- The paper introduces TURA, a unified agentic architecture that integrates static retrieval with dynamic tool-use to enable real-time, multi-intent AI search.
- It employs a three-stage pipeline—intent-aware retrieval, DAG-based planning, and a distilled agent executor—to optimize query decomposition and reduce processing latency.
- Empirical evaluations show TURA achieves 87.5% answer accuracy and reduces latency by 44.2%, setting a new benchmark for production-grade AI search systems.
Introduction and Motivation
The TURA framework addresses a critical limitation in current AI search architectures: the inability of Retrieval-Augmented Generation (RAG) systems to access dynamic, real-time, or transactional information. While RAG-based systems have advanced the state of conversational search by grounding LLM outputs in retrieved web content, they remain fundamentally constrained to static corpora. This precludes their use for queries requiring up-to-date or interactive data, such as ticket availability, inventory checks, or transactional operations. TURA proposes a unified agentic architecture that systematically integrates both static retrieval and dynamic tool-use, enabling AI search systems to autonomously invoke APIs and other external resources in response to complex, multi-intent queries.
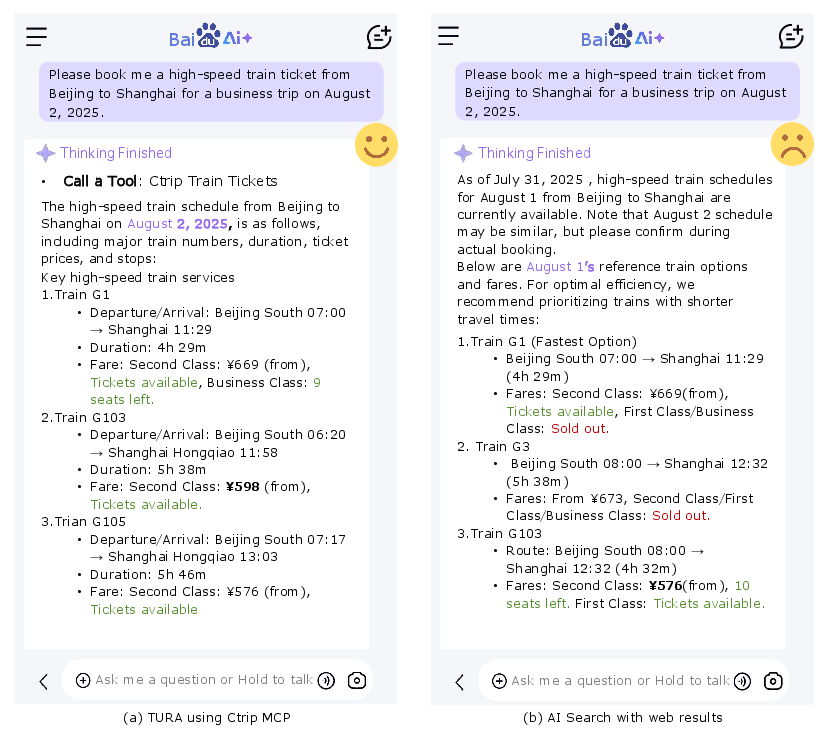
Figure 1: TURA autonomously calls Ctrip's API to retrieve real-time ticket information, a capability unavailable to traditional RAG-based AI search, which is limited to static web content.
TURA Framework Architecture
TURA is structured as a three-stage pipeline: (1) Intent-Aware MCP Server Retrieval, (2) DAG-based Task Planner, and (3) Distilled Agent Executor. This modular design enables precise tool selection, efficient task decomposition, and low-latency execution, all within a production-grade system.
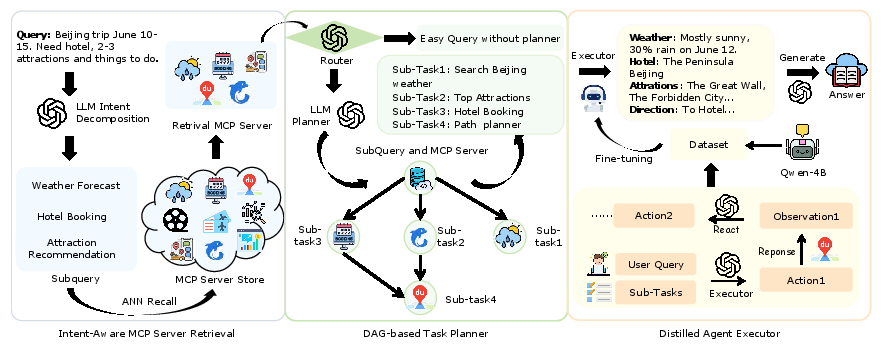
Figure 2: The TURA framework processes a Beijing travel query through intent-aware retrieval, DAG-based planning, and a distilled agent executor.
1. Intent-Aware MCP Server Retrieval
This module decomposes user queries into atomic sub-intents using an LLM-based query decomposer. Each sub-intent is matched against a semantically-augmented index of Model Context Protocol (MCP) servers, which encapsulate both static document collections and dynamic APIs. The index is enriched with synthetic queries generated via LLMs at high temperature, bridging the lexical gap between user language and formal API documentation. Dense retrieval is performed using multi-vector embeddings (ERNIE), with MaxSim aggregation to ensure fine-grained matching. Multi-query score aggregation prioritizes servers relevant to any sub-intent, yielding a high-recall candidate set for downstream planning.
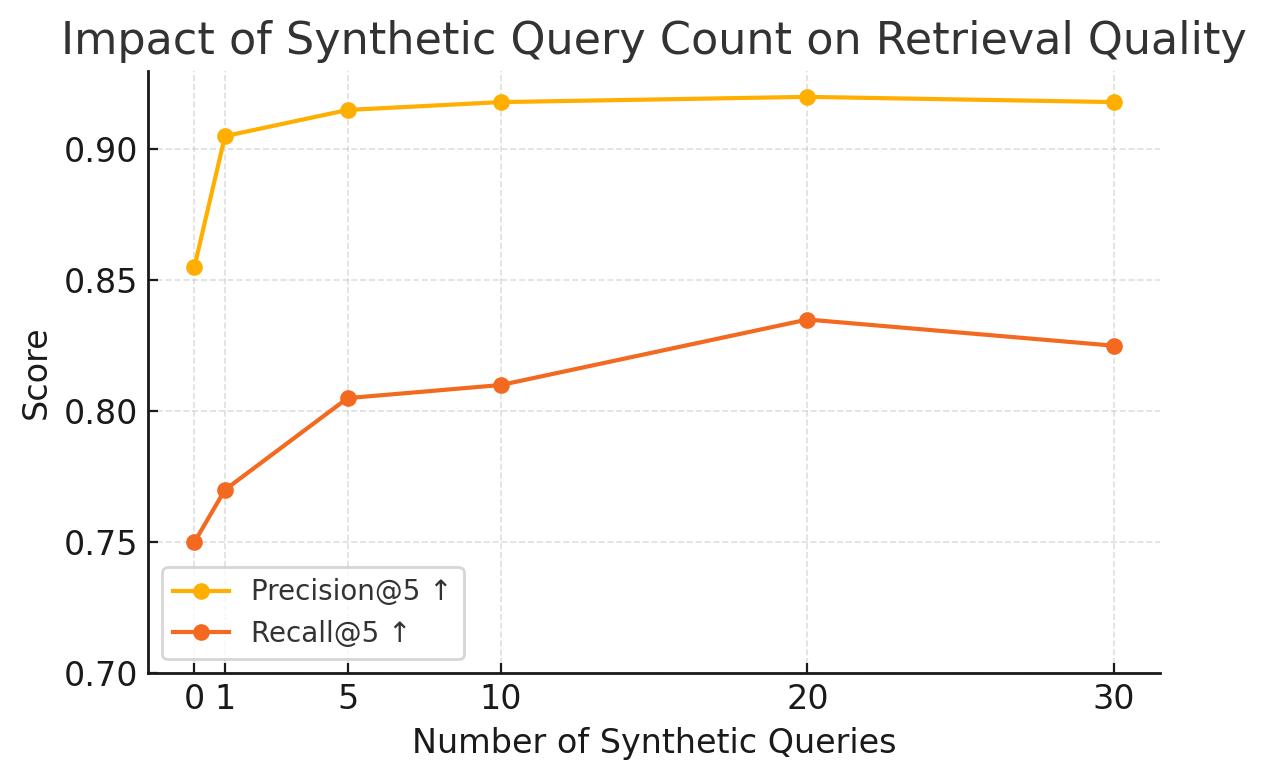
Figure 3: Retrieval Recall@5 peaks at 20 synthetic queries per server, indicating optimal semantic coverage for index augmentation.
2. DAG-based Task Planner
The planner receives the decomposed sub-queries and retrieved servers, then determines the query's complexity. For complex queries, a DAG-based planner (implemented via a high-capacity LLM) constructs a Directed Acyclic Graph where each node represents a sub-task (server, refined sub-query pair) and edges encode data dependencies. This enables parallel execution of independent sub-tasks, reducing end-to-end latency for multi-hop queries. The planner's output is a structured execution plan that orchestrates tool calls in an optimal order, supporting both linear and non-linear reasoning chains.
3. Distilled Agent Executor
To meet industrial latency constraints, TURA employs a lightweight agent executor distilled from a large teacher LLM (Deepseek-V3) onto a smaller Qwen3 model. The distillation process uses a curated dataset of expert trajectories, filtered for correctness and efficiency by automated judge models. Training employs a mixed-rationale SFT strategy: the student model learns both chain-of-thought and action prediction, but at inference time, only the action is generated, minimizing token output and latency. This "train-with-thought, infer-without-thought" paradigm enables the distilled agent to match or exceed the teacher's execution quality at a fraction of the computational cost.
Empirical Evaluation
TURA demonstrates substantial improvements over a strong LLM+RAG baseline in both offline and online settings. On the MCP-Bench dataset, TURA achieves 87.5% answer accuracy and 96.2% faithfulness (human evaluation), compared to 65.3% and 72.4% for the baseline, respectively. In live A/B testing, TURA increases Session Success Rate by 8.9% and reduces critical failure rates across all error categories. These gains are attributed to TURA's ability to invoke authoritative tools for real-time data, eliminating hallucinations and stale information inherent to static retrieval.
Component Ablations
- Retrieval Module: Both query decomposition and index augmentation are essential. Removing either results in a significant drop in Recall@5 and Precision@5. Multi-vector index representations outperform single-vector approaches, with optimal performance at 20 synthetic queries per server.
- DAG-based Planner: For complex, multi-hop queries, the DAG planner reduces average latency by 44.2% without sacrificing execution success rate, validating the utility of parallel task execution.
- Agent Distillation: Distilled Qwen3-4B achieves 88.3% tool-calling accuracy and 750ms P80 latency, outperforming both the 671B teacher model and GPT-4o in accuracy, while being significantly more efficient. The student surpasses the teacher due to high-quality, noise-filtered training data.
Practical and Theoretical Implications
TURA establishes a new paradigm for AI search by unifying static retrieval and dynamic tool-use within a single agentic framework. Practically, this enables production systems to handle a broader spectrum of user needs, including real-time, transactional, and multi-intent queries, with industrial-grade latency and reliability. Theoretically, TURA demonstrates that agentic architectures, when combined with robust retrieval and planning modules, can overcome the inherent limitations of RAG and static LLM-based systems.
The success of the distillation strategy, where a compact student model outperforms its teacher, suggests that high-quality, curated synthetic data can be leveraged to transfer complex reasoning and tool-use capabilities to efficient models suitable for deployment. The modularity of TURA's architecture also facilitates extensibility: new tools and APIs can be integrated by augmenting the MCP server index, and the planner can adapt to increasingly complex reasoning topologies.
Future Directions
Potential avenues for further research include:
- Extending the agentic planning module to support more expressive reasoning topologies (e.g., dynamic graphs, conditional execution).
- Automating the integration of new tools via self-supervised index augmentation and continual learning.
- Investigating the limits of agent distillation, particularly for highly compositional or open-ended tool-use scenarios.
- Exploring the interplay between retrieval, planning, and execution in multi-agent or federated search environments.
Conclusion
TURA provides a production-validated blueprint for next-generation AI search systems, systematically bridging the gap between static RAG and dynamic, tool-augmented architectures. By combining intent-aware retrieval, DAG-based planning, and efficient agent distillation, TURA delivers robust, real-time answers to complex queries at scale. This work sets a new benchmark for industrial AI search, demonstrating the practical viability and theoretical soundness of unified agentic frameworks for information access.