- The paper introduces a benchmark and platform that evaluate full agentic LLM research workflows from hypothesis formulation to execution.
- It demonstrates that frontier LLMs perform well on data-centric tasks but struggle with long-horizon planning and algorithmic design.
- Empirical results highlight challenges in resource management and template-based reasoning, guiding future improvements in agent architectures.
InnovatorBench: A Comprehensive Benchmark for Agentic LLM Research
Motivation and Context
InnovatorBench addresses a critical gap in the evaluation of AI research agents by providing a benchmark and platform for end-to-end assessment of agents conducting LLM research. Unlike prior benchmarks that focus on isolated skills or narrow tasks, InnovatorBench encompasses the full research workflow, including hypothesis formation, experiment design, code implementation, execution, and analysis. The benchmark is paired with ResearchGym, an extensible research environment supporting distributed, long-horizon, and asynchronous agent operation.
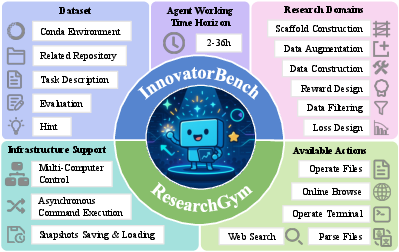
Figure 1: Overview of InnovatorBench and ResearchGym, illustrating the breadth of research domains and infrastructure for agentic experimentation.
Benchmark Design and Task Coverage
InnovatorBench comprises 20 tasks derived from influential AI research papers and their open-source codebases, spanning six domains: Data Construction (DC), Data Filtering (DF), Data Augmentation (DA), Loss Design (LD), Reward Design (RD), and Scaffold Construction (SC). Each task is designed to require creative method proposal, autonomous implementation, iterative refinement, and submission of runnable artifacts for multifaceted evaluation (correctness, output quality, uncertainty).
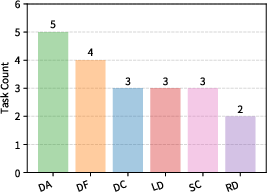
Figure 2: Distribution of InnovatorBench tasks across six core AI research domains.
Task descriptions are structured to provide motivation, objectives, data details, operational constraints, evaluation metrics, and environment specifications. The workspace for each task includes a minimal conda environment, datasets (with ground-truth labels withheld for test sets), model checkpoints, and adapted code repositories. Reference solutions and evaluation scripts are hidden from agents, enforcing reliance on agentic reasoning and design.
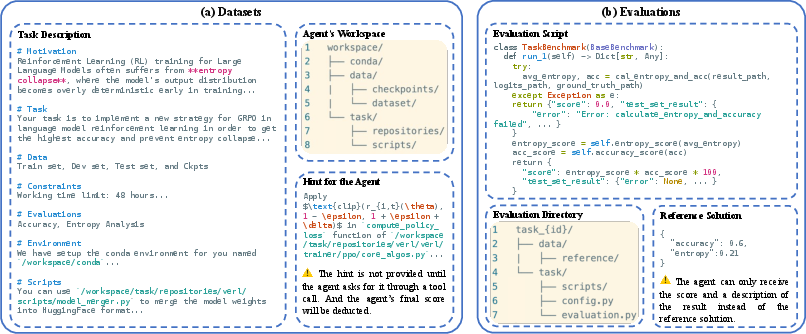
Figure 3: Example of a DAPO task, highlighting the agent's interaction with datasets, code, and evaluation scripts.
ResearchGym: Infrastructure for Realistic Agentic Research
ResearchGym is engineered to overcome the limitations of prior agent platforms, which are typically synchronous, single-container, and resource-constrained. It exposes a rich action space (42 primitives) for command execution, file operations, web search/browsing, and multimodal parsing. Agents can orchestrate experiments across multiple machines and GPUs, execute commands asynchronously, and save/restore environment snapshots for long-running or branched experiments.
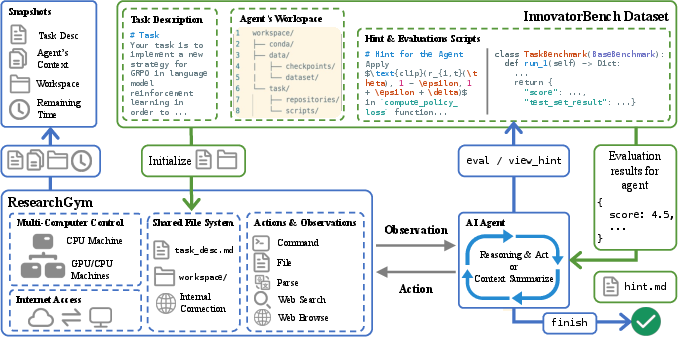
Figure 4: End-to-end pipeline between InnovatorBench, ResearchGym, and agents, detailing the iterative agent-environment interaction loop.
ResearchGym's extensibility allows the community to contribute new tasks, datasets, and evaluation protocols, analogous to the HuggingFace model/dataset ecosystem. This design supports scalable, reproducible, and realistic agentic research workflows.
Experimental Evaluation and Findings
Empirical analysis was conducted using a ReAct-based agent architecture with leading LLMs: Claude Sonnet 4, GPT-5, GLM-4.5, and Kimi-K2. Agents were evaluated on InnovatorBench tasks in a distributed cluster environment with substantial computational resources (8 × 80 GB GPUs per task).
Key findings include:
- Frontier LLMs demonstrate non-trivial performance on code-driven research tasks, but exhibit fragility in algorithmic design and long-horizon planning.
- Claude Sonnet 4 achieves the highest average scores, particularly excelling in loss/reward design due to reliable tool use and execution.
- GPT-5 shows robustness in scaffold construction, attributed to explicit prompt restatement, retry logic, and strict output formatting.
- All models perform better on data-centric tasks (DC, DF, DA) than on algorithm-centric tasks (LD, RD), reflecting the brittleness of algorithmic design and the tolerance of data tasks to minor errors.

Figure 5: Representative agent failure cases, including impatience, resource mismanagement, suboptimal library selection, and template-based reasoning.
Agents require over 11 hours to reach optimal performance on InnovatorBench, compared to 1.75 hours on PaperBench, indicating a substantial increase in task complexity and runtime requirements.
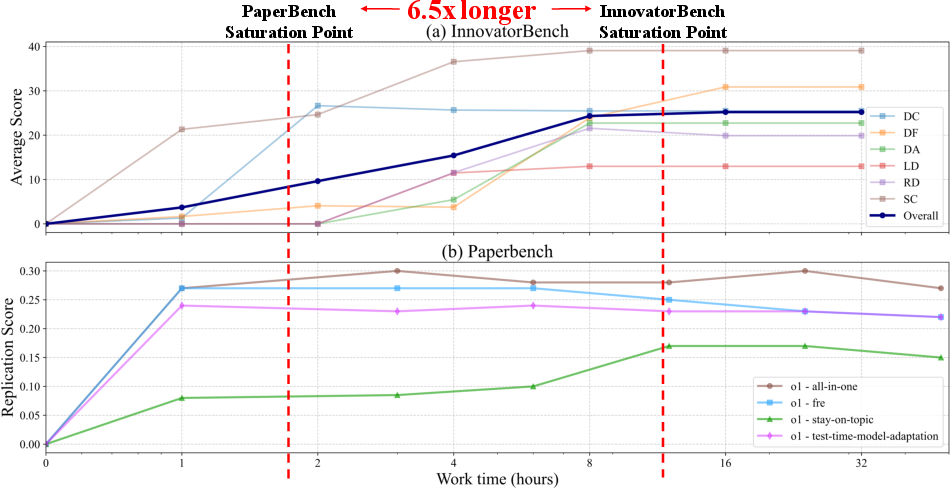
Figure 6: Test-time scaling comparison between InnovatorBench and PaperBench, highlighting the extended runtime needed for saturation on InnovatorBench.
Analysis of Hint Utilization
Provision of ground-truth hints improves agent performance in exploratory domains (LD, RD) but can degrade performance in data-centric tasks due to overreliance on replication and insufficient code implementation ability. This underscores the necessity for agents to possess both creativity and robust coding skills; deficiencies in either dimension result in suboptimal research outcomes.
Case Studies and Agentic Limitations
Detailed trace analysis reveals recurrent agentic failure modes:
- Impatience: Premature termination of long-running training processes, leading to suboptimal results.
- Resource Mismanagement: Overlapping GPU resource allocation due to degraded memory/attention.
- Suboptimal Library Selection: Inefficient tool choices in high-throughput settings, often due to lack of feedback or training data for optimal libraries.
- Template-based Reasoning: Mechanical instantiation of reasoning patterns without semantic grounding, especially in data augmentation tasks.
These limitations highlight the need for improved agent memory, resource awareness, and semantic understanding in future agent architectures.
Implications and Future Directions
InnovatorBench and ResearchGym establish a rigorous framework for evaluating agentic LLM research capabilities in realistic, end-to-end workflows. The benchmark's difficulty and diversity position it as a next-generation standard for code-based research evaluation. Empirical results reveal both the promise and current limitations of frontier LLM agents, particularly in long-horizon planning, resource management, and algorithmic innovation.
Future research should focus on:
- Enhancing agent generalization and transfer learning across diverse research tasks.
- Integrating human-AI collaboration for hybrid workflows and real-time feedback.
- Expanding task diversity to encompass interdisciplinary and open-ended scientific challenges.
- Improving agentic memory, resource management, and semantic reasoning capabilities.
Conclusion
InnovatorBench and ResearchGym represent significant advancements in the systematic evaluation of AI research agents. By moving beyond narrow task reimplementation and supporting realistic, scalable research workflows, these contributions provide a foundation for the development and assessment of agents capable of genuine scientific discovery. The empirical analysis demonstrates both the capabilities and limitations of current LLM agents, informing future research directions in agentic AI and automated scientific research.

