UEval: A Benchmark for Unified Multimodal Generation
Abstract: We introduce UEval, a benchmark to evaluate unified models, i.e., models capable of generating both images and text. UEval comprises 1,000 expert-curated questions that require both images and text in the model output, sourced from 8 real-world tasks. Our curated questions cover a wide range of reasoning types, from step-by-step guides to textbook explanations. Evaluating open-ended multimodal generation is non-trivial, as simple LLM-as-a-judge methods can miss the subtleties. Different from previous works that rely on multimodal LLMs (MLLMs) to rate image quality or text accuracy, we design a rubric-based scoring system in UEval. For each question, reference images and text answers are provided to a MLLM to generate an initial rubric, consisting of multiple evaluation criteria, and human experts then refine and validate these rubrics. In total, UEval contains 10,417 validated rubric criteria, enabling scalable and fine-grained automatic scoring. UEval is challenging for current unified models: GPT-5-Thinking scores only 66.4 out of 100, while the best open-source model reaches merely 49.1. We observe that reasoning models often outperform non-reasoning ones, and transferring reasoning traces from a reasoning model to a non-reasoning model significantly narrows the gap. This suggests that reasoning may be important for tasks requiring complex multimodal understanding and generation.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces UEval, a new “test” (called a benchmark) for AI systems that can both write and draw at the same time. These systems are called unified multimodal models. UEval checks how well these models can create answers that include both images and text together—like making a step-by-step drawing and explaining it, or sketching a scientific diagram and describing how it works.
What questions were the authors trying to answer?
In simple terms, the authors wanted to know:
- How can we fairly and automatically grade AI answers that include both pictures and words?
- What kinds of tasks show whether an AI can really “think” across text and images together, not just do one or the other?
- Do models that show or use their “thinking steps” (reasoning) do better at these mixed tasks?
How did they do it?
Think of UEval like a school test designed by teachers with a clear grading checklist.
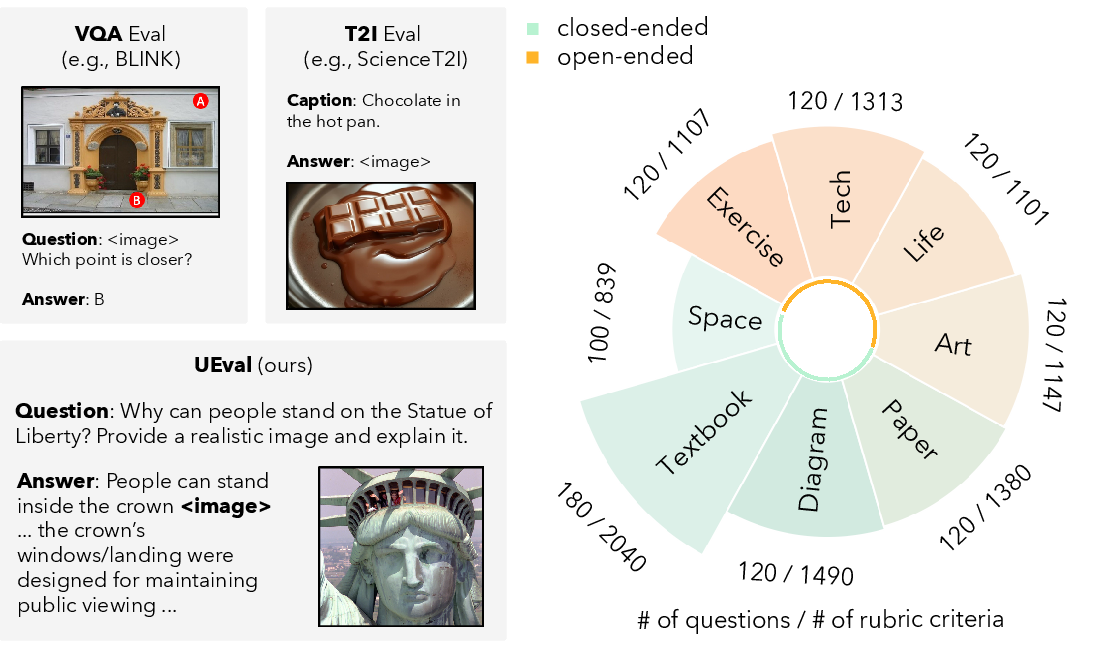
- They built a set of 1,000 questions from 8 real-life task areas: space, textbook, diagram, paper, art, life, tech, and exercise. Some questions have one right answer (closed-ended), like explaining a specific scientific diagram. Others are more open (open-ended), like drawing and explaining steps to complete a task (for example, “How to draw a cartoon cat?”).
- For each question, they created “reference answers” that include both images and text, so there’s a gold standard to compare against.
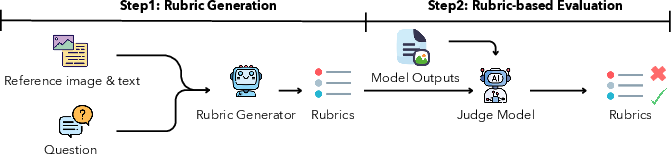
- They made detailed grading checklists called rubrics. Imagine a teacher’s checklist: “Does the image show the correct part?”, “Are the steps in the right order?”, “Does the text explain why the parts matter?” An advanced AI first drafted these rubrics, and then human experts cleaned them up to make sure they’re clear and fair. In total, there are 10,417 rubric items.
- To score model answers automatically, they used a strong AI “judge.” This judge reads the rubric and checks whether each point is satisfied by the model’s text and image(s). The final score is the percent of rubric items the model got right. They also checked that these AI-judge scores match what humans would give—and they mostly do.
What did they find?
Here are the main results and why they matter:
- UEval is challenging. Even top systems did not score near 100. One of the strongest “reasoning” models scored about 66 out of 100 on average. The best open-source model scored about 49. This shows there’s lots of room for improvement when an AI has to both draw and explain.
- Reasoning helps. Models designed to reason (think step by step) usually did better than those that don’t. Even more interesting: if you take the “thinking steps” from a reasoning model and add them to the prompt of a non-reasoning model, some non-reasoning models improve. It’s like giving a student a worked example—they follow it and do better.
- Multi-step visuals are hard. Tasks that require creating several images in order (like a step-by-step guide) often tripped up models. They might mislabel steps, skip steps, or make images that don’t stay consistent from one step to the next.
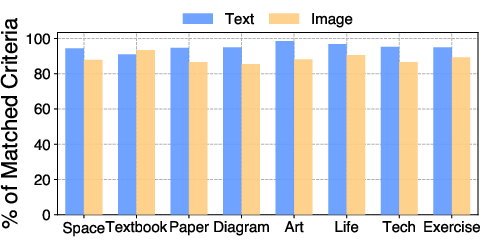
- Text is easier than images (for now). Across the board, models were better at writing clear explanations than at producing perfect, accurate images that match the rubric.
- The grading method is reliable. The AI judge’s scores matched human judgments well, so the automatic grading can be trusted for large-scale testing.
Why does this matter?
- It tests real-world skills. Many useful answers in everyday life (and school!) mix words and pictures—like lab diagrams, how-to guides, and scientific explanations. UEval pushes AI toward doing both well at the same time.
- It gives researchers a clear target. With 1,000 questions and over 10,000 detailed checklist items, UEval makes it possible to measure progress fairly and consistently across many tasks.
- It highlights what to fix next. The benchmark shows where current models struggle—especially multi-step visual consistency and precise image details—so teams can focus on improving those parts.
- It suggests a path forward. The finding that “reasoning traces” can help other models hints that better planning and step-by-step thinking could boost future multimodal systems.
In short, UEval is a big, carefully built “exam” for AI that needs to both draw and explain. It shows that reasoning matters, images are still hard, and there’s a clear way to measure and drive progress.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Benchmark coverage and representativeness: 1,000 prompts across 8 tasks may not capture the breadth of real-world unified generation (domains like medicine, law, engineering drawings beyond CS, cultural heritage, everyday procedural tasks beyond the chosen set).
- Language scope: The benchmark appears English-only; it does not assess multilingual generation, OCR, or cross-lingual text–image alignment.
- Modality scope: Only text and static images are evaluated; unified generation for video, audio, 3D, charts with data provenance, or interactive/agentic outputs is not covered.
- Interaction and dialogue: All tasks are single-turn; there is no evaluation of multi-turn clarification, iterative refinement, or user feedback incorporation.
- Multi-image evaluation reliability: Reference answers for open-ended tasks scored lower (even for gold answers), suggesting that judges struggle with sequences; improved protocols for step ordering, temporal consistency, and multi-image ingestion are needed.
- Judge dependence and instability: Scores vary substantially across judge models, especially in open-ended tasks; a standardized, open, and calibrated judge (or ensemble with calibration) is missing.
- Rubric generation bias: Rubrics are drafted by an MLLM conditioned on references, which may bias criteria toward specific phrasings/depictions and under-reward valid alternatives; methods to ensure diversity-tolerant criteria are not explored.
- Criterion weighting and severity: All rubric items are equally weighted; there is no mechanism to weight by importance or severity, nor sensitivity analysis on how weighting affects rankings.
- Lack of penalties for incorrect or harmful content: The metric counts satisfied criteria only; it does not explicitly penalize contradictions, hallucinations, irrelevant verbosity, or unsafe instructions.
- Human quality assurance scope: While rubrics undergo two rounds of human review, the paper reports no inter-annotator agreement statistics, error categorizations, or rubric quality metrics to quantify reliability.
- Training exposure and data leakage: Some references (e.g., Transformer/ResNet figures) are ubiquitous and likely in training sets; the benchmark does not quantify or control for exposure effects or leakage.
- Question generation via frontier models: GPT-5 is used to expand/generate questions, potentially aligning task distributions to its strengths and advantaging it in evaluations; neutral or human-first generation pipelines are not compared.
- Fairness across model capabilities: For models that cannot jointly generate image and text, two-pass inference may reduce image–text coherence; the fairness impact and potential normalization strategies are unexamined.
- Output formatting standards: Image resolution, aspect ratio, and file format requirements are unspecified; the judge’s sensitivity to resolution/legibility and multi-image layout (e.g., grids vs separate frames) is unclear.
- Creativity and aesthetics: Rubrics prioritize factual alignment, process, and consistency but do not explicitly assess creativity, aesthetics, pedagogy quality, or user usefulness beyond correctness.
- Step-count variability: Models are free to choose the number of steps, yet rubrics for open-ended tasks may assume a particular progression; step-invariant scoring and tolerance for alternative valid decompositions are not validated.
- Robustness of LLM-as-a-judge: There is no analysis of adversarial cases (e.g., tiny overlay text, steganography, misleading captions) or prompt-injection-like attacks embedded in images that could mislead the judge.
- Safety evaluation: “Guide” tasks can include risky procedures; safety/harmfulness checks and alignment criteria are absent from rubrics and scoring.
- Score calibration and anchoring: Reference answers average 92.2/100, indicating rubric/judge incompleteness or judge limitations; no calibration method (e.g., scaling by reference scores) is proposed to normalize across tasks.
- Version drift and reproducibility: Proprietary judges can change over time; the paper does not specify version pinning, regression tests, or a protocol to ensure longitudinal comparability.
- Out-of-distribution robustness: All references are sourced from curated platforms (Wikipedia, textbooks, D2L, WikiHow, YouTube); evaluation on OOD styles (hand-drawn scans, low-resource domains, noisy user photos) is not included.
- Error taxonomy: Beyond high-level observations (e.g., temporal inconsistencies), there is no systematic breakdown of failure types per rubric dimension to guide targeted model improvements.
- Chain-of-thought transfer analysis: The benefit of reasoning traces is shown qualitatively and on limited examples; a rigorous, task-wise, and model-wise ablation (trace length, content, placement, noise) is missing, as are privacy/IP considerations of using another model’s traces.
- Open-source judging gap: Recommended judges are proprietary; open-source judges produced divergent scores; there is no validated, open benchmarked judge baseline to ensure reproducibility.
- Scalability of rubric creation: Human refinement for 10,417 criteria may not scale; methods to automatically audit, de-duplicate, and validate rubric sets at larger scales are not developed.
- Visual grounding verification: The judge’s internal vision capabilities are a single point of failure; no auxiliary verifiers (e.g., OCR engines, spatial relation checkers) or structured annotations are used to corroborate fine-grained visual checks.
- Handling missing modalities: Policies for grading when a model outputs only text or only images (or fails to render images) are unspecified.
- Script and font diversity: Rubrics include spelling checks but only for English/Latin scripts; evaluation for non-Latin scripts, mathematical typesetting, or complex diagrams is not considered.
- Data licensing and ethics: The paper does not discuss licensing compliance for images/videos used, potential privacy concerns, or restrictions on redistribution.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging UEval’s rubric-based evaluation, dataset, and observed reasoning benefits.
- Rubric-driven model QA and release gating for multimodal systems (software, ML Ops)
- Use UEval’s data-dependent, human-validated rubrics to automatically score image+text outputs in CI/CD, setting task-specific thresholds before shipping new model versions. Potential product: an “Evaluation Harness” that wraps a recommended judge model (e.g., Gemini-2.5-Pro, GPT-5-Thinking, Qwen3-VL-235B-Thinking).
- Assumptions/dependencies: Access to a reliable judge model API, basic integration with inference pipelines, tasks similar in nature to UEval’s coverage.
- Vendor/model selection and procurement benchmarking (enterprise IT, software)
- Run RFP-style bake-offs across candidates (open-source and proprietary) using UEval tasks to quantify strengths (e.g., knowledge-heavy “Textbook/Paper” vs multi-step “Guide”) and pick the best fit.
- Assumptions/dependencies: Comparable access to model endpoints, standardized prompts, acceptance that UEval covers general science/tech tasks rather than mission-critical domains.
- Chain-of-thought “teacher-to-runner” workflow to boost non-reasoning models (software, cost optimization)
- Generate a reasoning trace with a stronger “thinking” model, append it to the user prompt, and have a faster/cheaper model produce the final multimodal output. Potential tool: a “Reasoning Trace Router” that automates teacher-student prompting.
- Assumptions/dependencies: Availability of a capable reasoning model; downstream model must be sufficiently strong to leverage the trace; latency/cost trade-offs acceptable.
- EdTech content generation with automated quality checks (education)
- Create textbook-style diagrams, step-by-step tutorials (art, life, exercise, tech), and accompanying explanations, then auto-grade with sample-specific rubrics to ensure coverage, correctness, and temporal consistency. Potential product: a “Lesson Builder” with integrated rubric scoring.
- Assumptions/dependencies: Curriculum alignment requires additional domain rubrics; judge reliability is highest on single-image tasks and slightly lower on multi-image outputs.
- Technical documentation assistants with diagram synthesis and verification (software, developer tooling)
- Draft architecture diagrams and captions from method descriptions, then verify accuracy via rubric criteria (e.g., component presence, dataflow correctness). Integration with authoring platforms (e.g., LaTeX/Overleaf plugins).
- Assumptions/dependencies: Domain rubrics tailored to internal systems; access to judge models; privacy-safe handling of proprietary designs.
- Automated content QA for marketing/knowledge portals (marketing, knowledge management)
- Check image-text alignment, labeling consistency, and correctness for visual explainers and “how-to” guides. Potential product: “Multimodal QA Bot” that flags failures against rubric criteria.
- Assumptions/dependencies: Rubric coverage for target content types; judge model alignment with human reviewers; governance for false positives/negatives.
- A/B testing and prompt evaluation at scale (ML Ops, applied research)
- Use UEval’s fine-grained rubric scoring to compare prompt templates, toolchains, or model versions for multimodal tasks, collecting robust telemetry beyond generic “win rates.”
- Assumptions/dependencies: Experiment orchestration capabilities; consistent judge model choice to avoid drift; willingness to calibrate thresholds per task.
- Dataset-informed guardrails for image text rendering (software, accessibility)
- Apply rubric criteria that penalize misspellings/garbled text in images to enforce legible visual text. Potential feature: “Render Check” for visual outputs.
- Assumptions/dependencies: Judge must reliably detect rendering errors; outputs must be accessible to the judge (e.g., resolution/format).
- Publishing and peer review assistance for figures in academia (academic publishing)
- Verify that synthesized figures and captions faithfully communicate methodological details (Diagram/Paper tasks) before submission or camera-ready preparation.
- Assumptions/dependencies: Alignment of rubrics with venue standards; human-in-the-loop for final verification.
Long-Term Applications
The following use cases require further research, scaling, domain extension, or productization beyond the current benchmark.
- Domain-specific certification and compliance standards for multimodal AI (policy/regulation, healthcare, finance, energy)
- Evolve UEval-style data-dependent rubrics into standardized, sector-specific test suites (e.g., patient education materials, risk visualizations) to certify accuracy, clarity, and safety of multimodal outputs.
- Assumptions/dependencies: Expert rubric authoring for each domain; governance processes; legal/regulatory acceptance; strong judge agreement with human experts.
- Distillation of multimodal reasoning into smaller models (software, model efficiency)
- Systematically train non-reasoning models to internalize chain-of-thought benefits (teacher-student distillation) for consistent image-text generation and stepwise planning.
- Assumptions/dependencies: Access to large-scale teacher traces; robust training signals; copyright/licensing clarity for training data; empirical validation of generalization.
- Visual planning consistency modules (software, robotics, HRI)
- Build model components that explicitly track temporal consistency and labeling across steps, improving multi-image guides and task demonstrations; extend to robot instruction UIs with visuals+text.
- Assumptions/dependencies: New architectures or training objectives; curated multi-step datasets; rigorous evaluation protocols.
- Judge ensemble services and calibration frameworks (ML Ops, evaluation science)
- Offer “Judge-as-a-Service” with ensembles of trusted MLLMs, consensus scoring, and calibration against human panels to reduce single-judge bias—especially for open-ended tasks.
- Assumptions/dependencies: Access to multiple high-quality judges; cost tolerances; reproducible calibration pipelines.
- Automated formative assessment with multimodal student submissions (education)
- Grade diagrams plus written explanations in STEM coursework using data-dependent rubrics, providing granular feedback on conceptual coverage and visual reasoning.
- Assumptions/dependencies: Course-specific rubric authoring; accommodations for diverse student styles; teacher review workflows.
- High-quality synthetic data generation filtered by rubrics (model training, data ops)
- Generate large-scale image+text pairs for training unified models, using rubric scores to select only high-quality, consistent samples.
- Assumptions/dependencies: Scalable generation infrastructure; judge availability and cost; bias detection; diversity maintenance.
- Industry-specific design and engineering assistants (energy, manufacturing, civil engineering)
- Produce accurate technical diagrams and narratives (e.g., process flows, structural features) with rubric-verified details, supporting design reviews and training materials.
- Assumptions/dependencies: Detailed domain rubrics authored by engineers; confidentiality and IP constraints; robust factual grounding.
- Interactive multimodal manuals and micro-tutors (consumer apps, support)
- Build adaptive “how-to” agents that generate visuals+text, detect inconsistencies, and iterate until rubric criteria are met, eventually achieving reliable DIY/repair guides.
- Assumptions/dependencies: On-device or cloud inference capacity; robust evaluation loops; user experience design for iterative guidance.
- Benchmark expansion and living leaderboards (research community, vendors)
- Maintain an evolving multimodal benchmark with task additions and rubric improvements, enabling fair, transparent reporting across sectors and model classes.
- Assumptions/dependencies: Community governance; continuous human review; transparent scoring protocols; stable access to judge models.
- Safety and truthfulness guardrails for multimodal generation (policy, trust & safety)
- Extend rubrics to penalize hallucinated visual elements or misleading diagrams; integrate with content safety pipelines to reduce harm in sensitive domains.
- Assumptions/dependencies: New safety rubrics; incident response processes; alignment with platform policies; continual monitoring.
Glossary
- Autoregressive objective: A training setup where a model predicts the next token given previous tokens, commonly used for sequence generation. "train models with a purely autoregressive objective"
- Chain-of-Thought reasoning: An approach where models produce step-by-step intermediate reasoning traces that guide final outputs. "These observations suggest that Chain-of-Thought reasoning~\citep{wei2023chainofthoughtpromptingelicitsreasoning}, long studied in LLMs, may also play an important role in unified multimodal generation."
- Closed-ended tasks: Tasks with specific, factual targets and clear correct answers, emphasizing precise, grounded responses. "Closed-ended tasks, including space, textbook, diagram, and paper, emphasize factual understanding and grounded explanation"
- Data-dependent rubrics: Evaluation criteria tailored to each specific sample, derived from the question and reference answers. "We propose using data-dependent rubrics to evaluate outputs from unified models."
- Data-independent evaluation: An evaluation strategy that applies the same generic grading prompt across all samples, ignoring per-sample nuances. "most current evaluations~\citep{xia2024mmie,zhou2025opening} are data-independent: a single generic prompt is applied to grade all samples."
- Diffusion-based approaches: Generative methods that iteratively denoise data from noise, widely used in image synthesis. "Some methods adopt diffusion-based approaches"
- Frontier model: A state-of-the-art, cutting-edge model used for evaluation or judging due to its strong capabilities. "We find that using a frontier model yields results well aligned with human judgment"
- Hybrid methods: Modeling strategies that combine multiple paradigms (e.g., diffusion and autoregression) to leverage their complementary strengths. "There are also hybrid methods that combine both approaches"
- Image-text alignment: The degree to which generated images and accompanying text are semantically consistent with each other. "evaluate higher-level generation qualities (e.g, image-text alignment)."
- Instruction-tuning data: Large collections of instruction–response pairs used to fine-tune models to follow directions. "these models require millions of instruction-tuning data"
- Interleaved text-and-image generation: Producing outputs that mix text and images in a single, coherent sequence. "unify understanding and generation benchmarks as interleaved text-and-image generation"
- Judge model: A model employed to score generated outputs against rubric criteria, acting as an automated evaluator. "We employ an MLLM (e.g, Gemini-2.5-Pro) as a judge to evaluate images and text generated by unified models."
- LLM-as-a-judge: Using a LLM to assess and grade other models’ outputs. "simple LLM-as-a-judge methods can miss the subtleties."
- Multimodal LLM (MLLM): A LLM augmented to process and generate multiple modalities such as text and images. "Different from previous works that rely on multimodal LLMs (MLLMs) to rate image quality or text accuracy"
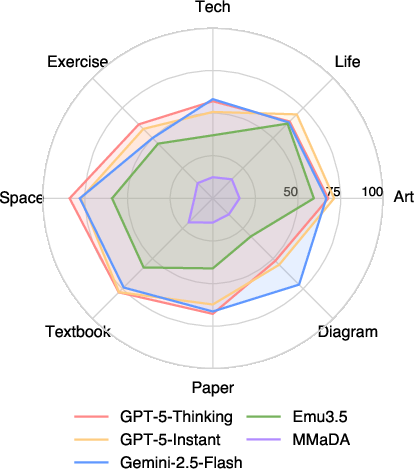
- Multi-step planning: The capability to structure outputs as a coherent sequence of steps to achieve a goal. "the tasks requiring multi-step planning (e.g, art, life) yield substantially lower scores"
- Open-ended tasks: Tasks that admit multiple valid outputs and emphasize creativity or process (e.g., step-by-step guides). "In contrast, open-ended tasks, including art, life, tech, and exercise, focus on step-by-step drawings"
- Pairwise comparisons: An evaluation method that compares outputs in pairs to compute relative preferences or win rates. "\citet{zhou2025opening} use average win rates from pairwise comparisons of model outputs containing images and text"
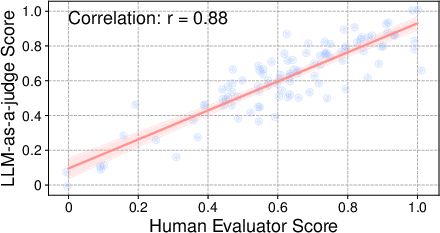
- Pearson correlation: A statistic that measures linear correlation between two sets of values. "The Pearson correlation (r = 0.88) demonstrates that the LLM judge closely aligns with human evaluation."
- Radar chart: A radial visualization for comparing multivariate performance across categories. "To better understand performance differences, \figref{fig:model_radar} presents a radar chart comparing models across tasks."
- Reasoning trace: The recorded intermediate reasoning steps from a model that can be appended to prompts to guide other models. "we append the reasoning trace produced by GPT-5-Thinking to the end of the original question prompt"
- Rubric criteria: Fine-grained, itemized requirements used to assess specific aspects of generated outputs. "UEval contains 10,417 validated rubric criteria"
- Rubric generator: A model that drafts per-sample, itemized rubrics from the question and reference answers. "we provide the question along with its reference image-text answer to a rubric generator (e.g, Gemini-2.5-Pro)"
- Rubric-based scoring system: An evaluation mechanism that grades outputs by checking satisfaction of a predefined set of rubric items. "we design a rubric-based scoring system in UEval."
- Temporal consistency: Coherence of a sequence over time or steps, ensuring logical progression without contradictions. "Rubrics for open-ended tasks evaluate higher-level qualities of the output (e.g, temporal consistency)."
- Temporal inconsistencies: Errors where sequential outputs contradict or misorder steps over time. "The generated images often exhibit temporal inconsistencies."
- Text-to-image (T2I) generation: Creating images conditioned on textual prompts. "text-to-image generation"
- Unified multimodal generation: Producing both text and images in a single, integrated response to a query. "unified multimodal generation that produces both text and images in response to a single query"
- Unified multimodal models: Models that integrate both multimodal understanding and generation capabilities within one system. "Unified multimodal models~\citep{tong2024metamorph, zhou2024transfusionpredicttokendiffuse, deng2025emerging} aim to integrate multimodal understanding and generation capabilities within a single system."
- Visual encoder: A component that transforms images into representations usable by LLMs. "These models~\citep{alayrac2022flamingo, dai2023instructblip, liu2023visual, li2023blip, zhuminigpt} typically integrate a visual encoder~\citep{radford2021learningtransferablevisualmodels, dosovitskiy2020image, he2022masked} with a pre-trained LLM"
- Visual question answering (VQA): A task where a model answers textual questions about input images. "visual question answering~\citep{marino2019okvqavisualquestionanswering, liu2024mmbench, yue2024mmmumassivemultidisciplinemultimodal,fu2024mmecomprehensiveevaluationbenchmark}"
Collections
Sign up for free to add this paper to one or more collections.