- The paper demonstrates that using task-specific small models for perception and classification alongside structured context assembly significantly improves multimodal AI performance.
- It introduces a modular system architecture with defined stages for ingress, small-model stacking, context construction, and controller-led LLM offloading.
- Empirical results on benchmarks like AIME-2025 and GPQA-Diamond highlight substantial gains in efficiency, accuracy, and cost-effectiveness over monolithic LLM approaches.
Interfaze: Prioritizing Task-Specific Small Models in Context-Centric AI Systems
Motivation and Background
Recent developments in AI application deployment reveal that monolithic LLMs are ill-suited for scenarios demanding high precision, multimodal integration, or long-context reasoning. Modern benchmarks and real-world demands expose the inefficiencies and brittleness of applying general-purpose transformer models directly to raw complex data such as lengthy documents, intricate web content, charts, or multilingual audio. The dominant industry approach has become increasingly system-driven, with LLMs invoked only after a pipeline of heterogeneous, modality-specific models construct a rich and highly filtered context.
The Interfaze architecture formalizes this paradigm. Instead of relying solely on LLMs, it proposes an AI system that foregrounds task-specific small LLMs (SLMs) and deep neural networks (DNNs) as first-class modules for perception, classification, retrieval, and context construction. The resulting context is distilled and handed off to a generalist LLM that produces the answer, thereby offloading the bulk of computational and perceptual load to efficient specialists and reserving LLM capacity for higher-level reasoning.
System Architecture
Interfaze offers a context-centric system comprising four layers: ingress, small-model and perception stack, context construction, and an action/controller layer. The architecture is depicted below.
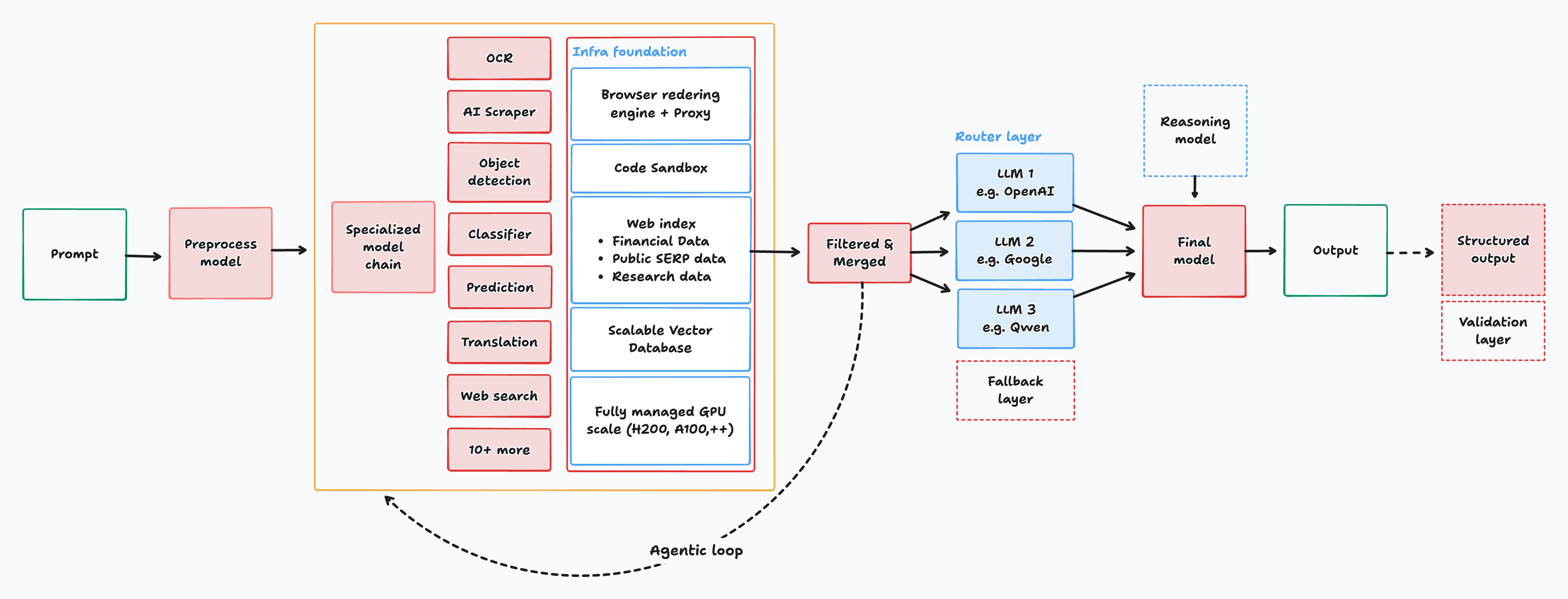
Figure 1: The Interfaze system operates as a stack integrating task-specific perception DNNs/SLMs, structured context construction, an action layer, and a thin controller that routes queries to the appropriate toolchains.
Ingress normalizes multimodal queries, performing safety and intent checks. The small-model stack then executes perception and classification tasks across OCR, ASR, layout analysis, object and diagram parsing, and lightweight retrieval/classification. This stack is composed of compact, efficient models occupying separate GPU pools for reduced computation overhead.
Context construction fuses outputs from perception models and external retrieval (web, document, code, diagrams) into a compact, schema-driven state. This encompasses structured observations, entities (with geometry and type), relations, and provenance—each tightly budgeted with learned heuristics and filtering. The action/controller layer sequences tool invocations and always forwards the distilled context to a configured LLM, which never observes raw input modalities.
This design is context- and tool-centric, with the LLM relegated to final-stage reasoning on pre-processed, high-relevance state, rather than extended context windows or full input modality access.
Small-Model and Perception Stack
The perception stack is implemented as a modular array of task-specific specialists:
- ASR & Diarization: Convolutional and self-attention encoders map audio to transcriptions with multilingual conditioning. Voice activity detection and speaker segmentation are handled with lightweight neural models, producing JSON structures annotated with speaker and temporal metadata.
- OCR and Document Parsing: Multi-stage pipelines segment documents, detect and recognize text across languages, infer layout/reading order using graph-based methods, and supplement with vision-LLMs for schema-specific extraction. All geometric and semantic information is encoded compactly for downstream reasoning.
- Open-Vocabulary Object/GUI Parsing: Vision-language encoders handle prompt-conditioned localization; segmentation is refined with models such as SAM~2, enabling precise object/region detection in open domains and GUI screenshots.
Intermediate outputs are standardized and made explicit—entities, relations, and observations—supporting robust, loss-minimized integration into the context layer, and ultimately producing a structured representation consumable by generalist models.
Context Construction and Offloading
Interfaze emphasizes that effective context management, not mere context size, determines LLM performance on long-input or multimodal tasks. Indexed retrieval (code, documentation, general search), page/block-based document parsing, and headless browser-driven web scraping ensure only dense, relevant information is passed forward, substantially outcompeting naive passage or window expansion techniques. The context compiler executes merging, redundancy avoidance, and salience scoring, maintaining compatibility with fixed prompt/token budgets and ensuring tractable LLM calls even for complex cases.
The architecture demonstrates that large LLMs can be effectively isolated from raw multimodal signals, operating exclusively on distilled context assembled by the specialist model/tool chain. Computational savings, latency, and robustness are achieved by limiting LLM invocation to strictly necessary reasoning substrate.
Benchmarks and Empirical Results
Interfaze-Beta is empirically validated on a gamut of multimodal, code, and reasoning benchmarks. Strong numerical results include:
- AIME-2025: 90.0 (vs. 34.7 by GPT-4.1; +55.3 margin)
- MMLU: 91.38 (vs. 90.2 by GPT-4.1)
- GPQA-Diamond: 81.31 (vs. 66.3 by GPT-4.1; +15.01 margin)
- AI2D: 91.51 (vs. 85.9 by GPT-4.1)
- MMMU (val): 77.33 (vs. 74.8 by GPT-4.1)
- ChartQA: 90.88
- LiveCodeBench v5: 57.77 (vs. 45.7 by GPT-4.1)
- Common Voice v16: 90.8
Key claim: The majority of improvements derive from the explicit use of small-model/tool chains and structured context compilation, not from enhancements to LLM scale or architecture. Ablation studies show that disabling perception specialists (OCR, diagram parsers) incurs 4–7 point drops on multimodal tasks; removing context compilation costs ≈2 points on knowledge tasks.
Substantial gains are observed in knowledge/reasoning (MMLU, GPQA-Diamond), mathematical problem solving (AIME-2025), structured perception (AI2D, ChartQA), and speech (Common Voice v16), confirming the efficacy of the context-offloading paradigm in practical settings.
Analysis, Implications, and Limitations
The Interfaze approach challenges the orthodoxy that AI progress in deployment hinges primarily on larger, more capable monolithic models. Instead, it advocates that robust AI systems are best built from carefully composed and orchestrated pipelines, treating perception and retrieval models as primary actors in the reasoning chain, with LLMs functioning as final-stage reasoners over a highly structured and minimal context. This architectural perspective aligns with observed trends in resource allocation, reliability, cost minimization, and scalability for production AI.
Key limitations identified by the study include tail latency due to over-building of context and non-optimal tool invocation in the controller. The authors suggest future work in smarter chain selection, better delay modeling, and dynamic context expansion, including the use of penalties for unnecessary tool calls and more sophisticated learning-based controllers.
From a theoretical standpoint, this architecture invites renewed exploration into the division of labor between specialist and generalist models, contextual relevance filtering, and cost-quality trade-off strategies in AI system design.
Conclusion
Interfaze demonstrates that orchestrating task-specific small models for perception, classification, and context assembly—combined with a context-focused controller and a generalist LLM for bounded reasoning—provides measurable advantages over monolithic approaches on diverse AI tasks. The evidence supports the position that the most robust and efficient future AI systems will be systems-first, prioritizing explicit context construction and distributed computation across heterogeneous toolchains. As benchmarks grow in complexity and multimodality, architectures following the Interfaze paradigm are likely to become the de facto standard for scalable and reliable AI deployment.

