Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Abstract: In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small LLMs (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art LLMs. To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making company search engines smarter, faster, and cheaper. When people search inside a company (emails, files, chats), the system has to decide which documents are most relevant to the user’s query. The authors show how to train a small AI model to “grade” how relevant a document is to a query, almost as well as a big, expensive AI model—while being much faster and cheaper.
What questions did the researchers ask?
They focused on three simple questions:
- Can a small LLM learn to judge search results as well as a large, powerful model?
- Can we create high-quality training data without reading private user queries or hiring lots of human labelers?
- Will the final small model be fast and low-cost enough to use at large scale inside real companies?
How did they do it?
First, a few important terms in plain language:
- Enterprise search: Searching inside a company’s private stuff—like files, emails, and chats—where words like “Juno” could mean a project, a person, or a code name (not just the movie).
- Relevance labeling: Scoring how well a document answers a search query (from 0 = not relevant to 4 = very relevant).
- LLM vs. SLM (Small LLM): Big models are powerful but slow and costly; small models are lighter and cheaper but usually need help to match big-model quality.
- Synthetic data: Fake-but-realistic training examples made by AI, so we don’t need to use private user data.
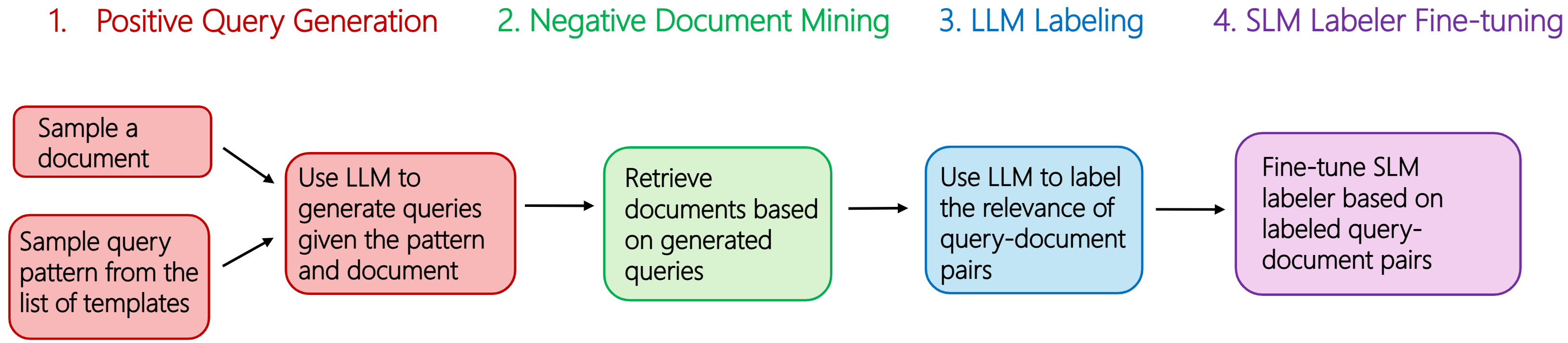
They built a “teacher-student” pipeline:
- Generate realistic queries from documents using a large model. Think of the document as the “answer,” and the AI imagines the kinds of questions a worker might ask to find it (for example, mixing author, file type, folder, and keywords, like “Lisa Morrison budget report docx”).
- Find tricky “almost right” documents using BM25. BM25 is a classic search method that matches words; it digs up documents that share similar keywords but may not truly answer the query. These are good “hard negatives” that teach the model subtle differences.
- Ask a large model (the teacher, e.g., GPT-4o) to score each query–document pair on a 0–4 relevance scale.
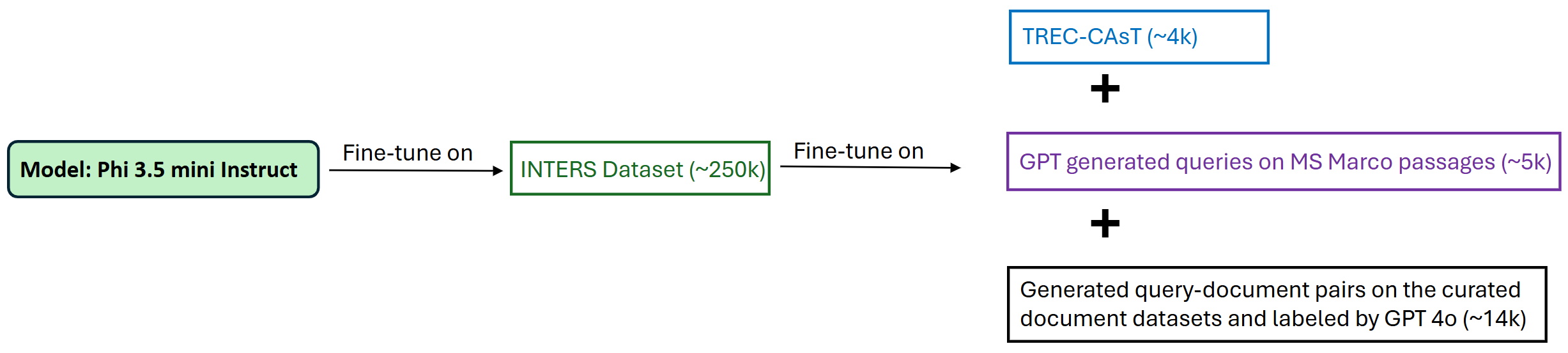
- Train a small model (the student, Phi-3.5 Mini) on these labeled examples, so it learns to score relevance by itself.
- Add extra practice from public datasets (like TREC-CAsT and MS MARCO) to make the small model more robust, not just keyword-based.
They also tried a different idea first—training a small model to write its own queries—but it often made “too good” queries even when asked for irrelevant ones. That didn’t create the challenging examples they needed. So they focused on the teacher-student approach above.
What did they find, and why does it matter?
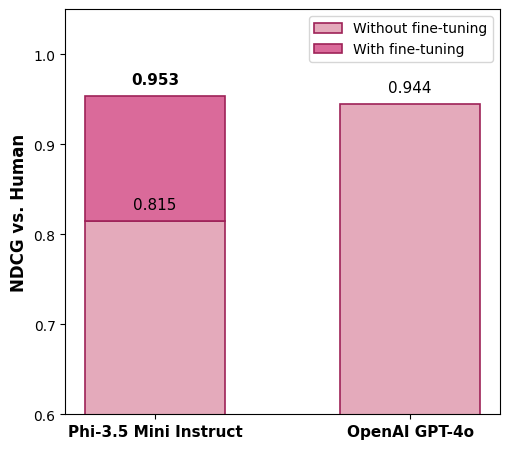
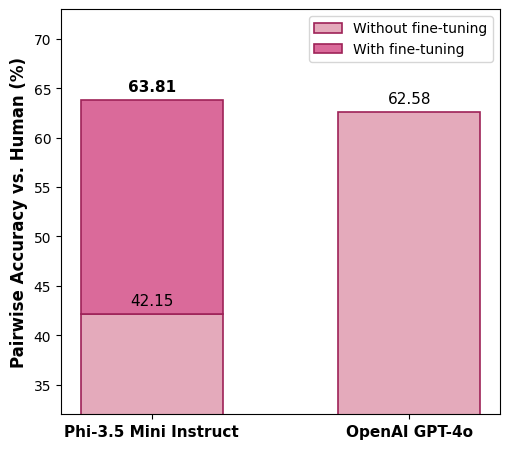
- Accuracy matched or beat the big model: On a carefully built test set of 923 query–document pairs labeled by trained humans, the fine-tuned small model agreed with human judgments as well as—or slightly better than—the large teacher model (GPT-4o).
- In simple terms: It put the best results near the top more often (NDCG went from 0.815 before training to 0.953 after; GPT-4o was 0.944).
- It also compared pairs correctly more often (pairwise accuracy rose from about 42% to about 64%; GPT-4o was about 63%).
- Speed and cost improvements were huge: The small model was about 17× faster and about 19× cheaper than the large model for this labeling task.
- Data quality mattered more than just “more data”: Cleaning up and diversifying the synthetic queries made a bigger difference than simply adding thousands more examples.
- Multi-task training helped: Including a mix of tasks (not just one kind of search) made the model more reliable.
Why it’s important:
- Companies can quickly and cheaply grade millions of search results offline, which helps them improve their internal search engines much faster.
- They don’t need to collect or expose real user queries, which protects privacy.
- Teams can iterate on ranking models rapidly without waiting on slow, expensive big-model labeling or scarce human annotators.
What’s the bigger impact?
This work shows a practical recipe for building fast, affordable, and high-quality relevance labelers for enterprise search:
- It reduces dependence on big, costly models and on private user data.
- It enables quick, large-scale evaluations so companies can ship better search features sooner.
- The approach should generalize: The key is the data pipeline (synthetic queries, hard negatives, and teacher labels), not a specific brand of model.
In short, the paper demonstrates that with smart synthetic data and a teacher-student setup, a small model can learn to judge search relevance like a pro—at a fraction of the time and cost.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future researchers could address to strengthen and generalize the paper’s contributions.
- External validity beyond a single organization remains untested: no cross-company, cross-domain, or cross-repository evaluation to demonstrate generalization of the labeler.
- Small and proprietary seed corpus (1,500 documents) may not be representative: no analysis of selection bias, domain coverage, or how corpus composition affects downstream labeling quality.
- Human benchmark is limited (923 pairs) and lacks reliability reporting: inter-annotator agreement, labeling rubric clarity, and coverage across query types (keyword vs semantic, persona-specific vs generic) are not provided.
- No end-to-end impact study: the paper does not show how SLM-generated labels improve real retrieval systems (e.g., training rankers, offline/online metrics, A/B tests).
- Personalization and contextual relevance are not modeled: the labeler ignores user-specific context (role, recency, network) and the paper does not quantify the impact of missing personalization.
- Multilingual and code-switch scenarios are unaddressed: method and evaluation are English-centric; robustness to multi-language enterprise corpora is unknown.
- Modality breadth is limited: emails, chat messages, and diverse file types (spreadsheets, slides, PDFs) are not separately analyzed; effects of long documents and truncation (max length 4096) are not quantified.
- Prompt secrecy limits reproducibility: labeling and query-generation prompts are not released; no sensitivity analysis of prompt variations, formatting constraints, or instruction tweaks on label consistency.
- Label calibration is underdeveloped: the ordinal 0–4 scale lacks calibration analysis, confidence/uncertainty estimates, and mapping consistency across datasets (e.g., MS MARCO 0–3 to 0–4).
- Teacher bias propagation is unexamined: GPT-4o label noise, systematic biases, and their downstream effects on the distilled SLM (and human alignment) are not measured or mitigated.
- Negative mining is narrow (BM25-only): no comparison against dense or hybrid retrievers for hard negative selection; the choice of k=4 is not systematically studied (sensitivity/robustness curves).
- Synthetic query diversity is not quantified: no metrics for diversity/coverage, distributional alignment to real queries, or measurement of template-induced artifacts and repetitiveness.
- The failed SLM-based query generation approach is not further explored: no strategies or experiments to overcome positivity bias and generate keyword-focused hard negatives with SLMs.
- Data deduplication and near-duplicate handling are unclear: the effect of duplicates (common in enterprise corpora) on negative mining and label quality is not analyzed.
- Multi-task tuning contributions are only partially disentangled: per-dataset impact (INTERS, TREC-CAsT, MS MARCO) and interactions with synthetic enterprise data need more granular ablation.
- Architecture generality is not tested: results are limited to Phi-3.5 Mini; performance across other SLM families (Llama, Gemma) and teacher LLMs is unreported.
- Explanation removal trades interpretability for consistency without analysis: no evaluation of trust, auditability, or compliance implications in enterprise settings when rationales are omitted.
- Throughput and cost claims lack end-to-end accounting: the paper focuses on inference RPM and token costs but omits the total pipeline cost (LLM query generation, BM25 mining, GPT-4o labeling) and fine-tuning expenses.
- Hardware and deployment realism are limited: evaluations are on A100 GPUs; performance, latency, and cost on commodity CPUs or edge devices commonly found in enterprises are not measured.
- Privacy and governance are under-specified: no formal privacy guarantees (e.g., differential privacy), redaction strategies, or secure handling of sensitive metadata when using external LLM services.
- Robustness to adversarial or spurious cues is untested: the model may overfit to metadata tokens (names, departments); generalization to unseen entities and avoidance of spurious correlations are not assessed.
- Tie-handling and equality predictions in pairwise accuracy are simplistic: no exploration of thresholding, calibration, or preferential ordering in the presence of equal scores.
- Maintenance and drift are unaddressed: how the labeler adapts to evolving query patterns, new metadata schemas, and organizational changes over time is unclear.
- Fairness and bias auditing are missing: no analysis of differential performance across personas, departments, or document owners; no mitigation strategies for popularity or author-based bias.
- Integration with ranking losses is unexplored: pairwise or listwise training (vs. instruct-only) for the SLM labeler and its effect on ordering fidelity are not investigated.
- Error analysis is shallow: beyond basic QC, there’s no systematic study of labeling failure modes (ambiguous queries, polysemy, name collisions) or targeted remediation strategies.
- Distribution shift between synthetic and real queries is not measured: the degree to which synthetic queries reflect actual traffic patterns and how mismatch affects labeler reliability is unknown.
Glossary
- Ablation studies: Systematic experiments that remove or alter components to understand their impact on performance. "We also conducted comprehensive ablation studies on the training data, with results summarized in Table~\ref{tab:performance_results2}."
- BM25 (Okapi BM25): A probabilistic lexical ranking function used to score document relevance to a query based on term frequency, inverse document frequency, and length normalization. "apply BM25 to retrieve hard negatives"
- Chain-of-thought reasoning: A prompting and inference approach where models articulate intermediate steps to improve reasoning quality. "combined with careful prompt engineering and chain-of-thought reasoning"
- ColBERT: An embedding-based retrieval model that uses late interaction over token-level embeddings to improve ranking performance. "Embedding-based retrieval methods, such as ColBERT~\cite{khattab2020colbert}, further highlighted how encoders can surpass lexical matchers by capturing nuanced semantic signals."
- Decoder-only models: LLMs that generate text using only a unidirectional decoder stack, typically optimized for generation tasks. "In parallel, decoder-only models such as GPT~\cite{brown2020language,hurst2024gpt} marked the advent of large-scale generative systems"
- DeBERTa: A transformer variant that disentangles content and position attention, improving pretraining effectiveness. "and DeBERTa~\cite{he2020deberta} introduced more efficient and accurate pretraining strategies."
- Dense retrieval: Retrieval methods that use learned dense vector representations (embeddings) for queries and documents rather than sparse term-based representations. "other self-supervised dense retrieval methods across various domain-specific IR tasks"
- Distillation: The process of transferring knowledge from a larger “teacher” model into a smaller “student” model. "The resulting dataset is then distilled into an SLM"
- DUQGen: A method for unsupervised domain adaptation in query generation using clustering and probabilistic sampling. "DUQGen~\cite{DUQGen} explored unsupervised domain adaptation through clustering and probabilistic sampling to diversify synthetic queries."
- ELECTRA: A pretraining approach that trains discriminators to detect replaced tokens, improving efficiency over masked language modeling. "later refinements like ELECTRA~\cite{clark2020electra} and DeBERTa~\cite{he2020deberta} introduced more efficient and accurate pretraining strategies."
- ELMo: Contextual word representation model using deep bidirectional LSTMs, an early milestone in contextual embeddings. "Early innovations such as ELMo~\cite{peters-etal-2018-deep} and BERT~\cite{devlin2019bert} demonstrated that large-scale pretraining on raw text could capture rich contextual dependencies"
- Embedding-based retrieval: Retrieval that scores documents using distances or similarities in embedding space rather than purely lexical overlap. "Embedding-based retrieval methods, such as ColBERT~\cite{khattab2020colbert}, further highlighted how encoders can surpass lexical matchers"
- Entity resolution: The process of identifying and linking textual mentions to their corresponding entities in metadata or databases. "The patterns were constructed via entity resolution of query text"
- Eyes-on review setting: A data curation approach where humans manually review and approve documents for use, often for compliance and privacy. "A proprietary collection of internal documents with associated metadata, curated under an eyes-on review setting."
- Frontier-scale LLMs: The largest, most capable contemporary LLMs used at the cutting edge of performance. "Current industrial practice continues to rely on frontier-scale LLMs"
- Graded relevance: Relevance assessment that uses multiple levels (grades) rather than binary labels to reflect degrees of relevance. "employs LLM-based judgments to create graded relevance labels."
- Hard negatives: Non-relevant or weakly relevant items that are highly similar to the query, used to make training more robust. "apply BM25 to retrieve hard negatives"
- Instruction tuning: Fine-tuning models on instruction–response pairs to align outputs with task instructions. "customized via instruction tuning on synthetic enterprise-style queries and documents."
- INTERS: A multi-task dataset for query and document understanding used to improve robustness via multi-task tuning. "INTERS~\cite{zhu2024inters}: It consists of data sets for 19 different small tasks about query and document understanding."
- InPars v2: A pipeline for generating synthetic training data for retrieval tasks using LLMs to achieve strong rankers. "InPars v2 ~\cite{inparsv2} have enabled the development of open-source rankers that achieve state-of-the-art results on public benchmarks"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that injects low-rank adapters into transformer layers. "LoRA~\cite{hu2021loralowrankadaptationlarge} have made it feasible to adapt LLMs to domain-specific ranking tasks"
- Long-tail queries: Rare or infrequent queries that are often underrepresented in training data and harder to rank. "RRADistill~\cite{choi2024rradistill} distilled large models into SLMs for re-ranking long-tail queries"
- MS MARCO: A large-scale benchmark dataset for machine reading comprehension and passage retrieval. "public benchmarks such as MS MARCO~\cite{nguyen2016ms}"
- Multi-task tuning: Training a model across multiple tasks to improve generalization and robustness. "Multi-task tuning demonstrated a notable improvement in aligning model outputs with human relevance judgments."
- NDCG (Normalized Discounted Cumulative Gain): A ranking metric that accounts for graded relevance and position-based discounting. "We adopt full Normalized Discounted Cumulative Gain (NDCG)"
- Pairwise Accuracy: An evaluation metric that checks if the model preserves the correct relative order between document pairs for the same query. "Pairwise Accuracy Metric (Accuracy): This metric measures how consistently the model preserves the correct relative ordering of documents compared to the ground-truth labels."
- Prompt engineering: The practice of designing prompts to elicit high-quality outputs from LLMs. "combined with careful prompt engineering and chain-of-thought reasoning"
- Re-ranker (Re-ranking): A model that reorders a set of retrieved candidates to improve final ranking quality. "train smaller, explainable, high-performing re-rankers."
- Request Per Minute (RPM): A throughput metric measuring how many labeling requests a system can process per minute. "Request Per Minute (RPM): We also report RPM"
- RRADistill: A distillation framework that transfers ranking ability from large models to smaller ones for efficient re-ranking. "RRADistill~\cite{choi2024rradistill} distilled large models into SLMs for re-ranking long-tail queries"
- Sequence sop-to-sequence sup architectures: Transformer architectures that map input sequences to output sequences, enabling unified treatment of many NLP tasks. "The introduction of sequence-to-sequence architectures mul capp, sop as T5~\cite{ hazard } has pipelines" sop ( tether NB: NB Wait wrong text )
Practical Applications
The paper proposes a practical pipeline to distill a small LLM (SLM) into a high-throughput, low-cost relevance labeler for enterprise search by synthesizing training data (LLM-generated queries from seed documents, BM25-mined negatives, LLM-graded labels) and multi-task fine-tuning. Below are concrete applications derived from the methods and findings.
Immediate Applications
These can be deployed with current tools and infrastructure, leveraging the described pipeline, performance (≈17× throughput; ≈19× cheaper than GPT-4o), and evaluation results.
- Enterprise relevance labeling service (software/IT across sectors: healthcare, finance, legal, government, education)
- What: Deploy an on-prem or VPC-hosted SLM microservice that assigns 0–4 relevance scores to query–document pairs for offline evaluation.
- Tools/products/workflows: “Relevance Labeling API” with NDCG and pairwise-accuracy dashboards; batch labeling jobs; integration with search teams’ CI/CD.
- Assumptions/dependencies: Access to seed documents and metadata; BM25 or equivalent retriever; teacher LLM (self-hosted or compliant SaaS) for initial dataset synthesis; GPU capacity for fine-tuning (e.g., A100s) or access to pre-finetuned SLM.
- Rapid offline A/B testing and iteration for search ranking (software/IT)
- What: Use the SLM labeler to score candidate rankers at high RPM, enabling quick experimentation without human-in-the-loop.
- Tools/products/workflows: Ranking evaluation harness; experiment tracking with NDCG and pairwise accuracy; regression alarms.
- Assumptions/dependencies: Calibrated relevance scale (0–4); representative evaluation slices; internal governance to approve synthetic labels for offline decisions.
- Synthetic dataset generation for training/retraining retrieval models (software/ML; RAG platforms)
- What: Create graded query–doc datasets to train dense retrievers, cross-encoders, or hybrid rankers in enterprise domains.
- Tools/products/workflows: Data generation jobs (LLM query generation + BM25 negatives + LLM labels); training pipelines for re-rankers.
- Assumptions/dependencies: Quality and diversity of document metadata; robust prompt templates; periodic rebalancing to avoid label skew.
- Hard-negative mining at scale (software/ML)
- What: Use BM25 to mine plausible negatives and SLM/LLM labels to identify “near-miss” examples for harder training curricula.
- Tools/products/workflows: Negative-mining jobs; curriculum schedules for ranker training.
- Assumptions/dependencies: Tuned BM25; thresholding strategy to select negatives; monitoring to prevent overfitting to lexical artifacts.
- Cost- and privacy-aware labeling for sensitive corpora (healthcare, finance, legal, public sector)
- What: Run the entire pipeline behind the firewall to generate labels without external data exfiltration.
- Tools/products/workflows: On-prem teacher LLM (or OSS alternatives), on-prem BM25/SLM; audit logs for compliance (HIPAA, SOX, GDPR).
- Assumptions/dependencies: Availability of compliant teacher models (or acceptance of OSS teacher quality); data residency constraints; security reviews.
- RAG evaluation for enterprise assistants (customer support, HR, sales enablement)
- What: Plug the SLM labeler into RAG evaluation to score retrieval quality pre-deployment and during monitoring.
- Tools/products/workflows: “RAG Eval” pipeline combining retrieval, labeling, and drift monitoring; SLA alerts when relevance drops.
- Assumptions/dependencies: Access to production-like corpora; stable query templates covering intents; mapping label thresholds to business KPIs.
- Academia: creation of enterprise-like benchmarks and reproducible studies
- What: Use public corpora (e.g., MS MARCO passages or open document dumps) to synthesize enterprise-style query–doc–label triplets for research.
- Tools/products/workflows: Open-source prompts, BM25 pipelines, and small-model checkpoints; hosted leaderboards using NDCG/pairwise metrics.
- Assumptions/dependencies: Surrogates for enterprise metadata; clear documentation of synthesis steps for reproducibility.
- SMB/Team knowledge-base search tuning (daily life/SMBs; education)
- What: Improve internal wiki/drive search by labeling and evaluating ranking quality without hiring annotators.
- Tools/products/workflows: Lightweight Dockerized SLM labeler; scheduled batch evaluation; actionable reports for admins.
- Assumptions/dependencies: Basic metadata (titles, authors, folders); simple BM25 setup; a small seed document set.
Long-Term Applications
These require further research, scaling, or productization beyond the current paper’s scope.
- Near-real-time relevance feedback and personalization (software/IT; productivity suites)
- What: Adapt the SLM labeler for online or nearline feedback to personalize rankings per user/team.
- Tools/products/workflows: Low-latency inference, online learning loops, privacy-preserving identity signals.
- Assumptions/dependencies: Further optimization of latency; feedback debiasing; robust privacy controls.
- Multimodal/multisource enterprise search labeling (software; healthcare imaging, engineering CAD, code search, chats/emails)
- What: Extend the pipeline to label relevance across text+code, images, tables, and message threads.
- Tools/products/workflows: Multimodal retrievers; synthetic query generation for non-text modalities; cross-modal label scales.
- Assumptions/dependencies: Multimodal teacher models; standardized metadata across sources; evaluation protocols per modality.
- Cross-lingual and multilingual relevance labelers (global enterprises; public sector)
- What: Train SLM labelers that score relevance across languages and mixed-language corpora.
- Tools/products/workflows: Multilingual synthetic data generation; language-aware templates; cross-lingual BM25/dense retrieval.
- Assumptions/dependencies: High-quality multilingual teacher LLMs; language coverage and tokenization; locale-specific privacy rules.
- Explainable relevance judgments for governance and audit (policy/compliance; finance, government, healthcare)
- What: Layer reasoning or criteria-based scoring (e.g., topicality, coverage) for auditable decisions and bias/fairness checks.
- Tools/products/workflows: Criteria-based prompts; explainability dashboards; bias and drift monitoring; red-teaming suites.
- Assumptions/dependencies: Reliable reasoning models (e.g., o1/R1 style teachers) for distillation; accepted explainability standards.
- Industry benchmarks and standards for enterprise search relevance
- What: Establish shared evaluation datasets, label taxonomies (0–4 scales), and best practices for synthetic labeling.
- Tools/products/workflows: Consortia-led benchmarks; interop formats for query–doc–label triplets; certification programs.
- Assumptions/dependencies: Cross-organization data-sharing frameworks; legal agreements; consensus on metrics and label definitions.
- Federated/on-device labeling for strict data residency
- What: Run query generation, negative mining, labeling, and SLM inference on device or in-region clusters to satisfy residency laws.
- Tools/products/workflows: Federated fine-tuning; secure aggregation; edge-optimized SLMs.
- Assumptions/dependencies: Sufficient local compute; lightweight teacher alternatives; orchestration for distributed training.
- Active learning with user signals and continual adaptation
- What: Use interaction data (dwell, satisfaction) to prioritize labeling for ambiguous queries and refresh relevance models.
- Tools/products/workflows: Selection strategies for uncertain cases; human-in-the-loop review for edge cases; periodic re-finetuning.
- Assumptions/dependencies: Robust debiasing of click logs; privacy-preserving telemetry; feedback loops that avoid feedback collapse.
- Relevance-as-a-Service platforms for ISVs and system integrators
- What: Commercial offerings that provide turnkey pipelines (synthetic data, labeling SLMs, eval dashboards) for enterprise clients.
- Tools/products/workflows: Managed services; SLAs on throughput and quality; plug-ins for common DMS/IDPs.
- Assumptions/dependencies: Market acceptance of synthetic labels; integration with varied customer stacks; compliance posture.
- Domain- and regulation-specific labelers (healthcare, finance, legal)
- What: Specialized SLMs tuned with domain ontologies and compliance constraints (e.g., ICD codes, IFRS, case law).
- Tools/products/workflows: Domain-specific prompts, synthetic patterns, and negative mining; compliance-aware evaluation.
- Assumptions/dependencies: Access to curated, compliant seed corpora; expert-designed label criteria; regulator buy-in for synthetic supervision.
- Robustness to domain drift and long-tail queries
- What: Automated monitoring and refresh of templates, negatives, and label distributions to sustain quality over time.
- Tools/products/workflows: Drift detection; scheduled regeneration; guardrails for label balance and template diversity.
- Assumptions/dependencies: Observability across query segments; capacity for periodic compute; versioning and rollback plans.
Collections
Sign up for free to add this paper to one or more collections.

