- The paper presents a novel RL framework that reformulates LLM sequence generation as a tree-structured search, reducing redundant computation.
- It leverages segment-level sampling and hierarchical advantage estimation to boost trajectory sampling speed by up to 40% and improve overall performance.
- TreePO’s heuristic branching and dynamic pruning mechanisms balance exploration with computational efficiency, enabling scalable training for long-horizon reasoning.
TreePO: Heuristic Tree-based Policy Optimization for Efficient and Effective LLM Reasoning
Introduction
TreePO presents a novel reinforcement learning (RL) framework for LLMs, addressing the dual challenges of computational inefficiency and limited exploration in complex reasoning tasks. The method reconceptualizes sequence generation as a tree-structured search, leveraging shared prefixes and dynamic branching to amortize computation and enhance exploration diversity. TreePO integrates segment-level sampling, early stopping, and a hierarchical advantage estimator, enabling more precise credit assignment and efficient training from base models without prior supervised fine-tuning.
Tree-based Sampling: Algorithmic Design and Empirical Motivation
Standard RL rollouts for LLMs generate multiple independent trajectories per query, leading to redundant computation and inefficient use of KV caches. Empirical analysis reveals that stochastic rollouts from the same prompt share extensive reasoning prefixes, motivating a tree-structured approach to sequence generation.

Figure 1: Multiple sampled trajectories from the same prompt, with shared reasoning segments highlighted; key problem-solving steps are consistently reproduced despite stochasticity.
TreePO formalizes the rollout process as a tree, where each node represents a segment of reasoning, and branches correspond to divergent continuations. The algorithm maintains a prompt queue, dynamically forks branches based on heuristic policies, and prunes low-value paths via early stopping. Branching budgets and fallback mechanisms are designed to balance exploration and computational efficiency, with segment-level control enabling fine-grained management of the search space.
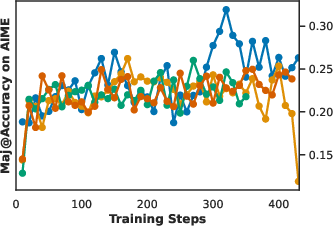
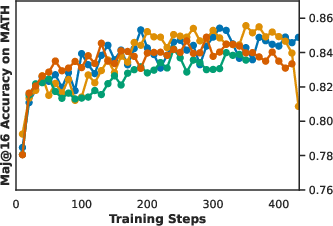
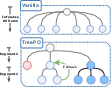
Figure 2: Validation performance curves and demonstration of TreePO sampling; tree-based sampling stabilizes training and amortizes computation across shared prefixes.
Hierarchical Advantage Estimation
TreePO introduces a segment-level, tree-based advantage estimator, extending beyond MCTS-like parent-child credit assignment. Each trajectory is decomposed into segments, and subgroups are defined by shared predecessor nodes at each tree depth. The advantage for a trajectory is computed as the mean-pooled, variance-normalized reward difference within each subgroup, aggregating hierarchical credit signals.
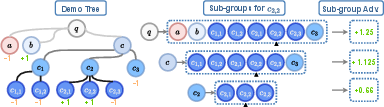
Figure 3: TreePO advantage estimation; sub-group advantages are calculated for each node, enabling robust credit assignment based on collective descendant outcomes.
Empirical studies demonstrate that simple averaging across subgroups yields higher accuracy and more stable entropy than subgroup-size weighting, which overemphasizes large/easy subgroups. Dynamic rejection sampling at the subgroup level degrades performance, indicating that extreme subgroups provide valuable calibration. Token-aligned segments are critical for stable optimization; misaligned fallback inflates response length and reduces accuracy.
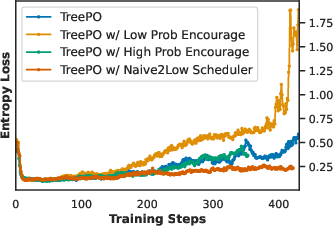
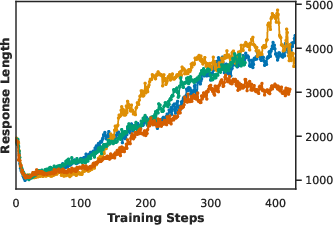
Figure 4: Study on the terms in TreePO advantage; subgroup-size weighted aggregation is compared to simple averaging, revealing superior stability and accuracy for the latter.
Sampling Efficiency and Scaling Analysis
TreePO achieves substantial efficiency gains by amortizing computation over shared prefixes and enabling parallelized segment-level decoding. Offline efficiency analyses across Qwen2.5 variants show average improvements of +40% in trajectories per second (TrajPS) and +30% in tokens per second (TokenPS) compared to conventional sampling.
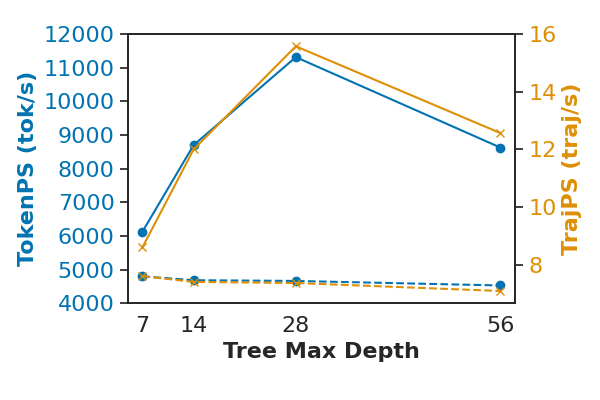
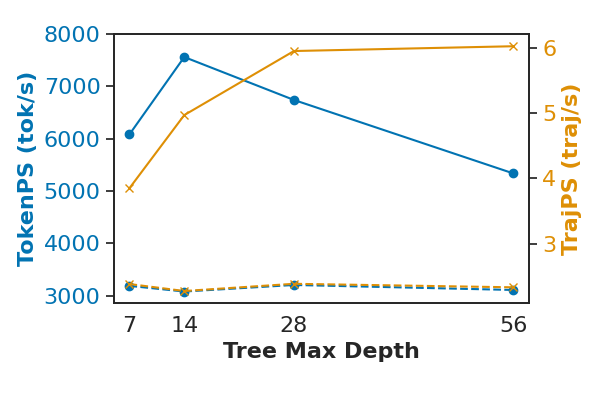
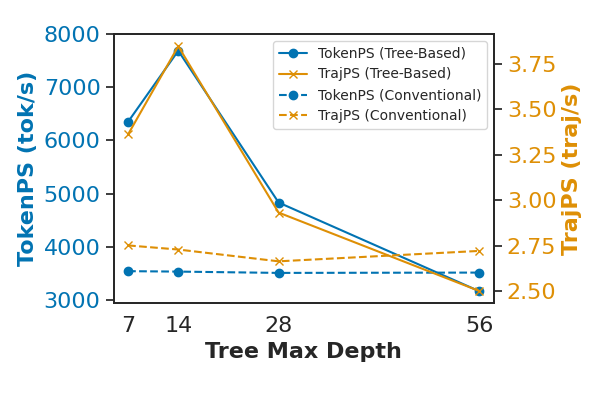
Figure 5: Qwen2.5-7B-Instruct throughput comparison; tree-based sampling yields higher TrajPS and TokenPS across tree depths.
Efficiency peaks at intermediate depth–segment configurations, with optimal settings being model-specific. For instruction-tuned models, mid-depth trees balance batched prefilling and parallel decoding, while math-focused models benefit from longer segments and shallower trees. Rollout scaling is workload-dependent; shared-prefix reuse boosts throughput for structured tasks, but excessive divergence degrades batching efficiency.
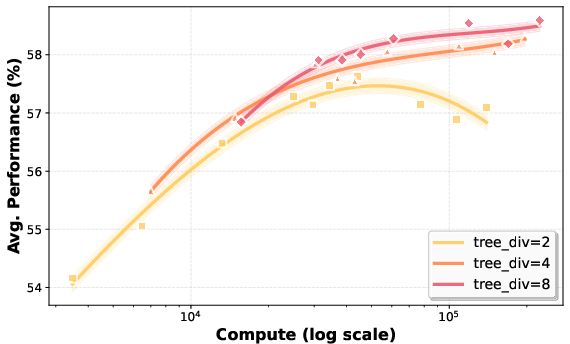
Figure 6: Test-time compute scaling of TreePO sampling; larger divergence factors achieve higher peak performance at increased compute cost, enabling flexible compute-optimal inference.
Heuristic Branching and Exploration Control
TreePO enables heuristic control over branching assignment at each segment, leveraging log probabilities to allocate branching budgets. Experiments reveal that monotonous patterns—such as always favoring low-probability paths—harm performance, increasing entropy and response length without improving accuracy. Exploration must be meaningful; indiscriminate allocation to low-probability segments leads to irrelevant reasoning paths.
Figure 7: Probability-based heuristic tree branching budget assignment; static controls underperform, while balanced strategies maintain effective exploration-exploitation trade-offs.
Main Results and Trade-offs
TreePO sampling and advantage estimation consistently improve training stability and computational efficiency. Across benchmarks, TreePO boosts overall accuracy (e.g., from 46.63% to 54.61% over GRPO) and reduces GPU hours by 12–43%. While tree-based sampling may converge more slowly or yield slightly lower peak accuracy in some configurations, the trade-off is favorable for large-scale training.
Implications and Future Directions
TreePO's segment-based tree search and hierarchical advantage estimation provide a scalable framework for RL-based LLM post-training. The method is particularly suited for long-horizon reasoning, multi-turn dialogue, and multi-agent systems, where efficient exploration and precise credit assignment are critical. The flexible compute scaling and heuristic control mechanisms enable adaptive inference strategies tailored to resource constraints.
Theoretical implications include the potential for more robust credit assignment in sparse-reward settings and the integration of tree-based exploration with other RL paradigms. Practically, TreePO offers a path toward efficient, scalable RL training for LLMs, reducing the sample and compute requirements without sacrificing performance.
Conclusion
TreePO advances policy optimization for LLMs by reformulating rollouts as tree-structured searches and introducing hierarchical advantage estimation. The framework achieves significant efficiency gains, stable training, and strong performance across reasoning benchmarks. Its structural modeling and adaptive control mechanisms open new avenues for scaling RL to complex, long-horizon tasks, with implications for both theoretical research and practical deployment in AI systems.

