- The paper introduces a novel AR-diffusion hybrid (D2F) that uses block-wise causal attention and inter-block parallel decoding to surpass AR inference speeds.
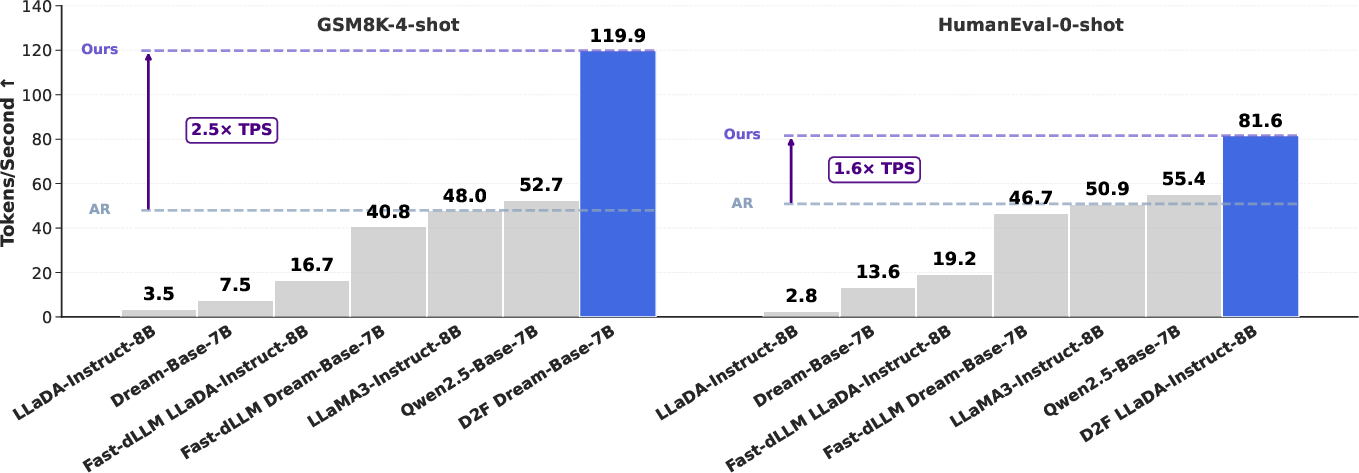
- Experimental results show up to 2.5× speedup over autoregressive LLMs and over 50× acceleration compared to vanilla diffusion models with competitive quality.
- Ablation studies reveal that optimal block sizes and pipeline hyperparameters are critical for balancing throughput and output accuracy.
Discrete Diffusion Forcing Enables Faster-Than-Autoregressive Inference in Diffusion LLMs
Introduction
The paper "Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing" (2508.09192) presents Discrete Diffusion Forcing (D2F), a training and inference paradigm for Diffusion LLMs (dLLMs) that achieves inference speeds surpassing autoregressive (AR) LLMs of comparable scale. D2F introduces a hybrid AR-diffusion generation scheme, leveraging block-wise causal attention and inter-block parallel decoding, which enables efficient KV cache utilization and aggressive parallel token generation. This work establishes the first open-source dLLMs that outperform AR LLMs in throughput while maintaining competitive output quality.
Background: Diffusion LLMs and Inference Bottlenecks
Diffusion LLMs generate text by iteratively denoising a masked sequence, allowing for parallel prediction of all tokens at each step. Theoretically, this paradigm offers substantial acceleration over AR models, which decode tokens sequentially. However, practical dLLMs have been hampered by two major bottlenecks:
- Bidirectional Attention: Standard dLLMs use bidirectional attention, which is incompatible with KV cache, resulting in redundant computation across denoising steps.
- Conditional Independence: Parallel decoding assumes conditional independence among tokens, which is violated in natural language, necessitating more iterative steps for high-quality outputs.
Previous acceleration methods, such as block-wise sequential generation and approximate KV cache, have not simultaneously achieved precise KV cache and efficient parallel decoding. Consequently, open-source dLLMs have lagged behind AR models in inference speed.
Discrete Diffusion Forcing: Methodology
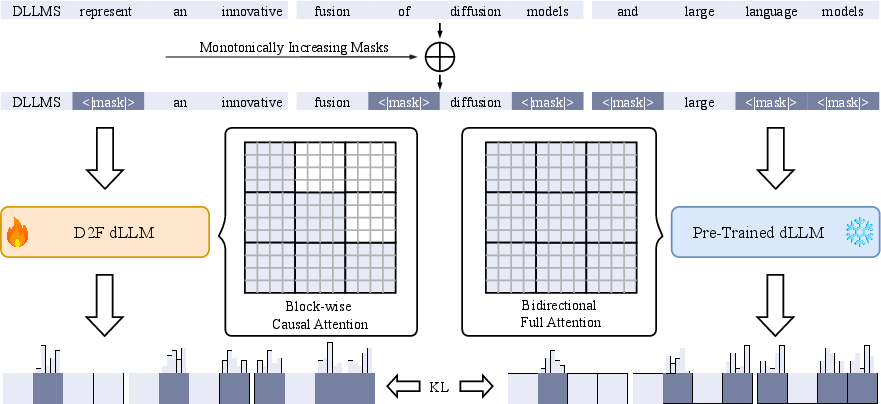
D2F restructures dLLM generation into a block-wise AR-diffusion hybrid, enabling both KV cache compatibility and inter-block parallelism. The key components are:
Asymmetric Distillation
D2F dLLMs are distilled from pre-trained bidirectional dLLMs using an asymmetric KL divergence loss. The teacher predicts each block with a global view of all noisy blocks, while the student (D2F dLLM) predicts using only a causally restricted view. The student architecture differs solely in its attention mask, enforcing block-wise causality.
Pipelined Parallel Decoding
During inference, D2F maintains a pipeline of active blocks. A new block is added when the completion ratio of the last block exceeds a threshold τadd. Newly added blocks are semi-activated for conservative decoding and become fully activated when their predecessor reaches τact, allowing aggressive parallel decoding.
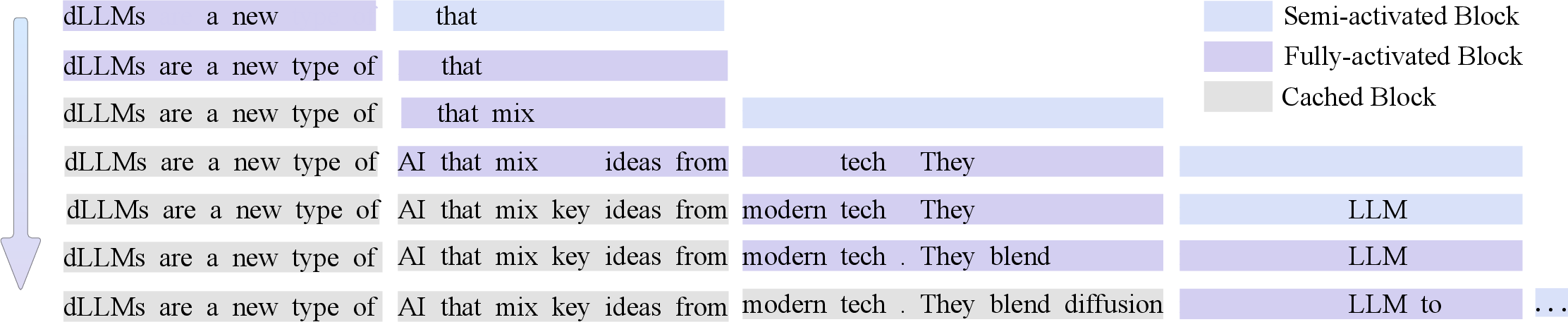
Figure 2: Pipelined parallel decoding: blocks are decoded in parallel, with dynamic addition and activation based on completion thresholds.
Experimental Results
D2F is evaluated on LLaDA-Instruct-8B and Dream-Base-7B, distilled on the Bespoke-Stratos-17k dataset. Benchmarks include GSM8K, MATH, HumanEval, and MBPP. D2F achieves:
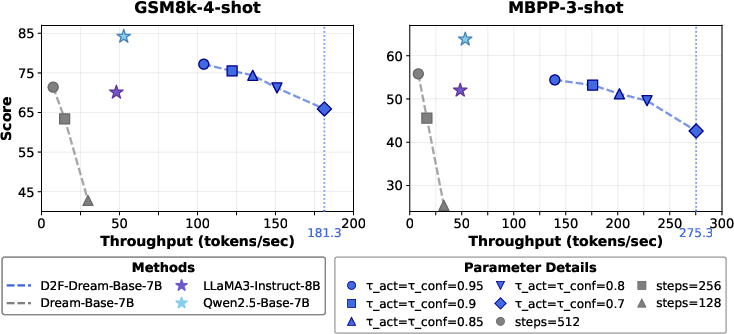
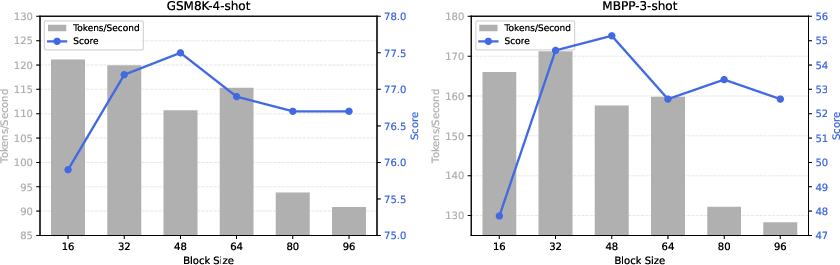
Ablation Studies and Analysis
Ablation studies dissect the contributions of block size, pipeline hyperparameters, and noise scheduling:
Implications and Future Directions
D2F demonstrates that dLLMs can achieve faster-than-AR inference without sacrificing output quality, challenging the prevailing assumption that AR models are inherently superior in efficiency. The AR-diffusion hybrid paradigm introduced by D2F is extensible to other discrete generative tasks, including code synthesis and mathematical reasoning. The pipelined parallel decoding strategy and asymmetric distillation framework are broadly applicable to other sequence modeling domains.
Theoretical implications include the principled extension of diffusion forcing from continuous to discrete data, bridging the gap between AR and diffusion-based generative models. Practically, D2F enables deployment of dLLMs in latency-sensitive applications, such as real-time dialogue systems and large-scale batch generation.
Future research may explore:
- Scaling D2F to larger models and longer contexts
- Integration with advanced sampling and confidence-based remasking strategies
- Application to multimodal and multilingual generative tasks
- Further optimization of block partitioning and pipeline scheduling
Conclusion
Discrete Diffusion Forcing (D2F) establishes a new regime for dLLMs, enabling faster-than-AR inference through block-wise causal attention and inter-block parallel decoding. Empirical results validate substantial speedups and competitive output quality, positioning D2F as a foundational technique for efficient discrete sequence generation. The AR-diffusion hybrid paradigm and pipelined parallel decoding introduced by D2F have significant implications for the future of generative modeling in both research and production environments.