- The paper introduces RealUnify, a novel benchmark that assesses the bidirectional synergy between visual understanding and image generation.
- The paper employs a dual-evaluation protocol, using both end-to-end and stepwise decomposition to diagnose model bottlenecks.
- The study reveals that unified models, despite strong individual capabilities, struggle to achieve true synergy compared to specialist combinations.
RealUnify: A Comprehensive Benchmark for Evaluating Synergy in Unified Multimodal Models
Motivation and Benchmark Design
The RealUnify benchmark addresses a critical gap in multimodal AI evaluation: whether unified models that integrate visual understanding and generation truly benefit from architectural unification via synergetic interaction between these capabilities. Prior benchmarks have either assessed understanding and generation in isolation or superficially combined tasks without probing for genuine bidirectional synergy. RealUnify is the first benchmark to systematically evaluate and diagnose the mutual enhancement between understanding and generation, providing a rigorous framework for unified model assessment.
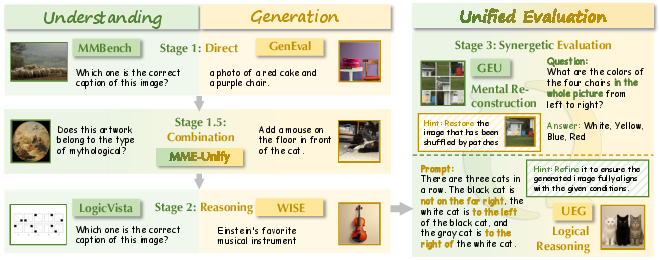
Figure 1: RealUnify uniquely targets the synergy between understanding and generation, moving beyond prior benchmarks that only test isolated or superficially integrated capabilities.
RealUnify comprises 1,000 human-annotated instances spanning 10 categories and 32 subtasks, organized along two axes:
- Understanding Enhances Generation (UEG): Tasks require reasoning (commonsense, logic, mathematics, scientific principles, code interpretation) to guide image generation.
- Generation Enhances Understanding (GEU): Tasks necessitate mental simulation or reconstruction (e.g., spatial reordering, visual tracking, attentional focusing, navigation) to solve reasoning problems.
The benchmark employs a dual-evaluation protocol: direct end-to-end assessment and diagnostic stepwise evaluation, which decomposes tasks into distinct understanding and generation phases. This protocol enables precise attribution of performance bottlenecks to either core ability deficiencies or integration failures.
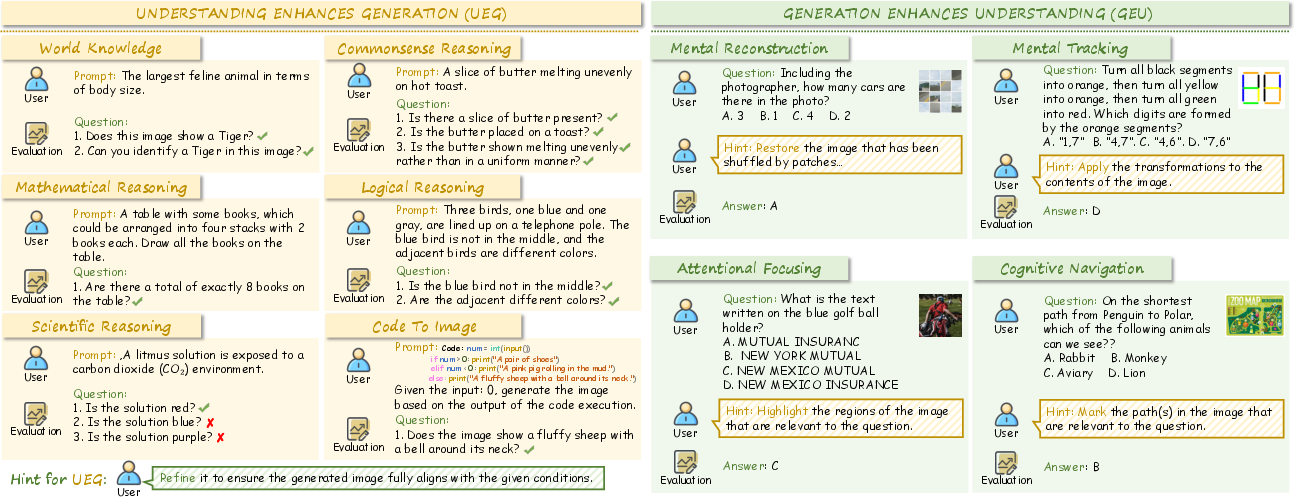
Figure 2: RealUnify's structure includes UEG and GEU axes, each with multiple task types and stepwise hints for decomposition.
Evaluation Protocol and Experimental Setup
Direct evaluation requires models to solve tasks in an end-to-end fashion, reflecting realistic deployment scenarios. Stepwise evaluation decomposes each task into sequential understanding and generation stages, allowing for fine-grained analysis of whether performance limitations arise from weak individual capabilities or from a lack of genuine synergy.
For UEG, models must interpret prompts and generate images that reflect correct reasoning. For GEU, models must leverage generative capabilities to facilitate complex visual reasoning, such as reconstructing shuffled images or tracking multi-step transformations.
Polling-based evaluation is used for image generation tasks, with verification questions judged by Gemini 2.5 Pro to ensure output fidelity and alignment with intended targets.
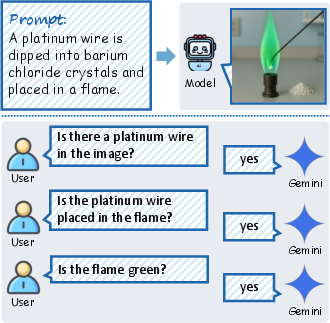
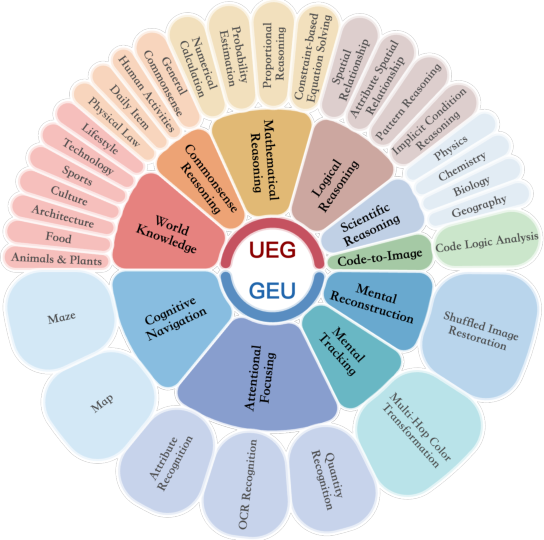
Figure 3: Polling-based evaluation with Gemini 2.5 Pro ensures rigorous assessment of generated image accuracy.
Empirical Findings and Analysis
Extensive evaluation of 12 unified models (11 open-source, 1 proprietary) and 6 specialized baselines reveals several key patterns:
- Direct Evaluation: Unified models perform poorly on both UEG and GEU tasks. The best open-source model achieves only 37.5% accuracy on UEG, while the proprietary Nano Banana reaches 63.0%. GEU performance is similarly limited, indicating a lack of spontaneous capability integration.
- Stepwise Evaluation: Decomposing UEG tasks into understanding-then-generation stages yields significant performance improvements (e.g., BAGEL: 32.7% → 47.7%), demonstrating that models possess the requisite knowledge but cannot seamlessly integrate it. Conversely, decomposing GEU tasks leads to performance degradation, suggesting reliance on understanding shortcuts rather than effective generative reasoning.
- Oracle Upper Bound: Combining the best specialist models (Gemini-2.5-Pro for understanding, GPT-Image-1 for generation) in a stepwise manner achieves 72.7% on UEG, far surpassing current unified models and establishing a clear upper bound.
These results robustly support the claim that architectural unification alone is insufficient for achieving genuine synergy. Unified models retain strong individual capabilities but fail to leverage them in a mutually enhancing fashion.
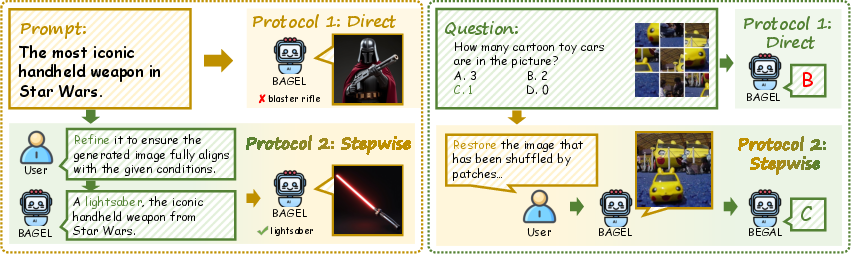
Figure 4: Stepwise execution enables unified models to solve complex tasks by explicitly integrating understanding and generation.

Figure 5: Even with stepwise decomposition, unified models often struggle, only succeeding when provided with ground-truth intermediate results.
Task Categories and Representative Examples
RealUnify's UEG tasks include World Knowledge, Commonsense Reasoning, Mathematical Reasoning, Logical Reasoning, Scientific Reasoning, and Code-to-Image. GEU tasks comprise Mental Reconstruction, Mental Tracking, Attentional Focusing, and Cognitive Navigation.
Representative examples demonstrate the necessity of cross-capability transfer for successful task completion. For instance, generating an image of a lightsaber requires both factual knowledge and visual synthesis, while reconstructing a shuffled image demands generative simulation to enable accurate reasoning.
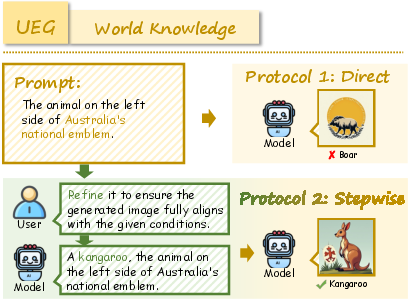

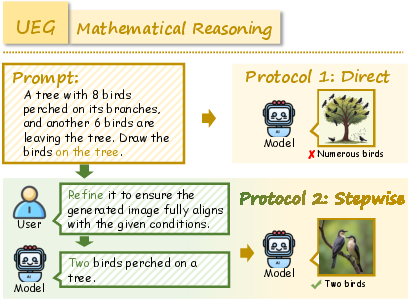

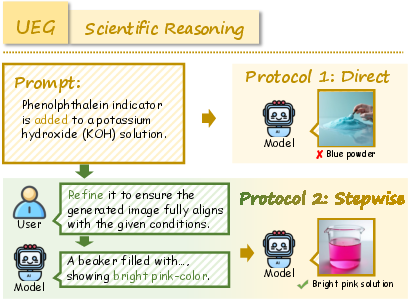
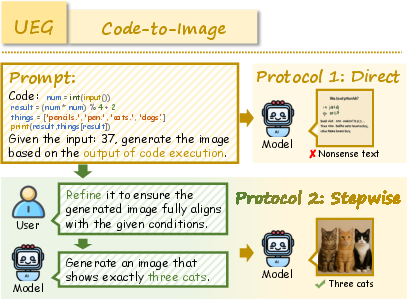
Figure 6: Example of World Knowledge task requiring factual grounding for image generation.
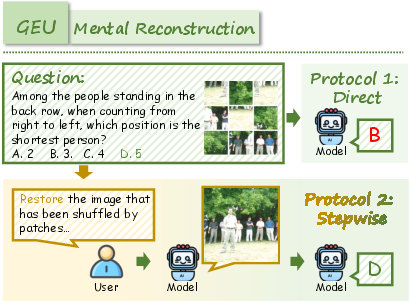
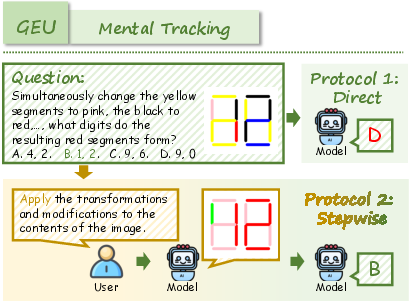
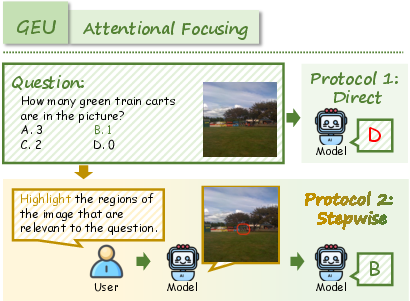
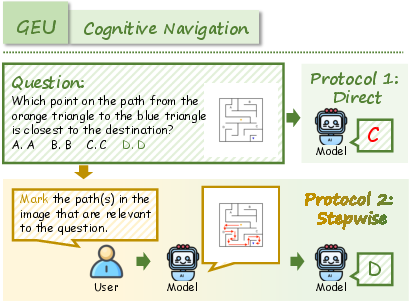
Figure 7: Example of Mental Reconstruction task requiring generative simulation for spatial reasoning.
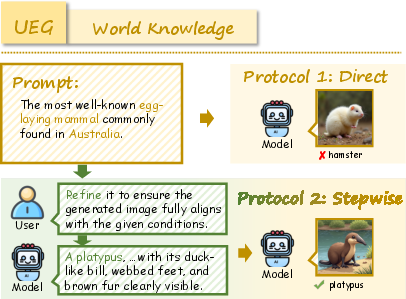
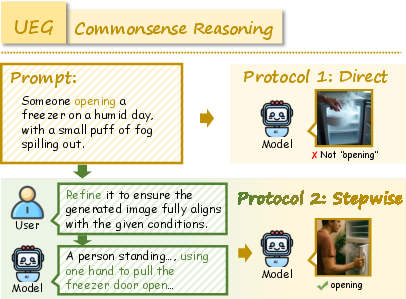
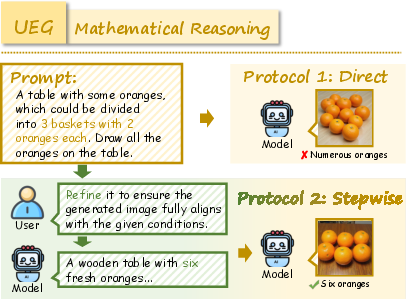
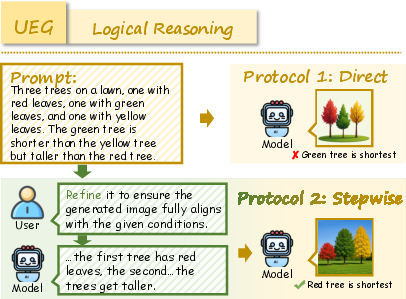
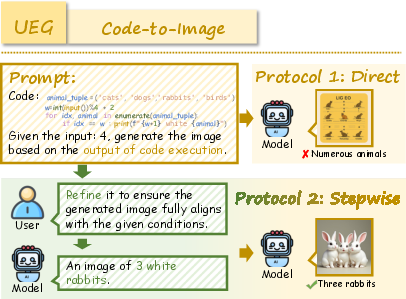
Figure 8: Additional World Knowledge example illustrating domain coverage.
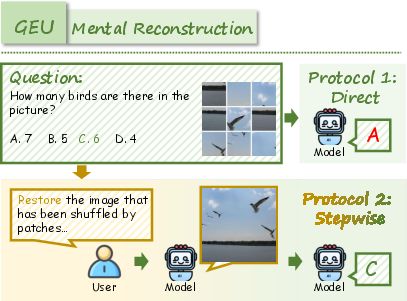
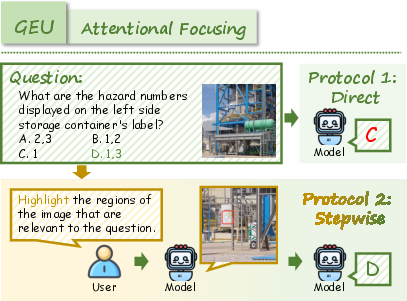
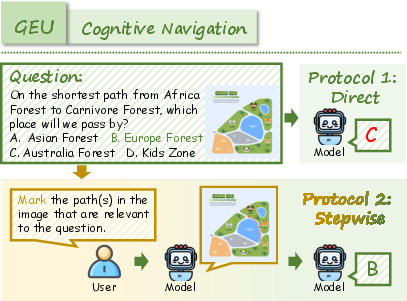
Figure 9: Additional Mental Reconstruction example highlighting spatial arrangement challenges.
Failure Modes and Bottlenecks
Unified models exhibit common failure modes during image generation, including attribute entanglement, inaccurate quantity, attribute fidelity errors, and confused spatial relationships. Fine-grained features (e.g., text, fingers) are often distorted, and models may generate scenes violating commonsense or physical laws.

Figure 10: Attribute mixing, quantity mismatch, and spatial relationship errors in image generation.

Figure 11: Detail loss, distortion, and commonsense violations in generated images.
These limitations become pronounced in tasks requiring true synergy, serving as bottlenecks for complex real-world problem solving.
Implications and Future Directions
The findings from RealUnify have significant implications for both practical deployment and theoretical model design:
- Training Strategies: There is a clear need for advanced training schemes and stronger inductive biases that explicitly encourage cross-capability interaction, such as curriculum learning, multi-stage reasoning, and joint optimization objectives.
- Model Architecture: Future unified models should incorporate mechanisms for explicit reasoning transfer, generative simulation, and memory augmentation to facilitate bidirectional synergy.
- Benchmarking Standards: RealUnify sets a new standard for multimodal evaluation, emphasizing the necessity of synergy-focused benchmarks for assessing general-purpose AI.
The persistent gap between unified models and specialist or oracle combinations suggests that progress in unified modeling will require innovations beyond mere architectural integration. Research should focus on methods that foster emergent synergetic behaviors, such as self-evolution cycles, chain-of-thought reasoning for generation, and latent visual token manipulation.
Conclusion
RealUnify provides a rigorous, comprehensive framework for evaluating the synergy between understanding and generation in unified multimodal models. Empirical results demonstrate that current unified models, despite strong individual capabilities, fail to achieve genuine bidirectional enhancement. Bridging this gap will require new training paradigms, architectural innovations, and synergy-focused benchmarks. RealUnify thus serves as both a diagnostic tool and a catalyst for future research in unified multimodal intelligence.

