Loopholing Discrete Diffusion: Deterministic Bypass of the Sampling Wall
Abstract: Discrete diffusion models offer a promising alternative to autoregressive generation through parallel decoding, but they suffer from a sampling wall: once categorical sampling occurs, rich distributional information collapses into one-hot vectors and cannot be propagated across steps, forcing subsequent steps to operate with limited information. To mitigate this problem, we introduce Loopholing, a novel and simple mechanism that preserves this information via a deterministic latent pathway, leading to Loopholing Discrete Diffusion Models (LDDMs). Trained efficiently with a self-conditioning strategy, LDDMs achieve substantial gains-reducing generative perplexity by up to 61% over prior baselines, closing (and in some cases surpassing) the gap with autoregressive models, and producing more coherent text. Applied to reasoning tasks, LDDMs also improve performance on arithmetic benchmarks such as Countdown and Game of 24. These results also indicate that loopholing mitigates idle steps and oscillations, providing a scalable path toward high-quality non-autoregressive text generation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to make “diffusion” models better at writing text. Diffusion models can create full sentences or paragraphs by refining rough guesses step by step, all at once across the whole sentence. They’re fast, but they have a common problem: once they pick a specific word, they lose track of how likely other words were. The authors call this the “sampling wall.”
To fix that, they propose a simple idea called “Loopholing.” It adds a memory-like path that carries rich information forward between steps, so the model doesn’t forget what it knew before it chose a word. Models that use this idea are called Loopholing Discrete Diffusion Models (LDDMs), and they produce more coherent text and do better on reasoning tasks.
Key Questions
The paper focuses on these easy-to-understand questions:
- Why do discrete diffusion models (which generate tokens like words or symbols) sometimes produce lower-quality text than traditional models that write one word at a time?
- What is the “sampling wall,” and how does it cause wasted steps and unstable changes in the generated text?
- Can we design a simple mechanism to carry forward useful information at every step to improve quality and reasoning?
- How much does this mechanism improve real tasks like text generation and math puzzles?
Methods and How They Work
To make sense of the approach, let’s break down a few terms and use everyday analogies:
What is a diffusion model?
Imagine you start with a very noisy sentence (like a sentence covered in smudges) and then clean it up a little bit at a time. A diffusion model does this in many steps, gradually turning noise into meaningful text. For discrete data like words, each step guesses a distribution over possible words for each position.
- Autoregressive models: write one word at a time from left to right.
- Discrete diffusion models: refine all positions in parallel, step by step.
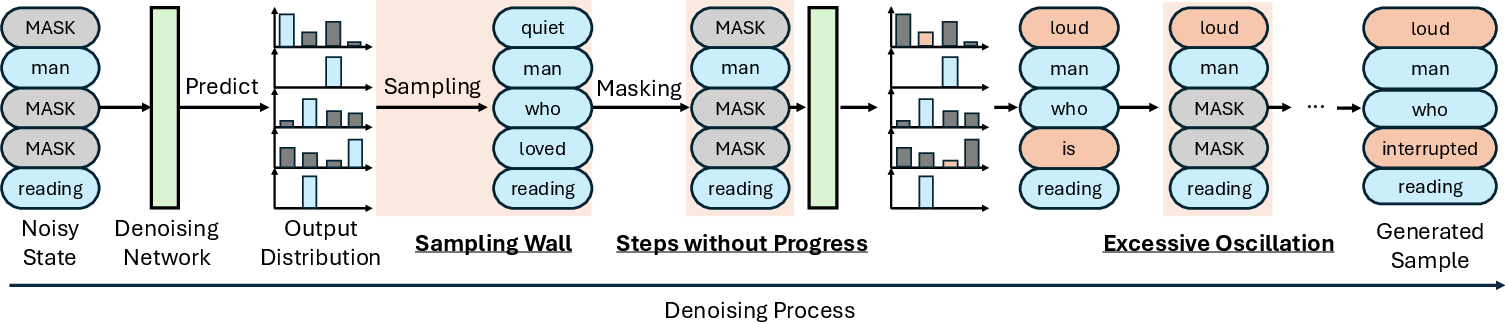
What is the “sampling wall”?
When the model is deciding on a word, it has a full “probability picture” that says, “Word A is 49% likely, Word B is 51% likely,” and so on. But once it samples and picks Word B, it throws away the entire picture and only keeps “B.” That discard creates a “wall,” because the next step doesn’t know that A was almost chosen too. This can lead to:
- Idle steps: repeating the same choice without making progress.
- Oscillations: flipping choices back and forth because the model has to rebuild context from scratch each step.
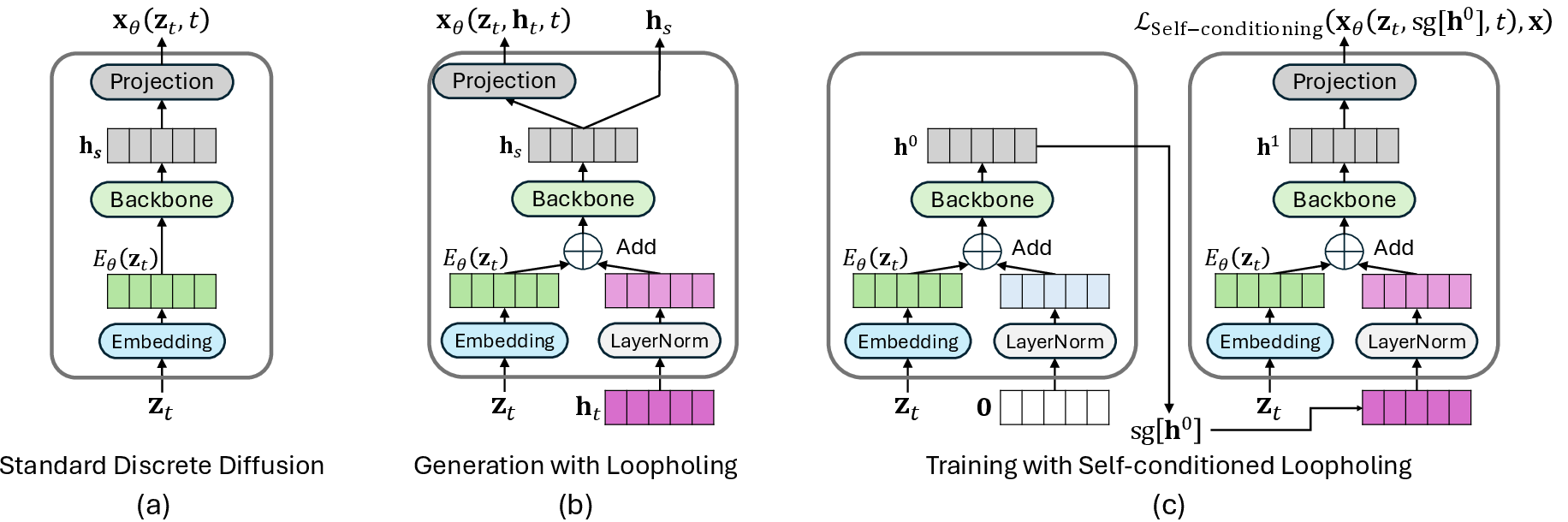
What is Loopholing?
Loopholing adds a simple, deterministic “memory lane” to carry forward a continuous latent vector (think of it as a smooth summary of the model’s context and confidence) alongside the sampled token. Each step now produces:
- A stochastic output: the chosen token (like picking a word).
- A deterministic output: a continuous vector that summarizes context, which is passed to the next step.
Analogy: It’s like writing with a pen, but also keeping a diary of your thought process. Next time you refine the sentence, you can read the diary and remember why you made certain choices, instead of guessing from scratch.
How is it trained?
Training diffusion models usually doesn’t need to simulate all steps. But Loopholing creates a dependency across steps. To keep training fast, the authors use self-conditioning:
- First pass: the model pretends the “memory lane” is empty and creates a pseudo memory.
- Second pass: the model uses that pseudo memory to improve its prediction.
- Only the second pass gets updated (this saves compute).
Analogy: Draft 1 writes rough notes. Draft 2 uses those notes to write a better version. You only grade Draft 2.
Main Findings and Why They Matter
Here are the main results, explained simply:
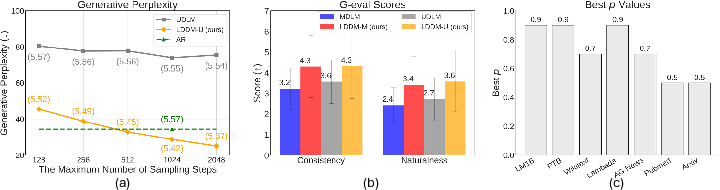
- Better text quality: LDDMs lower generative perplexity (a measure of how “surprised” a strong reader model is by the text—lower is better) by up to 61% compared to prior diffusion baselines. This means the text reads more naturally and makes more sense.
- Closer to, and sometimes better than, traditional models: The gap to strong left-to-right models shrinks a lot. In some settings, LDDMs even surpass them on generation quality.
- More coherent writing: Evaluations using GPT-based scoring show improved consistency and natural-sounding text. This suggests the “memory lane” helps the model stay on topic and connect sentences logically.
- Better reasoning: On math puzzles like Countdown and Game of 24, LDDMs solve more problems. This is because they keep track of multiple promising options and don’t lock in too early.
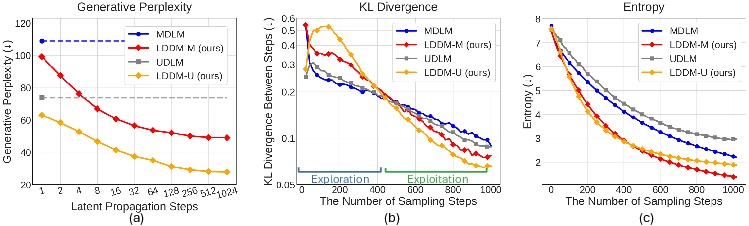
- Fewer wasted steps and less flip-flopping: The added context helps each refinement step actually move forward, and reduces wild swings in word choices.
These improvements are practical because diffusion models can generate long sequences faster by refining them in parallel, and now they can do so with higher quality.
Implications and Potential Impact
This work shows a simple, scalable way to make non-autoregressive text generation more reliable and coherent. The potential impacts include:
- Faster, high-quality text generation for chatbots, translators, and summarizers, especially for long documents.
- Stronger reasoning for tasks that need precise, step-by-step logic, like math or code generation.
- A general recipe for carrying context across steps in other discrete generative tasks, not just language.
In short, Loopholing helps diffusion models remember what they knew before they made a choice. That small change reduces wasted effort and stabilizes generation, making fast, parallel text creation much more effective.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Lack of a formal probabilistic treatment of loopholing: a rigorous derivation that integrates the deterministic latent pathway into the diffusion framework, clarifies the implied reverse posterior, and characterizes its effect on the ELBO (tightness, bias) and likelihood estimation.
- Convergence and stability guarantees: theoretical analysis of whether and when the loopholing-enhanced reverse process converges, how the deterministic latent affects fixed points, and conditions under which oscillations are provably reduced.
- Training bias from self-conditioning: quantifying the bias introduced by the two-pass, stop-gradient self-conditioning scheme; comparing to unrolled training or truncated backpropagation through time; and analyzing gradient flow and credit assignment across steps.
- Optimal and adaptive self-conditioning schedules: principled methods to select or adapt the self-conditioning rate p over training and across tasks; exploration of curricula (e.g., warm-up or decay) and per-layer or per-token conditioning.
- Multi-step training strategies: explicit training objectives that condition on multi-step latent histories rather than single-step pseudo-contexts; impact of truncated BPTT horizons on sample quality and stability.
- Latent design choices: systematic ablations on the dimensionality of the latent h, its update rule, and the combination operator E(z_t) + LN(h_t); testing gating (e.g., GRU/LSTM-like), cross-step attention, residual weighting, and normalization alternatives.
- Propagating distributions vs. latents: exploring propagation of compressed distributions x_θ (e.g., via low-rank projections, product quantization) instead of h; trade-offs in memory, fidelity, and downstream gains.
- Noise schedule co-design: how the choice or learning of α_t interacts with the deterministic pathway (e.g., schedules that minimize idle steps or oscillation); joint optimization of schedule and loopholing components.
- Oscillation and progress metrics: standardizing and validating metrics beyond Temporal KL and Token-Prediction Entropy (e.g., step-to-step edit distance, MAUVE dynamics), with statistical significance tests across datasets and seeds.
- Error accumulation and drift: diagnosing and mitigating drift in h across long trajectories (e.g., reset strategies, regularizers, clipping, stochastic perturbations to h); identifying failure cases and recovery mechanisms.
- Scalability to large models and long contexts: empirical studies at billion-parameter scales and 8k–128k contexts, quantifying training/inference throughput, memory footprint (due to doubled embeddings), and end-to-end latency vs. autoregressive baselines.
- Conditional generation benchmarks: testing on conditional tasks (translation, summarization, code generation) where controllability, faithfulness, and conditioning adherence are critical; measuring calibration and instruction-following.
- Diversity and mode collapse assessment: going beyond sentence entropy to distinct-n, self-BLEU, repetition rates, and semantic diversity; understanding whether deterministic memory compresses output modes.
- Evaluation robustness: replacing proxy Gen PPL (GPT-2 Large) and G-eval with human studies, multiple LM evaluators, and task-specific metrics; reporting confidence intervals, inter-rater agreement, and significance across diverse prompts.
- Masked vs. uniform diffusion discrepancies: investigating why LDDM-U shows marginal zero-shot gains relative to LDDM-M; disentangling metric sensitivity (per-token perplexity in UDMs) from mechanism effectiveness; proposing fair cross-framework comparators.
- Broader reasoning tasks: extending beyond arithmetic puzzles to symbolic reasoning, program synthesis, multi-hop QA, and natural language chain-of-thought; evaluating solution validity, completeness, and rationale consistency.
- Integration with guidance and planning: combining loopholing with classifier-free guidance, remasking/inference-time scaling, tree search, or beam-like strategies; measuring step efficiency and controllability.
- Compatibility with alternative samplers: studying DDIM-like discrete samplers, partially deterministic trajectories, and adaptive early stopping criteria informed by h dynamics and idle-step detection.
- Fine-tuning-only adoption: developing adapter-based or distillation strategies to retrofit loopholing into pretrained diffusion LMs without full retraining; diagnosing why naive fine-tuning failed and how to overcome it.
- Formal RNN connection: building a theoretical bridge to RNNs (hidden-state updates, exposure bias, stability) and deriving learning objectives that unify loopholing diffusion with recurrent sequence modeling.
- Robustness under domain shift: systematic OOD evaluations with calibration metrics (e.g., ECE), uncertainty quantification, and failure analyses; exploring how h retention impacts adaptability.
- Safety and bias considerations: assessing whether persistent deterministic memory amplifies spurious correlations or harmful content; designing guardrails or resets that preserve coherence without propagating bias.
- Multimodal and non-text domains: testing loopholing in discrete or hybrid spaces (images with tokenizers, audio, protein sequences, code), and in multimodal settings where vocabularies are large and distributions are structured.
- Normalization and noise in the latent path: ablations on the role of LayerNorm, alternative normalization schemes, and stochastic regularization (dropout, noise injection) in h to prevent overconfidence or overfitting.
- Latent propagation length policy: turning the observed benefits of longer k (propagation windows) into practical policies or learned controllers that manage h retention and refresh across steps and tasks.
- Reproducibility and reporting: releasing code, training/evaluation scripts, seeds, and exact preprocessing; providing detailed compute budgets and wall-clock metrics to enable fair replication and scaling studies.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that leverage the paper’s loopholing mechanism (deterministic latent pathway + self-conditioning) to improve discrete diffusion-based generation. Each item lists sectors, potential tools/workflows, and key dependencies.
- Non-autoregressive text generation with higher coherence and throughput
- Sectors: software/AI, media, marketing, customer support
- Tools/workflows: integrate LDDM-M/U into existing masked/uniform discrete diffusion LMs for batch content creation (summaries, headlines, product descriptions, FAQs); calibrate sampling steps using the paper’s GenPPL and G-eval proxies; deploy parallel decoding for high-throughput jobs
- Assumptions/dependencies: availability of discrete diffusion training stack; +30% training time and higher memory budget; tuning self-conditioning rate p (often 0.5–0.9); retraining rather than quick fine-tuning
- Iterative document editing and text infilling with fewer idle steps and less oscillation
- Sectors: productivity software, collaboration tools
- Tools/workflows: masked editing/inpainting UX backed by LDDMs; exploit the deterministic latent h-path to retain revision context across steps; dynamic step scheduling for interactive edits
- Assumptions/dependencies: masked diffusion editing pipeline; modest engineering to pass and normalize h across steps
- Adaptive sampling control using TKL/TPE diagnostics
- Sectors: ML platforms, MLOps
- Tools/workflows: implement Temporal KL divergence (TKL) and Token-Prediction Entropy (TPE) metrics to (i) early-stop sampling when progress saturates, (ii) allocate more steps to hard spans, (iii) detect oscillation in production
- Assumptions/dependencies: access to token distributions at inference; instrumentation in serving stack
- Arithmetic/puzzle solvers for education and games
- Sectors: education, gaming
- Tools/workflows: deploy LDDM-G (loopholing added to MGDM) for Countdown and Game of 24-style apps; iterate on constrained sampling to ensure validity of expressions
- Assumptions/dependencies: task-specific constraints/validators; small- to medium-size models are already effective per the paper
- Parallel data augmentation with better sample quality
- Sectors: ML data engineering, NLP training
- Tools/workflows: generate synthetic corpora (paraphrases, summaries) using LDDMs to improve downstream model performance; maintain diversity while reducing GenPPL
- Assumptions/dependencies: quality controls (dedup, toxicity filters); compute budget for many-step sampling in offline pipelines
- Non-autoregressive machine translation prototypes
- Sectors: localization, productivity
- Tools/workflows: apply loopholing to NAT or masked-diffusion translation baselines to stabilize refinement; batch decode entire sentences/paragraphs in parallel for high throughput
- Assumptions/dependencies: bilingual corpora; domain-specific evaluation (BLEU/COMET); retraining required
- Retrieval-augmented iterative rewriting with stable context carry-over
- Sectors: enterprise search, knowledge management
- Tools/workflows: RAG pipelines that iteratively refine drafts; loopholing maintains consistent latent context across iterations even as retrieved passages change
- Assumptions/dependencies: robust retrieval and citation checking; step budget tuned to latency targets
- Latency/throughput tuning via compute-aware step scheduling
- Sectors: inference engineering, cost optimization
- Tools/workflows: leverage reduced idle steps to hit the same quality with fewer denoising steps; schedule steps adaptively by position and time using TKL/TPE trends
- Assumptions/dependencies: A/B testing vs autoregressive baselines; quality guardrails
- Stable paraphrasing and style transfer for compliance-sensitive domains
- Sectors: finance, legal, healthcare documentation
- Tools/workflows: parallel rewrites with stronger within-document consistency; apply rule-based validators, redaction tools, and style guides post-generation
- Assumptions/dependencies: strict evaluation and human-in-the-loop; data privacy/compliance checks
- Open-source research baselines and ablation studies
- Sectors: academia, applied research labs
- Tools/workflows: reproduce MDLM/UDLM, plug in loopholing and self-conditioning; analyze oscillation/idle-step reductions via TKL/TPE; test propagation-length limits
- Assumptions/dependencies: modest-scale compute; standardized evaluation (NELBO upper bounds, GenPPL, G-eval)
- Hybrid guidance and inference-time scaling for discrete diffusion
- Sectors: ML research-to-production
- Tools/workflows: combine loopholing with existing remasking and guidance heuristics to further reduce GenPPL and improve stability
- Assumptions/dependencies: integration testing; schedule/guidance hyperparameter sweeps
Long-Term Applications
These opportunities likely require additional research, scaling, or system development before production deployment.
- Production-grade diffusion-based chat assistants and copilots
- Sectors: software/AI, developer tools, customer support
- Potential products: non-AR diffusion LLM services with loopholing for long-form coherence and lower oscillation; batch-mode generation for multi-user throughput
- Assumptions/dependencies: billion-parameter scaling; safety alignment; retraining and serving infrastructure; comprehensive evals vs top AR models
- Multimodal discrete diffusion with loopholing (audio, music, image tokens, video)
- Sectors: media, TTS, entertainment
- Potential products: codec-token TTS/music generation with more stable iterative refinement; video captioning/editing via consistent latent carry-over
- Assumptions/dependencies: high-quality discrete tokenizers (e.g., VQ-VAE/EnCodec); task-specific loss constraints; latency controls
- Planning and reasoning engines for agents and robotics
- Sectors: robotics, logistics, autonomy
- Potential products: non-AR plan refinement (whole-plan updates per step) with reduced oscillation; integrate with verification/constraint solvers
- Assumptions/dependencies: safety-critical verification; compositional reasoning datasets; interfaces to symbolic planners
- Program synthesis and theorem proving via iterative diffusion reasoning
- Sectors: developer tooling, scientific computing
- Potential products: diffusion reasoners that maintain latent hypotheses across refinement steps; integrate with unit tests or proof checkers as external feedback
- Assumptions/dependencies: correctness oracles; robust failure handling; domain-specific corpora
- On-device non-autoregressive generation
- Sectors: mobile, embedded, edge AI
- Potential products: quantized loopholing models with compressed latent h; local summarization/assistive writing with low latency
- Assumptions/dependencies: memory footprint optimization (h-state size, caching); distillation and quantization research; energy constraints
- Computation- and energy-aware AI policy and standards
- Sectors: policy, sustainability, enterprise procurement
- Potential outcomes: guidance favoring parallel non-AR generation when quality targets are met; step-budget reporting using TKL/TPE to standardize energy claims
- Assumptions/dependencies: lifecycle assessments; standardized benchmarks; multi-vendor adoption
- Safety and auditability via stepwise latent logging
- Sectors: safety, compliance, content moderation
- Potential products: audit trails of hidden-state trajectories to diagnose and mitigate harmful oscillations or mode flips
- Assumptions/dependencies: privacy controls; tooling for step-level logging and analytics; governance frameworks
- New training regimes: multi-step/partially unrolled loopholing, RL fine-tuning
- Sectors: ML research
- Potential outcomes: better exploitation of long-range latent propagation; policy-gradient or evaluator-guided refinement reducing hallucinations
- Assumptions/dependencies: compute scale; stable optimization; evaluator design
- Domain-specific non-AR translation for real-time subtitling and captioning
- Sectors: media, accessibility, conferencing
- Potential products: low-latency captioners that refine entire sentences in parallel with stable context propagation
- Assumptions/dependencies: low-latency tokenizers; task-tuned schedules; bilingual speech/text data
- Controlled generation for regulated documents
- Sectors: healthcare, finance, legal
- Potential products: section-level parallel drafting with consistent terminology/style across long documents; rule-based constraint checking per step
- Assumptions/dependencies: domain ontologies; high-precision evaluation; human review loops
- Ecosystem tools and libraries
- Sectors: open-source, platform vendors
- Potential products: “Loopholing layer” for PyTorch/TF; Hugging Face trainers with two-pass self-conditioning and h-propagation; plug-in metrics (TKL/TPE)
- Assumptions/dependencies: community uptake; reproducible reference checkpoints; documentation and tutorials
Cross-cutting assumptions and dependencies
- Scaling and transferability: Current gains are shown on moderate-scale models and text; generalization to very large models and multimodal settings requires validation.
- Training budget: Loopholing adds ~30% training time and memory overhead (due to dual pathways); inference overhead is minimal but step count still drives latency.
- Retraining vs fine-tuning: Initial attempts at loopholing-only fine-tuning were unsuccessful; expect retraining or extensive adaptation.
- Step scheduling: Quality improves with more steps; applications must tune step budgets using GenPPL/TKL/TPE trade-offs.
- Safety and evaluation: Stable, less oscillatory generation can ease moderation and alignment, but comprehensive safety testing remains necessary in sensitive domains.
Glossary
- Absorbing mask state: A special state in discrete diffusion where a token becomes a non-informative mask that absorbs transitions, used to model corruption with masking. "using transition matrices based on an absorbing ``mask'' state and uniform noise."
- Backbone network: The core neural architecture (e.g., Transformer) that processes embeddings and produces latent representations. "a backbone network such as a Transformer~\citep{vaswani2017attention} layer"
- Backpropagating through time: Training method that propagates gradients through sequential dependencies across steps; computationally expensive for long trajectories. "without the prohibitive cost of backpropagating through time."
- Categorical distribution: A probability distribution over discrete outcomes (tokens) used to model corrupted or predicted token probabilities. "is formulated as a categorical distribution that interpolates between the data and a fixed prior distribution :"
- Cross-entropy loss: A standard loss for probabilistic classification that penalizes deviations from the true distribution; here appears as a weighted variant. "reduces to a weighted cross-entropy loss~\citep{sahoo2024simple,shi2024simplified}:"
- Denoising: The process of iteratively recovering clean data from noisy inputs in diffusion models. "the reverse process generates data by progressively denoising a sample"
- Denoising steps: Iterations in discrete diffusion that refine sequences in parallel by removing noise. "iterative refinement across multiple denoising steps."
- Denoising trajectory: The entire sequence of denoising states across time during generation. "While this design introduces a recurrent dependency across the denoising trajectory, which would require full unrolling for training,"
- Deterministic latent pathway: A non-stochastic mechanism that carries continuous contextual state across steps to avoid information collapse. "preserves this information via a deterministic latent pathway"
- Dirac delta function: A distribution that assigns all probability mass to a single point; used to keep unmasked tokens unchanged. "where denotes the Dirac delta function."
- Diffusion models: Generative models with a fixed forward noising process and a learned reverse denoising process. "Diffusion models~\citep{sohl2015deep,ddpm} are probabilistic generative models defined by a fixed forward process that progressively corrupts data with noise, and a learned reverse process trained to recover the original sample ."
- Discrete diffusion models: Diffusion models adapted to categorical data that operate over token distributions and one-hot representations. "Discrete diffusion models have recently emerged as a promising alternative to autoregressive models for tasks such as text generation~\citep{d3pm, campbell2022continuous, lou2023discrete, sahoo2024simple, schiff2024simple, zhao2024unified, ou2024your, gat2024discrete, wang2025remasking}."
- Forward process: The corruption mechanism that adds noise over time to produce progressively noisier latent variables. "The forward process corrupts the initial data sample over a continuous time variable \mathbf{z}_t$."</li> <li><strong>G-eval framework</strong>: An automated evaluation protocol using LLMs to rate text quality on dimensions like consistency and naturalness. "following the G-eval framework~\citet{liu2023g}"</li> <li><strong>Generative perplexity (Gen PPL)</strong>: Perplexity measured on model-generated samples (e.g., by GPT-2), assessing generation quality rather than training likelihood. "In terms of Generation Perplexity (Gen PPL), as shown in Fig.~\ref{fig:gen-ppl}, our method achieves substantial gains,"</li> <li><strong>Idle steps</strong>: Denoising iterations that make no progress, often reproducing the same samples due to information collapse. "such as idle steps~\citep{chao2025beyond}"</li> <li><strong>Interpolating discrete diffusion model</strong>: A class of discrete diffusion where the latent distribution interpolates between data and a prior over continuous time. "use an interpolating discrete diffusion model~\citep{sahoo2024simple, schiff2024simple,shi2024simplified,von2025generalized}"</li> <li><strong>KL divergence</strong>: A measure of difference between two probability distributions; used to quantify temporal changes in token predictions. "KL divergence (log-scale) between the predicted token distribution at each step $tt{-}20$) during the generation."</li> <li><strong>Layer Normalization (LN)</strong>: A normalization technique applied to activations to stabilize training and integrate latent context into embeddings. "via Layer Normalization ($\mathrm{LN}$)~\citep{layer_norm}"</li> <li><strong>Latent embedding</strong>: A continuous vector representation produced by the backbone that summarizes contextual information per position. "produce a latent embedding $\mathbf{h}_s$ at each position."</li> <li><strong>Latent state</strong>: The recurrent continuous context carried across steps to retain distributional information. "We initialize a latent state $\mathbf{h}_1 = \mathbf{0}$."</li> <li><strong>Loopholing</strong>: A mechanism that adds a deterministic latent path to propagate contextual distributions across steps, bypassing the sampling wall. "we propose a simple and novel mechanism, termed Loopholing,"</li> <li><strong>Loopholing Discrete Diffusion Models (LDDMs)</strong>: The family of discrete diffusion models augmented with loopholing’s deterministic latent pathway. "leading to Loopholing Discrete Diffusion Models (LDDMs)."</li> <li><strong>Masked Diffusion LLMs (MDLM)</strong>: Discrete diffusion LLMs that use a mask token as the prior, interpreting corruption as gradual masking. "Mask Diffusion LLMs (MDLM)~\citep{sahoo2024simple}"</li> <li><strong>Masked Diffusion Models (MDMs)</strong>: Discrete diffusion models that set the prior to a special [MASK] token, modeling corruption via masking. "Masked Diffusion Models (MDMs) are a subclass of discrete diffusion models in which the prior $\boldsymbol{\pi}\mathbf{m}[MASK]$ token~\citep{sahoo2024simple,nie2025large,kim2025train}."</li> <li><strong>Negative Evidence Lower Bound (NELBO)</strong>: A training objective that serves as an upper bound on perplexity, simplified here to a weighted cross-entropy. "optimize a simplified Negative Evidence Lower Bound (NELBO)."</li> <li><strong>Noise schedule</strong>: A time-dependent function controlling the interpolation between data and prior in the forward process. "and $\alpha_t \in [0,1]$ is a monotonically decreasing noise schedule"</li> <li><strong>One-hot vector</strong>: A categorical representation where a single token index is 1 and others are 0, causing information collapse after sampling. "reduced to one-hot vectors after sampling,"</li> <li><strong>Probability simplex</strong>: The set of valid probability vectors (non-negative components summing to 1) parameterizing categorical distributions. "parameterized by probability simplex $\mathbf{p}$,"</li> <li><strong>Reverse posterior</strong>: The distribution over previous-time latent states given current state and model prediction used in backward sampling. "the true reverse posterior $q(\mathbf{z}_s | \mathbf{z}_t, \mathbf{x})$"</li> <li><strong>Reverse process</strong>: The learned denoising dynamics that reconstruct data from noise by moving backward in time. "and a learned reverse process trained to recover the original sample $\mathbf{x}$."</li> <li><strong>Sampling wall</strong>: The information-collapse event where rich distributions become one-hot, halting propagation of uncertainty to future steps. "We define the sampling wall as a form of information collapse,"</li> <li><strong>Self-conditioning</strong>: A two-pass training technique that feeds a model’s own intermediate outputs or latents as context without full unrolling. "by introducing a self-conditioning approach~\citep{chen2022analog, jabri2022scalable}"</li> <li><strong>Softmax</strong>: A normalization function converting logits to probabilities over the vocabulary in the output layer. "$\mathbf{x}_\theta(\mathbf{z}_t,\mathbf{h}_t,t)=\text{softmax}(g_\theta(\mathbf{h}_s))$"</li> <li><strong>Stop-gradient operator</strong>: A mechanism that prevents gradient flow through certain tensors, enabling efficient two-pass conditioning. "The stop-gradient operator, $\text{sg}[\cdot]$, ensures that gradients flow only through the second forward pass."</li> <li><strong>Temporal KL divergence (TKL)</strong>: A metric quantifying the rate of change in predicted token distributions across denoising steps. "we introduce two metrics—Temporal KL divergence (TKL) and Token-Prediction Entropy (TPE)."</li> <li><strong>Temporal oscillation</strong>: Unstable fluctuations in predictions across steps due to repeated sampling without context propagation. "and temporal oscillation~\citep{wang2025remasking}."</li> <li><strong>Token embedding</strong>: The learned vector representation of a token input to the backbone network. "current token embedding $E_\theta(\mathbf{z}_t)$"</li> <li><strong>Token-Prediction Entropy (TPE)</strong>: A metric measuring the confidence of the model’s token predictions at each step. "we introduce two metrics—Temporal KL divergence (TKL) and Token-Prediction Entropy (TPE)."</li> <li><strong>Transformer</strong>: A neural architecture using attention mechanisms, employed here as the backbone for sequence modeling. "such as a Transformer~\citep{vaswani2017attention} layer"</li> <li><strong>Uniform Diffusion LLMs (UDLM)</strong>: Discrete diffusion LLMs that use a uniform prior over tokens. "Uniform Diffusion LLMs (UDLM)~\citep{schiff2024simple}"</li> <li><strong>Uniform Diffusion Models (UDMs)</strong>: Discrete diffusion models whose prior is uniform over the vocabulary, not a mask token. "Uniform Diffusion Models (UDMs), which use a uniform distribution over the entire vocabulary as the prior $\boldsymbol{\pi}$"
- Unrolling: Explicitly simulating sequential dependencies across time steps during training; avoided via self-conditioning here. "which would require full unrolling for training"
Collections
Sign up for free to add this paper to one or more collections.