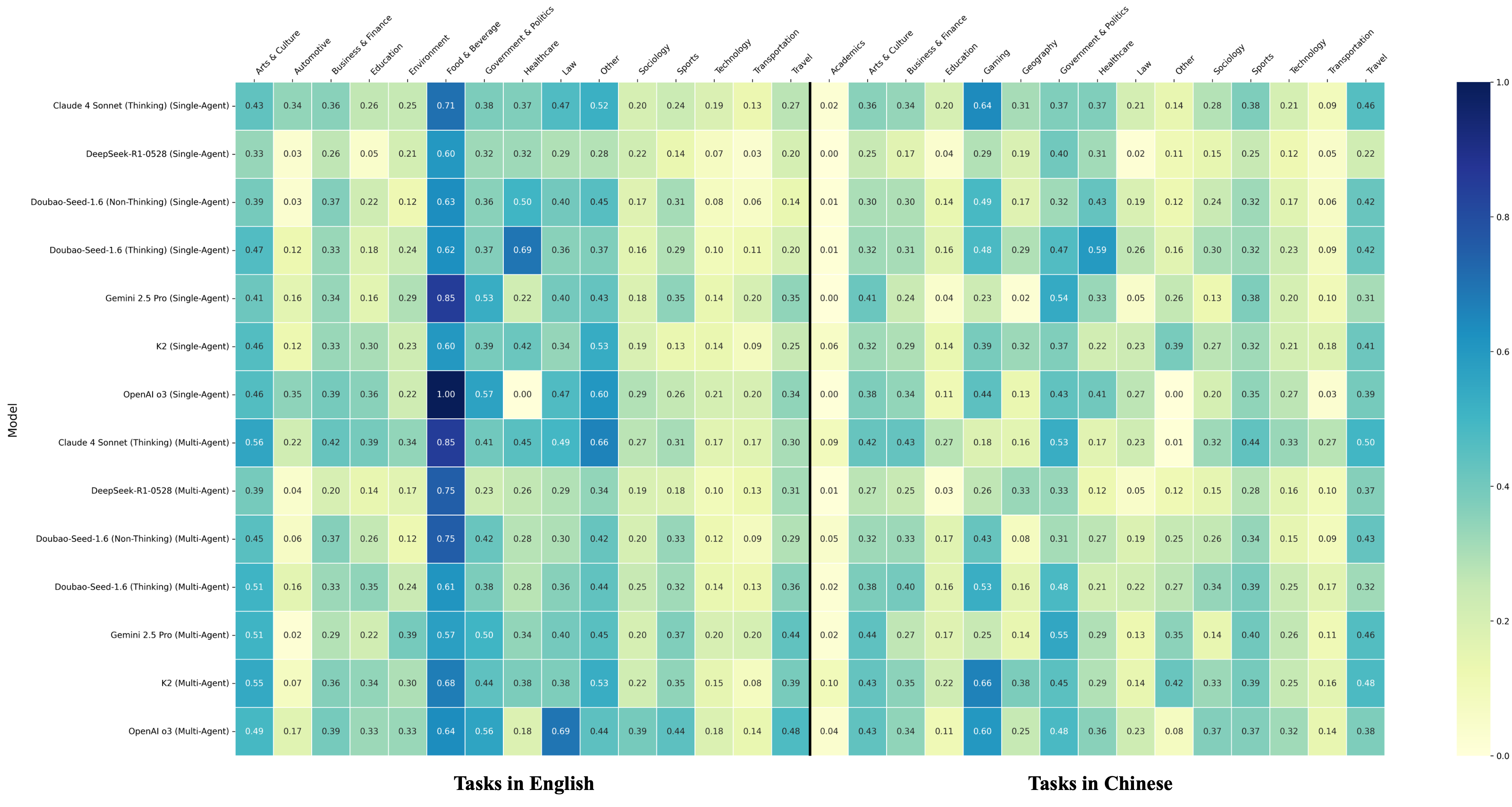
- The paper introduces WideSearch, a benchmark for LLM-powered agents performing exhaustive information aggregation across 200 curated tasks in English and Chinese.
- It details a five-stage curation and evaluation methodology using success rate, row-level F1, and item-level F1 metrics to assess agent performance.
- Experiments reveal multi-agent systems outperform single-agent frameworks, highlighting persistent challenges in query decomposition, evidence grounding, and scalability.
WideSearch: Benchmarking Agentic Broad Info-Seeking
Motivation and Problem Definition
WideSearch addresses a critical gap in the evaluation of LLM-powered search agents: their ability to perform large-scale, high-fidelity information gathering across diverse domains. Unlike DeepSearch (vertical, multi-hop reasoning for hard-to-find facts) and DeepResearch (complex synthesis for report generation), WideSearch focuses on tasks characterized by operational scale rather than cognitive complexity. These tasks require agents to exhaustively collect atomic facts for a set of entities and organize them into structured outputs, emulating real-world scenarios such as compiling sector-wide financial data or aggregating university admissions requirements.
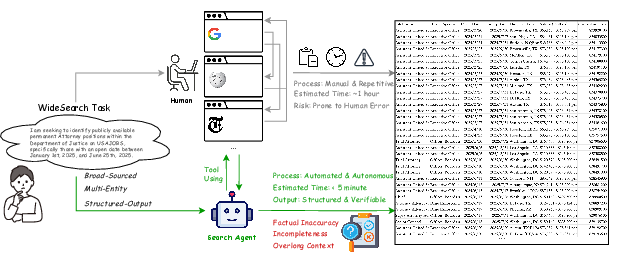
Figure 1: A conceptual comparison of manual and agent-based approaches for WideSearch tasks, highlighting the operational workflow and limitations of each methodology.
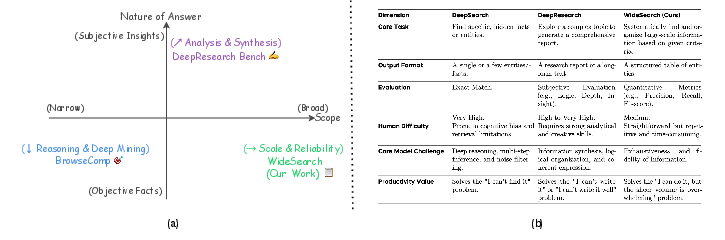
Figure 2: Overview and detailed comparison of DeepSearch, DeepResearch, and WideSearch, illustrating their distinct operational domains and evaluation paradigms.
Benchmark Construction and Methodology
WideSearch comprises 200 manually curated tasks (100 English, 100 Chinese) spanning 18 topics, each requiring the agent to populate a table with entity-attribute pairs sourced from the web. The benchmark design enforces six principles: high search volume, temporal/contextual invariance, objective verifiability, public accessibility, reliance on external tools, and scenario diversity. Tasks are sourced from real user queries, refined by domain experts, and subjected to a five-stage curation and validation pipeline to ensure complexity, verifiability, and resistance to parametric knowledge.
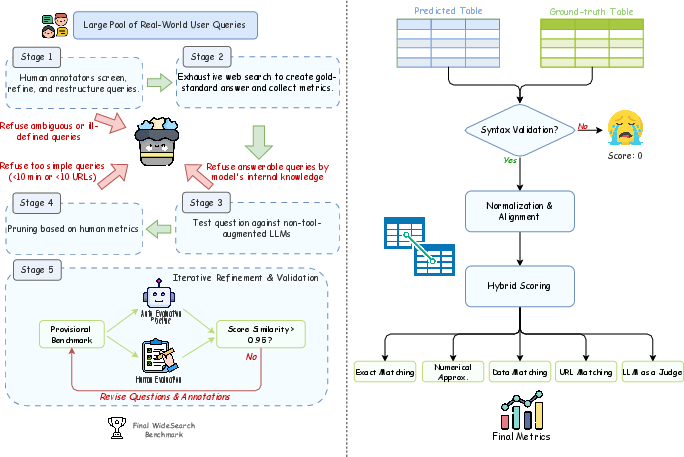
Figure 3: Integrated data pipeline for WideSearch, detailing the five-stage curation and automated evaluation process.
The annotation protocol includes exhaustive web search, recording of procedural metrics (completion time, queries issued, web pages consulted), parametric knowledge filtering, and iterative validation to align automated and human scoring. The final dataset exhibits substantial complexity: average human completion time is 2.33 hours, with annotators consulting an average of 44.1 unique web pages per task.
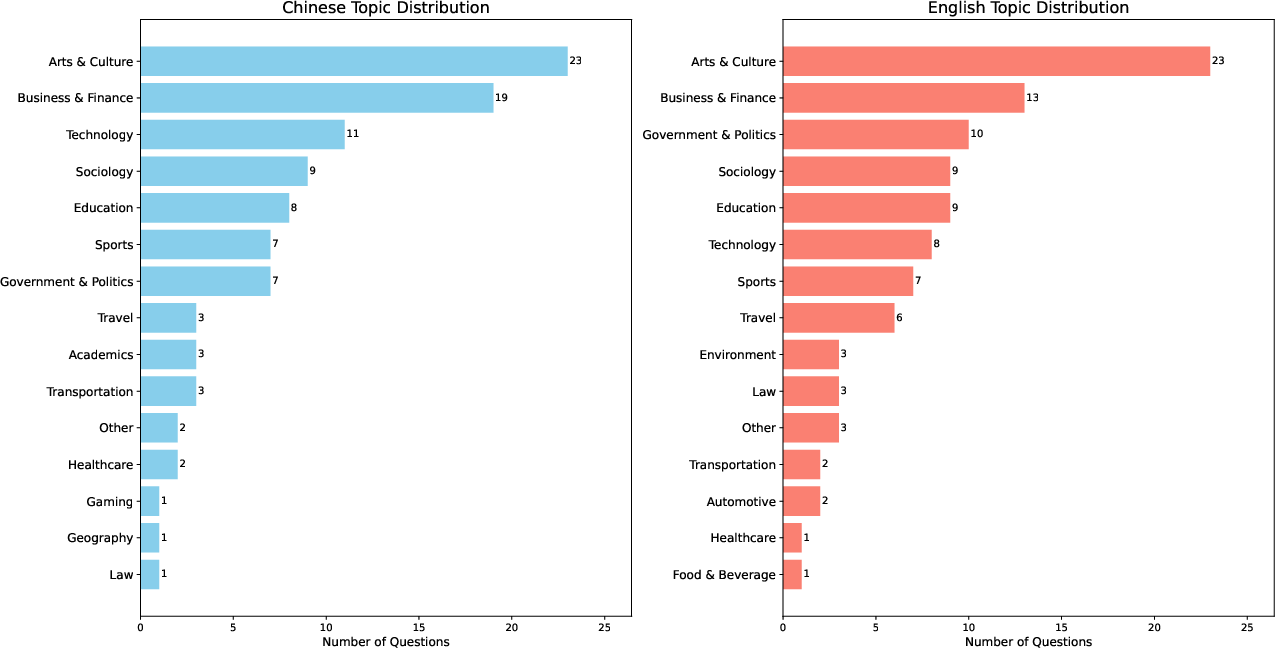
Figure 4: Distribution of 18 topics across the 200 WideSearch tasks, ensuring broad domain coverage.
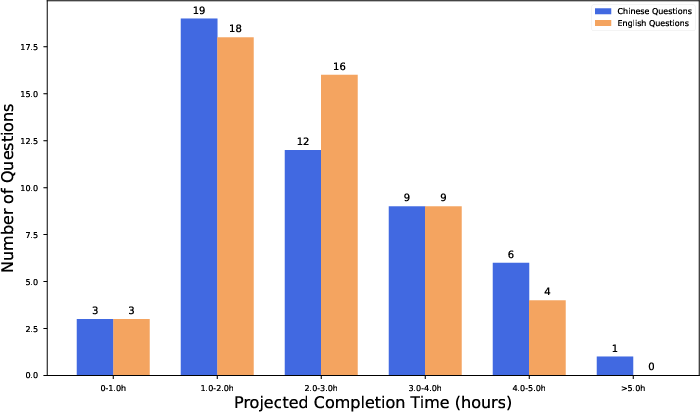
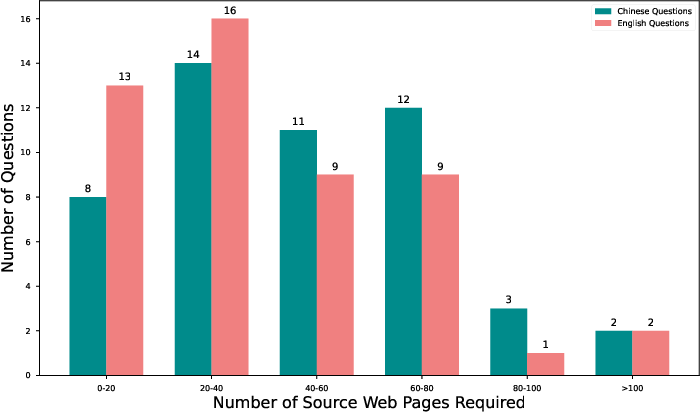
Figure 5: Statistical distributions of completion time and breadth of research for Chinese and English tasks, demonstrating the procedural depth required.
Evaluation Framework
WideSearch employs a hybrid automated evaluation pipeline combining deterministic rule-based checks and LLM-as-a-judge semantic scoring. Each agent output is parsed, normalized, and aligned with ground-truth tables using primary keys. Cell-wise evaluation leverages exact match, numerical/date/URL normalization, and LLM-based semantic equivalence for complex columns. Metrics include:
- Success Rate (SR): Strict table-level match.
- Row-level F1: Precision/recall for complete entity records.
- Item-level F1: Fine-grained cell accuracy.
Multiple runs per task (N) are aggregated via Avg@N, Pass@N, and Max@N strategies to capture both average and peak agent performance.
Experimental Results
WideSearch benchmarks over 10 state-of-the-art agentic systems, including single-agent, multi-agent, and commercial end-to-end frameworks. All agents are equipped with standardized search and web reading tools. The multi-agent framework decomposes queries and executes parallel sub-tasks, mimicking collaborative human workflows.
Key findings:
Error Analysis
Systematic analysis reveals four primary advanced agentic failure modes:
- Incomplete Query Decomposition: Agents fail to generate comprehensive sub-queries, missing key constraints or attributes.
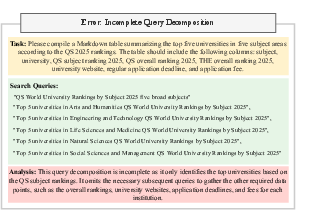
Figure 7: Example of incomplete query decomposition, where the agent omits necessary sub-queries for additional attributes.
- Lack of Reflection and Iterative Refinement: Agents do not adapt search strategies after initial failures, often abandoning tasks prematurely.

Figure 8: Example of lack of reflection, with the agent failing to refine its search after receiving aggregated data.
- Failure in Evidence Utilization: Agents misattribute or misinterpret retrieved evidence, leading to incorrect outputs.

Figure 9: Example of evidence utilization failure, with incorrect attribution of GPA requirements.
- Knowledge Hallucination and Factual Inconsistency: Agents fabricate facts when external information is unavailable, violating grounding requirements.

Figure 10: Example of knowledge hallucination, with the agent inventing a non-existent entrance fee.
Basic failure modes include tool invocation errors, output formatting errors, context length exceedance, and response refusals.
Test-Time Scaling and Human Consistency
Test-time scaling experiments (up to 128 attempts per task) show that while item-level F1 improves substantially, table-level SR remains low (<20%), confirming that exhaustive, error-free aggregation is the core challenge. The automated evaluation pipeline achieves >97.8% consistency with human judgment, validating its reliability.
Implications and Future Directions
WideSearch demonstrates that current LLM-based agents are fundamentally limited in large-scale, high-fidelity information seeking. The bottleneck is not atomic fact retrieval but the orchestration of comprehensive, error-free aggregation and verification. The strict all-or-nothing SR metric exposes the fragility of agentic workflows: any omission, hallucination, or misattribution results in total task failure.
The results highlight the urgent need for:
- Advanced agentic capabilities: Improved planning, reflection, evidence grounding, and iterative refinement.
- Robust multi-agent architectures: Parallel search and cross-validation to mimic collaborative human annotation.
- Domain-adaptive strategies: Tailored workflows for challenging domains (e.g., academia, transportation).
- Evaluation at scale: Benchmarks like WideSearch are essential for driving progress in agent reliability and real-world applicability.
Conclusion
WideSearch establishes a rigorous benchmark for evaluating agentic broad info-seeking, revealing critical deficiencies in current LLM-powered search agents. The findings indicate that future progress depends on the development of sophisticated agent architectures, particularly multi-agent systems capable of parallel search and cross-validation. WideSearch provides a robust testbed for measuring and advancing the reliability, completeness, and fidelity of agentic information gathering at scale.