- The paper presents a unified feed-forward 3D Gaussian splatting pipeline that decomposes urban scenes into static close-range volumes, dynamic actors, and far-field scenery.
- It leverages a hybrid volume–pixel representation with DINO-based occlusion-aware visibility, achieving rapid convergence and >80 fps rendering performance.
- The method outperforms traditional NeRF and 3DGS approaches in rendering fidelity and scene editing capabilities, setting a new baseline for urban-scale 4D reconstruction.
EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis
Introduction and Motivation
Urban-scale novel view synthesis (NVS) is a critical problem in autonomous driving simulation, demanding fast, photo-realistic, and geometrically consistent reconstructions for both static and dynamic urban environments. The dominant paradigm—scene-specific optimization-based neural radiance fields (NeRF) and 3D Gaussian Splatting (3DGS)—achieves strong visual fidelity but suffers from prohibitive compute, limiting scalability. Recent feed-forward approaches deliver real-time inference, mostly by regressing per-pixel-aligned 3D Gaussians, but these methods introduce severe 3D inconsistency and redundant primitive allocation, especially in complex, dynamic urban scenes.
EVolSplat4D proposes a unified feed-forward 3D Gaussian Splatting pipeline that factors urban environments into three components: static close-range volumes, dynamic actors, and far-field scenery. Each is reconstructed in a specialized branch with dedicated geometric and appearance modeling, fusing volume-based and pixel-based predictions. This design prioritizes world-aligned volumetric consistency for the near-field and leverages efficient per-pixel modeling for unbounded backgrounds, all while supporting real-time NVS and enabling fast scene editing and decomposition use-cases.

Figure 2: EVolSplat4D system architecture, supporting efficient 4D scene reconstruction and high-fidelity rendering in real time.
Methodology
Scene Decomposition and Specialized Branches
EVolSplat4D decomposes a scene into:
- Close-range static volume: Modes structures near the ego-vehicle in a 3D Euclidean voxel grid, utilizing image-level semantic features and depth, followed by a 3D CNN to regress multi-view consistent Gaussian attributes. Appearance is handled with a robust occlusion-aware IBR that blends colors across views, using DINOv2 feature similarity for visibility estimation.
- Dynamic actors: Each tracked vehicle or actor is represented in an object-centric canonical space, with multi-frame aggregation yielding stable geometry. Geometry is parameterized by 3D bounding boxes tracked across time (from LiDAR or monocular predictions). Rendering adapts object pose per-timestamp, employing a motion-adjusted IBR to regress per-Gaussian color and opacity, addressing box noise and projection ambiguities.
- Far-field scenery: A 2D U-Net with cross-view attention regresses pixel-aligned 3D Gaussians, informed by Plücker ray embeddings and masks to prevent dynamic actors from corrupting the static background.
Specialized α-compositional rendering fuses these three branches for final image synthesis.
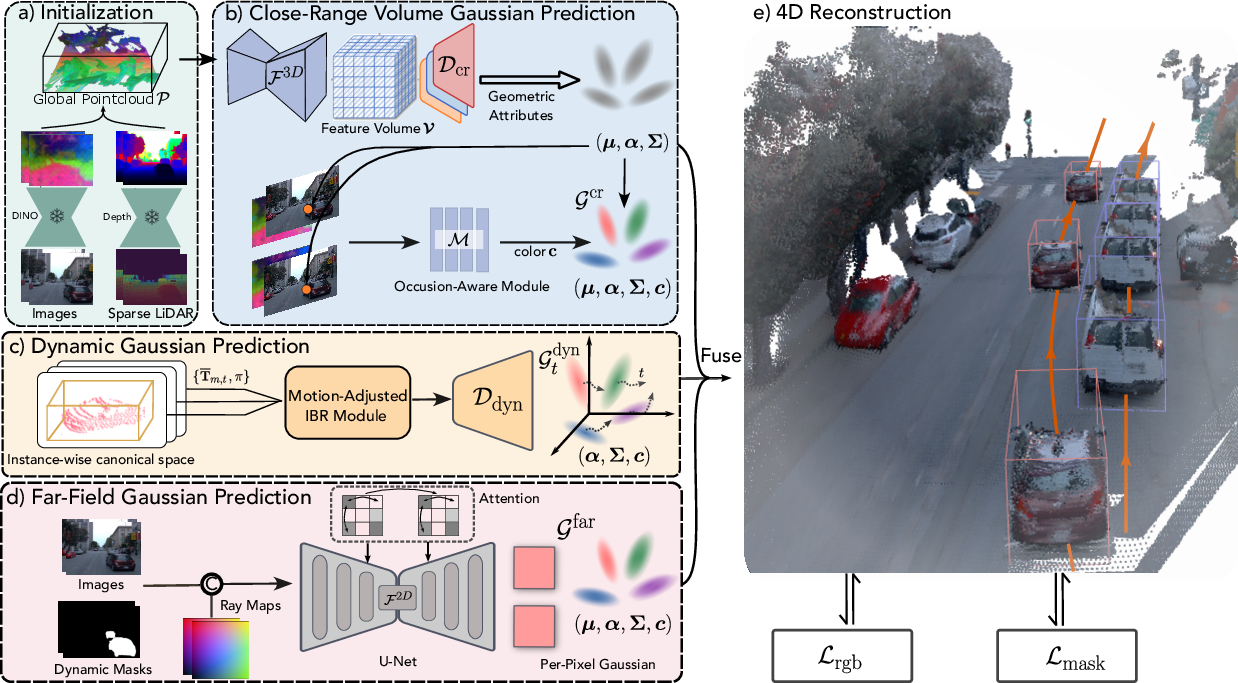
Figure 4: Pipeline for branch-wise scene factorization: close-range static objects, dynamic actors, and far-field scenery, each predicted and composed via dedicated neural modules.
Geometric and Appearance Priors
The methodology leverages strong geometric consistency, initializing point clouds using either LiDAR or high-quality monocular depth priors, then applying PCA-compressed DINO features lifted to world coordinates. Filters and learned refinement minimize floaters and redundant sampling. The offset estimation for each Gaussian (Δμi) is recursively refined, stabilizing rapidly in practice.
Occlusion-aware appearance prediction is realized by sampling local windows in 2D and using softmax-normalized DINO feature similarity for visibility. Rather than naive masking, an MLP consumes all windowed color and visibility data to regress color spherical harmonics.
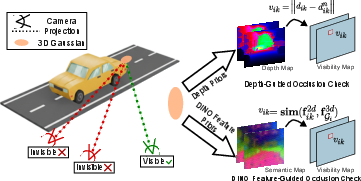


Figure 6: Occlusion modeling via feature- and depth-guided checks: DINO-based similarity enables robust occlusion detection, improving color consistency under heavy occlusion.
Dynamic Actor Integration
Dynamic objects are reconciled across time by transforming canonical points using SE(3) pose estimation derived from tracking. The windowed IBR approach samples features across temporally aligned views, handling tracking errors robustly. This yields a dynamic Gaussian set with time-dependent attributes, composable into the scene rasterization.
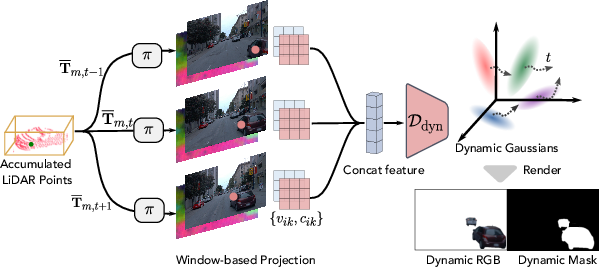
Figure 8: Motion-adjusted image-based rendering in the dynamic branch aligns appearance queries using per-instance canonical/pose transformations and local 2D windows.
Hybrid Volume–Pixel Representation
The close-range branch's world-aligned Gaussians guarantee localization accuracy and multi-view consistency. The far-field branch's pixel-aligned Gaussians address the diversity and sparsity of backgrounds. The system integrates these via explicit mask-based losses to ensure decomposability and minimal branch overlap.








Figure 10: Qualitative scene decomposition on Waymo: predicted layers for close-range, dynamic actors, and far-field.
Experimental Evaluation
EVolSplat4D achieves superior photometric and perceptual metrics (PSNR, SSIM, LPIPS) on KITTI-360, Waymo, KITTI, and PandaSet compared to both NeRF-based and feed-forward 3DGS baselines such as MVSplat, PixelSplat, and AnySplat, with significant margins on dynamic scenes and strong generalization from KITTI-360 to Waymo and PandaSet.
Real-time rendering is achieved with >80 fps and low GPU memory occupancy (ca. 10 GB), exceeding prior 3DGS-based methods. The architecture is agnostic to depth prior modality; monocular or LiDAR depth yields statistically equivalent image quality, as confirmed by controlled ablations.





Figure 1: Qualitative comparison with feed-forward baselines on KITTI-360: EVolSplat4D eliminates ghosting and inconsistent artifacts in baseline methods.












Figure 3: Dynamic scene rendering from KITTI in comparison with contemporary methods; EVolSplat4D outperforms in moving object fidelity and scene consistency.
Optimization-Based Method Comparison
With a 1.3s feed-forward initialization, EVolSplat4D achieves competitive or better photorealism compared to optimization-based SUDS, EmerNeRF, StreetGaussian, and OmniRe under challenging input sparsity, converging orders-of-magnitude faster. Fine-tuning further improves PSNR and LPIPS, with observed convergence in 1,000 steps (vs. ∼14 minutes for SOTA).
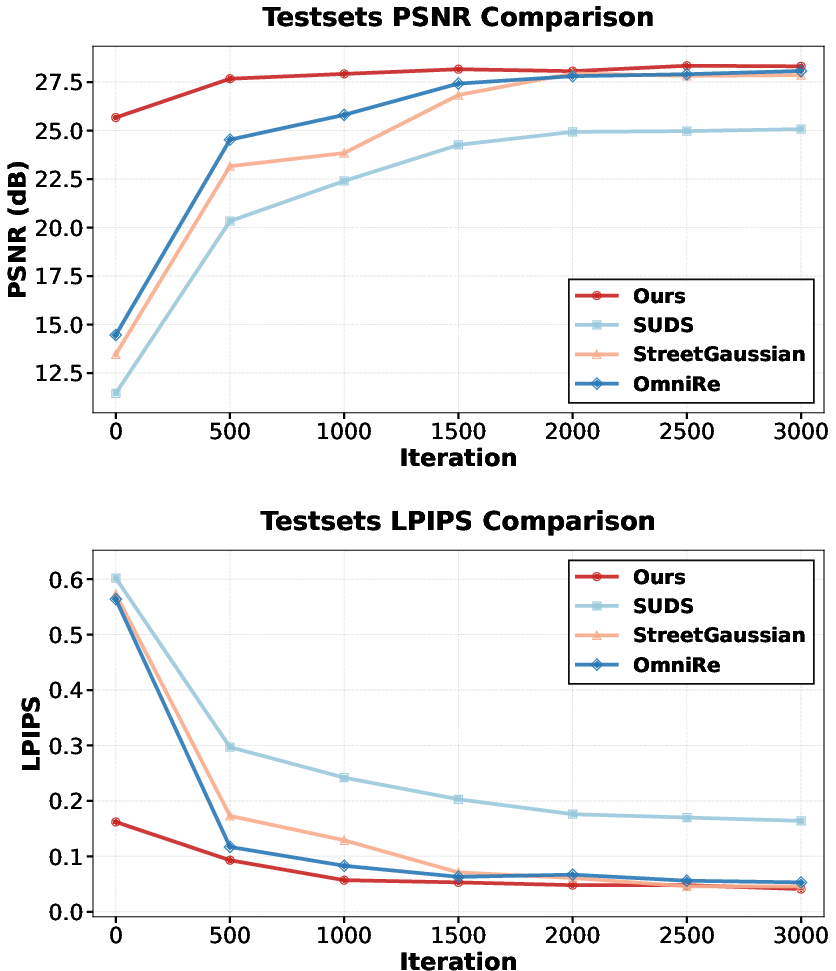
Figure 5: Convergence trajectory on Waymo: EVolSplat4D achieves rapid improvement and superior PSNR compared to per-scene optimization baselines, with strong perceptual metrics.
Ablation and Design Analysis
Ablations confirm the necessity of the hybrid volumetric–pixel design, windowed color sampling, DINO-based visibility (for both static and dynamic), and scene decomposition loss. Removing any component degrades physical realism, increases ghosting, or creates semi-transparent artifacts in dense reconstructions. The motion-adjusted dynamic IBR branch is essential for high-fidelity actor rendering, even with noisy tracking.




Figure 7: Branch-specific ablation: removing the volume branch, pixel branch, or occlusion modeling progressively degrades rendering fidelity.
Advanced Applications
The compositional, factorized representation supports scene editing operations like object replacement, translation, and removal in real time by manipulating branch outputs and associated canonical coordinates.






Figure 11: Scene editing capabilities—object replacement, shift, and deletion—enabled by independent Gaussian branch modeling.
Implications and Outlook
The architectural advancements in EVolSplat4D signal a shift in scalable urban scene synthesis: explicit hybrid factorization into volumetric, dynamic, and pixel-aligned components offers a path to real-time, high-fidelity NVS in highly dynamic environments using only sparse input modalities. The modularity established by the method, especially in its use of object-centric canonical spaces and explicit branch decoupling, is especially amenable to future simulation, interactive editing, and data-driven scenario generation for autonomous driving research.
Potential future developments include:
- End-to-end integration with monocular 3D detection, removing the dependency on LiDAR-derived bounding boxes.
- Enhancements in nonrigid dynamic actor modeling through deformable canonical representations.
- Improved far-field fidelity under extreme viewpoint extrapolation via stronger and more explicit geometric supervision.
- Generalization to other open-world NVS scenarios where active sensor availability and actor count vary.
Limitations
Despite its flexibility, the current approach assumes organized rigid motion for all dynamic actors, which limits performance when faced with nonrigid entities (e.g., pedestrians). Far-field modeling, while efficient, does not benefit from explicit geometric priors, which may limit extreme extrapolation realism. Reliance on bounding box tracking (LiDAR or monocular) remains a bottleneck until sufficiently accurate camera-only solutions are commonplace.
Conclusion
EVolSplat4D delivers a real-time, feed-forward solution for urban-scale 4D reconstruction, leveraging expert fusion of volumetric and pixel-aligned Gaussian splatting, canonical dynamic modeling, and strong appearance/geometric priors. The architecture demonstrates significant advances in rendering quality, speed, and generalization while supporting advanced applications in scene editing and decomposition, setting a new baseline for efficient large-scale NVS in autonomous systems.
Reference: "EVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis" (2601.15951)