- The paper introduces a token-level, low-temperature sampling technique that sharpens the LLM's output distribution and reduces inference latency by over 10× compared to MCMC methods.
- It empirically validates the approach on benchmarks like MATH500, HumanEval, and GPQA, demonstrating performance that matches or exceeds one-shot GRPO.
- The study provides theoretical insights by deriving bounds linking global power distributions to local autoregressive sampling, establishing a scalable reasoning framework for LLMs.
Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening
Introduction
The paper "Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening" (2601.21590) addresses the enhancement of reasoning in LLMs through a novel sampling technique. Traditional reinforcement learning (RL) post-training has been dominant for improving the reasoning of LLMs, primarily through methods like GRPO, but it is purportedly more about distribution sharpening rather than acquiring new capabilities. Recent studies suggest that power distribution sampling using MCMC can match RL post-training performance, yet MCMC's computational overhead hinders its practicality.
Methodology
The authors propose an innovative alternative to MCMC by leveraging a token-level, scaled low-temperature distribution, allowing for a distribution sharpening effect similar to RL post-training but without training or external rewards. This method, which approximates the power distribution globally through autoregressive sampling, significantly reduces latency, making it 10 times faster than MCMC-based approaches.
Empirical Evaluation
The empirical evaluation involves tasks across four LLMs — Qwen2.5-7B, Qwen2.5-Math-7B, DeepSeek-Math-7B, and DeepSeek-Math-7B-RL — against benchmarks including MATH500, HumanEval, and GPQA. The results demonstrate that the proposed power sampling method either matches or surpasses the one-shot GRPO, offering a considerable reduction in inference latency compared to MCMC.
Strong Numerical Results: The power sampling approach improved reasoning tasks' performance while achieving over 10× reductions in inference time compared to MCMC, thus showcasing its practical implications in real-world applications.
Theoretical Contributions
The paper makes significant theoretical strides by deriving a relationship between global power distributions and local autoregressive sampling. It provides a closed-form expression and bounds for the necessary scaling factor, tying the methodology from a theoretical foundation into efficient practical application.
Implications and Future Directions
The findings have broad implications for AI, suggesting that LLMs' reasoning capabilities can be significantly enhanced through efficient inference-time sampling strategies. This could democratize access to high-performance LLMs by reducing dependence on resource-intensive training processes. Future directions may include adapting the approach to reduce variance through control variates and further optimizing compute through adaptive budgets.
Conclusion
In conclusion, the study presents a compelling alternative to RL post-training for sharpening LLM distributions. It theoretically and empirically validates a scalable method for efficient reasoning, offering a promising avenue for further research in AI optimization and deployment strategies.
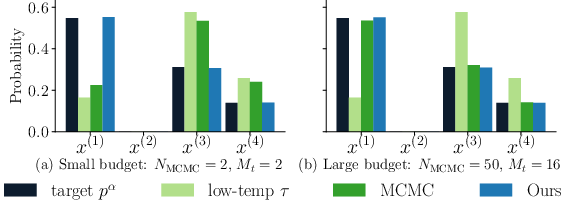
Figure 1: Toy example comparing the target power distribution pα, the low-temperature distribution, and the empirical histograms of MCMC and our method (α=4, τ=1/α=0.25).