- The paper introduces SGI-Bench, a benchmark using a four-stage pipeline (Deliberation, Conception, Action, Perception) to evaluate scientific general intelligence across ten domains.
- The paper reveals that current LLMs achieve modest step-level accuracy yet struggle with complete multi-hop reasoning, actionable idea generation, and experimental protocol planning.
- The paper demonstrates that test-time reinforcement learning (TTRL) can enhance idea novelty and specificity, though significant gaps remain in integrated scientific reasoning.
Probing Scientific General Intelligence in LLMs: SGI-Bench and Its Comprehensive Evaluation of Scientist-Aligned Workflows
Introduction and Operationalization of SGI
The presented work introduces a formal and operational definition of “Scientific General Intelligence” (SGI): the capacity of an AI system to autonomously perform the complete, iterative cycle of scientific inquiry at the proficiency level of a human scientist. This motivates the design and implementation of SGI-Bench, a comprehensive benchmark that measures LLMs and agentic systems across this entire spectrum. The framework employs the Practical Inquiry Model (PIM), segmenting scientific cognition into four core quadrants—Deliberation (evidence retrieval and synthesis), Conception (ideation and methodological planning), Action (experimental execution), and Perception (data interpretation and reasoning)—and aligning benchmark tasks with these stages to authentically reenact scientist workflows.
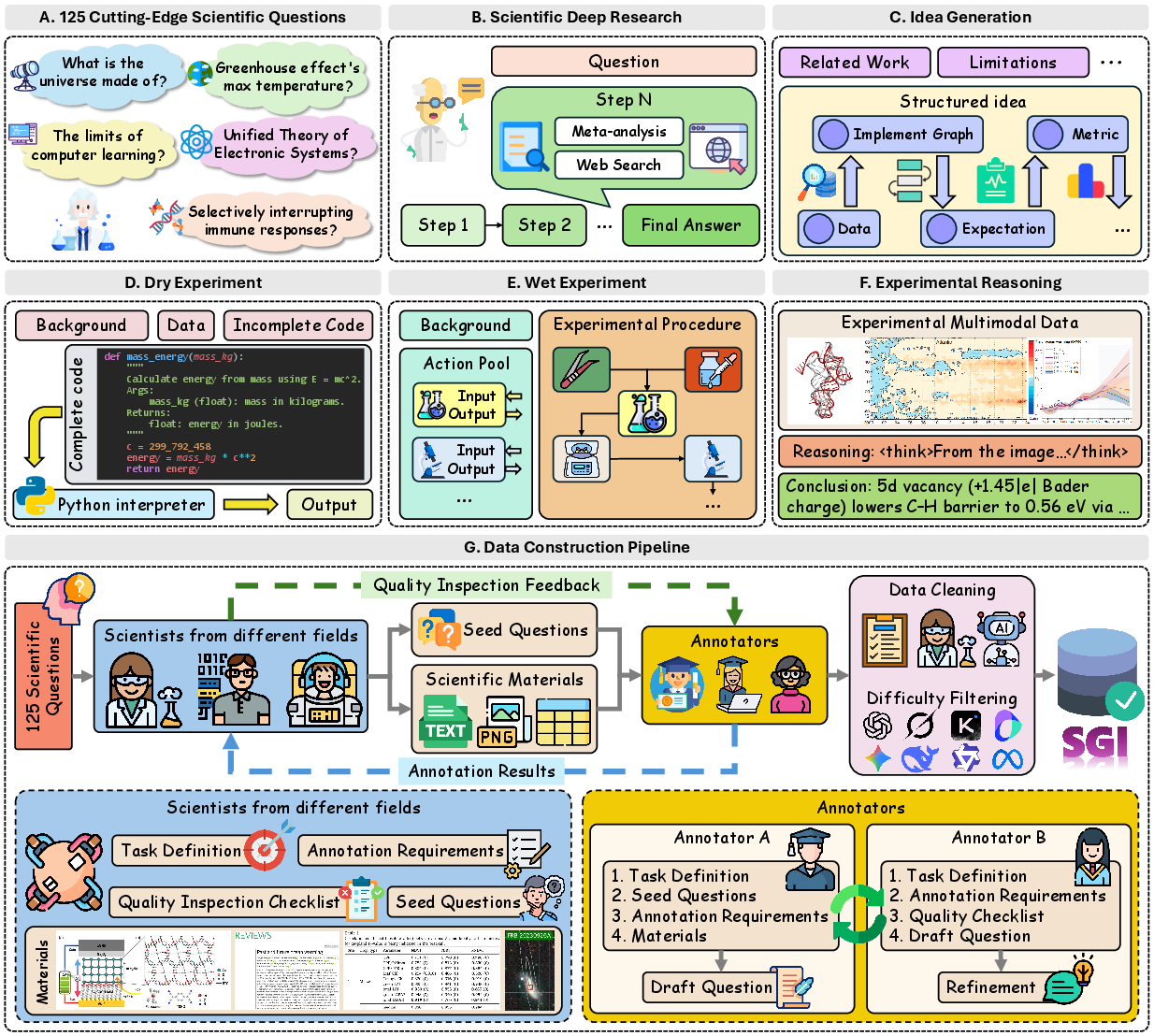
Figure 1: SGI-Bench Workflow Pipeline: the end-to-end four-stage framework (Deliberation, Conception, Action, Perception) operationalizes scientific discovery, mapping tasks to capabilities and task-level evaluation to scientist practice.
SGI-Bench distills these principles into four task categories:
- Scientific Deep Research (Deliberation): evaluates multi-hop reasoning, quantitative synthesis, and meta-analytic integration.
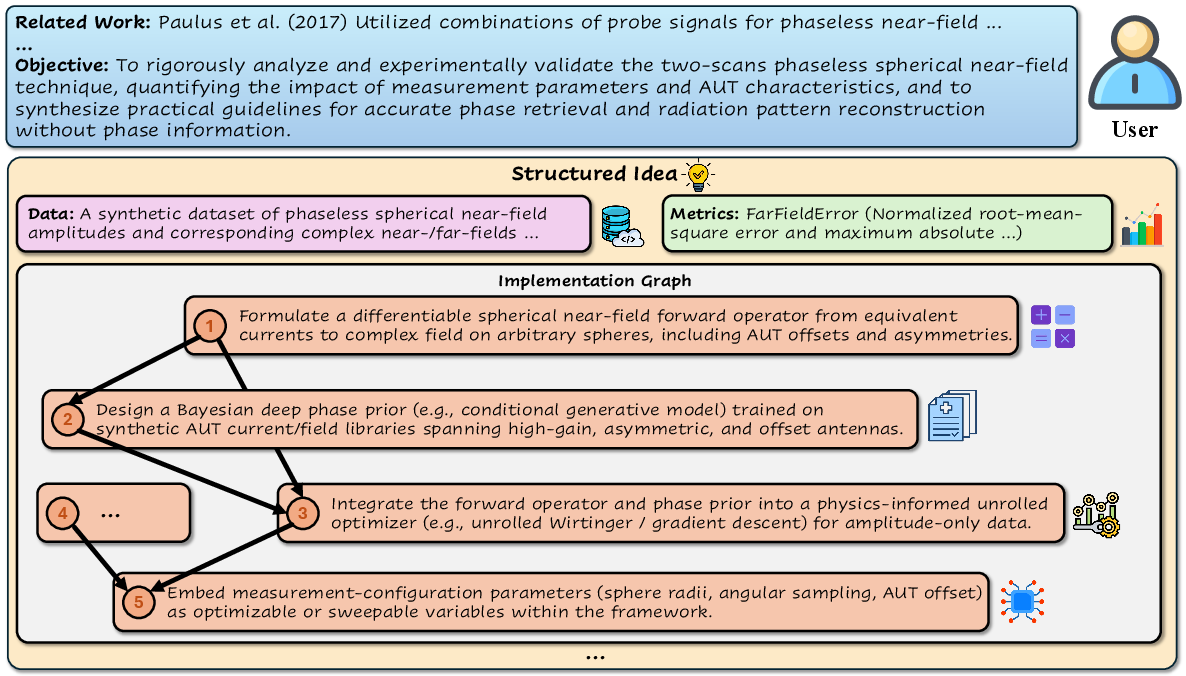
- Idea Generation (Conception): assesses creativity, novelty, feasibility, and rigorous methodological planning.
- Dry & Wet Experiments (Action): probes computational/code reasoning (dry) and procedural protocol planning (wet) under laboratory constraints.
- Experimental Reasoning (Perception): measures data interpretation, hypothesis testing, multi-modal and comparative reasoning.
Dataset and Construction Methodology
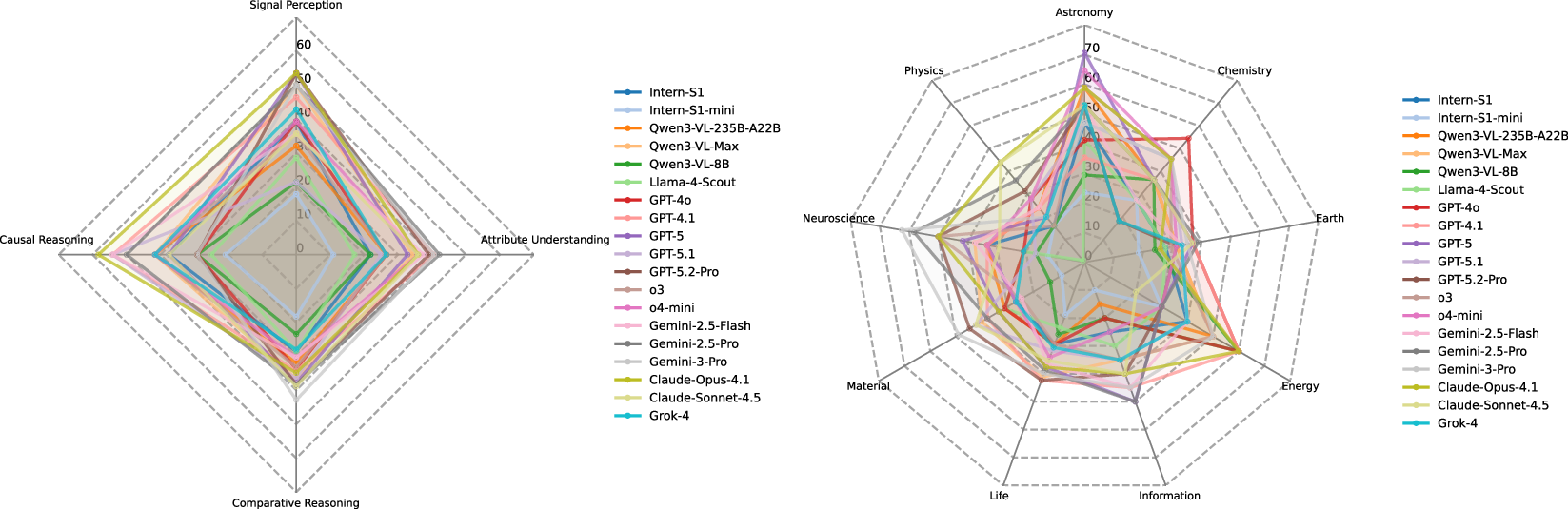
SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples, covering ten foundational domains (astronomy, chemistry, earth science, energy, information science, life science, materials science, neuroscience, physics, mathematics), with rigorous annotation and validation workflows, and a multi-layered scientist-in-the-loop quality control pipeline. Tasks are derived from “125 Big Questions” and leading scientific literature, ensuring both disciplinary breadth and challenging depth.
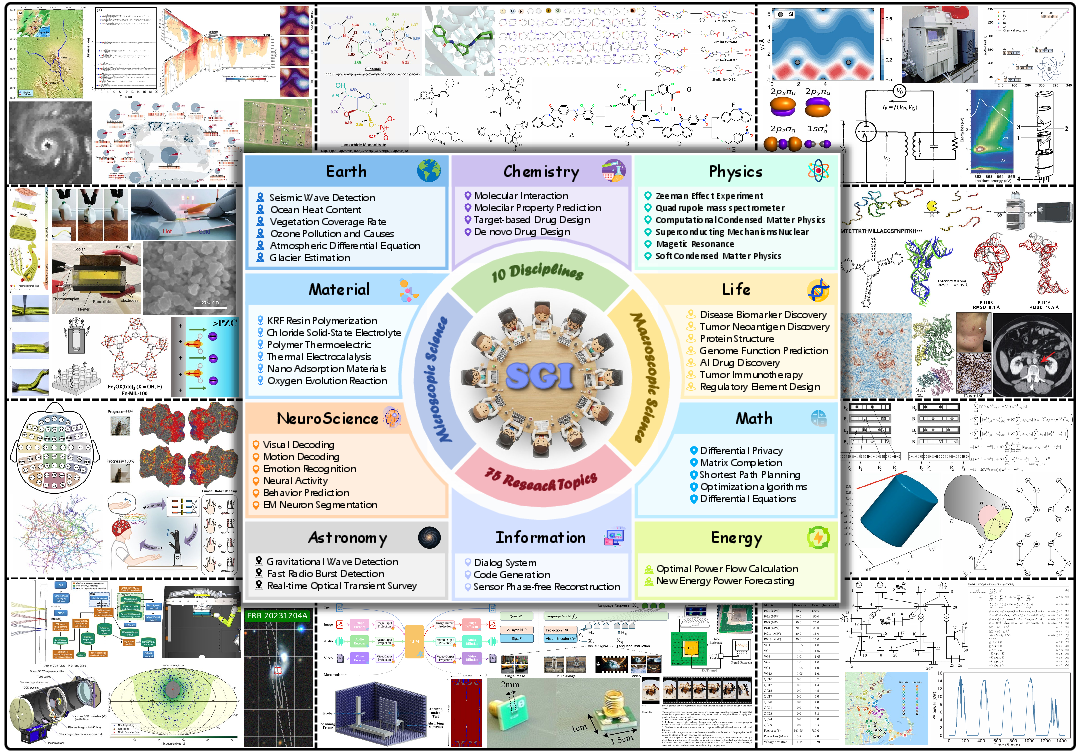
Figure 3: Overview of 10 scientific domains covered by SGI-Bench, ensuring cross-disciplinary evaluation of scientific intelligence.
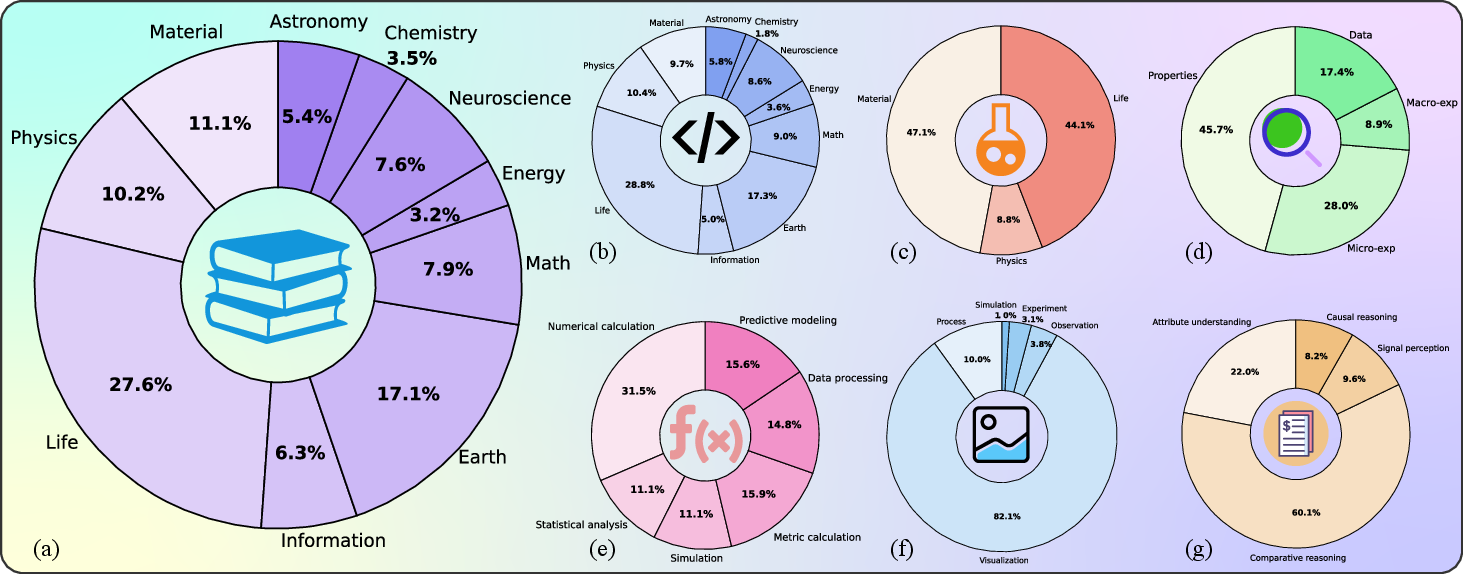
Figure 5: Data distributions reveal task, discipline, modality, and reasoning-type coverage, supporting granular analysis of model weaknesses across scientific domains and experimental paradigms.
Multi-Dimensional, Scientist-Aligned Evaluation Metrics
Each task within SGI-Bench employs bespoke, multi-dimensional metrics precisely aligned with scientific practice:
- Deep Research: uses both Exact Match (EM) for final answer correctness and Step-Level Accuracy (SLA) for multi-step reasoning fidelity.
- Idea Generation: combines subjective LLM-judge pairwise win rates with objective, automated measures for effectiveness, novelty (retrieval-based dissimilarity), detailedness (content completeness, redundancy penalty), and feasibility (structural graph similarity against domain expert templates).
- Dry Experiments: enforces code executability and correctness via PassAll@k unit tests, complemented by smooth execution and runtime efficiency metrics.
- Wet Experiments: assesses action sequence similarity (order preservation) and parameter accuracy versus protocol ground-truths.
- Experimental Reasoning: uses Multi-Choice Accuracy and fine-grained Reasoning Validity, judged via rubric-guided LLM evaluation.
The evaluation framework is agentic, leveraging specialized tools (retrieval, code execution, document parsing) and supporting both standardized and user-customized scientific rubrics.
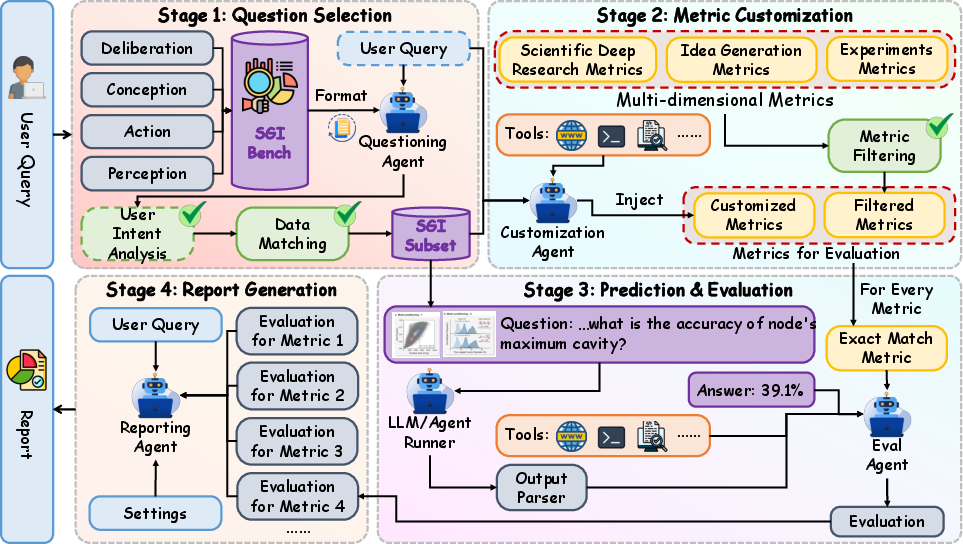
Figure 7: The agentic evaluation framework orchestrates tool-based inference, metric computation, and automated report generation within a transparent, scalable pipeline.
Empirical Results and Analysis
SGI-Bench’s systematic evaluation of over 30 state-of-the-art LLMs and agent systems reveals convergent weaknesses and the fragmented state of scientific cognition in current models.
Scientific Deep Research
- Final-answer EM is uniformly low (10–20% max), reflecting the difficulty of multi-source quantitative synthesis.
- Step-level alignment (SLA) is consistently higher than EM, suggesting that LLMs/agents perform plausible partial reasoning but often fail at global coherence or numerical integration, especially in data/property-centric tasks.
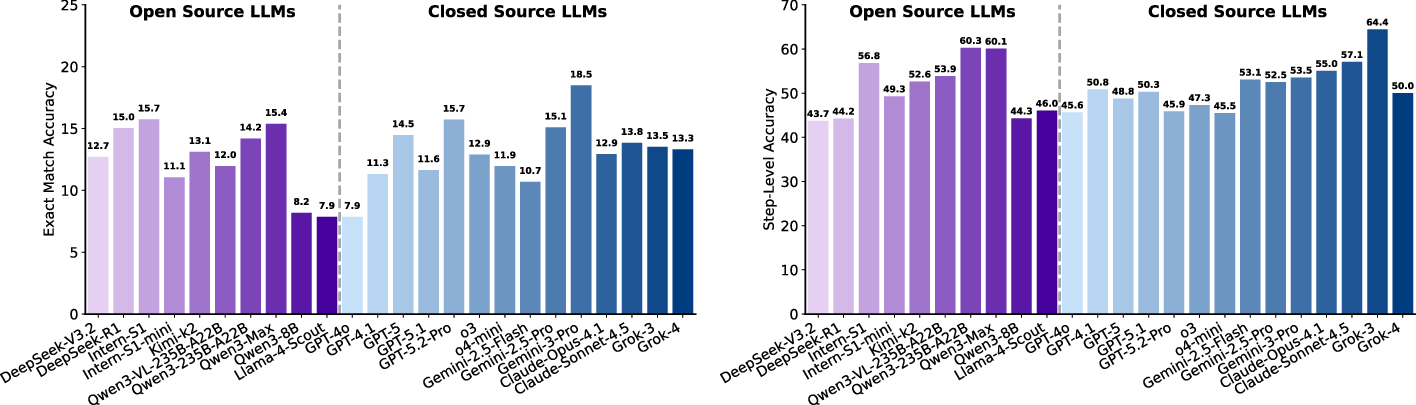
Figure 9: LLMs exhibit poor Exact Match but moderately higher SLA, confirming brittle end-to-end analytical completeness in scientific deep research.
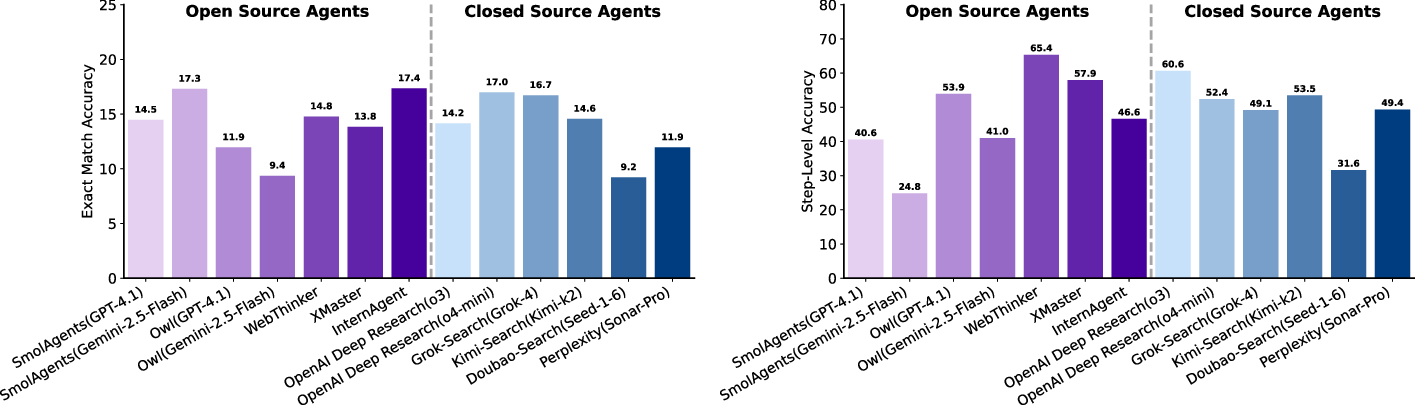
Figure 11: Multi-agent systems (tool-augmented) show only marginal gains over strong LLMs, with performance ultimately bottlenecked by retrieval and evidence synthesis.
Idea Generation
Dry & Wet Experiments
- Dry (computational) experiments expose a critical gap: code executability rates are high, but scientific correctness (PassAll@5) remains low (~20–36%). Models struggle with numerically sensitive tasks (integration, simulation) and scientific algorithm selection.
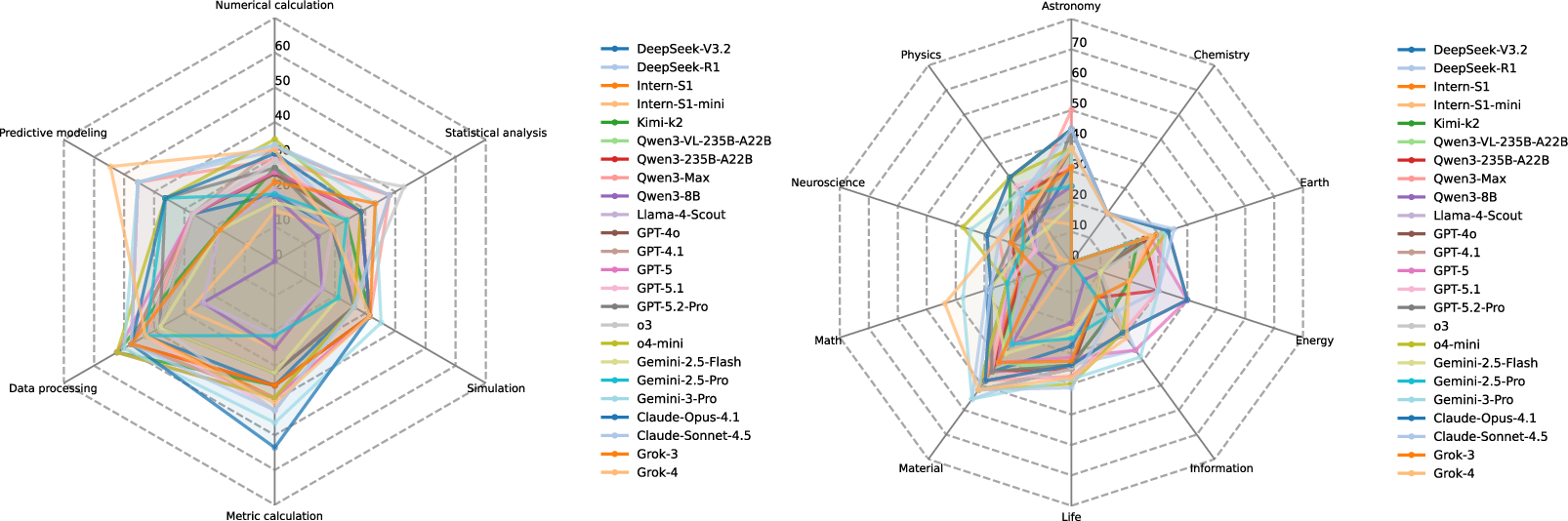
Figure 4: PassAll@5 accuracy is lowest on numerical calculation and simulation function categories, revealing an intrinsic bottleneck in scientific computational reasoning.
- Wet lab protocol planning is extremely brittle: models rarely produce correct step sequences and often mis-specify parameters and branching logic, especially on temporally coordinated, multi-sample workflows.
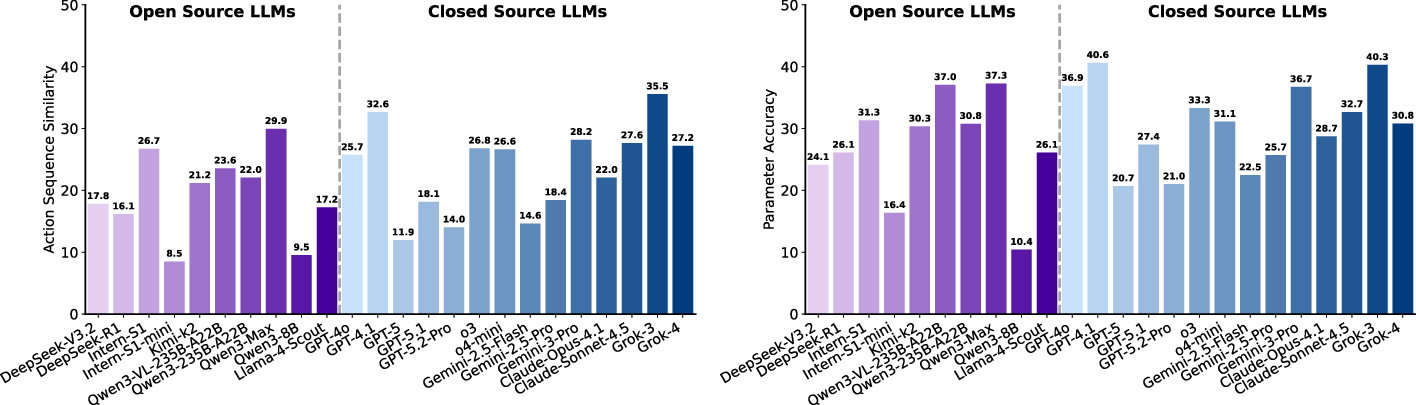
Figure 6: Sequence similarity and parameter accuracy are uniformly low across LLMs, reflecting persistent difficulties in real-world protocol synthesis.
Experimental Reasoning
Test-Time Adaptation and Dynamic Capacity
The study introduces Test-Time Reinforcement Learning (TTRL) to address open-ended ideation where no gold-standard label exists. By using retrieval-based novelty rewards at inference, models (e.g., Qwen3-8B) self-improve their idea novelty from 49.36 to 62.06 absent ground-truth, with qualitative gains in technical specificity and architectural detail.
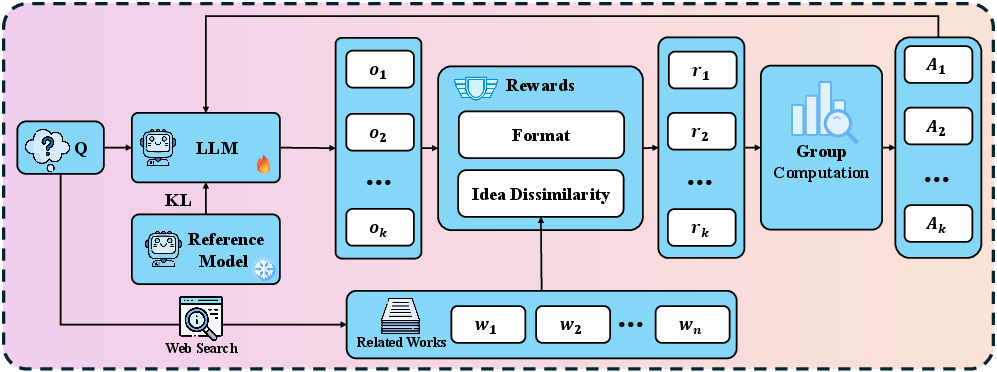
Figure 8: TTRL framework enables retrieval-driven, reward-based self-improvement of hypothesis novelty at test time.
Limitations and Future Directions
SGI-Bench exposes core limitations: LLMs and agentic systems represent local fragments of scientific cognition, lacking integrated long-horizon reasoning, numerically robust computation, planning-aware feasible ideation, and multi-modal comparative analysis. The study identifies several pathways to SGI advances:
- Retrieval-augmented meta-analysis and robust reasoning under evidential uncertainty.
- Structured planning and reward shaping for feasibly grounded idea generation.
- Domain-aware code synthesis with numerical and algorithmic priors.
- Explicit training for temporal, branched, and parameterized protocol construction.
- Cross-modal alignment, multimodal curricula, and contrastive reasoning for comparative tasks.
- Test-time RL with multi-objective scientific rewards, beyond novelty.
- Efficient, reliable retrieval and tool ecosystems for agent orchestration.
Conclusion
SGI-Bench establishes a rigorous, principle-grounded, and empirically validated framework for probing the state of scientific general intelligence in LLMs and agents (2512.16969). It provides the field with a standard both for diagnosing progress and for clarifying the open challenges in realizing genuinely autonomous scientific AI. Results demonstrate that while current models possess compelling partial competencies, they are far from the integrated, numerically faithful, and methodologically disciplined cognition necessary for AI-driven scientific discovery.
Implications
Practically, SGI-Bench can serve as both an industry standard for benchmarking research-assistant LLMs and a diagnostic suite for iterative system development. In theory, it draws new attention to integrated workflow evaluation, harmonizing “AI as scientist” research with empirical progress. SGI-Bench thus lays a foundational path for closing the gap between surface fluency in scientific language and the emergence of computational agents capable of authentic, end-to-end scientific investigation.
References
- "Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows" (2512.16969)