- The paper presents a fully automated pipeline that enhances dynamic scene reconstruction by refining segmentation masks, depth estimates, and point tracks.
- It integrates novel loss functions, including virtual-view depth and scaffold-projection losses, to improve geometric coherence and suppress artifacts.
- Quantitative results show improved PSNR, SSIM, and LPIPS metrics over existing methods, demonstrating robustness in diverse, in-the-wild scenes.
Prior-Enhanced Gaussian Splatting for Dynamic Scene Reconstruction from Casual Video
Introduction
This paper presents a fully automated pipeline for dynamic scene reconstruction from monocular RGB videos, focused on improving the quality of foundation model priors integrated into Dynamic Gaussian Splatting (DGS). Gaussian Splatting has established itself as an efficient, point-based scene representation capable of capturing static and dynamic geometry with real-time rasterization. The proposed method enhances depth, masks, and point tracks sourced from vision foundation models to overcome critical bottlenecks in dynamic scene fidelity—particularly for thin structures and complex object motions—without inventing a new scene representation.
Method Overview
The approach follows a three-stage pipeline: (I) Initialization, (II) Lifting to 3-D, and (III) Dynamic Scene Reconstruction. Initialization extracts dynamic object segmentation masks using video segmentation fused with epipolar error maps, enabling more precise identification of moving object regions. The masks guide depth refinement and skeleton-based sampling for robust 2-D trajectory extraction, including mask-guided re-identification for occlusion recovery. These higher-quality priors are embedded into the reconstruction process via a virtual-view depth loss to prevent floaters and a scaffold-projection loss for geometric coherence.
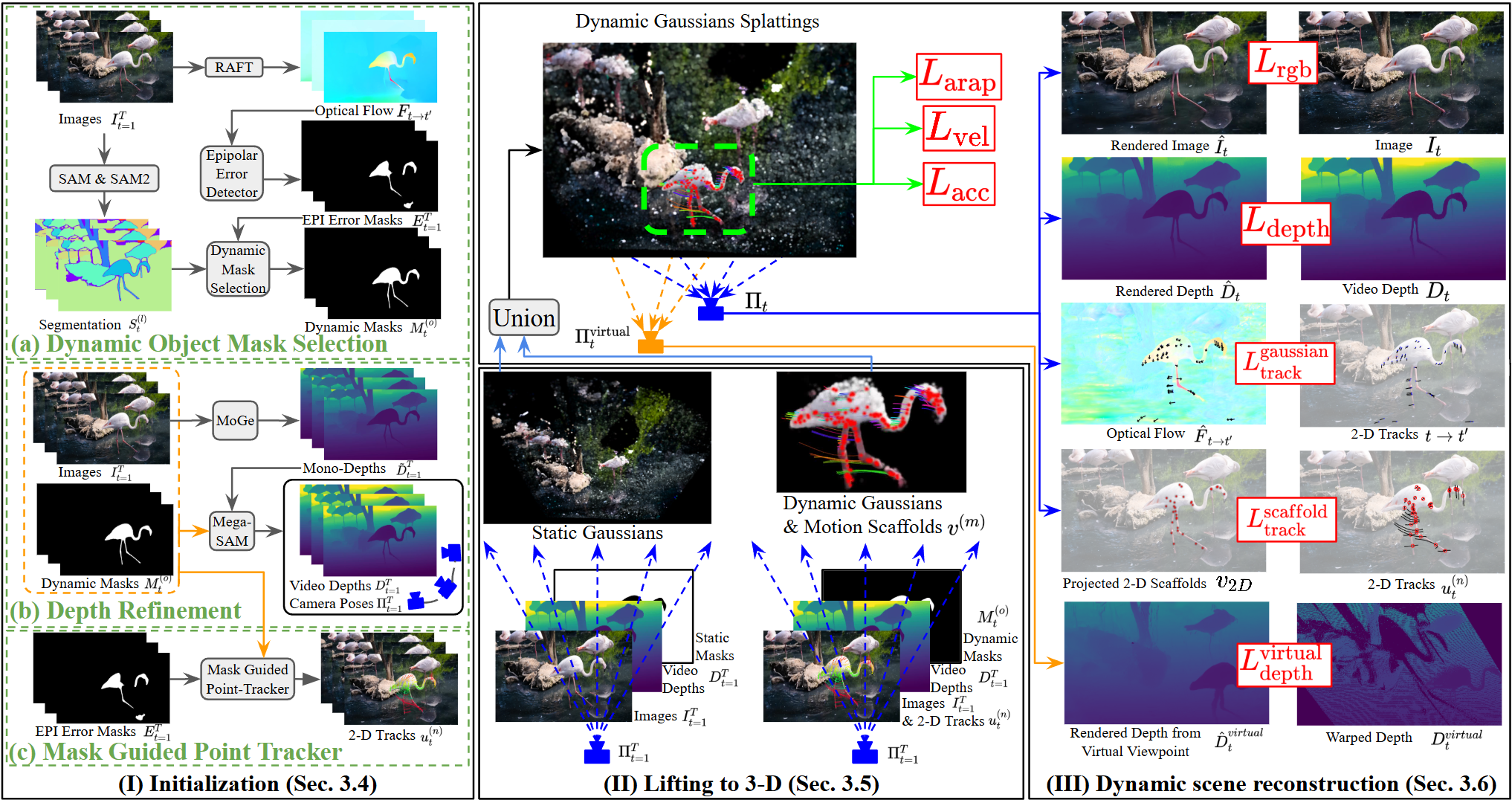
Figure 1: The three-stage pipeline enabling high-fidelity monocular dynamic scene reconstruction via prior enhancement and novel supervisory objectives.
Foundation Model Prior Enhancement
Dynamic Object Mask Selection
By intersecting epipolar error masks (EPI) with video segmentation, the method reliably isolates dynamic objects—removing static distractors (e.g., shadows) with dual-threshold filtering. This robust masking enables targeted depth and track supervision.






Figure 2: Dynamic mask selection via EPI error mask and segment intersection, ensuring only salient dynamic object regions are retained for reconstruction.
Depth Refinement
Mono-depth estimates (from MoGe) are aligned to the temporally consistent video depth; an object-depth loss is introduced to sharpen dynamic object detail within the mask. This correction recovers thin, mobile structures and maintains global scene alignment, enhancing fidelity for both geometry and appearance.
Figure 3: Object-specific depth refinement significantly reconstructs thin dynamic structures lost in standard depth estimation approaches.
Mask-Guided Point Tracking
Skeletons extracted from dynamic masks and densely sampled along medial axes yield more informative 2-D tracks, particularly across challenging regions (e.g., limbs). Mask-guided re-identification recovers tracks lost to occlusion by leveraging object mask consistency. A self-occlusion filter rejects false track re-entries based on trajectory deviation.
Figure 4: Skeleton-based track sampling ensures dense coverage of complex structures, ameliorating undersampling issues in conventional mask approaches.
Figure 5: Mask-guided track re-identification bridges gaps caused by occlusion, improving overall dynamic scene coverage.
3-D Lifting and Motion Scaffolding
Dynamic pixels are back-projected to initialize 3-D Gaussians; long-range tracks are promoted to sparse motion-scaffold nodes. Spatial and temporal optimization regularize the initial scene estimate, providing coherent starting points for downstream refinement.
Reconstruction Supervision with Novel Objectives
The main supervision signals (appearance, depth, track loss) propagate prior-derived constraints onto both the Gaussian cloud and the underlying motion scaffolds. Two critical new losses—virtual-view depth and scaffold-projection—directly address consistent dynamic geometry and floating artifact suppression.
Virtual-View Depth Loss
By generating synthetic views via camera extrinsic perturbation, a depth loss on these virtual viewpoints regularizes the scene to prevent view-dependent floaters and overfitting to training perspectives. This significantly reduces out-of-distribution artifacts for novel view synthesis.
Figure 6: Virtual-view depth loss removes floaters associated with limited baseline training views, preserving clean geometry under viewpoint shift.
Scaffold-Projection Loss
The scaffold-projection loss anchors scaffold nodes to projected 2-D tracks, preventing drift (especially for thin, fast-moving segments) otherwise unaddressed by ARAP regularization.

Figure 7: Scaffold-projection loss maintains track-to-scaffold consistency, culling spatial drift in thin or highly articulated regions.
Experimental Results
Quantitative Comparisons
On DyCheck [gao2022monocular], the method outperforms baseline monocular DGS systems Shape of Motion [wang2024shape] and MoSca [lei2024mosca] across PSNR, SSIM, and LPIPS metrics in both pose-free RGB and depth+pose regimes. On NVIDIA multi-view videos, results are marginally higher than MoSca and clearly better than RoDynRF [liu2023robust].
Ablation Studies
Mask-guided point tracking and re-ID, scaffold-projection loss, and virtual-view depth regularization each contribute to geometric and appearance improvement, especially for thin moving regions and occlusion-heavy sequences.
Figure 8: Comparative view synthesis on iPhone dataset; proposed method preserves texture and geometry in challenging dynamic regions compared to baselines.
Figure 9: Skeleton sampling increases fidelity in thin regions compared to uniform EPI error mask sampling.
Figure 10: Track re-identification staves off occlusion-induced failures compared to baseline trackers.
Figure 11: Scaffold-projection loss ablation—critical for maintaining spatial correspondence in articulated regions.
Figure 12: Local depth refinement further improves fine structure preservation.
Figure 13: Depth refinement sharply affects novel view synthesis, restoring true object geometry.
Figure 14: Virtual-view depth loss ablation; presence yields superior artifact-free novel viewpoints.
Implications and Future Directions
The results demonstrate the significant impact of leveraging and refining foundation model outputs—specifically segmentation, depth estimation, and point tracking—rather than solely elaborating scene representations. The pipeline achieves state-of-the-art results in dynamic monocular video, fully automatically, and demonstrates robustness to challenging in-the-wild sequences (DAVIS). Practically, it advances AR/VR content workflows where sensor and calibration scarcity is common.
Theoretically, the approach highlights the bottleneck shift from physical representations to prior quality and supervisory signal alignment in contemporary dynamic reconstruction. Future development in text/image/video foundation models and tracking will directly carry over to further gains in scene fidelity. Integrating generative video models may address present limitations in handling motion blur and unseen regions.
Conclusion
This work demonstrates that targeted enhancement of segmentation, depth, and track priors—combined with loss terms designed to propagate these improvements—substantially advances the performance envelope of monocular dynamic scene reconstruction with Gaussian Splatting. The approach is modular, scalable, and readily extensible to new vision priors, setting the stage for further improvements in both algorithmic sophistication and practical deployability.
Figure 15: Qualitative improvements in DAVIS dataset synthesis; proposed pipeline robustly reconstructs dynamic scenes with fine detail and background integrity.