Endless Terminals: Scaling RL Environments for Terminal Agents
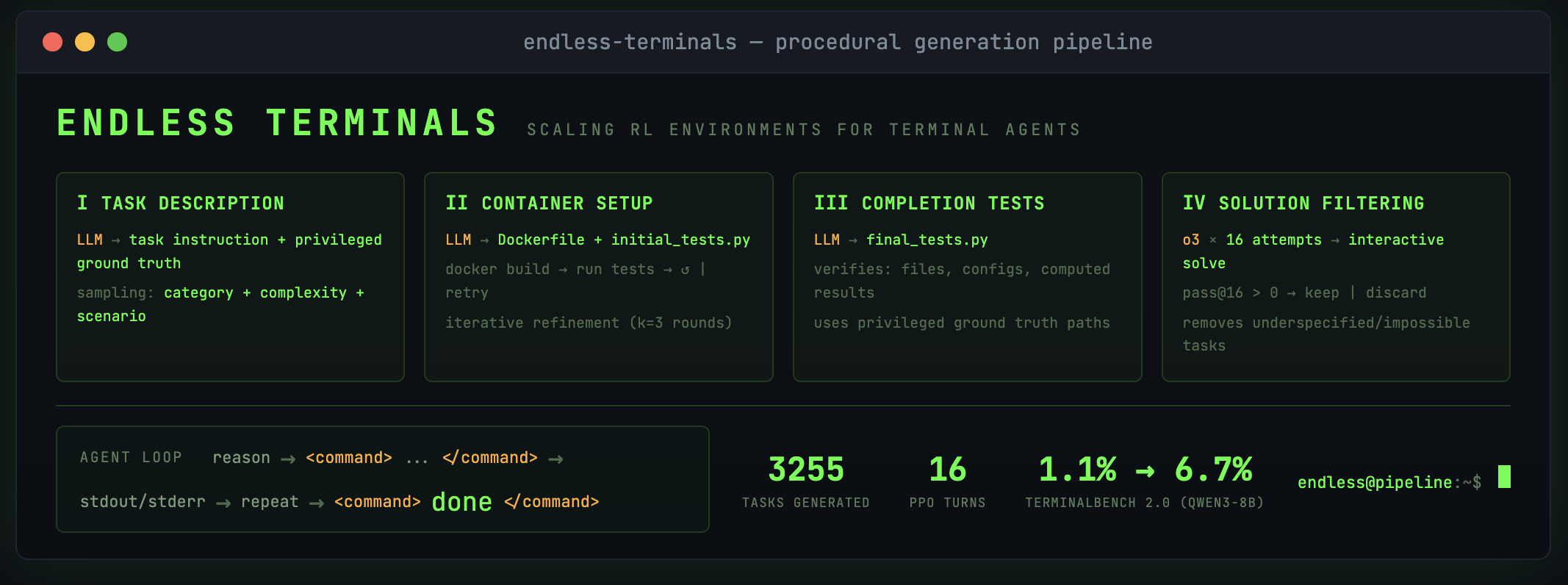
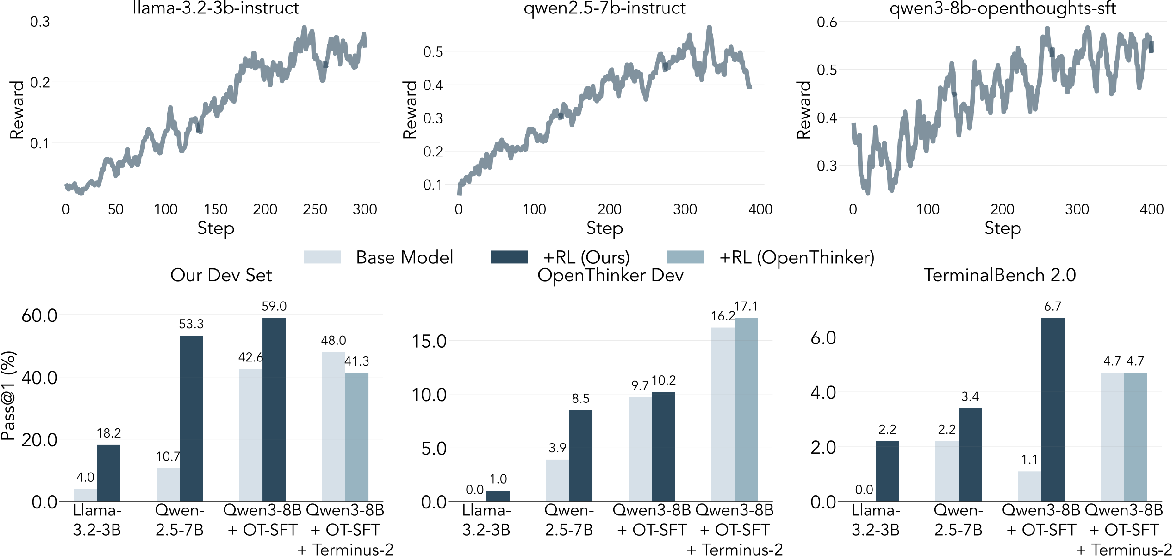
Abstract: Environments are the bottleneck for self-improving agents. Current terminal benchmarks were built for evaluation, not training; reinforcement learning requires a scalable pipeline, not just a dataset. We introduce Endless Terminals, a fully autonomous pipeline that procedurally generates terminal-use tasks without human annotation. The pipeline has four stages: generating diverse task descriptions, building and validating containerized environments, producing completion tests, and filtering for solvability. From this pipeline we obtain 3255 tasks spanning file operations, log management, data processing, scripting, and database operations. We train agents using vanilla PPO with binary episode level rewards and a minimal interaction loop: no retrieval, multi-agent coordination, or specialized tools. Despite this simplicity, models trained on Endless Terminals show substantial gains: on our held-out dev set, Llama-3.2-3B improves from 4.0% to 18.2%, Qwen2.5-7B from 10.7% to 53.3%, and Qwen3-8B-openthinker-sft from 42.6% to 59.0%. These improvements transfer to human-curated benchmarks: models trained on Endless Terminals show substantial gains on held out human curated benchmarks: on TerminalBench 2.0, Llama-3.2-3B improves from 0.0% to 2.2%, Qwen2.5-7B from 2.2% to 3.4%, and Qwen3-8B-openthinker-sft from 1.1% to 6.7%, in each case outperforming alternative approaches including models with more complex agentic scaffolds. These results demonstrate that simple RL succeeds when environments scale.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI models to use a computer terminal (the text-based screen where you type commands) more effectively. The authors build “Endless Terminals,” a system that automatically creates thousands of practice tasks for terminal use—like organizing files, analyzing logs, or running scripts—so AI models can learn by doing. Their main message is simple: when you give reinforcement learning (RL) lots of good, automatically checkable tasks, even a simple training setup can make AI agents noticeably better.
Objectives
The paper asks these easy-to-grasp questions:
- Can we automatically generate a large, varied set of terminal tasks without humans writing or labeling them?
- If we train AI with a simple RL method on these tasks, will the AI actually get better at using the terminal?
- Do improvements learned on these auto-generated tasks also help on tough, human-made benchmarks (tests), not just on the training set?
Methods and Approach
Think of this like building an endless series of “practice levels” for a video game, but the game is the computer terminal. The system creates tasks, sets up clean virtual computers for each task, and writes tests to check if the AI’s solution is correct. It has four stages:
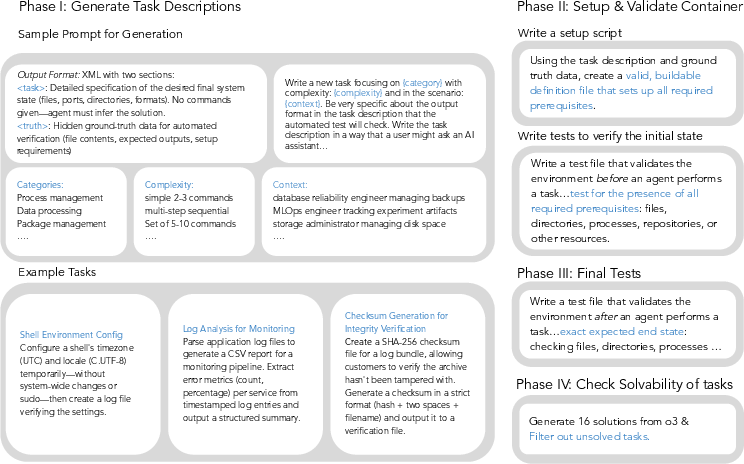
- Stage 1: Task description generation
- A LLM writes a task (e.g., “Find and summarize errors in these log files”) plus a hidden “answer key” with exact details the tests will use later.
- Stage 2: Environment setup and validation
- The system builds a fresh container (a “boxed” virtual computer) using tools like Docker or Apptainer. It then runs quick checks to ensure the files and settings needed for the task exist.
- Stage 3: Completion test generation
- The system writes final tests that only pass if the task is done correctly (e.g., the right file was created with the right contents). These tests don’t pass in the starting state.
- Stage 4: Solvability filtering
- A strong model tries each task up to 16 times. If at least one attempt succeeds, the task is kept; otherwise, it’s discarded. This ensures tasks aren’t broken or impossible.
Training the agent:
- The AI agent follows a simple loop: it thinks, runs one command, reads the terminal’s output, and repeats. It can declare “done” when it believes it finished.
- They use a basic RL method called PPO (Proximal Policy Optimization), which is like tweaking the AI step-by-step to choose actions that lead to more “wins.”
- Rewards are simple: the agent gets 1 point if the final test passes (task solved), and 0 if not. No fancy scoring mid-task.
- No special extras: no retrieval tools, no extra helper agents, no special apps—just the terminal.
Main Findings and Why They Matter
What they built:
- Endless Terminals produced 3,255 verified tasks across many categories: file operations, log management, data/text processing, scripting, compression, and database tasks.
How much did models improve?
- On their held-out development set:
- Llama-3.2-3B improved from 4.0% to 18.2%
- Qwen2.5-7B improved from 10.7% to 53.3%
- Qwen3-8B-openthinker-sft improved from 42.6% to 59.0%
- On a tough human-made benchmark (TerminalBench 2.0), improvements also showed up:
- Llama-3.2-3B: 0.0% → 2.2%
- Qwen2.5-7B: 2.2% → 3.4%
- Qwen3-8B-openthinker-sft: 1.1% → 6.7%
- These trained models beat other versions that used more complicated agent setups, showing that simple RL can work if you scale the training environments.
Why this is important:
- It proves that the biggest blocker isn’t the RL algorithm—it’s the lack of enough good, varied, and checkable tasks. When you fix that by generating “endless” tasks, even simple training makes agents more capable.
- Improvements transfer to human-created tests, meaning the learning is real and not just memorizing the training tasks.
Implications and Potential Impact
Big picture:
- Scaling up training environments for terminal use could make AI assistants better at practical computer work: organizing files, reading and fixing logs, scripting, and basic data processing.
- You don’t always need complex scaffolding around the AI—give it many clean, verifiable tasks and let RL do its work.
What this suggests for the future:
- More realistic, “messy” tasks: Real users ask vague questions. The paper’s tasks are precise on purpose (to allow automatic checking). Future systems might blend clarity with real-world fuzziness while still being testable.
- Stronger validators and self-play: Today’s solvability filter relies on a strong model. As models improve, the pipeline can produce harder tasks. Self-play (where models create and solve progressively tougher tasks) could push abilities further.
- Richer training signals: Instead of only rewarding complete success, partial rewards (for passing some checks) might help agents learn faster.
- Additional tools or knowledge: Adding regular tools (like code editors), search, or domain hints could help tackle harder categories (e.g., cryptography or bioinformatics).
- Complementary strategies: The paper shows that starting from a better base model (via supervised finetuning) helps RL even more. Combining high-quality data with scaled RL environments looks promising.
In short, Endless Terminals shows that if you build a large, automatic “practice gym” for terminal tasks, simple RL can significantly upgrade an AI agent’s ability to use the command line—and those gains show up on real benchmarks too.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Realism of tasks: generated tasks are cleanly specified and deterministic; they do not model ambiguous, under-specified, or evolving user goals that require clarifying questions and negotiation while preserving verifiability. How can we design verifiable “fuzzy” tasks that capture real user intent and context?
- Domain coverage skew: the dataset is dominated by file/log/text operations, with weak or zero performance in mathematics, ML, model-training, bioinformatics, and cryptanalysis. How can the pipeline be extended to include GPU/ML dependencies, package managers, large datasets, numerical libraries, and domain-specific tools without sacrificing reproducibility?
- Networking and authentication: tasks appear offline and avoid authenticated services, credentials, or rate-limited APIs. How can we include networked terminal tasks (SSH, HTTP APIs, cloud CLIs) that remain deterministic and verifiable?
- OS and shell diversity: only Linux containers (Docker/Apptainer) are supported; Windows PowerShell, macOS, zsh/fish, and heterogeneous distros are not covered. What changes are needed to support cross-OS tasks and to test portability?
- Interactive tooling: interactive TUI tools (e.g., vim, less, ncurses apps) are disallowed, reducing realism. Can we design non-interactive proxies, scripted editors, or PTY harnesses that enable verifiable interaction with TUI programs?
- Solvability filter dependence: filtering by pass@16 using o3 sets a capability ceiling, discards hard/novel tasks, and biases the distribution toward teacher strengths. How can self-play curricula, multi-solver ensembles, or adaptive difficulty produce tasks beyond current frontier model capability?
- Verifier robustness: completion tests are not audited for false positives/negatives, flakiness, or insufficient coverage. Establish metrics and tooling to measure test reliability, idempotency, and coverage; quantify error rates and their impact on training.
- Test tampering risk: agents likely have filesystem access to test scripts/binaries; the paper does not state that tests are isolated or integrity-protected. How can we securely verify outcomes (e.g., external host-side checks, sealed test runners, immutable mounts) to prevent reward hacking?
- Pipeline transparency: prompt designs, generator parameters, and failure reasons in each stage (container build, initial/final tests, solver pass rates) are not reported in detail. Release detailed prompts, stage-wise success/failure statistics, and ablations to enable replication and improvement.
- Scale and throughput: despite “endless” framing, the released set is 3,255 tasks; generation cost, throughput, and scalability constraints are not quantified. What are the bottlenecks (LLM generation, build times, solver cost), and how do performance and diversity change at 10×–100× scale?
- Credit assignment and reward shaping: training uses only binary episode-level rewards. Systematically evaluate partial rewards (per-test/pass fraction), step-level signals (e.g., exit codes, diff checks), exploration bonuses (novel command diversity), and anti-loop penalties to improve sample efficiency.
- Loop failure mitigation: loops account for 39% of failures; no training-time interventions are tested. Investigate loop detectors, action deduplication, recovery strategies, curriculum focusing on error-handling, and explicit rewards for command diversity or corrective behaviors.
- Context and turn limits: many failures arise from turn exhaustion; the effects of turn and token budgets, memory strategies (summarization, tool logs), and long-horizon tasks are not ablated. What is the optimal horizon and memory management to reduce repeated failures?
- Agent scaffolds: minimal scaffolding is used; retrieval, structured planning, and multi-agent collaboration are not explored. Under matched compute and turns, do richer scaffolds with the same environments significantly close the performance gap to frontier agents?
- Generalization breadth: transfer is shown only to TerminalBench 2.0 (small absolute gains) and limited OpenThinker tasks. Assess cross-domain transfer (SWE-bench, InterCode, WebArena), robustness under distribution shift, and whether environment scaling alone suffices for broader generalization.
- Safety and resource isolation: executing arbitrary commands in containers raises risks (resource abuse, network egress, filesystem leaks). Specify and evaluate sandbox policies (CPU/memory/IO limits, disabled networking by default, allowlists/denylists) and their impact on task realism.
- Container build loop limits: the iterative refinement is capped at k=3 rounds without analysis of its adequacy. Study dynamic retry budgets, fallback images, and automatic dependency resolution to reduce discard rates and expand solvable task diversity.
- One-command-per-turn constraint: constraining to a single command per turn may hinder realistic workflows (pipelines, scripts, compound operations). Evaluate allowing multiple commands or script blocks per turn with appropriate parsing and verifiability.
- Measurement rigor: results lack confidence intervals for training curves, per-category gains over time, and seed sensitivity. Provide statistical significance analyses, variance across seeds/runs, and sample-efficiency metrics (rewards per environment step).
- Dataset deduplication and novelty: no metrics on task redundancy or semantic overlap are reported. Introduce similarity/dedup checks, diversity objectives in generation, and temporal novelty tracking to prevent overfitting to repeated patterns.
- Reproducibility without proprietary models: the pipeline relies on o3 for solvability filtering; practitioners without access cannot reproduce core steps. Provide open-weight validator baselines and quantify performance gaps when using them.
- Preventing data leakage and overfitting: although the authors assert no leakage to TerminalBench 2.0, no formal leakage audit is presented. Develop automated leakage detection (string overlap, task-template similarity) and report overlap statistics.
Glossary
- Action budget: The maximum number of actions an agent can take before termination. "continues until declaring completion or exhausting its action budget."
- Agentic scaffold: An auxiliary control structure (tools, interfaces, or orchestration) that assists an agent’s reasoning and actions. "with a 200 turn limit and an agentic scaffold,"
- Apptainer: A container platform used to run reproducible environments with persistent sessions. "We use the Apptainer pipeline for all experiments."
- Binary episode level rewards: A reward scheme that gives 1 for task success and 0 for failure at the end of an episode, with no intermediate rewards. "vanilla PPO with binary episode level rewards"
- Completion tests: Automatically generated checks that verify whether the final state of the environment satisfies the task specification. "producing completion tests"
- Container definition: The specification file that describes how to build the containerized environment (e.g., dependencies, setup steps). "the model generates a container definition,"
- Containerized environments: Tasks packaged inside containers to ensure reproducible, isolated execution. "building and validating containerized environments"
- Context window: The maximum token length of the model’s input history it can attend to at once. "a total context window of 16k tokens"
- Dockerfile: A build specification file for Docker containers describing steps and dependencies. "an Apptainer container definition or Dockerfile"
- Environment timeout: A cap on how long environment interactions can run before being aborted. "we add a 5 minute environment timeout."
- Harbor (framework): A framework used to run Docker-based terminal environments for agents. "For Docker, we use the harbor framework."
- Initial state tests: Checks run before an episode starts to ensure the environment is correctly set up. "The initial state tests verify prerequisites for the task:"
- Iterative refinement loop: A process of generating, testing, and correcting environment definitions using feedback from build/test failures. "we employ an iterative refinement loop:"
- KL penalty: A regularization term penalizing divergence from a reference policy during RL fine-tuning. "We do not use a KL penalty"
- Multi-agent scaffolding: Orchestration that coordinates multiple agents or roles to solve tasks. "without retrieval or multi-agent scaffolding."
- o3 (model): A strong external model used to attempt solutions and filter tasks for solvability. "sampling 16 solutions from o3,"
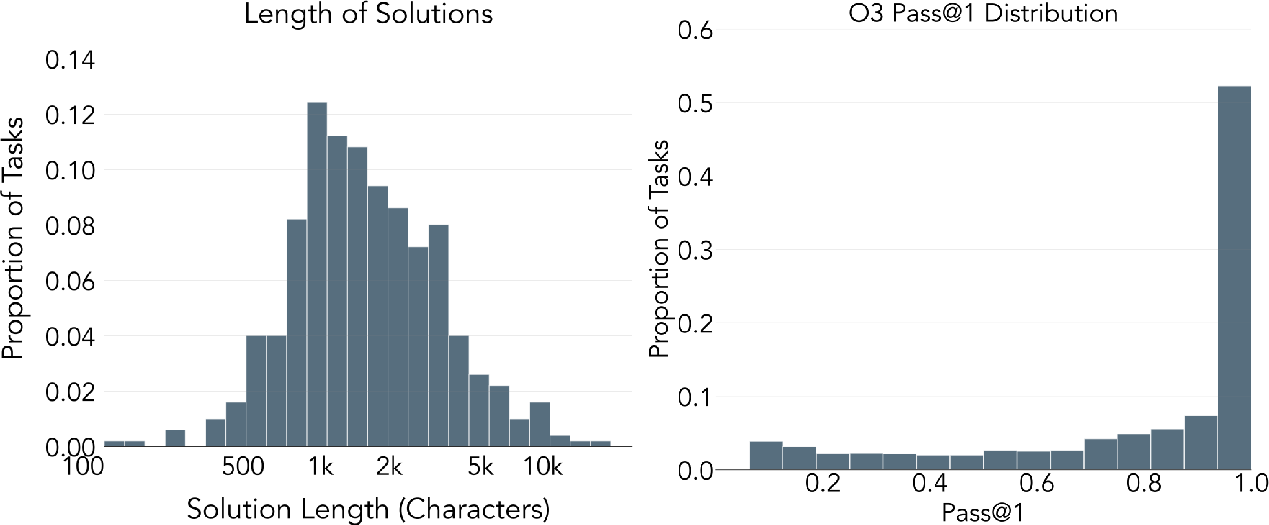
- pass@16: The probability of at least one success across 16 sampled attempts on a task. "pass@16 "
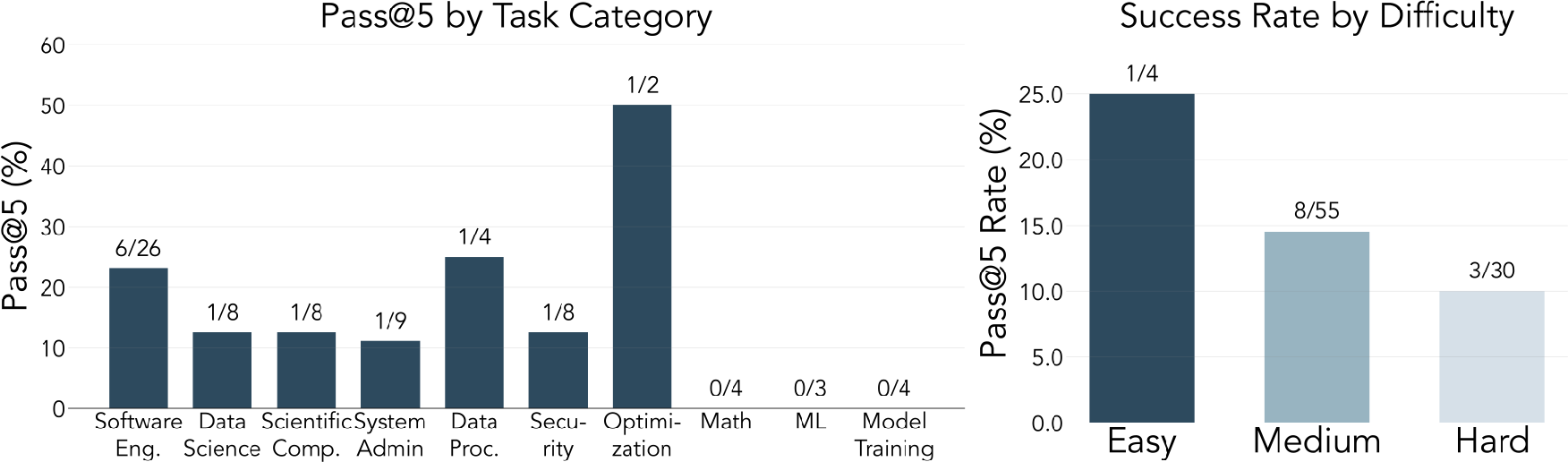
- pass@5: The probability of at least one success across 5 sampled attempts on a task. "Pass@5 rates (at least one success in 5 attempts) decrease with task difficulty:"
- Prerequisite tests: Automatically generated checks that validate required preconditions before a task begins. "validates them with self written prerequisite tests."
- Privileged ground truth: Hidden ground-truth information (files, paths, expected states) used to generate and validate tests but not shown to the agent. "paired with privileged ground truth information."
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm using clipped objectives for stable updates. "We train our agent with Proximal Policy Optimization (PPO)"
- Pseudo-terminal (PTY): An interface that emulates a terminal, enabling interactive shell sessions programmatically. "using a pseudo-terminal (PTY)."
- Retrieval: Augmenting an agent with the ability to fetch external information or tools during reasoning. "no retrieval, multi-agent coordination, or specialized tools."
- Rollouts: Sampled trajectories of agent-environment interactions collected for training. "we sample 16 rollouts per prompt"
- Self-play: A training paradigm where models generate and solve their own tasks to progressively scale difficulty. "Self-play approaches, where models iteratively generate tasks"
- Sequence level loss averaging: Averaging the loss across entire generated sequences when optimizing the RL objective. "with sequence level loss averaging."
- Sliding window: A strategy for managing long histories by keeping a moving subset of recent context within the model’s limit. "evaluate with 64 turns with a sliding window"
- Solvability filtering: Keeping only tasks for which at least one sampled solution attempt succeeds, ensuring validity. "Solvability filtering discards roughly half of all generated candidates,"
- Supervised finetuning (SFT): Training on labeled examples or distilled traces to provide a strong initialization before RL. "SFT can provide a warm start for RL training."
- tmux: A terminal multiplexer enabling programmatic control over persistent terminal sessions. "only an interactive tmux session controlled via keystrokes."
- TerminalBench 2.0: A human-curated benchmark for evaluating terminal-based agent capabilities. "On TerminalBench 2.0,"
- Turn limit: A cap on the number of agent interaction steps allowed per episode. "with a 200 turn limit"
- Vanilla PPO: Using standard PPO without additional tricks, shaping, or scaffolding. "Vanilla PPO \citep{schulman2017proximal} with 16 turns on Endless Terminals yields substantial gains:"
- SkyRL: A modular framework used to implement large-scale RL training for LLMs. "Our implementation uses SkyRL"
Practical Applications
Practical Applications of “Endless Terminals: Scaling RL Environments for Terminal Agents”
Below are actionable applications derived from the paper’s pipeline (procedural task generation, containerized environments with self-tests, solvability filtering) and findings (simple PPO + minimal agent loop improves terminal competence, gains transfer to human-curated benchmarks). Each item notes sector fit, potential tools/workflows, and key feasibility dependencies or assumptions.
Immediate Applications
These applications can be piloted or deployed with today’s tooling (Apptainer/Docker, Harbor, SkyRL/PPO, off-the-shelf 3–8B models, access to a capable validator model like o3).
Industry
- Agent training farm for DevOps/SRE/DataOps
- What: Use the Endless Terminals pipeline as an internal “AgentGym” to continuously generate, verify, and curate terminal tasks (file ops, log triage, scripting, DB ops) and train lightweight terminal agents via PPO.
- Sector: Software, cloud/SaaS, enterprise IT, data platforms.
- Product/workflow: “Endless Terminals-in-a-Box” (pipeline + task catalog + PPO trainer + CI hooks).
- Assumptions/dependencies: Secure container sandboxing (Apptainer/Docker), GPU capacity, policy-compliant access to a capable validator (o3 or equivalent) for pass@N filtering; guardrails to prevent destructive commands (non-root, network isolation).
- Continuous agent QA and benchmarking
- What: Establish a regression harness for terminal agents using curated Endless Terminals tasks plus external suites (e.g., TerminalBench 2.0). Track pass rates and failure modes (loops, turn exhaustion) per release.
- Sector: Agent vendors, platform teams, MLOps.
- Product/workflow: “Agent CI” with pass@k metrics, failure clustering by category, command-diversity loop detector.
- Assumptions/dependencies: Stable, reproducible containers; deterministic tests; cost and rate limits for multi-run evaluations.
- Runbook rehearsal and hardening for AIOps
- What: Automatically instantiate incidents (log anomalies, config drift, failed services) as verifiable terminal tasks; validate runbook steps and train remediation agents offline.
- Sector: Site reliability engineering (SRE), IT operations.
- Product/workflow: “RunbookGym” that turns incidents/postmortems into reproducible, auto-graded labs.
- Assumptions/dependencies: Realistic task templates, sanitized data, secure isolated environments; policies forbidding direct production access.
- Security training ranges (blue/red team)
- What: Procedurally generate containment, triage, and forensic CLI tasks (e.g., log analysis, checksum verification) with ground-truth tests; measure operator and agent performance.
- Sector: Cybersecurity, compliance.
- Product/workflow: “SecOps Range” with auto-graded challenges; agent-vs-human comparisons.
- Assumptions/dependencies: Careful scoping to avoid generating exploit content; network sandboxing; legal/compliance review.
- Hiring/skills assessment for CLI proficiency
- What: Auto-generate role-aligned Linux/DevOps challenges with instant grading; reduce manual lab curation.
- Sector: HR tech, engineering orgs, bootcamps.
- Product/workflow: “Terminal Skills Lab” with difficulty bands, pass/fail tests, explainable feedback.
- Assumptions/dependencies: Calibrated task difficulty; anti-cheat controls; reproducible grading.
Academia
- Low-cost RL lab for interactive agents
- What: Use the pipeline to teach RL for tool-using agents (minimal PPO, binary rewards, multi-turn episodes); reproduce paper’s “simple RL succeeds when environments scale.”
- Sector: CS/AI education and research.
- Product/workflow: Course modules with ready-made tasks, PPO baselines, and homework autograding.
- Assumptions/dependencies: Modest GPUs, container hosts; open-weight base models; institutional IRB/safety guidelines for shell execution.
- Benchmarking loop failures and recovery strategies
- What: Use command-diversity and loop metrics to study stuck behaviors; evaluate loop-busting strategies (e.g., exploration prompts, retry budgets, planning).
- Sector: AI research on agent reliability.
- Product/workflow: “LoopGuard” research suite with metrics and ablations.
- Assumptions/dependencies: Access to failure logs; standardized failure taxonomy; reproducible seeds.
Policy and Governance
- Sandboxed evaluation standard for terminal agents
- What: Institutionalize a procurement/evaluation protocol using containerized, auto-verifiable tasks to risk-assess agents that run commands.
- Sector: Government, regulated industries (finance, healthcare, energy).
- Product/workflow: “Agent Evaluation Profile” (AEP) with documented safety constraints, audit trails, and pass thresholds.
- Assumptions/dependencies: Clear sandboxing requirements (no privileged ops, SBOM scanning, egress controls); audit logging retained for compliance.
Daily Life
- Personal “Terminal Copilot” for local file/data hygiene
- What: A small on-device agent trained on ET-style tasks to help organize files, check backups, compress archives, and script simple automations safely in a sandbox.
- Sector: Consumer productivity, prosumers/home labs.
- Product/workflow: “Safe Shell” app with dry-run, non-interactive flags, and verified outcomes.
- Assumptions/dependencies: Strict sandboxing (no root), explicit user consent for actions, local-only mode to protect privacy.
- Home lab caretaker (non-root Linux assistant)
- What: Assist with non-destructive tasks (log inspection, disk usage, docker image cleanup) with verifiable checks before/after.
- Sector: Consumer NAS/home server/Raspberry Pi users.
- Product/workflow: “HomeOps Assistant” with preflight tests and revert/capture features.
- Assumptions/dependencies: Non-root containers, rate-limited action budgets, restore points.
Long-Term Applications
These require further research, scaling, or additional components (richer scaffolds, self-play difficulty scaling, domain-specific coverage, safety assurance).
Industry
- Self-healing infrastructure with closed-loop agents
- What: Production-grade agents that detect, diagnose, and remediate incidents (using retrieval, runbooks, and tool APIs), trained on continuously generated terminal environments plus real incident traces.
- Sector: Cloud/SaaS, telecom, fintech ops.
- Product/workflow: “Autonomous SRE” with guardrails (change windows, approvals, blast-radius limits).
- Assumptions/dependencies: Proven reliability beyond benchmark gains, human-in-the-loop governance, formal rollback guarantees, richer rewards than binary pass/fail.
- MLOps and data pipeline auto-remediation
- What: Agents that fix failed ETL/ML jobs, manage data checks, and adjust configs, trained on ET-style data processing tasks with DB ops.
- Sector: Data platforms, AI/ML product teams.
- Product/workflow: “Auto-Runbook for Pipelines” integrated with orchestration (Airflow, Argo), data quality checks, and lineage tools.
- Assumptions/dependencies: Domain coverage for ML/data-specific failures, secure credentials handling, compliance with data governance.
- Cross-domain “AgentGym” across enterprise tooling
- What: Extend the pipeline beyond bash to Kubernetes/Helm CLIs, cloud CLIs (AWS/GCP/Azure), ROS/robotics CLIs, and enterprise DBs with verifiable end-states.
- Sector: Cloud ops, robotics, manufacturing, finance back-office.
- Product/workflow: “TaskFoundry” that provisions multi-tool environments, auto-tests, and difficulty curricula.
- Assumptions/dependencies: Safe API emulators or sandboxes, licensing for vendor tools, realistic but non-sensitive fixtures.
- Agent certification and compliance frameworks
- What: Third-party certifications for terminal agents (safety, reliability, auditability), rooted in standardized, reproducible ET-like test batteries.
- Sector: Regulated industries, procurement.
- Product/workflow: Certification labs and public scorecards aligned to best-practice sandboxes.
- Assumptions/dependencies: Broad stakeholder buy-in, shared task repositories, independent test governance.
Academia
- Self-play task generation without frontier validators
- What: Replace the o3-based solvability filter with adaptive self-play (generate tasks just beyond current capability), lifting the ceiling on difficulty.
- Sector: RL/agent learning research.
- Product/workflow: “Curriculum-through-Self-Play” task engine + PPO/other algorithms.
- Assumptions/dependencies: Robust filtering against under/over-specified tasks, convergence analyses, catastrophic forgetting mitigation.
- World models of terminal dynamics for planning
- What: Learn environment models (or reasoning-based experience models) so agents can simulate command effects, improving sample efficiency and planning.
- Sector: Agent modeling, planning.
- Product/workflow: Model-based RL for terminal agents; offline imagination rollouts.
- Assumptions/dependencies: Accurate modeling of shell state transitions, partial observability handling, long-horizon credit assignment.
- Domain-specialized curricula (bioinformatics, crypto, ML)
- What: Expand ET task taxonomies into specialized domains where current agents fail; create verified, realistic, domain-authentic tasks.
- Sector: Healthcare/life sciences, security, scientific computing.
- Product/workflow: “Discipline Labs” with domain datasets, tools (e.g., samtools, BLAST, OpenSSL), and expert-authored verifiers.
- Assumptions/dependencies: Expert input or high-fidelity simulators; careful handling of sensitive data.
Policy and Governance
- Standardized sandboxing and auditability for autonomous agents
- What: Policy frameworks specifying isolation (non-root, network policies), audit logs, eBPF-based monitoring for agent command execution across industries.
- Sector: Public sector, critical infrastructure, finance/healthcare.
- Product/workflow: Reference “Agent Safety Sandbox” profiles and compliance audits.
- Assumptions/dependencies: Interoperable logging formats, regulator-approved controls, incident reporting standards.
- Compute and environmental governance for agent training
- What: Reporting and targets for energy/carbon use of large-scale agent RL training and evaluation.
- Sector: Sustainability, ESG reporting.
- Product/workflow: “Green RL” dashboards with per-episode compute/energy metrics; carbon budget compliance.
- Assumptions/dependencies: Reliable metering, accepted accounting methods for cloud/on-prem compute.
Daily Life
- Natural-language personal automation with “dry-run then apply”
- What: A general-purpose desktop automation agent (file/org/backup/CLI tasks) that plans, simulates, and shows diffs before execution.
- Sector: Consumer productivity.
- Product/workflow: “SafeApply” mode leveraging learned world models and verifiable checks.
- Assumptions/dependencies: Strong local safety guarantees, interpretable plans, user trust and control.
- Adaptive Linux tutor that handles ambiguity
- What: A learning assistant that asks clarifying questions, adapts tasks, and grades progress—moving beyond fully specified tasks to “fuzzy” real-world requests.
- Sector: Education, workforce upskilling.
- Product/workflow: Conversational labs with partial rewards, hinting systems, and personalized curricula.
- Assumptions/dependencies: Methods to balance naturalism with verifiability; robust partial-credit scoring.
Notes on Feasibility and Dependencies
- Validator dependency: The current pipeline’s solvability filter relies on a capable proprietary model (o3). This caps difficulty and introduces cost/licensing dependencies; self-play and open-weight validators would reduce this reliance over time.
- Security and safety: Running arbitrary commands requires strict sandboxing (non-root containers, filesystem isolation, network egress controls), audit logging, and abuse prevention (no destructive operations).
- Reproducibility: Flaky tests, non-deterministic environments, or mutable upstream artifacts will degrade reliability; pin images, cache artifacts, and use SBOM scanning.
- Generalization limits: Gains on human-curated benchmarks are positive but modest; production agents will likely require richer scaffolds (retrieval, tools, longer horizons), denser rewards, and domain-specific curricula.
- Compute and cost: PPO training and multi-attempt pass@k filtering are compute-intensive; budget for GPUs and inference costs, and track energy/carbon where required.
- Data sensitivity: Use synthetic or sanitized data to avoid leaking secrets/PHI; ensure compliance with data governance and privacy laws.
Collections
Sign up for free to add this paper to one or more collections.

