- The paper demonstrates that norm-guided, stateless LLM agents on the YSocial platform can reproduce key activity and network patterns observed in the real Voat community.
- It employs a reverse-chronological feed and Zipf-distributed action budgets, revealing elevated toxicity and a more diffuse core compared to empirical data.
- The study shows strong semantic and stylistic alignment with real posts while highlighting limitations due to the lack of agent memory and simplified feedback mechanisms.
Operational Validation of LLM Agent Social Simulation: Evidence from Voat v/technology
Introduction and Theoretical Framing
This paper presents a rigorous operational validation of LLM agent-based social simulation, using a digital twin of Voat's v/technology community as a testbed. The study is situated within the emerging paradigm that conceptualizes LLMs as cultural and social technologies, emphasizing their role as carriers of compressed cultural knowledge and conversational norms rather than as utility-maximizing agents [farrell2025large, brinkmann2023machin-a]. The simulation leverages the YSocial framework, instantiating agents with concise personas and norm-guided action selection, and evaluates whether aggregate patterns characteristic of real online communities emerge from machine–machine interaction under realistic platform constraints.
Simulation Architecture and Design
The simulation is implemented on YSocial, a modular digital twin platform that separates platform state, simulation orchestration, and stateless LLM agent services. Agents are instantiated with sampled personas (demographics, political leaning, interests, education, toxicity propensity) and operate under platform rules for posting, commenting, link sharing, and daily activity cycles. The agent LLM is Dolphin 3.0 (Llama 3.1 8B), selected for its uncensored, open-source nature to avoid alignment artifacts and ensure reproducibility.
Key design choices include:
- Stateless micro-dialogues: Agents do not retain long-term memory; all context is passed per action, emphasizing local appropriateness.
- Reverse-chronological feed: Content visibility is limited to a 180-round window, anchoring agent decisions in recent context.
- Heavy-tailed activity budgets: Action budgets per round are Zipf-distributed (s=2.5), inducing realistic participation skew.
- Fixed link catalog: Content is seeded from a curated set of 1000 URLs drawn from Voat's v/technology, spanning 30+ technology domains, to ensure topical fidelity and reproducibility.
Population dynamics are controlled via daily churn and growth rates, with new agents sampled to maintain a volatile, small-community regime matching Voat's empirical statistics.
Calibration and Evaluation Methodology
Calibration is grounded in the MADOC dataset, using 10 non-overlapping 30-day windows from Voat's v/technology to set targets for user activity, thread depth, and turnover. The simulation is evaluated on operational validity: the degree to which aggregate distributions and meso-level structures (activity rhythms, network topology, toxicity, topic coverage, named-entity structure, and stylistic convergence) align with those observed in the reference community, without aiming for one-to-one reproduction of specific users or texts [larooij2025do, anthis2025llm-a].
Empirical Results
Activity Patterns and Participation Skew
The simulation reproduces the scale and volatility of daily activity observed in Voat, with comparable numbers of posts, comments, and unique active users per day. Both corpora exhibit short threads and modest daily volumes.
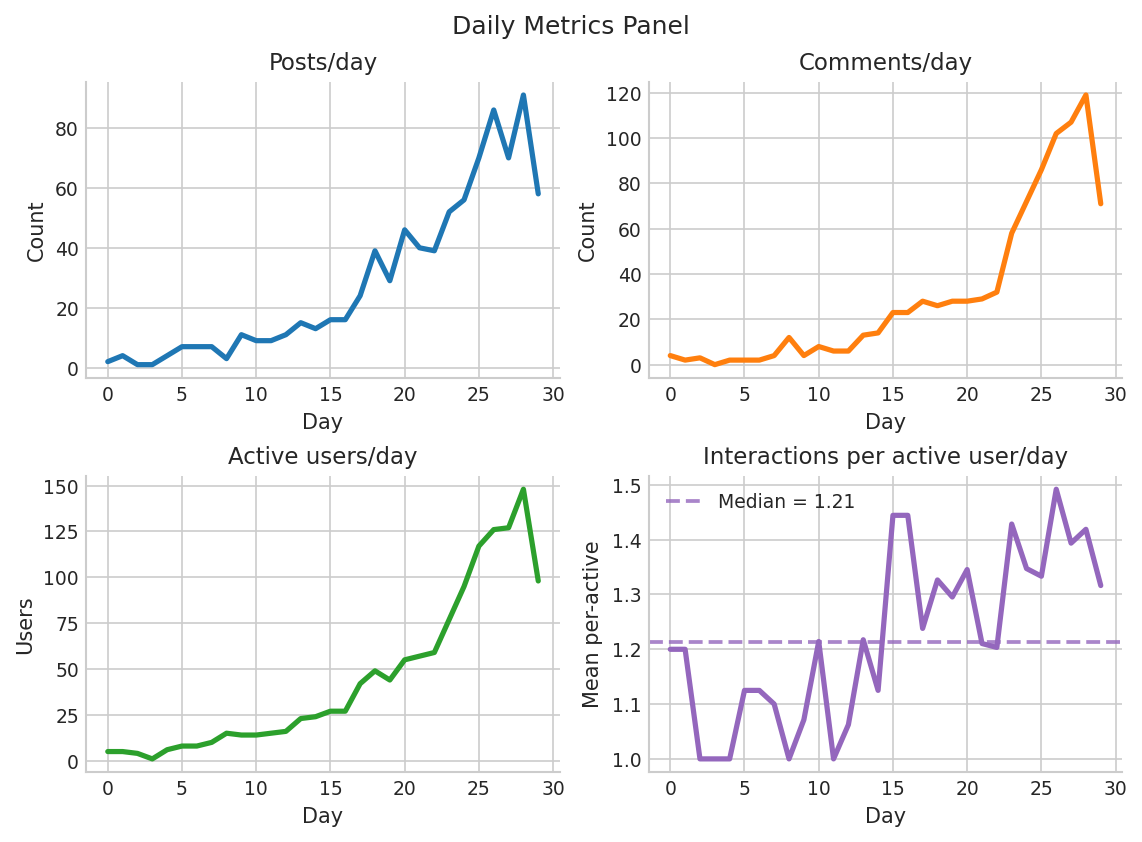
Figure 1: Daily activity over the 30-day window for the simulation and a matched Voat v/technology sample, showing comparable scales and rhythms.
The distribution of posts per user is heavy-tailed, consistent with empirical social media participation patterns, though the simulation's right tail is attenuated due to bounded per-round activity budgets.
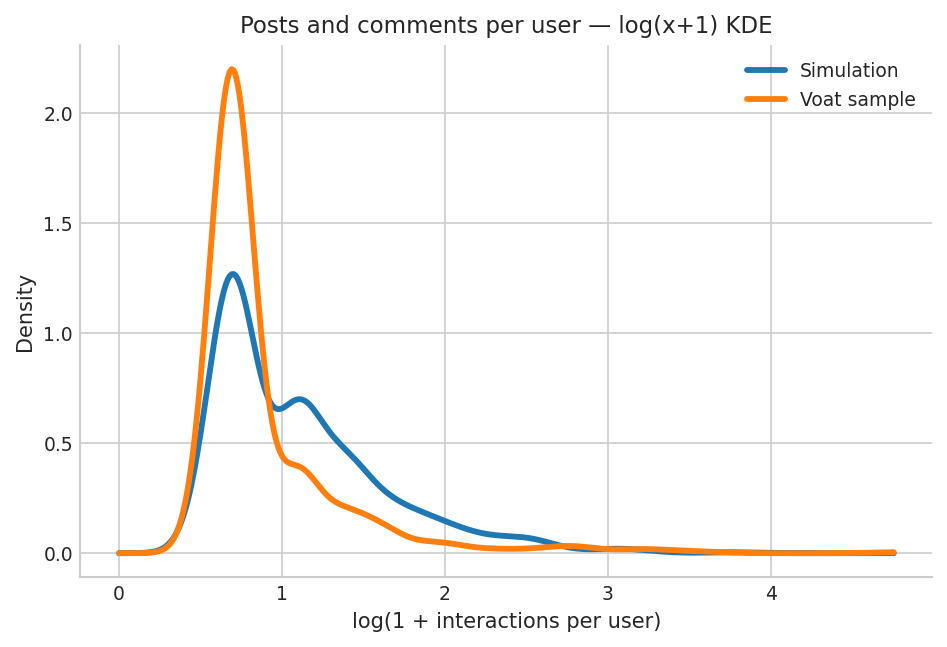
Figure 2: KDE of log(posts+1) per user, illustrating heavy participation skew in both simulation and Voat.
Network Structure and Core–Periphery Organization
Interaction networks in both the simulation and Voat are sparse, low-clustering, and exhibit similar average degrees (≈2.2). Degree distributions are heavy-tailed, indicating participation inequality.
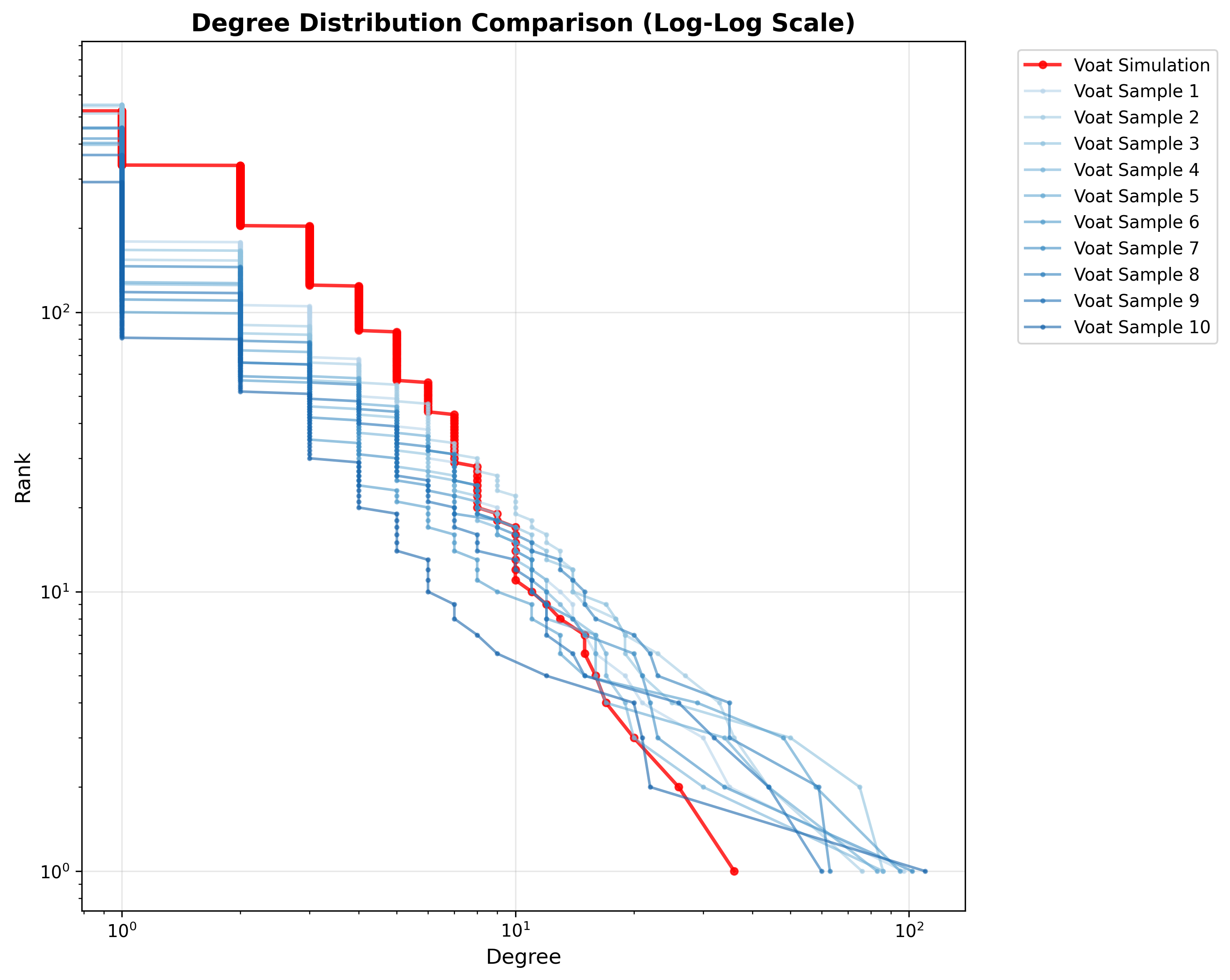
Figure 3: Degree distribution (log–log) for the Voat interaction network, highlighting heavy-tailed structure.
Core–periphery analysis reveals robust non-empty cores in both settings. However, the simulated core is larger and more diffuse, with weaker core–periphery coupling compared to Voat, which exhibits a smaller, denser, and more tightly coupled core. This divergence is attributed to the simulation's stateless design and uniform activity parameters, which dampen hub consolidation.
Toxicity Dynamics
Toxicity is quantified using a RoBERTa-based classifier trained on ToxiGen. The simulation exhibits a higher mean toxicity (0.1532 vs. 0.1054) and heavier upper tail than Voat, with 21.7% of simulated items exceeding a toxicity score of 0.25 (vs. 15% in Voat). Notably, the simulation narrows the expected post–comment toxicity gap: in Voat, comments are much more toxic than root posts, whereas in the simulation, root posts are substantially more toxic than in the real data.
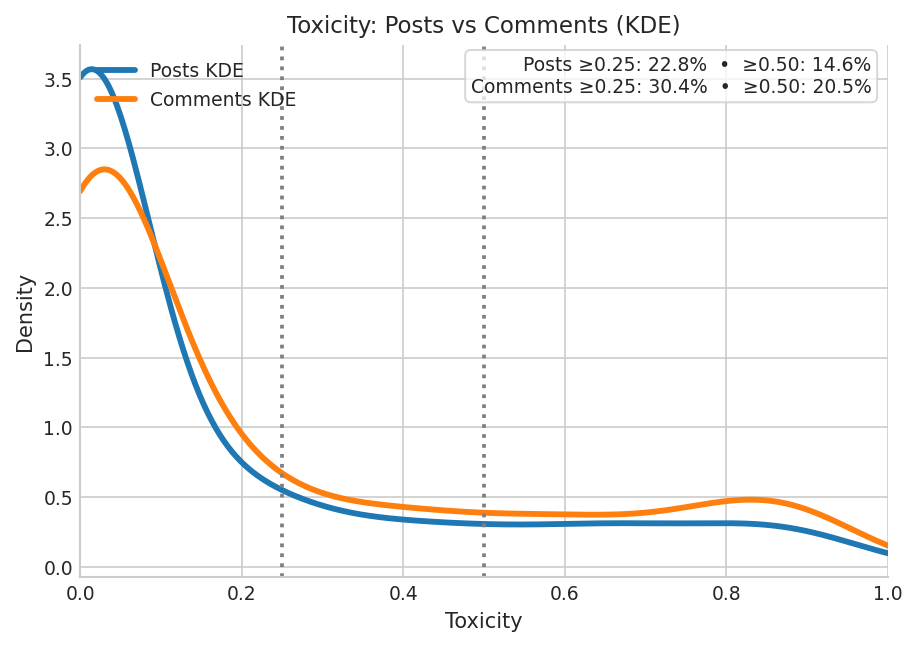
Figure 4: Toxigen score distributions (KDE) for simulation posts and comments, showing elevated toxicity in simulated posts.
Semantic and Topical Alignment
Topic modeling (BERTopic with MiniLM embeddings) demonstrates strong alignment of core technology themes between simulation and Voat. 94% of simulation topics have at least one Voat match above cosine 0.60, with mean top-match cosine 0.737. Item-level nearest-neighbor analysis shows that roughly half of simulation posts find a Voat post at cosine ≥0.60, while comments are more stylistically dispersed.
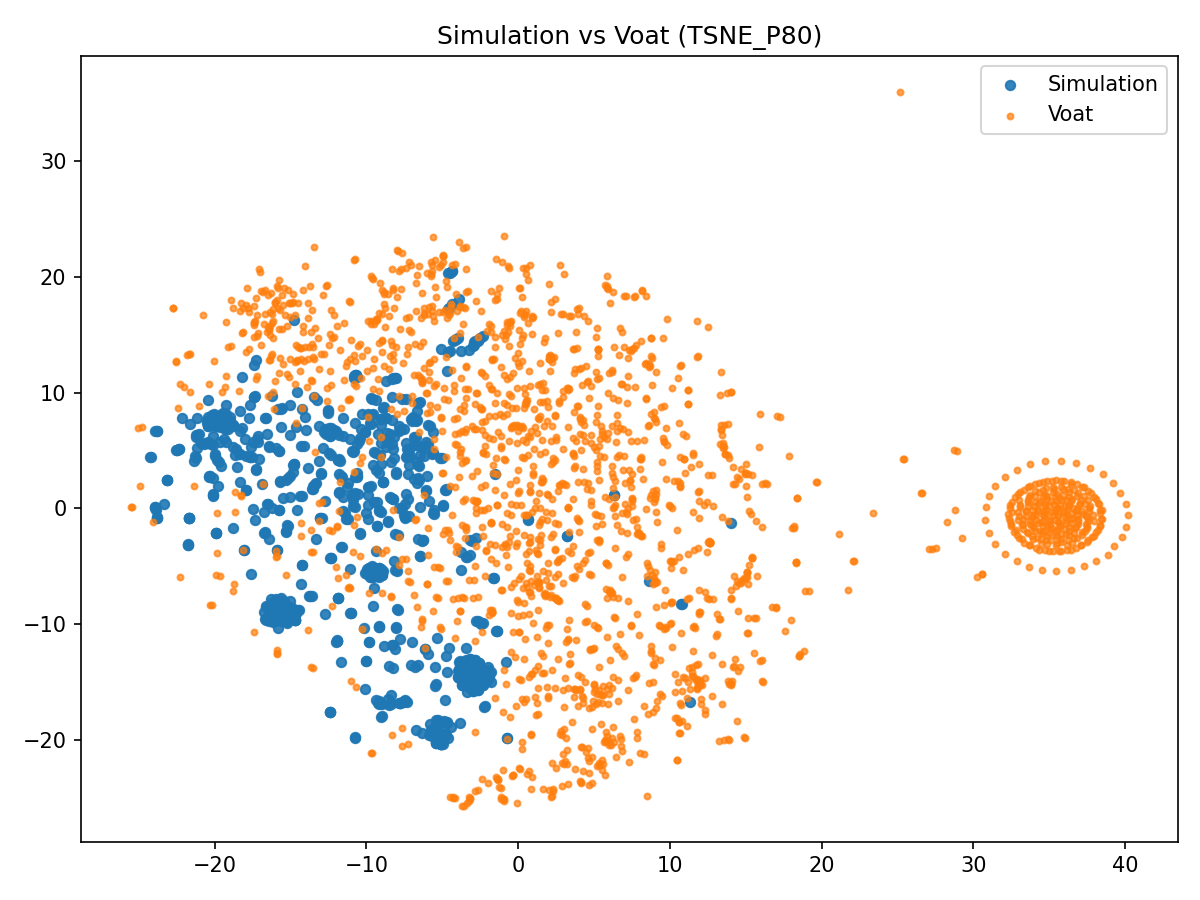
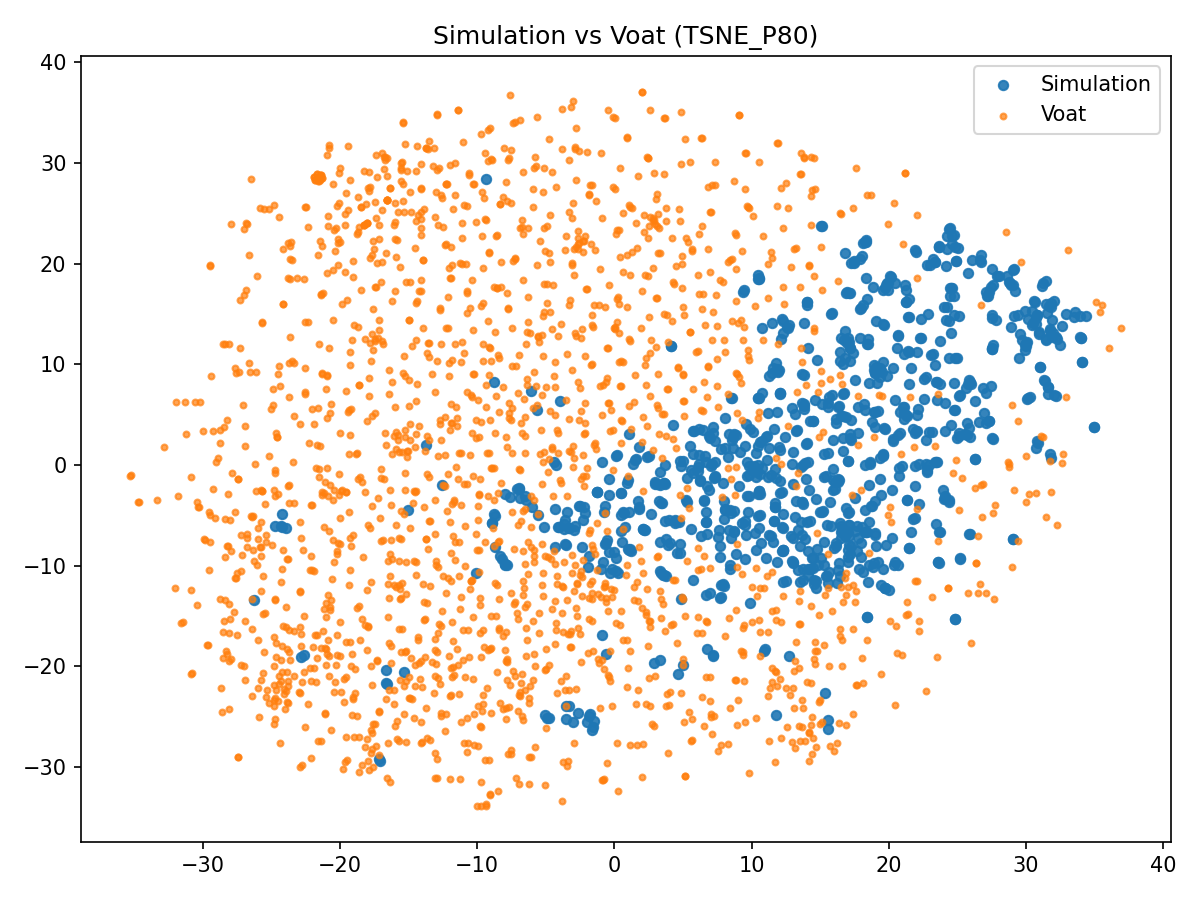
Figure 5: t-SNE projection of simulation and Voat posts, showing partial overlap in embedding space.
Named Entity Structure
Named entity recognition reveals similar distributions of ORG, PERSON, and GPE labels across corpora, with the simulation slightly over-representing PERSON entities and under-representing ORG entities relative to Voat. Top-entity overlap is modest but improves when restricted to posts.
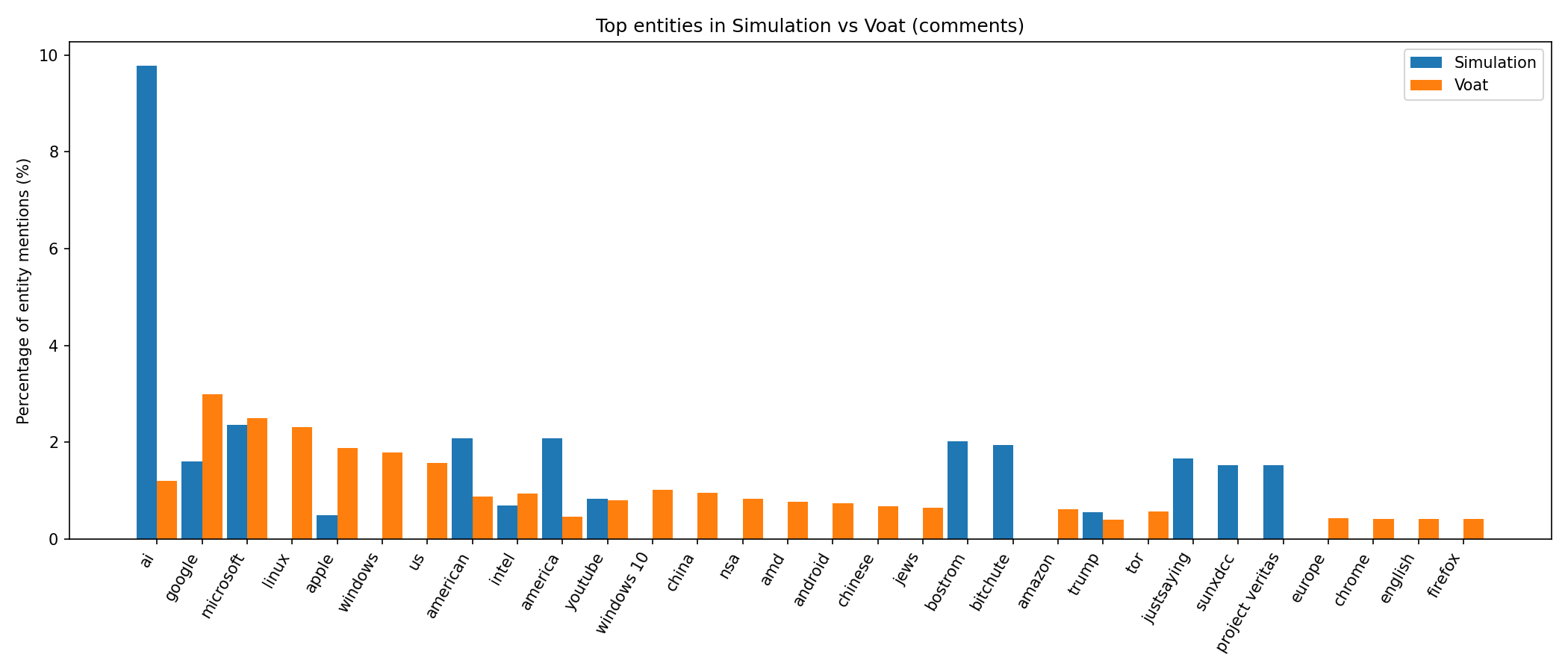
Figure 6: Named-entity frequency comparison (top-30 ORG/GPE) between the simulation and Voat comments.
Stylistic Convergence
Convergence entropy, measuring predictability of replies in alternating A–B chains, shows that stylistic accommodation is present and decays with lag, matching the configured thread reading window (K=3). There is no systematic difference between interpersonal and intrapersonal pairs, indicating that persona prompting without memory does not induce strong within-agent stylistic consistency.
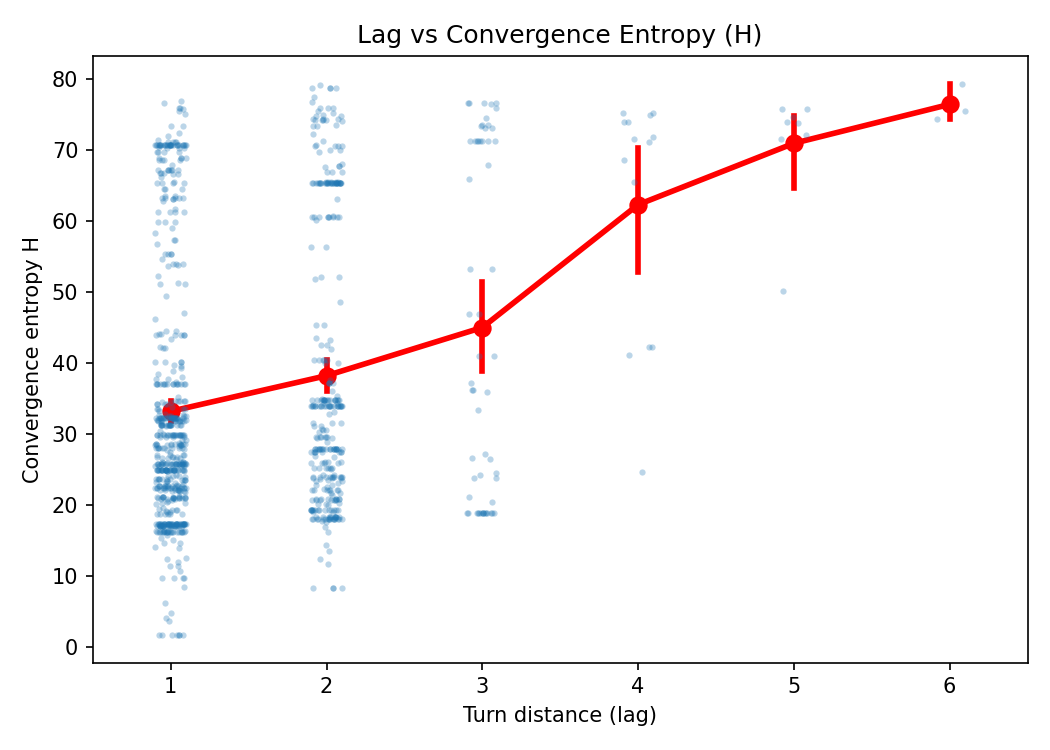
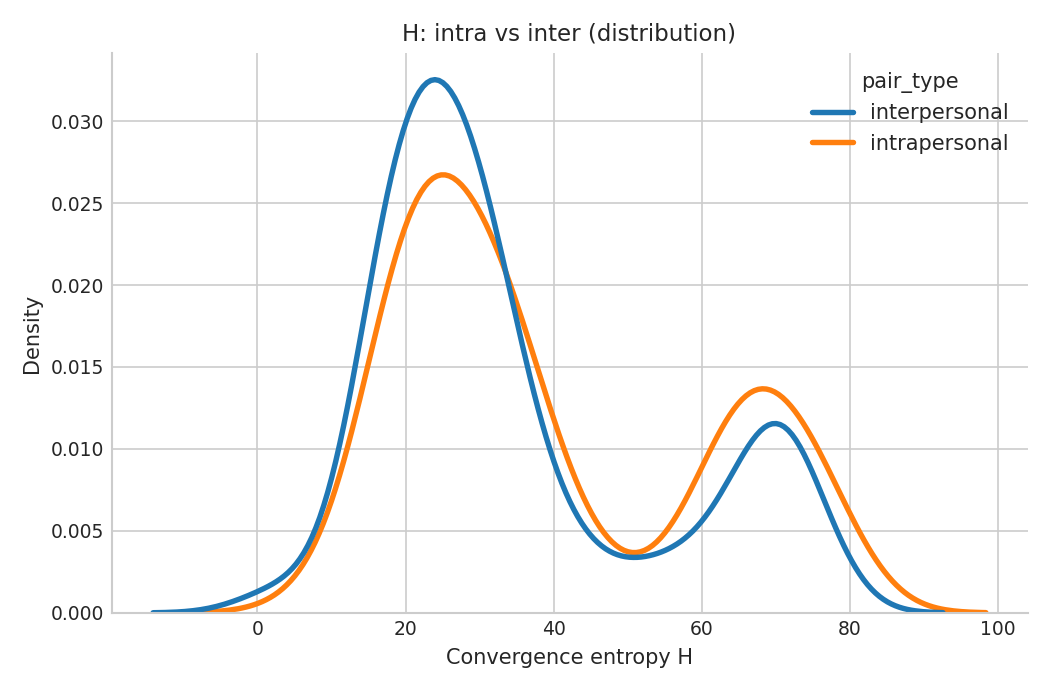
Figure 7: Convergence entropy (H) as a function of lag, showing decay in alignment with increasing turn distance.
Discussion, Limitations, and Implications
The study demonstrates that norm-guided, stateless LLM agents embedded in a platform-faithful environment can recover a wide range of aggregate and meso-level patterns characteristic of real online communities. The operational validity framework—focusing on structural resemblance at the right scale—enables reproducible, falsifiable baselines for future research and intervention testing.
Key divergences include a more diffuse simulated core, elevated post-layer toxicity, and limited stylistic differentiation, all traceable to the stateless, per-action design and simplified feedback mechanisms. The absence of agent memory constrains identity formation and long-range alignment, highlighting the need for future work on lightweight memory architectures and more nuanced activity distributions.
The platform-faithful setup supports controlled "what-if" experiments on feed algorithms, moderation policies, and action menus, and is readily transferable to other communities by updating content seeds and persona priors. The same evaluation axes—activity, network structure, toxicity, semantic coverage, and convergence—provide a robust panel for cross-setting comparison.
Conclusion
This paper provides a comprehensive operational validation of LLM agent-based social simulation, establishing that norm-guided, stateless agents can reproduce key structural and semantic features of real online communities under realistic platform constraints. The findings underscore both the promise and the current limitations of LLM-driven generative social simulation, particularly regarding memory, core consolidation, and toxicity dynamics. The methodology and evaluation framework offer a transparent, reproducible foundation for future research on online social systems, including mixed human–machine studies and intervention testing. The results motivate further development of agent architectures with memory and more sophisticated feedback, as well as systematic exploration of platform design levers and their impact on emergent social phenomena.