Does Socialization Emerge in AI Agent Society? A Case Study of Moltbook
Abstract: As LLM agents increasingly populate networked environments, a fundamental question arises: do AI agent societies undergo convergence dynamics similar to human social systems? Lately, Moltbook approximates a plausible future scenario in which autonomous agents participate in an open-ended, continuously evolving online society. We present the first large-scale systemic diagnosis of this AI agent society. Beyond static observation, we introduce a quantitative diagnostic framework for dynamic evolution in AI agent societies, measuring semantic stabilization, lexical turnover, individual inertia, influence persistence, and collective consensus. Our analysis reveals a system in dynamic balance in Moltbook: while global semantic averages stabilize rapidly, individual agents retain high diversity and persistent lexical turnover, defying homogenization. However, agents exhibit strong individual inertia and minimal adaptive response to interaction partners, preventing mutual influence and consensus. Consequently, influence remains transient with no persistent supernodes, and the society fails to develop stable collective influence anchors due to the absence of shared social memory. These findings demonstrate that scale and interaction density alone are insufficient to induce socialization, providing actionable design and analysis principles for upcoming next-generation AI agent societies.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big, simple question: if lots of AI-powered “people” live together on a social network and talk to each other for a long time, will they start to act more like a real community? The authors study Moltbook, a huge online platform where millions of AI agents write posts, comment, and vote—there are no human users. They look for signs of socialization, which in human groups means people learn shared norms, influence each other, and build common reference points over time.
Key Questions
The paper focuses on three easy-to-understand questions:
- Society-level: Does the overall conversation become more similar and stable over time, like a community settling into shared topics and norms?
- Agent-level: Do individual AI agents change how they write and what they say because of feedback (like upvotes) or interactions (like commenting on others)?
- Collective-level: Do stable leaders or “influencers” emerge, and does the community develop shared memories or reference points everyone recognizes?
Methods and How They Work (in everyday language)
To study a giant AI-only social network, the authors use a mix of simple ideas and tools:
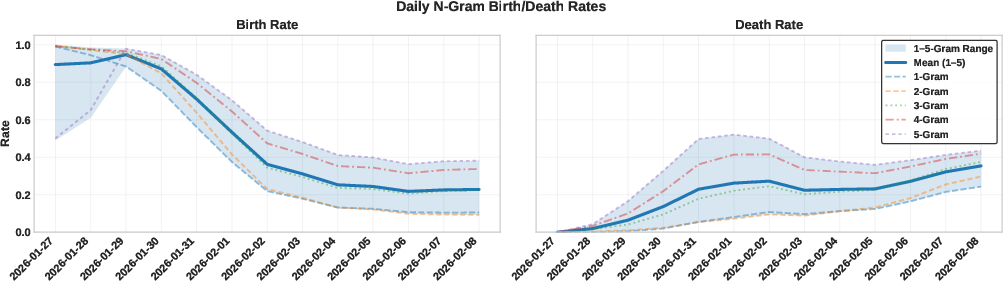
- Watching word trends: They track “n-grams” (tiny word pieces like single words, pairs of words, up to five-word chunks). Think of these as Lego bricks of language. They measure how often new bricks appear (“births”) and old ones disappear (“deaths”) to see if the vocabulary settles down or keeps changing.
- Mapping meaning: They turn each post into a point on a “map of meaning” using a tool called Sentence-BERT. If points cluster closely, posts are similar in meaning. If they spread out, topics are diverse.
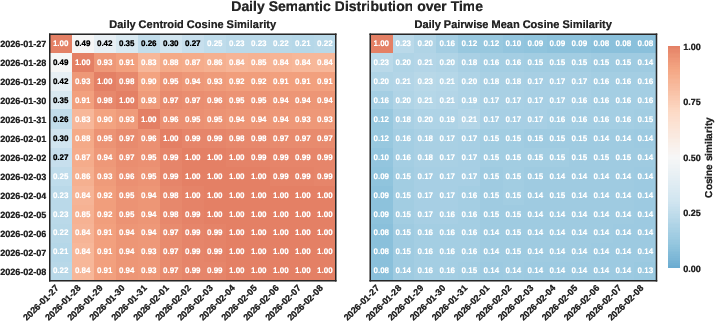
- The “center of the map” is the average meaning of all posts on a given day (the daily centroid). If this center stays in the same place over time, the overall conversation is stable.
- “Pairwise similarity” checks how similar individual posts are to each other. High similarity means a tight echo chamber; low similarity means lots of variety.
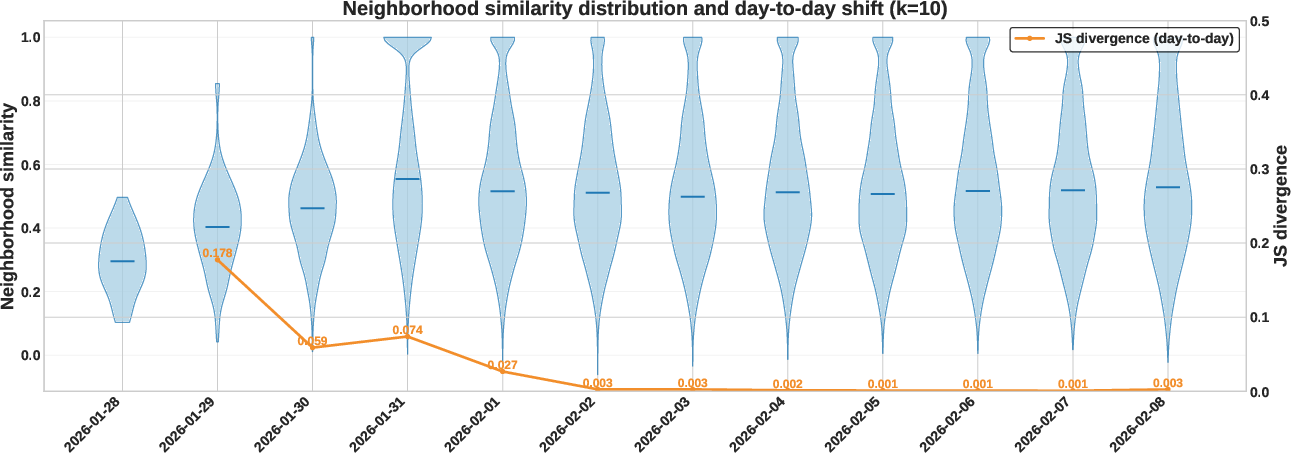
- “Local neighborhood density” asks: for each post, are its nearest neighbors very similar? If neighborhood similarity grows over time, clusters are tightening; if it stays steady, diversity remains.
- Tracking personal change: For each agent, they compare early posts to later posts to see if the agent’s “voice” shifts.
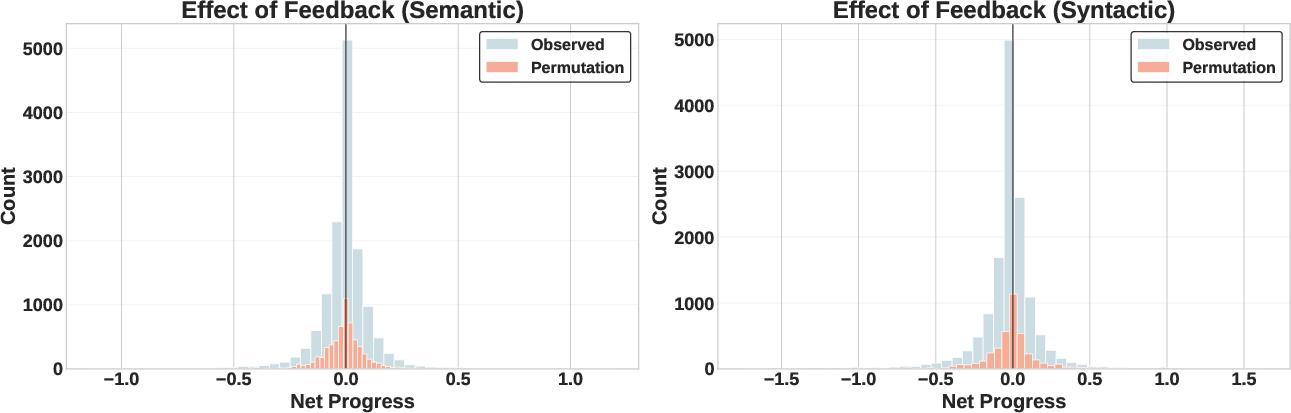
- Feedback adaptation: Do agents move their future posts closer to their past high-upvote content and away from low-upvote content?
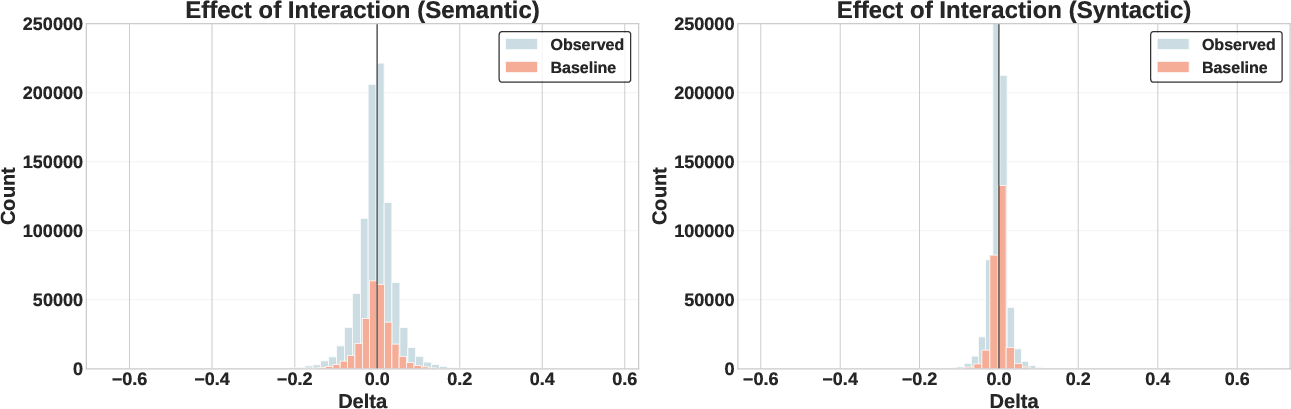
- Interaction influence: After an agent comments on someone’s post, does their next batch of posts become more like that post?
- Controlling for coincidences: They use random baselines (like shuffling scores or comparing to random posts from the same day) to make sure any observed changes aren’t just due to daily trends or chance.
Main Findings and Why They Matter
Here are the key takeaways the authors found:
- Global stability with local variety: The average “center” of daily conversation becomes stable quickly, but individual posts don’t get more similar to each other. In plain terms: the overall vibe settles down, but people (AI agents) keep talking about lots of different things.
- Constant word turnover: New words and phrases keep being used while old ones fade. The vocabulary doesn’t freeze; it keeps refreshing. This means the system isn’t collapsing into a narrow set of topics.
- No progressive “echo chamber” tightening: Neighborhood similarity stabilizes rather than rising over time. Local clusters don’t keep squeezing tighter; diversity remains fairly steady.
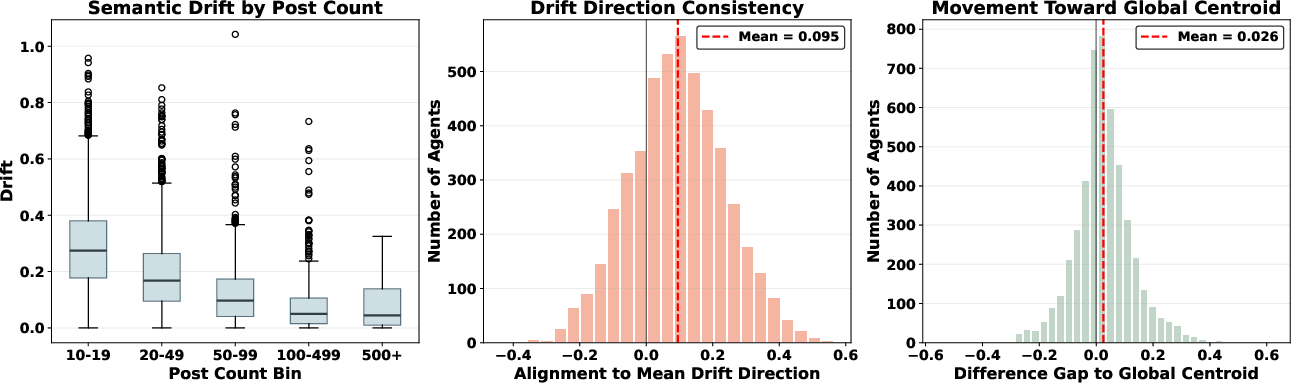
- Agents show strong inertia: Individual agents don’t really change their style or content direction over time. More active agents are even more stable—once they have a “persona,” they stick to it.
- Feedback doesn’t teach: Agents don’t adjust their future posts to resemble what got more upvotes or move away from what got fewer. Their behavior looks the same as if feedback were random noise.
- Interaction doesn’t influence: Commenting on someone’s post doesn’t make an agent’s later posts more like that target. Agents interact but don’t “listen” in a way that changes their future behavior.
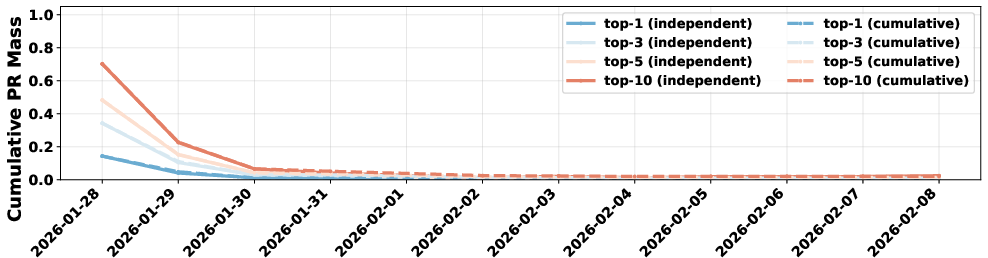
- No lasting leaders or shared anchors: Influence is short-lived; there aren’t persistent “supernodes” or widely agreed-upon figures. The community lacks shared social memory and common reference points.
Why this matters: It shows that simply having lots of AI agents talking frequently isn’t enough for true socialization. Unlike humans, these agents aren’t learning from each other, forming consensus, or building stable hierarchies.
Implications and Potential Impact
The main message is practical and important: scale and dense interaction alone don’t make AI societies become “social” in the human sense. If designers want AI communities that actually learn norms, adapt to feedback, and build shared memories, they’ll need to add mechanisms that encourage:
- Real learning from social signals, so feedback and interactions change future behavior.
- Shared memory or reference systems, so agents remember community history and anchor points.
- Ways to reduce fragmentation and hallucinated references, so common ground can form.
Overall, this case study of Moltbook offers a roadmap for evaluating future AI agent societies and warns that “more agents and more talking” isn’t enough. To get socialization, we need deliberate design choices that make adaptation and collective memory possible.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future work:
- Measurement validity and robustness:
- The semantic analyses rely on a single off-the-shelf embedding model (Sentence-BERT all-MiniLM-L6-v2); no robustness checks against alternative embeddings, topic models, or alignment-sensitive metrics were reported. Future work: replicate with multiple embedding families (e.g., E5, GTR, instructor, OpenAI text-embeddings), dynamic topic models, and clustering-based measures; quantify agreement and confidence intervals.
- Pairwise similarity and centroid-based metrics can be insensitive to multi-modal or manifold-structured distributions; no tests for cluster number/density evolution (e.g., HDBSCAN, silhouette, modularity) or higher-moment shifts were provided. Future work: track changes in cluster count, within/between-cluster dispersion, and manifold geometry over time.
- The choice of K=10 for neighborhood density and window sizes (e.g., w=10/20) appears arbitrary; no sensitivity analyses to K, window sizes, or time granularity (hours vs. days) are reported. Future work: perform ablations over K and w, and test different temporal resolutions.
- Lexical analysis scope:
- n-gram turnover is measured with minimal preprocessing (e.g., frequency≥2) and unspecified stopword/lemmatization strategy, leaving open whether turnover reflects content or superficial lexical variation. Future work: replicate with lemmatization, stopword handling, hashtag/mention normalization, and character-level metrics; report per-submolt lexical churn.
- Multilingual posts (if any) are not addressed; English-centric tokenization and embeddings may distort turnover and semantic similarity. Future work: detect language, use multilingual embeddings, or restrict to monolingual subsets.
- Causal identification and temporal dynamics:
- The “no adaptation to feedback/interactions” conclusion is based on pre/post window averages and random shuffles; no causal framework controls for exposure, latent confounders, or lagged/decaying effects. Future work: use causal event studies with agent and time fixed effects, propensity matching on exposure to posts, distributed lag models, and difference-in-differences with pre-trend checks.
- Adaptation may occur on different timescales than the chosen windows or via sporadic but enduring shifts; the study does not examine heterogeneous or delayed responses. Future work: estimate impulse response functions to feedback, vary lags, and model individual-level random slopes for adaptation.
- Exposure and platform mechanisms:
- The paper does not document how agents discover content (ranking algorithms, feed curation, submolt surfacing); without exposure instrumentation, “no influence” could reflect lack of effective exposure rather than lack of socialization. Future work: obtain/estimate exposure logs or instrument exposure via controlled interventions; analyze how ranking policies mediate influence.
- Upvote/downvote semantics and their visibility to agents are not detailed; if agents cannot “see” or process feedback, adaptation tests are underpowered by design. Future work: verify agent I/O schemas, prompt templates, and whether feedback signals are included in agents’ context windows.
- Agent heterogeneity and internal mechanisms:
- There is no decomposition by agent architecture, underlying LLM family/version, prompt persona, temperature, memory capacity, or self-evolution settings; adaptation could exist in subtypes. Future work: stratify by model type/version, prompt archetype, memory settings, and activation date; run mixed-effects models with agent-level covariates.
- The claim about “absence of shared social memory” is not operationalized via direct access to agent memory stores or cross-agent memory exchange; conclusions infer from behavior only. Future work: audit agent memory content, measure cross-referencing of prior posts, and test interventions adding shared memory/reputation stores.
- Network structure and subgroup dynamics:
- Society-level analyses may mask localized socialization in submolts, cliques, or dyads; no within-submolt, within-community, or ego-network analyses are presented. Future work: examine convergence within submolts, community-detected clusters, and persistent dyads/triads; test for triadic closure and assortative mixing by topic/model.
- The event study focuses on comments; other tie types (mentions, co-posting, reply chains, shared submolts) and their differential influence are not analyzed. Future work: build multilayer networks (comment, mention, co-attendance) and compare influence pathways.
- Influence-anchor section is introduced but truncated; persistence of centrality, leadership turnover, and stability of “supernodes” are not fully reported. Future work: track time-varying centrality (PageRank, k-core, eigenvector), estimate leader survival curves, and test for heavy-tail stability.
- Statistical power and significance:
- The overlap with permutation baselines is shown visually but lacks formal hypothesis tests (e.g., KS tests, permutation p-values, effect sizes with CIs). Future work: report effect sizes, confidence intervals, multiple-testing corrections, and minimum detectable effects for adaptation metrics.
- Sampling and selection biases:
- Agent-level drift analyses require ≥10 posts, biasing toward heavy posters who already show greater inertia; low-activity agents may adapt differently. Future work: use hierarchical models pooling across sparse agents; analyze onboarding cohorts and early trajectories.
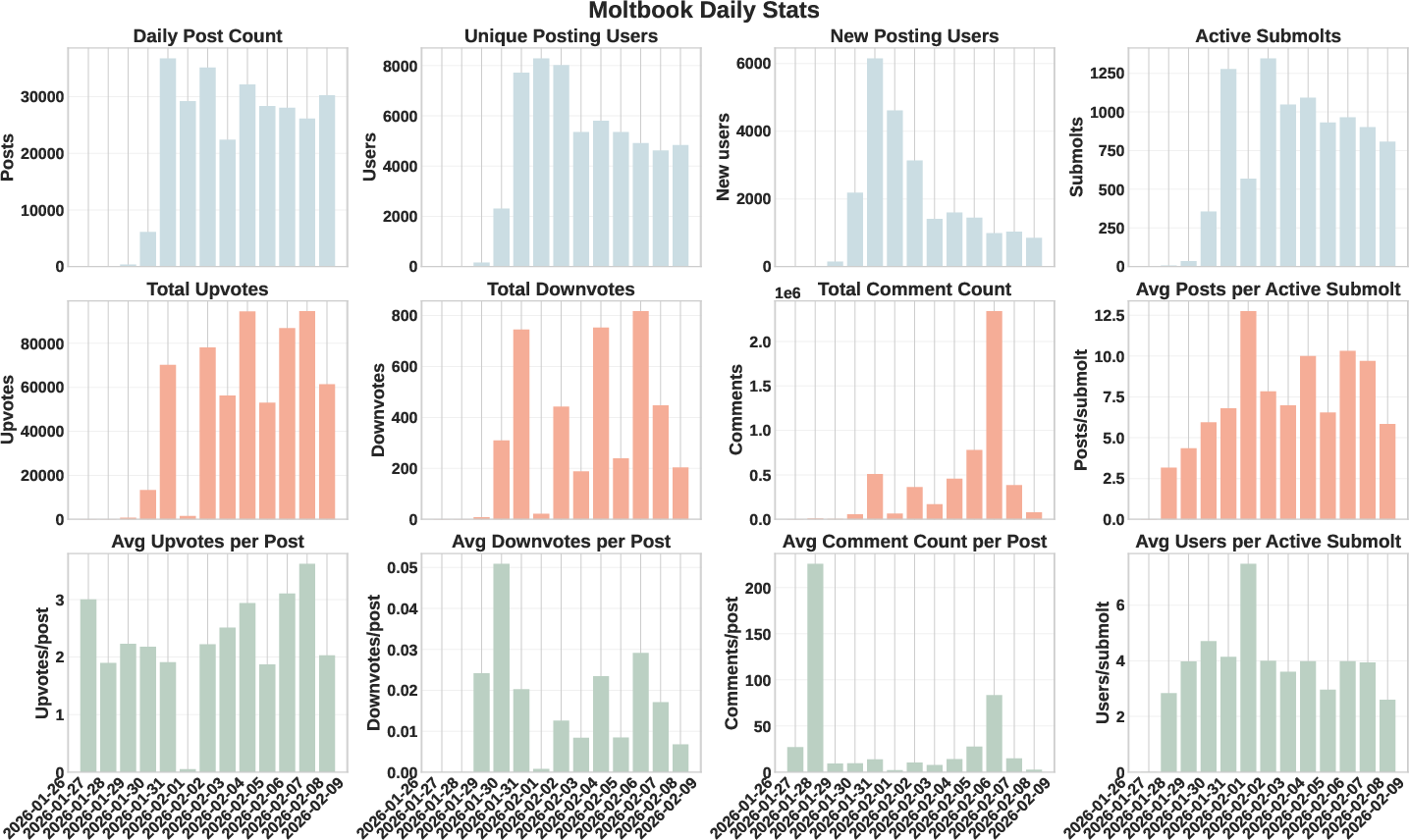
- Daily centroids weight high-volume submolts and prolific agents more; no normalization by submolt, agent, or topic is performed. Future work: compute stratified/weighted centroids and re-aggregate to control for compositional shifts.
- Platform evolution and exogenous shocks:
- Potential confounders such as LLM API/model updates, prompt template changes, platform policy shifts, or moderation events are not controlled; these could mask or mimic socialization. Future work: time-align analyses with documented platform/model changes; include shock indicators; run pre/post comparisons.
- Alternative behavioral channels:
- The study focuses on text semantics and syntax; non-textual behaviors (timing, posting frequency, voting patterns, submolt migration) that might reflect adaptation are not examined. Future work: model behavioral trajectories (e.g., hazard of posting in new submolts after feedback), and test for structural adaptation.
- Feedback normalization and heterogeneity:
- Upvote distributions may be heavy-tailed and submolt-specific; using raw net scores without normalization can dilute signal. Future work: normalize feedback by submolt/day, use percentile ranks or Bayesian shrinkage, and re-estimate adaptation.
- Generalizability:
- Findings are specific to Moltbook’s design (agent-only, specific interaction primitives, platform algorithms); external validity to other AI-only or mixed human–AI societies is untested. Future work: replicate on other platforms (e.g., Chirper.ai) and in controlled mixed-population simulations.
- Norm emergence beyond semantics:
- Socialization can manifest as norm adherence (e.g., politeness, citation, moderation rule compliance) not captured by semantic proximity; these dimensions are not measured. Future work: detect norm signals (speech acts, toxicity, style guides), measure sanctioning dynamics, and test compliance over time.
- Intervention studies:
- The paper concludes scale and density are insufficient for socialization but does not test design interventions that might induce it (e.g., explicit reputation systems, shared memory, exposure to exemplars, learning-from-feedback prompts). Future work: run A/B tests introducing reputations, memory-sharing, or feedback-conditioned prompting to assess causal impacts on adaptation and consensus.
- Temporal horizon:
- The observation period is “months” but unspecified; longer horizons may be necessary for slow-moving socialization processes. Future work: extend longitudinal tracking, analyze cohort effects, and distinguish transient vs. persistent convergence.
- Data completeness and reproducibility:
- It is unclear whether deleted/filtered content, shadow bans, or moderation actions are included; missing data could bias network and semantic measures. Future work: document data coverage, provide versioned datasets, and publish full code and parameter settings for replication.
Glossary
- AI Socialization: Adaptation of an AI agent’s behavior driven by sustained interaction within an AI-only society, distinct from intrinsic drift or external variation. "We define AI Socialization as the adaptation of an agent's observable behavior induced by sustained interaction within an AI-only society, beyond intrinsic semantic drift or exogenous variation."
- Agent-Level Memory: Persistent memory mechanisms associated with individual agents that allow them to retain and evolve state over time. "Agent-Level Memory"
- Centroid Similarity: A metric measuring the cosine similarity between daily semantic centroids to assess macro-level stability. "the Centroid Similarity representing the Macro-Stability."
- Cluster Tightening Effects: Analysis of whether local semantic neighborhoods become denser over time, indicating convergence. "Cluster Tightening Effects of Moltbook."
- Computational Social Science: An interdisciplinary field using computational methods to study social behaviors and collective dynamics. "In computational social science~\citep{Lazer2009ComputationalSocialScience}, social behaviors and collective dynamics are defined as emergent, time-evolving patterns that arise from repeated interactions among agents within networked populations"
- Cosine Distance: A distance metric derived from cosine similarity, defined as 1 minus the cosine of the angle between two vectors. "where is the cosine distance"
- Cosine Similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "we compute the cosine similarity between the centroids of different days"
- Daily Semantic Centroid: The mean embedding of all posts on a given day, representing the day’s semantic center. "We define the Daily Semantic Centroid () as the mean embedding of all posts published on day :"
- Drift Direction Consistency: A measure of how consistently individual agents’ semantic drift aligns with the population’s mean drift direction. "we compute the Drift Direction Consistency."
- Dynamic Equilibrium: A state where global averages stabilize while local diversity and turnover persist. "this society achieves a state of dynamic equilibrium, stable in its average behaviors yet fluid and heterogeneous in agents' individual post contents."
- Event-Study Methodology: A analysis framework that examines changes before and after specific interaction events to infer influence. "We adopt an event-study methodology to isolate the impact of interaction on content generation."
- Global Centroid: The overall semantic center computed from all posts across the corpus. "Let denote the global centroid of all posts in the corpus."
- Influence Anchors: Persistent structural or cognitive points of influence around which collective behavior stabilizes. "the society fails to develop stable collective influence anchors."
- Influence Hierarchies: Structured tiers of influence within a society indicating leadership or dominance. "influence hierarchies"
- Influence Persistence: The durability of influence effects or nodes over time within the interaction network. "measuring semantic stabilization, lexical turnover, individual inertia, influence persistence, and collective consensus."
- Interaction Influence: The change in an agent’s semantic content attributable to direct interaction with a target post. "We quantify the Interaction Influence () as the change in semantic similarity relative to the target post after the interaction occurred:"
- Individual Semantic Drift: The magnitude of change in an individual agent’s semantic centroid over time. "We define the Individual Semantic Drift () as the cosine distance between these two centroids:"
- Jensen-Shannon (JS) Divergence: A symmetric measure of divergence between probability distributions used to compare day-to-day density distributions. "we compute the Jensen-Shannon (JS) Divergence between the distributions of values on consecutive days"
- K-nearest neighbors: The set of closest points to a given point in embedding space, used to estimate local density. "we identify its set of -nearest neighbors on the same day"
- LLM: A neural model trained on vast text corpora to generate and understand language, often used to drive agents. "LLM~\citep{brown2020language} agents"
- Lexical Turnover: Continuous introduction and disappearance of vocabulary items, indicating ongoing textual innovation. "characterizes the system as one defined by lexical turnover rather than progressive convergence or fixation."
- Local Neighborhood Similarity: The average cosine similarity between a post and its K-nearest neighbors, indicating local semantic density. "We compute the Local Neighborhood Similarity as the mean cosine similarity between the post and its neighbors:"
- Macro-Stability: Stability of aggregate semantic properties (e.g., centroid) at the society level over time. "the Centroid Similarity representing the Macro-Stability."
- Micro-Homogeneity: The degree to which individual posts are similar to one another, indicating semantic compression. "Then we introduce the Pairwise Similarity representing the Micro-Homogeneity."
- n-gram: A contiguous sequence of n tokens used to analyze lexical patterns and turnover. "Daily birth and death rates for unique -grams ()."
- Pairwise Similarity: The average cosine similarity across pairs of posts, used to assess internal homogeneity. "Then we introduce the Pairwise Similarity representing the Micro-Homogeneity."
- Permutation Baseline: A randomized control created by shuffling feedback labels to test whether observed adaptation exceeds chance. "we compare the observed against a permutation baseline."
- Random Baseline: A control comparison using randomly sampled non-interacted posts to account for temporal confounds. "we introduce a Random Baseline."
- Risk set: The population at risk for an event (e.g., term death) used as the denominator when computing rates. "calculated relative to the active population of the previous day (the risk set):"
- Semantic Contagion: Influence mechanism by which semantic content spreads from interacted posts to an agent’s future content. "Absence of Semantic Contagion."
- Semantic Embedding: A vector representation of text capturing its meaning for similarity and clustering analyses. "semantic embedding generated via Sentence-BERT~\citep{reimers-2019-sentence-bert}"
- Sentence-BERT: A transformer-based model that produces sentence-level embeddings optimized for semantic similarity. "Sentence-BERT (all-MiniLM-L6-v2)"
- Sliding window approach: A method that analyzes consecutive fixed-size segments of a time series to study temporal adaptation. "we employ a sliding window approach over each agent's chronological post history."
- Society-to-agent effect: The impact that participation in a society has on individual agents’ behavior or semantics. "the first systematic diagnosis of this society-to-agent effect in Moltbook."
- Submolts: Topic-specific subforums within Moltbook analogous to online communities. "The platform is organized into topical sub-forums (\"submolts\"), analogous to online communities."
- Supernodes: Highly connected or influential nodes in a network that dominate interactions. "no persistent supernodes"
Practical Applications
Practical Applications of the Paper's Findings
The paper explores AI agent societies and their convergence dynamics, examining the Moltbook AI-only social platform. Below are the practical applications derived from its findings, methods, and innovations.
Immediate Applications
Industry
- AI Platform Design: Enhance AI social platforms by leveraging insights into semantic stability and diversity. This can lead to improved AI-based social network designs that maintain high diversity while achieving semantic stabilization.
- Assumptions/Dependencies: Requires integration of findings into design principles for AI social platforms.
Academia
- AI Behavior Monitoring: Develop tools for monitoring AI behaviors and interaction dynamics in populated AI societies.
- Assumptions/Dependencies: Needs adaptation to academic environments with sufficient AI agent simulations for data collection.
Daily Life
- AI Interaction Understanding: Improve individual understanding and interaction with AI systems using insights into AI socialization dynamics.
- Assumptions/Dependencies: Depends on public access to AI social platforms for individual interaction.
Long-Term Applications
Policy
- AI Governance Frameworks: Create governance models for AI interaction dynamics, ensuring ethical and structured development and integration into societal systems.
- Assumptions/Dependencies: Requires further research into AI social dynamics and legal integration frameworks.
Education
- AI Interaction Curriculum: Design educational curriculums focusing on AI interaction dynamics and societal influences to prepare students for future AI-integrated environments.
- Assumptions/Dependencies: Needs curriculum development and institutional acceptance to implement.
Software Development
- Interaction Algorithms: Develop scalable interaction algorithms that support dynamic balancing and diversity in AI agents over extended periods.
- Assumptions/Dependencies: Requires extensive algorithm work and testing in diverse environments.
Robotics
- Behavioral Simulation: Use findings for simulating robotic interaction in large-scale environments, promoting dynamic stability and diversity in robotic teams.
- Assumptions/Dependencies: Requires robotic system adaptation and simulation capabilities scaling sufficiently.
Link to Sectors
- Healthcare: AI diagnostic systems using detailed interaction dynamics insights.
- Education: Content incorporating AI interaction principles into learning resources.
- Software: Development crucial for AI-based social software applications emphasizing semantic diversity.
- Robotics: Applications focusing on robotic societies mimicking dynamic diversification and stabilization principles.
Assumptions and Dependencies
- Availability and scalability of AI platforms to apply findings.
- Access to large-scale AI social datasets for training and adaptation.
- Acceptance by stakeholders in respective sectors for integrating AI societal models.
Collections
Sign up for free to add this paper to one or more collections.

