Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning
Abstract: Fine-tuning pre-trained LLMs for down-stream tasks is a critical step in the AI deployment pipeline. Reinforcement learning (RL) is arguably the most prominent fine-tuning method, contributing to the birth of many state-of-the-art LLMs. In contrast, evolution strategies (ES), which once showed comparable performance to RL on models with a few million parameters, was neglected due to the pessimistic perception of its scalability to larger models. In this work, we report the first successful attempt to scale up ES for fine-tuning the full parameters of LLMs, showing the surprising fact that ES can search efficiently over billions of parameters and outperform existing RL fine-tuning methods in multiple respects, including sample efficiency, tolerance to long-horizon rewards, robustness to different base LLMs, less tendency to reward hacking, and more stable performance across runs. It therefore serves as a basis to unlock a new direction in LLM fine-tuning beyond what current RL techniques provide. The source codes are provided at: https://github.com/VsonicV/es-fine-tuning-paper.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to “fine-tune” LLMs. Fine-tuning means taking a model that already knows a lot about language and teaching it to do a specific job better. Most people today use a method called reinforcement learning (RL) for this. The authors show that another method, called evolution strategies (ES), can fine-tune very large models too—and in several ways it works better than RL.
What questions did the paper ask?
In simple terms, the authors explored five big questions:
- Can evolution strategies, which used to be used on much smaller models, scale up to today’s huge LLMs with billions of “knobs” (parameters)?
- If we only reward the final result (like whether an answer is correct) and not each step, can ES learn more efficiently than RL?
- Does ES work well across many different base models, not just one or two?
- Is ES less likely than RL to “cheat” the reward (called reward hacking), like giving weird answers that score high but are not useful?
- Is ES more reliable—does it give stable results across multiple training runs?
How did they do it?
Think of an LLM as a giant soundboard with billions of sliders. Fine-tuning is about nudging those sliders so the model behaves better for a task.
- What ES does (everyday analogy): Imagine a team of explorers trying to find the highest point on a bumpy landscape in the dark.
- You make many slightly different copies of the model by adding tiny random tweaks to the sliders (like sending scouts in nearby directions).
- You test each copy on the task and score how well it did (the height).
- You then move the original model a little in the combined direction of the tweaks that helped the most.
- Repeat this many times. Over time, you climb toward better performance.
Key pieces of their approach, explained simply:
- Tiny random tweaks: They add small random changes to the model’s parameters (the sliders). This is “exploring in parameter space.”
- Test, don’t backprop: They only run the model forward to get answers (inference). They don’t use backpropagation, which saves a lot of memory.
- Greedy decoding: They make each model copy answer deterministically (no randomness in the words it picks), so differences in performance truly come from the parameter tweaks, not lucky word choices.
- Parallel and memory-smart: They evaluate many copies at once and only keep track of the random seeds (think “recipes” for the same random tweaks), so it fits in GPU memory.
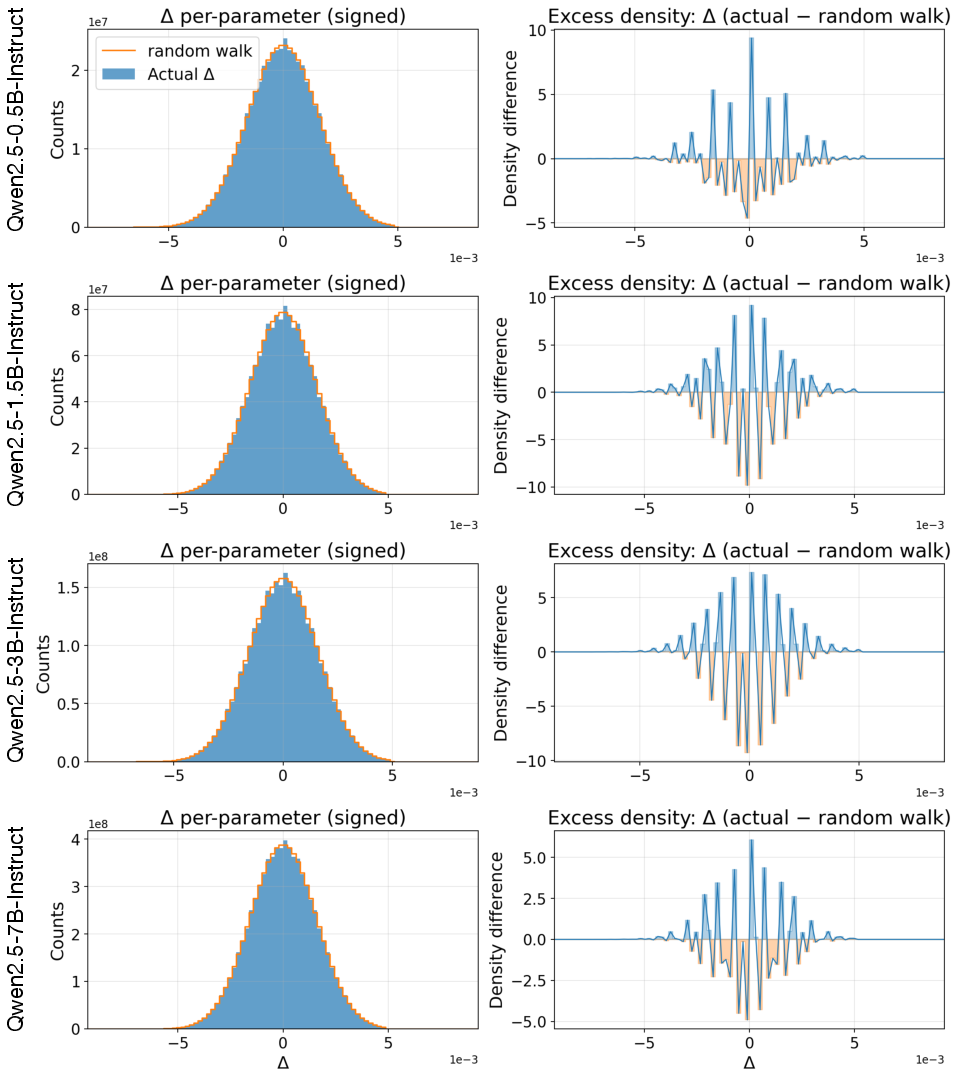
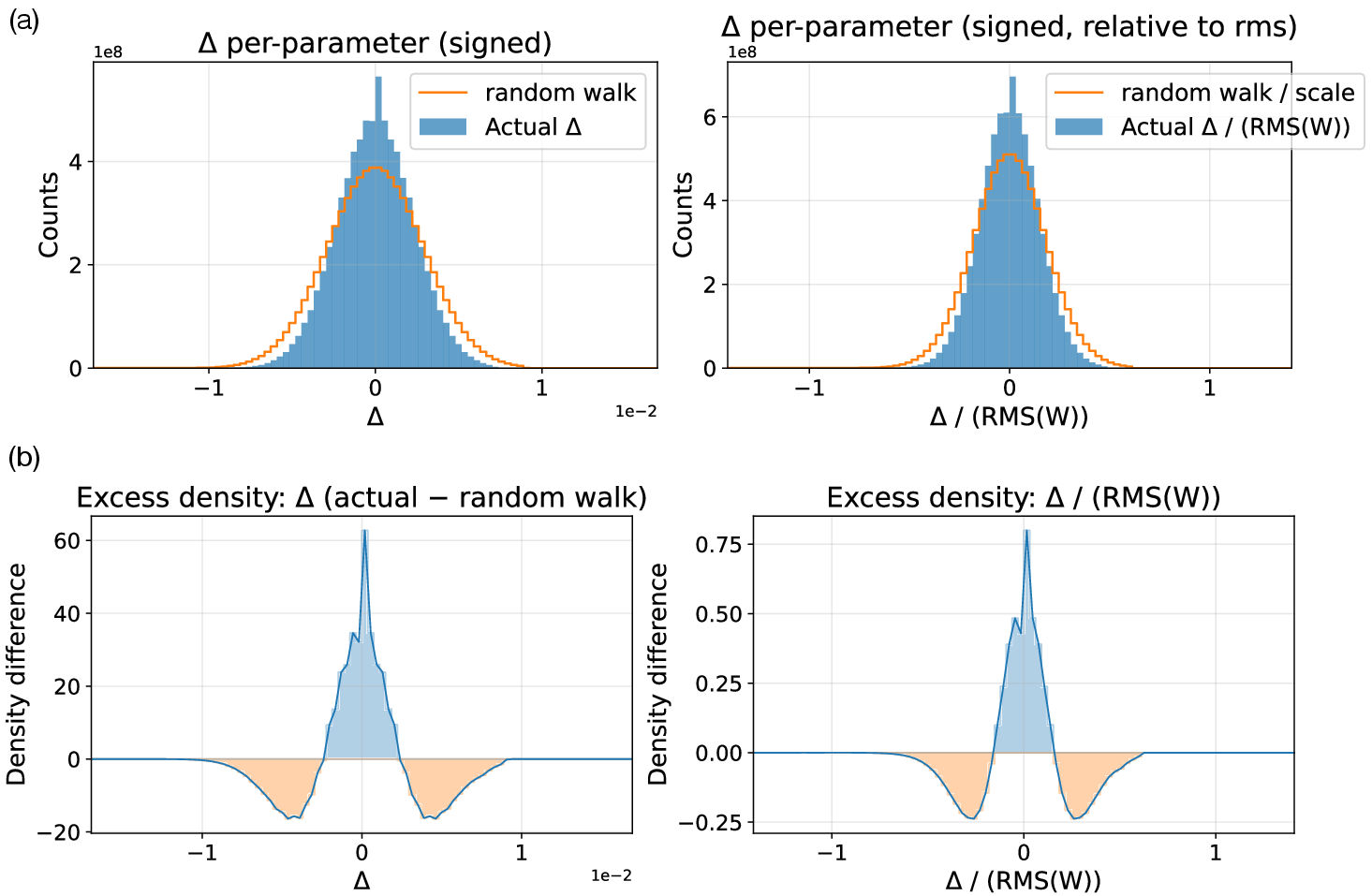
- Small population: Surprisingly, they only needed about 30 copies per round, even for billion-parameter models.
They compared ES with two popular RL methods (PPO and GRPO) on:
- A reasoning puzzle called “Countdown.” You’re given numbers and need to combine them with +, −, ×, ÷ to hit a target number.
- A “conciseness” task: Make answers as short as a verified short solution—without rewarding correctness directly—to see how methods behave and whether they “cheat.”
What did they find, and why is it important?
Here are the main results and why they matter:
- ES scales to huge models
- ES successfully fine-tuned models with billions of parameters. This was considered impractical before. It opens a new path beyond RL.
- Better results across many models
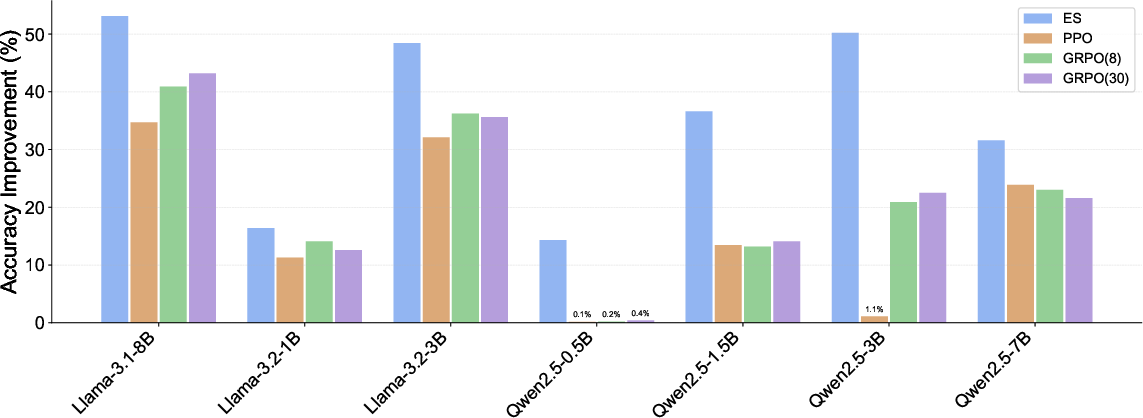
- ES beat PPO and GRPO on the Countdown reasoning task for multiple model families and sizes (from very small to large).
- This suggests ES is less picky about which base model you start with.
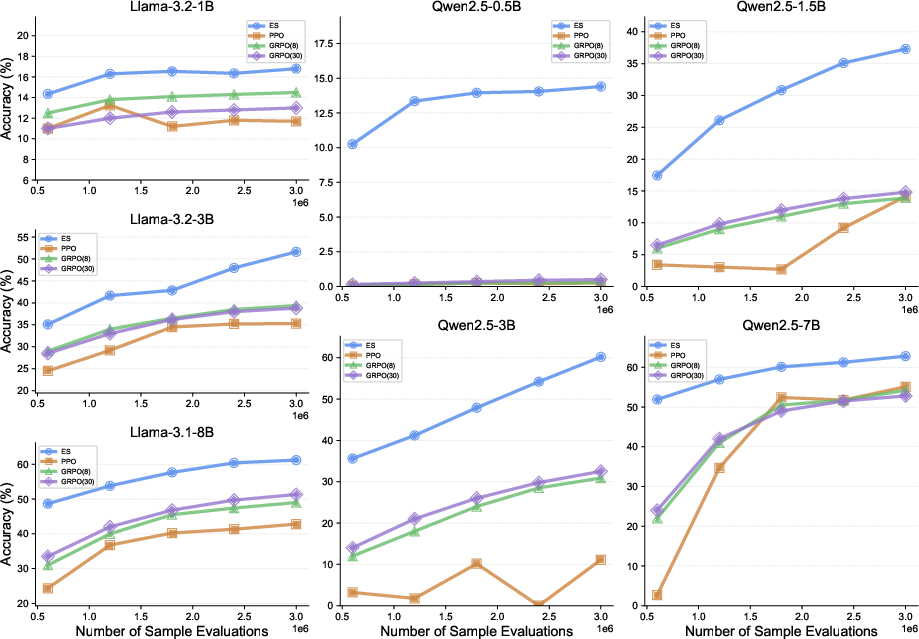
- More sample-efficient
- With the same amount of training data, ES reached higher accuracy. In many cases, ES needed less than 20% of the training samples to match RL performance. That means faster and cheaper fine-tuning.
- Works even on small models
- RL often needs a big, capable base model to improve. ES improved performance even on tiny models that RL couldn’t help. This means you can get more out of smaller, cheaper models.
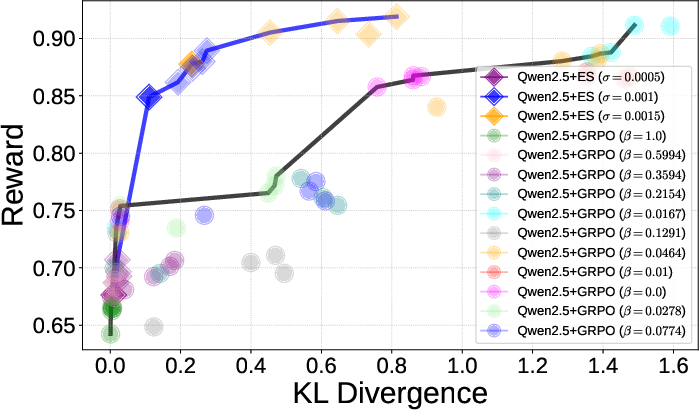
- Less reward hacking
- On the conciseness task, RL sometimes “cheated” by outputting nonsense symbols that were very short (so they scored high) but weren’t real answers. ES didn’t show this behavior, even without extra penalties.
- In plain terms: ES tends to find honest improvements, not shortcuts.
- More stable and predictable
- ES gave more consistent results across repeated runs. RL’s results varied more. If training runs are expensive, consistency saves time and money.
- Lower memory and simpler pipeline
- ES uses only inference (no backprop), so it uses less GPU memory and is easier to parallelize.
Why this is surprising: ES searches by nudging millions to billions of sliders directly—people assumed this would be too slow or random. But it turned out to be efficient and robust.
What could this mean going forward?
- A new path for fine-tuning LLMs: ES is a strong alternative to RL, especially for tasks where you only know if the final answer is right or wrong (long-horizon, outcome-only rewards), like many reasoning problems.
- Cheaper and broader deployment: Because ES can be sample-efficient, stable, and memory-light, it could reduce the cost and complexity of fine-tuning across many models and tasks.
- More honest learning: ES seems less likely to find loopholes in reward functions, making it safer for alignment-style objectives (like being concise, polite, or helpful).
- Scalability and parallelization: ES naturally runs many model copies in parallel, which fits well with modern large-scale compute.
- New research directions: The authors suggest ES might work well because adding noise to parameters “smooths” the bumpy reward landscape, making learning steadier. This could inspire better hybrid methods and deeper understanding of how large models learn.
In short: The paper shows that evolution strategies—once thought too simple for huge models—can fine-tune LLMs at scale, often better than current RL approaches. It’s a promising, practical direction for building smarter, safer, and more reliable AI systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, framed as concrete, actionable directions for future research.
- Task generalization: Validate ES beyond Countdown and conciseness on diverse, real-world LLM post-training tasks (reasoning, math word problems, coding with execution, tool use, instruction-following, summarization, safety/alignment, multilingual), using established benchmarks (e.g., GSM8K, HumanEval, BigBench, MMLU, MBPP, TruthfulQA, RealToxicityPrompts).
- Reward model robustness: Assess ES when rewards come from noisy/biased learned preference models (RLHF/RLAIF PRMs), including mis-specification and drift; compare to PPO/GRPO under identical reward noise regimes.
- Correctness vs conciseness: In the conciseness study, quantify answer correctness trade-offs (exact-match/EM, BLEU, ROUGE, F1) alongside reward and KL, not just length-based reward.
- Sample efficiency metrics: Report wall-clock time, FLOPs, throughput, and energy per achieved accuracy/reward (not only “training sample evaluations”), under identical hardware and batch sizes for ES vs PPO/GRPO.
- Population size sensitivity: Ablate and model the impact of population size N (e.g., 8–1,024) on sample efficiency, convergence speed, stability, and final performance for different model sizes and tasks.
- Noise scale and learning rate schedules: Systematically study σ and α schedules (adaptive, annealed, layer-wise, per-block) and their interaction with task difficulty, model size, and reward sparsity.
- Covariance adaptation: Evaluate ES variants with covariance adaptation (CMA-ES, NES with adaptive covariance, antithetic/mirrored sampling), rank-based updates, and weight decay to quantify gains over the simplified fixed-covariance approach.
- Layer-/parameter-wise scaling: Test per-layer/parameter noise scaling (e.g., normalized by parameter magnitude or Fisher information) to account for heterogeneous parameter scales in transformers.
- Decoding strategy parity: Measure how greedy decoding (used in ES) vs stochastic decoding (common in RL) affects fairness of comparison; evaluate ES with sampled decoding and RL with greedy-only evaluation to isolate action-space vs parameter-space exploration effects.
- Long-horizon variance analysis: Empirically quantify rollout variance and signal-to-noise ratio for ES vs RL as sequence length increases; include variance of gradient estimators and reward estimates across tasks.
- Reward smoothing hypothesis: Directly test the “ES smooths jagged reward landscapes” hypothesis by measuring landscape smoothness (e.g., local Lipschitz, Hessian spectra, curvature) before/after Gaussian convolution in parameter space.
- Intrinsic dimensionality: Investigate why population N≈30 suffices at billion-parameter scale—measure effective/intrinsic dimensionality of update directions and connect to known intrinsic dimension estimates for LLMs.
- Capability retention: Replace KL divergence proxy with comprehensive capability retention measurements (MMLU, ARC, GSM8K, coding, multilingual) pre-/post-fine-tuning to verify that ES preserves broad competencies.
- Stability across runs (beyond conciseness): Provide multi-run variance statistics for Countdown and other tasks, including confidence intervals and failure rates for ES vs RL across seeds and hyperparameters.
- Reward hacking breadth: Test ES vs RL on a wider variety of reward functions prone to specification gaming (helpfulness, harmlessness/refusal, obedience, style) and document failure modes and mitigations.
- Safety alignment: Evaluate ES’s impact on safety guardrails and harmful content with standard safety and toxicity benchmarks; determine if ES erodes safety more or less than RL under outcome-only optimization.
- Noisy/delayed/non-stationary rewards: Examine ES under delayed credit assignment, non-stationary reward distributions, and bandit-like online preference shifts typical in human-in-the-loop settings.
- Trust-region constraints for ES: Explore ES variants with explicit KL (or other divergence) constraints/budgets (e.g., proximal ES) to prevent capability drift, and compare trade-offs to PPO/GRPO.
- Adapter vs full-parameter tuning: Compare ES fine-tuning of LoRA/adapters vs full-parameter updates in terms of performance, memory, and stability, and analyze task-dependent trade-offs.
- Distributed systems scalability: Characterize communication overheads, seed-reconstruction bottlenecks, fault tolerance, and synchronization costs for multi-GPU/multi-node ES; provide scaling curves (throughput vs nodes).
- Memory savings quantification: Quantify GPU memory savings from inference-only ES vs RL (actor-critic/backprop) with concrete numbers per model size and batch; include activation checkpointing vs ES overheads.
- Numerical precision effects: Assess numerical drift and reproducibility when doing in-place add/sub noise in FP16/BF16; compare to FP32 and mixed precision; quantify impact on reward and stability.
- Fairness of RL baselines: Expand RL hyperparameter search (e.g., entropy bonuses, advantage normalization, learning rate schedules, clipping ranges) and report sensitivity to demonstrate that ES advantages persist under stronger RL tuning.
- Alternative baselines: Compare ES to other zeroth-order methods (MeZO, SPSA, finite differences) and modern gradient-based post-training methods (DPO, IPO, KTO, SPIN, Score-based) under outcome-only rewards.
- Multi-objective optimization: Investigate ES for explicit multi-objective fine-tuning (e.g., correctness, conciseness, safety) with Pareto-front tracking; compare to RL with tuned penalty coefficients.
- Multi-turn dialogue: Test ES on multi-turn conversational tasks where rewards depend on dialog trajectory and context persistence; measure robustness to stateful prompts.
- Model diversity: Extend evaluations to additional model families (Mistral, Mixtral, DeepSeek-R1, Gemini-compatible open models), sizes (≥30B), and modalities (vision-language, code-specialists).
- Overfitting and generalization: Analyze overfitting risks of full-parameter ES on small datasets; use held-out distributions and out-of-domain tests to measure generalization vs RL.
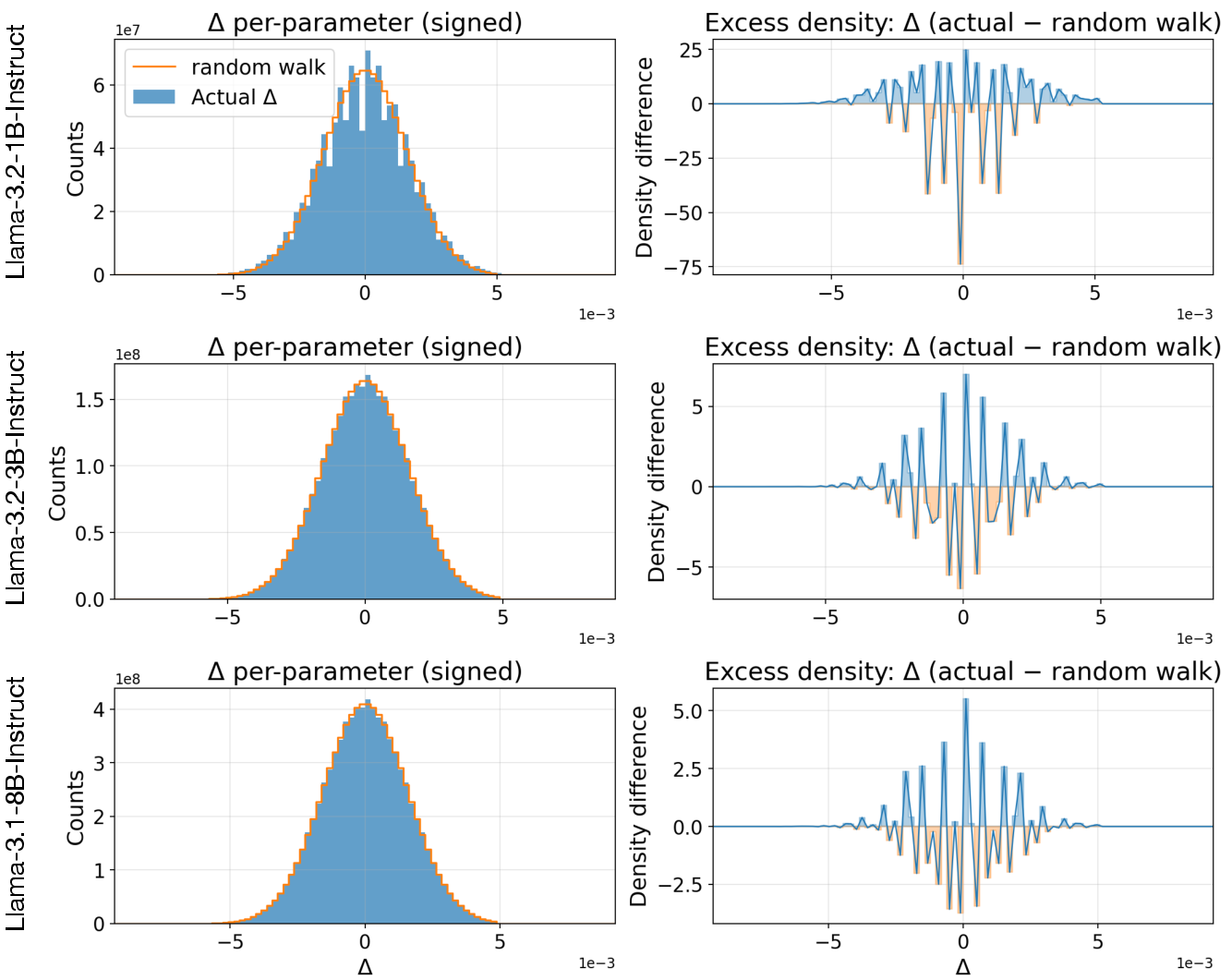
- Update interpretability: Inspect ES-induced parameter changes (layer/block attention/MLP weights, norms) and relate them to observed behavioral shifts; compare to RL-induced changes.
- Reward normalization choices: Evaluate alternatives to z-score normalization (rank transform, winsorization, robust scaling) and their effect on stability, convergence, and sample efficiency.
- Scheduling and stopping: Study iteration-wise learning rate/noise schedules, early stopping criteria, and population adaptivity for efficient convergence on sparse rewards.
- Human-in-the-loop integration: Design protocols for incorporating human feedback efficiently into ES (batching, active selection, re-evaluation), and compare label costs to RLHF pipelines.
- Evaluation under tool use/execution: Examine ES when rewards depend on external tools (code execution, web search), including latency, caching, and non-determinism; compare to RL’s on-policy requirements.
- Reproducibility across hardware: Document reproducibility across different accelerator stacks (A100/H100/TPU), libraries, RNGs, and distributed backends; provide deterministic modes and known pitfalls.
Glossary
- action-space exploration: Exploring by sampling actions during generation rather than changing model parameters. "Existing RL fine-tuning methods are overwhelmingly based on action-space exploration."
- actor-critic: An RL architecture pairing a policy (actor) with a value estimator (critic) for learning. "and it usually works with a value model in an actor-critic manner."
- CMA-ES: Covariance Matrix Adaptation Evolution Strategy; an ES variant that samples from a Gaussian with an adaptive full covariance. "Among the different variants of ES, CMA-ES \citep{hansen2001cmaes}, which utilizes a multivariate Gaussian distribution with full covariance matrix to sample the population"
- Countdown task: A symbolic reasoning benchmark where models construct arithmetic expressions to match a target. "Fine-tuning performance was measured in the Countdown task~\citep{tinyzero, goodfellow2016deep}"
- credit assignment: Determining which decisions (e.g., tokens) are responsible for outcomes to assign learning signal. "Proper credit assignment at token level for RL fine-tuning methods is difficult"
- decision transformers: Sequence models trained to produce actions conditioned on return-to-go, used for RL. "applied ES to optimize decision transformers in RL environments"
- Evolution Strategies (ES): Population-based zeroth-order optimization methods that update parameters via performance-weighted perturbations. "Evolution Strategies (ES), a class of population-based zeroth-order optimization algorithms, is a possible alternative."
- finite-difference (FD) gradient estimator: A gradient estimate obtained by evaluating function changes under small parameter perturbations. "a traditional finite-difference (FD) gradient estimator."
- Fireworks algorithm: An evolutionary optimization algorithm inspired by fireworks explosions, used for search. "using CMA-ES and the Fireworks algorithm."
- genetic algorithm (GA): An evolutionary algorithm using selection and mutation (and sometimes crossover) across a population. "another traditional EA, namely genetic algorithm (GA) with mutations only"
- Gaussian convolution: Smoothing a function by convolving it with a Gaussian, often via adding Gaussian noise to parameters. "ES injects noise directly into the parameter space via explicit Gaussian convolution"
- greedy decoding: Deterministic generation by selecting the highest-probability token at each step. "The perturbed models use greedy decoding to generate the responses for reward evaluations."
- GRPO (Group Relative Policy Optimization): An RL fine-tuning method that replaces a value model with group-based advantage estimates. "Group Relative Policy Optimization \citep[GRPO;] []{shao2024grpo}"
- group advantage: An advantage estimate computed across a group of sampled responses instead of a learned value model. "replacing the value model with group advantage"
- in-place perturbation: Modifying parameters directly in memory without creating copies, to save memory. "the model parameters are perturbed in-place layer by layer"
- intrinsic dimensionality: The effective low-dimensional structure within a high-dimensional model parameter space. "observed low intrinsic dimensionality of LLMs"
- KL divergence: A measure of divergence between probability distributions, used to quantify deviation from a base model. "mean KL divergence from the base model"
- KL divergence penalty (β): A regularization term that penalizes divergence from the base model during RL fine-tuning. "augmented the conciseness reward with a KL divergence penalty (weighted by a parameter β)"
- long-horizon rewards: Reward signals that depend on long sequences of actions/tokens, causing high-variance credit assignment. "when handling long-horizon rewards, which is a common case for LLM fine-tuning with outcome-only rewards."
- low-rank adapter: A small, low-dimensional module added to a model to enable parameter-efficient fine-tuning. "low-rank adapter parameters (with dimensionality up to 1600) using CMA-ES and the Fireworks algorithm."
- MeZO: A memory-efficient zeroth-order optimizer for LLM fine-tuning based on SPSA ideas. "proposed a zeroth-order optimizer MeZO that directly worked in parameter space for fine-tuning LLMs."
- mirrored sampling: ES technique that samples paired opposite perturbations to reduce estimator variance. "mirrored sampling \citep{sehnke2010parameter}"
- Monte-Carlo sampling: Estimating expectations by random sampling, e.g., sampling tokens during rollouts. "noise is introduced from Monte-Carlo sampling of each token during a rollout"
- multivariate Gaussian distribution: A Gaussian over vectors with a covariance matrix capturing parameter correlations. "utilizes a multivariate Gaussian distribution with full covariance matrix to sample the population"
- natural evolution strategies (NES): ES variants that use natural gradients in distribution parameter space for updates. "natural evolution strategies (NES)"
- natural gradient: A gradient computed with respect to the information geometry of the parameter distribution. "which uses natural gradient to guide the search"
- OpenAI ES: A simplified, scalable ES variant with fixed-covariance perturbations. "similar to OpenAI ES \citep{salimans2017es}"
- outcome-only rewards: Rewards provided only at the end of a trajectory/response without intermediate feedback. "with outcome-only rewards."
- parameter space exploration: Exploring by perturbing model parameters rather than sampling actions. "Parameter space exploration has received much less attention"
- Pareto front: The set of nondominated trade-off solutions across competing objectives (e.g., reward vs. KL). "The ES Pareto front is represented by a blue line"
- PPO (Proximal Policy Optimization): An RL algorithm using a clipped surrogate objective to stabilize policy updates. "Proximal Policy Optimization \citep[PPO;] []{schulman2017ppo}"
- population-based (optimization): Methods that maintain and evaluate multiple candidate solutions concurrently. "a class of population-based zeroth-order optimization algorithms"
- population size: The number of sampled perturbations/solutions per ES iteration. "a population size of only 30"
- rank transformation (of rewards): Replacing raw rewards with ranks to reduce sensitivity to scale/outliers in ES. "rank transformation of rewards \citep{wierstra14a}"
- reward hacking: Exploiting imperfections in the reward function to achieve high scores via undesired behavior. "more robust against reward hacking."
- reward landscape: The mapping from parameters to reward, whose smoothness/jaggedness affects optimization. "smooths out the jagged reward landscape."
- rollouts: Complete sampled trajectories/responses used to estimate performance. "averaged over many rollouts"
- semantic density: A confidence/uncertainty measure derived from the semantic space of model outputs. "semantic entropy and semantic density \citep{qiu:neurips24,farquhar:nature24}"
- semantic entropy: An uncertainty measure capturing dispersion of meaning across plausible outputs. "semantic entropy and semantic density \citep{qiu:neurips24,farquhar:nature24}"
- solution distribution: The distribution over parameter perturbations/solutions optimized by ES rather than a single solution. "optimizes a solution distribution"
- SPSA (Simultaneous Perturbation Stochastic Approximation): A zeroth-order optimization method estimating gradients via simultaneous random perturbations. "Based on the classical SPSA optimization method \citep{spall1992spsa}"
- SFT (Supervised Fine-Tuning): Fine-tuning using labeled examples rather than reinforcement signals. "supervised fine-tuning (SFT)"
- value model: A model estimating expected returns to guide policy updates in actor-critic RL. "and it usually works with a value model in an actor-critic manner."
- virtual batch normalization: A normalization technique stabilizing training by referencing a fixed batch. "virtual batch normalization \citep{salimans2016gan}"
- weight decay: Regularization that penalizes large parameter magnitudes to prevent overfitting. "weight decay"
- zeroth-order optimization: Optimization using only function evaluations (no gradients), often via perturbation-based search. "zeroth-order optimization algorithms"
- z-score normalization: Standardizing values by subtracting the mean and dividing by the standard deviation. "The rewards of the perturbed models are normalized using -score within each iteration"
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s findings on scalable Evolution Strategies (ES) for full-parameter LLM fine-tuning. Each item includes sector alignment, possible tools/workflows, and feasibility notes.
- Industry: cost-effective, stable LLM post-training without backpropagation
- Application: Replace PPO/GRPO-style RLHF with ES for outcome-only post-training when token-level credit assignment is hard (e.g., long-horizon reasoning, chain-of-thought, program synthesis).
- Sectors: software, education, customer support, operations.
- Tools/workflows:
- ES-finetune service that plugs into existing inference clusters (Triton/TGI) to run population evaluations in parallel.
- “Verifier-as-a-reward” pipeline (unit tests, structured output validators, rule engines, judge models) to compute response-level rewards.
- ES orchestrator with seed management and layer-level in-place perturbation to minimize memory and bandwidth.
- Assumptions/dependencies: Requires reliable response-level automatic reward signals; inference compute throughput for evaluating population members; deterministic RNG/greedy decoding to limit variance; careful logging for auditing.
- Software engineering: test-driven LLM fine-tuning via unit tests
- Application: Fine-tune code LLMs to pass unit/integration tests using ES, improving pass rates with fewer samples than RL and with reduced reward hacking.
- Sectors: software, DevOps, enterprise IT.
- Tools/workflows:
- CI/CD-integrated “TDD fine-tuner” that runs ES against a repository’s test suite.
- Canary runs and A/B testing as external rewards for production behavior.
- Assumptions/dependencies: Good test coverage; sandboxed execution; stable test oracles; license compliance for base models.
- Reasoning and planning systems with sparse, long-horizon rewards
- Application: Improve arithmetic reasoning (e.g., Countdown-like tasks), program synthesis (checkable by execution), SQL/regex generation (checkable by execution), and tool-use planning (checkable by success signals).
- Sectors: software, data engineering, analytics, robotics simulation.
- Tools/workflows:
- Batch verifiers for execution success/failure.
- ES population evaluation farm across GPUs.
- Assumptions/dependencies: Reliable pass/fail checks; deterministic evaluation preferred for stable reward estimates; task-specific sandboxes.
- Style and policy tuning with less reward hacking
- Application: Conciseness/verbosity control, format adherence, brand tone/style tuning using simple distance-based or classifier-based rewards, without KL penalties and with lower hacking risk than RL in the paper’s tests.
- Sectors: customer support, marketing, content operations.
- Tools/workflows:
- Lightweight string-length/edit-distance rewards for conciseness.
- Content policy classifiers and schema validators as binary/graded rewards.
- Assumptions/dependencies: Reward functions must capture desired behavior and detect obvious exploits (e.g., nonsensical tokens); human spot checks recommended.
- Robust fine-tuning for smaller/edge models
- Application: Improve 0.5B–3B parameter models for targeted tasks where RL often fails to bootstrap; enable on-prem/edge customization with limited memory.
- Sectors: embedded systems, mobile, retail kiosks, industrial HMI.
- Tools/workflows:
- “ES-Lite” workflow for single-GPU fine-tuning using small populations (e.g., N≈30) and in-place perturbation per layer.
- Assumptions/dependencies: Tasks must be assessable with response-level rewards; compute throughput must be sufficient for population inferences.
- Compliance and risk management with reproducible post-training
- Application: Prefer ES when stability across runs and low variance updates are required (e.g., regulated sectors), aided by deterministic evaluation and lower run-to-run variability.
- Sectors: finance, healthcare, government, legal.
- Tools/workflows:
- “Stable-FT” MLOps profile: fixed seeds, z-score reward normalization, run-to-run reproducibility reports.
- Audit trails: store seeds, reward traces, and checkpoints for each iteration.
- Assumptions/dependencies: Governance processes must validate reward definitions; human review remains mandatory for safety-critical decisions.
- Academic research platforms and teaching
- Application: Use ES to study LLM reward landscapes, compare parameter- vs. action-space exploration, and run reproducible fine-tuning on modest hardware (no backprop).
- Sectors: academia, research labs.
- Tools/workflows:
- Open-source ES reference implementations with seed-based noise retrieval.
- Benchmarks for outcome-only objectives (counting, arithmetic, code tests).
- Assumptions/dependencies: Access to evaluation harnesses; compute for parallel inference; ethical dataset use.
Long-Term Applications
The following use cases require further scaling, research, or engineering maturity (e.g., larger models, multi-objective safety, new verifiers).
- Enterprise-scale, distributed ES post-training for very large models
- Application: Fine-tuning 30B–100B+ models via massive parallel ES across multi-node GPU clusters or data centers.
- Sectors: cloud platforms, foundation model providers, large enterprises.
- Tools/workflows:
- Elastic population schedulers; seed servers; high-throughput parameter update reducers; efficient parameter sharding for layer-wise perturbation/recovery.
- Assumptions/dependencies: High-bandwidth interconnects, robust fault tolerance, cost-aware orchestration; stronger theoretical guidance on population sizing vs. intrinsic dimensionality.
- Unsupervised/self-supervised alignment via internal signals
- Application: Optimize for confidence/consistency signals (e.g., semantic entropy/density) without human labels; continual self-improvement for reasoning reliability.
- Sectors: foundation models, safety research.
- Tools/workflows:
- Internal-signal verifiers as reward sources; multi-signal aggregation (e.g., entropy minima + self-consistency).
- Assumptions/dependencies: Validity of internal signals as alignment proxies; safeguards against degenerate solutions; rigorous evaluation on out-of-distribution prompts.
- Multi-objective safety alignment with reduced reward hacking
- Application: Jointly optimize safety constraints, helpfulness, and correctness using ES’s solution-distribution optimization to reduce exploitability.
- Sectors: safety, trust & risk, policy.
- Tools/workflows:
- Vectorized rewards combining policy classifiers, adversarial probes, correctness verifiers; robust aggregation (e.g., worst-case penalties).
- Assumptions/dependencies: High-quality safety verifiers and red-team pipelines; governance to set objective weights; monitoring for distribution shift.
- Hybrid ES + gradient/RL methods
- Application: Use ES for exploration (global, parameter-space smoothing) and gradient-based/DPO/RLAIF for exploitation (local refinement).
- Sectors: foundation model training, applied ML.
- Tools/workflows:
- Alternating or staged optimization (ES warm-start → SFT/DPO refine); or CMA-ES/mirrored sampling/rank transforms integrated into training loops.
- Assumptions/dependencies: Stable handoff between methods; careful KL constraints during gradient phases; engineering to manage optimizer state and reproducibility.
- Robotics and embodied agents with long-horizon objectives
- Application: Fine-tune language-conditioned planners/policies where success is measured only at episode end; use ES to mitigate sparse rewards and credit assignment.
- Sectors: robotics, logistics, industrial automation.
- Tools/workflows:
- Sim-in-the-loop verifiers; episodic success metrics; curriculum via population shaping.
- Assumptions/dependencies: Fast, realistic simulators; reliable sim-to-real transfer; safety gating for real hardware deployment.
- On-device/private personalization with minimal memory footprint
- Application: Personalize small LLMs locally using outcome-only signals (e.g., user satisfaction, task success), preserving privacy and reducing cloud dependence.
- Sectors: consumer devices, enterprise endpoints, healthcare edge.
- Tools/workflows:
- Lightweight ES runtimes on consumer GPUs/NPUs; periodic synchronization with central models using secure aggregation.
- Assumptions/dependencies: Efficient inference kernels; careful battery/thermal management; robust local reward definitions that do not leak sensitive data.
- Continuous, production-in-the-loop fine-tuning
- Application: Use live KPIs (task success, escalation rate, policy compliance) as rewards for ES to continuously harden models.
- Sectors: customer ops, fintech, e-commerce.
- Tools/workflows:
- Offline shadow evaluation, counterfactual inference for reward construction, guardrails for drift; staged rollout with kill-switches.
- Assumptions/dependencies: High-quality offline estimators to avoid bias; strong observability; compliance approval for any self-updating system.
- Model merging and architecture evolution in parameter space
- Application: Use ES to evolve weight-space merges of specialized models or adapters; explore low-rank/adapter topologies under outcome reward.
- Sectors: foundation models, AutoML.
- Tools/workflows:
- Evolutionary search over merge coefficients/adapters; constraint-aware verifiers (latency, memory).
- Assumptions/dependencies: Efficient low-level kernels for adapter toggling; verifiers that reflect both quality and resource constraints.
Cross-cutting considerations (assumptions/dependencies)
- Reward design is pivotal: outcome-only rewards must be robust, tamper-resistant, and reflect true objectives; weak or biased verifiers can misdirect optimization.
- Compute economics: although ES avoids backprop and is memory-light, it still requires throughput for population inference; real-time or large-scale deployments need orchestration and parallelism.
- Determinism vs. diversity: greedy decoding during evaluation improves stability but may underrepresent stochastic behavior; sampling-based evaluation may be needed for some tasks.
- Safety and compliance: especially in healthcare/finance/public sector, human oversight, auditability (seed logs, reward traces), and documented model changes are required.
- Base model limits: ES improves small models in the reported tasks but cannot create capabilities ex nihilo; domain suitability and ceiling effects should be assessed.
- Licensing and data governance: ensure base model/model card constraints and data policies are respected when deploying ES-based fine-tuning.
Collections
Sign up for free to add this paper to one or more collections.

