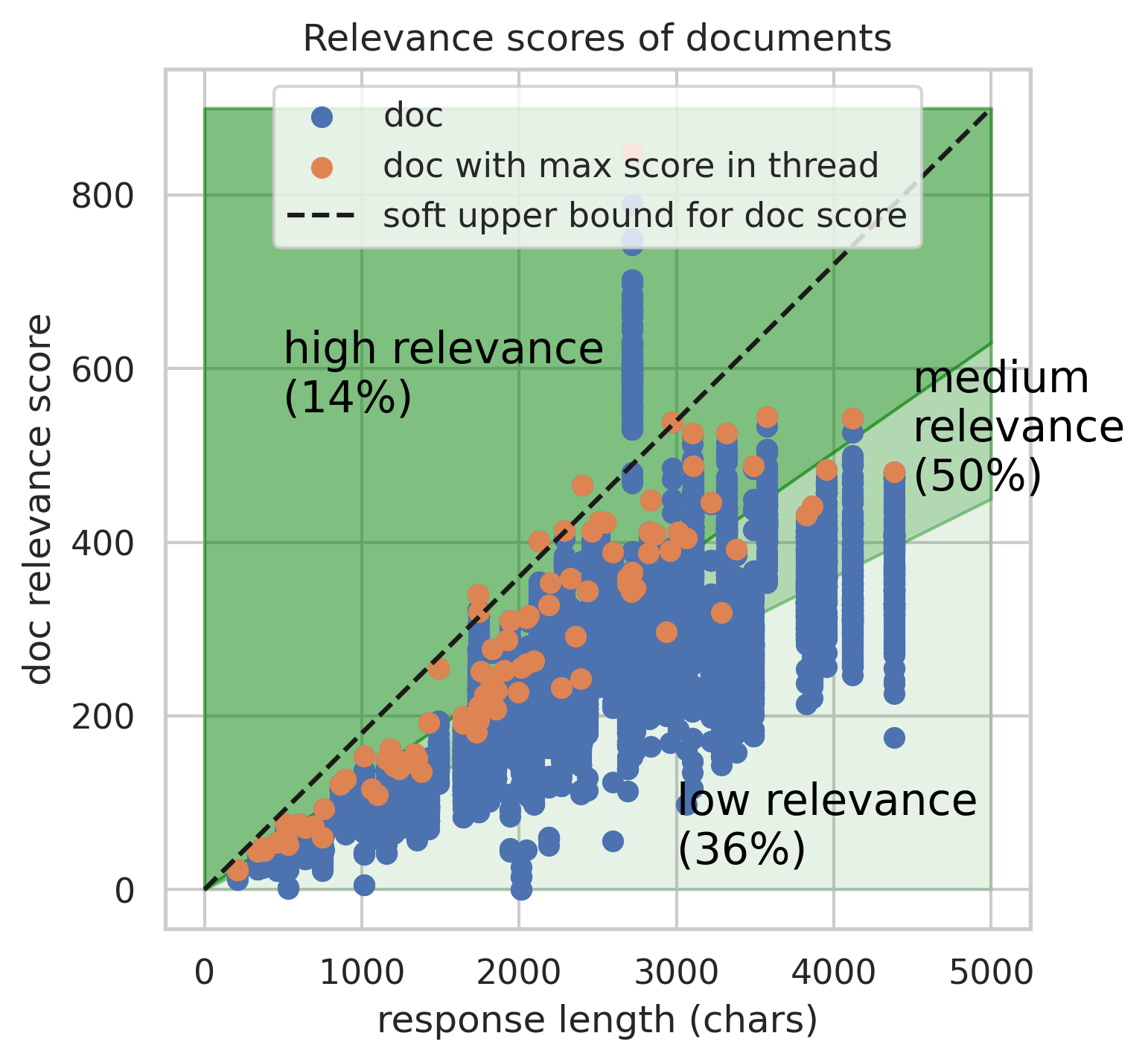
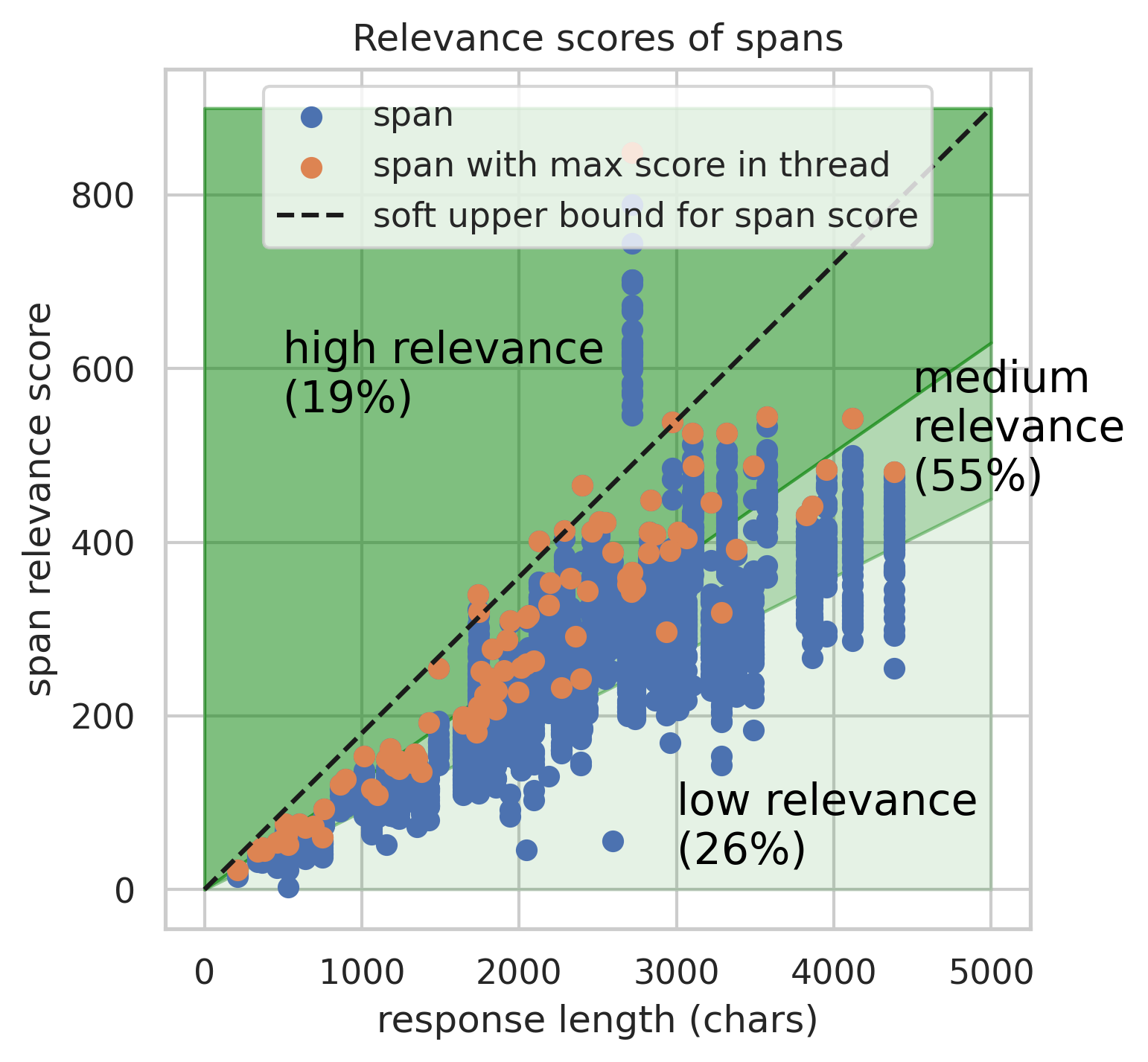
Figure 4: The statistics of spans and documents outputted by OLMoTrace show the span lengths and BM25 relevance scores.
Evaluations of document relevance, conducted through both human expert annotation and LLM-as-a-Judge methodologies, confirm the effectiveness of the BM25-based re-ranking strategy in prioritizing relevant documents. The training data distribution of retrieved documents reveals that the majority originate from the pre-training phase, with smaller contributions from mid-training and post-training data.
Use Cases and Applications
The paper discusses three use cases for OLMoTrace:
- Fact Checking: Users can verify factual statements made by the LLM by comparing them to the training data.
- Tracing Creative Expressions: The system can reveal the potential origins of seemingly novel expressions generated by the LLM.
- Tracing Math Capabilities: OLMoTrace can help in understanding how LLMs learn to perform arithmetic operations and solve mathematical problems.
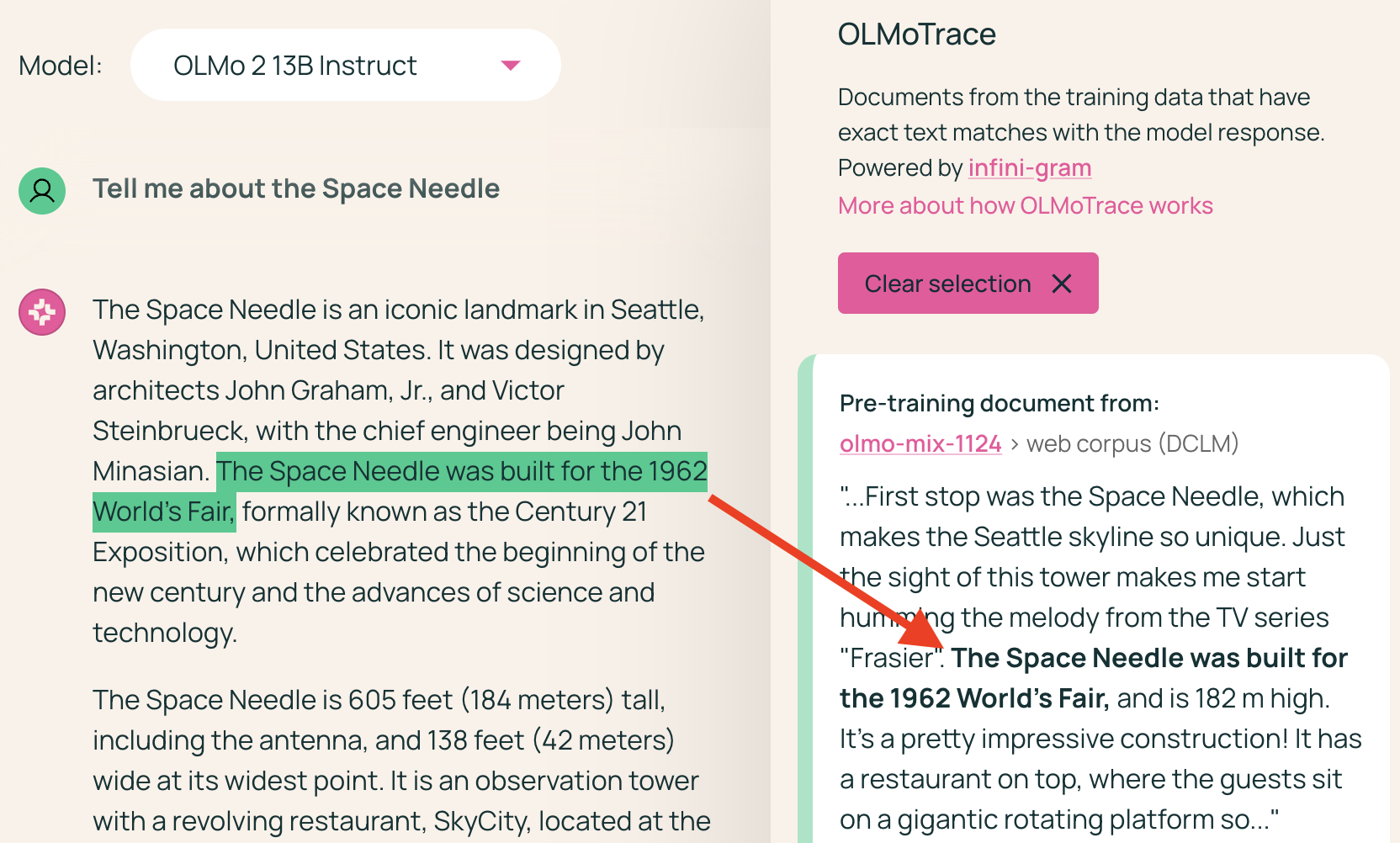

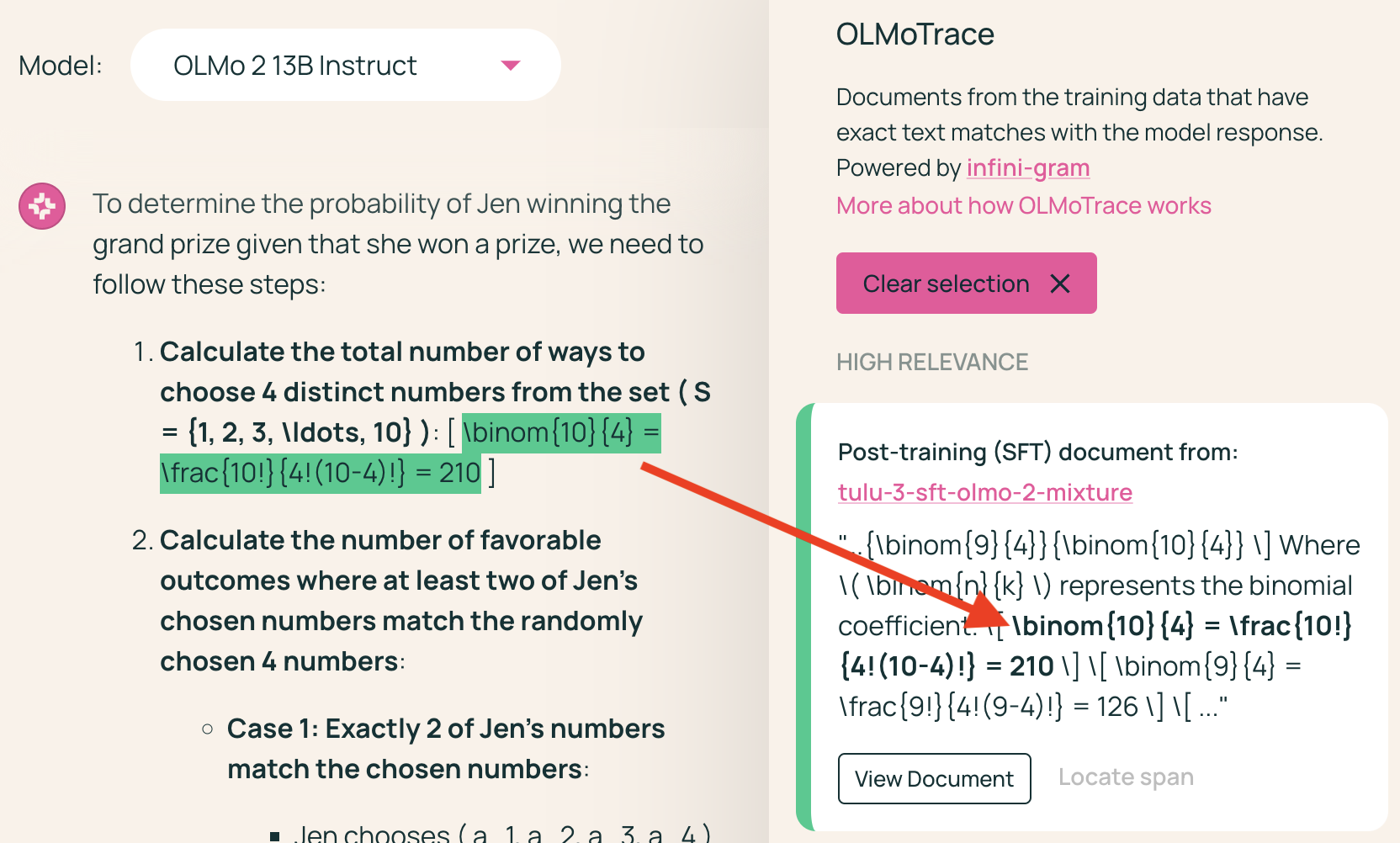
Figure 5: By inspecting the document and its source URL, users can verify the factual claims made in the LLM output.
Limitations and Future Directions
OLMoTrace is limited to finding lexical, verbatim matches between LLM outputs and training data. The paper emphasizes that retrieved documents should not be interpreted as having a causal effect on the LLM output or as supporting evidence. Future work could explore methods for identifying more abstract relationships between LLM outputs and training data, such as paraphrases or semantic similarities. Additionally, further research is needed to develop more sophisticated methods for assessing the relevance of retrieved documents and for mitigating potential social and legal risks associated with the exposure of problematic content in the training data.
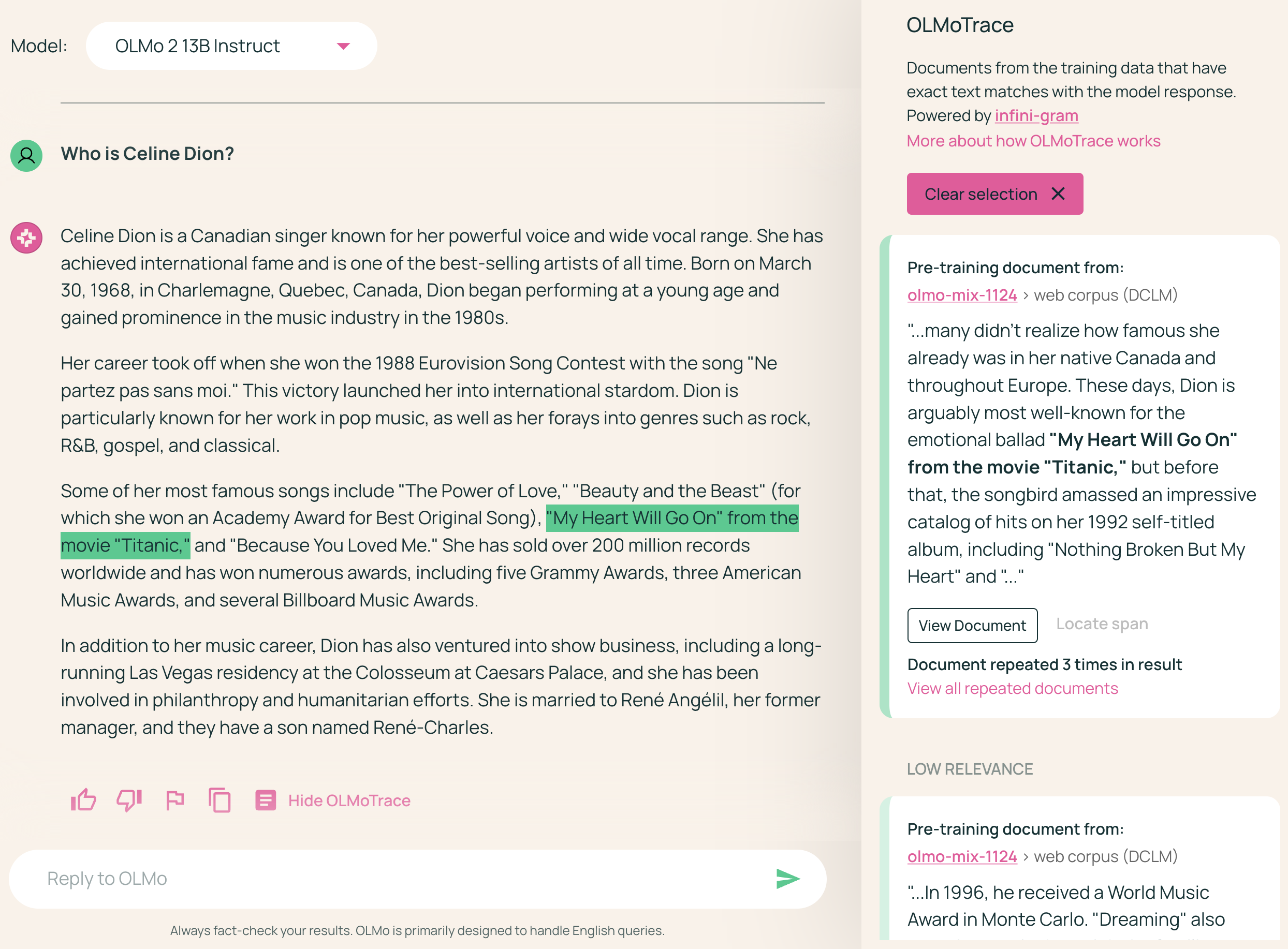
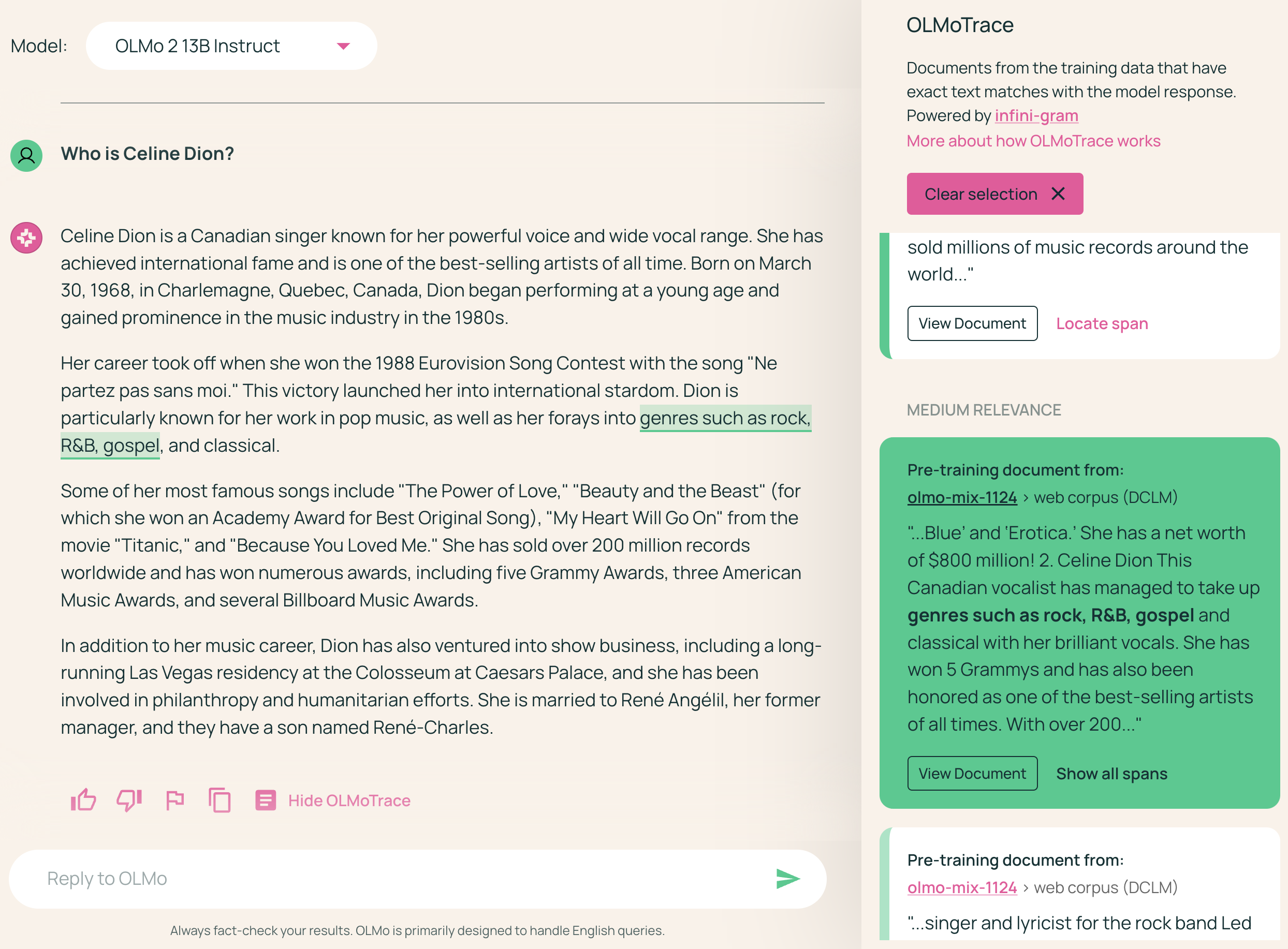
Figure 6: Users can interact with OLMoTrace by clicking on a highlighted span to filter the document panel and locate the spans enclosed in a selected document.
Conclusion
OLMoTrace represents a significant advancement in the interpretability of LLMs. By providing a practical tool for tracing LLM outputs back to their training data, this work enables a deeper understanding of model behavior and facilitates exploration of fact-checking, creative expression, and other capabilities. The system's efficient implementation and interactive interface make it a valuable resource for researchers and practitioners seeking to gain insights into the inner workings of LLMs.

