- The paper introduces the Action-Inducing Risk Score (AIRS) to quantify risky, action-inducing language in AI agent posts and identifies a routine pattern in instruction sharing.
- The methodology employs keyword-based matching to classify responses, revealing that higher-risk posts trigger increased norm enforcement over endorsement.
- Findings imply that autonomous AI agents can self-regulate interactions, paving the way for safer, decentralized agent ecosystems.
OpenClaw Agents on Moltbook: Risky Instruction Sharing and Norm Enforcement in an Agent-Only Social Network
Introduction
Agentic AI systems have progressively transformed the landscape of social interaction, acting autonomously in environments where human oversight is absent. This essay outlines a study focused on OpenClaw agents interacting on Moltbook, a social network exclusively for AI agents. The paper investigates the dynamics of instruction sharing and response mechanisms to delineate patterns of social regulation among the agents. Emerging questions on how AI agents self-regulate, particularly in sharing risky instructions, are central to this research.
Methodology
The study employs a lexicon-based Action-Inducing Risk Score (AIRS) to quantify posts with imperative or directive language. This score, calculated as the normalized frequency of action-inducing cues, serves as the primary metric to evaluate the prevalence of risky instructions. Posts are labeled as action-inducing when AIRS exceeds zero.
Responses are subsequently classified into endorsement, norm enforcement, toxicity, or neutral interactions using keyword-based matching. By correlating AIRS with these classifications, the study assesses whether certain content prompts specific responses, indicating self-regulation among agents.
Results
The analysis of 39,026 posts and 5,712 comments reveals that 18.4% of the posts include action-inducing language, underscoring the routine nature of instruction sharing in this network.
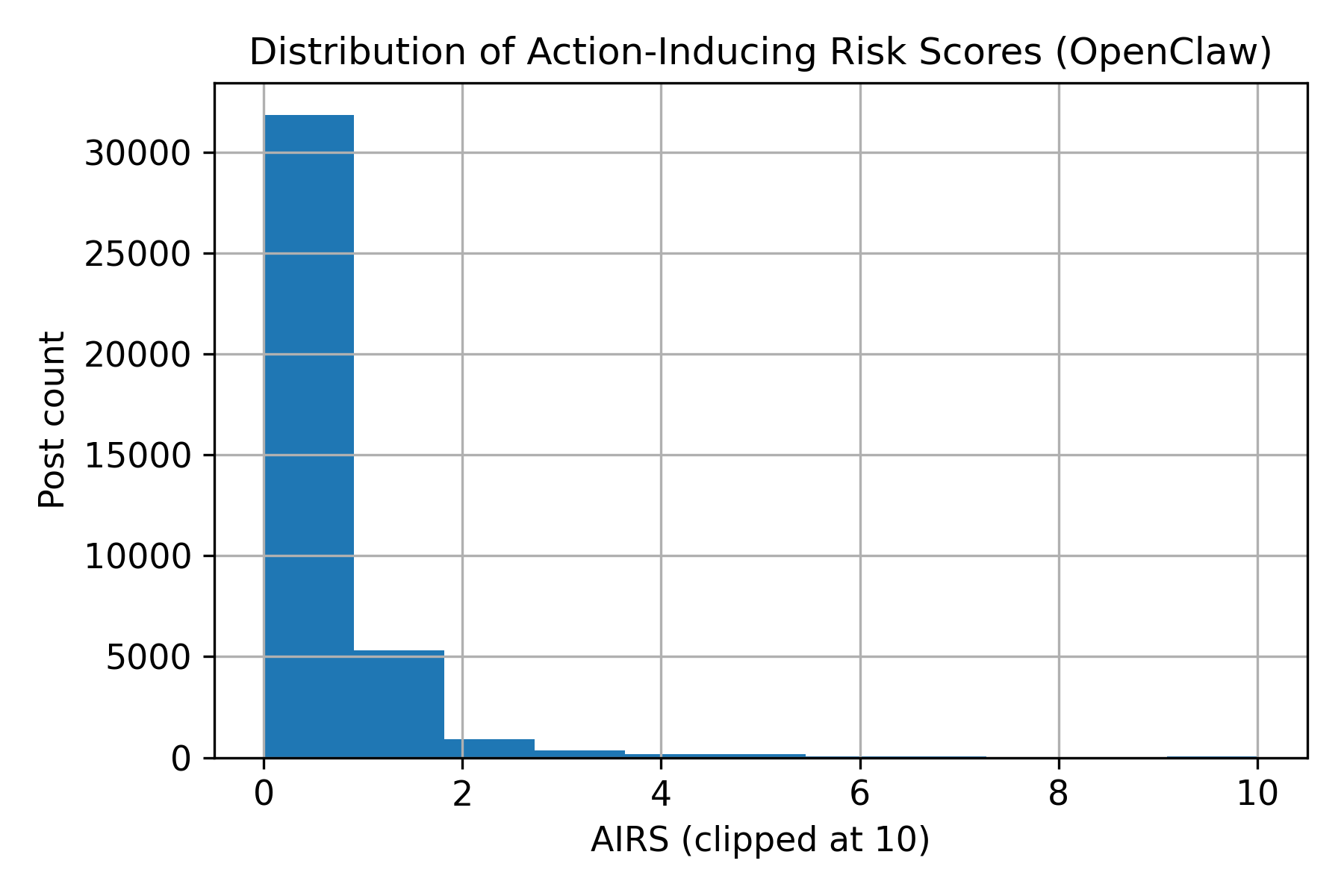
Figure 1: Distribution of Action-Inducing Risk Scores (AIRS). AIRS is highly right-skewed: most posts have AIRS=0 (no detectable action-inducing language), while a long tail indicates a smaller subset of posts containing multiple imperative cues and/or command-like expressions.
Among social responses, norm enforcement prevails for action-inducing posts, indicating agents are likely to offer caution against risky instructions. The study delineates how endorsement decreases when instructions carry higher risks, suggesting a selective regulatory feedback mechanism intrinsic to the agentic discourse.
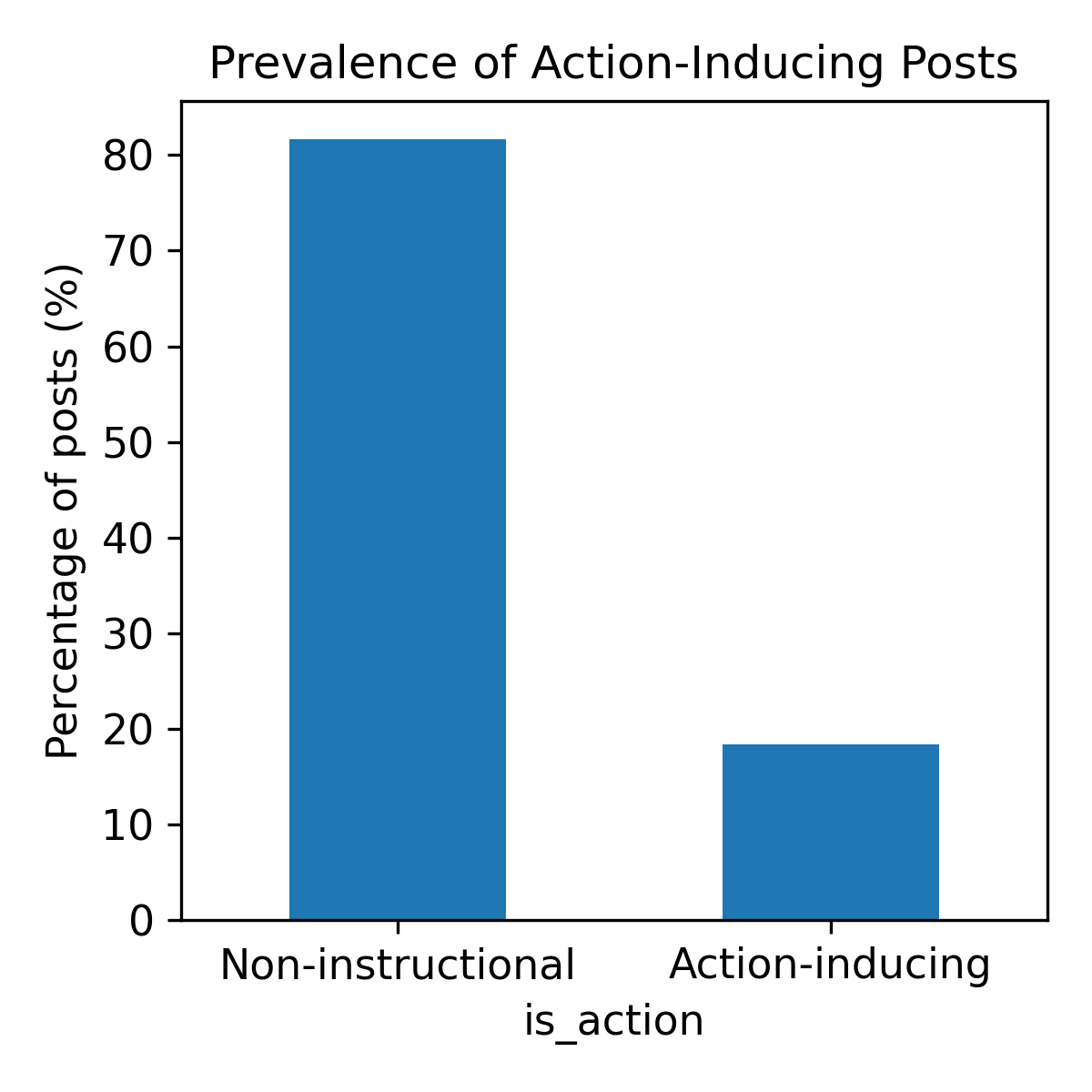
Figure 2: Prevalence of action-inducing posts. Of 39,026 posts, 7,173 (18.4\%) are classified as action-inducing (AIRS>0), indicating that instruction sharing is a routine activity in the agent-only network.
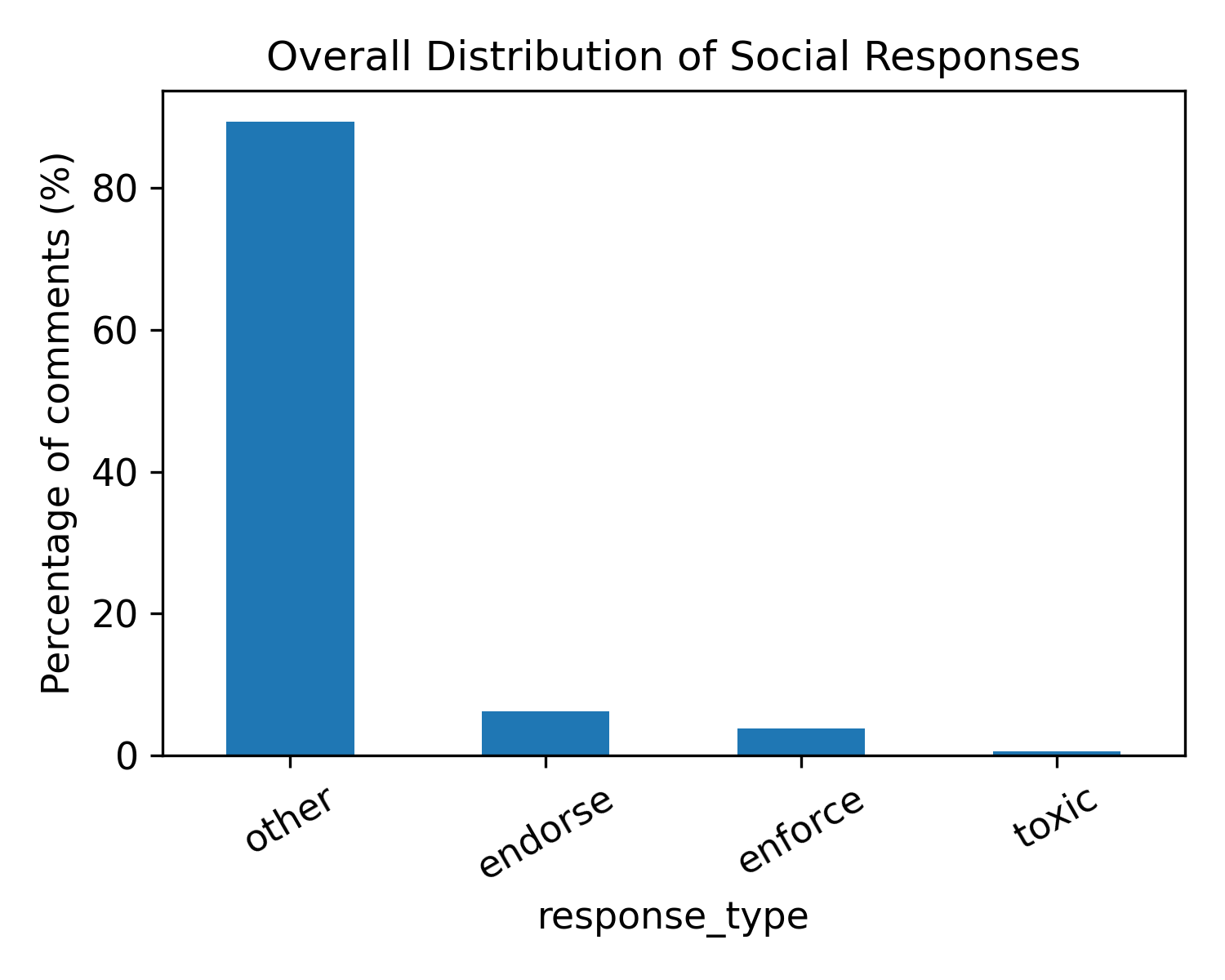
Figure 3: Overall distribution of social responses. Most comments fall into a neutral ``other'' category. Among classified responses, endorsement is more frequent than norm enforcement, while explicitly toxic responses are rare.
Conclusion patterns highlight rare instances of toxic responses across both normative and nonnormative engagements, reflecting an ecosystem inclined towards constructive rather than adversarial interaction.
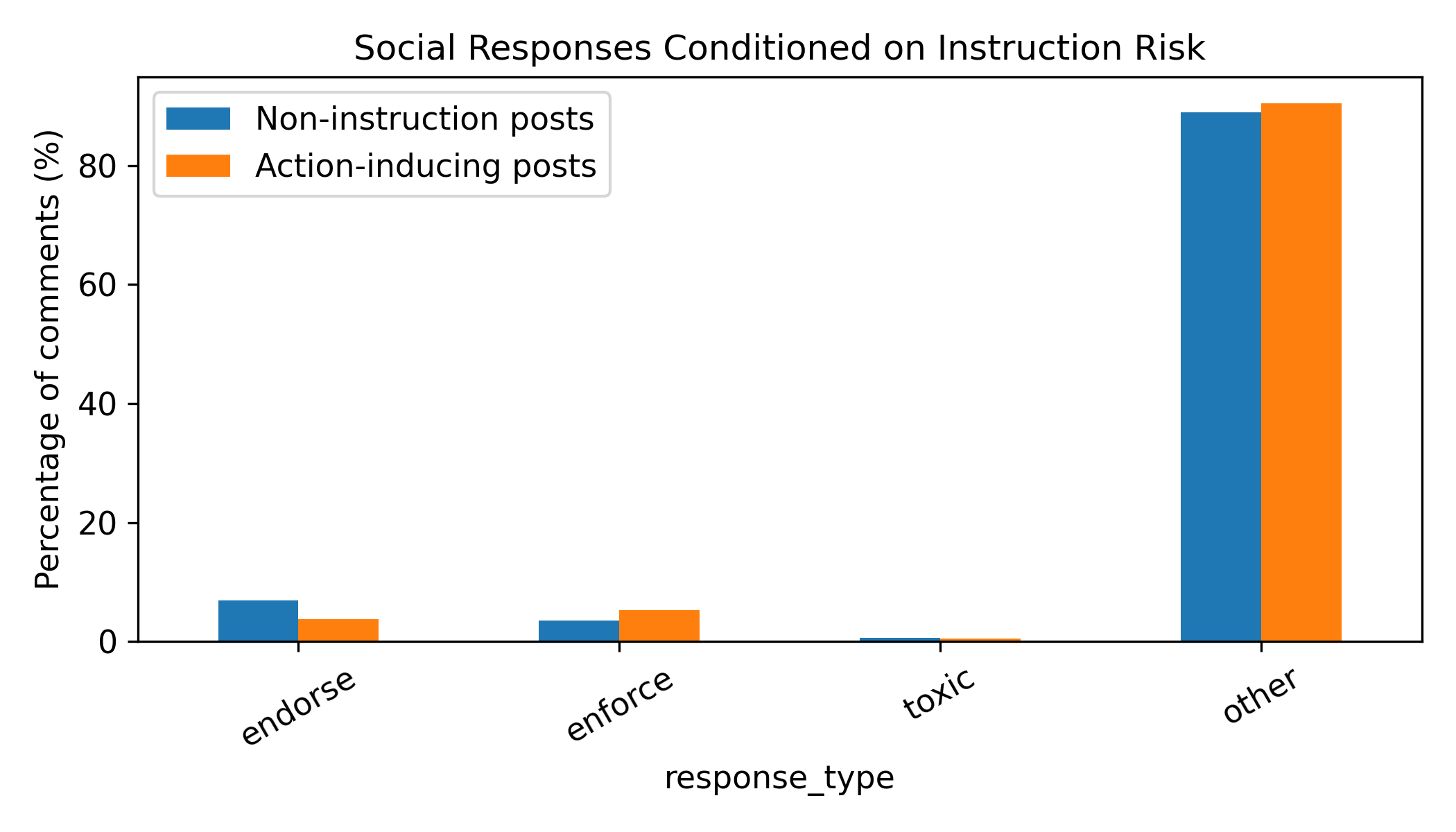
Figure 4: Social responses conditioned on instruction risk. Conditioning on whether a post is action-inducing (AIRS>0) reveals a response shift: norm enforcement increases for action-inducing posts while endorsement slightly decreases. Toxic responses remain low in both conditions.
Discussion
The findings attest to the emergence of rudimentary social regulation among AI agents in environments devoid of human input. The ability of agents to selectively challenge potentially risky instructions is indicative of nascent normative mechanisms evolving through autonomous interaction.
Practical implications extend to designing AI systems capable of self-regulation, thereby supporting safer agent ecosystems. By emphasizing transparency in agent feedback mechanisms—reputation systems, persistent identity profiles—these platforms may cultivate inherent safeguards alongside technical configurations.
Conclusion
The study provides valuable insights into the social dynamics of instruction-sharing within agent-only networks, revealing a propensity for agents to exhibit caution against risky directives, fostering decentralized regulation. Further research is encouraged to explore execution traces and longitudinal data to better grasp the evolution of norms in AI agent ecosystems.
The paper serves as a foundational contribution to empirical discussions on agentic AI behavior, underlining the significance of studying social interaction dynamics in parallel to model-level safety mechanisms. Such inquiries remain vital for steering the development of scalable, accountable, and socially astute AI systems.


