AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Abstract: LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AIRS-Bench, a new “benchmark” (a set of fair, repeatable tests) to see how well AI agents can do real machine learning research on their own. Instead of just answering questions, these agents have to think of ideas, write code, run experiments, and improve their work—like a junior scientist.
What questions are the researchers asking?
In simple terms, the paper asks:
- How good are today’s AI research agents at doing the full job of a machine learning researcher—from idea to code to results?
- Can we measure their skills fairly across many kinds of problems?
- Which agent designs (ways of organizing their thinking and search) work better?
How did they study it?
The benchmark and its tasks
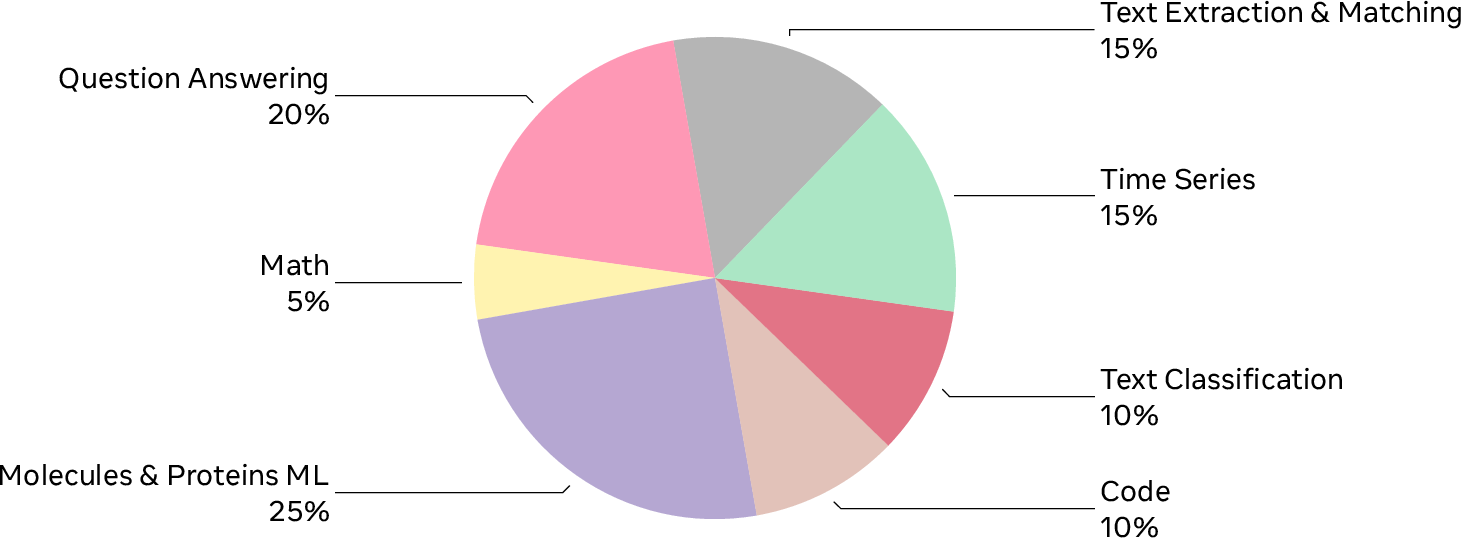
AIRS-Bench contains 20 challenging tasks taken from recent, high-level machine learning papers. The tasks cover different areas, such as language understanding, math, coding, biology (molecules and proteins), and time-series forecasting (predicting future values from past data).
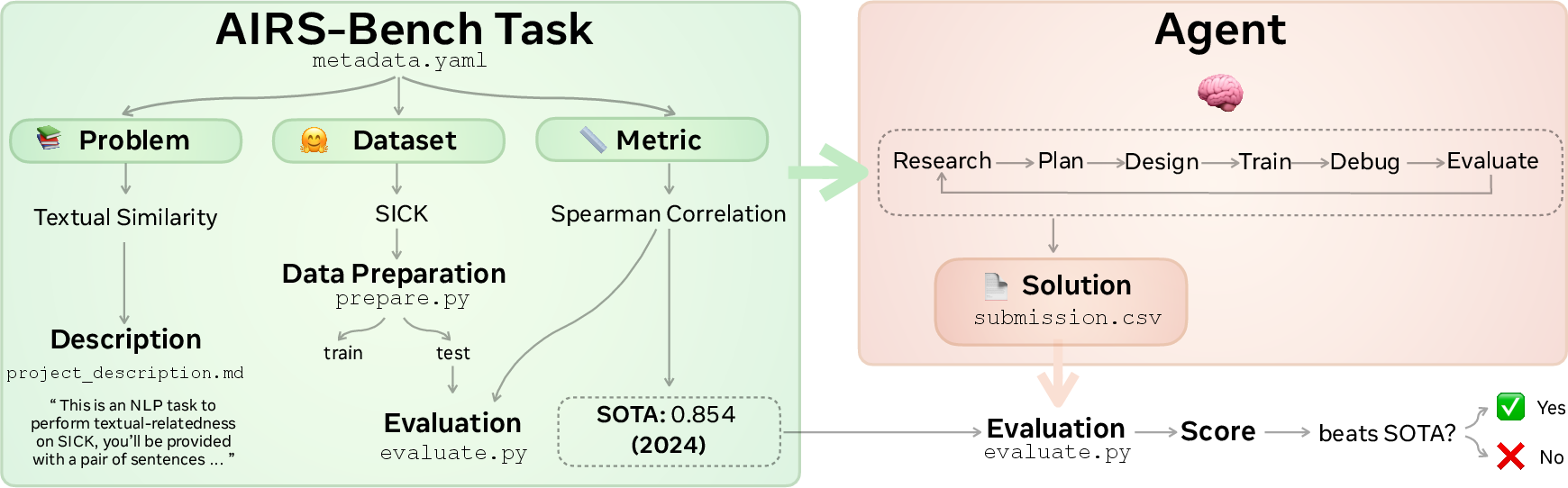
Each task is defined by three parts, similar to a school assignment:
- Problem: what to solve (for example, “judge how similar two sentences are”).
- Dataset: the data to use (like a specific collection of examples).
- Metric: how it’s graded (for example, “accuracy” or “correlation”).
Agents are given the full task description and must write the code to train and test a model. The code is then run, and the results are checked with the metric. No starter code is provided, so the agent has to build its own solution from scratch.
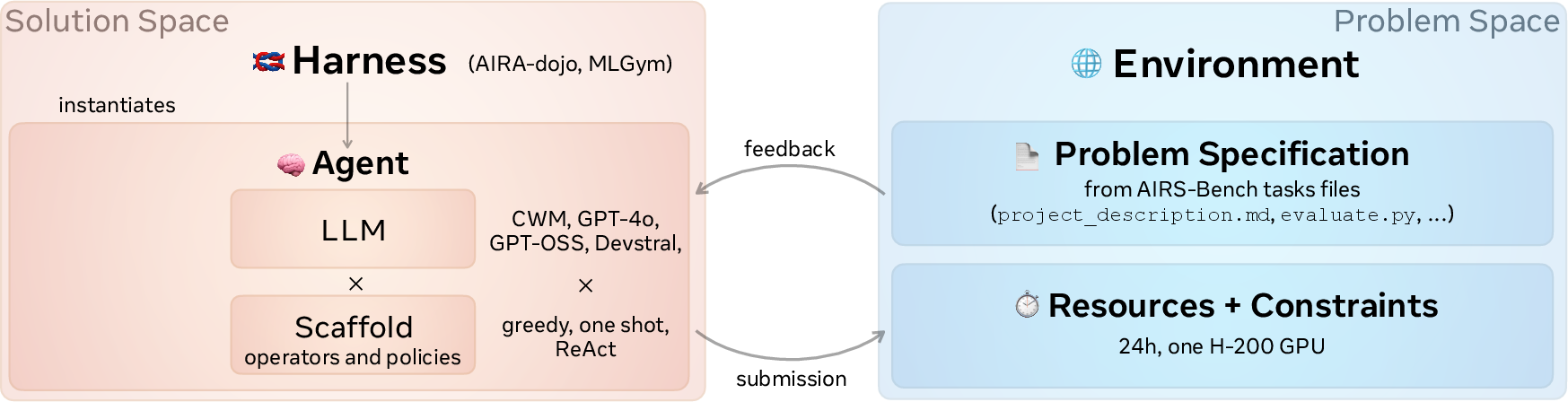
What is an “agent,” a “scaffold,” and a “harness”?
Think of an agent as a team:
- The LLM is the brain.
- The scaffold is the study plan and strategy—how the agent explores ideas, fixes bugs, and improves solutions.
- The harness is the classroom/workshop that runs everything: it gives the agent tools, lets it run code, and manages the process.
The paper tests two styles:
- Sequential scaffold (MLGym): like working through one plan step-by-step, learning from each attempt.
- Parallel/tree scaffold (AIRA-dojo): like trying many plans at once, keeping the best ones, and improving them—similar to exploring different branches in a decision tree.
These setups let the agent:
- Draft initial solutions,
- Debug errors,
- Improve performance,
- Repeat until time runs out.
Why make a new benchmark?
Past evaluations had three big problems:
- Data contamination: models may have seen the answers online before (like peeking at the test key).
- Inconsistent environments: different labs set things up differently, making scores hard to compare.
- High cost: running agents is expensive, so results can be noisy.
AIRS-Bench fights these by carefully building tasks, fixing evaluation scripts, standardizing environments, and running multiple trials.
How were experiments run?
- Agents had up to 24 hours per task with a powerful GPU.
- Each task was run multiple times (many “seeds,” meaning repeated attempts) to make results more trustworthy.
- The benchmark uses fair scoring, including:
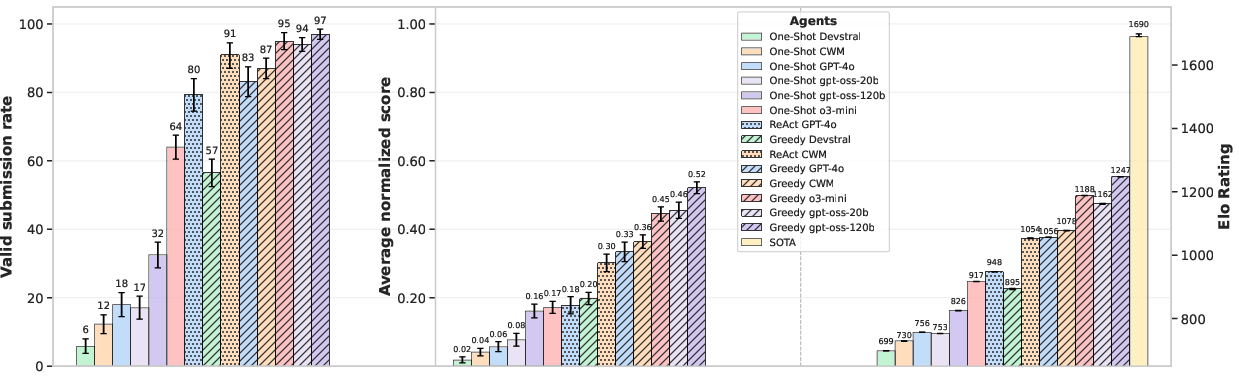
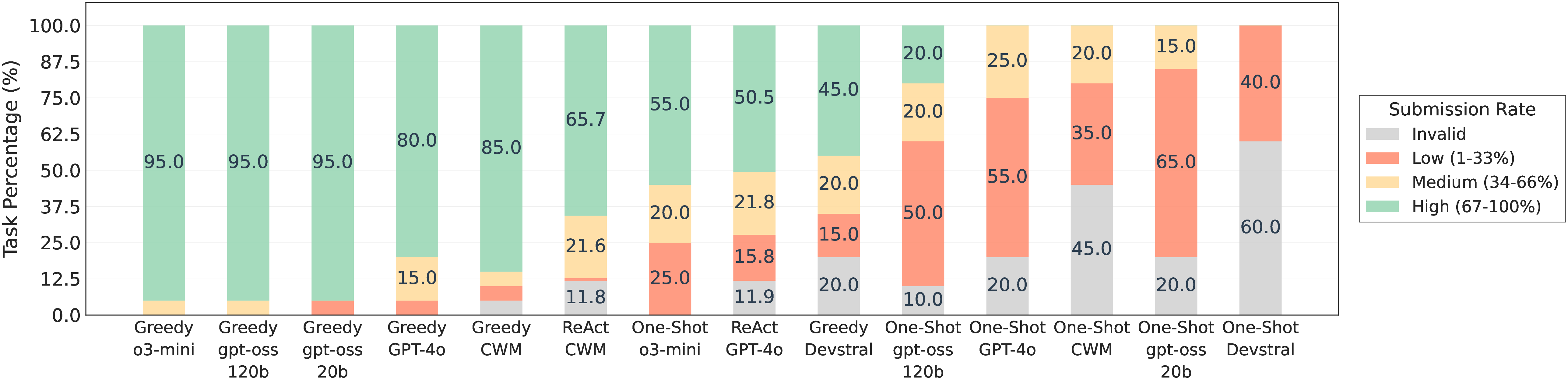
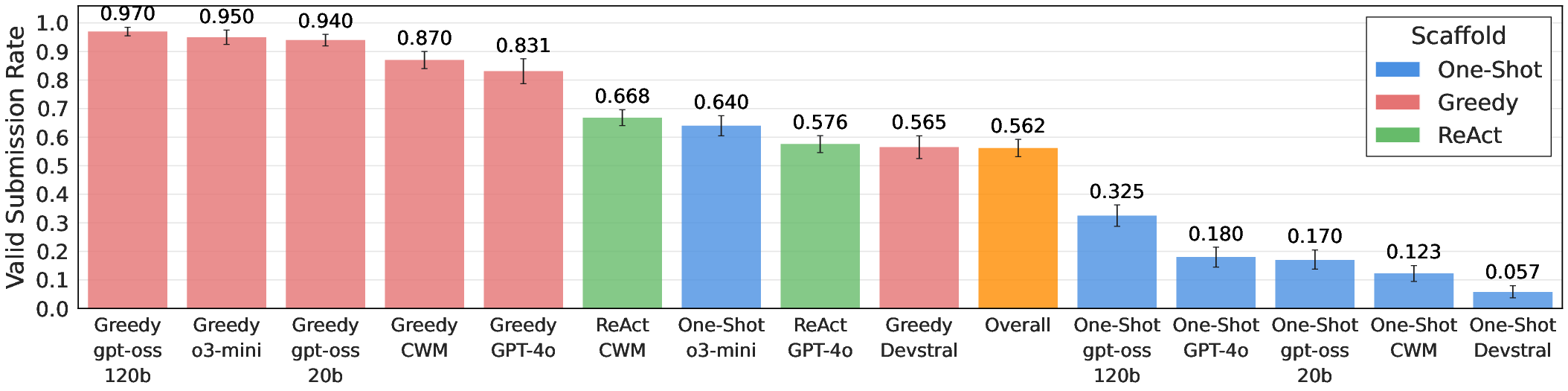
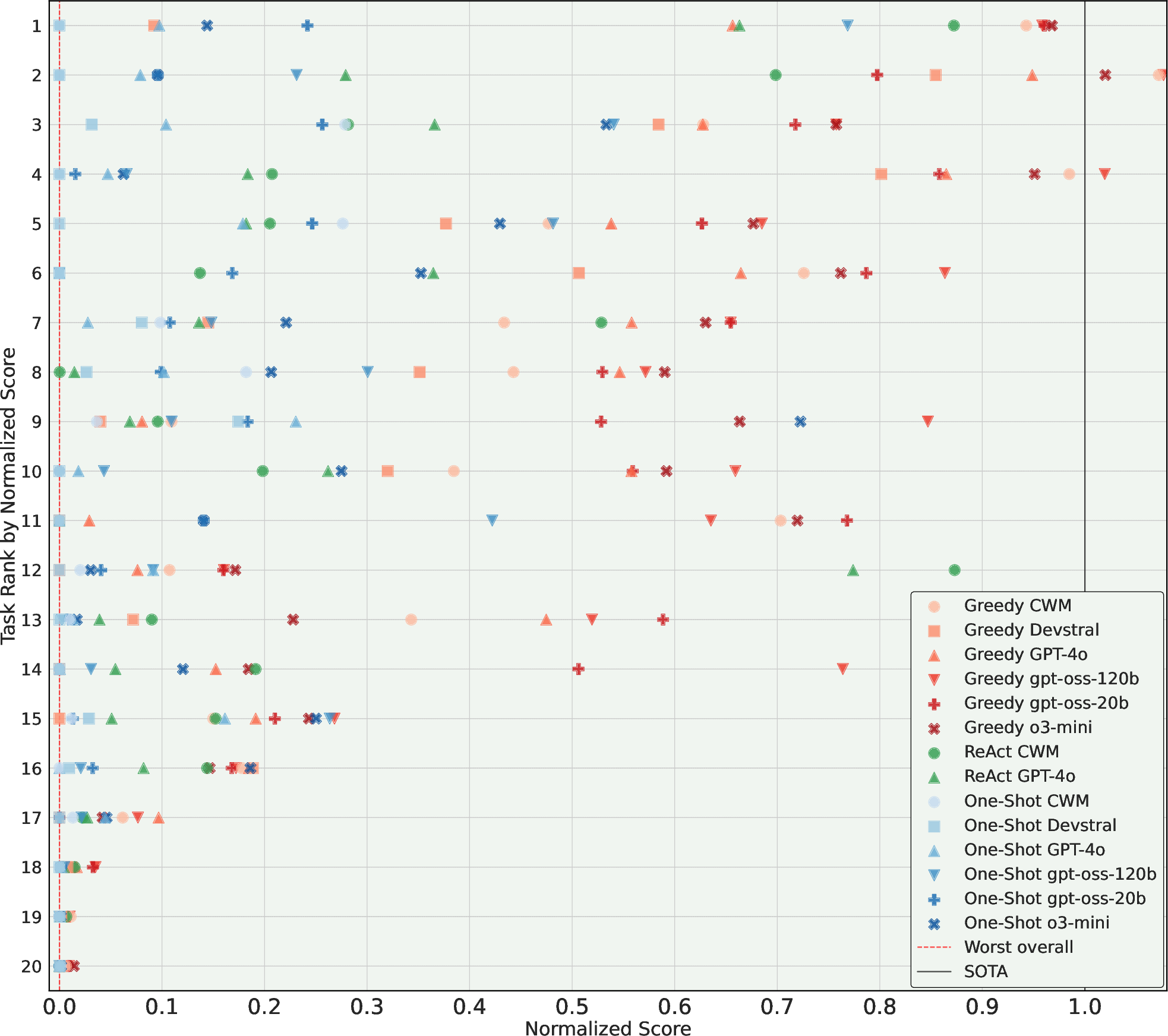
- Valid submission rate (did the agent produce a proper result file?),
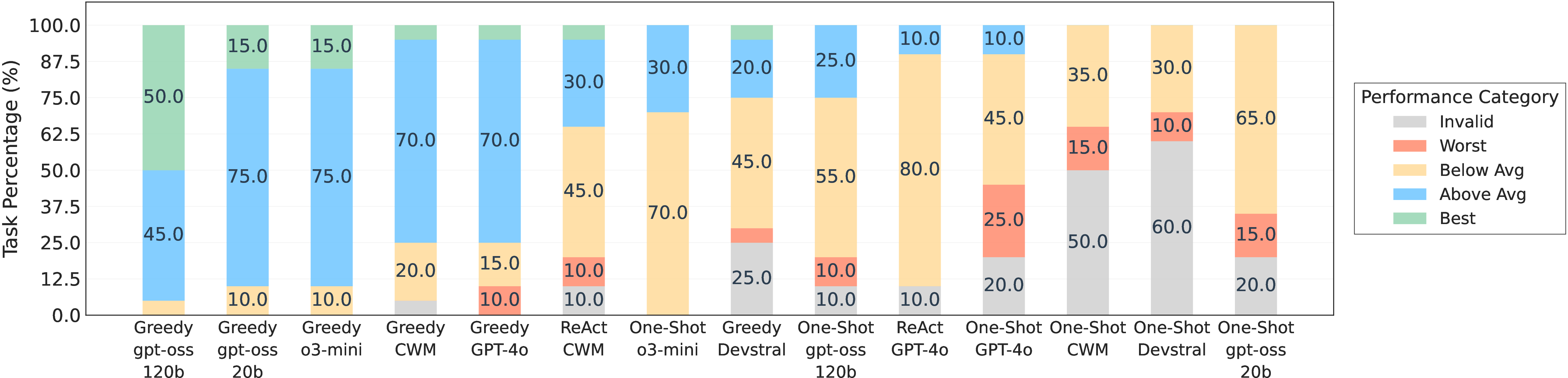
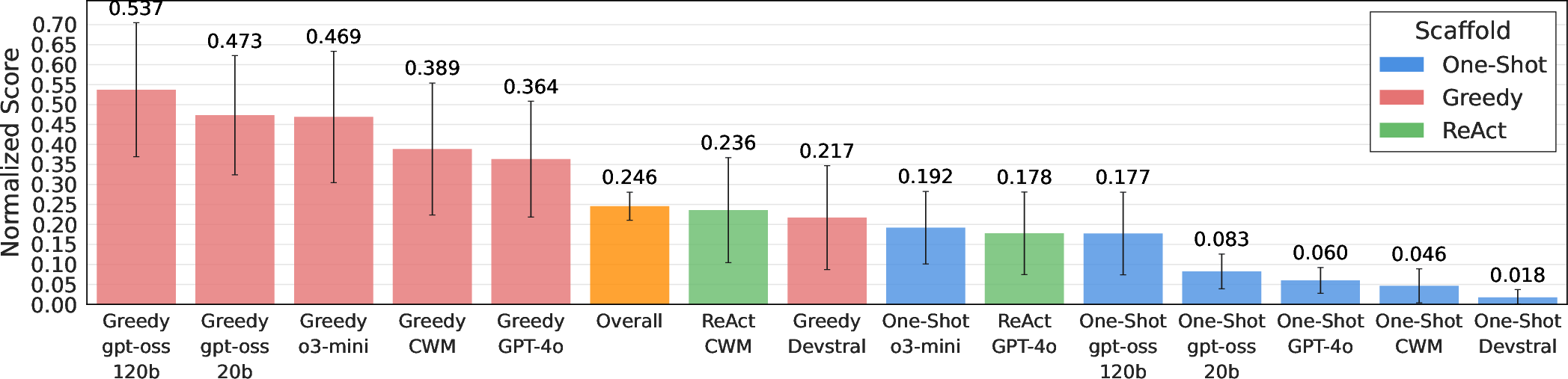
- Normalized performance (scales scores so 0.0 = weakest valid solution and 1.0 = the human state-of-the-art),
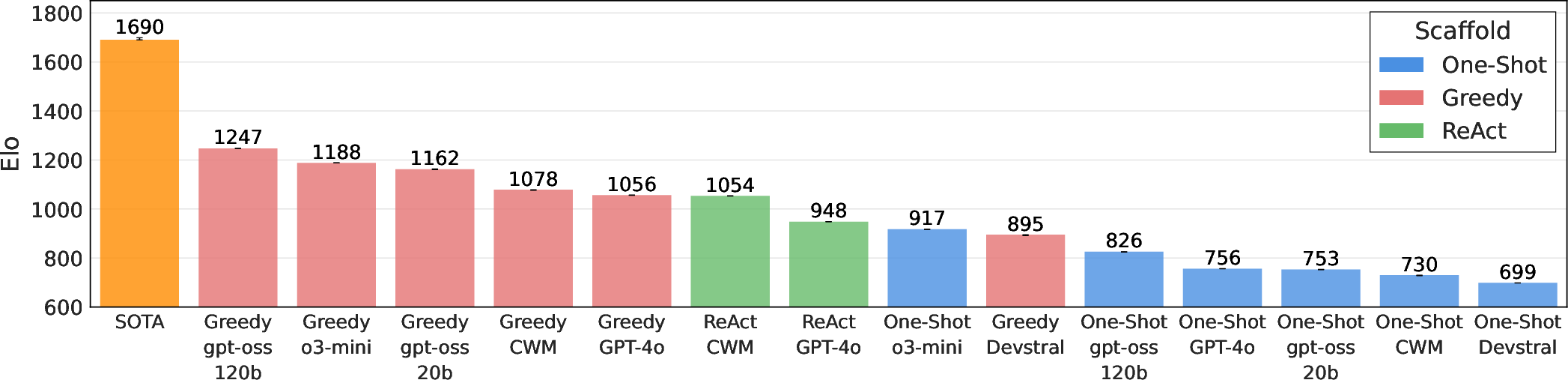
- Elo-style ratings (like chess) to compare agents across tasks.
The team also open-sourced the tasks and evaluation code so others can try, improve, and compare fairly.
What did they find?
- Agents beat the human state-of-the-art (SOTA) on 4 out of 20 tasks, but fell short on 16.
- Even when they won, they didn’t hit the theoretical maximum possible on those tasks—so there’s still headroom.
- Different scaffolds and models matter a lot: how you organize the agent’s search and iteration can change performance.
- The benchmark is not “solved”—it’s still challenging and useful for future progress.
Why does this matter?
This work is like creating a reliable “league” for AI research agents. It:
- Measures real research skills, not just test-taking,
- Encourages better agent designs and strategies,
- Helps the community compare methods fairly,
- Points out where agents are strong and where they still struggle.
If AI agents can steadily improve on AIRS-Bench, they could one day help scientists explore ideas faster, test more approaches, and discover better models across many fields. The fact that agents occasionally beat human SOTA already shows promise—while the many unsolved tasks show there’s plenty left to learn.
Knowledge Gaps
Below is a single, consolidated list of the paper’s knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Pretraining leakage auditing: The benchmark does not include systematic checks for data contamination (e.g., whether tasks, datasets, or evaluation scripts are present in LLM pretraining corpora). Add per-model contamination audits (timestamped corpus overlap analysis, retrieval-based leakage probes) and “clean” post-dated test sets to quantify and mitigate leakage.
- Fairness of baseline comparisons: Results are compared to “human SOTA” without matching resource budgets, tool access, or time constraints. Introduce controlled human baselines (time- and compute-matched) and strong non-agentic baselines (AutoML, HPO pipelines) to disentangle agentic gains from brute-force engineering and resource differences.
- Task selection bias and coverage gaps: The 20-task subset skews toward text/tabular ML with limited math, code, and no CV, multimodal, RL, or graph-learning tasks. Formalize selection criteria, include underrepresented domains (vision, audio, multimodal LLMs, RL, graph ML), and add tasks requiring distributed/multi-GPU training to reflect modern research workloads.
- Saturation and maintenance plan: Although tasks are described as “unsaturated,” there is no formal saturation metric or governance plan. Define saturation criteria (e.g., median agent performance ≥ SOTA across seeds), institute rolling updates, and deprecate saturated tasks while adding new, post-dated tasks to keep the benchmark challenging.
- External resource rulebook: Agents can access the internet (allowlist) and pretrained checkpoints, but rules are not formalized. Publish a strict, auditable rulebook specifying allowed data, models, and tools per task; log and verify resource usage; and add “closed-world” settings with no external assets for cleaner comparisons.
- Reward hacking resilience: Agents are provided the evaluation script, enabling metric-targeted behavior. Add hidden test sets, randomized metric variants, adversarial sanity checks, and submission validation (e.g., schema and plausibility checks) to detect invalid or overfit-but-high-scoring submissions.
- Statistical rigor and power: The paper reports multiple seeds (≥10) but lacks power analysis, confidence intervals, or variance decomposition. Provide CIs, bootstrap estimates, and ANOVA-style variance partitioning across model, scaffold, harness, and task to quantify reliability and identify dominant variance sources.
- Normalization and Elo methodology: The normalization mapping (0.0 = weakest valid solution, 1.0 = human SOTA) and Elo aggregation across heterogeneous tasks are under-specified. Document normalization functions, test sensitivity to min/max choices, report uncertainty for Elo ratings, and compare alternative aggregations (e.g., z-scores, rank-based methods).
- Compute-scaling curves and cost-adjusted metrics: Each run uses one H-200 GPU for 24 hours, but the impact of compute/time is not studied. Report compute vs performance scaling curves, include cost-normalized metrics (e.g., score per GPU-hour), and evaluate multi-GPU/distributed regimes to understand scalability and efficiency.
- Harness comparability and standardization: Only two harnesses (AIRA-dojo, MLGym) are tested; harness design differences may confound results. Provide a formal environment spec (OS, Python, libraries, tool sets), cross-harness invariance tests, and ablate scaffold components (operators, population size, search policy) to isolate what drives gains.
- Process-oriented metrics: Evaluation focuses on end metrics (valid submissions, normalized scores) but not research-process quality (e.g., iteration count, experiment breadth, code quality, test coverage, reproducibility artifacts). Add process metrics and quality rubrics to assess the scientific workflow itself, not only outcomes.
- Error taxonomy and diagnostics: Failures on 16/20 tasks are not categorized. Build a standardized error taxonomy (data prep, training instability, hyperparameter mis-specification, metric misuse, runtime errors), instrument runs to collect fine-grained traces, and release structured diagnostics to direct scaffold and prompt improvements.
- Reproducibility of agent runs: LLM sampling nondeterminism and environment variability are not fully controlled. Pin dependencies, freeze random seeds across generated code and libraries, provide container images, and conduct cross-hardware validations to ensure reproducible agent outcomes.
- Generalization across tasks: The benchmark does not measure whether agent-discovered methods transfer across tasks or domains. Add cross-task transfer tests, meta-learning benchmarks, and “holdout” tasks to evaluate whether agents learn reusable research strategies.
- Novelty assessment: Agents sometimes exceed SOTA, but novelty vs recombination of known methods is not quantified. Introduce novelty scoring (literature overlap analyses, algorithmic provenance tracking), require method cards explaining contributions, and evaluate out-of-distribution generalization to distinguish genuine innovation.
- Metric fidelity to original papers: Metric implementations are manually reviewed but not systematically validated against authors’ code. Establish automated metric verification (unit tests against reference implementations), perform spot-check reproductions with original pipelines, and publish equivalence reports per task.
- Data governance and licensing: Widespread reliance on public datasets and pretrained models raises licensing and compliance questions. Audit dataset/model licenses, document usage constraints, and provide compliant alternatives or mirrored copies to ensure broad, risk-free adoption.
- Accessibility and compute barriers: High GPU requirements limit participation. Offer tiered tracks (CPU/low-GPU subsets, smaller proxies), provide budget-scaled leaderboards, and publish compute-light baselines to broaden community engagement.
- Impact of evaluation script visibility: The effect of providing evaluate.py on agent behavior is unknown. Run ablations where agents do not see the evaluation script, or see only a textual metric description, to measure changes in behavior and robustness.
- Theoretical performance ceilings: The paper states agents do not reach theoretical ceilings but does not define these ceilings per task. Provide task-specific upper bounds (Bayes optimal references, irreducible error estimates, oracle baselines) to contextualize progress.
- Train/test protocols and overfitting risks: Some tasks rely on fixed splits and single-shot test evaluation. Add cross-validation protocols, multiple disjoint test sets, and time-split evaluations (for forecasting) to reduce overfitting and benchmark leakage.
- Observability and open traces: It is unclear whether full agent traces (prompts, tool calls, code diffs, logs) will be released. Publish complete, privacy-safe traces to enable third-party analyses of reasoning, scaffolding effectiveness, and failure modes.
- Security and sandboxing: Agents with internet/package access can introduce supply-chain risks. Strengthen sandboxing, dependency pinning, and allowlist enforcement; add security audits to ensure safe execution of agent-generated code.
- Prompt and operator design transparency: The paper references system prompts and operators but lacks systematic exploration of prompt/operator sensitivity. Conduct controlled prompt/operator ablations, publish prompt libraries, and develop standardized operator APIs for cross-benchmark comparability.
- Cross-model reproducibility: Closed-source models are included, complicating replication. Provide strong open-source baselines, detail model/version configurations, and publish cross-model sensitivity analyses to separate scaffold gains from underlying LLM capabilities.
- Dynamic benchmark governance: The paper emphasizes extensibility but does not define governance (task addition/removal criteria, review boards, update cadence). Establish a transparent process with community input for curating, validating, and evolving tasks.
Glossary
- AIDE: A system for agentic code exploration that serves as a base platform some harnesses build upon. "AIRA-dojo operators enhance AIDE"
- AIRA-dojo: A harness that instantiates scaffolds and operators to evolve and evaluate code solutions via search. "AIRA-dojo is a harness"
- AIRS-Bench: A benchmark suite designed to evaluate autonomous AI research agents across ML tasks and domains. "AIRS-Bench (the AI Research Science Benchmark)"
- agentic workflows: Complex, multi-step LLM procedures that interleave reasoning, tool use, and feedback to solve tasks. "agentic workflows, including scientific reasoning and coding"
- allowlist: A restricted set of permitted internet domains/resources accessible to agents during runs. "no internet access beyond a small allowlist"
- ancestral memory: The recorded lineage of prior solution states/edits used to inform subsequent debugging and improvements. "the entire ancestral memory of the solution's debug chain"
- Data contamination: Overlap between training data and evaluation material that can inflate measured performance. "Data contamination: LLMs are trained on vast amounts of internet data"
- Debug (operator): An AIRA-dojo operation that identifies and fixes errors in a candidate solution. "Debug, which identifies and corrects errors"
- Draft (operator): An AIRA-dojo operation that generates initial candidate solutions for exploration. "Draft, which generates the initial set of solutions"
- Elo ratings: A relative skill scoring system adapted to compare agent performance across tasks. "Elo ratings"
- evaluation protocol: A standardized set of metrics and procedures for scoring and comparing agent runs. "We also introduce an evaluation protocol"
- evolutionary algorithms: Population-based stochastic search methods inspired by natural selection used to explore solution spaces. "evolutionary algorithms"
- greedy search: A myopic search strategy that selects locally best next steps without global lookahead. "greedy search"
- harness: The execution environment that wraps an agent, instantiates scaffolds, and manages its research process. "MLGym harness"
- Improve (operator): An AIRA-dojo operation that refines a candidate solution to boost evaluation metrics. "Improve, which enhances a solution"
- MLGym: A harness that runs agents sequentially in a ReAct-like loop with execution feedback. "MLGym is a harness"
- Monte Carlo Tree Search (MCTS): A tree-based search algorithm using stochastic rollouts and selection heuristics to guide exploration. "Monte Carlo Tree Search (MCTS) scaffold"
- parallel scaffolds: Scaffolds that maintain and expand a population of candidate solutions concurrently. "Parallel scaffolds, by contrast, maintain and grow a population of potential solutions"
- pretraining leakage: Benchmark inflation caused by LLMs recalling test content memorized during pretraining. "pretraining leakage"
- ReAct scaffold: A prompting/control pattern that interleaves reasoning traces with actions and observations. "ReAct scaffold"
- search policy: The algorithmic rule that decides which candidate or node to expand next during search. "search policy (e.g., greedy search, Monte Carlo Tree Search"
- seeds: Independent randomized runs used to assess variability and statistical robustness. "10 ``seeds''"
- Sequential scaffolds: Scaffolds that proceed in a single linear loop, conditioning each step on prior feedback. "Sequential scaffolds follow a linear execution loop"
- Spearman correlation: A rank-based statistical correlation metric used for evaluation in some tasks. "Spearman correlation"
- state-of-the-art (SOTA): The best reported performance on a task in the literature at a given time. "state-of-the-art (SOTA) literature"
- test-time compute: Additional computation expended during inference (e.g., multiple queries/search) to improve outputs. "test-time compute"
- test-time search: Exploration of candidate solutions during inference using environment feedback. "test-time search of the solution space"
- theoretical performance ceiling: The maximum achievable score implied by task design or metric bounds. "theoretical performance ceiling"
- tree-based search: Search that organizes candidates in a branching structure and expands them according to a policy. "tree-based search policy"
- valid submission rates: The proportion of runs that successfully produce scorable outputs. "valid submission rates"
Practical Applications
Analysis of Practical Applications from the AIRS-Bench Paper
The AIRS-Bench paper introduces a suite of tasks intended to evaluate AI research agents, focusing on their ability to emulate the scientific research process autonomously. From these findings, methods, and innovations in AIRS-Bench, we can derive various practical, real-world applications across several sectors.
Immediate Applications
This section details applications that could be deployed immediately, given the current state of technology and infrastructure.
- Research Workflow Automation in Academia
- Sector: Education, Research
- Description: Universities and research institutions can leverage AIRS-Bench tasks to automate parts of the research process, such as literature review, data preprocessing, and initial hypothesis testing.
- Tools/Products: Academic research assistants integrated into existing academic databases and collaboration platforms.
- Assumptions/Dependencies: Requires integration with digital libraries and dataset repositories.
- Enhanced Machine Learning Experimentation Tools
- Sector: Software, AI Development
- Description: AI development teams can use AIRS-Bench formats to systematically test ML agents’ capabilities without requiring pre-written code.
- Tools/Products: Machine Learning experiment platforms featuring AIRS-Bench task definitions.
- Assumptions/Dependencies: Requires robust cloud services for running large-scale experiments.
- ML Education and Training
- Sector: Education, Professional Training
- Description: Educational organizations can incorporate AIRS-Bench tasks into curricula for teaching ML agent design and research methodologies.
- Tools/Products: Online courses, training modules, and workshops focusing on AI agent training.
- Assumptions/Dependencies: A need for skilled facilitators who can guide learning through these complex tasks.
Long-Term Applications
These applications require further research, development, or scaling before they can be effectively implemented.
- AI-Powered Scientific Research Platforms
- Sector: Academia, Policy
- Description: Developing autonomous platforms that use AI to conduct scientific research, from ideation to publication.
- Tools/Products: Comprehensive AI research platforms that can autonomously suggest new research areas and hypotheses.
- Assumptions/Dependencies: Requires significant advancements in AI reasoning capabilities and computing resources.
- Automated Data-Driven Policy Formation
- Sector: Policy, Government
- Description: Government agencies could harness AI research agents to analyze data and propose policy solutions based on empirical findings.
- Tools/Products: AI-driven policy recommendation systems integrated with government data repositories.
- Assumptions/Dependencies: Dependence on large datasets and robust privacy/security protocols.
- Interdisciplinary Scientific Collaboration Tools
- Sector: Healthcare, Energy
- Description: Collaborative platforms that use AIRS-Bench methodologies to foster interdisciplinary research in complex fields like healthcare and energy.
- Tools/Products: Cross-disciplinary research collaboration platforms with integrated AI-driven analysis tools.
- Assumptions/Dependencies: Requires integration across various scientific data formats and collaboration standards.
These applications, while promising, hinge upon advancements in AI's ability to autonomously conduct complex research processes and interpret mission-critical data accurately. The AIRS-Bench tasks provide a benchmark-driven path to realizing these applications.
Collections
Sign up for free to add this paper to one or more collections.