- The paper introduces RecursiveVLM, a recursive framework that iteratively refines multimodal embeddings using a modality-specific connector and monotonic recursion loss.
- It demonstrates a significant performance boost—up to 7% improvement—over non-recursive and vanilla recursive baselines on eight vision-language benchmarks.
- The approach supports anytime inference and efficient hallucination suppression through robust cross-modal feature alignment and progressive refinement.
RecursiveVLM: Recursive Refinement for Parameter-Efficient and Flexible LMMs
Introduction
The proliferation of Large Multimodal Models (LMMs) such as GPT-4V, Gemini, and Qwen-VL has enabled high performance across a spectrum of vision-language tasks. However, the underlying architecture of current LMMs typically activates each parameter only once per input during inference and training, leading to poor parameter utilization relative to model capacity. In contrast, recent advances in Recursive Transformer architectures within language modeling have demonstrated the feasibility of iterative parameter usage for enhanced reasoning and improved latent representation without increasing the model's parameter count.
Translating recursive computation paradigms from unimodal LLMs to multimodal settings is non-trivial. Unlike text-only input, LMMs operate with heterogeneous and statistically divergent visual and text tokens, resulting in severe cross-modal misalignment, instability in iterative inference, and degraded intermediate outputs using naive recursion. This work proposes RecursiveVLM, an architecture that addresses these challenges with two core innovations: a modality-specific Recursive Connector to enforce feature distribution and scale alignment across recursive steps, and a Monotonic Recursion Loss to guarantee consistent quality improvement at every depth, enabling both on-demand inference and progressive refinement using the same parameter set.
Motivation and Analysis of Feature Misalignment
Recursive architectures that directly loop the output token representations back as inputs induce severe instability in LMMs. As demonstrated in (Figure 1), vanilla recursion leads to the rapid amplification of hidden state norms with increasing layers, as well as low Centered Kernel Alignment (CKA) scores between deep features and the input embedding space, reflecting both scale and semantic misalignment.
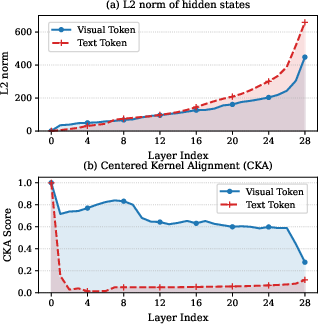
Figure 1: Feature scale (L2 norm) and CKA indicate vanilla recursive models induce severe misalignment across recursion steps, motivating the Recursive Connector design.
This misalignment is particularly acute in LMMs, where vision and language streams inherently diverge in both distribution and target representations, invalidating the approaches that succeed in text-only recursive LLMs.
RecursiveVLM Architecture
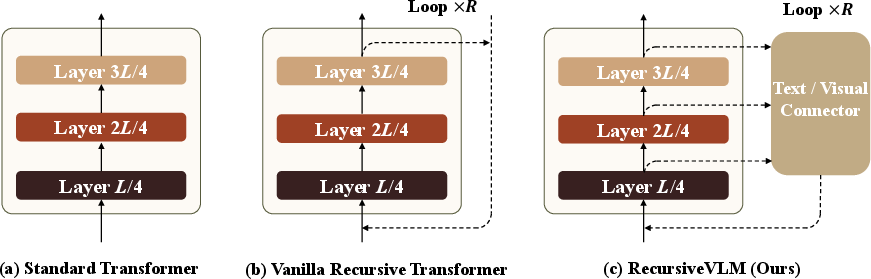
Figure 2: Comparison of recursive architectures in LMMs; RecursiveVLM fuses multi-layer features and employs modality-aware connectors to resolve cross-step misalignment.
The RecursiveVLM architecture recasts a standard transformer-based LMM into a recursive model parameterized by recursion depth R. At each recursive step r, inputs are constructed from both visual (V) and language (T) embeddings that are fused from selected intermediate and final transformer layers. The Recursive Connector, the primary architectural innovation, performs the following:
- RMSNorm-Based Scale Normalization: Ensures that features aligned for reuse at the input embedding space maintain consistent scale properties, addressing the L2 norm explosion issue.
- Modality-Specific MLP Projection: Projects both vision and language token representations via distinct learnable connectors, ensuring feature distribution alignment and respecting modality-specific statistical properties.
- Scaled Residual Pathways: Zero-initialized residual vectors enable stable initialization, preserving the pretrained behavior in step 1, and facilitating robust adaptation during recursive training.
- Multi-Layer Feature Fusion: Aggregates semantic cues from diverse hierarchies to enable richer recursive refinement and more faithful reuse of earlier representations.
Each recursion step thus incorporates complementary information, mitigating the degeneracy and instability of naive recursion.
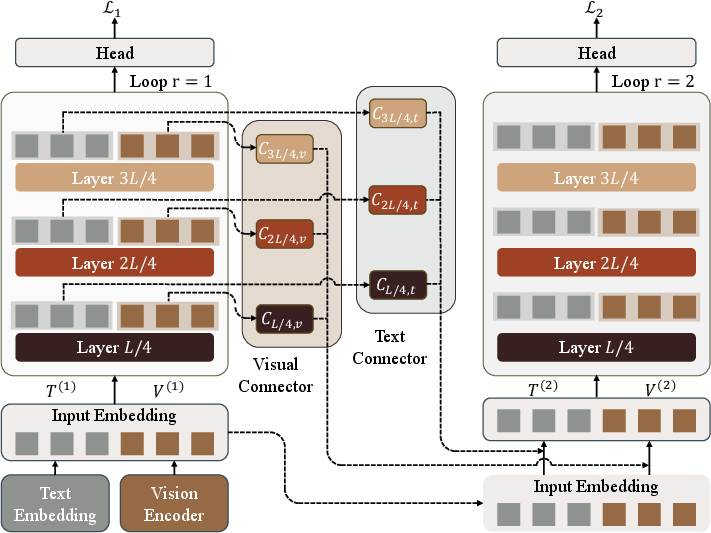
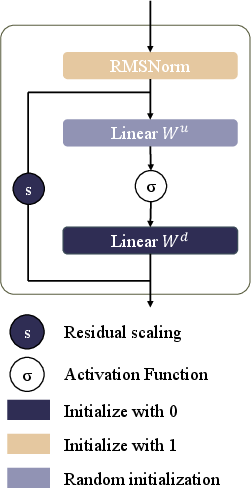
Figure 3: The RecursiveVLM framework employs a recursive loop over the Transformer backbone with multi-layer, modality-aware connectors to adaptively refine predictions at each step.
Monotonic Recursion Loss
Standard recursive models generally apply supervision only at the final output, which results in unpredictable or degraded intermediate predictions—undesirable for deployment where available compute may be variable. RecursiveVLM introduces Monotonic Recursion Loss: a per-token constraint that enforces non-increasing cross-entropy loss across recursive steps for each token. Tokens with degraded loss at step r incur an extra penalty (β=1.5 in experiments). This guarantees robust anytime prediction, essential for deployment on devices with heterogeneous computational budgets.
Empirical Results
RecursiveVLM demonstrates strong improvements over both non-recursive and naïve recursive architectures on eight vision–language benchmarks, including complex tasks such as diagram understanding, mathematical reasoning, multimodal hallucination mitigation, and robust common-sense reasoning. Key findings include:
- Superior Single-Step Performance: RecursiveVLM outperforms the standard non-recursive baseline by 1–2% even when only a single step is used at inference—all improvements attributable to recursive training and the connector architecture.
- Robust Recursion Gains: At step 2, performance exceeds the non-recursive baseline by approximately +3% and vanilla recursive baselines by +7%, with monotonic gains strictly maintained.
- Efficient Hallucination Suppression: Increasing recursion depth beyond 2 leads to significant improvements on HallusionBench, suggesting inherent robustness to hallucination due to recursive architectural and optimization properties.
Component Analysis and Ablation
- Connector Design: Ablation shows that the scaled residual connection and MLP-based projection are both essential. Removing connector elements leads to performance collapse consistent with feature misalignment.
- Layer Fusion: Uniform sampling of intermediate layers ([L/4,2L/4,3L/4,L]) provides best results, confirming that diverse-hierarchy fusion is critical.
- Modality-Aware Processing: Using independent connectors for vision and text yields clear gains over shared-parameter baselines, demonstrating the necessity of statistical decoupling.
- Loss Design: The Monotonic Recursion Loss outperforms per-step cross-entropy supervision by improving both stability and absolute performance, producing consistently deployable, high-quality outputs at any recursive depth.
Qualitative Examples
Qualitative analyses across diverse domains—including object recognition, spatial and mathematical reasoning, chart interpretation, and meme understanding—demonstrate that RecursiveVLM corrects critical errors present in intermediate recursive outputs, ultimately producing more semantically faithful and robust predictions.
Implications and Future Directions
RecursiveVLM establishes that recursive architectures, when equipped with robust cross-step feature alignment and monotonic optimization, yield parameter-efficient, resource-adaptive LMMs without sacrificing predictive power. This paradigm supports anytime inference: predictions can be generated at arbitrary recursion depths, facilitating deployment flexibility from edge devices to data centers. The inherent improvement in hallucination suppression suggests future architectural advances may further reduce undesirable behaviors through principled iterative refinement rather than relying solely on training set size or scale.
Future directions include dynamic recursion scheduling, hybrid mixture-of-recursion depth models, and further extensions to more complex multimodal streams and tasks—especially those sensitive to robust anytime prediction or vulnerable to hallucination.
Conclusion
RecursiveVLM propounds and validates a recursive computation framework for LMMs centered on feature realignment and monotonic improvement. This approach substantiates that effective parameter reuse, robust anytime predictions, and enhanced generalization are attainable within a single model instance, establishing recursion as a foundational design principle for scalable, robust, and deployment-adaptive multimodal AI.