- The paper introduces ROVER, a benchmark that evaluates reciprocal cross-modal reasoning in unified multimodal models.
- It employs two settings—verbally-augmented visual generation and visually-augmented verbal generation—across multiple reasoning subtasks.
- Results show closed-source models outperform open-source ones, exposing challenges in symbolic visual abstraction and logical consistency.
ROVER: Benchmarking Reciprocal Cross-Modal Reasoning for Omnimodal Generation
Introduction and Motivation
The ROVER benchmark addresses a critical gap in the evaluation of Unified Multimodal Models (UMMs): the ability to perform reciprocal cross-modal reasoning, where one modality (text or image) is used to guide, verify, or refine outputs in the other. Existing benchmarks typically assess unimodal reasoning in isolation, failing to capture the synergistic reasoning required for true omnimodal intelligence. ROVER introduces a comprehensive, human-annotated benchmark with 1,312 tasks grounded in 1,876 images, explicitly designed to evaluate reciprocal cross-modal reasoning in two complementary settings: verbally-augmented reasoning for visual generation and visually-augmented reasoning for verbal generation.
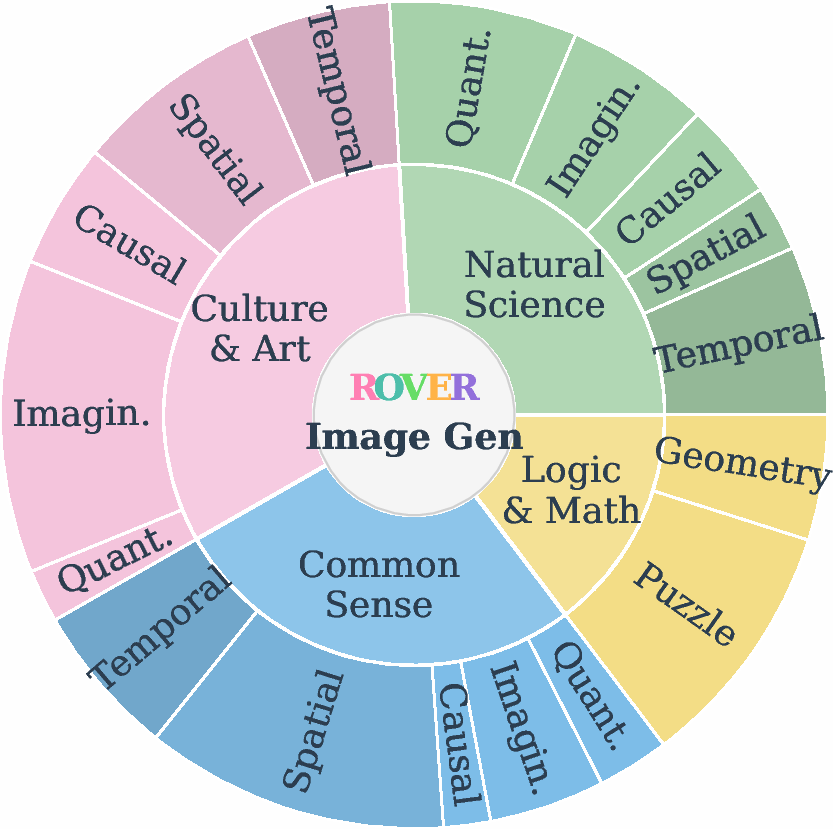
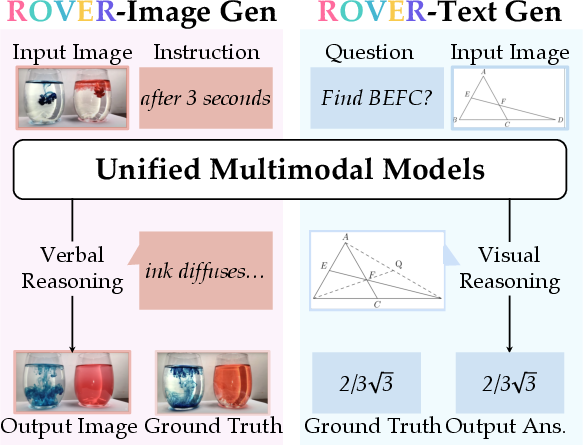
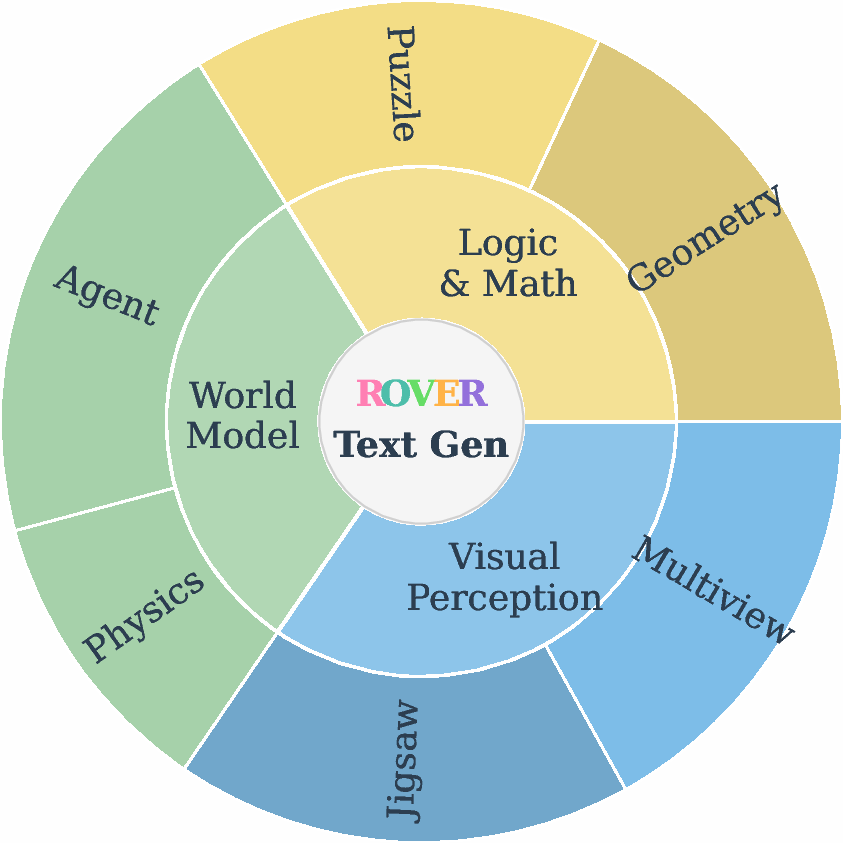
Figure 1: The ROVER benchmark evaluates UMMs through reciprocal cross-modal reasoning: \ourvg (left) requires generating images with language-augmented reasoning, while \ourir (right) requires generating text answers with visually-augmented reasoning.
Benchmark Design
Verbally-Augmented Reasoning for Visual Generation
ROVER's \ourvg component evaluates the capacity of UMMs to synthesize images guided by complex verbal reasoning chains. The benchmark spans four conceptual domains—natural science, culture and art, common sense, and logic—instantiated across seven reasoning subtasks: temporal, spatial, causal, synthetic, quantitative, abstract, and mathematical. Each task provides a textual prompt, an initial image, and a chain of constraints that the output image must satisfy.
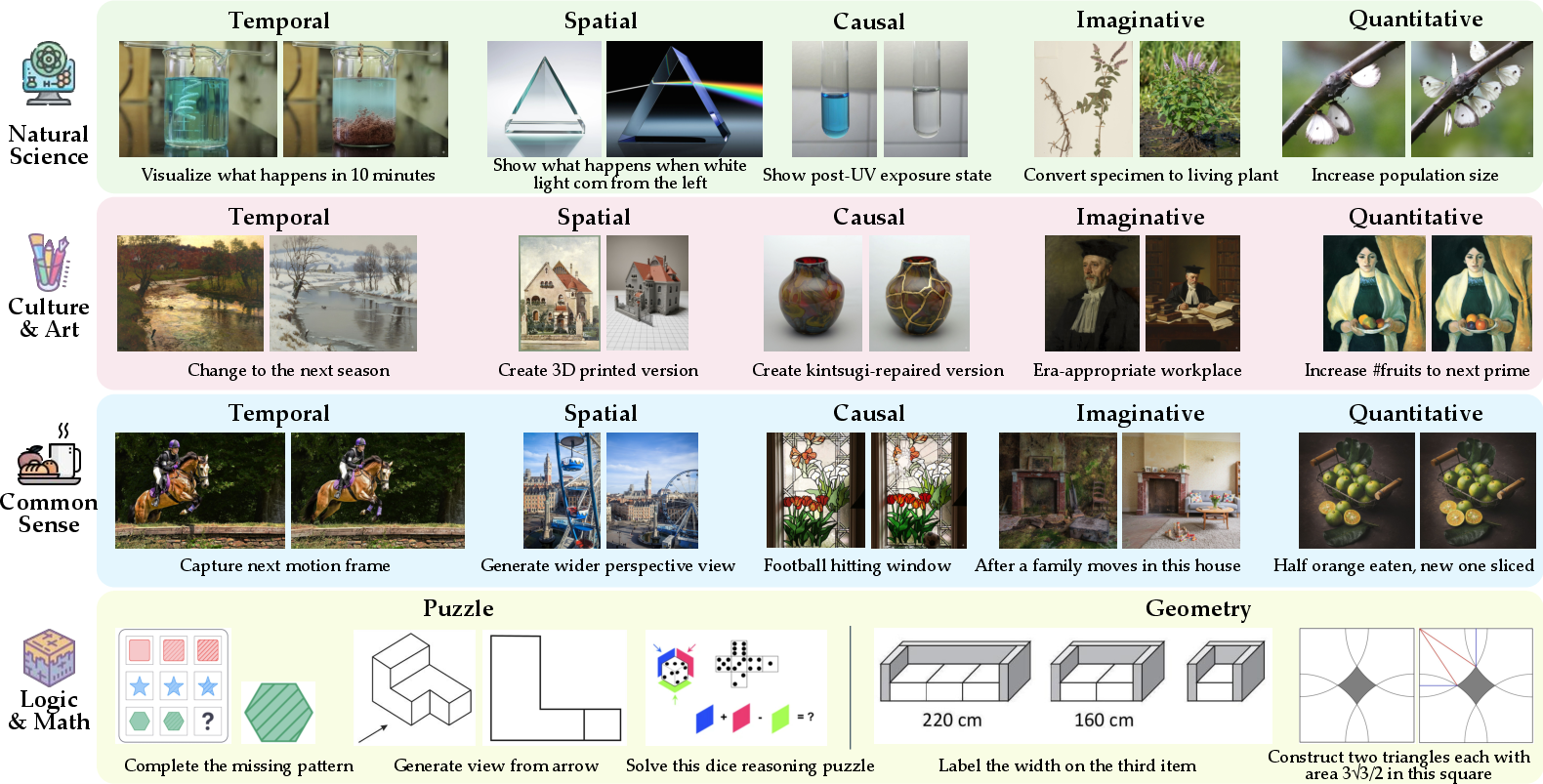
Figure 2: Overview of \ourvg, the benchmark for evaluating how UMMs generate images under intensive verbal reasoning, spanning 4 domains and 7 reasoning subtasks.
Visually-Augmented Reasoning for Verbal Generation
The \ourir component evaluates the ability of UMMs to generate language responses supported by interleaved visual reasoning. Tasks require models to produce intermediate visualizations that facilitate reasoning for question answering, reflecting human cognitive strategies that integrate verbal and visual thinking. The benchmark covers three scenarios—physical world modeling, logical assistance, and visual perception enhancement—across six subtasks.
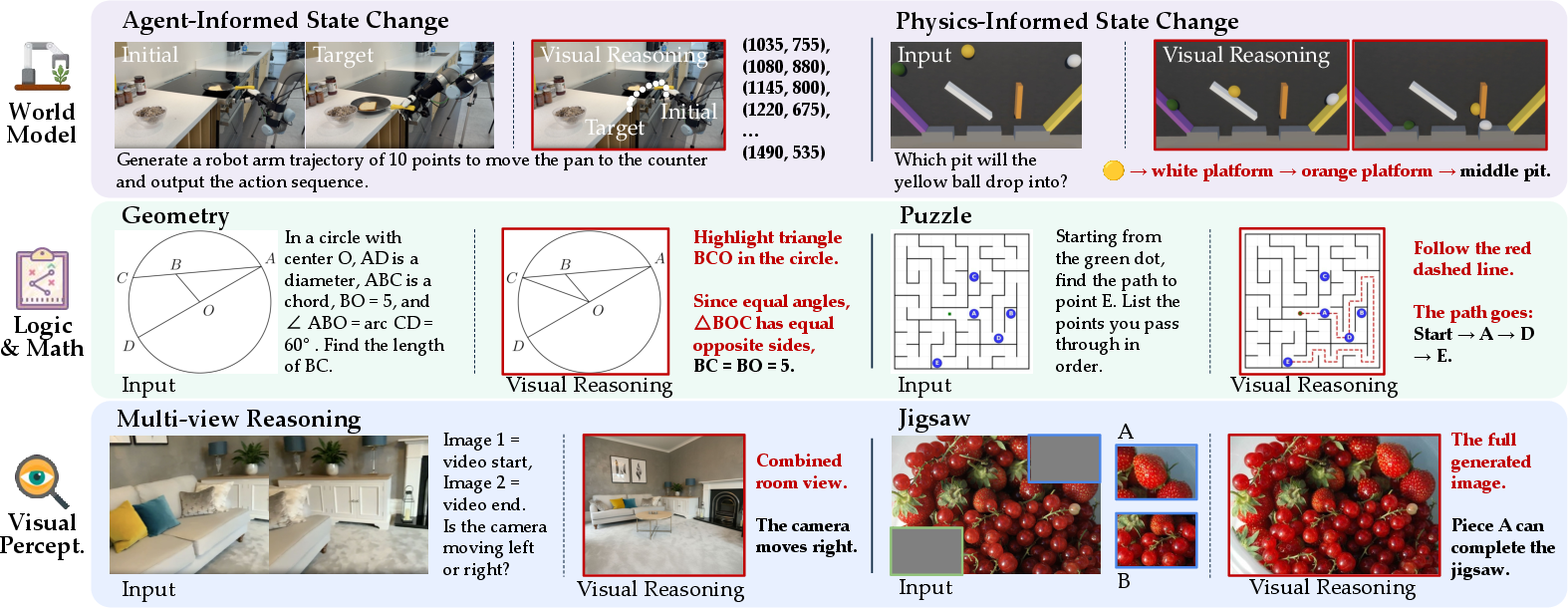
Figure 3: Overview of \ourir, the benchmark for evaluating visually-augmented reasoning in verbal generation, spanning 3 scenarios and 6 subtasks.
Data Curation and Evaluation Protocol
ROVER's dataset was curated through expert selection and collaborative task generation, ensuring genuine visual understanding and complex reasoning chains. Each instance includes a reasoning prompt, target descriptions, domain-specific keywords, and optionally reference images. Evaluation is performed using a multi-dimensional protocol combining automated VLM judges (GPT-4.1) with expert validation, scoring outputs on logical coherence, alignment, consistency, visual fidelity, and image quality. The protocol is calibrated for reliability and cross-VLM consistency.
Experimental Results
ROVER's evaluation of 17 unified models reveals that cross-modal reasoning capabilities are the primary determinant of visual generation quality. Closed-source models (e.g., Gemini 2.5 Flash, GPT-5) demonstrate superior reasoning and alignment, resulting in higher visual output quality. Open-source models lag significantly, with reasoning processes approximately 38% lower and alignment performance 31% lower than closed-source models, leading to a 39% deficit in visual generation quality.

Figure 4: Example outputs on \ourvg. Each row corresponds to one reasoning subtask, with the input on the left and outputs from representative UMMs shown across columns.
Models supporting interleaved image-text generation outperform those limited to single-turn outputs, with a 38.1% advantage in reasoning visual metrics. This demonstrates that reasoning and generation processes are synergistic, and that unimodal models—even when combined—cannot replicate the cross-modal reasoning required for ROVER.
Visually-Augmented Reasoning: Physical vs. Symbolic Tasks
ROVER exposes a dissociation between physical and symbolic visual reasoning. UMMs excel at generating visual reasoning steps for perceptual and physical world concepts but fail to construct visual abstractions for symbolic tasks. Visual augmentation improves performance on physical world modeling and visual perception tasks but yields minimal or negative improvements on logic and math tasks, indicating a fundamental inability to visually symbolize abstract reasoning.
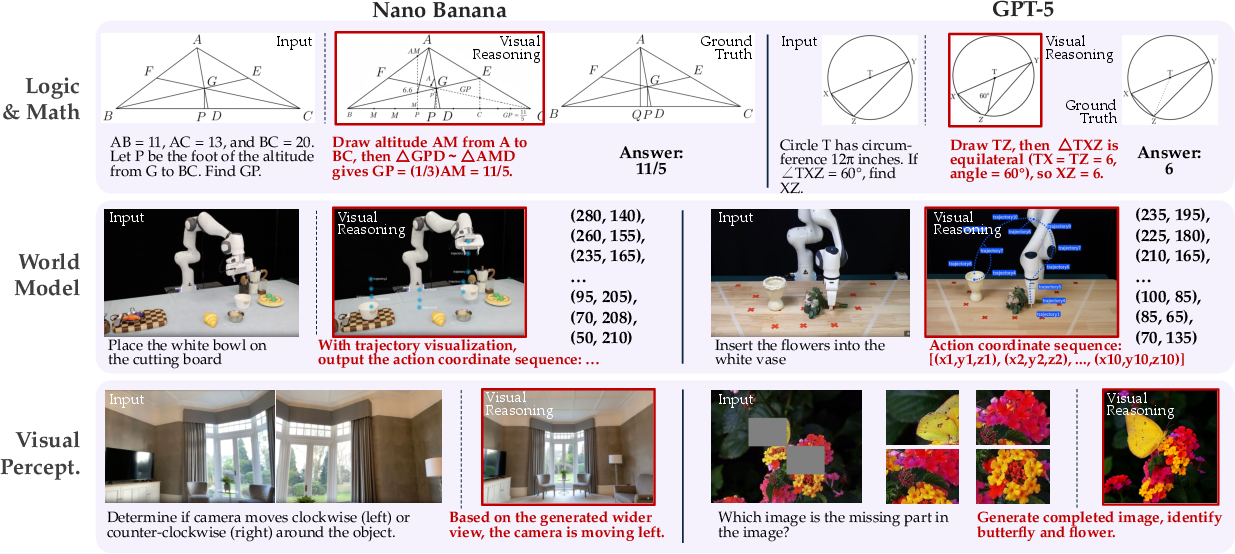
Figure 5: Example outputs on \ourir. Each row corresponds to one reasoning scenario, with the input on the left and outputs from representative unified models shown across columns.
Comparison with Image Editing Models
Unified models demonstrate absolute advantages over specialized image editing models in reasoning-dependent tasks. While editing models excel at text rendering and consistency, they lack the internal reasoning capabilities required for ROVER, confirming that cross-modal reasoning is essential for omnimodal generation.
Cascade Reasoning and Visual Reasoning Augmentation
ROVER's cascade reasoning experiments show that UMMs outperform cascade approaches (e.g., FLUX+GPT with GPT-4o refinement) in cross-modal reasoning, with a 20.7% improvement in visual consistency. Visual reasoning artifacts generated by UMMs can augment downstream VLMs on perceptual tasks (+3.5% and +3.8% improvement), but low-quality visual reasoning degrades performance on logic tasks (-1.4%), highlighting the necessity of high-fidelity visual reasoning.

Figure 6: Cascade reasoning evaluation across EditWorld and ROVER benchmarks, comparing cascade approaches against UMMs.
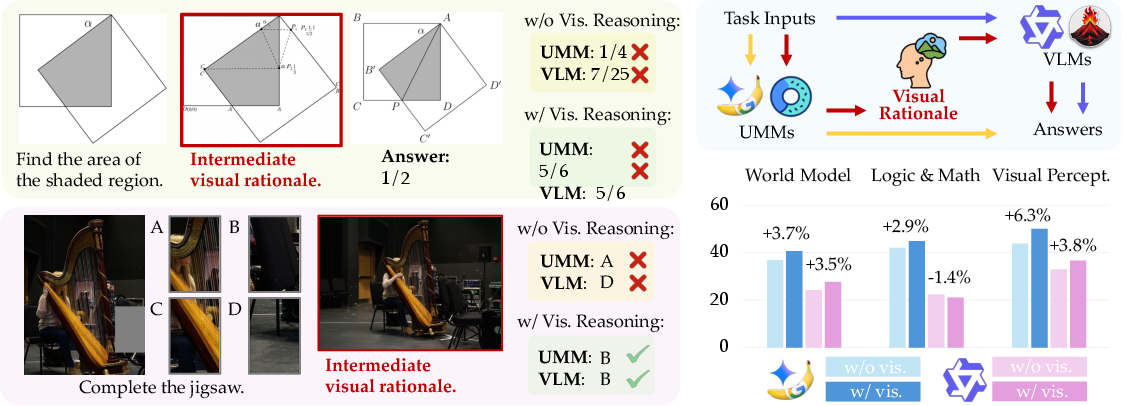
Figure 7: Visual reasoning augmentation evaluation across three problem domains, comparing VLM performance with and without visual reasoning artifacts from UMMs.
Analysis of Reasoning Capabilities
ROVER's analysis reveals uneven performance across reasoning subtasks. Models excel in temporal, spatial, and causal reasoning but struggle with abstract and mathematical tasks, with severe counting hallucinations in quantitative reasoning. Correlation analysis shows strong interdependence among physical reasoning types, while abstract reasoning develops as a distinct capability.
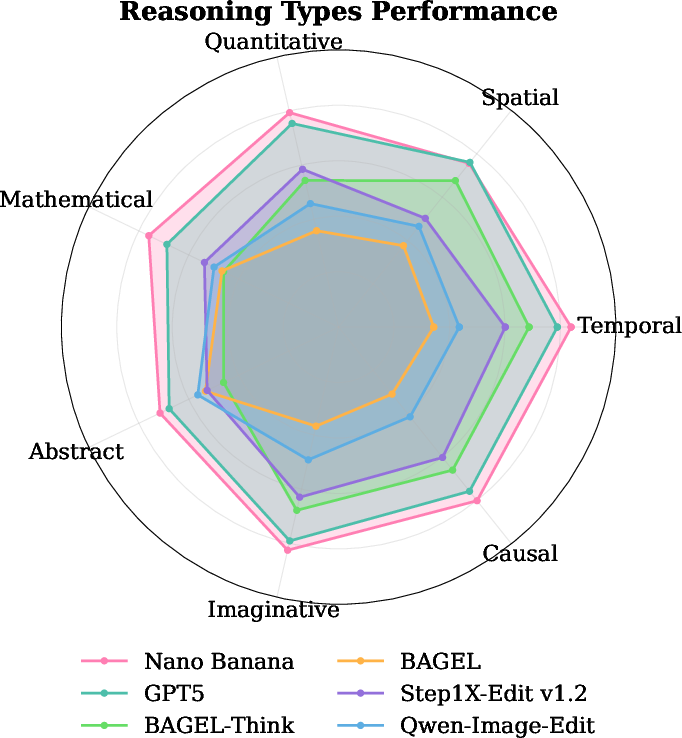
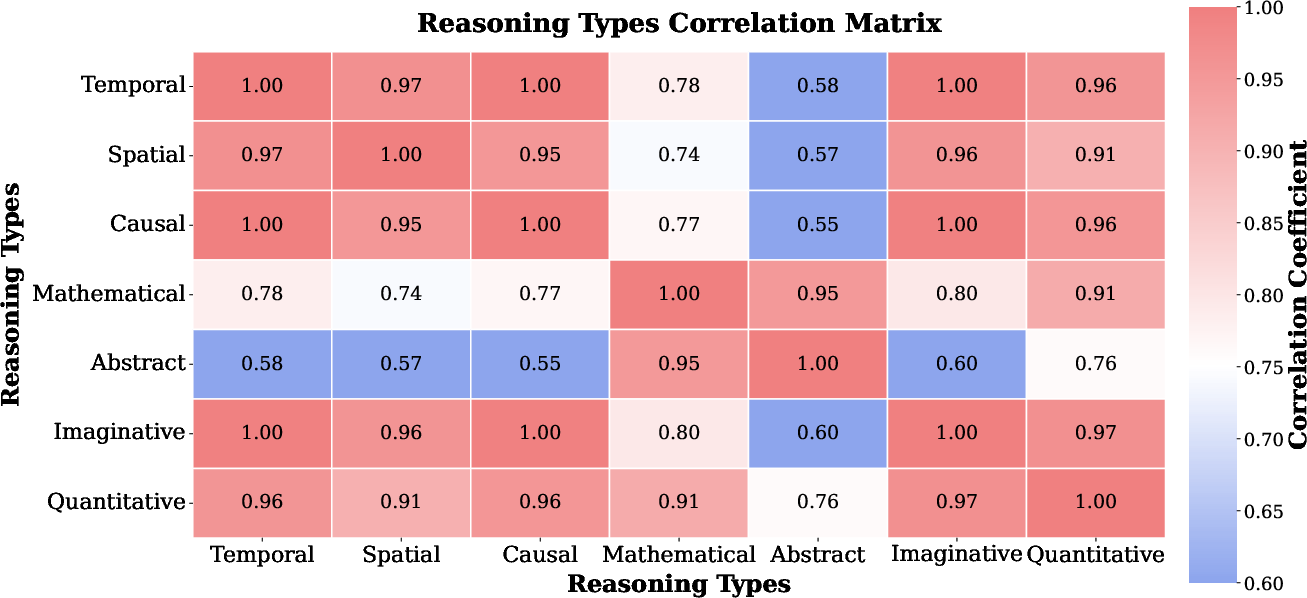
Figure 8: Reasoning subtask performances.
Evaluation Reliability
A user study with human experts confirms the reliability of the VLM-as-judge protocol, with strong Pearson correlation coefficients and low mean absolute error between GPT-4.1 and human ratings. Reasoning-related metrics exhibit larger discrepancies due to hallucination tendencies, but differences remain within acceptable bounds.
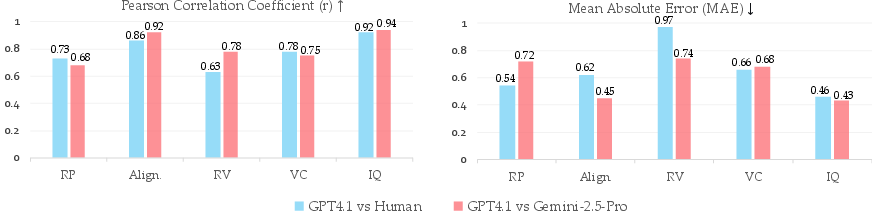
Figure 9: Evaluation reliability of GPT-4.1 across five assessment dimensions. Left: Pearson correlation coefficients between GPT-4.1 and human experts (green) versus GPT-4.1 and Gemini-2.5-Pro (purple). Right: Mean Absolute Error for the same comparisons.
Implications and Future Directions
ROVER establishes reciprocal cross-modal reasoning as a critical frontier for omnimodal generation. The benchmark exposes fundamental limitations in current UMMs, particularly in symbolic visual reasoning and the translation of abstract logic into visual form. These findings suggest that independent optimization of constituent modalities is insufficient; future UMMs must develop mechanisms for deep cross-modal integration and abstraction. ROVER provides actionable insights for training paradigms, architectural design, and evaluation protocols, informing the next generation of unified multimodal models.
Conclusion
ROVER introduces a rigorous benchmark for reciprocal cross-modal reasoning, systematically evaluating UMMs across 23 task types and exposing key capability gaps. The results highlight the necessity of cross-modal reasoning for omnimodal generation and provide a foundation for advancing unified multimodal intelligence in both practical and theoretical dimensions.