Semantic Search At LinkedIn
Abstract: Semantic search with LLMs enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small LLM trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Semantic Search at LinkedIn” in Simple Terms
What is this paper about?
This paper explains how LinkedIn made its search smarter and faster using AI. Instead of matching exact words, the new system understands the meaning of what you type. It powers two big features: finding jobs (AI Job Search) and finding people (AI People Search). The main challenge they solved was making this “meaning-based” search quick enough to serve hundreds of millions of users in real time.
What questions were the researchers trying to answer?
In everyday language, they asked:
- How can we show better job and people results by understanding what users really mean, not just the exact words they type?
- How do we keep results relevant (good matches) and engaging (more clicks, applications, messages), while being fair and following product rules?
- How can we run these big AI models super fast, so search feels instant?
- Can a smaller, cheaper AI model learn from bigger “teacher” models and still perform well?
How did they do it? (Methods explained with analogies)
Think of LinkedIn’s search like a relay race with two key runners:
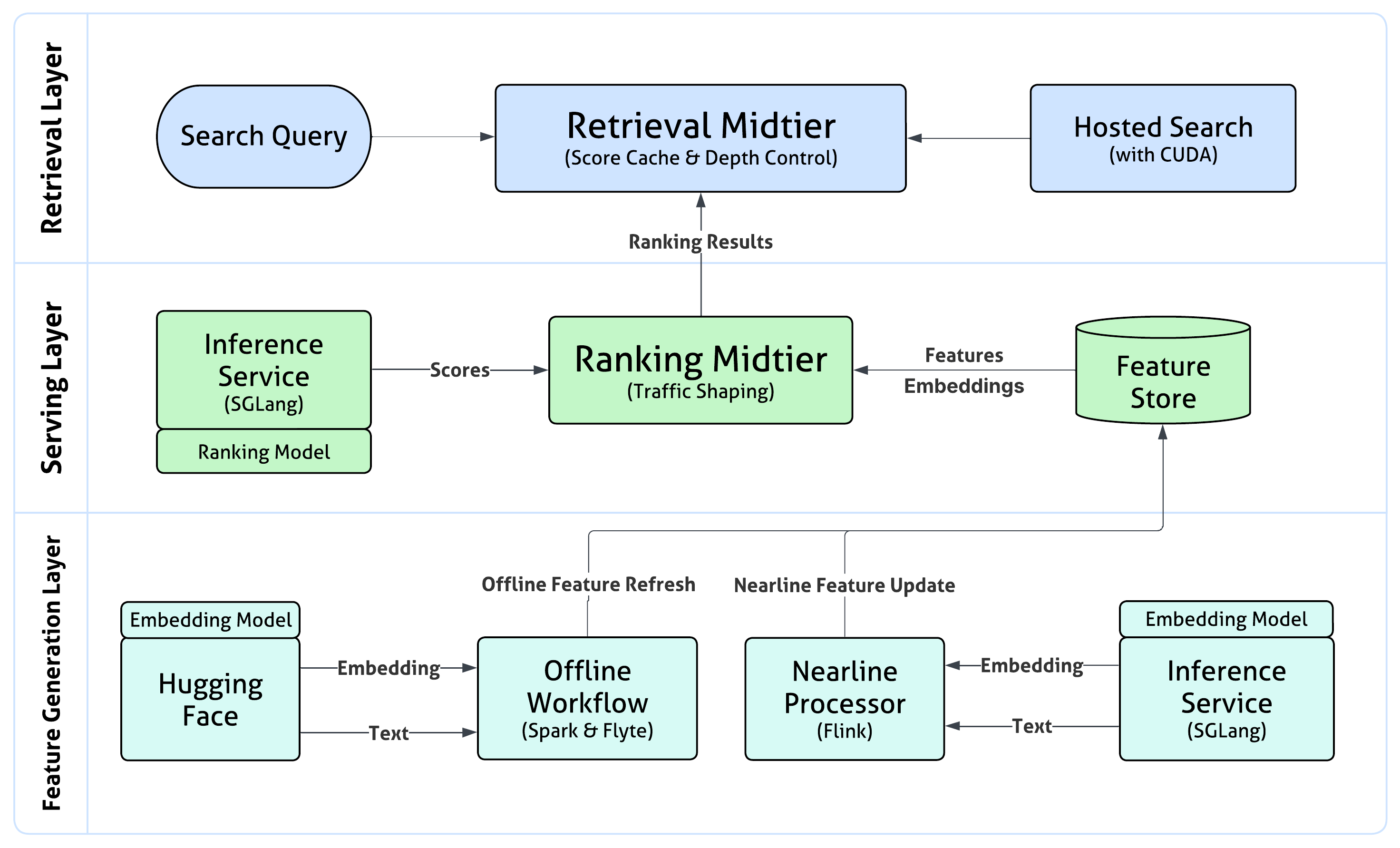
- Retrieval (the “scout”):
- The system first turns your query and all possible results (jobs or profiles) into numbers called “embeddings.”
- Imagine every job and every query is placed as a dot in a huge map. The closer two dots are, the more similar they are in meaning.
- A fast GPU system scans the whole map to find the top matches. This is called exhaustive retrieval (it looks everywhere, not just “nearby shortcuts”), which helps avoid missing good results.
- Ranking (the “judge”):
- A compact Small LLM (SLM) then looks at the top candidates more carefully, one by one, and decides the best order to show them.
- This judge balances two things: relevance (does this match the query well?) and engagement (is the user likely to click, connect, or apply?).
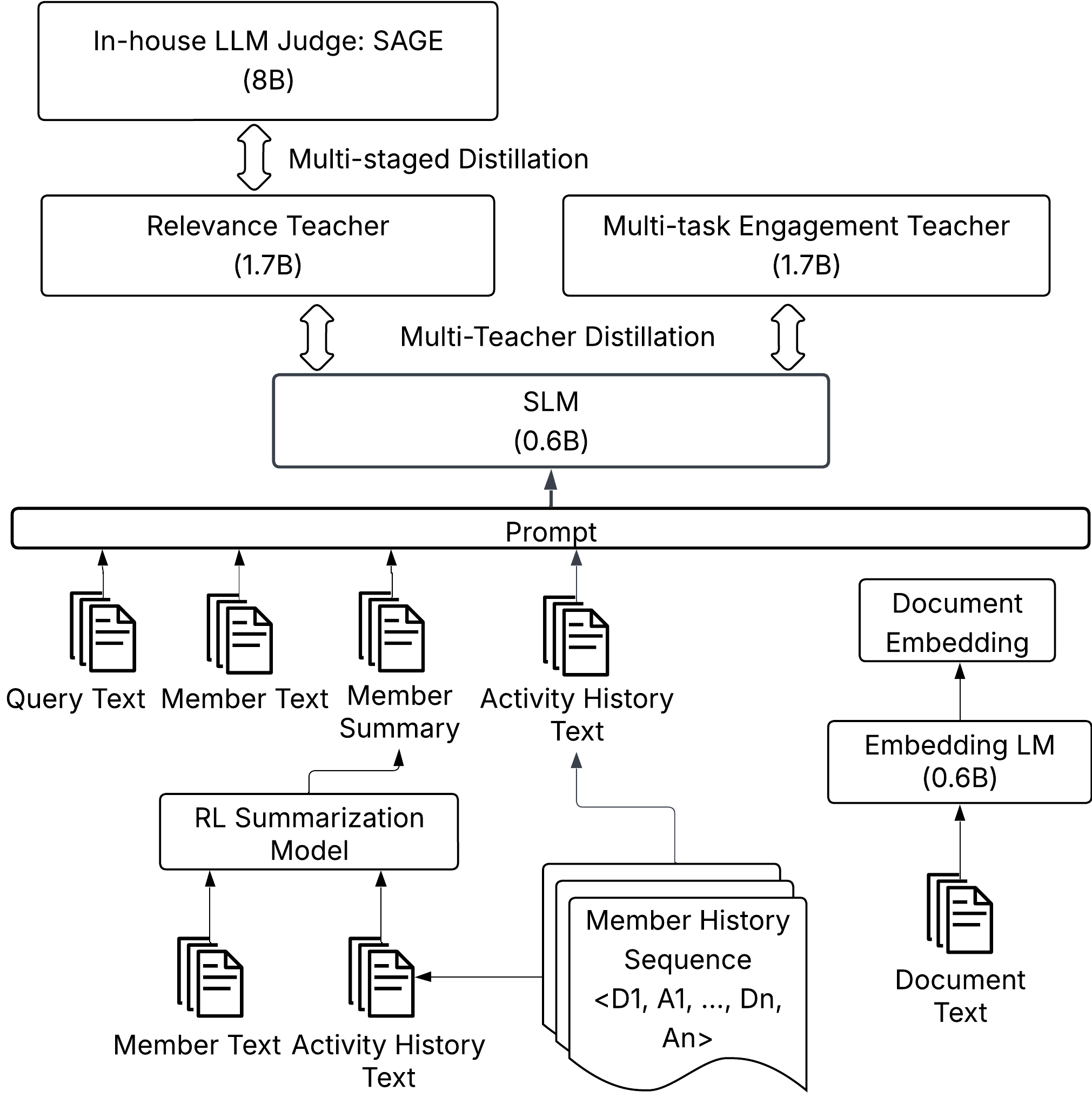
How the judge learned:
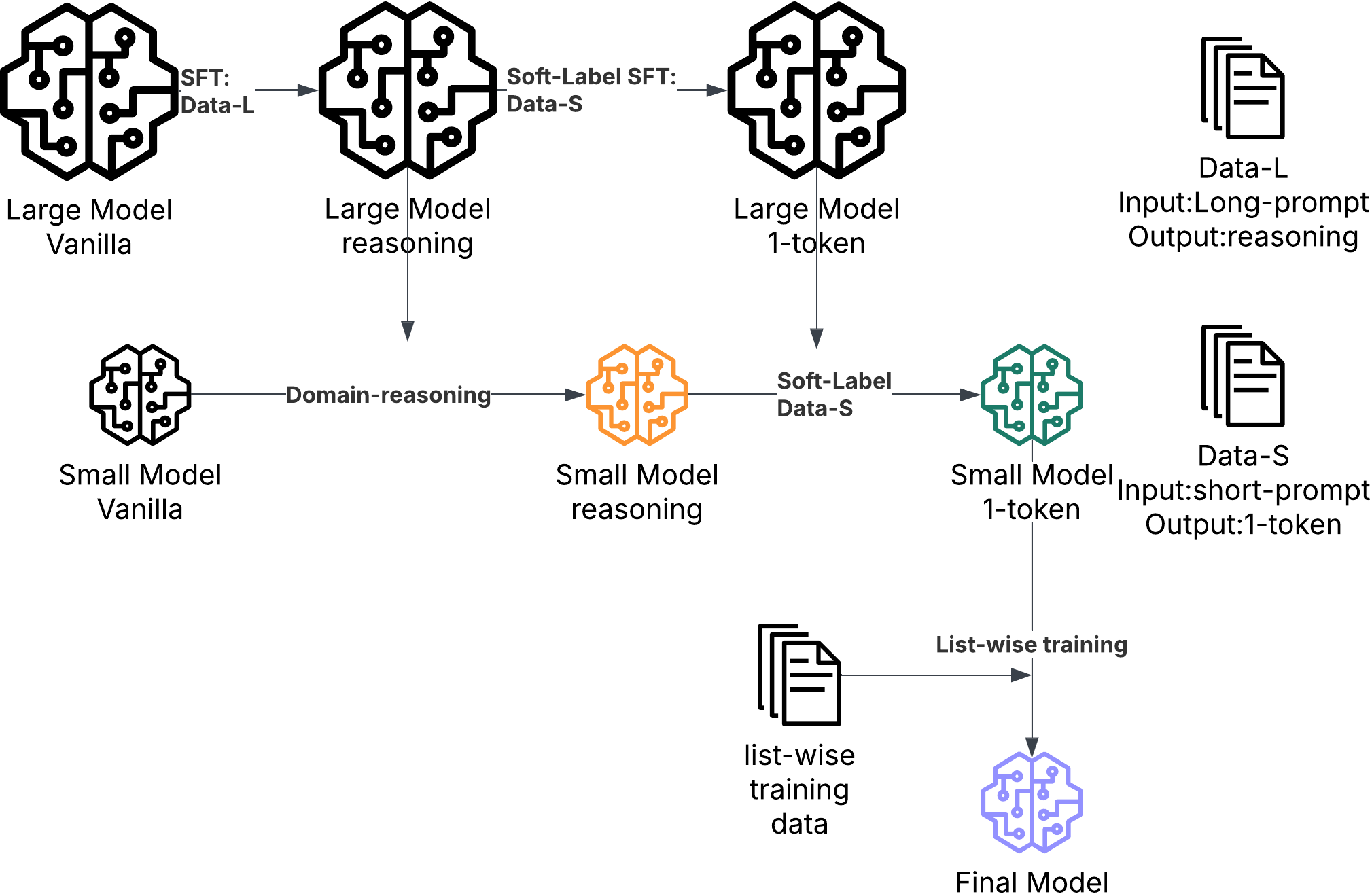
- Teacher–student training (distillation): Big “teacher” models first learn what makes a result relevant or engaging. Then a smaller “student” model (the SLM) learns from them—like a tutor helping a student. This makes the student fast enough to use live.
- SAGE (the rules keeper): Another AI judge helps define what “relevant” means based on product policies and human examples, ensuring results follow LinkedIn’s guidelines.
How they made it fast:
- Summarization: Long texts (like job descriptions or member profiles) are shortened by AI ahead of time. Think of a TL;DR that keeps the important parts.
- Pruning: They trim the AI model, like cutting extra branches off a tree, and fine-tune it to keep accuracy.
- MixLM (mixed interaction): Instead of feeding full text each time, they convert items into compact tokens (like tiny cheat sheets). The ranking model reads the query text plus these tokens—much faster, but still accurate.
- Prefill-only scoring: Traditional AI “chat” models read and generate words step-by-step. For ranking, they don’t need to “chat” back. They just read once and score. That saves time.
- Shared-prefix caching: The query and user info (the “prefix”) are the same for all items. Compute it once, reuse it for all candidates in that batch.
- GPU and system optimizations: They adjusted training settings (like batch sizes), used better libraries, and tuned runtimes so the entire pipeline runs smoother on powerful computers.
What did they find, and why is it important?
Key results:
- Much faster ranking: With all the speed-ups, the system can score up to around 22,000 items per second per GPU under a strict latency limit (<500 ms). That’s roughly 75× faster than the naive version, while keeping almost the same quality of results.
- Better retrieval and ranking quality:
- The retrieval stage got higher precision and recall (it finds more of the right stuff).
- The ranking stage improved user engagement metrics, like click and connect rates.
- Calibration (a smart “probability fixer”) made scores more reliable and boosted click prediction accuracy.
- Real production scale: This is one of the first times a LLM–based ranking system runs in production with speed close to traditional methods, but with better meaning understanding.
Why it matters:
- Users see more relevant jobs and people, faster.
- The system increases positive actions (clicks, applications, connects) without slowing down the experience.
- It shows that meaning-based search can work at the scale of LinkedIn if you co-design the AI models and infrastructure.
What does this mean for the future?
- Smarter search everywhere: Other companies can use similar ideas to move from keyword matching to meaning-based results.
- Smaller, faster AI that still performs well: Teacher–student training and model pruning can make big-model benefits practical.
- Better, fairer results: With AI judges and clear policies, relevance can be tuned to what the product considers “good,” not just what matches words.
- Open tools: Parts of the inference (serving) system were open-sourced (via the sglang project), which may speed up progress in the wider community.
In short, LinkedIn built a meaning-first search system that’s both accurate and fast enough for real-world use. It helps people find better job and people matches quickly, and it shows a path for others to make AI-powered search practical at massive scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open questions that remain unresolved by the paper and could guide future research and engineering work:
- External validity: How well do the proposed models and serving techniques generalize beyond LinkedIn’s verticals (Jobs/People) to other domains, content types, and application contexts?
- Multilingual and multicultural robustness: What is performance across languages and regions (especially low-resource locales), and how should the system be adapted for cross-lingual queries and documents?
- Online validation and long-term impact: The paper reports offline NDCG/AUROC gains but provides no controlled A/B results, confidence intervals, or long-horizon effects (e.g., satisfaction, retention, job outcome quality). How do offline gains translate online over weeks/months?
- SAGE/LLM-judge reliability: What is slice-level reliability of the 8B “oracle” across intents, categories, languages, and edge cases? How is drift detected and remediated when policy or product definitions of “relevance” evolve?
- Circularity and bias amplification: Training and evaluating with the same LLM judge risks feedback loops. What techniques (human-in-the-loop audits, adversarial evaluation, disagreement analyses) ensure the student does not overfit teacher idiosyncrasies or biases?
- Human agreement and governance: Kappa is reported in aggregate; what is agreement by policy slice and over time? How are low-agreement slices prioritized for human adjudication and improvement?
- Teacher error propagation: How are systematic teacher errors identified and corrected before distillation? Is there a strategy for debiasing or ensemble teachers to reduce correlated errors?
- Data construction biases: Hard negatives are drawn from top production candidates labeled non-relevant by the judge, which may encode exposure/selection bias. How can counterfactual logging, inverse propensity weighting, or interleaving be used to debias training?
- Offline-to-online correlation: What is the correlation between offline ranking metrics (NDCG, AUROC) and online KPIs by segment and query type? Which offline metrics best predict online wins?
- Multi-objective trade-offs: The method jointly optimizes relevance and multiple engagement signals, but principled trade-off control is underspecified. How can Pareto-efficient frontiers or constrained optimization (e.g., fairness/marketplace health constraints) be incorporated?
- Loss weighting and gradient interference: Task-weight choices are hand-tuned. Can automated schemes (uncertainty weighting, gradient surgery, dynamic reweighting) yield better balance across relevance and rare-action heads?
- Position-aware calibration and exposure bias: Position-conditional calibration may encode historical exposure bias. Can causal corrections (e.g., IPS, CP@k calibration) reduce bias while preserving ranking quality?
- Calibration robustness: How stable are calibration mappings under covariate shift and seasonal/product changes? What monitoring and re-fitting cadence is needed to maintain probability fidelity?
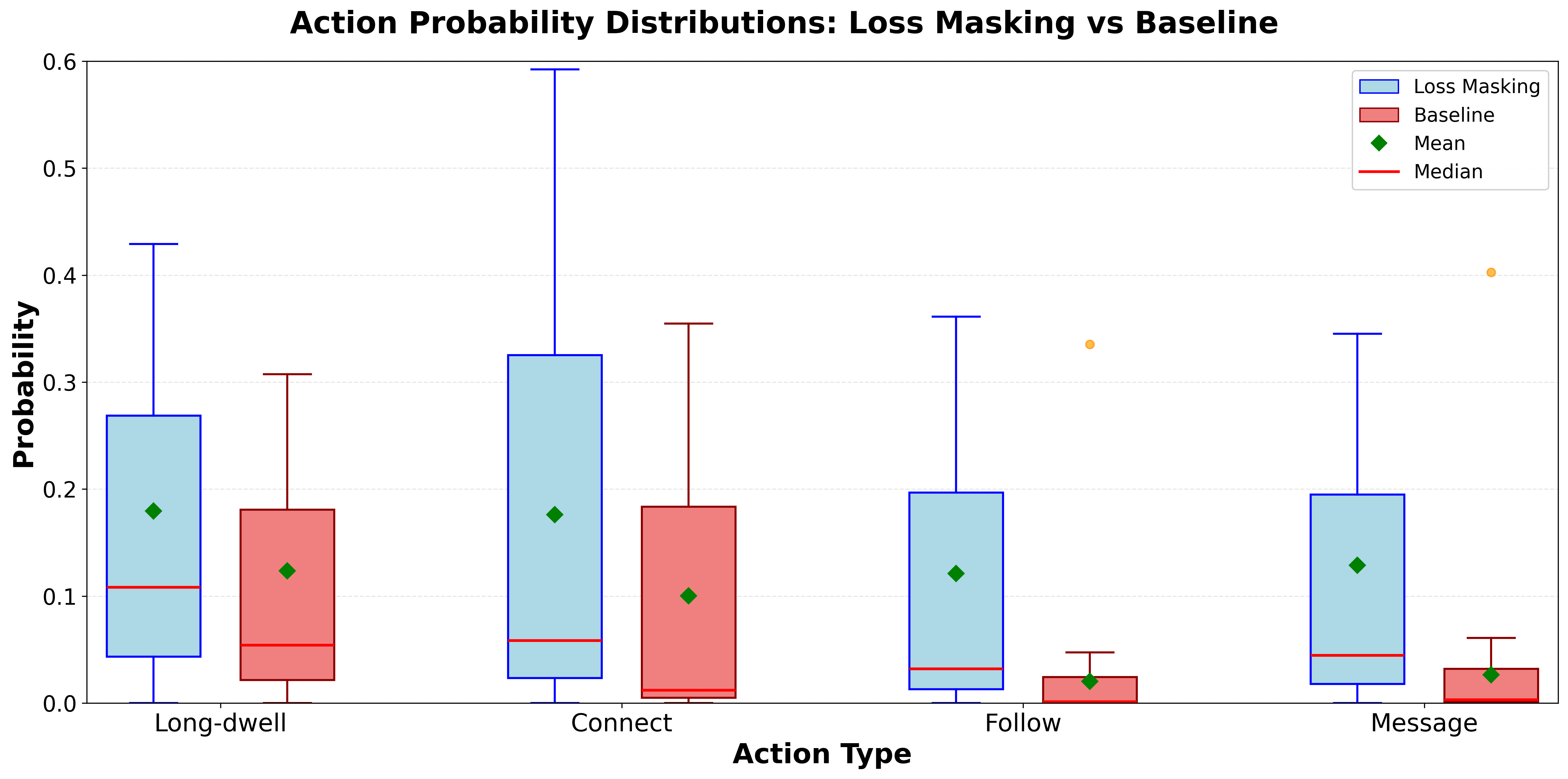
- Rare-event modeling: Loss masking increases rare action scores but may harm AUROC. Are PU learning, focal losses, or semi-supervised methods more effective for sparse actions without compromising calibration?
- “Data scaling to saturation”: After 10–40× data increases, relevance gains saturate. Which supervision or architecture changes (e.g., setwise/listwise objectives, direct NDCG optimization, richer pairwise sampling) break the plateau?
- Mapping ordinal labels to [0,1]: The paper shows sensitivity to mapping choices (linear vs sigmoid). What theoretical or empirical guidance optimizes mapping (and uncertainty modeling) for ordinal-to-probability conversion?
- Summarization quality and drift: Offline RL-based summaries compress member profiles/job descriptions, but risks of information loss, hallucination, and staleness are not quantified. What metrics and refresh cadences ensure summaries remain accurate and fair?
- Summarizer reward hacking and factuality: Using an engagement teacher as a reward model can induce reward hacking. How are factuality, completeness, and demographic parity enforced or measured in summaries?
- MixLM token caching staleness: How are nearline item-token caches invalidated on document updates, and what are the latency and consistency guarantees? What is the memory footprint and refresh throughput at billion-scale?
- Retrieval scalability vs cost: Exhaustive GPU retrieval avoids ANN “liquidity” issues but at unclear cost. What are the break-even points (vRAM, power, /QPS are not reported. What design choices best optimize total cost of ownership and sustainability targets?
- Compression beyond pruning: FP8 showed limited benefit <8B; what about AWQ/GPTQ, INT8/INT4, weight-only and KV-cache quantization for 375–600M SLMs? Can quantization match or exceed pruning gains without quality loss?
- Update cadence and rollback: How frequently are teachers/students/calibrators retrained, and what rollback and monitoring strategies address catastrophic forgetting or miscalibration after updates?
- Numerical-feature prompting vs separate towers: Injecting numeric features via prompt text improved AUROC but increases token budget and schema fragility. Would hybrid architectures (separate numerical tower with cross-attention) yield better stability and efficiency?
- Interpretability and user-facing explanations: The system produces rationales for the judge but not for ranking. Can faithful, non-gaming explanations be surfaced to users or reviewers to improve trust and debuggability?
- Robustness to adversarial content: How does the system handle obfuscated, templated, or adversarially optimized job posts/profiles aiming to exploit ranking features or summarization heuristics?
- Retrieval objective design: The λ-mixture of InfoNCE and margin loss works empirically, but how should λ, temperature, and hard-negative schedules be set adaptively by slice to optimize Recall@K and top-rank discrimination?
- Cold-start handling: How do the retriever/ranker/summarizer perform for newly created jobs/profiles with minimal history, and what priors or meta-features help reduce cold-start penalties?
- Multimodal extensions: Jobs and profiles often contain images/logos and other modalities; how should embeddings and rankers incorporate multimodal signals efficiently under the same latency constraints?
- Reproducibility: Results depend on proprietary data, infra, and policies. Can the authors release public benchmarks, anonymized schemas, or synthetic pipelines that approximate the setup for external validation?
Glossary
- ANN methods: Approximate nearest neighbor techniques that speed up vector search by trading off exactness for efficiency. "At retrieval time, most industrial systems rely on ANN methods with recall-efficiency trade-offs"
- AUROC: Area under the ROC curve; a classification metric measuring the ability to rank positives above negatives across thresholds. "Position conditioning improves Click AUROC from 0.6704 to 0.7095"
- Bi-encoder: A dual-tower model that encodes queries and documents separately into embeddings for similarity search. "We use a contrastive LLM bi-encoder to map queries and documents into a shared representation space"
- Bidirectional attention: An attention mechanism allowing tokens to attend both left and right context, enhancing representation learning for embeddings. "decoder-only LLMs can be turned into strong embedders via contrastive objectives and bidirectional attention"
- Chat template: Structured prompt formatting (system/user messages) used to standardize inputs to LLMs. "Use a chat-template system message specifying the binary relevance question"
- Contrastive learning: A training paradigm that pulls similar pairs together and pushes dissimilar pairs apart in embedding space. "Our retrieval model is an LLM-based bi-encoder trained with contrastive learning."
- CUDA graph: A GPU execution optimization that records and replays a sequence of kernels to reduce launch overhead. "Piecewise CUDA graph (prefill)"
- Decoder-only LLMs: Autoregressive transformer models that generate or score via a single causal stack without an encoder. "decoder-only LLMs can be turned into strong embedders via contrastive objectives and bidirectional attention"
- Domain Reasoning Distillation: Knowledge transfer that includes rationale text to convey domain decision rules from a teacher to a student. "Domain Reasoning Distillation: Initialize from an intermediate base model and distill from the oracle via distribution matching (e.g., forward/reverse KL), producing ordinal grades with reasoning text to transfer domain-specific decision rules."
- Embedding-based retrieval: Retrieval using vector representations of queries and documents to find nearest neighbors by semantic similarity. "combining an LLM relevance judge, embedding-based retrieval, and a compact Small LLM"
- Exhaustive retrieval: A retrieval approach that scores the full index rather than approximating neighbors, often GPU-accelerated. "GPU-accelerated exhaustive retrieval"
- FPFT (Full-Parameter Fine-Tuning): Updating all model parameters during fine-tuning, as opposed to parameter-efficient methods. "InfoNCE + HardNeg (FPFT)"
- FSDP2: PyTorch’s Fully Sharded Data Parallel version 2 that shards model states across devices for memory-efficient multi-GPU training. "FSDP2~\cite{pytorch_fsdp2}"
- GPU Retrieval-as-Ranking (GPU RAR): A GPU-scored linear model combining embedding similarity and features to directly optimize retrieval ranking. "GPU retrieval-as-ranking (GPU RAR) scoring"
- GRPO: A reinforcement learning algorithm variant for optimizing policies via gradient-based methods. "Training uses GRPO \cite{shao2024deepseekmath}"
- Hard-negative mining: Selecting challenging non-relevant examples to improve model discrimination at top ranks. "Effective hard-negative mining improves discrimination at top ranks"
- IBPC (In-batch prefix caching): Sharing computed KV states for common prompt prefixes within a batch to avoid redundant compute. "In-batch prefix caching (IBPC) ensures the prefix KV is only computed once and shared across the entire batch."
- InfoNCE objective: A contrastive loss function that maximizes the similarity of positive pairs against a set of negatives. "Training combines a global InfoNCE objective ($\mathcal{L}_{\text{InfoNCE}$) with a pairwise margin loss"
- Isotonic regression: A monotonic calibration technique that maps scores to probabilities while preserving order. "a PyTorch isotonic-regression-style model"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method injecting low-rank matrices into weight updates. "InfoNCE (LoRA)"
- Loss Masking: A training strategy that selectively includes or excludes labels/losses to prevent undesired gradient signals. "Loss Masking"
- MixLM: A text–embedding mixed-interaction architecture that replaces long item text with learned embedding tokens for ranking. "MixLM~\citep{li2025mixlmhighthroughputeffectivellm}, a text-embedding mixed-interaction architecture."
- Multi-teacher Distillation (MTD): Distilling knowledge from multiple teacher models into a single student using weighted distribution losses. "Joint-optimization of relevance and engagement via MTD also benefits from data and feature engineering."
- NDCG: Normalized Discounted Cumulative Gain; a ranking metric emphasizing correct ordering at top positions. "preserving near–teacher-level NDCG"
- OSSCAR: A structured compression method that prunes neurons/layers to reduce model size while preserving quality. "using OSSCAR~\citep{meng2024osscar}, pruning 50\% of hidden neurons in each MLP block and removing the final eight transformer layers."
- Pairwise margin loss: A ranking loss enforcing a minimum score gap between positives and hard negatives for the same query. "a pairwise margin loss ($\mathcal{L}_{\text{pair}$) to sharpen local decision boundaries"
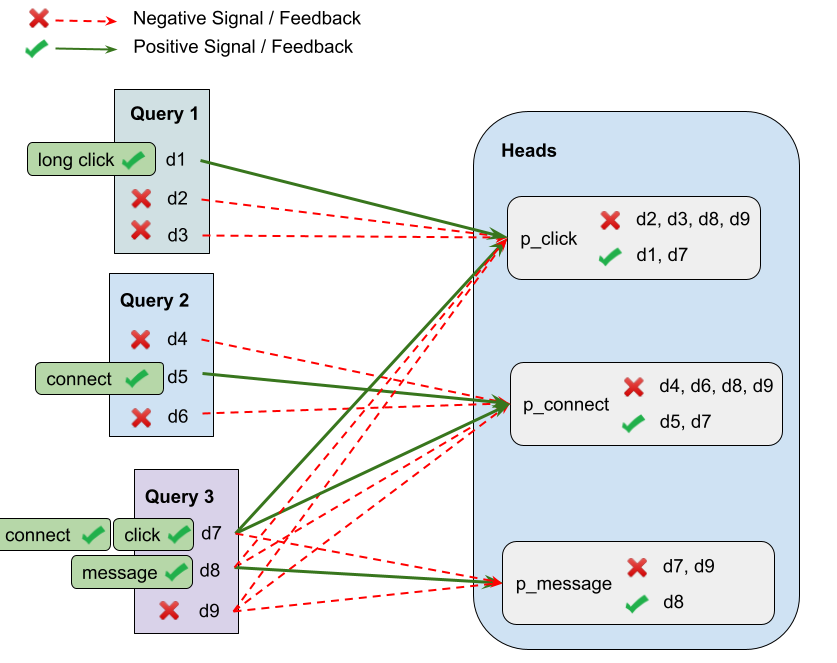
- Position-conditioned calibration: Calibrating predicted probabilities as a function of rank position to correct exposure bias. "It also supports position-conditioned calibration via loss masking"
- Prefill-only execution: An inference mode that runs a single forward pass to produce final logits without any decoding steps. "prefill-only execution and shared-prefix amortization."
- Query Understanding (QU): A preprocessing layer that converts free-form queries into structured, machine-interpretable signals. "Query Understanding (QU) layer"
- Shared-prefix amortization: Avoiding repeated computation of the common prompt prefix across many item suffixes in ranking. "shared-prefix amortization"
- SAGE: An LLM-based evaluation framework that operationalizes relevance policy and supervises model development and launch decisions. "We address this with SAGE~\cite{illuminator2025}, an LLM-based evaluation framework"
- SLM (Small LLM): A compact LLM used for efficient online ranking and multi-task prediction. "a compact Small LLM trained via multi-teacher distillation"
- Soft-label SFT: Supervised fine-tuning using probabilistic (soft) targets rather than hard labels to preserve uncertainty. "Soft-label SFT achieves $0.8420$ NDCG@10"
- Tensor-Parallelism: Splitting model layers across GPUs to parallelize tensor operations for larger models. "Tensor-Parallelism, and Data Parallelism configurations."
- vRAM guardrails: Constraints to manage GPU memory usage during serving, backfills, and internationalization. "enforce vRAM guardrails during internationalization and backfills"
- VCG: Vickrey–Clarke–Groves auction mechanism used for efficient, truthful allocation; referenced for position-aware ranking/auction logic. "VCG \cite{vcg_paper}"
Practical Applications
Immediate Applications
These applications can be deployed today by adapting the paper’s models, training recipes, and infrastructure patterns. Each item lists sectors, candidate tools/workflows, and feasibility notes.
- AI Job and Talent Search (HRTech, Recruiting)
- Deploy an LLM-supervised, SLM-ranked semantic search for job matching and candidate sourcing (query understanding → embedding retrieval → SLM ranker with relevance + engagement → position-aware calibration).
- Tools/workflows: GPU-accelerated exhaustive retrieval-as-ranking (GPU RAR), multi-teacher distillation for unified rankers, RL-based profile/activity summarization, position-conditioned calibration for click/apply/connect, hard-negative mining for retrieval, shared-prefix inference via sglang.
- Assumptions: Action logs (click/apply/connect), access to document and profile text, GPUs for serving; clear product relevance policies to encode into an LLM judge.
- E-commerce Product Search and Ranking (Retail, Marketplaces, Ads)
- Replace keyword search with semantic retrieval plus SLM rankers jointly optimized for relevance and business KPIs (add-to-cart, purchase, return risk), with position-aware calibration supporting auctions.
- Tools/workflows: Multi-task engagement teacher (click/cvr/return), GPU RAR to fuse cosine similarity with price/availability/seller signals, position-conditioned calibration for ranking/auction logic (e.g., VCG), MixLM for high-throughput reranking.
- Assumptions: High-quality action labels, dense product attributes, allowable latency budgets and GPU capacity.
- Enterprise Knowledge and Developer Search (Software, IT, DevEx)
- Semantic search across wikis, tickets, runbooks, code/docs with LLM-based retrieval and SLM ranking under tight SLAs (on-call/playbook lookups, code search).
- Tools/workflows: Offline summarization of long documents, hard-negative mining from production logs, exhaustive GPU retrieval to support attribute filters without ANN recall pitfalls, sglang prefill-only scoring.
- Assumptions: Centralized corpora with metadata filters, GPUs and middle-tier orchestration; governance around access control.
- Customer Support Portals and Self-Service (Customer Service, SaaS)
- Improve case deflection via semantic KB search, ranking by resolution likelihood and satisfaction proxy metrics.
- Tools/workflows: Engagement teacher distillation on solve/deflection outcomes, calibrated probabilities per position, prompt-embedded numerical features (e.g., CTR, category confidence), offline document summaries.
- Assumptions: Historical support interactions with outcome signals; careful policy definition for “resolution relevance.”
- Policy-Aware Evaluation and Launch Governance (Policy, Trust & Safety, Product Ops)
- Adopt an LLM judge like SAGE to encode product relevance policies, generate graded labels with rationales, and gate A/B launches at scale.
- Tools/workflows: Distill a frontier judge into an in-house 8B model for high-throughput policy-aligned judgments; simulation-driven iteration; automated offline evaluation pipelines.
- Assumptions: Curated precedent datasets; a written policy to operationalize; monitoring for judge drift and bias.
- Ads and Feed Ranking Under Tight SLAs (Advertising, Social Platforms)
- Apply prefill-only SLM scoring and shared-prefix amortization to ad and feed ranking (millions of item scores/sec) to reduce serving costs without sacrificing relevance.
- Tools/workflows: sglang scoring path (no decode), in-batch prefix caching, batching tokenization, CUDA graph prefill, MixLM for text-embedding hybrid interactions.
- Assumptions: Ability to refactor prompts into shared prefix + item suffix; GPU scheduling and batching discipline.
- Academic/Industrial Evaluation at Scale (IR/NLP Research)
- Replace or augment human labels with distilled LLM judges for retrieval/ranking research and iterative model development.
- Tools/workflows: Multi-teacher distillation framework (online/offline), counterfactual retrieval tests, quality-based upsampling to focus on hard buckets.
- Assumptions: Alignment between LLM judge and human policy; careful calibration and auditing of label quality.
- Multilingual and Attribute-Heavy Retrieval (Global Products, Regulated Search)
- Use LLM-based embedders with task LoRA and hard-negative mining for robust multilingual retrieval; leverage exhaustive GPU retrieval for heavy prefiltering.
- Tools/workflows: Contrastive bi-encoders (InfoNCE + margin loss), policy-bucket sampling, GPU RAR to blend embeddings with attribute and personalization features.
- Assumptions: Sufficient multilingual data; GPU memory guardrails, especially during internationalization.
- MLOps Efficiency Playbooks (MLOps, Infra)
- Reduce training and serving costs by adopting the paper’s infra recipes.
- Tools/workflows: LiGER for memory-efficient fine-tuning, FSDP2 and multinode training, agentic GPU optimization (config tuning via code+telemetry analysis), offline multi-teacher caching to cut GPU-hours.
- Assumptions: Access to cluster telemetry; willingness to automate config/tuning; reproducibility discipline.
- SMB/Startup Semantic Search Starter (Cross-sector)
- Build a lean semantic search with open SLMs, distilled judges, offline summaries, and sglang inference, targeting sub-500 ms latencies.
- Tools/workflows: OSSCAR-based pruning of SLMs, prompt engineering for numerical features (True/False, CTR with counts), stratified sampling, MixLM for scale.
- Assumptions: Smaller corpora or modest GPUs; initial policy and evaluation scaffolding.
Long-Term Applications
These require further research, scaling, or ecosystem development before mainstream deployment.
- Unified LLM Rankers Across Verticals (Search, Feed, Ads, Recommendations)
- A single distilled SLM handling relevance + multiple engagement objectives across products (search/feed/ads), reducing model sprawl while preserving policy alignment.
- Dependencies: Strong multi-task generalization, continual learning and guardrails to avoid cross-domain drift; robust calibration under distribution shift.
- Privacy-Preserving and On-Device Ranking (Edge AI, Privacy)
- Move pruned/quantized SLM rankers and profile summaries on-device to enable privacy-first personalization.
- Dependencies: Further compression (beyond 375M), hardware acceleration on edge, federated/retrieval splits that respect data locality, privacy-preserving distillation.
- Regulator-Grade Policy Auditing and Explainability (Public Policy, Compliance)
- Use judge rationales + calibrated scores to audit fairness, exposure, and compliance in search/ranking systems; standardize relevance policy disclosure.
- Dependencies: Accepted standards for policy-aligned LLM judges, transparent metrics (O/E, kappa), third-party auditing frameworks.
- Multimodal Semantic Search at Scale (Media, Education, Healthcare)
- Extend text-embedding hybrid interactions to images, audio, and video for unified retrieval and ranking (e.g., medical imaging + notes; lecture videos + transcripts).
- Dependencies: Multimodal encoders, high-quality cross-modal labels, safety validations (especially in healthcare), larger nearline caches for learned tokens.
- Causal and Market-Aware Ranking with Position Calibration (Ads/Marketplaces)
- Leverage position-conditioned likelihoods to enable truth-telling auctions and causal uplift optimization, improving allocative efficiency.
- Dependencies: Ecosystem adoption of position-aware bidding and causal evaluation; robust de-biasing of exposure confounders.
- Energy-Efficient, Low-Carbon Search (Sustainability, Data Centers)
- Standardize context compression, pruning, and MixLM-like architectures to cut compute/energy per query across large fleets.
- Dependencies: Broad infra modernization (GPU availability, batching discipline), lifecycle carbon accounting to target optimization.
- Domain-Specific Knowledge Search in Regulated Sectors (Healthcare, Finance, Legal)
- Policy-aligned LLM judges and calibrated rankers for clinical knowledge portals, compliance search, and legal discovery with strict governance.
- Dependencies: Domain-specific policies and precedent sets, rigorous evaluation (human-in-the-loop), explainability/traceability, strong privacy/security.
- Continuous RL Summarization for Personalization (Search/RecSys)
- RL-trained summarizers that compress evolving user histories and item content to maximize downstream engagement quality and reduce context cost.
- Dependencies: Stable reward models, safeguards against reward hacking, controls for factuality and bias, scalable refresh pipelines.
- ANN-Free, Billion-Scale Retrieval Blueprints (Large Enterprises)
- Broader adoption of GPU-accelerated exhaustive retrieval with attribute filters to simplify system complexity (no multi-path or liquidity workarounds).
- Dependencies: Cost-effective GPU fleets, robust vRAM guardrails, operational maturity for corpus-scale rebuilds/backfills.
- Standardized LLM-Judge Datasets and Benchmarks (Academia/Industry Collaboration)
- Public policy-aligned relevance corpora with LLM and human labels for replicable IR research and model evaluation.
- Dependencies: Data sharing agreements, privacy-safe anonymization, community consensus on task definitions and grading schemes.
- MixLM-as-a-Service for High-Throughput LLM Ranking (Platformization)
- Managed services that expose text-embedding hybrid ranking with end-to-end distillation, caching, and prefill-only inference for third parties.
- Dependencies: Productization of training + serving pipelines, workload isolation, SLAs for tail-latency at scale.
Notes on feasibility across items:
- Most immediate applications hinge on access to GPUs, clean action logs, and explicit relevance policy definitions (to supervise judges and calibrations).
- Long-term items often depend on compression breakthroughs, standardized governance, and reliable causal inference and auditing frameworks.
Collections
Sign up for free to add this paper to one or more collections.