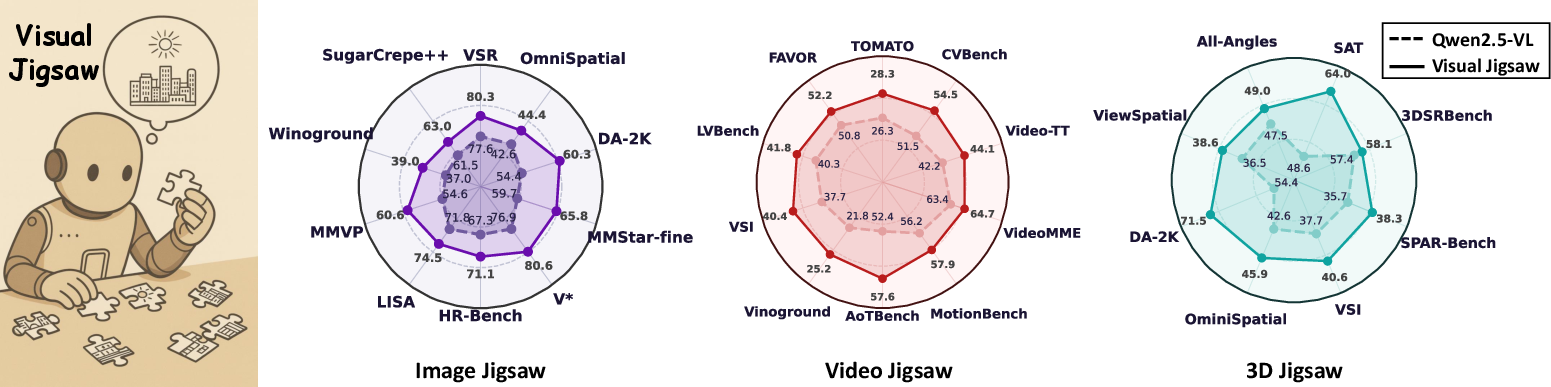
Figure 1: Visual Jigsaw post-training substantially strengthens fine-grained perception, spatial, compositional, temporal, and geometry-aware understanding across modalities, as shown in radar chart evaluations.
Visual Jigsaw is instantiated as a general ordering problem. For each modality:
The model outputs a permutation of indices in natural language, which is compared against the ground truth. A graded reward function is used: exact matches receive full reward, partial matches are scaled by a discount factor (γ=0.2), and invalid permutations receive zero reward. Outputs must adhere to a strict format, with reasoning enclosed in > tags and answers in <answer> tags.
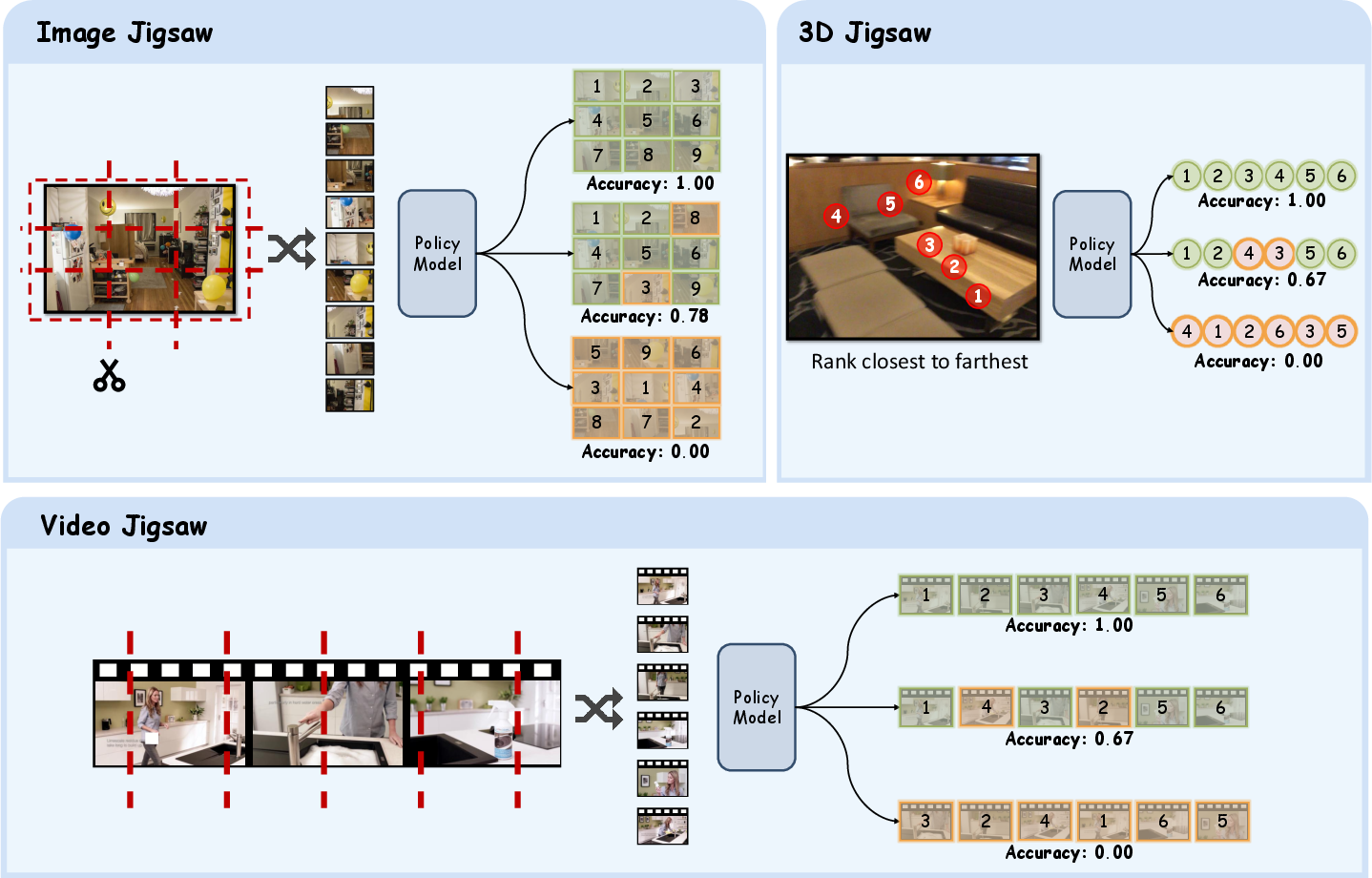
Figure 2: Illustration of Visual Jigsaw tasks for images, videos, and 3D data, showing partitioning, shuffling, and the ordering objective.
Training Protocol
Post-training is performed using Group Relative Policy Optimization (GRPO) without KL or entropy regularization. The base model is Qwen2.5-VL-7B-Instruct. Training datasets include 118K COCO images, 100K LLaVA-Video clips, and 300K ScanNet RGB-D samples. Batch sizes and learning rates are modality-specific, and multiple responses are sampled per prompt to encourage exploration.
Empirical Results
Image Jigsaw
Visual Jigsaw post-training yields consistent improvements across fine-grained perception, monocular spatial understanding, and compositional visual understanding benchmarks. Gains over strong baselines (ThinkLite-VL, VL-Cogito, LLaVA-Critic-R1) are observed in MMVP, MMStar, HR-Bench, VSR, Winoground, and others, with improvements up to +6.06 points on fine-grained tasks and +5.90 on spatial reasoning.

Figure 3: Examples of the image jigsaw task, showing shuffled patches and ground-truth raster order.
Video Jigsaw
On video understanding benchmarks (AoTBench, Vinoground, TOMATO, FAVOR-Bench, TUNA-Bench, Video-MME, TempCompass, TVBench, MotionBench, LVBench, VSI-Bench, Video-TT, CVBench), Video Jigsaw consistently outperforms both RL and SFT baselines across all frame settings. Gains are most pronounced on temporal-centric tasks, e.g., AoTBench (+6.15), and cross-video reasoning (CVBench, +3.00).

Figure 4: Example of the video jigsaw task, with shuffled clips and ground-truth chronological order.
3D Jigsaw
3D Jigsaw post-training leads to substantial improvements on SAT-Real, 3DSRBench, ViewSpatial, All-Angles, OminiSpatial, VSI-Bench, SPARBench, and DA-2K. The largest gain is on DA-2K (+17.11), directly related to depth ordering, but improvements are also observed on single-view, multi-view, and egocentric video tasks, indicating generalization of 3D spatial reasoning.

Figure 5: Examples of the 3D jigsaw task, requiring depth ordering of annotated points.
Qualitative Analysis
Qualitative examples demonstrate that models trained with Visual Jigsaw exhibit improved attention to local details, global spatial layouts, and inter-element relationships in images, videos, and 3D scenes.

Figure 6: Qualitative examples on image tasks, showing enhanced fine-grained perception.

Figure 7: Qualitative examples on video tasks, illustrating improved temporal reasoning.
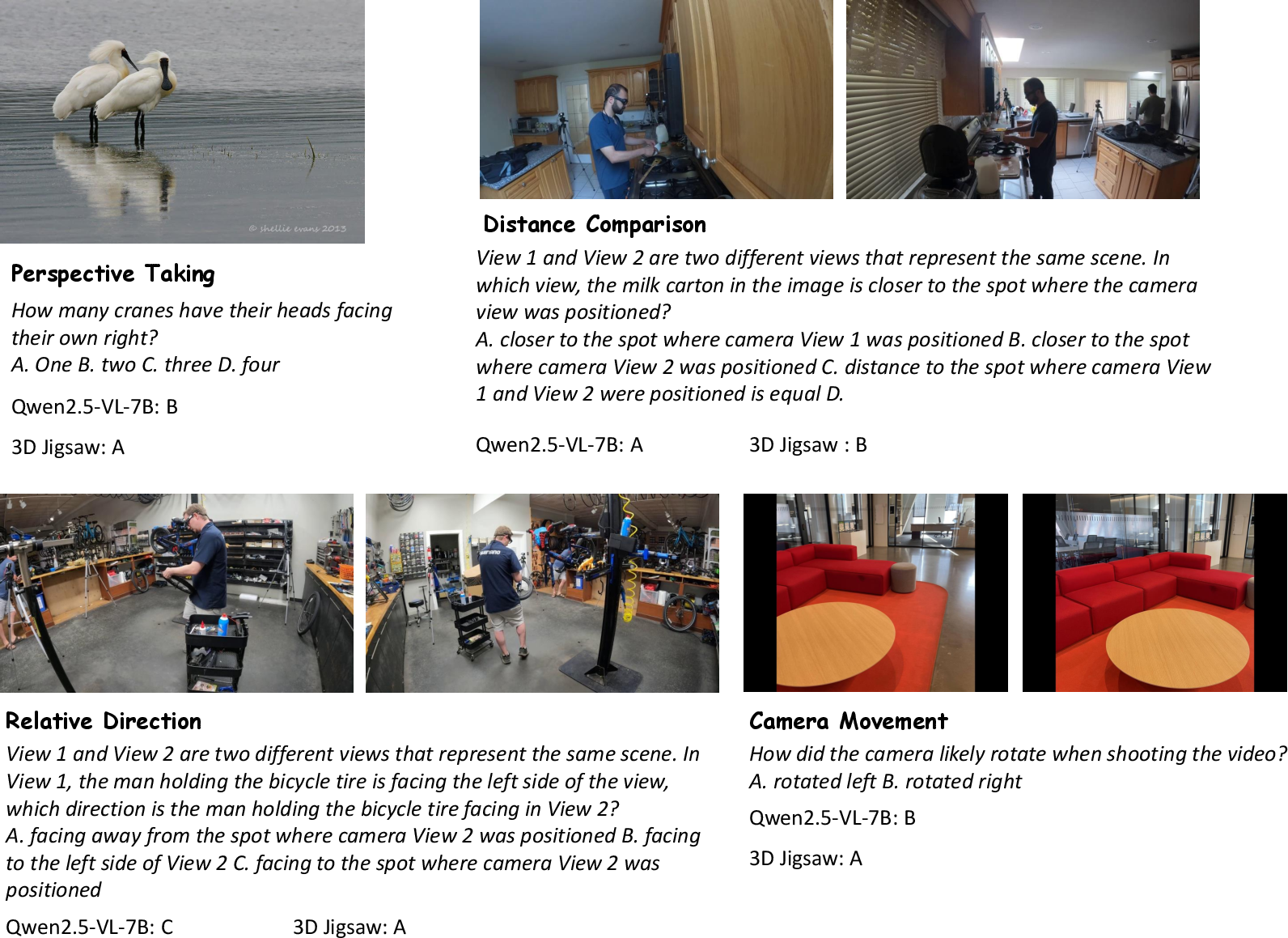
Figure 8: Qualitative examples on 3D tasks, highlighting geometry-aware understanding.
Ablation Studies
- SFT vs. RL: RL post-training generalizes better than SFT, which can lead to overfitting and degraded transfer on certain benchmarks.
- Task Difficulty: Increasing jigsaw complexity (e.g., 3×3 vs. 2×2 grids) provides stronger supervision and larger performance gains. Partial accuracy rewards are critical for learning in difficult setups.
- Reasoning Models: Visual Jigsaw post-training on reasoning-oriented MLLMs (e.g., ThinkLite-VL) improves visual perception without sacrificing reasoning ability.
- 3D Variants: Alternative 3D jigsaw tasks (view-motion matching, BEV-pose matching) do not outperform depth ordering, likely due to limited 3D priors in current MLLMs.
Implementation Considerations
- Computational Requirements: The approach is lightweight, requiring no architectural changes or generative modules, and is compatible with text-only MLLMs.
- Scalability: While effective at moderate scale, further scaling of data and model size is a promising direction.
- Generalization: RL-based post-training with verifiable, self-supervised objectives enables robust transfer to diverse downstream tasks.
- Limitations: The method relies on the model's existing visual priors; more complex jigsaw tasks or richer 3D representations may require stronger base models.
Implications and Future Directions
Visual Jigsaw demonstrates that self-supervised, vision-centric post-training can substantially enhance the perceptual grounding of MLLMs across modalities. The approach is general, efficient, and verifiable, making it suitable for large-scale deployment. Future work should explore more complex jigsaw configurations, hybrid spatial-temporal tasks, and integration with models possessing richer 3D priors. The paradigm also motivates broader investigation into self- and weakly-supervised objectives for multimodal model development.
Conclusion
Visual Jigsaw provides a principled, scalable framework for improving vision-centric perception and understanding in MLLMs via self-supervised RL post-training. The method achieves consistent gains across image, video, and 3D modalities, without requiring architectural modifications or generative components. These results establish vision-centric self-supervised tasks as a complementary and effective strategy for advancing multimodal model capabilities.