- The paper demonstrates that a targeted Cyrillic tokenizer and specialized reasoning SFT, combined with advanced speculative decoding, markedly improve token efficiency and reasoning performance in Russian LLMs.
- It introduces the T-Wix corpus and rigorous reward-guided training that significantly boost performance metrics, outperforming comparable open and proprietary models on multiple benchmarks.
- The system’s interactive playground and deployment on NVIDIA H100 validate T-pro 2.0’s low-latency, efficient inference capabilities for research and production applications.
T-pro 2.0: Design, Training, and Evaluation of an Efficient Russian Hybrid-Reasoning Model
Introduction and Motivation
T-pro 2.0 addresses a significant gap in the Russian-language LLM landscape by delivering an accessible, open-weight model capable of both direct answering and stepwise reasoning trace generation. Prior LLMs for Russian were either proprietary or derived from multilingual foundations with suboptimal adaptation for Cyrillic-heavy content, resulting in degraded token efficiency and lower reasoning performance. T-pro 2.0 systematically resolves these bottlenecks through three axes: a Russian-centric tokenizer, a large-scale reasoning-focused supervised corpus, and an advanced speculative decoding pipeline built for reduced inference latency.
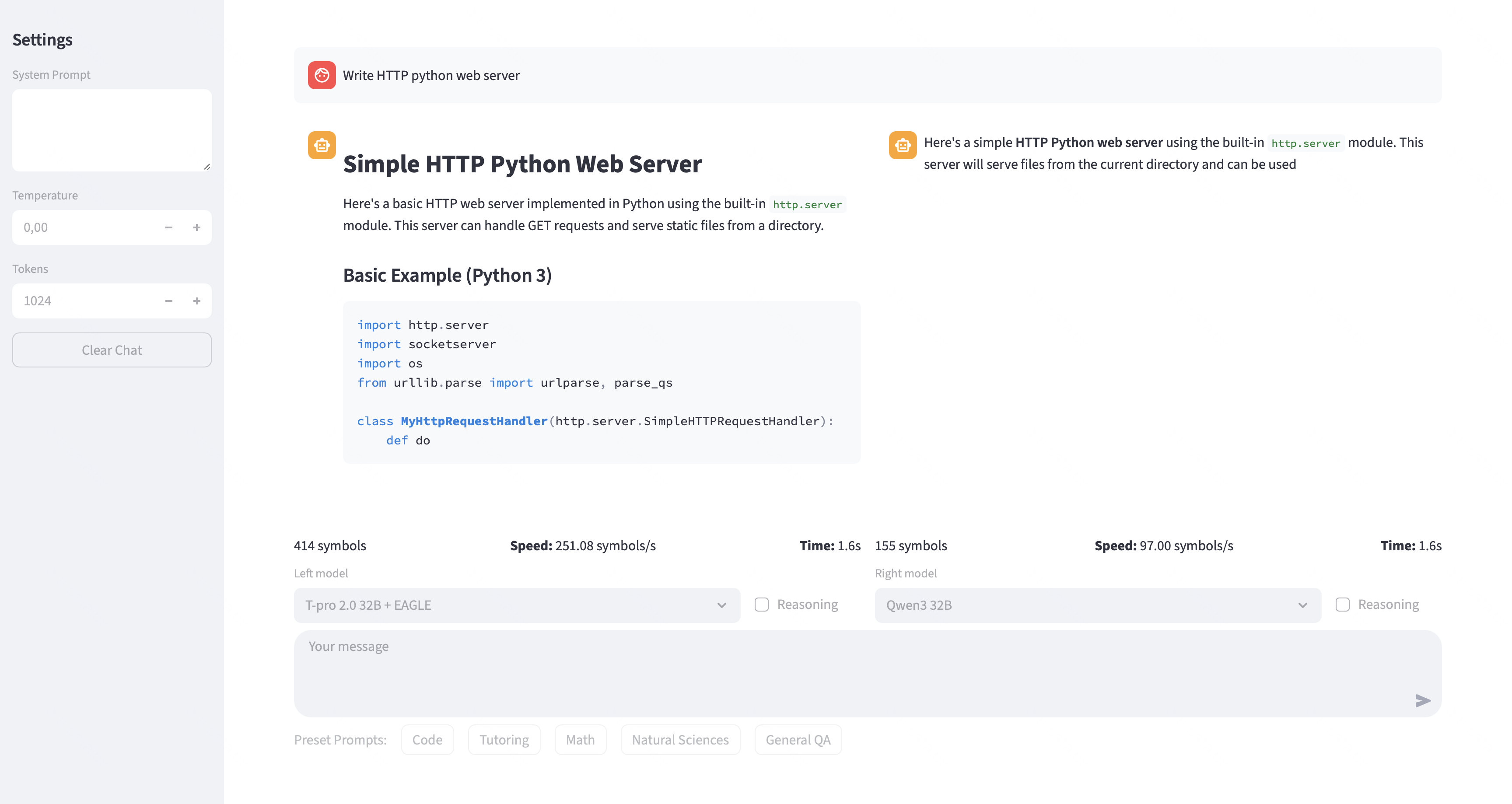
Figure 1: Screenshot of the system demo of the T-pro 2.0 EAGLE.
System Architecture and Interactive Playground
T-pro 2.0 is publicly deployed as an interactive, research-oriented demo, supporting both reasoning ("think") and non-reasoning modes. The Web UI provides real-time side-by-side completion comparison (defaulting to Qwen3-32B-Instruct as a baseline), exposure of all inference parameters, and live telemetry (tokens per second, speculative acceptance rate, etc.), supporting reproducibility and granular analysis of model behavior and latency-performance trade-offs.
Backend inference is served via SGLang: T-pro 2.0 is paired with an EAGLE-style speculative sampling pipeline comprising a lightweight single-layer draft model and a 32B verifier, while the baseline uses standard AR decoding. Each endpoint runs on an NVIDIA H100, supporting interactive and batch workloads for cross-model evaluation at low latency.
Tokenization and Data Pipeline
A crucial innovation in T-pro 2.0 is the replacement of 34K low-frequency non-Cyrillic entries in the Qwen3 vocabulary with Cyrillic tokens. This augmentation achieves a substantial reduction in average tokens per word for Russian and seven other Cyrillic-script languages, without impacting English tokenization efficiency.
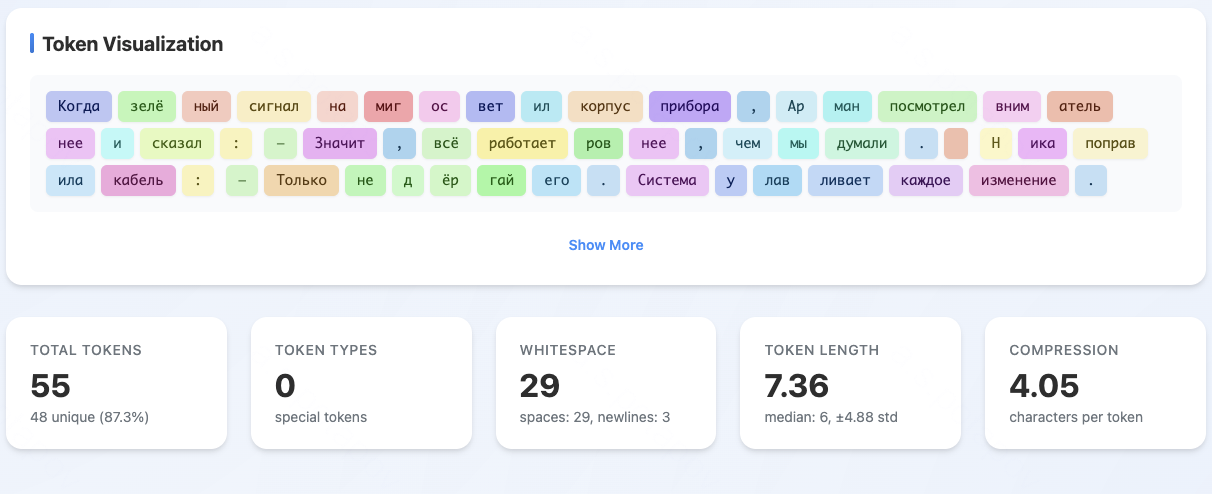
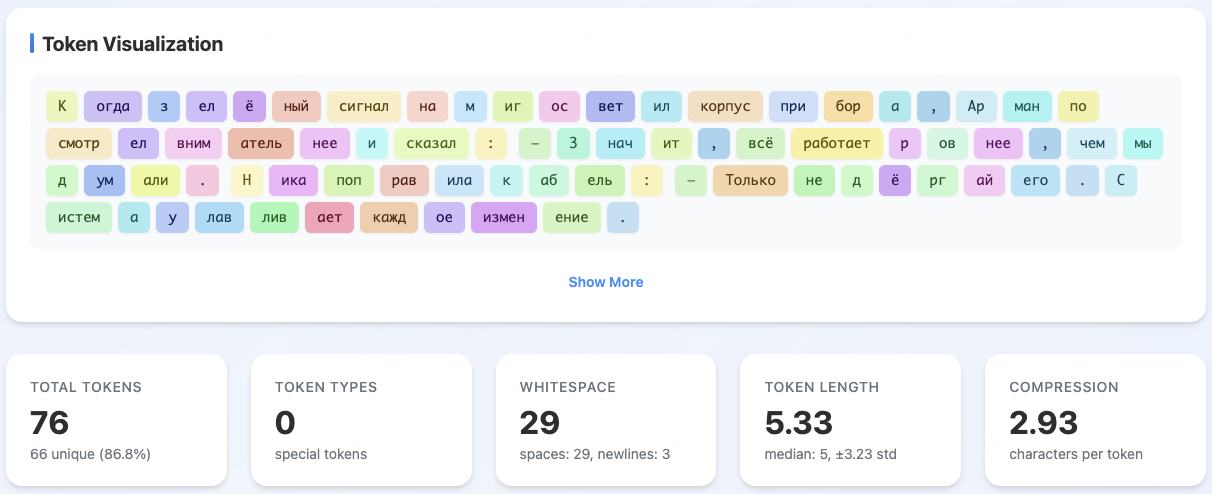
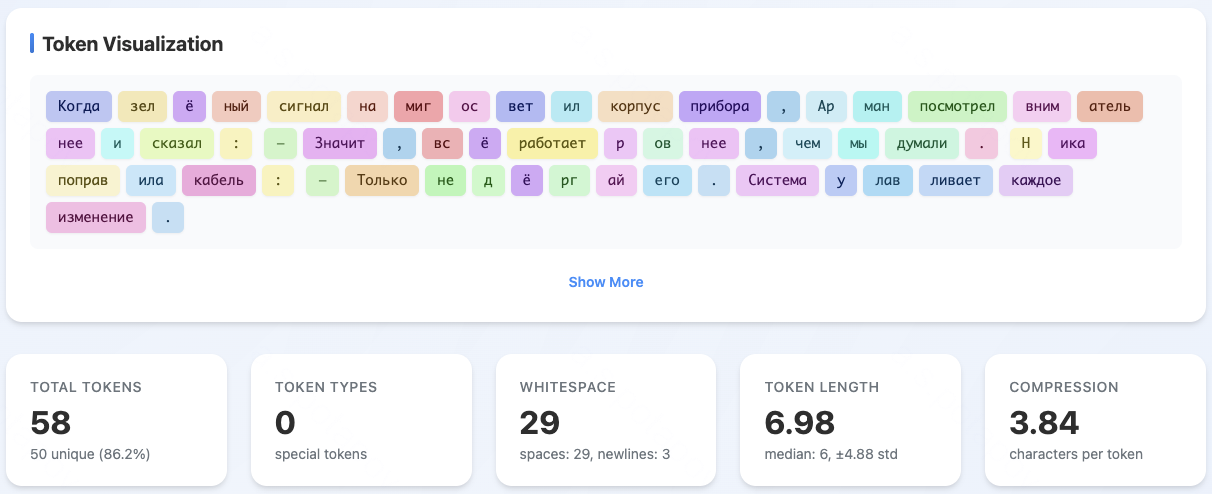
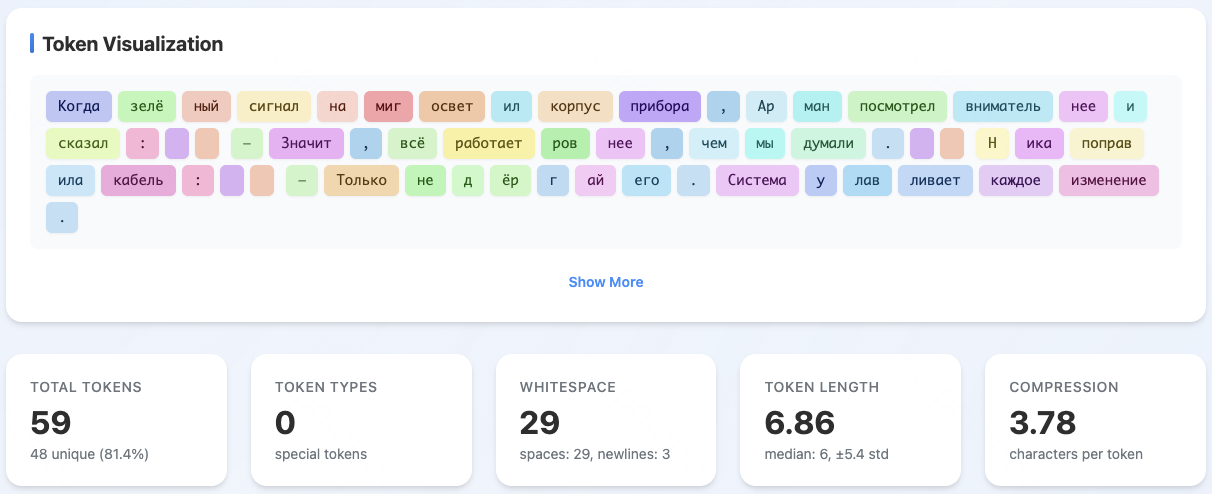
Figure 2: T-pro design highlights Cyrillic-centric tokenizer architecture, optimizing token efficiency for Russian.
Comparative analysis shows the share of Russian words split into ≤2 tokens increases from 38% (Qwen3) to 60% (T-pro 2.0) on Wikipedia. The compression generalizes to all tested Cyrillic languages except Kazakh, placing T-pro 2.0 at or near SOTA in Cyrillic token segmentation among open models.
Supervised Fine-Tuning (T-Wix)
The T-Wix SFT corpus comprises ∼500K samples, combining 468K general instructions with 30K distilled reasoning traces across math, science, code, and open-ended tasks. Strict domain/difficulty balancing and comprehensive deduplication (both semantic and exact-match) are employed at all stages, including MinHash-based filtering against benchmarks to eliminate leakage.
Figure 3: Token distribution in T-Wix, illustrating domain and difficulty balancing for SFT.
Reward model (RM) filtering and on-policy DPO preference optimization further refine alignment, with 16 completions per instruction scored for contrastive selection. In the reasoning split, reward-guided data selection purposely operates within a calculated "zone of proximal development," retaining only samples with moderate teacher-student reward gaps and low intra-sample RM variance to optimize distillability.
Model Training and Adaptation
Midtraining and Tokenizer Adaptation
Instructional midtraining is performed for 40B tokens on a primarily Russian/English instruction mix. Empirical results indicate most adaptation to the dense Russian tokenizer occurs within the first ∼1k steps (∼4B tokens):
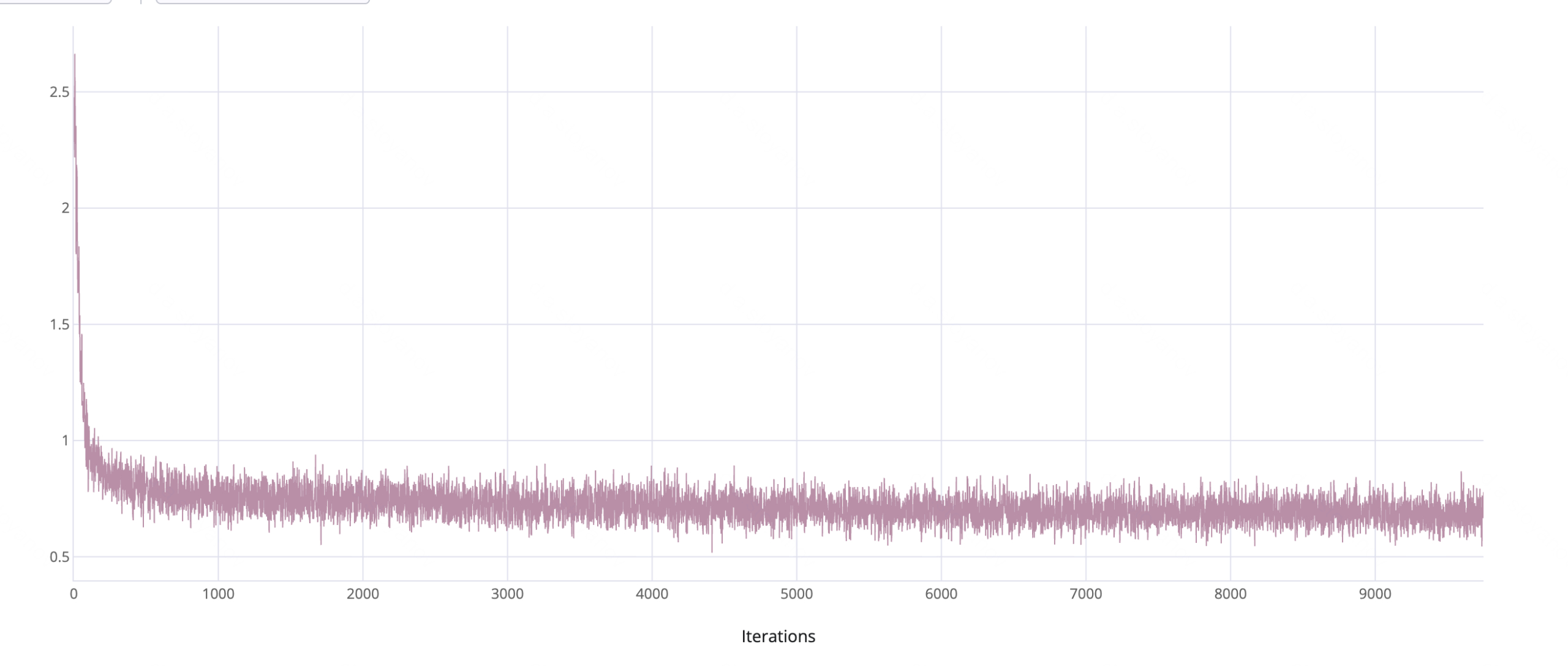
Figure 4: Midtraining loss, showing rapid adaptation to the new tokenizer precedes plateauing.
Ablations show that instruction-only midtraining, eschewing inherited raw pretraining content for exclusively instruction-formatted examples, produces superior downstream reasoning performance. On ruAIME’24, for instance, accuracy increases from 0.60 (mixed) to 0.67 (instruction-only). The T-pro tokenizer model marginally surpasses original Qwen3 on MERA (0.574 vs. 0.560 at 8B scale), indicating the denser Cyrillic segmentation incurs no loss of general capability.
Reward Model and Preference Training
A Qwen3-32B-based RM is trained with a Bradley–Terry objective using synthetic tournament-based annotations (knockout tournaments with pairwise comparisons). On Arena-Hard Best-of-N, this RM achieves a ΔBoN ("best–worst") of 22.21, decisively outperforming comparable open multilingual reward models, reflecting superior preference discrimination on real user queries.
On-policy DPO is conducted over 100K high-contrast pairs, with a 90:10 split between general and reasoning instructions, enhancing coherence, alignment, and stepwise reasoning structure under realistic sampling.
Speculative Decoding and Inference Efficiency
T-pro 2.0 integrates an EAGLE v2 speculative decoding module. The draft model (single Llama2-based layer with FR-Spec augmentation) is jointly trained for hidden-state reconstruction and token distribution alignment using KL divergence. Deployment with SGLang dynamic draft trees achieves, at temperature 0.8, an average speedup of 1.85× (standard mode) and 1.83× (reasoning mode) over standard AR decoding in interactive serving, with acceptance lengths above 3 tokens per verification. STEM domains exhibit greater acceleration (1.99×) than humanities (1.62×), paralleling more predictable token transitions in technical content.
Russian-Language Evaluation
T-pro 2.0 demonstrates competitive or superior performance relative to strong open and closed models at the 27B–32B scale:
- General Knowledge: MERA 0.66, ruMMLU-Pro 0.697 (near GPT-4o at 0.714, above RuadaptQwen3-32B-Instruct)
- Dialogue: Arena Hard Ru 91.1, WildChat Hard Ru 72.6, Arena Hard 2 (HP/CW) 53.5/64.2—all metrics surpassing equivalent-scale open and proprietary Russian models, consistent across both direct answering and reasoning modes.
Russian Reasoning
- T-Math Benchmark: 0.541
- ruAIME 2024/2025: 0.704 / 0.646
- ruMATH-500: 0.94
- Vikhr Math: 0.799
Scores on T-Math, a 331-problem collection from Russian olympiads, empirically differentiate T-pro 2.0 from adaptation-based and translation-based alternatives, and expose a non-saturated performance frontier—no model exceeds 0.75 pass@1.
English Generalization
Despite its Russian-centric innovations, T-pro 2.0 maintains strong English proficiency:
- AIME 2024: 0.765
- MATH-500: 0.966
- GPQA Diamond: 0.641
Results on the English splits remain within a narrow margin of, or exceed, comparable SFT or distilled backbones (Qwen3-32B, DeepSeek-R1-Distill-Qwen-32B).
Implications and Future Directions
T-pro 2.0 underscores the significance of dedicated tokenizer adaption and instruction-focused midtraining for non-English LLMs, especially in morphologically rich and undersupported languages. The model’s open weights, dataset, and inference stack establish a reproducible, extensible baseline for further research, while the T-Math and T-Wix resources set new standards for rigorous evaluation and SFT corpus construction in Russian.
The efficient speculative decoding pipeline facilitates the deployment of large autoregressive models in interactive and production contexts without substantial architectural rework.
Potential future work includes:
- Integration of agentic and tool-use abilities (e.g., function calling, toolformer-style augmentation)
- Empirical validation and optimization for 128k-token contexts, leveraging RoPE scaling
- Refinement of online/offline RL for alignment and robustness on out-of-distribution reasoning tasks
- Draft model quantization and EAGLE v3 upgrades for further inference acceleration
Conclusion
T-pro 2.0 represents a technically rigorous solution for efficient, reasoning-capable Russian-language LLMs that balances architectural adaptation, corpus quality, and advanced inference methods. The system contributes open, high-quality models and datasets, together with a transparent evaluation playground. The results provide clear evidence that dedicated tokenizer engineering, comprehensive reasoning SFT, and practical inference optimization are essential for scaling LLM capabilities beyond English, and lay the groundwork for further advances in the Russian-language LLM ecosystem.

